
Tworzenie aplikacji przy użyciu Serverless Framework, AWS i BigQuery
Opublikowany: 2021-01-28Bezserwerowe odnosi się do aplikacji, w których zarządzanie i alokacja serwerów i zasobów jest zarządzana przez dostawcę chmury. Oznacza to, że dostawca chmury dynamicznie przydziela zasoby. Aplikacja działa w kontenerze bezstanowym, który może zostać wyzwolony przez zdarzenie. Jeden z przykładów powyższego i ten, którego będziemy używać w tym artykule, dotyczy AWS Lambda .
Krótko mówiąc, możemy określić „aplikacje bezserwerowe” jako aplikacje, które są systemami opartymi na zdarzeniach w chmurze. Aplikacja opiera się na usługach innych firm, logice po stronie klienta i wywołaniach zdalnych (bezpośrednio wywołując funkcję Function as a Service ).
Instalowanie Serverless Framework i konfigurowanie go dla Amazon AWS

1. Bezserwerowa platforma
Serverless Framework to platforma typu open source. Składa się z interfejsu wiersza poleceń lub CLI oraz hostowanego pulpitu nawigacyjnego, który zapewnia nam w pełni bezserwerowy system zarządzania aplikacjami. Korzystanie z platformy zapewnia mniejsze nakłady i koszty, szybkie opracowywanie i wdrażanie oraz zabezpieczanie aplikacji bezserwerowych.
Zanim przystąpisz do instalacji platformy Serverless, musisz najpierw skonfigurować NodeJS. W większości systemów operacyjnych jest to bardzo łatwe — wystarczy odwiedzić oficjalną witrynę NodeJS, aby ją pobrać i zainstalować. Pamiętaj, aby wybrać wersję wyższą niż 6.0.0.
Po zainstalowaniu możesz potwierdzić, że NodeJS jest dostępny, uruchamiając w konsoli node -v . Powinien zwrócić wersję węzła, którą zainstalowałeś:
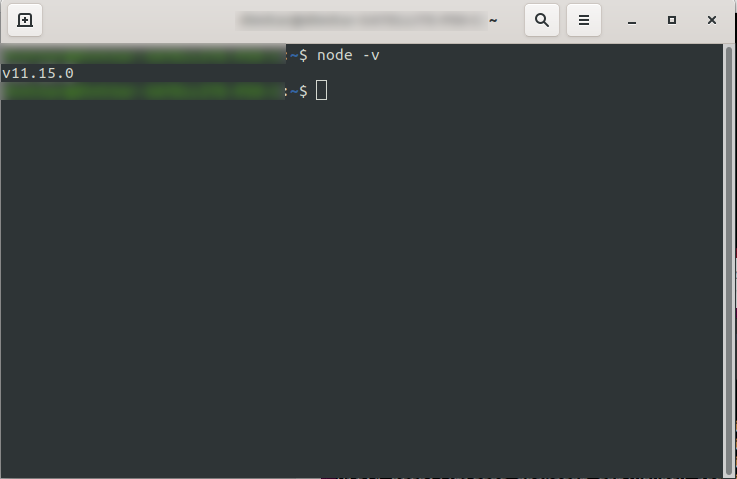
Teraz możesz już iść, więc śmiało zainstaluj platformę Serverless.
W tym celu postępuj zgodnie z dokumentacją, aby skonfigurować i skonfigurować framework. Jeśli wolisz, możesz zainstalować go tylko dla jednego projektu, ale w DevriX zazwyczaj instalujemy framework globalnie: npm install -g serverless
Poczekaj na zakończenie procesu i upewnij się, że instalacja Serverless została pomyślnie zainstalowana, uruchamiając: serverless -v
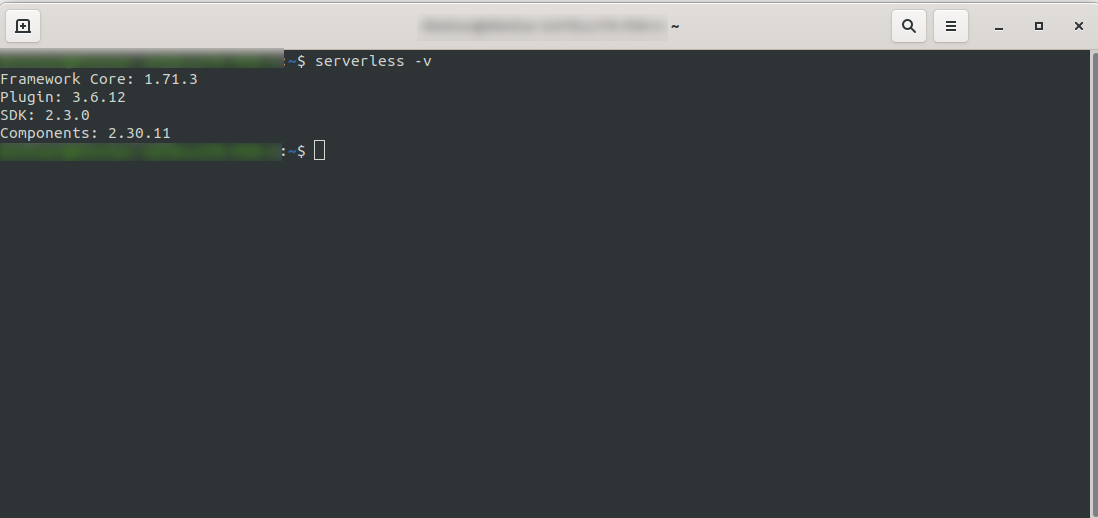
2. Utwórz konto Amazon AWS
Zanim przystąpisz do tworzenia przykładowej aplikacji, powinieneś utworzyć konto w Amazon AWS . Jeśli jeszcze go nie masz, wystarczy przejść do Amazon AWS i kliknąć „Utwórz konto AWS” w prawym górnym rogu i postępować zgodnie z instrukcjami, aby utworzyć konto.
Amazon wymaga podania karty kredytowej, więc nie możesz kontynuować bez podania tych informacji. Po udanej rejestracji i logowaniu powinieneś zobaczyć Konsolę Zarządzania AWS:
Świetnie! Przejdźmy teraz do tworzenia Twojej aplikacji.
3. Skonfiguruj platformę Serverless Framework z dostawcą AWS i utwórz przykładową aplikację
W tym kroku musimy skonfigurować platformę Serverless z dostawcą AWS. Niektóre usługi, takie jak AWS Lambda, wymagają poświadczeń, gdy uzyskujesz do nich dostęp, aby upewnić się, że masz uprawnienia do zasobów należących do tej usługi. W tym celu AWS zaleca użycie AWS Identity and Access Manager (IAM).
Zatem pierwszą i najważniejszą rzeczą jest stworzenie użytkownika IAM w AWS , który będzie go używał w naszej aplikacji:
W konsoli AWS:
- Wpisz IAM w polu „Znajdź usługi” .
- Kliknij „IAM” .
- Przejdź do „Użytkownicy” .
- Kliknij „Dodaj użytkownika” .
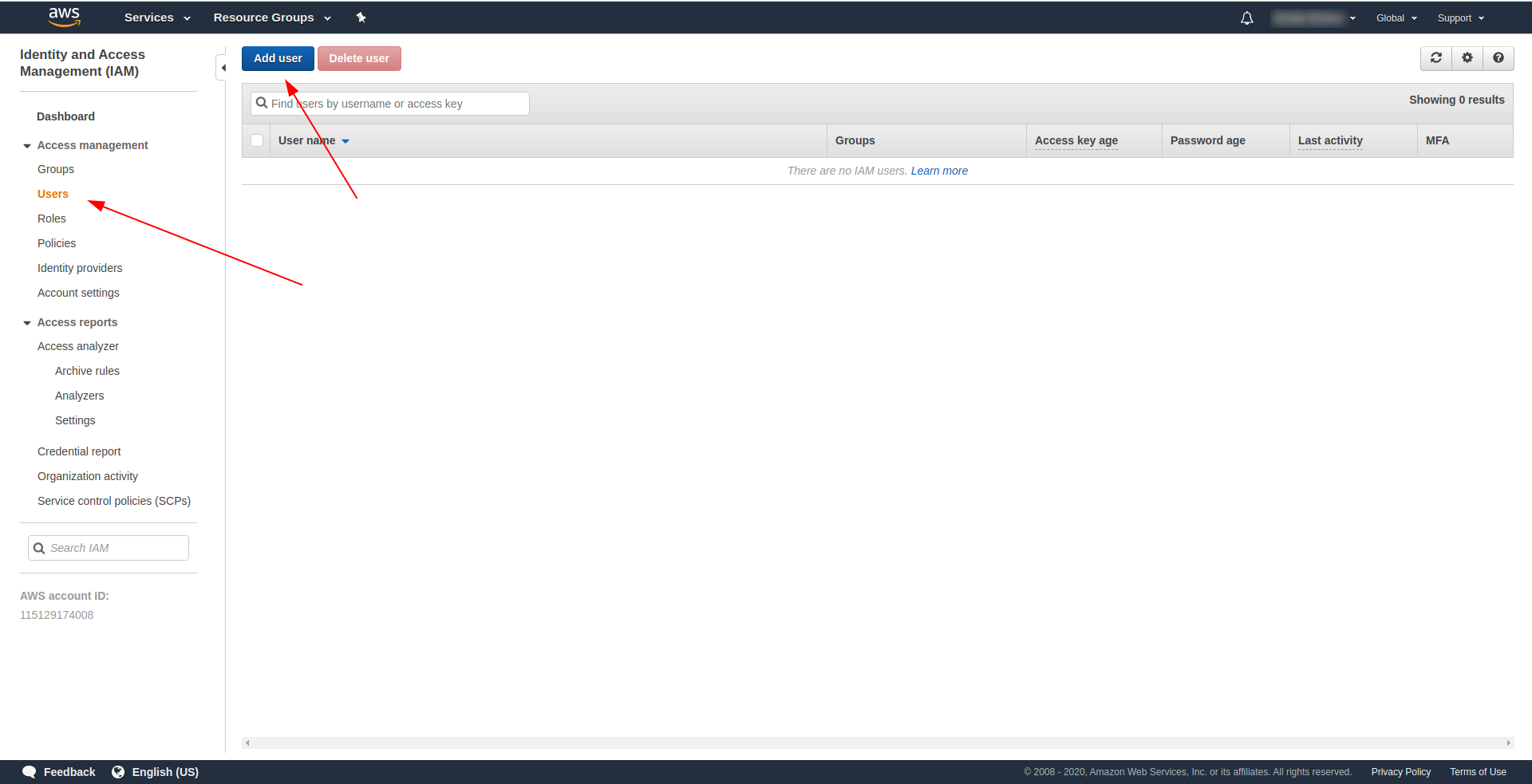
W przypadku „Nazwy użytkownika” użyj, co chcesz. Na przykład używamy serverless-admin. W polu „ Typ dostępu” zaznacz „Dostęp programowy” i kliknij „Dalsze uprawnienia ”.
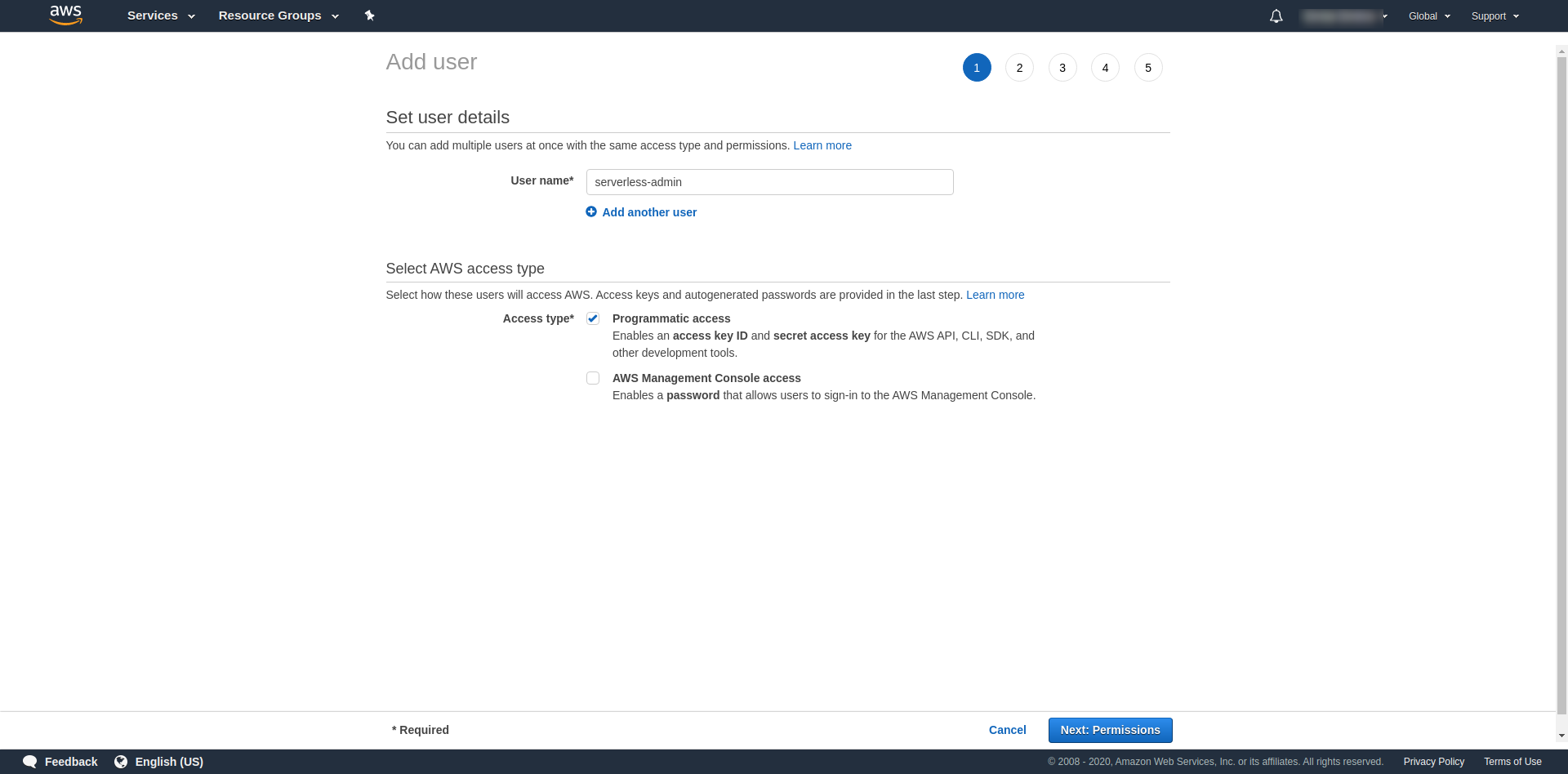
Następnie musimy dołączyć uprawnienia dla użytkownika, kliknąć „Dołącz istniejące zasady bezpośrednio”, wyszukaj „Dostęp administratora” i kliknij go. Kontynuuj, klikając „Dalej tagi”
Tagi są opcjonalne, więc możesz kontynuować, klikając „Następna recenzja” i „Utwórz użytkownika”. Po zakończeniu i załadowaniu na stronie pojawia się komunikat o powodzeniu z potrzebnymi nam danymi uwierzytelniającymi.
