
Przewodnik po diagnozowaniu typowych problemów z SEO JavaScript
Opublikowany: 2023-07-10Bądźmy szczerzy, JavaScript i SEO nie zawsze dobrze ze sobą współpracują. Dla niektórych SEO temat może wydawać się owiany zasłoną złożoności.
Cóż, dobra wiadomość: kiedy zdejmiesz warstwy, wiele problemów SEO opartych na JavaScript wraca do podstaw interakcji robotów wyszukiwarek z JavaScriptem.
Więc jeśli rozumiesz te podstawy, możesz zagłębiać się w problemy, rozumieć ich wpływ i współpracować z programistami, aby naprawić te, które mają znaczenie.
W tym artykule pomożemy zdiagnozować niektóre typowe problemy, gdy witryny są zbudowane na platformach JS. Ponadto podzielimy się podstawową wiedzą, której potrzebuje każdy techniczny SEO, jeśli chodzi o renderowanie.
Renderowanie w skrócie
Zanim przejdziemy do bardziej szczegółowych rzeczy, porozmawiajmy o dużym obrazie.
Aby wyszukiwarka mogła zrozumieć treść obsługiwaną przez JavaScript, musi zaindeksować i wyrenderować stronę.
Problem polega na tym, że wyszukiwarki mają tylko określoną liczbę zasobów do wykorzystania, więc muszą być selektywne, kiedy warto z nich korzystać. Nie jest pewne, że strona zostanie wyrenderowana, nawet jeśli robot indeksujący wyśle ją do kolejki renderowania.
Jeśli zdecyduje się nie renderować strony lub nie może prawidłowo renderować treści, może to stanowić problem.
Wszystko sprowadza się do tego, w jaki sposób front-end obsługuje HTML w początkowej odpowiedzi serwera.
Gdy adres URL jest tworzony w przeglądarce, interfejs taki jak React, Vue lub Gatsby wygeneruje kod HTML strony. Robot indeksujący sprawdza, czy ten kod HTML jest już dostępny z serwera („wstępnie wyrenderowany” kod HTML), zanim wyśle adres URL, aby czekał na renderowanie, aby mógł przejrzeć wynikową treść.
Dostępność wstępnie wyrenderowanego kodu HTML zależy od konfiguracji interfejsu użytkownika. Wygeneruje kod HTML za pośrednictwem serwera lub przeglądarki klienta.
Renderowanie po stronie serwera
Nazwa mówi wszystko. W konfiguracji SSR robot otrzymuje w pełni wyrenderowaną stronę HTML bez konieczności wykonywania i renderowania dodatkowego kodu JS.
Więc nawet jeśli strona nie jest renderowana, wyszukiwarka może nadal indeksować dowolny kod HTML, kontekstualizować stronę (metadane, kopie, obrazy) i rozumieć jej relacje z innymi stronami (bułka tarta, kanoniczny adres URL, linki wewnętrzne).
Renderowanie po stronie klienta
W CSR kod HTML jest generowany w przeglądarce wraz ze wszystkimi komponentami JavaScript. JavaScript wymaga renderowania, zanim kod HTML będzie dostępny do indeksowania.
Jeśli usługa renderowania zdecyduje się nie renderować strony przesłanej do kolejki, kopie, wewnętrzne adresy URL, łącza do obrazów, a nawet metadane pozostaną niedostępne dla robotów indeksujących.
W rezultacie wyszukiwarki mają niewiele kontekstu lub nie mają go wcale, aby zrozumieć znaczenie adresu URL dla wyszukiwanych haseł.
Uwaga : w początkowej odpowiedzi HTML można podać połączenie kodu HTML, a także kod HTML, który wymaga wykonania kodu JS w celu wyrenderowania (wyświetlenia). Zależy to od kilku czynników, z których najpowszechniejsze to framework, sposób budowy poszczególnych komponentów witryny oraz konfiguracja serwera.
Zestaw narzędzi SEO JavaScript
Z pewnością istnieją narzędzia, które pomogą zidentyfikować problemy SEO związane z JavaScript.
