
Apache Apex – wprowadzenie
Opublikowany: 2015-12-29Apache Hadoop stał się de facto strukturą oprogramowania do niezawodnego, skalowalnego, rozproszonego przetwarzania na dużą skalę. Od samego początku Hadoop jest platformą pierwszego wyboru do przetwarzania wsadowego. Od dużych banków po gigantów handlu detalicznego online, wszyscy używają Hadoop do okresowego generowania raportów, obliczeń i wielu innych zastosowań. Zazwyczaj te przypadki użycia są procesami zorientowanymi wsadowo i wymagają kilku godzin, zanim uzyskamy znaczenie danych. Dzisiejszy szybki świat wymaga znaczenia lub działań z surowych danych niemal w momencie ich generowania. Doprowadziło to do koncepcji przetwarzania strumieniowego. Chociaż Hadoop nie był początkowo uważany za odpowiedni do przetwarzania strumieniowego, wynalezienie YARN (Hadoop 2.0) uczyniło go dobrym kandydatem do tego. Obecnie w ekosystemie Hadoop istnieje wiele struktur przetwarzania strumieni, a Apex jest zupełnie nowym rozwiązaniem wchodzącym na ten zatłoczony rynek.
Co to jest Apache Apex?
Apache Apex to natywna platforma oparta na YARN, która pomaga twórcom aplikacji pisać aplikacje zorientowane na strumień, a także aplikacje zorientowane wsadowo. Jest przeznaczony do przetwarzania danych w ruchu, w sposób rozproszony, wysoce wydajny i odporny na błędy. Wisienką na tym jest łatwy interfejs API, który umożliwia użytkownikom pisanie kodu Java z ograniczoną wiedzą na temat przetwarzania strumieniowego.
Apex opiera się na oddzielnych specyfikacjach funkcjonalnych i operacyjnych, a raczej łączy je razem. To sprawia, że twórcy aplikacji skupiają się na pisaniu funkcji zdefiniowanych przez użytkownika, bez konieczności zastanawiania się, jak będą działać w środowisku rozproszonym.
Apache Apex posiada bogatą bibliotekę najczęściej używanych funkcji. Są one dodawane jako część biblioteki Apache Apex-Malhar. Ta biblioteka ma operatorów, którzy mają dostęp do różnych systemów plików, baz danych, kolejek wiadomości. Społeczność dodaje codzienne życie operatorów, ułatwiając życie programistom aplikacji.
Jakie są podstawowe bloki Apache Apex?
Architektura Apex jest bardzo prosta. Apex ma Malhar, bibliotekę operatorów i podstawowy silnik do pracy. Rdzeń Apex można przedstawić w następujący sposób, często określa się je jako główne bloki Apache Apex.
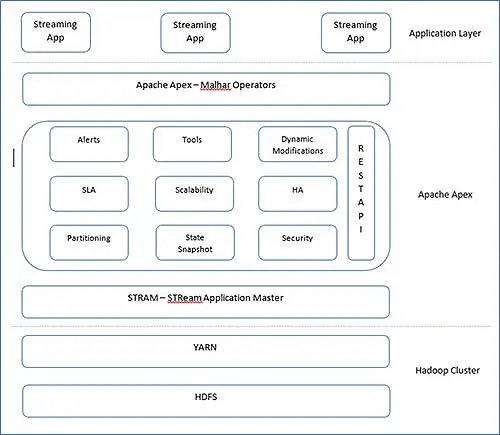
Możesz wyraźnie oddzielić warstwy i uzyskać przegląd, gdzie pasuje. Zobaczmy informacje o tych blokach.
