
Jak ChatGPT może pomóc w optymalizacji treści pod kątem podmiotów
Opublikowany: 2023-08-07Przy strategicznym wykorzystaniu ChatGPT może przewyższyć ręczny ludzki wysiłek w jakości wyjściowej.
Nie, narzędzia nie napiszą lepszej treści.
Zamiast tego uważam, że pisarz uzbrojony w tę technologię może tworzyć zoptymalizowane treści, które są lepiej dopasowane do kryteriów rankingowych Google.
Badając różne metody oceny treści i ekstrakcji jednostek, staram się poprowadzić Cię w kierunku maksymalizacji korzyści z narzędzi.
„Poza słowami kluczowymi: Jak podmioty wpływają na nowoczesne strategie SEO” omówiono, jak i dlaczego uwzględniać odpowiednie podmioty w witrynie (tj. mapę tematyczną).
W tym artykule skupimy się na tym, dlaczego i jak używać bytów do tworzenia treści SEO o lepszym rankingu.
W jaki sposób powiązane są elementy SEO i OpenAI?
Zanim omówimy, w jaki sposób oprogramowanie optymalizuje wykorzystanie encji w wynikach wyszukiwania, zrozummy podobieństwa między SEO encji a ChatGPT OpenAI.
Elementy składowe języka
Na najbardziej podstawowym poziomie język jest zbudowany wokół:
- Podmioty: O czym (lub o kim) jest zdanie.
- Predykaty: mówi coś o temacie.
Na przykład w zdaniu „Kot usiadł na macie” „Kot” jest podmiotem, a „siedział na macie” jest orzeczeniem.
Zarówno wyszukiwarka Google, jak i ChatGPT OpenAI mają na celu zrozumienie podstawowej struktury języka.
Wyszukiwarki semantyczne koncentrują się na zrozumieniu treści w sposób wydajny obliczeniowo.
ChatGPT idzie o krok dalej, wykorzystując znacznie więcej obliczeń do generowania treści.
Wyszukiwarki semantyczne
Wyszukiwarka Google identyfikuje podmioty, które zasadniczo są podmiotami zdań na stronie internetowej.
Następnie wykorzystuje kontekst wokół tych jednostek, aby zrozumieć predykaty - lub to, co jest powiedziane o tych jednostkach.
Dzięki temu Google może zrozumieć zawartość strony i jej przydatność do zapytania użytkownika.
Rozważane relacje są przedstawione na Grafie wiedzy Google.
Gdy Google analizuje artykuł, korzysta z Grafu wiedzy, aby uzyskać głębsze informacje.
Identyfikuje odpowiednie jednostki i predykaty w treści, co pozwala rozpoznać, do jakiego słowa kluczowego wyszukuje dany artykuł.
ChatGPT OpenAI
Z drugiej strony ChatGPT wykorzystuje swój model transformatora i osadzania, aby zrozumieć zarówno tematy, jak i predykaty.
W szczególności mechanizm uwagi modelu pozwala mu zrozumieć relacje między różnymi słowami w zdaniu, skutecznie rozumiejąc predykat.
Tymczasem osadzenie pomaga modelowi zrozumieć relacje i znaczenie samych słów, co obejmuje zrozumienie tematów.

Pomimo ogromnych różnic, ChatGPT i SEO podmiotów mają wspólną cechę:
Rozpoznawanie bytów i predykatów związanych z tematem. Ta wspólność podkreśla, jak ważne są byty dla naszego rozumienia języka.
Pomimo złożoności specjaliści SEO powinni skoncentrować swoje wysiłki na podmiotach, podmiotach i ich predykatach.
Jak więc wykorzystać to nowe zrozumienie do optymalizacji naszych treści?
Optymalizacja nowych treści dla podmiotów
Google identyfikuje jednostki i ich predykaty na stronie internetowej. Porównuje je również na potencjalnie odpowiednich stronach.
Zasadniczo działa jak system swatający, który stara się znaleźć najlepsze dopasowanie między zapytaniem użytkownika a treścią dostępną w sieci.
Biorąc pod uwagę, że algorytm Google jest zoptymalizowany pod kątem wysokiej jakości wyników, rozpocznij proces optymalizacji od sprawdzenia 10 najlepszych wyników Google.
Dzięki temu uzyskasz wgląd w atrybuty preferowane przez Google dla danego wyszukiwanego hasła.
W naszej agencji stosujemy ramy identyfikowania potencjalnych ulepszeń, które mogą sprawić, że nasze artykuły będą lepsze o 10-20%, którymi podzielę się poniżej.