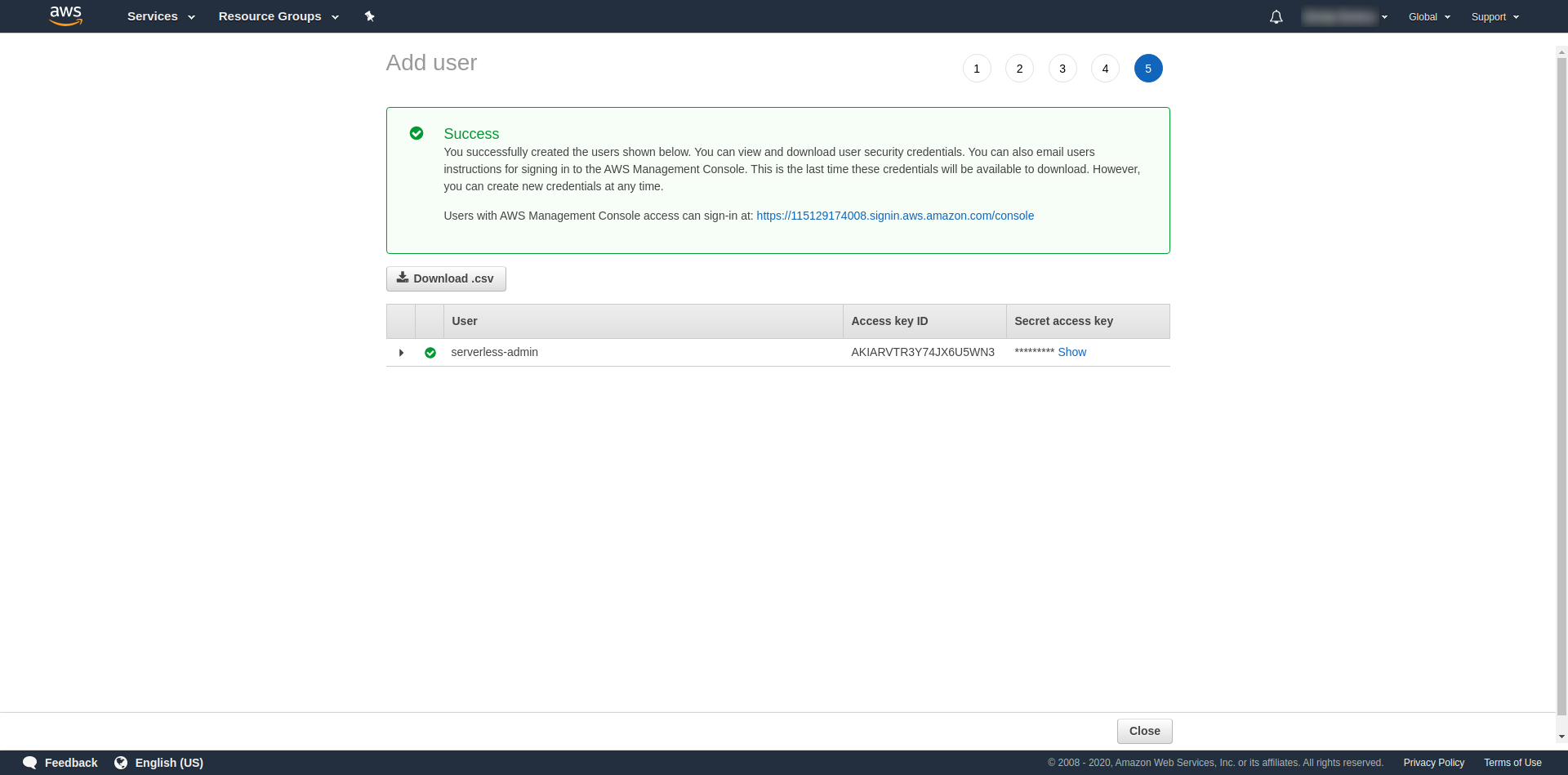
Teraz musimy uruchomić następującą komendę:
serverless config credentials --provider aws --key key --secret secret --profile serverless-admin
Zastąp klucz i klucz tajny podanym powyżej. Twoje dane logowania do AWS są tworzone jako profil. Możesz to dokładnie sprawdzić, otwierając plik ~/.aws/credentials . Powinien składać się z profili AWS. Obecnie w poniższym przykładzie jest to tylko jeden – ten, który stworzyliśmy:
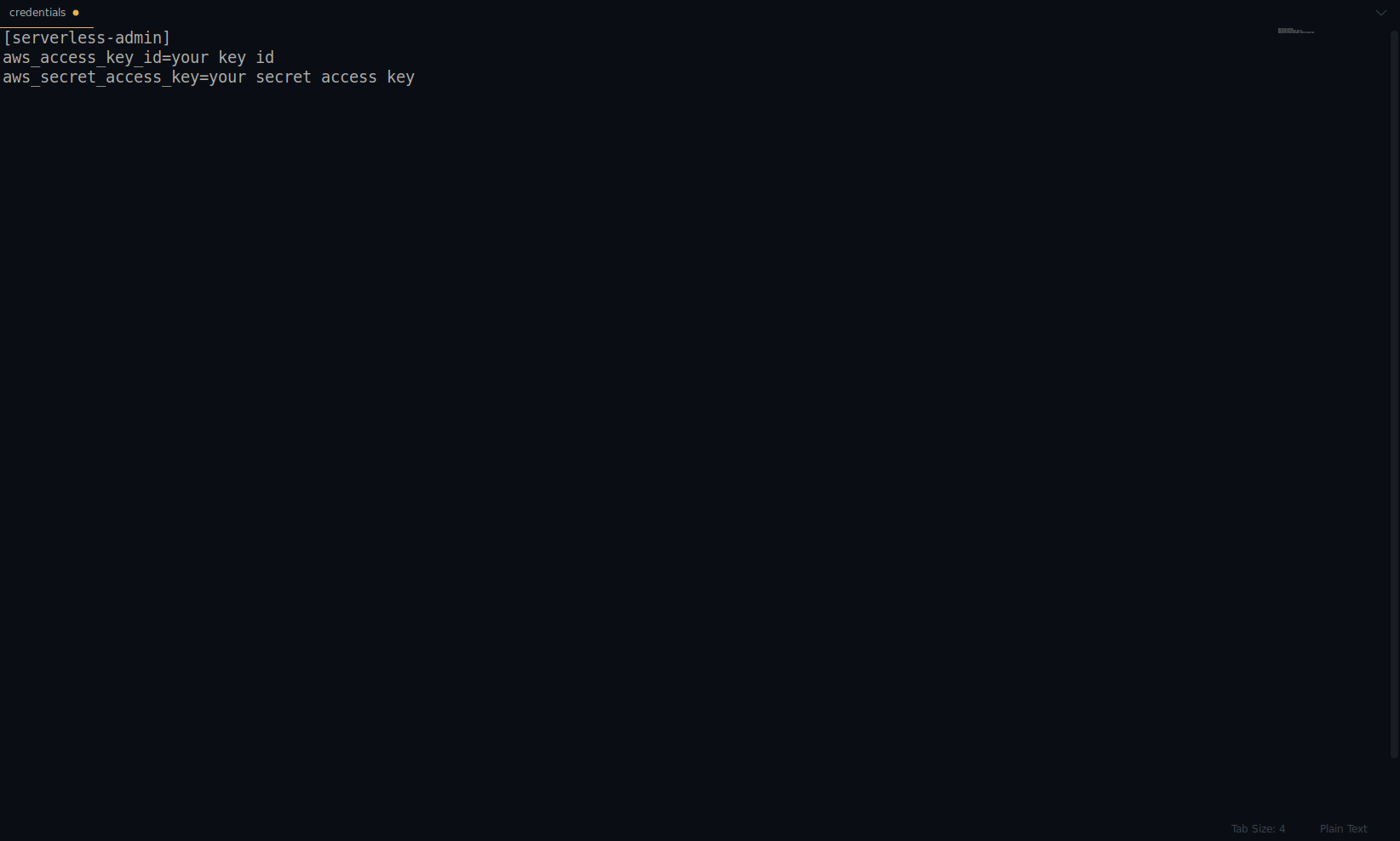
Jak dotąd świetna robota! Możesz kontynuować, tworząc jedną przykładową aplikację przy użyciu NodeJS i wbudowanych szablonów startowych.
Uwaga: Ponadto w artykule używamy polecenia sls , które jest skrótem od serverless .
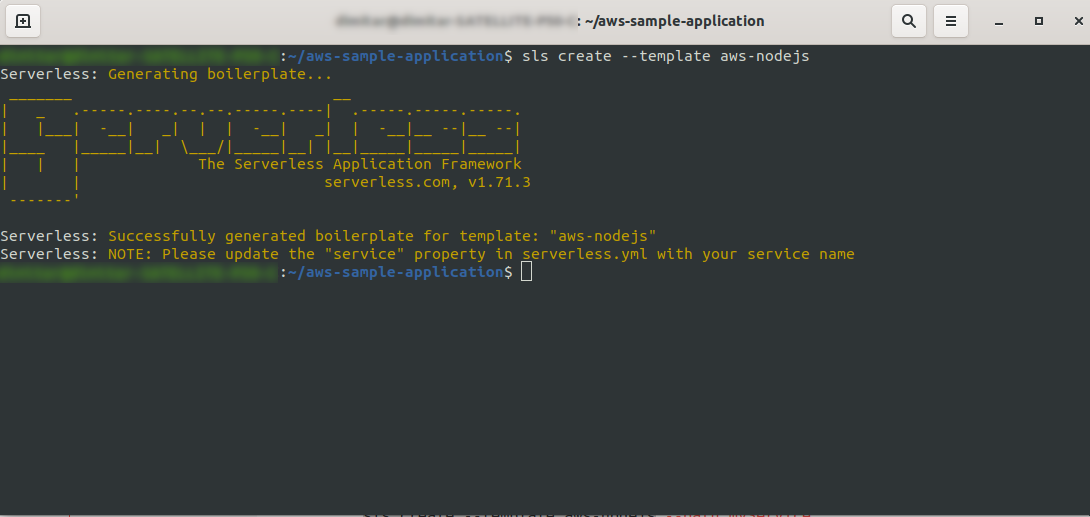
Utwórz pusty katalog i wprowadź go. Uruchom polecenie
ls create --template aws-nodejs
Za pomocą polecenia create –template określ jeden z dostępnych szablonów, w tym przypadku aws-nodejs, który jest aplikacją szablonową NodeJS „Hello world”.
Po zakończeniu twój katalog powinien składać się z następujących elementów i wyglądać tak:
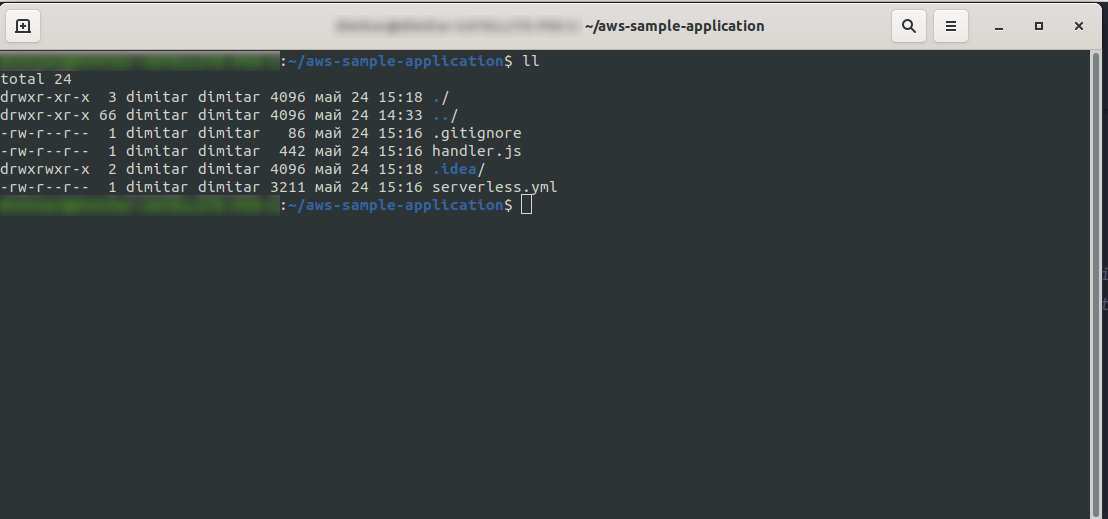
Stworzyliśmy nowe pliki handler.js i serverless.yml .
Plik handler.js przechowuje twoje funkcje, a serverless.yml przechowuje właściwości konfiguracyjne, które zmienisz później. Jeśli zastanawiasz się, czym jest plik .yml , w skrócie, jest to czytelny dla człowieka język serializacji danych . Warto się z nim zapoznać, gdyż jest on używany podczas wstawiania dowolnych parametrów konfiguracyjnych. Ale spójrzmy teraz, co mamy w pliku serverless.yml :
usługa: aws-przykładowa-aplikacja
dostawca:
nazwa: aws
środowisko uruchomieniowe: nodejs12.x
Funkcje:
cześć:
handler: handler.hello
- usługa: – Nasza nazwa usługi.
- provider: – Obiekt, który zawiera właściwości providera i jak widzimy tutaj, naszym dostawcą jest AWS, a my używamy środowiska uruchomieniowego NodeJS.
- funkcje: – Jest to obiekt, który zawiera wszystkie funkcje, które można wdrożyć w Lambdzie. W tym przykładzie mamy tylko jedną funkcję o nazwie hello , która wskazuje na funkcję hello handler.js.
Musisz zrobić tutaj jedną kluczową rzecz, zanim przystąpisz do wdrażania aplikacji. Wcześniej ustawiliśmy poświadczenia dla AWS z profilem (nazywaliśmy go serverless-admin ). Teraz wszystko, co musisz zrobić, to powiedzieć konfiguracji bezserwerowej , aby używała tego profilu i twojego regionu. Otwórz serverless.yml i pod właściwością providera tuż pod runtime wpisz to:
profil: bezserwerowy-admin region: us-wschód-2
W końcu powinniśmy mieć to:
dostawca: nazwa: aws środowisko uruchomieniowe: nodejs12.x profil: bezserwerowy-admin region: us-wschód-2
Uwaga: Aby uzyskać region, prostym sposobem jest sprawdzenie adresu URL po zalogowaniu się do konsoli: Przykład:
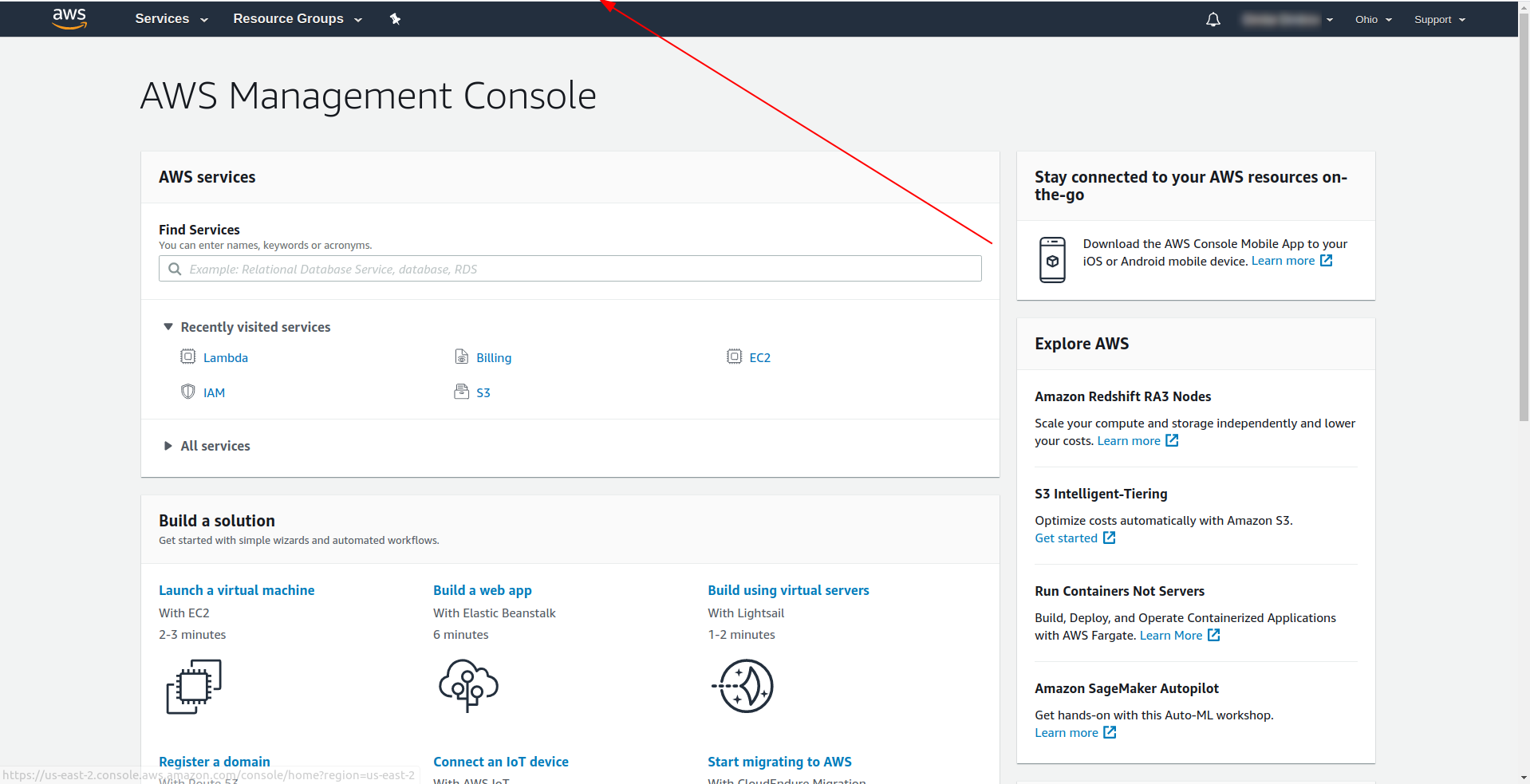
Teraz, gdy mamy niezbędne informacje o naszym wygenerowanym szablonie. Sprawdźmy, jak możemy wywołać funkcję lokalnie i wdrożyć ją w AWS Lambda.