- StrAM (Master A pplication Stream)
StrAM jest Mistrzem Aplikacji YARN. Jego odpowiedzialność obejmuje uruchamianie aplikacji strumieniowych, alokację zasobów, planowanie logicznych DAG-ów. Wraz z tymi operacjami YARN, StrAM inicjuje operatory, strumienie. StraM zbiera również statystyki od swoich dzieci. - Migawka stanu
Struktury przetwarzania strumieni nie mogły pozwolić sobie na utratę przetworzonych wyników. Ponadto muszą wiedzieć, ile przetworzyli, aby poprawnie przetwarzać rekordy po odzyskaniu sprawności po awarii. Dlatego od czasu do czasu w przetwarzaniu strumieniowym ważne jest wskazywanie punktów kontrolnych. W Apex, StrAM śledzi punkty kontrolne, a na granicy operatora okresowe punkty kontrolne są przeprowadzane na HDFS. - REST API
StrAM jest punktem dostępowym dla REST API. Narzędzia zewnętrzne mogą uzyskiwać dostęp do tego interfejsu API REST i integrować się z dowolną aplikacją zewnętrzną. - Narzędzia
Apex zapewnia CLI do uruchamiania i monitorowania aplikacji Apex. Nawet my możemy zbudować własne za pomocą REST API. Wraz z CLI aplikacja może konfigurować się za pomocą statycznych skryptów konfiguracyjnych do automatycznego uruchamiania. - Partycjonowanie
- Modyfikacje dynamiczne
- Analiza SLA
Apache Apex okresowo wykonuje samodzielnie analizę SLA. Wykonuje analizę opóźnień, wąskich gardeł i przepustowości oraz dodaje więcej zasobów, aby spełnić skonfigurowaną umowę SLA. - Bezpieczeństwo
- Duża dostępność
Apache Apex wykorzystuje funkcję ponownego uruchamiania YARN i uruchamia się ponownie od ostatniego wskazanego stanu. - Malhar
Apache Apex – Malhar to biblioteka operatorów z licznymi operatorami. Te operatory są podzielone na kategorie - Operatory wejścia / wyjścia –
W tej kategorii Malhar ma obecnie operatorów do odczytu/zapisu - System plików
- RDBMS
- Sklepy NoSQL
- Kolejki wiadomości
- Bazy danych w pamięci
- Media społecznościowe
- Operatory obliczeń –
- Dopasowywanie wzorów
- Statystyki i matematyka
- Nauczanie maszynowe
- Parsery
- Media społecznościowe
- Serwery buforowe
Apex zapewnia partycjonowanie w oparciu o klucze i dynamiczne równoważenie obciążenia. Nawet użytkownik może zdefiniować własny schemat partycjonowania.
Apache Apex ma tę bardzo przydatną i unikalną funkcję. Obsługuje logiczną zmianę DAG, fizyczną zmianę planu wykonania.
Apex obsługuje protokół Kerberos. Bazując na zabezpieczonym klastrze Hadoop, może uzyskać dostęp dzięki wbudowanej integracji Kerberos.
Malhar ma wielu operatorów, którzy pomogą w rzeczywistej implementacji logiki biznesowej. Ta biblioteka ma
Serwery buforowe leżą na granicy każdego operatora. W przypadku danych, lokalne serwery buforowe operatora mogą znajdować się po ciągach operatorów. Głównym ich celem jest tymczasowe zatrzymanie danych na krawędziach przed przekazaniem ich do następnego. Pełnią ważną rolę, gdy węzeł jest odzyskiwany po awarii. Serwery buforowe ładują dane z ostatniego stanu punktu kontrolnego do ponownego odtworzenia

Czym jest model programowania aplikacji Apex?
Zawiera bogatą strukturę i bibliotekę Malhar, co oznacza, że twórcy aplikacji muszą tylko połączyć operatorów i uruchomić aplikację. Dlatego Twoja aplikacja to nic innego jak sekwencja operatorów.
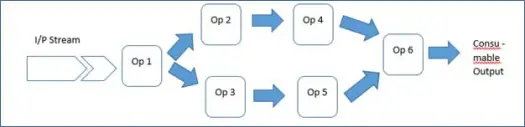
W ten sposób bogaty framework ułatwia życie programistom. Zobaczmy więc, jak działa ta aplikacja demonstracyjna
Wersja demonstracyjna Apache Apex
Zacznijmy więc od ' Hello World of Big Data J ', małej demonstracji liczby słów przy użyciu Apache Apex.
