
Apache Spark: błyszcząca gwiazda na firmamencie Big Data.
Opublikowany: 2015-09-24- Rekomendowanie milionów produktów właściwym klientom.
- Śledzenie historii wyszukiwania i oferowanie obniżonych cen podróży lotniczych.
- Porównywanie umiejętności technicznych osoby i odpowiednie sugerowanie osób, z którymi można się połączyć w Twojej dziedzinie.
- Zrozumienie wzorców w miliardach obiektów mobilnych, wieżach sieciowych i transakcjach połączeń oraz obliczanie optymalizacji sieci telekomunikacyjnej lub znajdowanie luk w sieci.
- Badanie milionów funkcji czujników i analizowanie awarii w sieciach czujników.
Podstawowe dane, które należy wykorzystać, aby uzyskać właściwe wyniki dla wszystkich powyższych zadań, są stosunkowo bardzo duże. Tradycyjne systemy nie mogą sobie z tym poradzić wydajnie (zarówno pod względem przestrzeni, jak i czasu).
To wszystko są scenariusze dotyczące dużych zbiorów danych.
Aby zbierać, przechowywać i wykonywać obliczenia na tego rodzaju obszernych danych, potrzebujemy specjalistycznego systemu przetwarzania klastrowego. Apache Hadoop rozwiązał za nas ten problem.
Oferuje rozproszony system pamięci masowej (HDFS) i platformę przetwarzania równoległego (MapReduce).
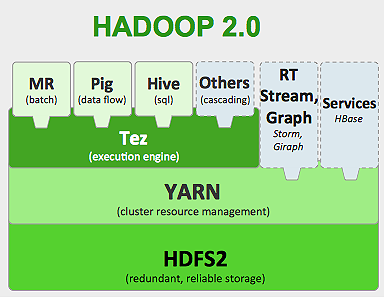
Framework Hadoop działa jak poniżej:
- Dzieli duże pliki danych na mniejsze porcje, które mają być przetwarzane przez poszczególne maszyny (dystrybucja pamięci masowej).
- Dzieli dłuższą pracę na mniejsze zadania, które mają być wykonywane równolegle (obliczenia równoległe).
- Automatycznie obsługuje awarie.
Ograniczenia Hadoop
Hadoop ma w swoim ekosystemie wyspecjalizowane narzędzia do wykonywania różnych zadań. Tak więc, jeśli chcesz uruchomić kompletny cykl życia aplikacji, musisz skorzystać z wielu narzędzi. Na przykład w przypadku zapytań SQL będziesz używać hive/pig , dla źródeł strumieniowania musisz skorzystać z wbudowanego przesyłania strumieniowego Hadoop lub Apache Storm (który nie jest częścią ekosystemu Hadoop) lub dla algorytmów uczenia maszynowego musisz użyć Mahout . Integracja wszystkich tych systemów razem w celu zbudowania jednego przypadku użycia potoku danych to nie lada zadanie.
W pracy MapReduce ,
- Wszystkie dane wyjściowe zadań map są zrzucane na dyski lokalne (lub HDFS).
- Hadoop łączy wszystkie pliki rozlewania w większy plik, który jest sortowany i partycjonowany zgodnie z liczbą reduktorów.
- I zredukuj zadania, aby ponownie załadować je do pamięci.
Ten proces spowalnia zadanie, powodując we/wy dysku i sieci we/wy. Sprawia to również, że Mapreduce nie nadaje się do przetwarzania iteracyjnego, w którym musisz wielokrotnie stosować algorytmy uczenia maszynowego do tej samej grupy danych.
Wejdź do świata Apache Spark:
Apache Spark jest rozwijany w UC Berkeley AMPLAB w 2009 roku, a w 2010 roku do dziś stał się najlepiej wspieranym projektem open source Apache.
Apache Spark to bardziej uogólniony system, w którym można jednocześnie uruchamiać zadania wsadowe i strumieniowe . Zastępuje swojego poprzednika MapReduce pod względem szybkości, dodając możliwości szybszego przetwarzania danych w pamięci. Jest również bardziej wydajny na dysku. Wykorzystuje przetwarzanie pamięci przy użyciu podstawowej jednostki danych RDD (Resilient Distributed Dataset). Przechowują one w pamięci możliwie najwięcej zestawu danych przez cały cykl życia zadania, a tym samym zapisują na dysku we/wy. Niektóre dane mogą zostać rozlane na dysku po przekroczeniu górnych limitów pamięci.
Poniższy wykres przedstawia czas działania w sekundach zarówno Apache Hadoop, jak i Spark do obliczania regresji logistycznej. Hadoop zajął 110 sekund, podczas gdy Spark wykonał tę samą pracę w zaledwie 0,9 sekundy.
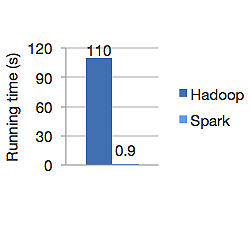
Spark nie przechowuje wszystkich danych w pamięci. Ale jeśli dane znajdują się w pamięci, najlepiej wykorzysta pamięć podręczną LRU, aby przetworzyć je szybciej. Jest 100x szybszy podczas przetwarzania danych w pamięci i wciąż szybszy na dysku niż Hadoop.