Możemy od razu przetestować aplikację, wywołując funkcję lokalnie:
sls invoke local -f hello
Wywołuje funkcję (ale tylko lokalnie!) i zwraca dane wyjściowe do konsoli:
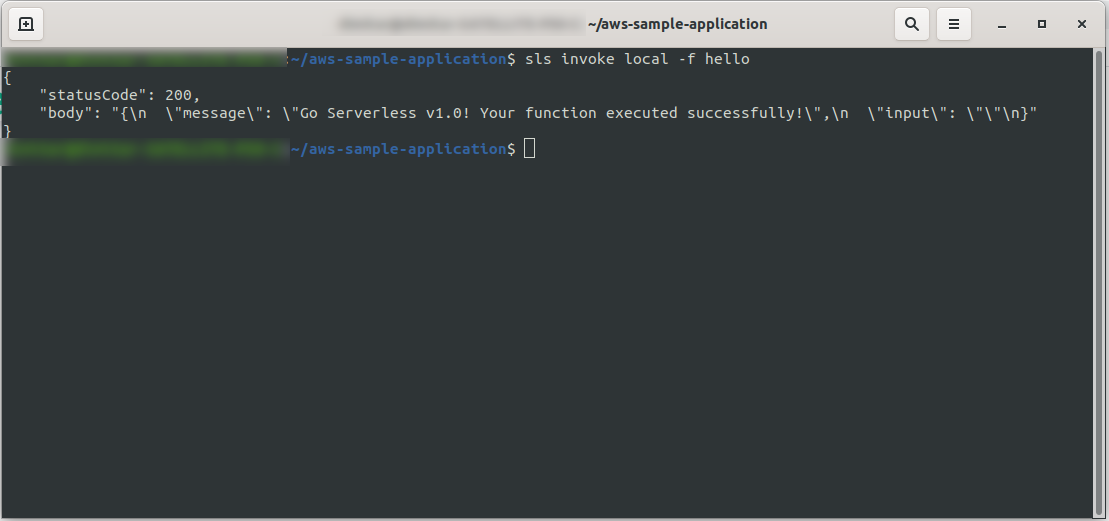
Teraz, jeśli wszystko poszło dobrze, możesz spróbować wdrożyć swoją funkcję w AWS Lambda .
Czy to było skomplikowane? Nie, nie było! Dzięki Serverless Framework jest to tylko jednowierszowy kod:
sls deploy -v
Poczekaj, aż wszystko się skończy, może to potrwać kilka minut, jeśli wszystko jest w porządku, powinieneś zakończyć coś takiego:
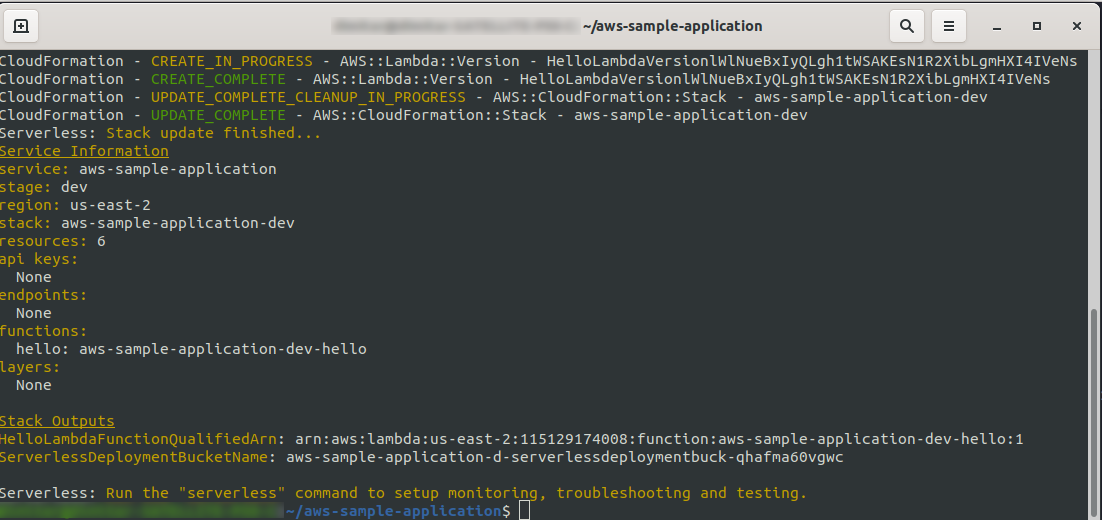
Sprawdźmy teraz, co się stało w AWS. Przejdź do Lambda (w „ Find Services ” wpisz Lambda ) i powinieneś zobaczyć utworzoną funkcję Lambda .
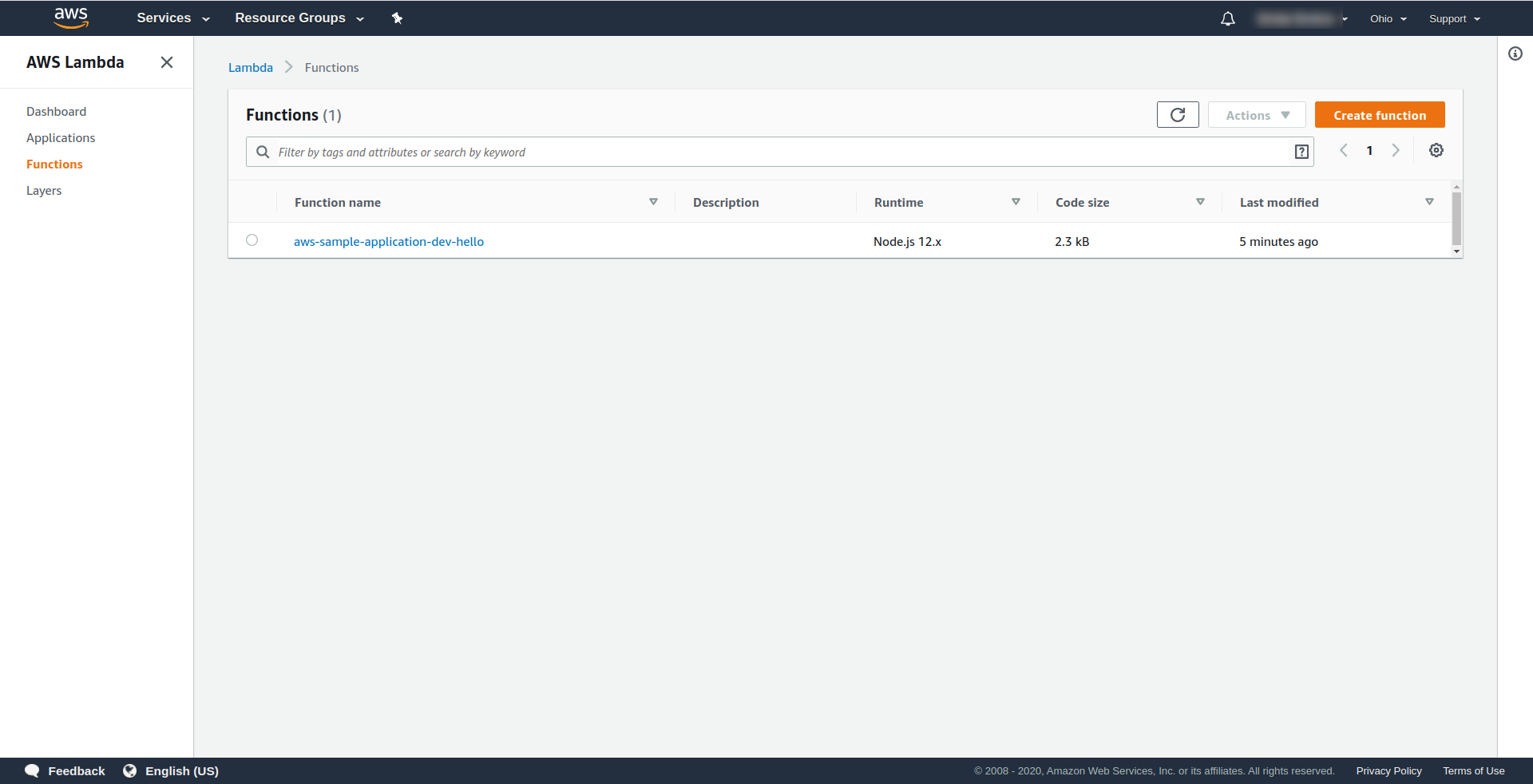
Teraz możesz spróbować wywołać swoją funkcję z AWS Lambda. W typie terminala
sls invoke -f hello
Powinien zwrócić to samo wyjście, co wcześniej (gdy testujemy lokalnie):
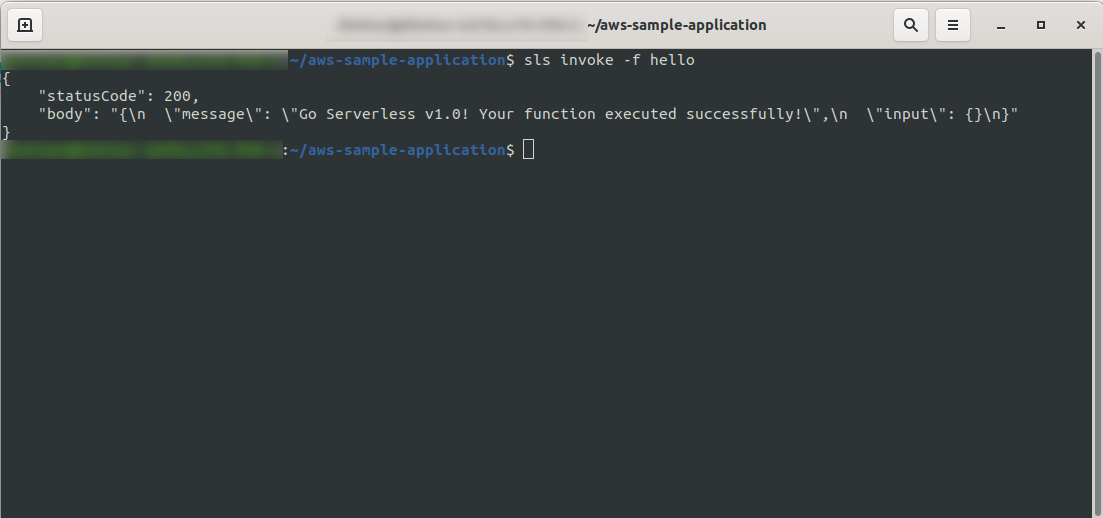
Możesz sprawdzić, czy uruchomiłeś funkcję AWS, otwierając funkcję w AWS Lambda i przechodząc do zakładki „ Monitorowanie ” i klikając „ Wyświetl logi w CloudWatch. “.
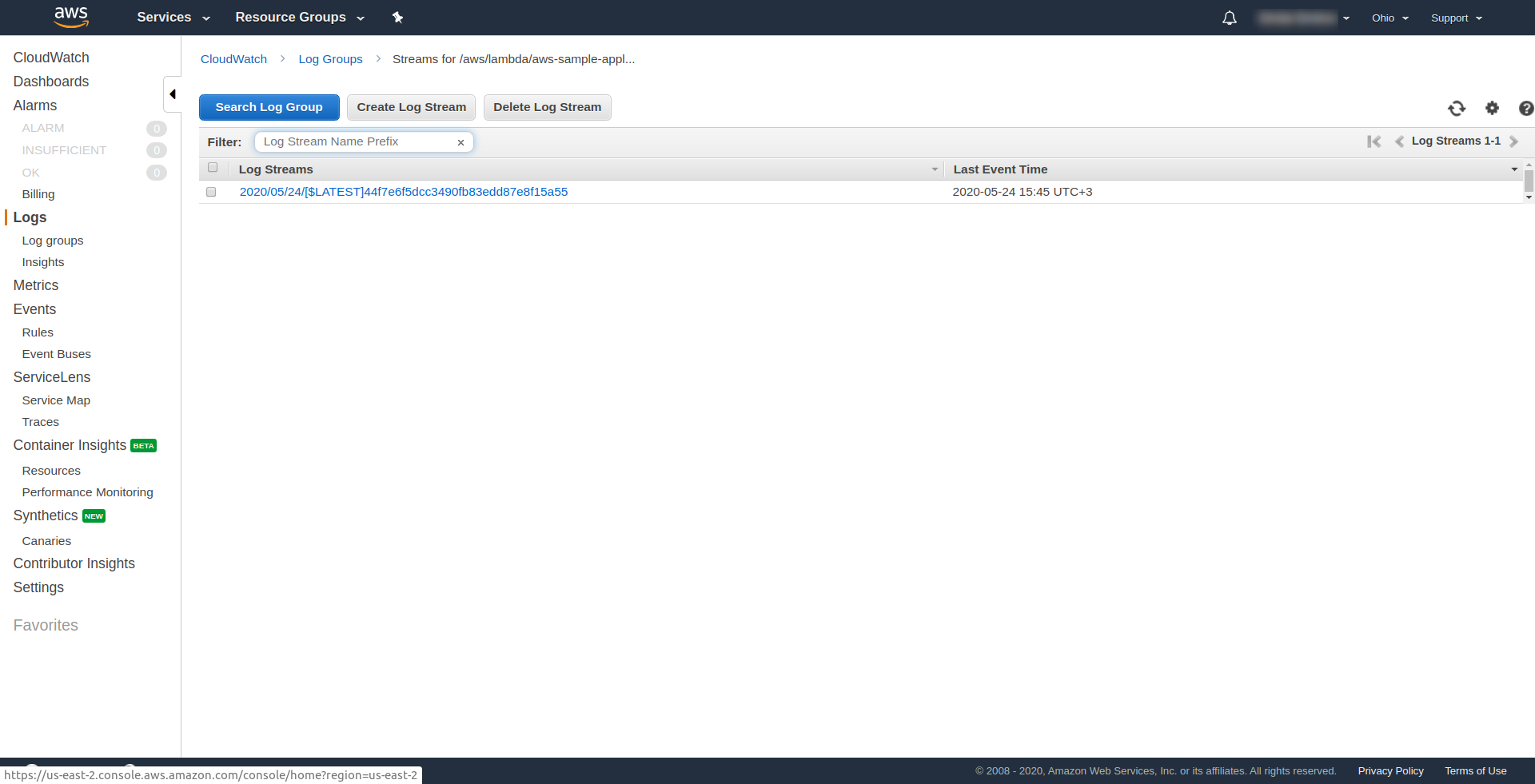
Powinieneś mieć tam jeden dziennik.
W Twojej aplikacji wciąż brakuje jednej rzeczy, ale co to jest…? Cóż, nie masz punktu końcowego, do którego można uzyskać dostęp dla swojej aplikacji, więc utwórzmy go przy użyciu bramy API AWS.
Musisz najpierw otworzyć plik serverless.yml i wyczyścić komentarze. Musisz dodać właściwość zdarzeń do naszej funkcji i pod jej właściwością http . To nakazuje frameworkowi Serverless utworzyć bramę API i dołączyć ją do naszej funkcji Lambda podczas wdrażania aplikacji. Nasz plik konfiguracyjny powinien kończyć się w ten sposób:
usługa: aws-przykładowa-aplikacja
dostawca:
nazwa: aws
środowisko uruchomieniowe: nodejs12.x
profil: bezserwerowy-admin
region: us-wschód-2
Funkcje:
cześć:
handler: handler.hello
wydarzenia:
- http:
ścieżka: /cześć
metoda: zdobądź
W http podajemy ścieżkę i metodę HTTP.