Ramy, które nadają priorytet właściwym aspektom, mogą zilustrować różnicę między Twoimi treściami a materiałami o najwyższej randze.
Tworząc treści, kierujemy się tymi ramami i spełniamy te priorytetowe elementy.
Jeśli spełnimy wszystkie te kryteria, nastawiamy się na natychmiastowy sukces.

Zagłębianie się w część listy kontrolnej dotyczącą encji
Pomyśl o tym w ten sposób:
Wyobraź sobie, że Google śledzi, jak często pewne jednostki i ich predykaty pojawiają się razem.
Ustalono, które kombinacje są najważniejsze dla użytkowników wyszukujących określone tematy.
Twoim celem jako eksperta SEO powinno być uwzględnienie w treści tych kluczowych podmiotów, które możesz zidentyfikować, przeprowadzając inżynierię wsteczną najlepszych wyników, które Google już Ci pokazuje.
Jeśli Twoja strona internetowa zawiera elementy i predykaty, jakich Google oczekuje w przypadku danego wyszukiwania użytkownika, Twoje treści uzyskają wyższy wynik.
Dotkniemy wyjątku nowych relacji encji w przyszłej dyskusji.
W tym miejscu do gry wchodzą narzędzia, które strategicznie wykorzystują techniki ChatGPT i NLP, aby pomóc w analizie 10 najlepszych wyników.
Próba wykonania tego ręcznie może być czasochłonna i trudna ze względu na skalę danych, które trzeba będzie zużyć.
Krok 1: Wyodrębnianie jednostek
Aby przeprowadzić tę analizę, musisz naśladować natywne procesy Google i wydobywać predykaty, a następnie przekształcić swoje ustalenia w wykonalny plan działania/przewodnik dla pisarza.
W żargonie technicznym ćwiczenie to znane jest jako rozpoznawanie jednostek nazwanych, a różne biblioteki NLP mają swoje własne, unikalne podejścia.
Na szczęście na rynku dostępnych jest wiele narzędzi do pisania treści, które automatyzują te kroki.
Zanim jednak ślepo zastosujesz się do zaleceń narzędzia SEO, warto zrozumieć, co będzie, a co nie.
Rozpoznawanie nazwanych jednostek (NER)
Pomyśl o NER jako o procesie dwuetapowym: wykrywaniu i kategoryzowaniu.
Plamienie
- Pierwszy krok przypomina grę „I Spy”. Algorytm czyta tekst słowo po słowie, szukając słów lub fraz, które mogłyby być bytami. To tak, jakby ktoś czytał książkę i podkreślał nazwiska osób, miejsc lub dat.
Kategoryzowanie
- Gdy algorytm wykryje potencjalne byty, następnym krokiem jest ustalenie, jakiego rodzaju bytem jest każdy z nich. Przypomina to sortowanie wyróżnionych słów do różnych kategorii: jedna dla People , jedna dla Locations , jedna dla Dates i tak dalej.
Rozważmy przykład. Jeśli mamy zdanie: „Elon Musk urodził się w Pretorii w 1971 roku”.
Na etapie wykrywania algorytm może zidentyfikować „Elona Muska”, „Pretorię” i „1971” jako potencjalne podmioty.
Na etapie kategoryzacji sklasyfikowałby „Elona Muska” jako osobę , „Pretorię” jako lokalizację i „1971” jako datę .
Algorytm wykorzystuje kombinację reguł i modeli uczenia maszynowego wytrenowanych na dużych ilościach tekstu.
Modele te nauczyły się na przykładach, jak wyglądają różne typy jednostek, dzięki czemu mogą zgadywać, gdy napotykają nowy tekst.
Ekstrakcja relacji (RE)
Po tym, jak NER zidentyfikuje jednostki w tekście, następnym krokiem jest zrozumienie relacji między tymi jednostkami.
Odbywa się to poprzez proces zwany ekstrakcją relacji (RE). Relacje te zasadniczo działają jak predykaty łączące jednostki.
W kontekście NLP połączenia te są często reprezentowane jako trójki, które są zestawami trzech elementów:
- Temat.
- predykat.
- Obiekt.
Podmiot i przedmiot to zazwyczaj byty identyfikowane przez NER, a predykat to związek między nimi, identyfikowany przez RE.