Możesz przeprowadzić wiele dochodzeń za pomocą narzędzi przeglądarki i Google Search Console. Oto krótka lista, która tworzy solidny zestaw narzędzi:
- Wyświetl źródło: kliknij prawym przyciskiem myszy stronę i kliknij „wyświetl źródło”, aby zobaczyć wstępnie wyrenderowany kod HTML strony (początkowa odpowiedź serwera).
- Przetestuj aktywny adres URL (inspekcja adresów URL): wyświetl zrzut ekranu, kod HTML i inne ważne szczegóły renderowanej strony na karcie inspekcji adresów URL w Google Search Console. (Wiele problemów z renderowaniem można znaleźć, porównując wstępnie wyrenderowany kod HTML z „źródła widoku” z wyrenderowanym kodem HTML z testowania aktywnego adresu URL w GSC).
- Narzędzia dla programistów Chrome: kliknij prawym przyciskiem myszy stronę i wybierz „Sprawdź”, aby otworzyć narzędzia do przeglądania błędów JavaScript i nie tylko.
- Wappalyzer: zobacz stos, na którym zbudowana jest dowolna witryna, i uzyskaj szczegółowe informacje na temat frameworka, instalując to bezpłatne rozszerzenie Chrome.
Typowe problemy z SEO JavaScript
Problem 1: Wstępnie renderowany kod HTML jest powszechnie niedostępny
Oprócz wspomnianych wcześniej negatywnych implikacji dla indeksowania i kontekstualizacji, istnieje również kwestia czasu i zasobów potrzebnych wyszukiwarce do wyrenderowania strony.
Jeśli robot indeksujący zdecyduje się poddać adres URL procesowi renderowania, trafi on do kolejki renderowania. Dzieje się tak, ponieważ robot indeksujący może wyczuć rozbieżność między wstępnie wyrenderowaną i wyrenderowaną strukturą HTML. (Co ma sens, jeśli nie ma wstępnie wyrenderowanego kodu HTML!)
Nie ma gwarancji, jak długo adres URL czeka na usługę renderowania sieci. Najlepszym sposobem na zachęcenie WRS do terminowego renderowania jest upewnienie się, że na stronie znajdują się kluczowe sygnały autorytetu ilustrujące znaczenie adresu URL (np. link w górnej nawigacji, wiele linków wewnętrznych, określanych jako kanoniczne). To trochę się komplikuje, ponieważ sygnały autoryzacji również muszą zostać przeszukane.
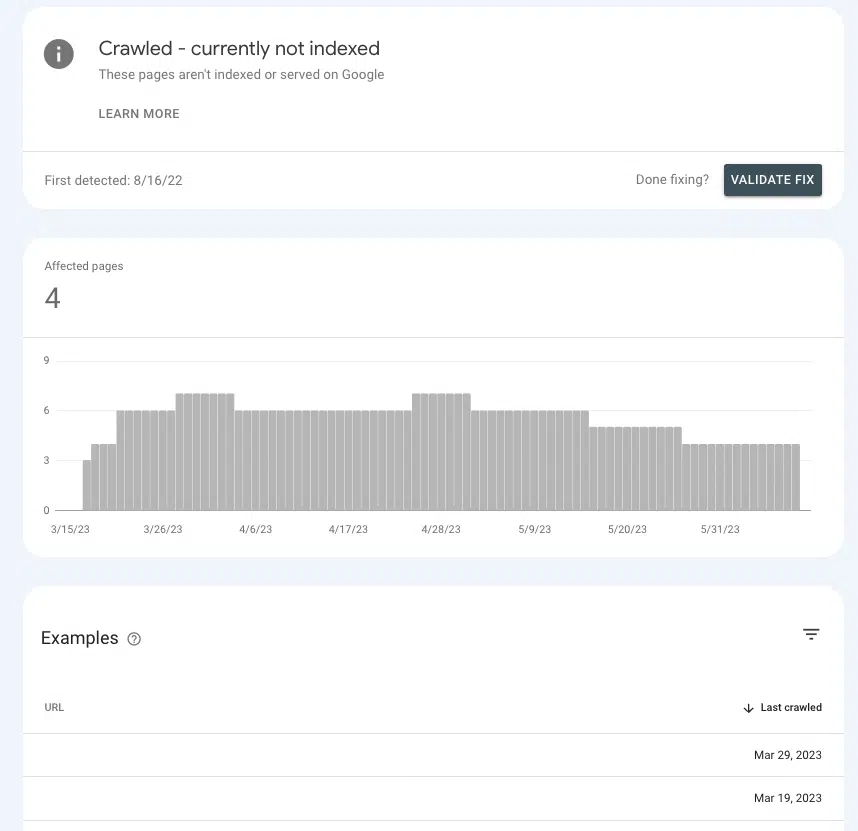
W Google Search Console można zorientować się, czy wysyłasz właściwe sygnały autorytatywne do kluczowych stron, czy też powodujesz, że siedzą w zawieszeniu.