To wszystko, wdróżmy ponownie naszą aplikację, uruchamiając sls deploy -v
Po zakończeniu w terminalu wyjściowym powinna pojawić się jedna nowa rzecz, a jest to utworzony punkt końcowy:
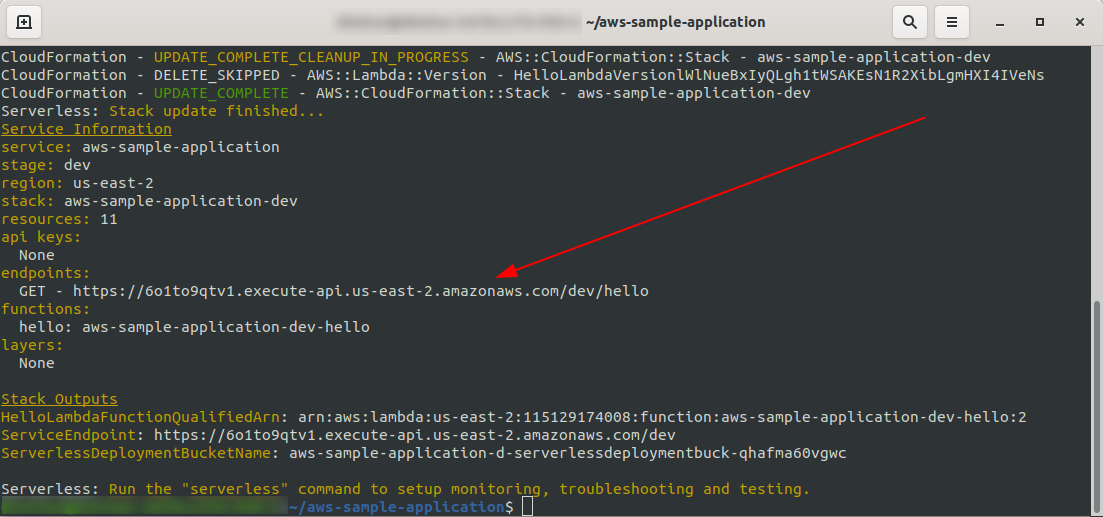
Otwórzmy punkt końcowy:
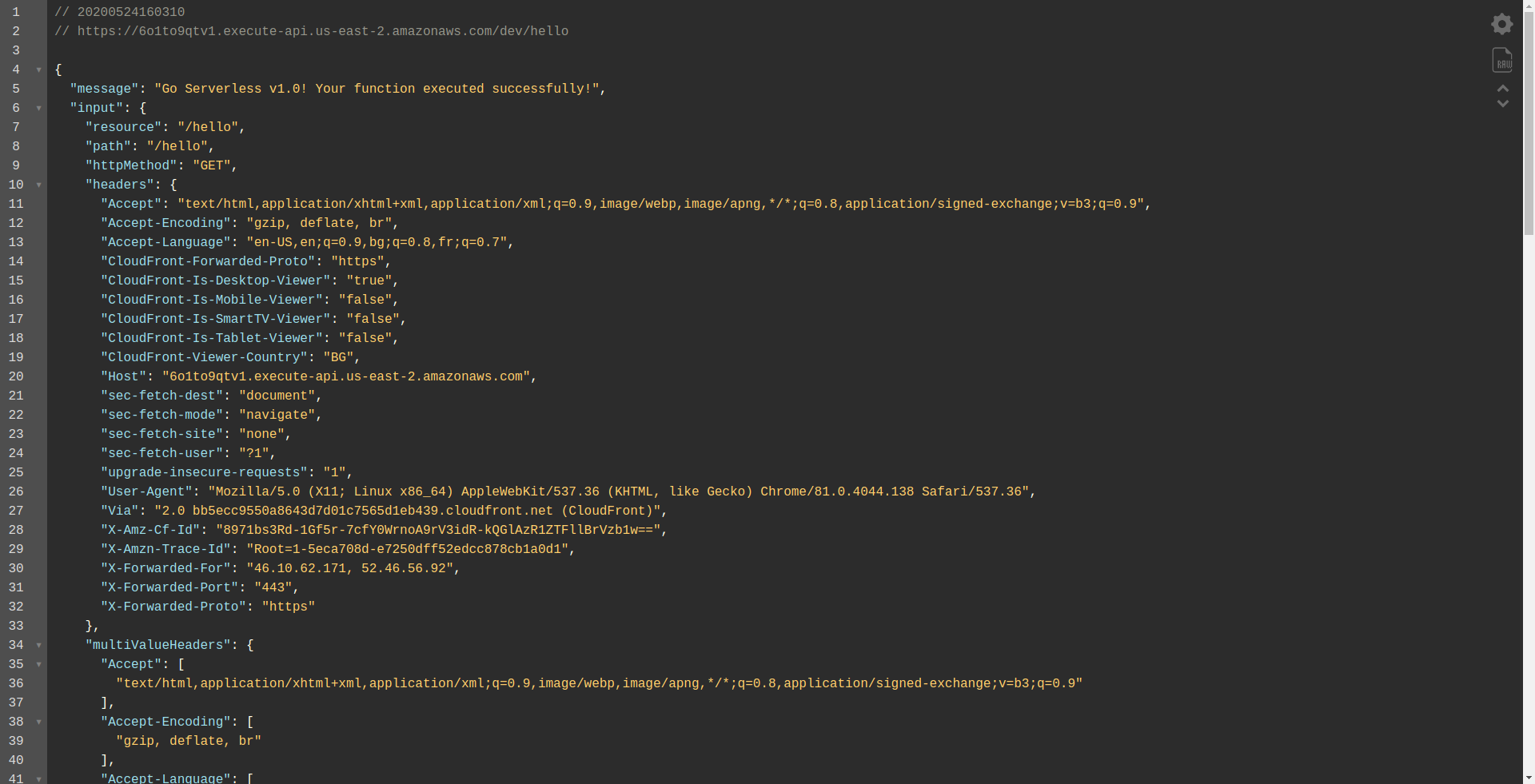
Powinieneś zobaczyć, że twoja funkcja jest wykonywana, zwraca dane wyjściowe i pewne informacje o żądaniu. Sprawdźmy, co się zmienia w naszej funkcji Lambda.
Otwórz AWS Lambda i kliknij swoją funkcję.
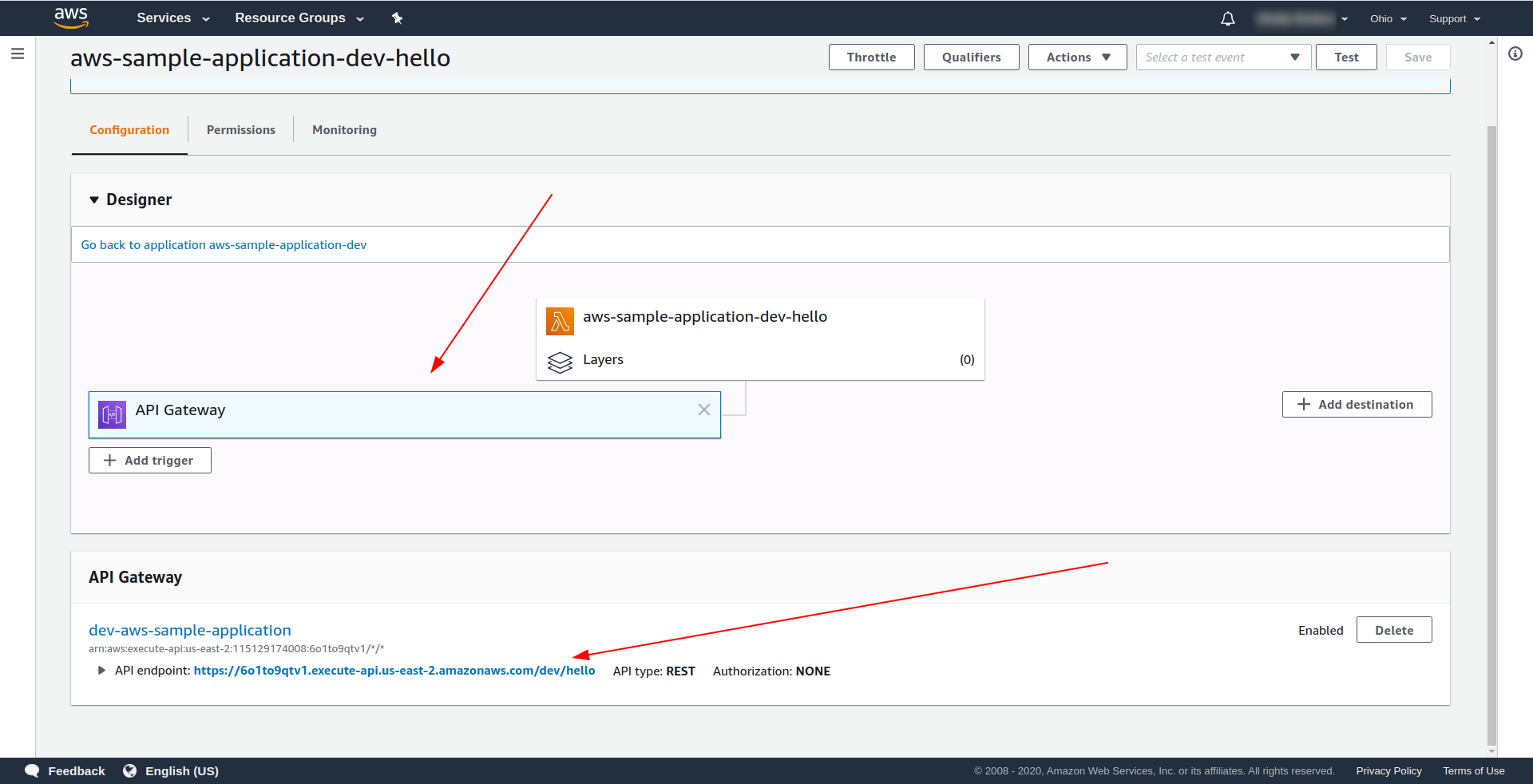
Widzimy pod zakładką „ Designer ”, że mamy API Gateway dołączoną do naszej Lambdy i API Endpoint.
Świetnie! Stworzyłeś bardzo prostą aplikację bezserwerową, wdrożyłeś ją w AWS Lambda i przetestowałeś jej funkcjonalność. Ponadto dodaliśmy punkt końcowy za pomocą AWS API Gateway .
4. Jak uruchomić aplikację w trybie offline
Do tej pory wiemy, że możemy wywoływać funkcje lokalnie, ale także możemy uruchomić całą naszą aplikację w trybie offline za pomocą wtyczki serverless-offline.
Wtyczka emuluje AWS Lambda i API Gateway na twojej lokalnej/deweloperskiej maszynie. Uruchamia serwer HTTP, który obsługuje żądania i wywołuje Twoje programy obsługi.
Aby zainstalować wtyczkę, uruchom poniższe polecenie w katalogu aplikacji
npm install serverless-offline --save-dev
Następnie w pliku serverless.yml projektu otwórz plik i dodaj właściwość plugins :
wtyczki: - bezserwerowy-offline
Konfiguracja powinna wyglądać tak:
usługa: aws-przykładowa-aplikacja
dostawca:
nazwa: aws
środowisko uruchomieniowe: nodejs12.x
profil: bezserwerowy-admin
region: us-wschód-2
Funkcje:
cześć:
handler: handler.hello
wydarzenia:
- http:
ścieżka: /cześć
metoda: zdobądź
wtyczki:
- bezserwerowy-offline
Aby sprawdzić, czy pomyślnie zainstalowaliśmy i skonfigurowaliśmy uruchomienie wtyczki
sls --verbose
Powinieneś to zobaczyć:
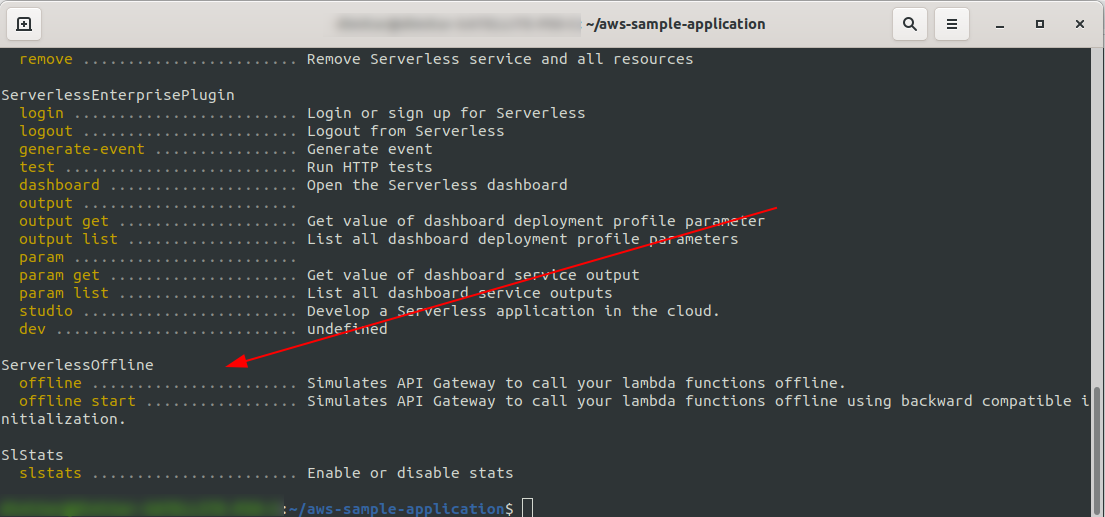
Teraz w katalogu głównym projektu uruchom polecenie
sls offline
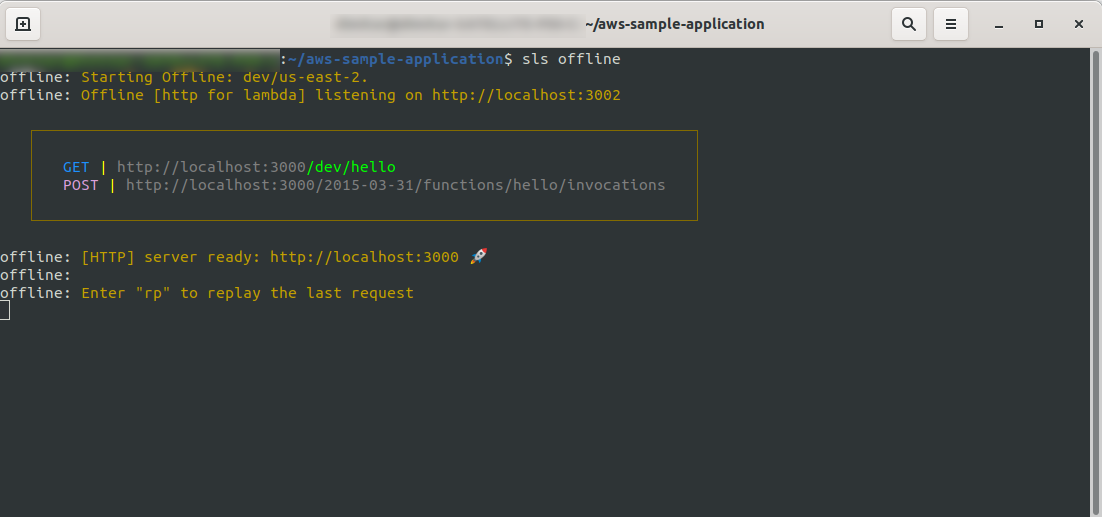
Jak widać, serwer HTTP nasłuchuje na porcie 3000 i możesz uzyskać dostęp do swoich funkcji, na przykład tutaj mamy http://localhost:3000/dev/hello dla naszej funkcji hello. Otwarcie, które mamy taką samą odpowiedź jak z API Gateway , które stworzyliśmy wcześniej.
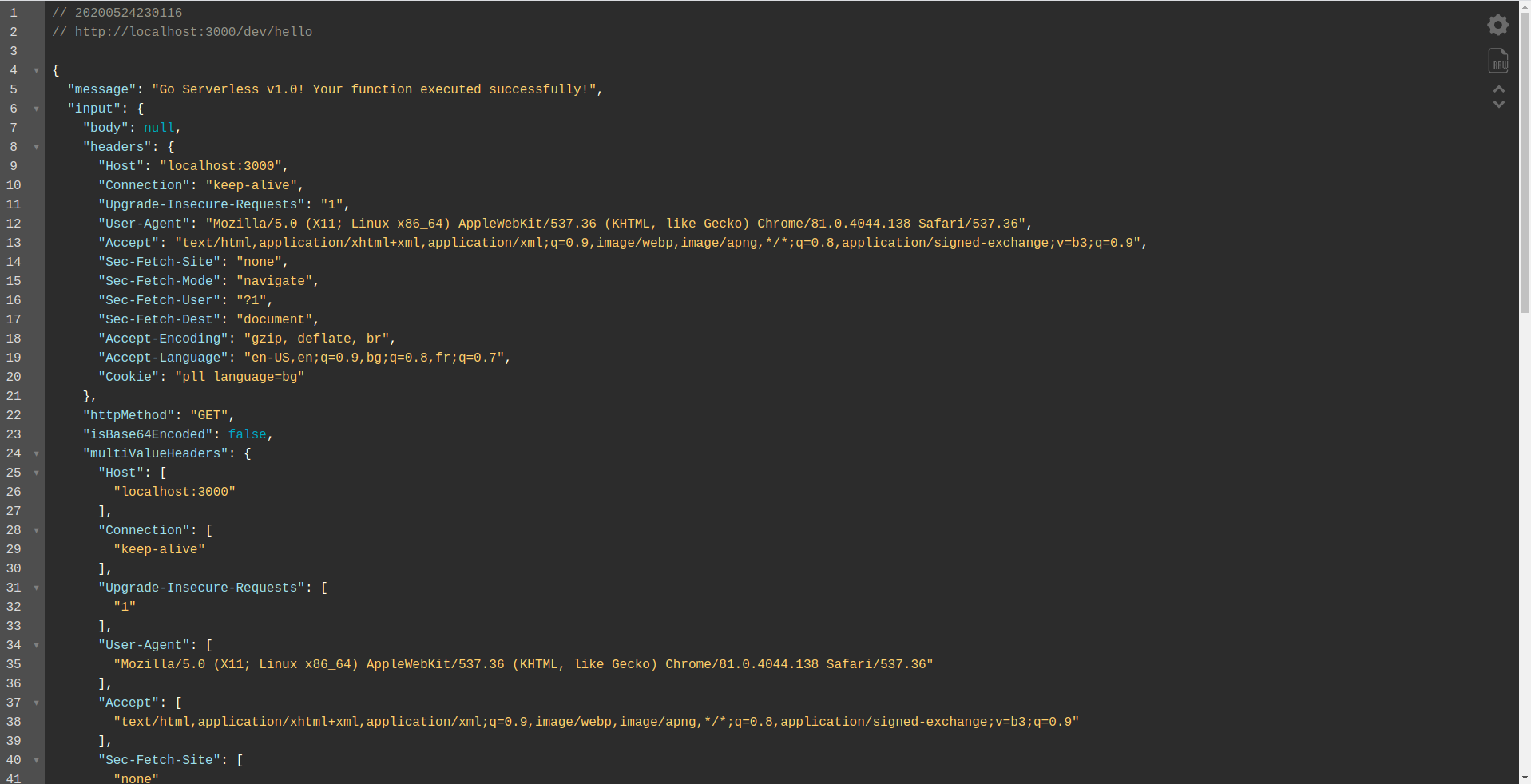
Dodaj integrację z Google BigQuery

Do tej pory wykonałeś świetną robotę! Masz w pełni działającą aplikację korzystającą z opcji Serverless. Rozszerzmy naszą aplikację i dodajmy do niej integrację BigQuery , aby zobaczyć, jak działa i jak przebiega integracja.