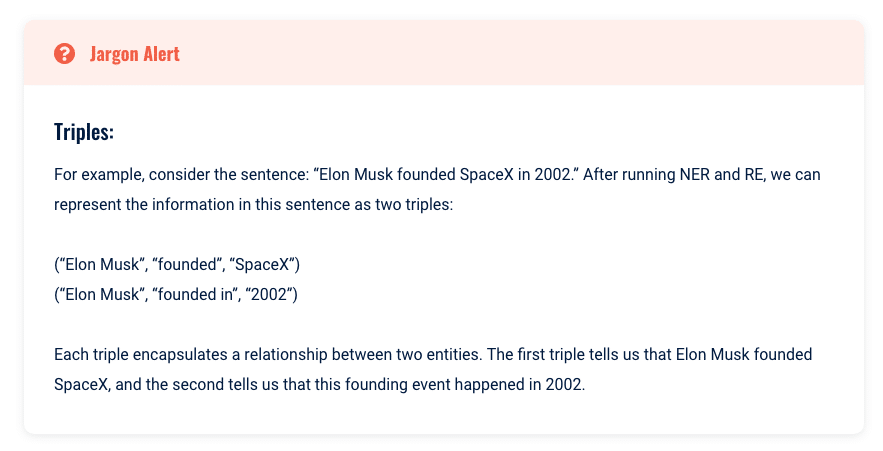
Koncepcja wykorzystania trójek do rozszyfrowania i zrozumienia relacji jest pięknie uproszczona. Możemy uchwycić podstawowe idee przedstawione przy minimalnych obliczeniach, czasie lub pamięci.
Świadectwem natury języka jest to, że dobrze rozumiemy, co się mówi, skupiając się tylko na jednostkach i ich predykatach.
Usuń wszystkie dodatkowe słowa, a pozostaną ci kluczowe elementy – migawka, jeśli chcesz, relacji, które tka autor.
Wyodrębnianie relacji i przedstawianie ich jako trójek jest kluczowym krokiem w NLP.
Pozwala komputerom zrozumieć narrację tekstu i kontekst wokół zidentyfikowanych podmiotów, umożliwiając bardziej szczegółowe zrozumienie i generowanie ludzkiego języka.
Pamiętaj, że Google to wciąż maszyna, a jego rozumienie języka różni się od ludzkiego.
Ponadto Google nie musi pisać treści, ale musi zrównoważyć wymagania obliczeniowe. Zamiast tego może wyodrębnić minimalną ilość informacji, która pozwala osiągnąć cel, jakim jest powiązanie treści z wyszukiwanym hasłem.
Krok 2: Tworzenie przewodnika dla pisarza
Musimy naśladować proces Google wyodrębniania podmiotów i ich relacji, aby wygenerować użyteczną analizę i plan działania.
Musimy zrozumieć i zastosować te dwie kluczowe idee w pierwszej dziesiątce wyników wyszukiwania. Na szczęście istnieje wiele sposobów podejścia do budowania mapy drogowej.
- Możemy polegać na ekstrakcji jednostek
- Możemy wyodrębnić frazy kluczowe.
Trasa podmiotu
Jedną z tras, którą można przetestować, jest metodologia podobna do narzędzi takich jak InLinks.
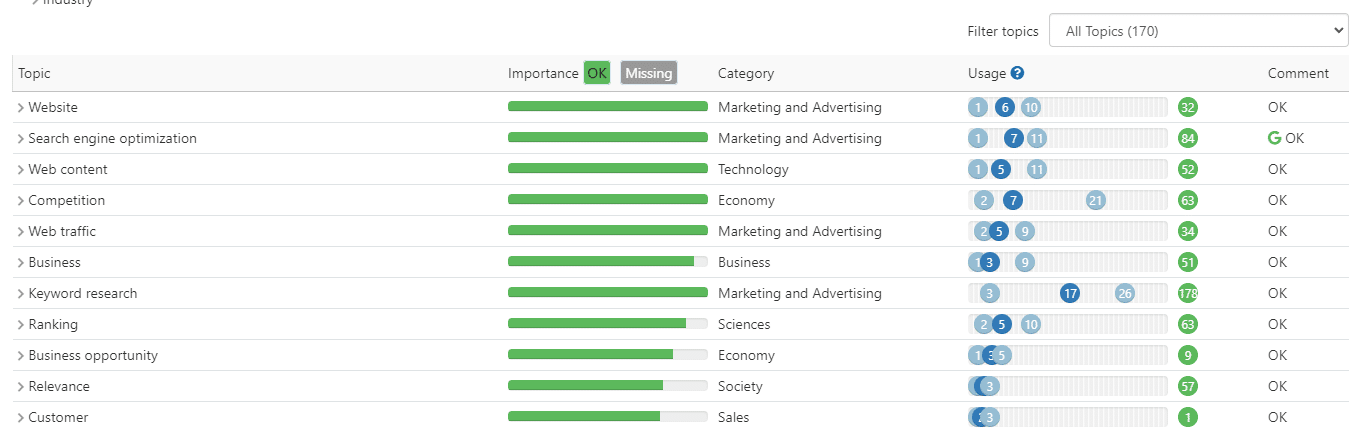
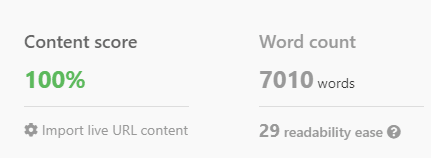
Platformy te wykorzystują wyodrębnianie jednostek z 10 najlepszych wyników, prawdopodobnie wykorzystując interfejs API NER firmy Google Cloud.
