
1년간의 SEO 사례 연구: Googlebot에 대해 알아야 할 사항
게시 됨: 2019-08-30편집자 주: JetOctopus 크롤러의 CEO인 Serge Bezborodov가 웹사이트를 Googlebot에 매력적으로 만드는 방법에 대한 전문적인 조언을 제공합니다. 이 문서의 데이터는 1년간의 연구와 3억 개의 크롤링 페이지를 기반으로 합니다.
몇 년 전, 저는 500만 페이지가 넘는 채용정보 웹사이트의 트래픽을 늘리려고 했습니다. 나는 트래픽이 지붕을 통과할 것으로 예상하여 SEO 대행사 서비스를 사용하기로 결정했습니다. 그러나 나는 틀렸다. 종합 감사 대신 타로 카드 읽기를 받았습니다. 그래서 처음으로 돌아가 종합적인 페이지 SEO 분석을 위한 웹 크롤러를 만들었습니다.
저는 1년 넘게 Googlebot을 염탐해 왔으며 이제 Googlebot의 행동에 대한 통찰력을 공유할 준비가 되었습니다. 내 관찰이 적어도 웹 크롤러가 작동하는 방식을 명확히 하고 기껏해야 페이지 최적화를 효율적으로 수행하는 데 도움이 될 것으로 기대합니다. 나는 새로운 웹사이트나 수천 페이지가 있는 웹사이트에 유용한 가장 의미 있는 데이터를 수집했습니다.
귀하의 페이지가 SERP에 표시됩니까?
검색 결과에 어떤 페이지가 있는지 확인하려면 전체 웹 사이트의 색인 기능을 확인해야 합니다. 그러나 1,000만 페이지가 넘는 웹사이트의 각 URL을 분석하는 데는 거의 새 차 한 대만큼의 비용이 듭니다.
대신 로그 파일 분석을 사용하겠습니다. 우리는 다음과 같은 방식으로 웹 사이트를 작업합니다. 검색 봇처럼 웹 페이지를 크롤링한 다음 반년 동안 수집된 로그 파일을 분석합니다. 로그는 봇이 웹 사이트를 방문했는지 여부, 크롤링된 페이지, 봇이 페이지를 방문한 시기와 빈도를 보여줍니다.
크롤링은 검색 봇이 귀하의 웹사이트를 방문하여 웹 페이지의 모든 링크를 처리하고 이러한 링크를 인덱싱을 위해 배치하는 프로세스입니다. 크롤링 중에 봇은 방금 처리된 URL을 이미 색인에 있는 URL과 비교합니다. 따라서 봇은 데이터를 새로 고치고 검색 엔진 데이터베이스에서 일부 URL을 추가/삭제하여 사용자에게 가장 관련성이 높고 새로운 결과를 제공합니다.
이제 다음과 같은 결론을 쉽게 내릴 수 있습니다.
- 검색 봇이 URL에 있지 않는 한 이 URL은 색인에 없을 것입니다.
- Googlebot이 하루에 여러 번 URL을 방문하는 경우 해당 URL은 우선순위가 높으므로 특별한 주의가 필요합니다.
전체적으로 이 정보는 웹사이트의 유기적인 성장과 개발을 방해하는 요소를 보여줍니다. 이제 맹목적으로 운영하는 대신 팀이 현명하게 웹사이트를 최적화할 수 있습니다.
귀하의 웹사이트가 작으면 Googlebot이 조만간 모든 웹페이지를 크롤링하기 때문에 우리는 주로 대형 웹사이트에서 작업합니다.
반대로 100,000+ 페이지가 있는 웹사이트는 크롤러가 웹마스터에게 보이지 않는 페이지를 방문할 때 문제에 직면합니다. 가치 있는 크롤링 예산이 이러한 쓸모 없거나 유해한 페이지에 낭비될 수 있습니다. 동시에 웹 사이트 구조가 엉망이기 때문에 봇이 수익성 있는 페이지를 찾지 못할 수도 있습니다.
크롤링 예산은 Googlebot이 웹사이트에서 사용할 수 있는 제한된 리소스입니다. 무엇을 언제 분석할지 우선순위를 정하기 위해 만들어졌습니다. 크롤링 예산의 크기는 웹사이트의 크기, 구조, 사용자 쿼리의 볼륨 및 빈도 등과 같은 여러 요인에 따라 달라집니다.
검색 봇은 웹사이트를 완전히 크롤링하는 데 관심이 없습니다.