BigQuery to bezserwerowe oprogramowanie jako usługa (SaaS), czyli opłacalna i szybka hurtownia danych obsługująca zapytania. Zanim będziemy kontynuować integrację z naszą aplikacją NodeJS, musimy utworzyć konto, więc przejdźmy dalej.
1. Skonfiguruj konsolę Google Cloud
Wejdź na https://cloud.google.com i zaloguj się na swoje konto, jeśli jeszcze tego nie zrobiłeś – utwórz konto i kontynuuj.
Kiedy logujesz się do Google Cloud Console, musisz utworzyć nowy projekt. Kliknij trzy kropki obok logo, a otworzy się modalne okno, w którym wybierzesz „ Nowy projekt. ”
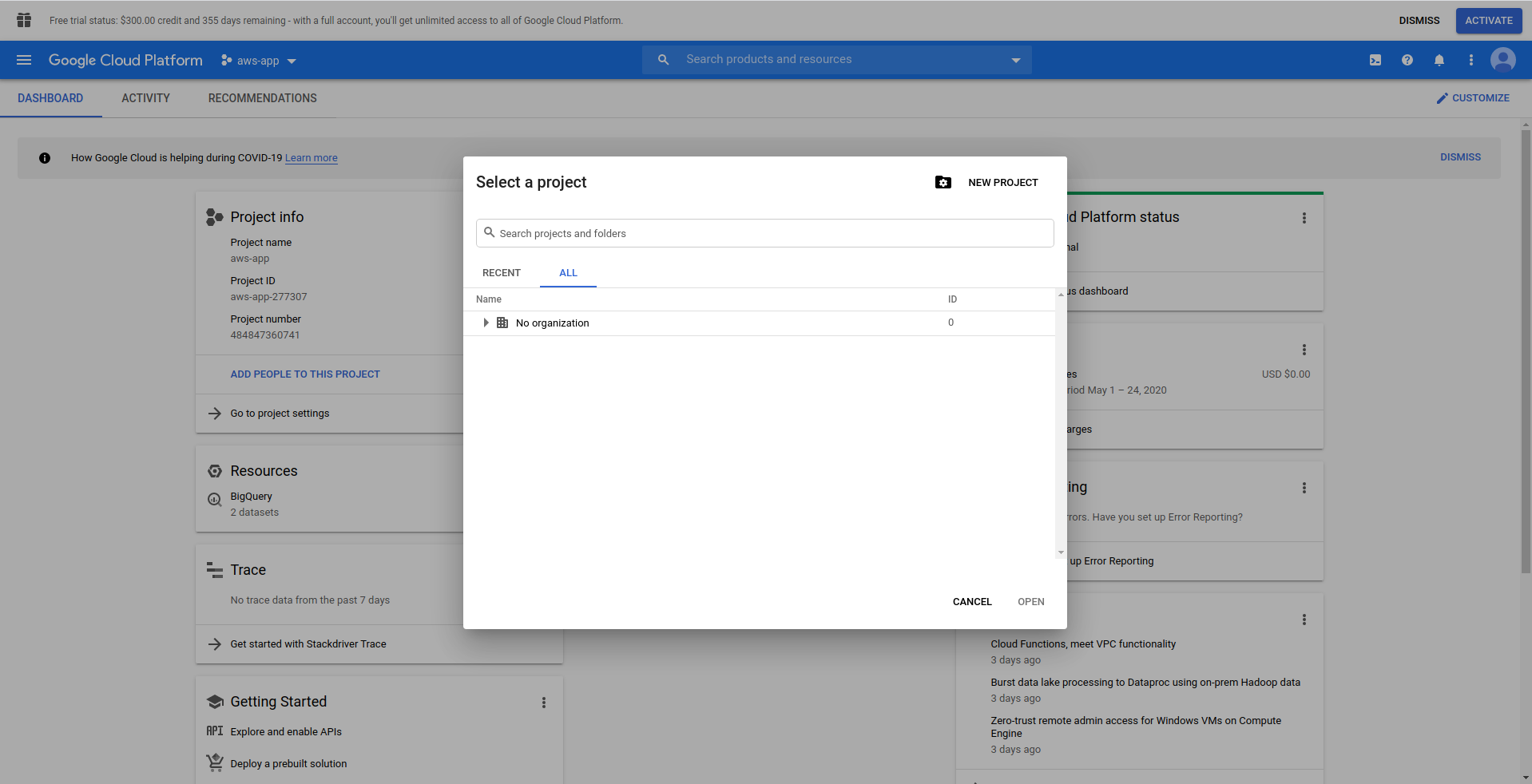
Wpisz nazwę swojego projektu. Użyjemy bigquery-example . Po utworzeniu projektu przejdź do BigQuery , korzystając z szuflady:
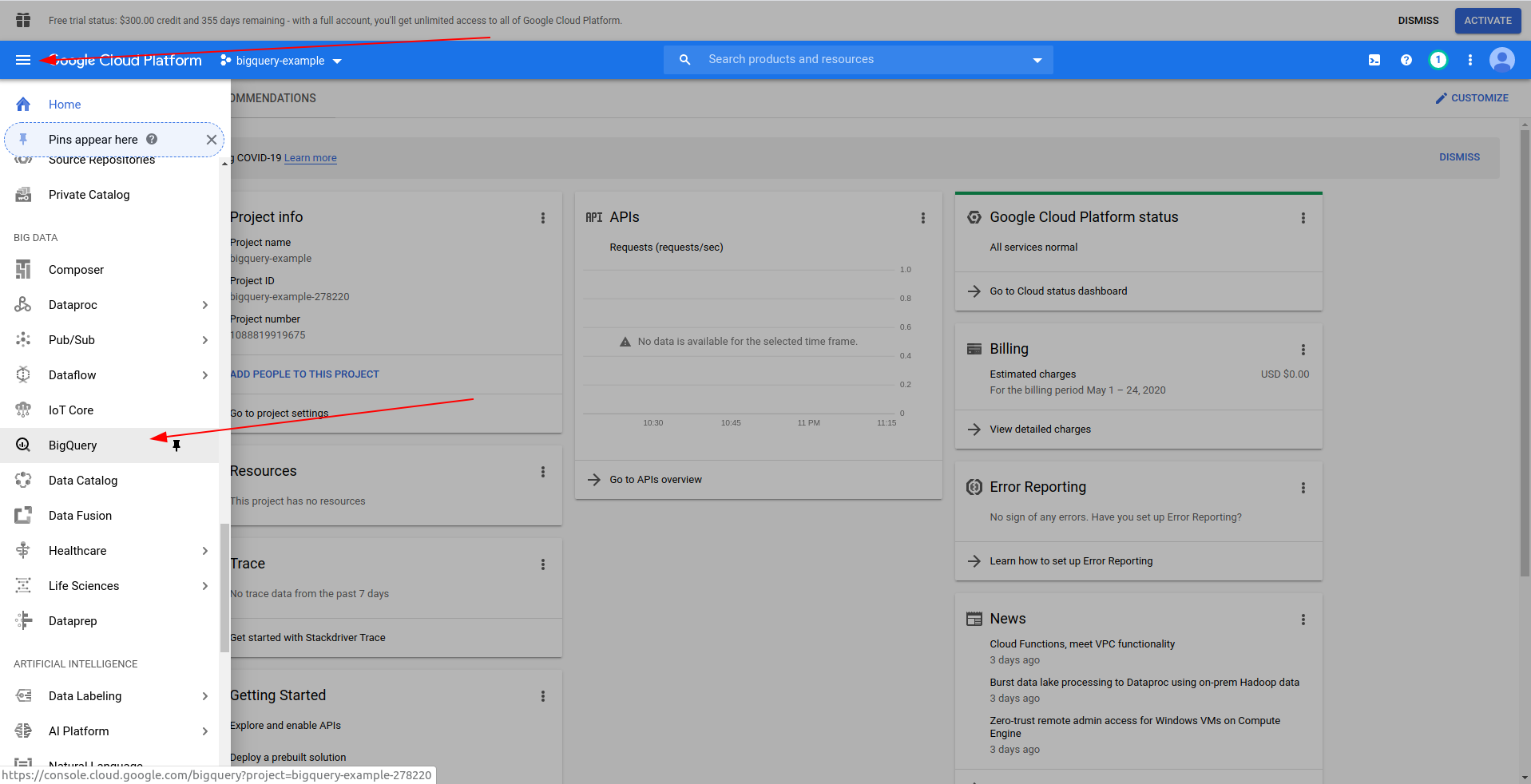
Po załadowaniu BigQuery po lewej stronie zobaczysz dane projektu, do których masz dostęp, a także publiczne zbiory danych. W tym przykładzie używamy publicznego zestawu danych. Nazywa się covid19_ecdc :
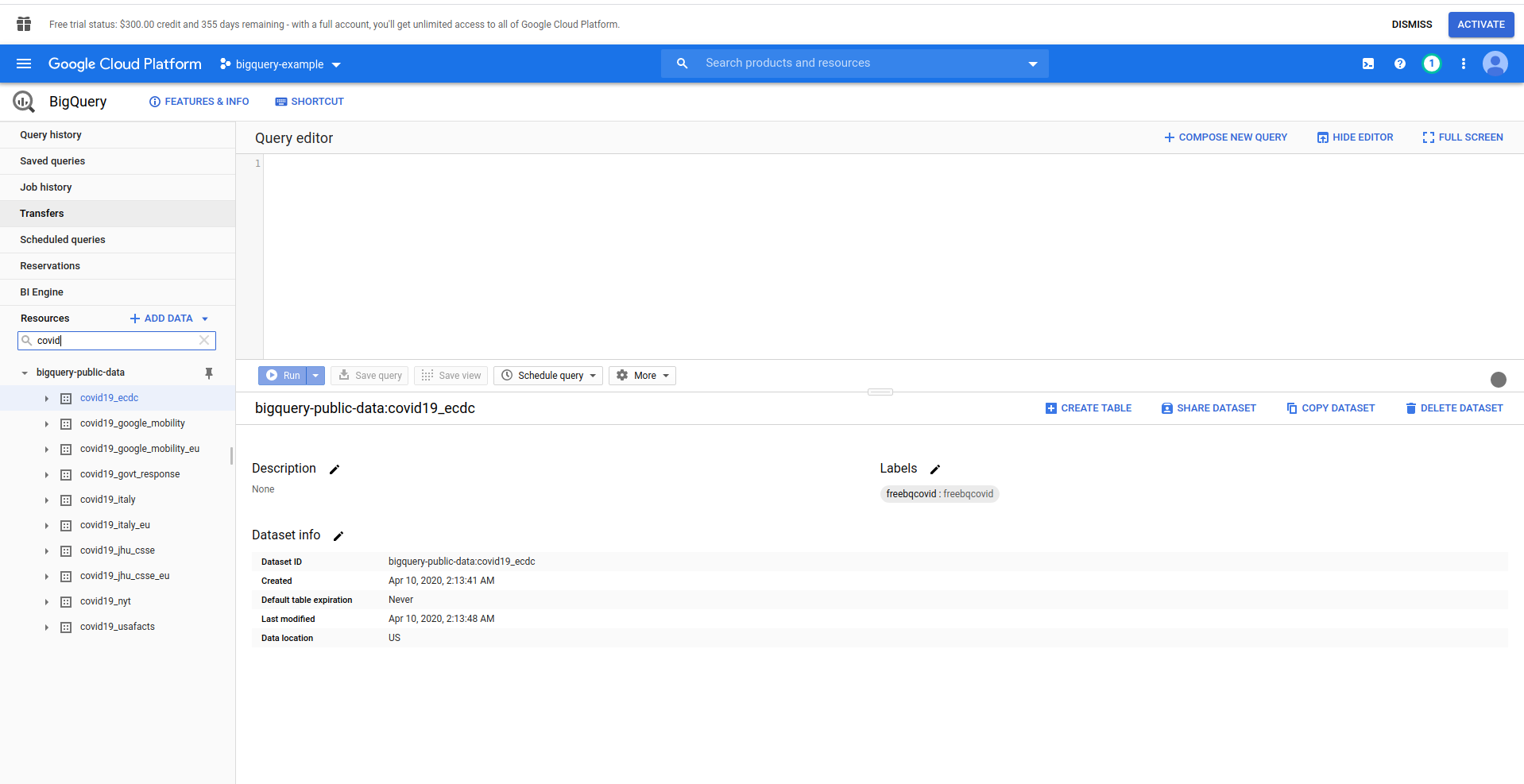
Baw się zbiorem danych i dostępnymi tabelami. Wyświetl podgląd danych w nim. To publiczny zbiór danych, który jest aktualizowany co godzinę i zawiera informacje o ogólnoświatowych danych dotyczących COVID-19 .
Aby uzyskać dostęp do danych, musimy utworzyć użytkownika IAM -> Konto usługi. W menu kliknij „IAM i administrator”, a następnie „Konta usług”.
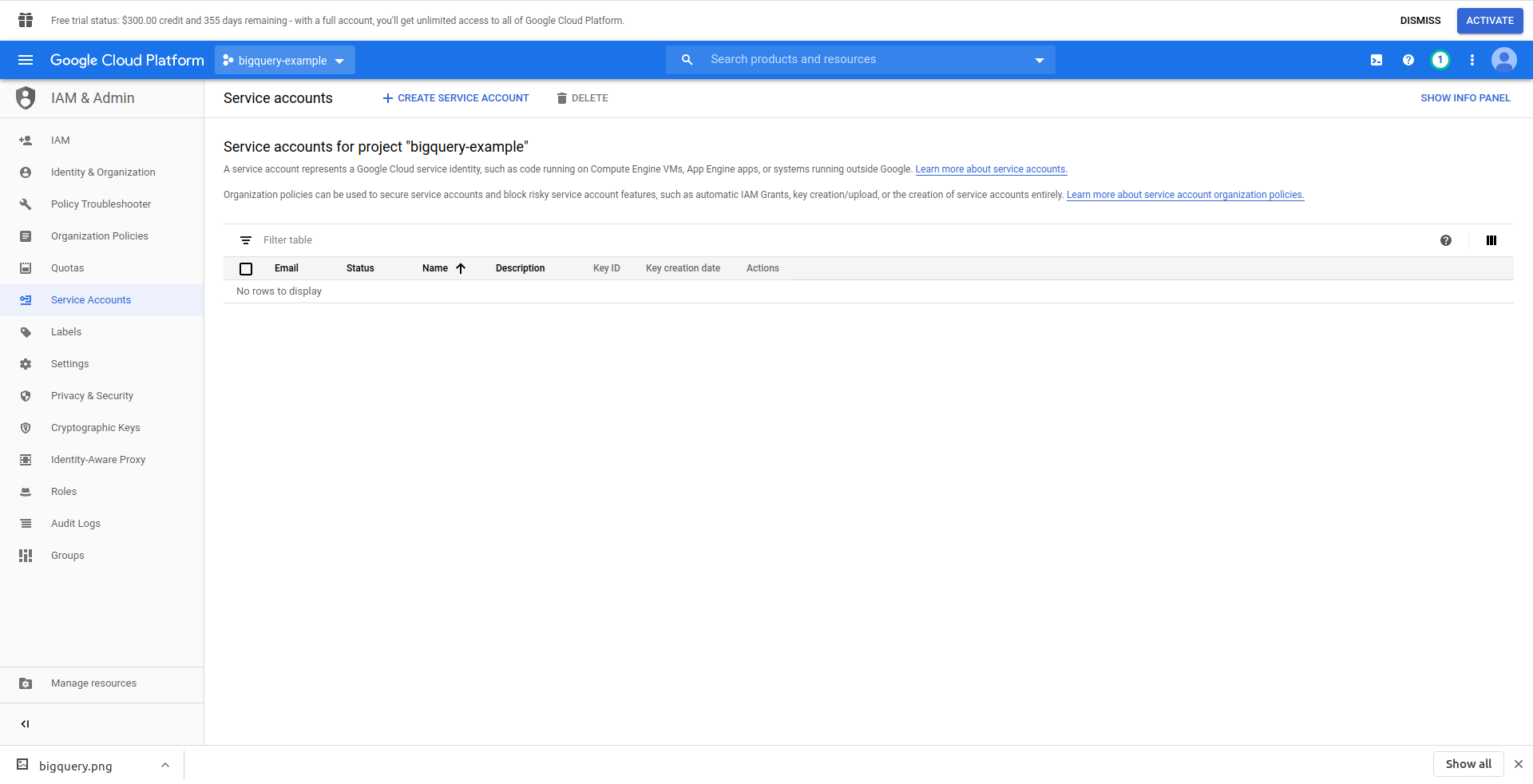
Kliknij przycisk „Utwórz konto usługi” , wprowadź nazwę konta usługi i kliknij „Utwórz”. Następnie przejdź do „ Uprawnienia konta usługi” , wyszukaj i wybierz „Administrator BigQuery” .