Następnie określają minimalną i maksymalną częstotliwość wyodrębnianych elementów w treści.
Na podstawie korzystania z tych podmiotów oceniają one Twoje treści.
Aby określić pomyślne użycie encji w twoim materiale, platformy te często opracowują własne algorytmy rozpoznawania encji.
Plusy i minusy
Ta metoda jest skuteczna i może pomóc w tworzeniu bardziej wiarygodnych treści. Pomija jednak kluczowy aspekt: ekstrakcję relacji.
Chociaż możemy dopasować użycie encji do najwyżej ocenianych artykułów, trudno jest zweryfikować, czy nasze treści zawierają wszystkie odpowiednie predykaty lub relacje między tymi encjami. (Uwaga: Google Cloud nie udostępnia publicznie interfejsu API wyodrębniania relacji).
Inną potencjalną pułapką tej strategii jest to, że promuje ona włączenie każdego podmiotu znalezionego w 10 najlepszych artykułach.
Idealnie byłoby, gdybyś chciał objąć wszystko, ale rzeczywistość jest taka, że niektóre byty mają większą wagę niż inne.
Sprawę dodatkowo komplikuje fakt, że wyniki wyszukiwania często zawierają mieszane intencje, co oznacza, że niektóre jednostki dotyczą tylko artykułów odpowiadających określonym celom wyszukiwania.
Na przykład skład encji strony z listą produktów będzie się znacznie różnił od wpisu na blogu.
Dla pisarza może być również trudne przekształcenie pojedynczych wyrazów w odpowiednie tematy dla ich treści. Włączanie i wyłączanie niektórych konkurentów może pomóc rozwiązać te problemy.
Nie zrozumcie mnie źle, jestem fanem tych narzędzi i wykorzystuję je jako część mojej analizy.
Każde podejście, którym się tutaj podzielę, ma swoje zalety i wady, z których wszystkie mogą do pewnego stopnia ulepszyć Twoje treści.
Jednak moim celem jest przedstawienie różnorodnych sposobów wykorzystania technologii i ChatGPT do optymalizacji podmiotów.
Trasa frazy kluczowej
Kolejną strategią, którą przyjęliśmy w naszych narzędziach, jest wyodrębnianie najważniejszych fraz kluczowych z 10 najlepszych konkurentów.
Piękno fraz kluczowych polega na ich przejrzystości, dzięki czemu użytkownik końcowy może łatwiej zrozumieć, co one reprezentują.
Ponadto zazwyczaj rejestrują temat i orzeczenie kluczowych tematów, a nie tylko podmioty lub podmioty.
Jednak jedną wadą jest to, że użytkownicy często mają trudności z bezproblemowym włączeniem tych słów kluczowych do swoich treści.
Zamiast tego mają tendencję do przepychania się w słowach kluczowych, tracąc istotę tego, co zawiera wyrażenie kluczowe.
Niestety, z punktu widzenia programisty, mierzenie i ocenianie pisarza na podstawie jego zdolności do uchwycenia esencji frazy kluczowej jest trudne.
Dlatego programiści muszą oceniać na podstawie dokładnego użycia wyrażenia kluczowego, co zniechęca do rzeczywistego zamierzonego zachowania.
Inną istotną zaletą podejścia opartego na frazach kluczowych jest to, że słowa kluczowe często służą jako drogowskazy dla narzędzi AI, takich jak ChatGPT, zapewniając, że generatywny model tekstu uchwyci kluczowe jednostki i ich predykaty (tj. trójki).