검색 엔진 봇의 주요 목적은 리소스 손실을 최소화하면서 사용자에게 가장 관련성 높은 답변을 제공하는 것입니다.봇은 주요 목적에 필요한 만큼의 데이터를 크롤링합니다. 따라서 봇이 가장 유용하고 수익성 있는 콘텐츠를 선택하도록 돕는 것은 귀하의 임무입니다.
Googlebot 감시
작년에 우리는 대형 웹사이트에서 3억 개 이상의 URL과 60억 개 이상의 로그 라인을 스캔했습니다. 이 데이터를 기반으로 Googlebot의 동작을 추적하여 다음 질문에 답했습니다.
- 어떤 유형의 페이지가 무시됩니까?
- 자주 방문하는 페이지는?
- 봇의 주목할만한 점은 무엇입니까?
- 가치가 없는 것은?
아래는 Google 웹마스터 가이드라인을 재작성한 것이 아니라 분석 및 결과입니다. 실제로 입증되지 않고 정당하지 않은 권장 사항은 제공하지 않습니다. 각 포인트는 사용자의 편의를 위해 사실에 입각한 통계와 그래프를 기반으로 합니다.
추적을 중단하고 알아봅시다.
- Googlebot에게 정말 중요한 것은 무엇인가요?
- 봇이 페이지를 방문하는지 여부는 어떻게 결정됩니까?
다음과 같은 요인을 확인했습니다.
인덱스로부터의 거리
DFI는 Distance From Index를 의미하며 URL이 기본/루트/색인 URL에 대한 클릭 수입니다. Googlebot의 방문 빈도에 영향을 미치는 가장 중요한 기준 중 하나입니다. 다음은 DFI에 대해 자세히 알아볼 수 있는 교육용 비디오입니다 .
DFI는 예를 들어 다음과 같은 URL 디렉토리의 슬래시 수가 아닙니다.
site.com / shop /iphone/iphoneX.html – DFI – 3
따라서 DFI는 메인 페이지에서 CLICKS로 정확하게 계산됩니다.
https://site.com/shop/iphone/iphoneX.html
https://site.com iPhone 카탈로그 → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
아래에서 DFI가 포함된 URL에 대한 Googlebot의 관심이 지난 달과 지난 6개월 동안 어떻게 점진적으로 감소했는지 확인할 수 있습니다.
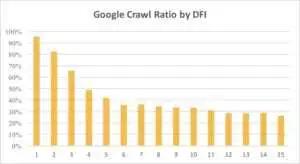
보시다시피 DFI가 5 t0 6이면 Googlebot은 웹페이지의 절반만 크롤링합니다. 그리고 DFI가 더 크면 처리된 페이지의 비율이 줄어듭니다. 표의 지표는 1,800만 페이지에 대해 통일되었습니다. 데이터는 특정 웹사이트의 틈새 시장에 따라 다를 수 있습니다.
무엇을 해야 합니까?
이 경우 가장 좋은 전략은 5보다 긴 DFI를 피하고, 탐색하기 쉬운 웹 사이트 구조를 구축하고, 링크에 특히 주의를 기울이는 것임이 자명합니다.
사실 이러한 조치는 100,000개 이상의 페이지가 있는 웹사이트에서 정말 시간이 많이 걸립니다. 일반적으로 큰 웹사이트는 재설계 및 마이그레이션의 오랜 역사를 가지고 있습니다. 그렇기 때문에 웹마스터는 DFI가 10, 12, 심지어 30인 페이지를 그냥 삭제해서는 안 됩니다. 또한 자주 방문하는 페이지에서 하나의 링크를 삽입하는 것으로는 문제가 해결되지 않습니다.
긴 DFI에 대처하는 최적의 방법은 이러한 URL이 관련성 있고 수익성이 있으며 SERP에서 어떤 위치에 있는지 확인하고 추정하는 것입니다.
DFI가 길지만 SERP에서 좋은 위치에 있는 페이지는 잠재력이 높습니다. 고품질 페이지의 트래픽을 늘리려면 웹마스터가 다음 페이지의 링크를 삽입해야 합니다. 1~2개의 링크로는 가시적인 진전을 이루기에 충분하지 않습니다.
페이지에 10개 이상의 링크가 있는 경우 Googlebot이 URL을 더 자주 방문한다는 것을 아래 그래프에서 확인할 수 있습니다.