Konfigurowanie Apache Apex
Aby uruchomić to demo, musimy skonfigurować Apex. Możesz zainstalować Apache Apex na istniejącym klastrze lub istnieje prosty sposób na wypróbowanie, możesz pobrać wstępnie instalowaną maszynę wirtualną sandbox ze strony DataTorrent stąd. W tym demo użyjemy preinstalowanej maszyny wirtualnej.
Konsola interfejsu użytkownika Apex — opis przejścia
Apex jest wyposażony w bardzo intuicyjnie i pięknie zaprojektowaną konsolę interfejsu użytkownika, której można używać do uruchamiania, monitorowania i zarządzania aplikacjami. Zawiera różne statystyki dotyczące różnych wdrażanych komponentów.
Po pobraniu maszyny wirtualnej z piaskownicy, odtaruj ją i załaduj do swojego ulubionego odtwarzacza VM (ja używam odtwarzacza VMWare VM). Całe oprogramowanie i narzędzia wymagane do uruchomienia Apex są już skonfigurowane w tej maszynie wirtualnej, a wszystkie skrypty startowe są skonfigurowane do wykonywania podczas uruchamiania systemu operacyjnego. Tak więc, gdy twoja maszyna wirtualna będzie działać, będziesz mieć uruchomioną instancję Apache Apex. Teraz, aby wyświetlić konsolę, po prostu naciśnij http://locahost:9090 w swojej ulubionej przeglądarce internetowej i zaloguj się do konsoli. Domyślna nazwa użytkownika: hasło do maszyny wirtualnej z piaskownicą to dtadmin: dtadmin. Zobaczysz konsolę jak poniżej
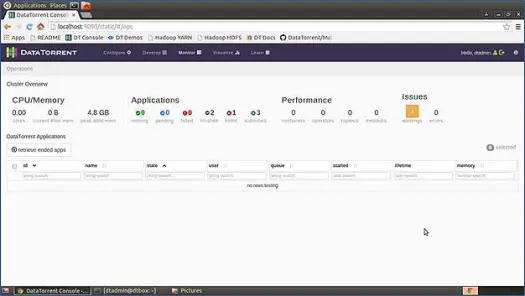
Ta strona daje nam pełny przegląd całego systemu, takiego jak użycie procesora i pamięci, aplikacje, wydajność, problemy itp.
Aby wdrożyć aplikację, przejdź do zakładki Develop u góry strony.
Tutaj możesz wdrożyć pakiety aplikacji i zarządzać schematami krotek dla danych w Apex.
Apex udostępnia szereg aplikacji, które można znaleźć poniżej:
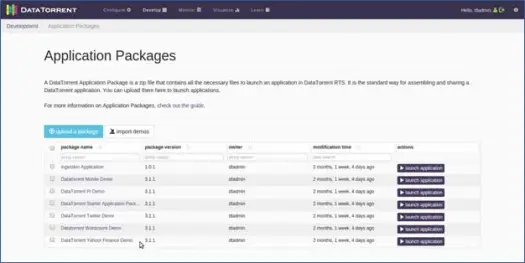
Demo WordCount'a
Teraz uruchommy aplikację wordcount. Możesz to zrobić, klikając opcję uruchamiania aplikacji obok DataTorrent Wordcount Demo. Następnie możesz podać inną aplikację i zmodyfikować szczegóły konfiguracji, jeśli jest to wymagane (nie zrobimy tego, ponieważ większość domyślnych ustawień działa dobrze, po prostu zmień nazwę aplikacji na „MyWordCountDemo”). Zobaczysz komunikat, który mówi, że aplikacja została pomyślnie wdrożona z linkiem do aplikacji. Kliknij ten link.