Na koniec rozważ różnicę między otrzymywaniem długiej listy rzeczowników a listą fraz kluczowych.
Tworzenie spójnej narracji z niepowiązanej listy rzeczowników może być dla ciebie kłopotliwe jako pisarz.
Ale kiedy masz do czynienia z frazami kluczowymi, znacznie łatwiej jest dostrzec, w jaki sposób mogą one naturalnie łączyć się w akapicie, przyczyniając się do bardziej spójnej i znaczącej narracji.
Jakie są różne podejścia do wydobywania fraz kluczowych?
Ustaliliśmy, że frazy kluczowe mogą skutecznie wskazywać tematy, o których należy pisać.
Należy jednak zauważyć, że różne narzędzia na rynku mają różne podejścia do wydobywania tych kluczowych fraz.
Ekstrakcja słów kluczowych to podstawowe zadanie w NLP, które polega na identyfikacji ważnych słów lub fraz, które mogą podsumować treść tekstu.

Istnieje kilka popularnych algorytmów wyodrębniania słów kluczowych, z których każdy ma swoje mocne i słabe strony podczas przechwytywania jednostek na stronie.
TF-IDF (częstotliwość dokumentu odwrotna do częstotliwości)
Chociaż TF-IDF był popularnym punktem dyskusji wśród SEO, często jest źle rozumiany, a jego spostrzeżenia nie zawsze są prawidłowo stosowane.
Ślepe przestrzeganie punktacji może, co zaskakujące, pogorszyć jakość treści.
TF-IDF waży każde słowo w dokumencie na podstawie jego częstotliwości w dokumencie i jego rzadkości we wszystkich dokumentach.
Chociaż jest to prosta i szybka metoda, nie bierze pod uwagę kontekstu słów ani znaczenia semantycznego.
Jaką wartość może zapewnić
Słowa o wysokiej punktacji reprezentują terminy, które są częste na poszczególnych stronach i rzadkie w całym zbiorze najwyżej ocenianych stron.
Z jednej strony terminy te można postrzegać jako wyznaczniki unikalnych, wyróżniających treści.
Mogą ujawnić określone aspekty lub podtematy w ramach docelowego tematu słów kluczowych, które nie są dokładnie uwzględnione przez konkurencję, co pozwala zapewnić wyjątkową wartość.
Jednak wysoko punktowane warunki mogą również wprowadzać w błąd.
TF-IDF może ujawnić wysoki wynik w kategoriach wyjątkowo ważnych dla określonych artykułów rankingowych, ale nie reprezentuje terminów ani tematów ogólnie ważnych dla rankingu.
Podstawowym tego przykładem może być nazwa marki firmy. Może być używany wielokrotnie w jednym dokumencie lub artykule, ale nigdy w innych artykułach rankingowych.
Włączenie go do treści nie miałoby sensu.
Z drugiej strony, jeśli znajdziesz hasła z niższymi wynikami TF-IDF, które pojawiają się konsekwentnie na stronach o wysokiej pozycji w rankingu, mogą one wskazywać na kluczowe „podstawowe” treści, które Twoja strona powinna zawierać.
Mogą nie być unikalne, ale mogą być niezbędne do trafności dla danego słowa kluczowego lub tematu.
Uwaga: TF-IDF reprezentuje wiele strategii, ale w odmianach można zastosować dodatkową matematykę. Należą do nich algorytmy takie jak BM25 do wprowadzania punktów nasycenia lub obliczania malejących zysków.
Dodatkowo, TF-IDF można znacznie ulepszyć, i często tak się dzieje, poprzez retroaktywne pokazywanie dla każdego terminu procentu 10 najlepszych stron, które zawierają to słowo. W tym przypadku algorytm pomaga zidentyfikować godne uwagi terminy, a następnie pomaga lepiej zrozumieć terminy „podstawowe”, pokazując stopień, w jakim 10 najlepszych terminów w rankingu ma te same warunki.
RAKE (Szybka automatyczna ekstrakcja słów kluczowych)
RAKE traktuje wszystkie frazy jako potencjalne słowa kluczowe, które mogą być przydatne do przechwytywania jednostek składających się z wielu słów.
Jednak nie bierze pod uwagę kolejności słów, co może prowadzić do bezsensownych fraz.
Zastosowanie algorytmu RAKE do każdej z 10 najlepszych stron z osobna stworzy listę fraz kluczowych dla każdej strony.