연결
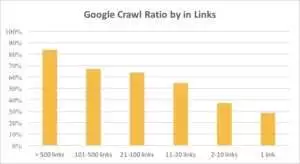
사실, 웹사이트가 클수록 웹페이지에 있는 링크의 수도 더 많습니다. 이 데이터는 실제로 100만 페이지가 넘는 웹사이트에서 가져온 것입니다.

수익성 있는 페이지에 링크가 10개 미만인 경우 당황하지 마십시오. 먼저 이러한 페이지가 고품질이고 수익성이 있는지 확인하십시오. 그렇게 할 때 서두르지 않고 짧은 반복으로 고품질 페이지에 링크를 삽입하고 각 단계 후 로그를 분석하십시오.
콘텐츠 크기
콘텐츠는 SEO 분석에서 가장 인기 있는 측면 중 하나입니다. 물론 웹사이트에 관련 콘텐츠가 많을수록 크롤링 비율이 높아집니다. 아래에서 500단어 미만의 페이지에서 Googlebot의 관심이 얼마나 극적으로 감소하는지 확인할 수 있습니다.
무엇을 해야 합니까?
내 경험에 따르면 500단어 미만의 모든 페이지 중 거의 절반이 휴지통 페이지입니다. 우리는 한 웹사이트가 70,000페이지에 옷 사이즈만 나와 있어서 그 중 일부만 색인에 있는 경우를 보았습니다.
따라서 먼저 해당 페이지가 정말로 필요한지 확인하십시오. 이러한 URL이 중요한 경우 관련 콘텐츠를 추가해야 합니다. 추가할 것이 없으면 긴장을 풀고 이 URL을 그대로 두십시오. 때로는 쓸모없는 콘텐츠를 게시하는 것보다 아무것도 하지 않는 것이 더 나을 수 있습니다.
기타 요인
다음 요소는 크롤링 비율에 상당한 영향을 미칠 수 있습니다.
로드 시간
웹 페이지 속도는 크롤링 및 순위 결정에 매우 중요합니다. 봇은 인간과 같습니다. 웹 페이지가 로드될 때까지 너무 오래 기다리는 것을 싫어합니다. 웹 사이트에 100만 개 이상의 페이지가 있는 경우 검색 봇은 5초 안에 로드되는 한 페이지를 기다리지 않고 1초 로드 시간으로 5개의 페이지를 다운로드할 것입니다.
무엇을 해야 합니까?
사실 이것은 기술적인 작업이며 더 큰 서버를 사용하는 것과 같은 "하나의 방법에 모두 맞는" 솔루션은 없습니다. 주요 아이디어는 문제의 병목 현상을 찾는 것입니다. 웹 페이지가 느리게 로드되는 이유를 이해해야 합니다. 이유가 밝혀진 후에야 조치를 취할 수 있습니다.
고유하고 템플릿화된 콘텐츠의 비율
고유한 데이터와 템플릿 데이터 간의 균형이 중요합니다. 예를 들어 다양한 애완 동물 이름이 있는 웹사이트가 있습니다. 이 주제에 대해 실제로 얼마나 관련성 있고 고유한 콘텐츠를 수집할 수 있습니까?
루나는 가장 인기 있는 "연예인" 개 이름이었고, 스텔라, 잭, 마일로, 레오가 그 뒤를 이었습니다.
검색 봇은 이러한 종류의 페이지에 리소스를 사용하는 것을 좋아하지 않습니다.
무엇을 해야 합니까?
균형을 유지하십시오. 사용자와 봇은 복잡한 템플릿, 나가는 링크가 많고 콘텐츠가 적은 페이지를 방문하는 것을 좋아하지 않습니다.
고아 페이지
고아 페이지는 웹 사이트 구조에 없고 이러한 페이지에 대해 알지 못하는 URL이지만 이러한 고아 페이지는 봇에 의해 크롤링될 수 있습니다. 명확하게 하기 위해 아래 그림에서 오일러의 원을 살펴보십시오 .

한동안 구조가 변경되지 않은 신생 웹 사이트의 정상적인 상황을 볼 수 있습니다. 사용자와 크롤러가 분석할 수 있는 페이지는 900,000개입니다. 약 500,000개의 페이지가 크롤러에 의해 처리되지만 Google에서는 알 수 없습니다. 이 500,000개의 URL을 인덱싱 가능하게 만들면 트래픽이 확실히 증가합니다.
주의: 신생 웹사이트에도 웹사이트 구조에는 없지만 봇이 정기적으로 방문하는 일부 페이지(그림의 파란색 부분)가 포함되어 있습니다.