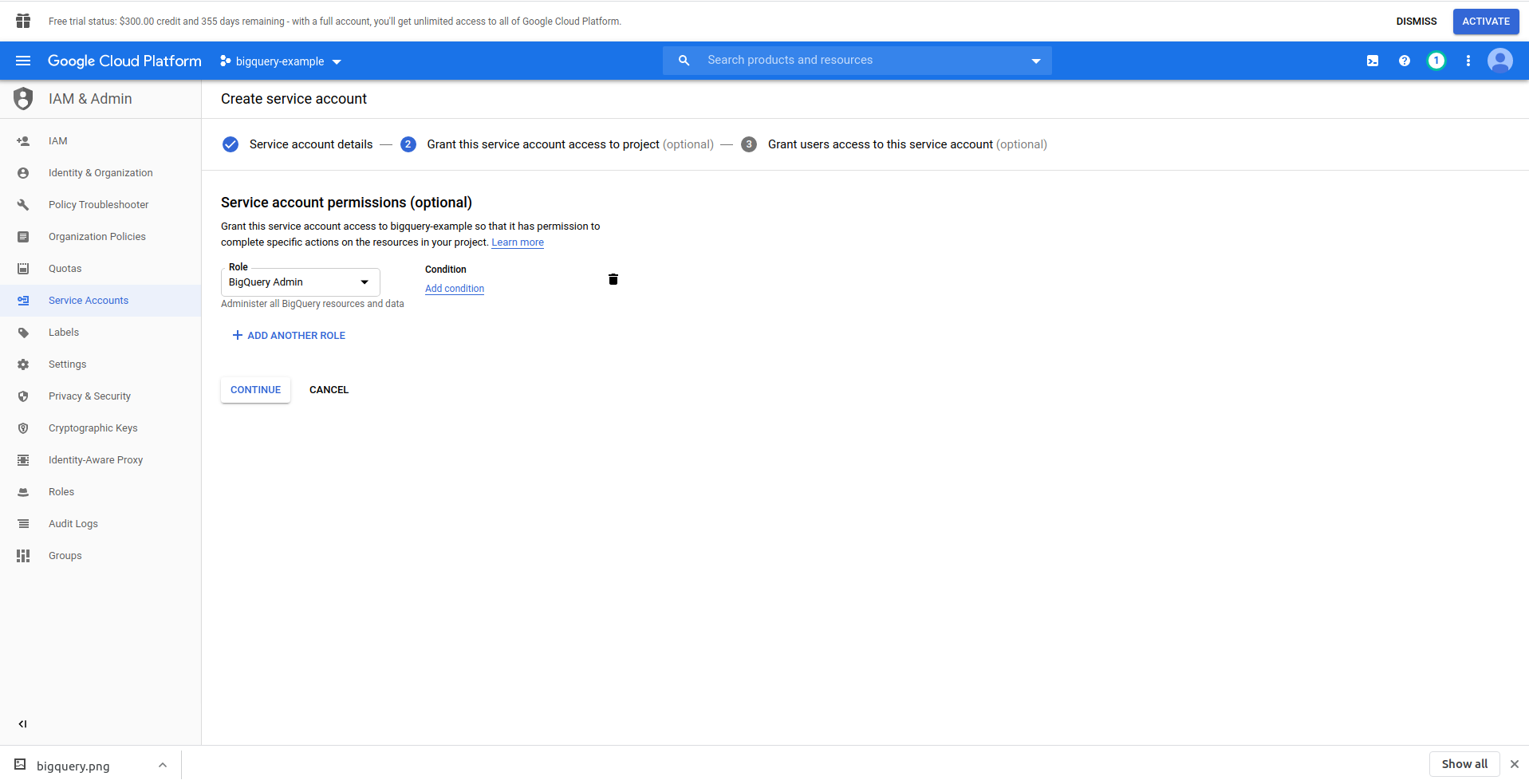
Kliknij „ Kontynuuj ”, to ostatni krok, tutaj potrzebujesz kluczy, więc kliknij przycisk tworzenia pod „ Klucze ” i wyeksportuj jako JSON . Zapisz to w bezpiecznym miejscu, będzie nam potrzebne później. Kliknij Gotowe , aby zakończyć tworzenie konta usługi.
Teraz użyjemy wygenerowanych tutaj poświadczeń, aby połączyć bibliotekę NodeJS BigQuery.
2. Zainstaluj bibliotekę NodeJS BigQuery
Musisz zainstalować bibliotekę BigQuery NodeJS, aby używać jej w właśnie utworzonym projekcie. Uruchom poniższe polecenia w katalogu aplikacji:
Najpierw zainicjuj npm, uruchamiając npm init
Wypełnij wszystkie pytania i kontynuuj instalację biblioteki BigQuery :
npm install @google-cloud/bigquery
Zanim przejdziemy dalej do zmiany naszego modułu obsługi funkcji, musimy przenieść klucz prywatny z utworzonego wcześniej pliku JSON. W tym celu użyjemy zmiennych środowiskowych Serverless . Więcej informacji znajdziesz tutaj.
Otwórz serverless.yml i we właściwości dostawcy dodaj właściwość środowiska w następujący sposób:
środowisko:
ID_PROJEKTU: ${plik(./config/bigquery-config.json):identyfikator_projektu}
CLIENT_EMAIL: ${plik(./config/bigquery-config.json):client_email}
KLUCZ_PRYWATNY: ${plik(./config/bigquery-config.json):klucz_prywatny}
Utwórz zmienne środowiskowe PROJECT_ID, PRIVATE_KEY i CLIENT_EMAIL , które pobierają te same właściwości (małe litery) z wygenerowanego przez nas pliku JSON. Umieściliśmy go w folderze config i nazwaliśmy go bigquery-config.json .
W tej chwili powinieneś otrzymać plik serverless.yml wyglądający tak:
usługa: aws-przykładowa-aplikacja
dostawca:
nazwa: aws
środowisko uruchomieniowe: nodejs12.x
profil: bezserwerowy-admin
region: us-wschód-2
środowisko:
ID_PROJEKTU: ${plik(./config/bigquery-config.json):identyfikator_projektu}
CLIENT_EMAIL: ${plik(./config/bigquery-config.json):client_email}
KLUCZ_PRYWATNY: ${plik(./config/bigquery-config.json):klucz_prywatny}
Funkcje:
cześć:
handler: handler.hello
wydarzenia:
- http:
ścieżka: /cześć
metoda: zdobądź
wtyczki:
- bezserwerowy-offline
Teraz otwórz handler.js i zaimportuj bibliotekę BigQuery, na górze pliku w sekcji „use strict” dodaj następujący wiersz:
const {BigQuery} = require('@google-cloud/bigquery');
Teraz musimy przekazać bibliotece BigQuery dane uwierzytelniające. W tym celu utwórz nową stałą, która tworzy instancję BigQuery z poświadczeniami:
const bigQueryClient = new BigQuery({
id projektu: process.env.PROJECT_ID,
referencje: {
client_email: process.env.CLIENT_EMAIL,
private_key: process.env.PRIVATE_KEY
}
});
Następnie utwórzmy nasze zapytanie BigQuery SQL. Chcemy uzyskać najnowsze informacje o przypadkach COVID-19 w Bułgarii. Używamy edytora zapytań BigQuery, aby przetestować go, zanim przejdziemy dalej, więc utworzyliśmy zapytanie niestandardowe:
WYBIERZ * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` GDZIE geo_ ZAMÓW WG daty LIMIT 1
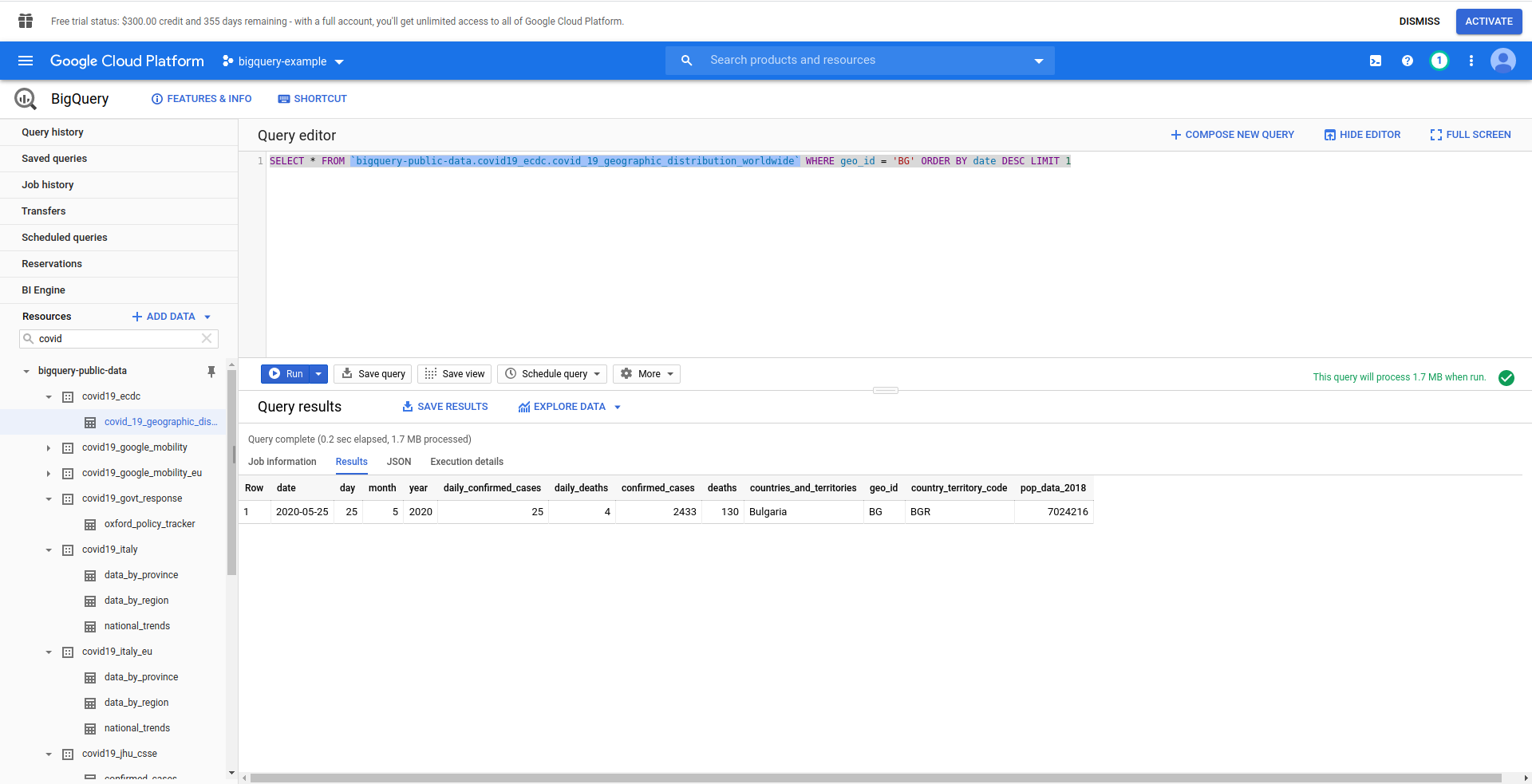
Dobry! Teraz zaimplementujmy to w naszej aplikacji NodeJS.
Otwórz handler.js i wklej poniższy kod
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
stałe opcje = {
zapytanie: zapytanie
}
const [zadanie] = czekaj bigQueryClient.createQueryJob(opcje);
const [wiersze] = await job.getQueryResults();
Stworzyliśmy stałe zapytań i opcji . Następnie uruchamiamy zapytanie jako zadanie i pobieramy z niego wyniki.
