
Sztuczna inteligencja w SEO: jak radzić sobie z wyzwaniami prawnymi i zapewnić zgodność
Opublikowany: 2023-09-26Sztuczna inteligencja (AI) może stać się istotnym narzędziem dla marek chcących zwiększyć swoją obecność w Internecie.
Jednak włączenie sztucznej inteligencji do strategii marketingowych nieuchronnie wiąże się z kwestiami prawnymi i nowymi przepisami, z którymi agencje muszą się ostrożnie obchodzić.
W tym artykule odkryjesz:
- Jak firmy, agencje SEO i media mogą zminimalizować ryzyko prawne związane z wdrażaniem strategii wspomaganych sztuczną inteligencją.
- Przydatne narzędzia zmniejszające stronniczość sztucznej inteligencji i przydatny proces sprawdzania jakości treści generowanych przez sztuczną inteligencję.
- Jak agencje mogą sprostać głównym wyzwaniom związanym z wdrażaniem sztucznej inteligencji, aby zapewnić swoim klientom wydajność i zgodność.
Względy zgodności z prawem
Własność intelektualna i prawa autorskie
Kluczową kwestią prawną związaną z wykorzystaniem sztucznej inteligencji w SEO i mediach jest przestrzeganie praw własności intelektualnej i praw autorskich.
Systemy AI często pobierają i analizują ogromne ilości danych, w tym materiały chronione prawem autorskim.
Istnieje już wiele procesów sądowych przeciwko OpenAI w związku z naruszeniami praw autorskich i prywatności.
Firmie grożą procesy sądowe dotyczące nieuprawnionego wykorzystania książek chronionych prawem autorskim do celów szkoleniowych ChatGPT oraz nielegalnego gromadzenia danych osobowych od użytkowników Internetu przy użyciu ich modeli uczenia maszynowego.
Obawy dotyczące prywatności związane z przetwarzaniem i zapisywaniem danych użytkowników przez OpenAI spowodowały również, że Włochy pod koniec marca całkowicie zablokowały korzystanie z ChatGPT.
Zakaz został teraz zniesiony po tym, jak firma wprowadziła zmiany mające na celu zwiększenie przejrzystości przetwarzania danych użytkowników chatbota i dodanie opcji rezygnacji z rozmów ChatGPT wykorzystywanych do algorytmów szkoleniowych.
Jednak wraz z uruchomieniem GPTBota, robota OpenAI, prawdopodobnie pojawią się dalsze względy prawne.
Aby uniknąć potencjalnych problemów prawnych i roszczeń o naruszenie, agencje muszą dopilnować, aby wszystkie modele sztucznej inteligencji były szkolone w oparciu o autoryzowane źródła danych i przestrzegały ograniczeń praw autorskich:
- Upewnij się, że dane zostały uzyskane legalnie, a agencja ma odpowiednie prawa do ich wykorzystania.
- Odfiltruj dane, które nie mają wymaganych uprawnień lub są złej jakości.
- Przeprowadzaj regularne audyty danych i modeli sztucznej inteligencji, aby upewnić się, że są one zgodne z prawami i przepisami dotyczącymi wykorzystania danych.
- Przeprowadź konsultację prawną dotyczącą praw do danych i prywatności, aby upewnić się, że nic nie stoi w sprzeczności z zasadami prawnymi.
Zanim modele sztucznej inteligencji będą mogły zostać włączone do strumieni pracy i projektów, prawdopodobnie będą musiały zostać zaangażowane w powyższe dyskusje zarówno zespoły prawne agencji, jak i klientów.
Prywatność i ochrona danych
Technologie sztucznej inteligencji w dużym stopniu opierają się na danych, które mogą obejmować wrażliwe dane osobowe.
Gromadzenie, przechowywanie i przetwarzanie danych użytkowników musi być zgodne z odpowiednimi przepisami dotyczącymi prywatności, takimi jak Ogólne rozporządzenie o ochronie danych (RODO) w Unii Europejskiej.
Co więcej, niedawno wprowadzona ustawa UE o sztucznej inteligencji również kładzie nacisk na rozwiązanie problemów związanych z prywatnością danych związanych z systemami sztucznej inteligencji.
Nie jest to pozbawione zasług. Duże korporacje, takie jak Samsung, całkowicie zakazały sztucznej inteligencji ze względu na ujawnienie poufnych danych przesyłanych do ChatGPT.
Dlatego też, jeśli agencje wykorzystują dane klientów w połączeniu z technologią AI, powinny:
- Nadaj priorytet przejrzystości w gromadzeniu danych.
- Uzyskaj zgodę użytkownika.
- Wdrażaj solidne środki bezpieczeństwa, aby chronić wrażliwe informacje.