Kolejnym krokiem jest poszukiwanie nakładania się – fraz kluczowych, które pojawiają się na wielu najwyżej ocenianych stronach.
Te popularne wyrażenia mogą wskazywać tematy o szczególnym znaczeniu, które wyszukiwarki spodziewają się zobaczyć w związku z docelowym słowem kluczowym.
Integrując te wyrażenia z własną treścią (w znaczący i naturalny sposób), możesz potencjalnie zwiększyć trafność swojej strony, a tym samym jej pozycję w rankingu dla docelowego słowa kluczowego.
Należy jednak pamiętać, że nie wszystkie wspólne wyrażenia są koniecznie korzystne. Niektóre mogą być powszechne, ponieważ są ogólne lub szeroko związane z tematem.
Celem jest znalezienie tych wspólnych fraz, które mają istotne znaczenie i kontekst związane z konkretnym słowem kluczowym.
Wszystkie techniki wydobywania słów kluczowych można udoskonalić, umożliwiając używanie mózgu do włączania lub wyłączania konkurencji lub słów kluczowych.
Możliwość włączania i wyłączania konkurencji i określonych słów kluczowych pomoże rozwiązać wyżej wymienione problemy.
Zawodnicy
Słowa kluczowe
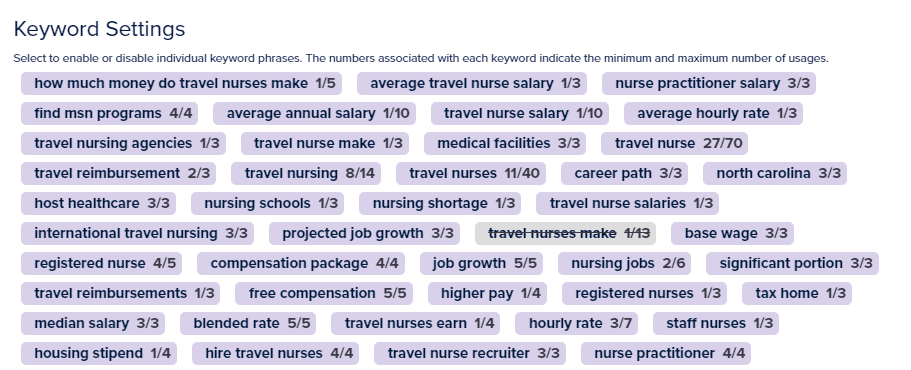
Podejście to zasadniczo zapewnia sposób na połączenie mocnych stron zarówno RAKE (identyfikowanie kluczowych fraz w poszczególnych dokumentach), jak i strategii bardziej zbliżonej do TF-IDF (biorąc pod uwagę znaczenie terminów w zbiorze dokumentów).
W ten sposób możesz wykorzystać bardziej całościowe zrozumienie krajobrazu treści dla docelowego słowa kluczowego, co pomoże Ci stworzyć unikalną i trafną treść.
YAKE (kolejny ekstraktor słów kluczowych)
W końcu, YAKE bierze pod uwagę częstotliwość występowania słów i ich pozycję w tekście.
Może to pomóc w zidentyfikowaniu ważnych jednostek, które pojawiają się na początku lub na końcu dokumentu.
Może jednak ominąć ważne podmioty, które pojawiają się w środku.
Każdy algorytm skanuje tekst i identyfikuje potencjalne słowa kluczowe na podstawie różnych kryteriów (np. częstotliwość, pozycja, podobieństwo semantyczne).
Następnie przypisują punktację każdemu potencjalnemu słowu kluczowemu; najwyżej punktowane słowa kluczowe są wybierane jako ostateczne.
Algorytmy te mogą skutecznie przechwytywać jednostki, ale istnieją ograniczenia.
Na przykład mogą pomijać rzadkie elementy lub nie pojawiać się w tekście jako słowa kluczowe. Mogą również zmagać się z bytami o wielu nazwach lub o których mowa w różny sposób.
Podsumowując, słowa kluczowe zapewniają kilka ulepszeń w porównaniu z prostym NER.
- Łatwiej je zrozumieć autorowi.
- Przechwytują zarówno predykaty, jak i jednostki.
- Jak zobaczymy w następnej sekcji, działają one jako lepsze drogowskazy dla sztucznej inteligencji do pisania treści zoptymalizowanych pod kątem encji.
OpenAI
ChatGPT i OpenAI naprawdę zmieniają zasady gry w SEO.