Przejdź do Strony > Indeksowanie stron > Zindeksowane — obecnie nieindeksowane i poszukaj na liście obecności stron priorytetowych.
Jeśli znajdują się w poczekalni, to dlatego, że Google nie może ustalić, czy są wystarczająco ważne, aby wydać na nie zasoby.
Najczęstsze przyczyny
Ustawienia domyślne
Najpopularniejsze interfejsy są gotowe do renderowania po stronie klienta, więc istnieje spora szansa, że winne są ustawienia domyślne.
Jeśli zastanawiasz się, dlaczego większość frontendów domyślnie korzysta z CSR, dzieje się tak z powodu korzyści związanych z wydajnością. Deweloperzy nie zawsze kochają SSR, ponieważ może to ograniczać możliwości przyspieszenia witryny i implementacji niektórych elementów interaktywnych (np. unikalnych przejść między stronami).
Aplikacja jednostronicowa
Jeśli witryna jest aplikacją jednostronicową, jest całkowicie opakowana w JavaScript i generuje wszystkie komponenty strony w przeglądarce (inaczej wszystko) jest renderowane po stronie klienta, a nowe strony są obsługiwane bez ponownego ładowania).
Ma to pewne negatywne implikacje, z których być może najważniejszą jest to, że strony są potencjalnie nie do wykrycia.
Nie oznacza to, że niemożliwe jest skonfigurowanie SPA w sposób bardziej przyjazny dla SEO. Ale są szanse, że będzie potrzebna znacząca praca programistów, aby to się stało.
Problem 2: Niektóre treści strony są niedostępne dla robotów indeksujących
Pozyskanie wyszukiwarki do renderowania adresu URL jest świetne, o ile wszystkie elementy są dostępne do indeksowania. Co się stanie, jeśli renderuje stronę, ale niektóre sekcje strony są niedostępne?
Na przykład SEO przeprowadza analizę linków wewnętrznych i znajduje niewiele lub nie znajduje żadnych linków wewnętrznych zgłoszonych dla adresu URL, do którego prowadzą odnośniki na kilku stronach.
Jeśli link nie pojawia się w wyrenderowanym kodzie HTML z narzędzia Testuj aktywny adres URL, prawdopodobnie jest wyświetlany w zasobach JavaScript, do których Google nie ma dostępu.