W takich przypadkach agencje mogą nadać priorytet przejrzystości w gromadzeniu danych, jasno informując użytkowników, jakie dane będą gromadzone, w jaki sposób będą wykorzystywane i kto będzie miał do nich dostęp.
Aby uzyskać zgodę użytkownika, upewnij się, że zgoda jest świadoma i dobrowolna, za pomocą jasnych i łatwych do zrozumienia formularzy zgody, które wyjaśniają cel i korzyści związane z gromadzeniem danych.
Ponadto solidne środki bezpieczeństwa obejmują:
- Szyfrowanie danych.
- Kontrola dostępu.
- Anonimizacja danych (jeśli to możliwe).
- Regularne audyty i aktualizacje.
Na przykład zasady OpenAI są zgodne z potrzebą prywatności i ochrony danych oraz skupiają się na promowaniu przejrzystości, zgody użytkownika i bezpieczeństwa danych w aplikacjach AI.
Uczciwość i stronniczość
Algorytmy sztucznej inteligencji stosowane w SEO i mediach mogą potencjalnie utrwalić uprzedzenia lub dyskryminować określone osoby lub grupy.
Agencje muszą aktywnie identyfikować i łagodzić błędy algorytmiczne. Jest to szczególnie ważne w świetle nowej unijnej ustawy o sztucznej inteligencji, która zabrania systemom sztucznej inteligencji nieuczciwego wpływania na zachowanie ludzi lub przejawiania zachowań dyskryminacyjnych.
Aby ograniczyć to ryzyko, agencje powinny dopilnować, aby przy projektowaniu modeli sztucznej inteligencji uwzględniono różnorodne dane i perspektywy, a także stale monitorować wyniki pod kątem potencjalnej stronniczości i dyskryminacji.
Można to osiągnąć, korzystając z narzędzi pomagających ograniczyć stronniczość, takich jak AI Fairness 360, IBM Watson Studio i narzędzie Google What-If.
Treści fałszywe lub wprowadzające w błąd
Narzędzia AI, w tym ChatGPT, mogą generować syntetyczne treści, które mogą być niedokładne, wprowadzające w błąd lub fałszywe.
Na przykład sztuczna inteligencja często tworzy fałszywe recenzje online, aby promować określone miejsca lub produkty. Może to mieć negatywne konsekwencje dla firm, które polegają na treściach generowanych przez sztuczną inteligencję.
Aby zapobiec temu ryzyku, kluczowe znaczenie ma wdrożenie jasnych zasad i procedur przeglądu treści generowanych przez sztuczną inteligencję przed publikacją.
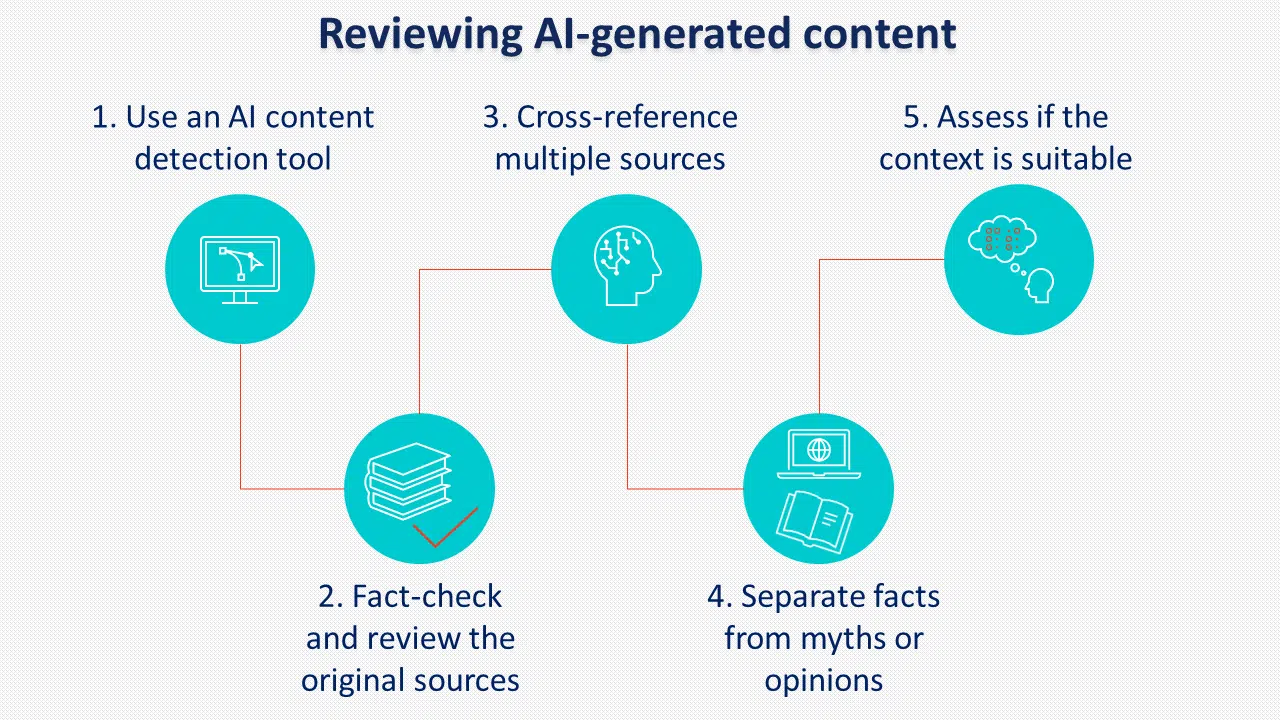
Inną praktyką, którą należy wziąć pod uwagę, jest oznaczanie treści generowanych przez sztuczną inteligencję. Choć wydaje się, że Google tego nie egzekwuje, wielu decydentów popiera etykietowanie sztucznej inteligencji.