Model rozproszonego przechowywania danych Spark, odporne rozproszone zestawy danych (RDD), gwarantują odporność na awarie, co z kolei minimalizuje operacje we/wy w sieci. Papier iskrowy mówi:

„RDD osiągają odporność na awarie dzięki pojęciu linii: jeśli partycja RDD zostanie utracona, RDD ma wystarczającą ilość informacji o tym, w jaki sposób pochodzi z innych RDD, aby móc odbudować tylko tę partycję”.
Nie musisz więc replikować danych, aby osiągnąć odporność na awarie.
W Spark MapReduce dane wyjściowe programu mapującego są przechowywane w pamięci podręcznej bufora systemu operacyjnego, a reduktory przeciągają je na bok i zapisują bezpośrednio w pamięci, w przeciwieństwie do usługi Hadoop, w której dane wyjściowe są przelewane na dysk i ponownie je odczytywane.
Pamięć podręczna Spark w pamięci podręcznej sprawia, że nadaje się ona do algorytmów uczenia maszynowego, w których trzeba wielokrotnie używać tych samych danych. Spark może uruchamiać złożone zadania, wieloetapowe potoki danych przy użyciu bezpośredniego wykresu acyklicznego (DAG).
Spark jest napisany w Scali i działa na JVM (Java Virtual Machine). Spark oferuje programistyczne interfejsy API dla języków Java, Scala, Python i R. Spark działa na Hadoop YARN, Apache Mesos, a także ma własnego samodzielnego menedżera klastra.
W 2014 roku zapewnił 1 miejsce w światowym rekordzie sortowania 100 TB danych (1 bilion rekordów) w zaledwie 23 minuty, podczas gdy poprzedni rekord Hadoop przez Yahoo wynosił około 72 minuty. To dowodzi, że posortowane dane są uruchamiane 3 razy szybciej i przy 10 razy mniejszej liczbie maszyn. Całe sortowanie odbywało się na dysku (HDFS), bez faktycznego korzystania z funkcji pamięci podręcznej Spark w pamięci.
Ekosystem iskry
Spark jest przeznaczony do wykonywania zaawansowanych analiz za jednym razem, aby to osiągnąć, oferuje następujące komponenty:
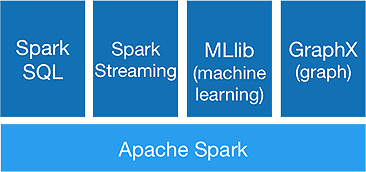
1. Rdzeń iskry:
Spark core API jest podstawą platformy Apache Spark, która obsługuje planowanie zadań, dystrybucję zadań, zarządzanie pamięcią, operacje we/wy i odzyskiwanie po awariach. Główna logiczna jednostka danych w Spark nazywa się RDD (Resilient Distributed Dataset), która przechowuje dane w sposób rozproszony do późniejszego równoległego przetwarzania. Leniwie oblicza operacje. Dlatego pamięć nie musi być zajęta przez cały czas, a inne zadania mogą ją wykorzystywać.
2. Spark SQL:
Oferuje interaktywne możliwości zapytań z małymi opóźnieniami. Nowy interfejs DataFrame API może przechowywać zarówno dane strukturalne, jak i częściowo ustrukturyzowane, a także umożliwia wykonywanie obliczeń wszystkim operacjom i funkcjom SQL.
3. Spark Streaming:
Udostępnia interfejsy API do strumieniowania w czasie rzeczywistym , które zbierają i przetwarzają dane w mikro partiach.
Wykorzystuje strumienie D , które są niczym innym jak ciągłą sekwencją RDD , do obliczania logiki biznesowej na przychodzących danych i natychmiastowego generowania wyników.
4.MLlib :
Jest to biblioteka uczenia maszynowego Spark (prawie 9 razy szybsza niż Mahout), która zapewnia uczenie maszynowe, a także algorytmy statystyczne, takie jak klasyfikacja, regresja, filtrowanie zespołowe itp.
5.WykresX :
GraphX API zapewnia możliwości obsługi wykresów i wykonywania obliczeń równoległych do wykresów. Zawiera algorytmy wykresów, takie jak PageRank i różne funkcje do analizy wykresów.
Czy Spark oznacza koniec ery Hadoop?
Spark to wciąż młody system, nie tak dojrzały jak Hadoop. Nie ma takiego narzędzia dla NOSQL jak HBase. Biorąc pod uwagę wysokie zapotrzebowanie na pamięć do szybszego przetwarzania danych, nie można tak naprawdę powiedzieć, że działa na zwykłym sprzęcie. Spark nie posiada własnego systemu przechowywania. W tym celu opiera się na HDFS.
Tak więc Hadoop MapReduce jest nadal dobry w przypadku niektórych zadań wsadowych, które nie obejmują zbyt dużego potokowania danych.
„Nowa technologia nigdy nie zastępuje całkowicie starej; oboje woleliby współistnieć”.
Wniosek
W tym blogu przyjrzeliśmy się, dlaczego potrzebujesz narzędzia takiego jak Spark, co czyni go szybszym systemem klastrowym i jego podstawowymi komponentami. W następnej części zagłębimy się w RDD, transformacje i działania Spark core API.