Zmieńmy też nasz moduł obsługi zwrotów, aby zwracał wygenerowane wiersze z zapytania:
powrót {
kod statusu: 200,
treść: JSON.stringify(
{
wydziwianie
},
zero,
2
),
};
Zobaczmy pełny handler.js :
„użyj ściśle”;
const {BigQuery} = require('@google-cloud/bigquery');
const bigQueryClient = new BigQuery({
id projektu: process.env.PROJECT_ID,
referencje: {
client_email: process.env.CLIENT_EMAIL,
private_key: process.env.PRIVATE_KEY
}
});
module.exports.hello = zdarzenie asynchroniczne => {
const query = 'SELECT * FROM `bigquery-public-data.covid19_ecdc.covid_19_geographic_distribution_worldwide` WHERE geo_id = \'BG\' ORDER BY date DESC LIMIT 1';
stałe opcje = {
zapytanie: zapytanie
}
const [zadanie] = czekaj bigQueryClient.createQueryJob(opcje);
const [wiersze] = await job.getQueryResults();
powrót {
kod statusu: 200,
treść: JSON.stringify(
{
wydziwianie
},
zero,
2
),
};
};
Dobra! Przetestujmy naszą funkcję lokalnie:
sls invoke local -f hello
Powinniśmy zobaczyć wynik:
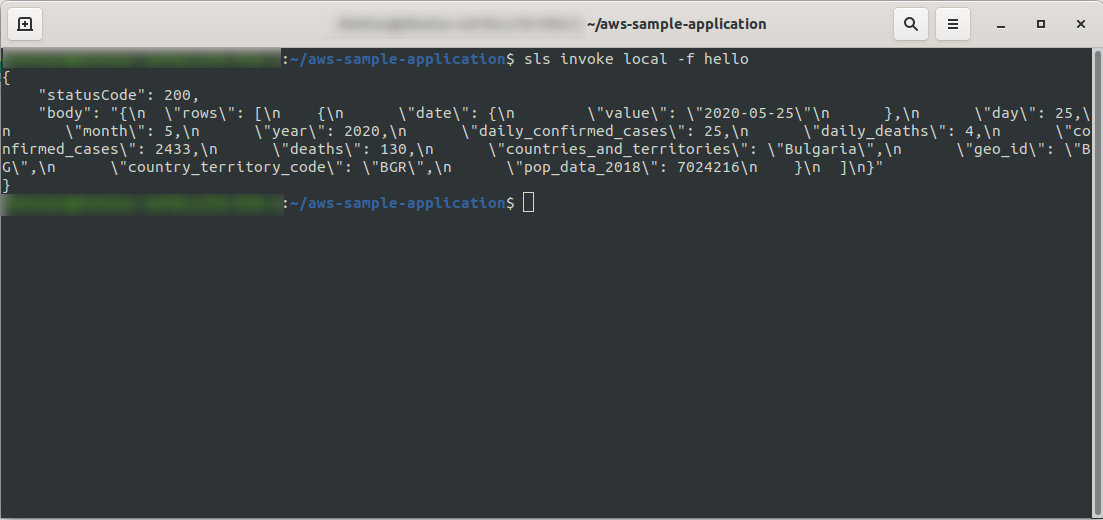
Kontynuuj wdrażanie aplikacji, aby przetestować ją za pośrednictwem punktów końcowych HTTP, więc uruchom sls deploy -v
Poczekaj, aż się zakończy i otwórz punkt końcowy. Oto wyniki:
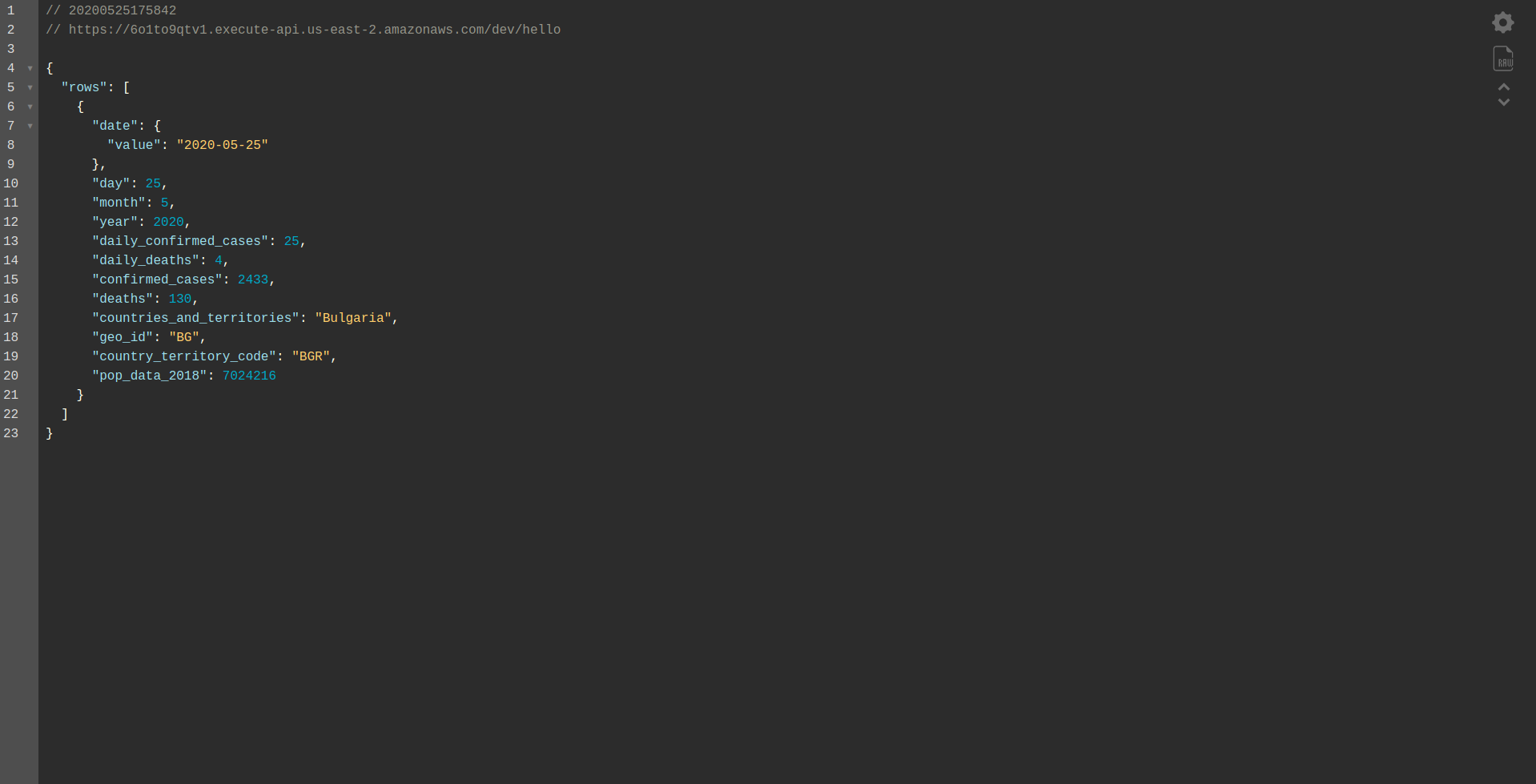
Dobrze zrobiony! Mamy teraz aplikację do pobierania danych z BigQuery i zwracania odpowiedzi! Sprawdźmy wreszcie, czy działa w trybie offline. Uruchom sls offline
I załaduj lokalny punkt końcowy:
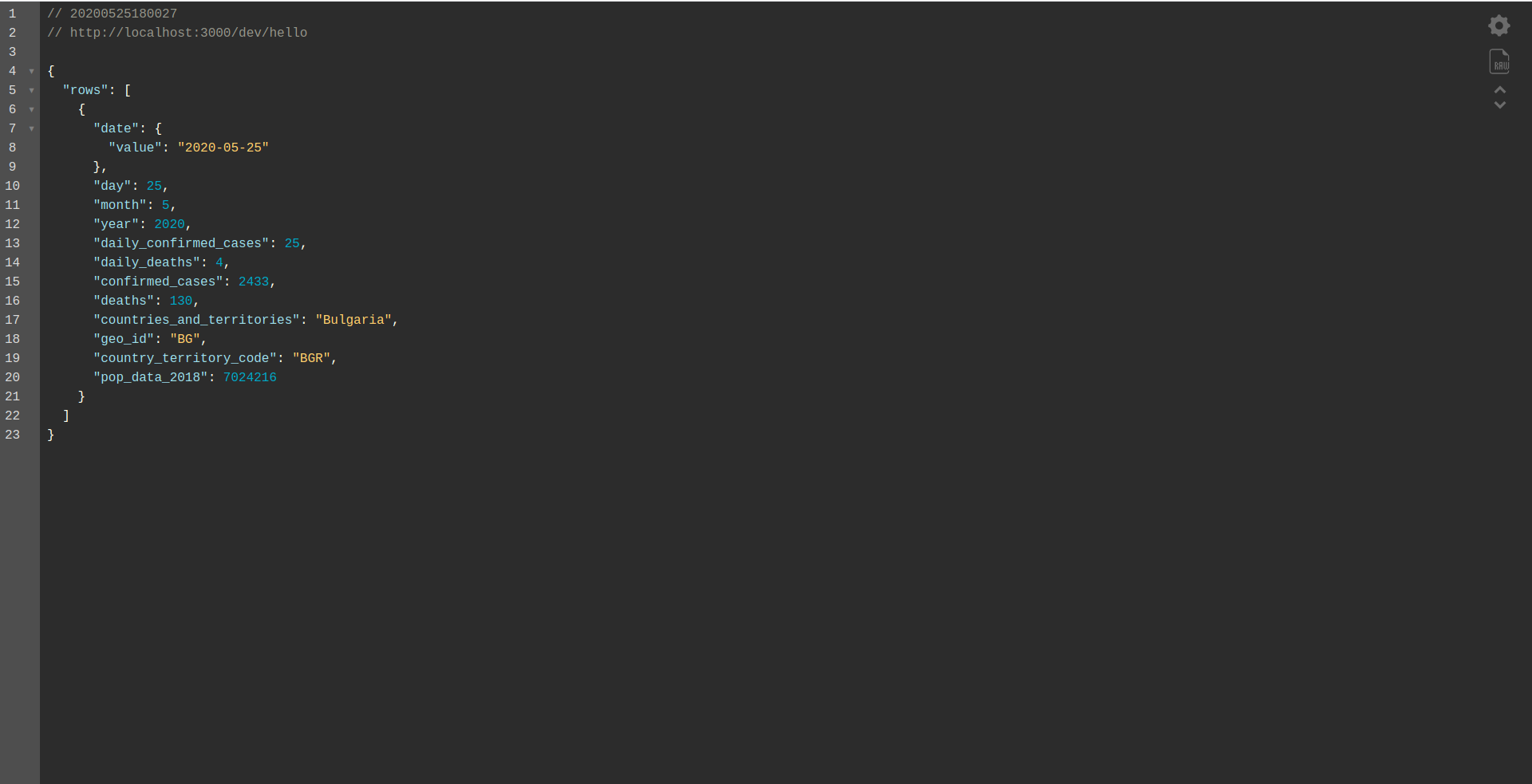
Dobra robota. Jesteśmy prawie na końcu procesu. Ostatnim krokiem jest nieznaczna zmiana aplikacji i zachowania. Zamiast AWS API Gateway chcemy użyć Application Load Balancer . Zobaczmy, jak to osiągnąć w następnym rozdziale.
ALB — system równoważenia obciążenia aplikacji w AWS
Stworzyliśmy naszą aplikację korzystając z AWS API Gateway. W tym rozdziale omówimy, jak zastąpić bramę interfejsu API modułem równoważenia obciążenia aplikacji (ALB).
Najpierw zobaczmy, jak działa load balancer aplikacji w porównaniu z API Gateway:
W load balancerze aplikacji mapujemy konkretną ścieżkę (np. /hello/ ) na grupę docelową – grupę zasobów, w naszym przypadku funkcję Lambda .
Z grupą docelową może być powiązana tylko jedna funkcja Lambda. Za każdym razem, gdy grupa docelowa musi odpowiedzieć, load balancer aplikacji wysyła żądanie do Lambda, a funkcja musi odpowiedzieć obiektem odpowiedzi. Podobnie jak brama interfejsu API, ALB obsługuje wszystkie żądania HTTP.
Istnieją pewne różnice między ALB i API Gateway . Jedną z głównych różnic jest to, że API Gateway obsługuje tylko HTTPS (SSL), podczas gdy ALB obsługuje zarówno HTTP, jak i HTTPS.
Zobaczmy jednak kilka zalet i wad bramy API:
Brama API:
Plusy:
- Doskonałe bezpieczeństwo.
- To proste do wdrożenia.
- Jest szybki do wdrożenia i gotowy w ciągu minuty.
- Skalowalność i dostępność.
Cons:
- W obliczu dużego natężenia ruchu może stać się dość drogie.
- Wymaga trochę więcej orkiestracji, co zwiększa poziom trudności dla programistów.
- Pogorszenie wydajności ze względu na scenariusze API może wpłynąć na szybkość i niezawodność aplikacji.
Kontynuujmy tworzenie ALB i przełączanie się na niego zamiast korzystania z API Gateway:
1. Co to jest ALB?
System równoważenia obciążenia aplikacji umożliwia programiście konfigurowanie i kierowanie ruchu przychodzącego. Jest to cecha „ elastycznego równoważenia obciążenia”. Służy jako pojedynczy punkt kontaktu dla klientów, rozdziela przychodzący ruch aplikacji na wiele celów, takich jak instancje EC2 w wielu strefach.
2. Utwórz system równoważenia obciążenia aplikacji za pomocą interfejsu użytkownika AWS
Utwórzmy nasz system równoważenia obciążenia aplikacji (ALB) za pomocą interfejsu użytkownika w Amazon AWS. Zaloguj się do Konsoli AWS w zakładce „ Znajdź usługi. ” wpisz „ EC2 ” i znajdź „ Load Balancer . ”
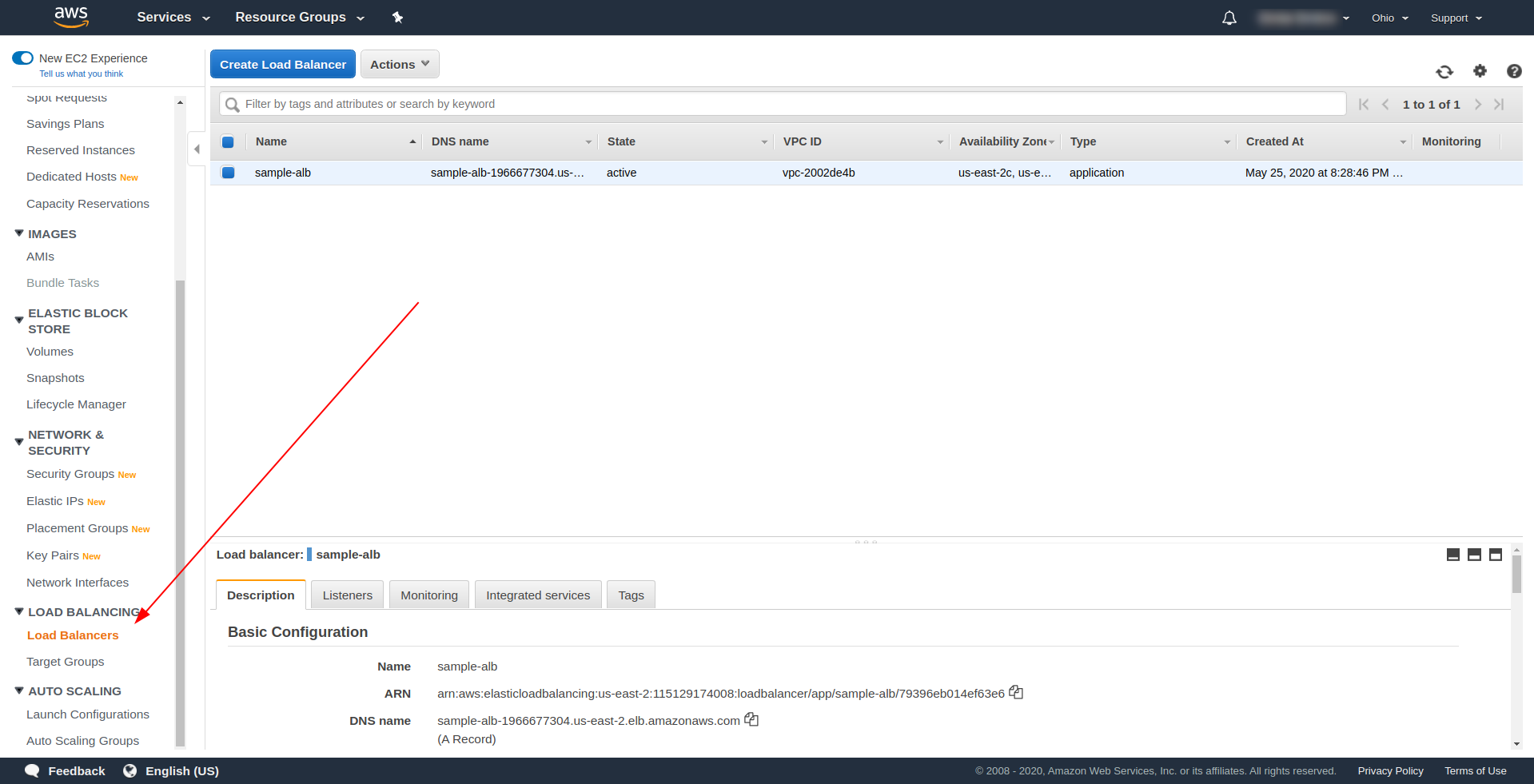
Kliknij „ Utwórz system równoważenia obciążenia ” w sekcji „ System równoważenia obciążenia aplikacji ” wybierz „ Utwórz ”. Jako nazwę wprowadź swój wybór, użyliśmy „ przykładowa-alb”, wybierz Schemat „ dostęp do Internetu ”, Typ adresu IP ipv4.
W „ Listeners ” pozostaw to tak, jak jest – HTTP i port 80. Można go skonfigurować dla HTTPS, chociaż musisz mieć domenę i potwierdzić ją, zanim będziesz mógł korzystać z HTTPS.
Strefy dostępności — w przypadku VPC wybierz tę, którą masz z listy rozwijanej i zaznacz wszystkie „ Strefy dostępności” :
Kliknij „ Dalej Skonfiguruj ustawienia zabezpieczeń ”, aby wyświetlić monit o poprawienie zabezpieczeń systemu równoważenia obciążenia. Kliknij Następny.