Odpowiedzialność i odpowiedzialność
W miarę jak systemy sztucznej inteligencji stają się coraz bardziej złożone, pojawiają się pytania dotyczące odpowiedzialności.
Agencje wykorzystujące sztuczną inteligencję muszą być przygotowane na wzięcie odpowiedzialności za wszelkie niezamierzone konsekwencje wynikające z jej użycia, w tym:
- Uprzedzenia i dyskryminacja podczas korzystania ze sztucznej inteligencji do sortowania kandydatów do zatrudnienia.
- Możliwość nadużywania mocy sztucznej inteligencji do szkodliwych celów, takich jak cyberataki.
- Utrata prywatności w przypadku gromadzenia informacji bez zgody.
Unijna ustawa o sztucznej inteligencji wprowadza nowe przepisy dotyczące systemów sztucznej inteligencji wysokiego ryzyka, które mogą znacząco wpływać na prawa użytkowników, podkreślając, dlaczego agencje i klienci muszą przestrzegać odpowiednich warunków i zasad podczas korzystania z technologii sztucznej inteligencji.
Niektóre z najważniejszych warunków i zasad OpenAI dotyczą treści dostarczanych przez użytkownika, dokładności odpowiedzi i przetwarzania danych osobowych.
Polityka treści stanowi, że OpenAI przypisuje użytkownikowi prawa do wygenerowanej treści. Określa również, że wygenerowane treści można wykorzystać w dowolnym celu, w tym komercyjnym, pod warunkiem, że jest to zgodne z ograniczeniami prawnymi.

Stwierdza jednak również, że dane wyjściowe mogą nie być ani całkowicie unikalne, ani dokładne, co oznacza, że treści generowane przez sztuczną inteligencję należy zawsze dokładnie sprawdzić przed użyciem.
W notatce dotyczącej danych osobowych OpenAI zbiera wszystkie informacje wprowadzone przez użytkowników, w tym przesłane pliki.
Korzystając z usługi przetwarzania danych osobowych, użytkownicy muszą przedstawić odpowiednią prawnie politykę prywatności i wypełnić formularz żądania przetwarzania danych.
Agencje muszą aktywnie rozwiązywać problemy związane z odpowiedzialnością, monitorować wyniki sztucznej inteligencji i wdrażać solidne środki kontroli jakości, aby złagodzić potencjalne zobowiązania prawne.
Otrzymuj codzienny biuletyn, na którym polegają marketerzy.
Zobacz warunki.
Wyzwania związane z wdrażaniem sztucznej inteligencji dla agencji
Odkąd OpenAI wypuściło w zeszłym roku ChatGPT, odbyło się wiele rozmów na temat tego, jak generatywna sztuczna inteligencja zmieni SEO jako zawód i jego ogólny wpływ na branżę medialną.
Chociaż zmiany wiążą się z szeregiem usprawnień w codziennym obciążeniu pracą, istnieją pewne wyzwania, które agencje powinny wziąć pod uwagę podczas wdrażania sztucznej inteligencji do strategii klienta.
Edukacja i świadomość
Wielu klientom może brakować wszechstronnego zrozumienia sztucznej inteligencji i jej konsekwencji.
Agencje stoją zatem przed wyzwaniem edukowania klientów na temat potencjalnych korzyści i zagrożeń związanych z wdrożeniem AI.
Zmieniający się krajobraz regulacyjny wymaga jasnej komunikacji z klientami w zakresie środków podjętych w celu zapewnienia zgodności z prawem.
Aby to osiągnąć, agencje muszą:
- Mają jasne zrozumienie celów swoich klientów.
- Umieć wyjaśnić korzyści.
- Wykaż się wiedzą we wdrażaniu AI.
- Zmierz się z wyzwaniami i zagrożeniami.