Otworzy się nowa strona. Poczekaj kilka sekund, aż stan aplikacji zmieni się z Zaakceptowana na Uruchomiona. Zobaczysz teraz stronę, która jest pełna różnych statystyk i informacji. Kolejne dwa zrzuty ekranu przedstawiają je.
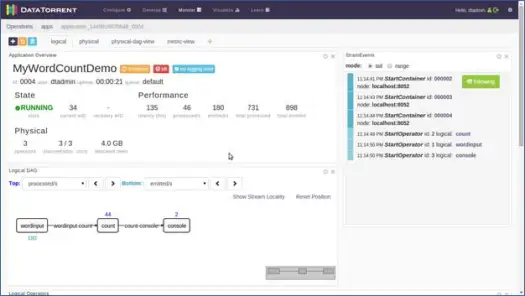
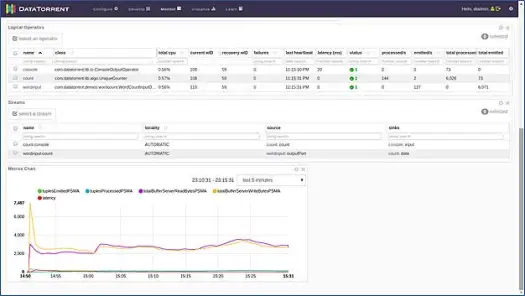
Te strony pokazują nam różne informacje, takie jak logiczny, fizyczny i metryczny widok aplikacji, wraz ze statystykami różnych krotek/rekordów, które są przetwarzane przez aplikację co sekundę. Pokazuje graficzną reprezentację emitowanych krotek i opóźnień itp.
Możesz kliknąć dowolny operator logiczny, sprawdzić jego zapisy, a nawet nagrać próbkę. Zróbmy to dla operatora konsoli. Kliknij na operatora konsoli, a otrzymasz szczegółowe informacje o operatorze jak poniżej:
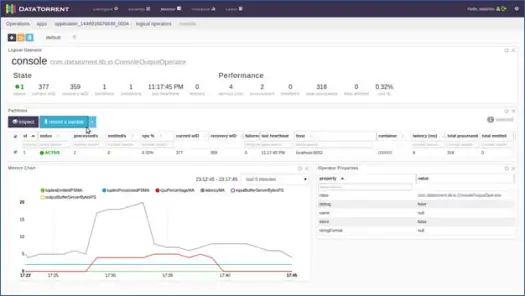
Następnie wybierz jedną z partycji i kliknij nagraj próbkę.
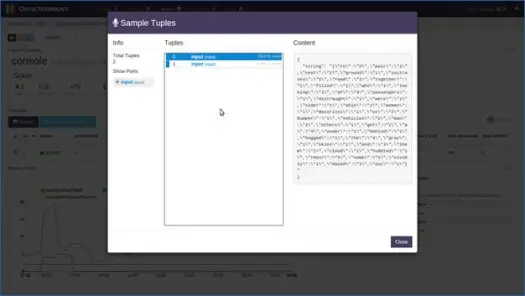
Po kilku sekundach zobaczysz, że krotki są wypełnione, kliknij krotkę, aby wyświetlić jej zawartość. Jak widać z treści, aplikacja wykonała zliczanie słów na danych opartych na oknach i w zerowej krotce wejściowej dla tego okna były 2 „do”, 4 „the”, 4 „a” itd. Możesz teraz zatrzymać aplikację, klikając „Zamknij” lub „Zabij” na stronie głównej aplikacji.
To wszystko, pomyślnie wdrożyliśmy i uruchomiliśmy aplikację wordcount.
Wniosek
To było wprowadzenie do nowego narzędzia do przesyłania strumieniowego – Apache Apex i udane uruchomienie aplikacji w Apache Apex. Apache Apex ma wiele istotnych funkcji, które dają mu przewagę nad innymi istniejącymi frameworkami, które omówię w kolejnych postach.