그리고 이러한 페이지에는 쓸모없는 자동 생성 방문자의 검색어와 같은 쓰레기 콘텐츠가 포함될 수 있습니다.
그러나 큰 웹사이트는 그렇게 정확하지 않습니다. 매우 자주 기록이 있는 웹사이트는 다음과 같습니다.

여기 또 다른 문제가 있습니다. Google은 귀하보다 귀하의 웹사이트에 대해 더 많이 알고 있습니다. 삭제된 페이지, JavaScript 또는 Ajax 페이지, 잘못된 리디렉션 등이 있을 수 있습니다. 한 번은 프로그래머의 실수로 인해 사이트맵에 500,000개의 끊어진 링크 목록이 나타나는 상황에 직면한 적이 있습니다. 3일 후 버그를 찾아 수정했지만 Googlebot은 반년 동안 이 끊어진 링크를 방문했습니다!
너무 자주 크롤링 예산이 이러한 고아 페이지에서 낭비되는 경우가 많습니다.
무엇을 해야 합니까?
이 잠재적인 문제를 해결하는 방법에는 두 가지가 있습니다. 첫 번째는 정식입니다. 엉망진창 정리입니다. 웹사이트 구조를 구성하고, 내부 링크를 올바르게 삽입하고, 색인이 생성된 페이지의 링크를 추가하여 고아 페이지를 DFI에 추가하고, 프로그래머를 위한 작업을 설정하고, 다음 Googlebot 방문을 기다립니다.
두 번째 방법은 프롬프트입니다. 고아 페이지 목록을 수집하고 관련성이 있는지 확인합니다. 대답이 "예"이면 이 URL로 사이트맵을 만들어 Google에 보냅니다. 이 방법은 더 쉽고 빠르지만 고아 페이지의 절반만 색인에 있게 됩니다.
넥스트 레벨
검색 엔진 알고리즘은 20년 동안 개선되었으며 검색 크롤링이 몇 개의 그래프로 설명될 수 있다고 생각하는 것은 순진한 생각입니다.
각 페이지에 대해 200개 이상의 서로 다른 매개변수를 수집하며 연말까지 이 수치가 증가할 것으로 예상합니다. 귀하의 웹사이트가 100만 줄(페이지)이 있는 테이블이고 이 줄에 200개의 열을 곱한다고 가정하면 간단한 샘플로는 포괄적인 기술 감사에 충분하지 않습니다. 동의하십니까?
우리는 각 경우에 Googlebot의 크롤링에 영향을 미치는 요인을 찾기 위해 더 깊이 파고들고 기계 학습을 사용하기로 결정했습니다.

하나는 웹사이트 링크가 중요하고 다른 하나는 콘텐츠가 핵심 요소입니다.
이 작업의 요점은 복잡하고 방대한 데이터에서 쉽게 답을 얻는 것이었습니다. 웹 사이트에서 색인 생성에 가장 큰 영향을 미치는 것은 무엇입니까? 동일한 요소와 연결된 URL 클러스터는 무엇입니까? 따라서 포괄적으로 작업할 수 있습니다.
HotWork 애그리게이터 웹 사이트에서 로그를 다운로드하고 분석하기 전에는 봇에게는 표시되지만 우리에게는 표시되지 않는 고아 페이지에 대한 이야기가 비현실적으로 보였습니다. 그러나 실제 상황은 저를 더욱 놀라게 했습니다. Crawl은 301개의 리디렉션이 있는 500개의 페이지를 표시했지만 Yandex는 이와 동일한 상태 코드가 있는 700,000개의 페이지를 찾았습니다.
일반적으로 기술 괴짜들은 로그 파일 저장을 좋아하지 않습니다. 이 데이터는 디스크에 "과부하"를 주기 때문입니다. 그러나 객관적으로 볼 때, 한 달에 최대 1,000만 명이 방문하는 대부분의 웹 사이트에서 로그 저장의 기본 설정은 완벽하게 작동합니다.
로그 볼륨에 대해 말하자면, 가장 좋은 솔루션은 아카이브를 생성하고 Amazon S3-Glacier에 다운로드하는 것입니다(단 1달러에 250GB의 데이터를 저장할 수 있음). 시스템 관리자에게 이 작업은 커피 한 잔을 만드는 것만큼 쉽습니다. 향후 기록 로그는 기술적 버그를 밝히고 Google 업데이트가 귀하의 웹사이트에 미치는 영향을 추정하는 데 도움이 될 것입니다.