Można to osiągnąć, udostępniając klientom arkusz informacyjny zawierający wszystkie niezbędne informacje oraz, jeśli to możliwe, przedstawiając studia przypadków lub inne przykłady korzyści, jakie mogą oni uzyskać dzięki wykorzystaniu sztucznej inteligencji.
Alokacja zasobów
Włączenie sztucznej inteligencji do strategii SEO i mediów wymaga znacznych zasobów, w tym inwestycji finansowych, wykwalifikowanego personelu i modernizacji infrastruktury.
Agencje muszą dokładnie ocenić potrzeby i możliwości swoich klientów, aby określić wykonalność wdrożenia rozwiązań AI w ramach swoich ograniczeń budżetowych, ponieważ mogą potrzebować efektywnie współpracujących specjalistów AI, analityków danych, SEO i specjalistów ds. treści.
Potrzeby w zakresie infrastruktury mogą obejmować narzędzia sztucznej inteligencji, platformy do przetwarzania danych i analizy w celu wydobywania spostrzeżeń. To, czy świadczyć usługi, czy udostępniać zasoby zewnętrzne, zależy od istniejących możliwości i budżetu każdej agencji.
Outsourcing innych agencji może prowadzić do szybszego wdrożenia, natomiast inwestowanie w wewnętrzne możliwości sztucznej inteligencji może okazać się lepsze pod względem długoterminowej kontroli i dostosowywania oferowanych usług.
Ekspertyza techniczna
Wdrożenie sztucznej inteligencji wymaga specjalistycznej wiedzy technicznej i doświadczenia.
Agencje mogą być zmuszone do rekrutacji lub podnoszenia kwalifikacji swoich zespołów, aby skutecznie opracowywać i wdrażać systemy sztucznej inteligencji i zarządzać nimi zgodnie z nowymi wymogami regulacyjnymi.
Aby w pełni wykorzystać sztuczną inteligencję, członkowie zespołu powinni posiadać:
- Dobra znajomość programowania.
- Przetwarzanie danych i umiejętności analityczne umożliwiające zarządzanie dużymi ilościami danych.
- Praktyczna wiedza z zakresu uczenia maszynowego.
- Doskonałe umiejętności rozwiązywania problemów.
Względy etyczne
Agencje muszą wziąć pod uwagę etyczne konsekwencje wykorzystania sztucznej inteligencji dla swoich klientów.
Należy ustanowić ramy i wytyczne etyczne, aby zapewnić odpowiedzialne praktyki sztucznej inteligencji w całym procesie, uwzględniając obawy wyrażone w zaktualizowanych przepisach.
Obejmują one:
- Przejrzystość, ujawnianie informacji i odpowiedzialność w przypadku korzystania ze sztucznej inteligencji.
- Szanowanie prywatności użytkowników i własności intelektualnej.
- Uzyskanie zgody klienta na wykorzystanie sztucznej inteligencji.
- Ludzka kontrola nad sztuczną inteligencją przy ciągłym zaangażowaniu w ulepszanie i dostosowywanie się do nowych technologii sztucznej inteligencji.
Liczy się odpowiedzialność: sprostanie wyzwaniom prawnym związanym z wdrażaniem sztucznej inteligencji
Podczas gdy sztuczna inteligencja stwarza ekscytujące możliwości poprawy praktyk SEO i mediów, agencje muszą stawić czoła wyzwaniom prawnym i przestrzegać zaktualizowanych przepisów związanych z jej wdrażaniem.
Firmy i agencje mogą minimalizować ryzyko prawne poprzez:
- Zapewnienie, że dane zostały pozyskane legalnie i że agencja posiada odpowiednie uprawnienia do ich wykorzystania.
- Odfiltrowywanie danych, które nie posiadają wymaganych prawem uprawnień lub są złej jakości.
- Przeprowadzanie audytów danych i modeli sztucznej inteligencji w celu zapewnienia ich zgodności z prawami i przepisami dotyczącymi wykorzystania danych.
- Przeprowadzenie konsultacji prawnych dotyczących praw do danych i prywatności, aby upewnić się, że nic nie stoi w sprzeczności z polityką prawną.
- Nadanie priorytetu przejrzystości w gromadzeniu danych i uzyskiwaniu zgody użytkownika za pomocą jasnych i łatwych do zrozumienia formularzy zgody.
- Korzystanie z narzędzi pomagających ograniczyć stronniczość, takich jak AI Fairness 360, IBM Watson Studio i narzędzie Google What-If.
- Wdrażanie jasnych zasad i procedur przeglądu jakości treści generowanych przez sztuczną inteligencję przed publikacją.
Opinie wyrażone w tym artykule są opiniami gościnnego autora i niekoniecznie należą do Search Engine Land. Autorzy personelu są tutaj wymienieni.