Aby w pełni wykorzystać swój potencjał, potrzebuje dobrze poinformowanego eksperta SEO, który poprowadzi go właściwą ścieżką, oraz skrupulatnie skonstruowanej mapy encji, która poprowadzi go w odpowiednich tematach, o których warto pisać.
Rozważ scenariusz:
Być może zdałeś sobie sprawę, że możesz udać się do ChatGPT i poprosić go o napisanie artykułu na prawie każdy temat, a on z łatwością się do tego zastosuje.
Jednak pytanie brzmi, czy powstały artykuł zostanie zoptymalizowany pod kątem rankingu dla słowa kluczowego?
Musimy wyraźnie rozróżnić treści ogólne od treści zoptymalizowanych pod kątem wyszukiwania.
Kiedy sztuczna inteligencja jest pozostawiona sama sobie, aby napisać treść, ma tendencję do generowania artykułu, który przemawia do zwykłego czytelnika.
Jednak treść zoptymalizowana pod kątem SEO tańczy do innej melodii.
Google ma tendencję do faworyzowania treści, które można przeskanować, zawiera definicje i niezbędną wiedzę podstawową oraz zasadniczo oferuje czytelnikom wiele haczyków, aby znaleźć odpowiedzi na ich zapytania.
ChatGPT, oparty na architekturze transformatora, ma tendencję do tworzenia treści w oparciu o obserwowaną częstotliwość i wzorce w danych, na których był szkolony. Niewielka część tych danych składa się z najwyżej ocenianych artykułów Google.
W przeciwieństwie do tego, w miarę upływu czasu Google dostosowuje swoje wyniki wyszukiwania do ich skuteczności dla użytkownika – zasadniczo przetrwanie najlepiej dopasowanych fragmentów treści.
Podmioty znalezione w tych trwałych artykułach są niezbędne do naśladowania jako podstawowa treść, która znacznie odbiega od tego, co ChatGPT tworzy od razu po wyjęciu z pudełka.
Kluczowym wnioskiem jest to, że istnieje różnica między treścią, która wygrywa z punktu widzenia czytelności, a treścią, która wygrywa w środowisku Google. W świecie treści internetowych użyteczność jest najważniejsza.
Jak pokazał dawno temu Nielsen, króluje możliwość skanowania.

Użytkownicy wolą skanować treści internetowe niż czytać je od góry do dołu. To zachowanie jest zwykle zgodne ze wzorem w kształcie litery F. Pisanie treści, które dobrze radzą sobie w wyszukiwaniu, powinno koncentrować się na tym, aby można je było łatwo przeskanować, a nie pisać wyłącznie do czytania od góry do dołu.
ChatGPT po wyjęciu z pudełka
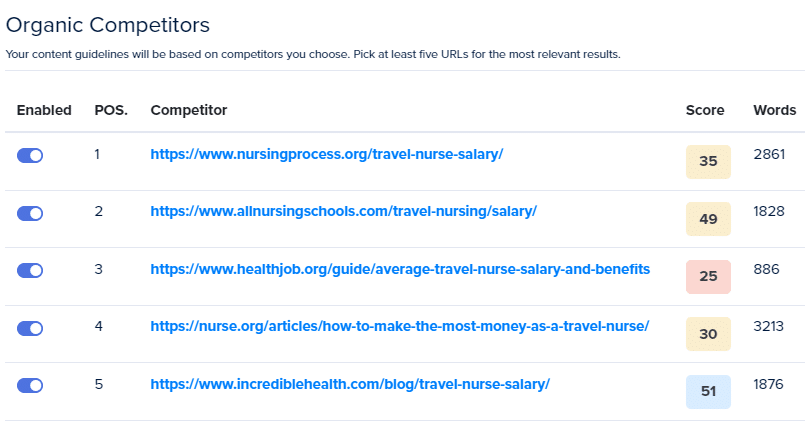
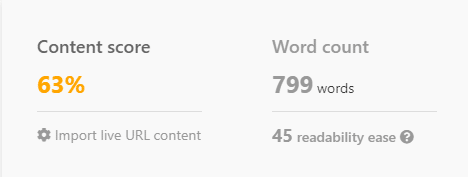
Przyjrzyjmy się, jak ChatGPT działa od razu po wyjęciu z pudełka, używając Noble i Inlinks do punktacji.
Nawet przy skrupulatnie przygotowanym monicie, bez kontekstu tego, co działa na pierwszej stronie Google, ChatGPT często nie trafia w sedno, tworząc treści, które raczej nie będą konkurować.