W „ Krok 3. Skonfiguruj grupy zabezpieczeń ”, w Przypisz grupę zabezpieczeń, aby wybrać „Utwórz nową grupę zabezpieczeń”. Kontynuuj, klikając „ Dalej: Konfiguruj routing. “. W kroku 4 skonfiguruj go tak, jak pokazano na powyższym zrzucie ekranu:
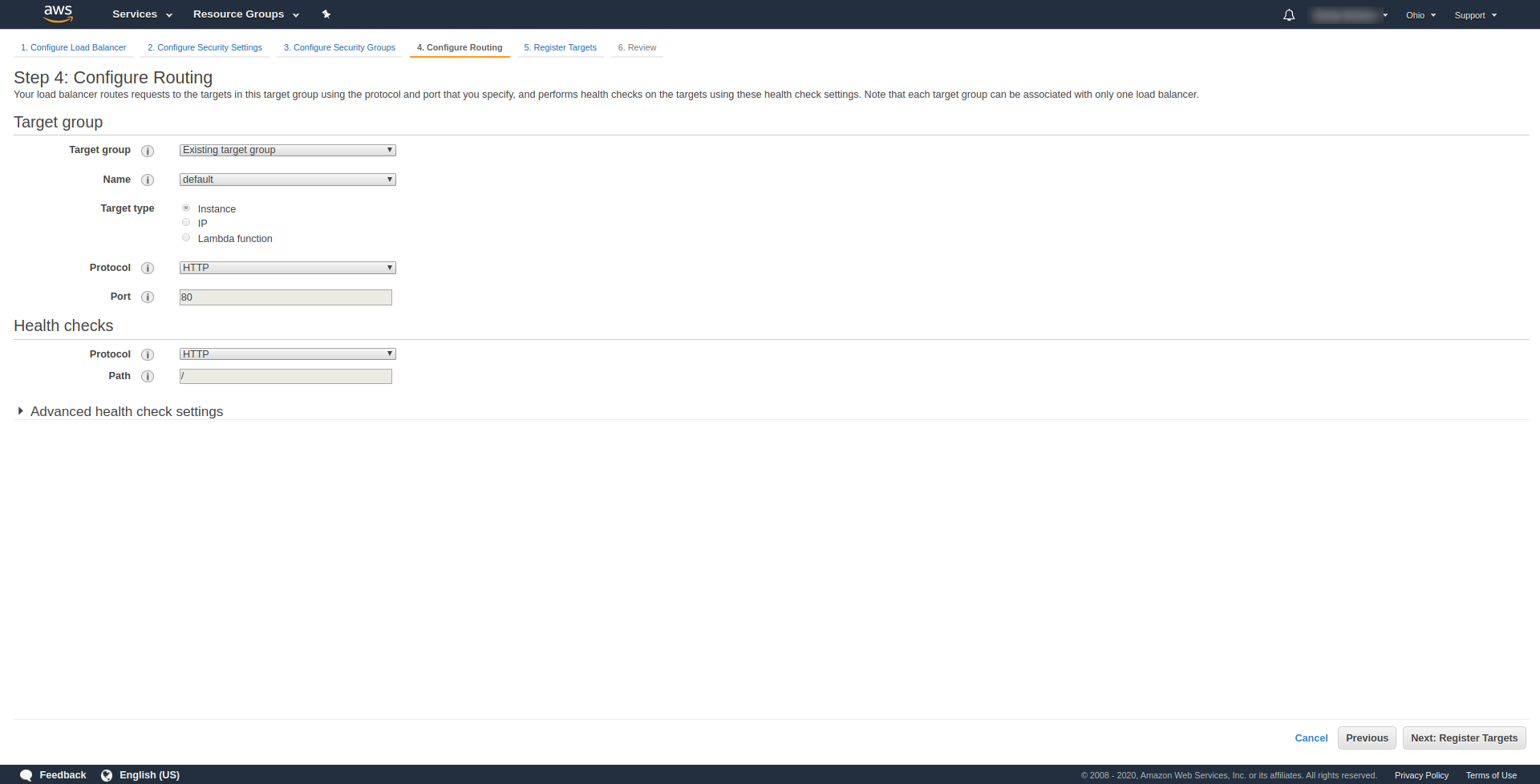
Kliknij Dalej , Dalej i Utwórz .
Wróć do systemów równoważenia obciążenia i skopiuj ARN, jak pokazano na zrzucie ekranu:
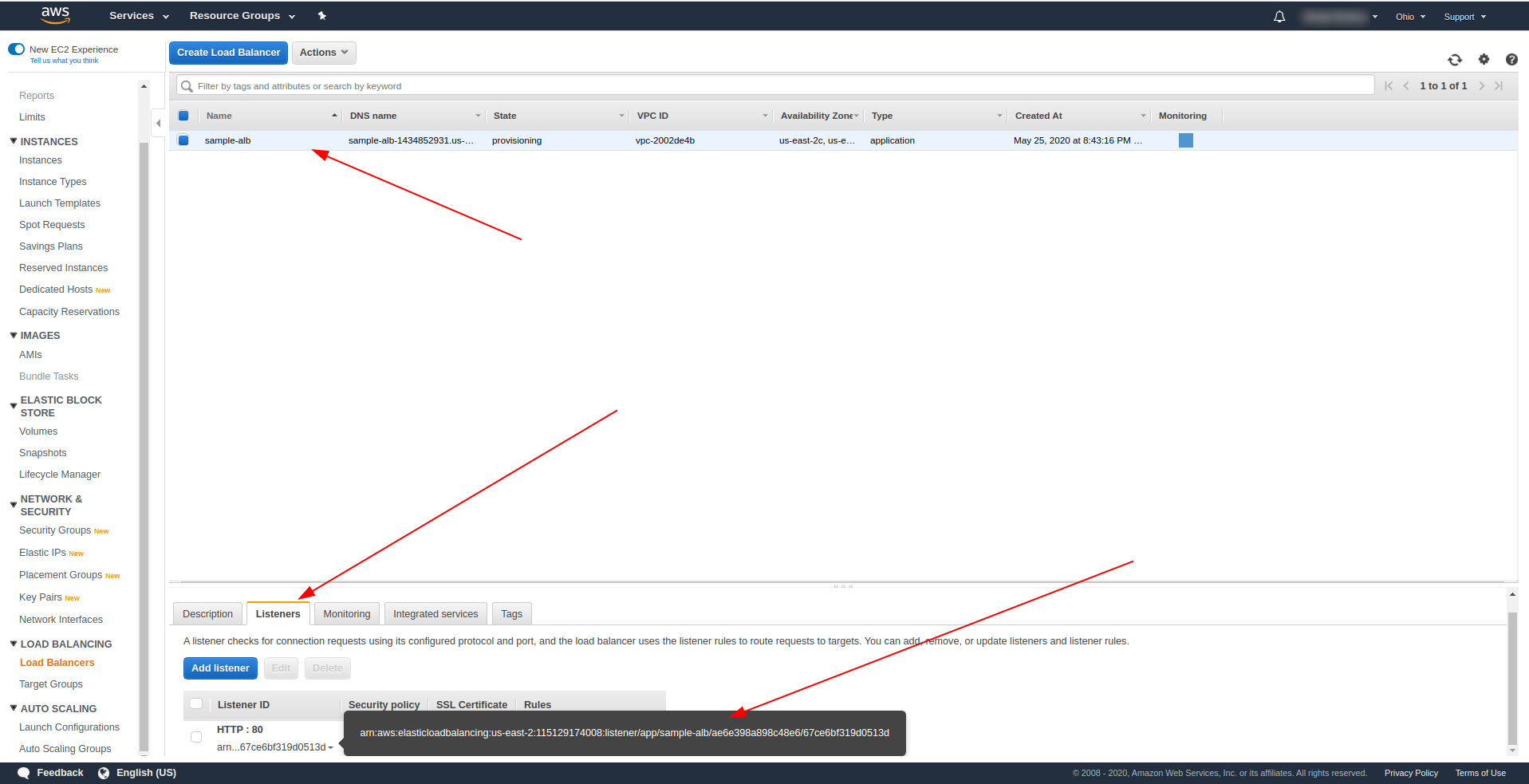
Teraz musimy zmienić nasz serverless.yml i usunąć właściwość http API Gateway. We właściwości zdarzenia usuń właściwość http i dodaj właściwość alb. Obiekt funkcji powinien kończyć się tak:
cześć:
handler: handler.hello
wydarzenia:
- alba:
listenerArn: arn:aws:elasticloadbalancing:us-east-2:115129174008:listener/app/sample-alb/ae6e398a898c48e6/67ce6bf319d0513d
priorytet: 1
warunki:
ścieżka: /cześć
Zapisz plik i uruchom polecenie wdrożenia aplikacji
sls deploy -v
Po pomyślnym wdrożeniu wróć do AWS Load Balancers i znajdź swoją nazwę DNS, jak pokazano na zrzucie ekranu:
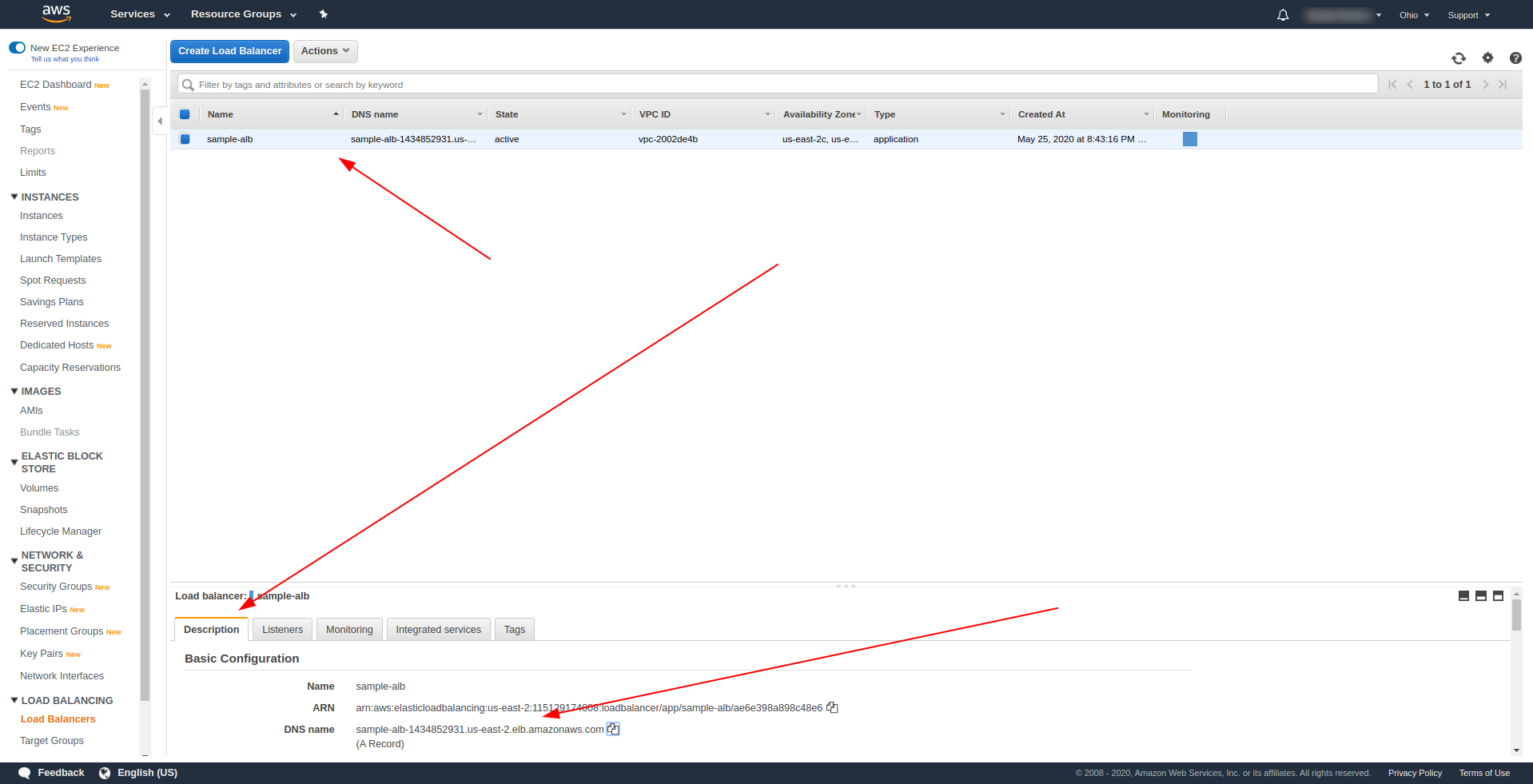
Skopiuj nazwę DNS i wpisz ścieżkę /hello .
Powinno działać i ostatecznie oferować opcję pobierania treści :). Jak dotąd load balancer aplikacji działa znakomicie, ale aplikacja musi zwrócić odpowiednią odpowiedź dla naszych użytkowników końcowych. Aby to zrobić, otwórz handler.js i zastąp instrukcję return następującą:
powrót {
kod statusu: 200,
statusOpis: "200 OK",
nagłówki: {
"Content-Type": "aplikacja/json"
},
isBase64Encoded: fałsz,
treść: JSON.stringify(wiersze)
}
Różnica ALB polega na tym, że odpowiedź musi zawierać statusDescription, nagłówki i isBase64Encoded kontenera. Zapisz plik i wdróż ponownie, ale tym razem nie całą aplikację, ale tylko zmienioną przez nas funkcję. Uruchom poniższe polecenie:
sls deploy -f hello
W ten sposób definiujemy tylko funkcję hello do wdrożenia. Po pomyślnym wdrożeniu ponownie odwiedź nazwę DNS ze ścieżką i powinieneś otrzymać poprawną odpowiedź!
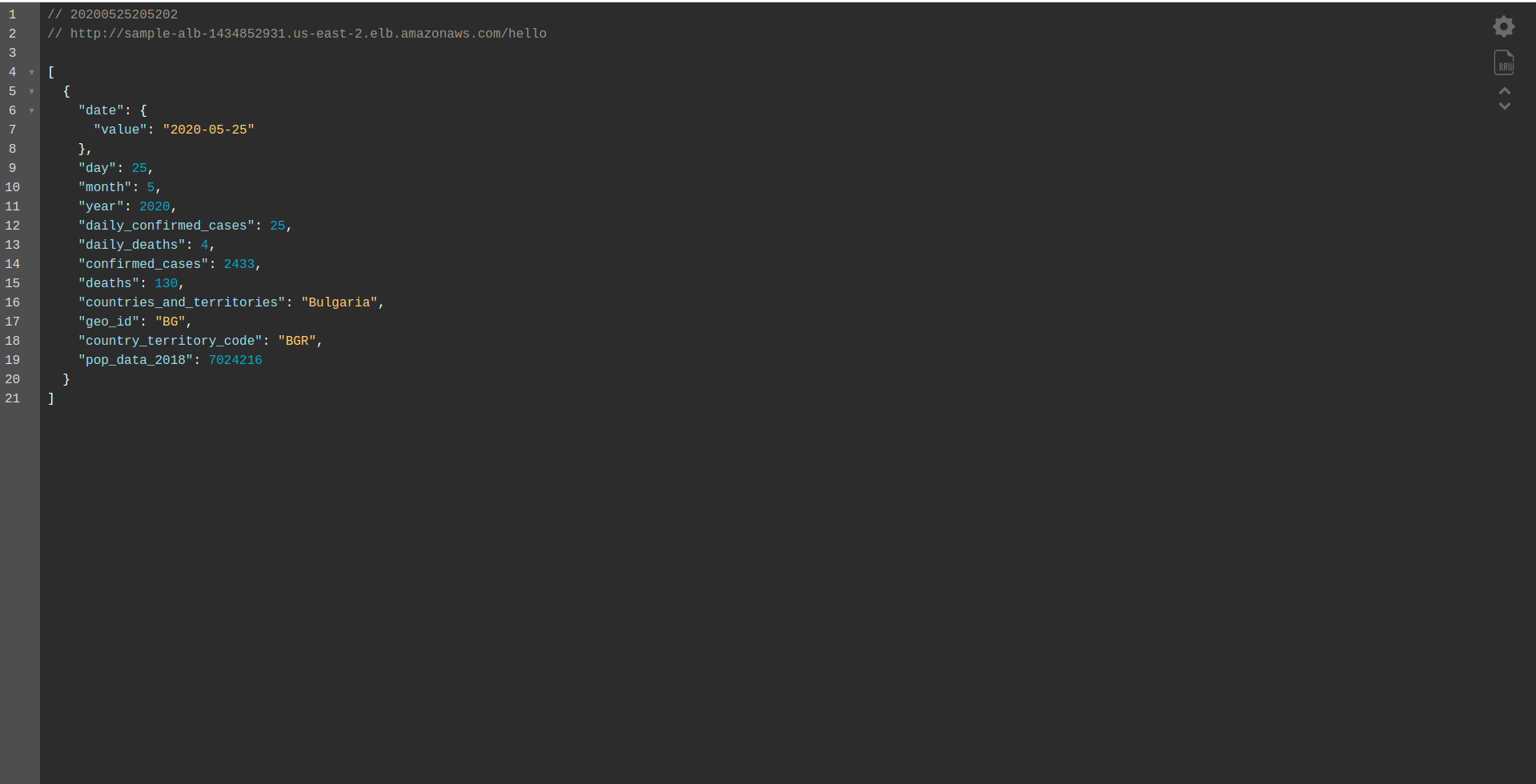
Świetnie! Teraz zastąpiliśmy API Gateway modułem Application Load Balancer. Load balancer aplikacji jest tańszy niż API Gateway, a teraz możemy rozszerzyć naszą aplikację tak, aby spełniała nasze potrzeby, zwłaszcza jeśli spodziewamy się większego ruchu.
Ostatnie słowa
Stworzyliśmy prostą aplikację przy użyciu platformy Serverless Framework, AWS i BigQuery i omówiliśmy jej podstawowe zastosowanie. Bezserwerowe to przyszłość i obsługa aplikacji za jej pomocą jest łatwa. Kontynuuj naukę i zanurz się w frameworku bezserwerowym, aby poznać wszystkie jego funkcje i sekrety, które posiada. Jest to również całkiem proste i wygodne narzędzie.