Poprosiłem ChatGPT o napisanie artykułu na temat „Ile zarabiają pielęgniarki podróżujące na godzinę”.

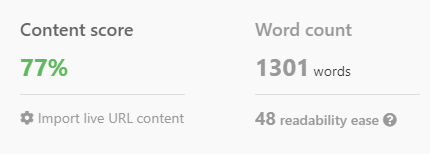
W połączeniu z analizą SEO
Jednak ChatGPT może pokazać swoją prawdziwą moc w połączeniu z analizą SERP i kluczowymi dla rankingu słowami kluczowymi.
Prosząc ChatGPT o uwzględnienie tych warunków, sztuczna inteligencja kieruje się w stronę generowania treści istotnych tematycznie.

Oto kilka ważnych punktów do zapamiętania
Podczas gdy ChatGPT będzie zawierać wiele kluczowych encji związanych z tematem, użycie narzędzi analizujących wyniki SERP może znacznie poprawić mieszankę encji w Twoich treściach.
Ponadto różnice te mogą być bardziej widoczne w zależności od tematu, ale jeśli przeprowadzisz ten eksperyment więcej razy, przekonasz się, że jest to spójny trend.
Podejścia oparte na słowach kluczowych spełniają jednocześnie dwa wymagania:
- Zapewnij włączenie najbardziej krytycznych podmiotów.
- Zapewnij bardziej rygorystyczny system oceniania, ponieważ obejmuje on zarówno predykaty, jak i byty.
Dodatkowe spostrzeżenia
ChatGPT może mieć trudności z samodzielnym osiągnięciem wymaganej długości treści.
Im bardziej intencje strony odbiegają od postów w stylu blogów, tym bardziej zauważalna staje się różnica w wydajności między narzędziami ChatGPT i SEO, które używają ChatGPT oddzielnie.
Pomimo możliwości sztucznej inteligencji, należy pamiętać o czynniku ludzkim. Nie wszystkie strony powinny być analizowane ze względu na mieszane wyniki wyszukiwania.
Ponadto techniki wyodrębniania słów kluczowych nie są niezawodne, a skrajne przypadki mogą dawać nieistotne rzeczowniki własne, które wciąż mogą przejść przez system punktacji.
Dlatego optymalna równowaga między interwencją człowieka a sztuczną inteligencją polega na ręcznym wyłączaniu dowolnej konkurencyjnej witryny o innym przeznaczeniu i przeczesywaniu listy słów kluczowych w celu usunięcia rażąco niewłaściwych słów kluczowych.
Ostatnie kroki: krok dalej
Omówione przez nas metody są punktem wyjścia, umożliwiającym tworzenie treści obejmujących szerszy zakres podmiotów i ich predykatów niż jakakolwiek konkurencja.
Postępując zgodnie z tym podejściem, tworzysz treści, które odzwierciedlają cechy stron, które Google już preferuje.
Ale pamiętaj, to tylko punkt wyjścia. Te konkurencyjne strony prawdopodobnie istnieją już od jakiegoś czasu i mogły zgromadzić więcej linków zwrotnych i wskaźników użytkowników.
Jeśli Twoim celem jest osiągnięcie lepszych wyników, musisz sprawić, by Twoje treści jeszcze bardziej się wyróżniały.
Ponieważ sieć staje się coraz bardziej nasycona treściami generowanymi przez sztuczną inteligencję, uzasadnione jest spekulowanie, że Google może zacząć faworyzować strony internetowe, którym ufa, aby ustanowić nowe relacje między podmiotami. Prawdopodobnie zmieni to sposób oceny treści, kładąc większy nacisk na oryginalne myśli i innowacyjność.
Dla pisarza oznacza to wykroczenie poza zwykłe uwzględnienie tematów objętych 10 najlepszymi wynikami. Zamiast tego zadaj sobie pytanie: jaką unikalną perspektywę możesz zaoferować, której brakuje w obecnej 10 najlepszych?
Nie chodzi tylko o narzędzia. Chodzi o nas, strategów, myślicieli, twórców.
Chodzi o to, jak dzierżymy te narzędzia i jak równoważymy moc obliczeniową oprogramowania z twórczą iskrą ludzkiego umysłu.
Podobnie jak w świecie szachów, to połączenie precyzji maszyny i ludzkiej pomysłowości naprawdę robi różnicę.
Wejdźmy więc w nową erę SEO, w której tworzymy treści i tworzymy doświadczenia, które rezonują z naszymi odbiorcami i wyróżniają się w rozległym cyfrowym krajobrazie.
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.