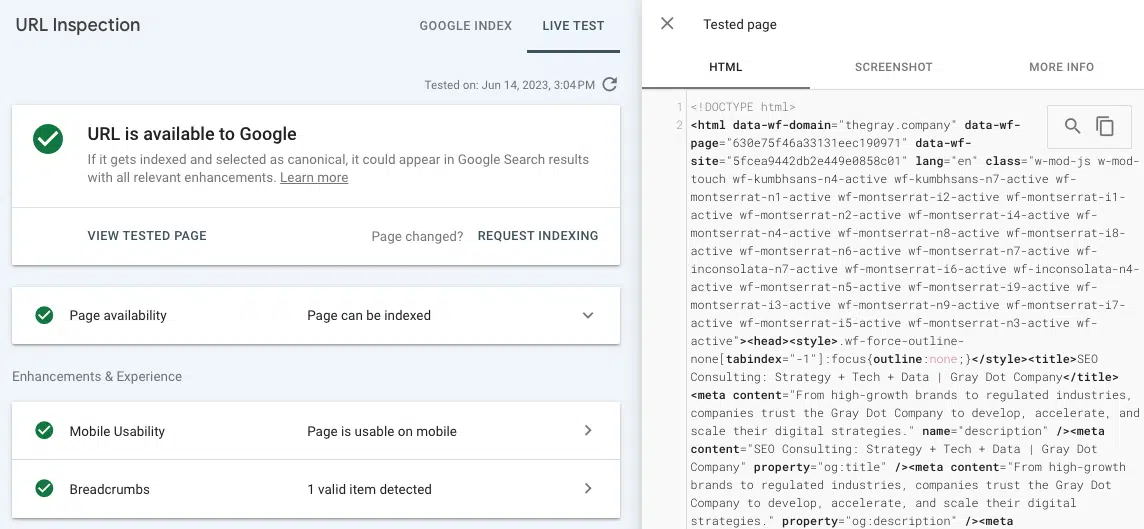
Aby zawęzić winowajcę, dobrze byłoby poszukać podobieństw pod względem tego, gdzie brakująca treść strony lub linki wewnętrzne znajdują się na stronie w różnych adresach URL.
Na przykład, jeśli jest to łącze FAQ, które pojawia się w tej samej sekcji na każdej stronie produktu, znacznie ułatwia to programistom zawężenie poprawki.
Najczęstsze przyczyny
Błędy JavaScript
Zacznijmy tutaj od zastrzeżenia. Większość napotkanych błędów JavaScript nie ma znaczenia dla SEO.
Jeśli więc wybierzesz się na poszukiwanie błędów, zaniesiesz swojemu programiście długą listę i zaczniesz rozmowę od „Co to za błędy?”, może nie odebrać jej tak dobrze.
Podejdź z „dlaczego”, rozmawiając z problemem, aby mogli być ekspertami JavaScript (bo są!).
Biorąc to pod uwagę, istnieją błędy składniowe, które mogą uniemożliwić analizę reszty strony (np. „blokowanie renderowania”). Gdy tak się stanie, moduł renderujący nie może wyodrębnić poszczególnych elementów HTML, ustrukturyzować treści w modelu DOM ani zrozumieć relacji.
Ogólnie rzecz biorąc, tego typu błędy są rozpoznawalne, ponieważ mają również pewien wpływ na widok przeglądarki.
Oprócz potwierdzenia wizualnego błędy JavaScript można również wyświetlić, klikając stronę prawym przyciskiem myszy, wybierając opcję „sprawdź” i przechodząc do karty „Konsola”.
Otrzymuj codzienny biuletyn wyszukiwania, na którym polegają marketerzy.
Zobacz warunki.
Treść wymaga interakcji użytkownika
Jedną z najważniejszych rzeczy, o których należy pamiętać podczas renderowania, jest to, że Google nie może renderować żadnych treści, które wymagają od użytkowników interakcji ze stroną. Lub, mówiąc prościej, nie może „klikać” rzeczy.

Dlaczego to ma znaczenie? Pomyśl o naszym starym, zaufanym przyjacielu, rozwijanym akordeonie io tym, ile witryn używa go do organizowania treści, takich jak szczegółowe informacje o produktach i często zadawane pytania.
W zależności od sposobu zakodowania akordeonu Google może nie być w stanie wyrenderować zawartości listy rozwijanej, jeśli nie zostanie ona wypełniona do czasu wykonania JS.
Aby to sprawdzić, możesz „zbadać” stronę i zobaczyć, czy „ukryta” treść (co pojawia się po kliknięciu akordeonu) znajduje się w kodzie HTML.
Jeśli tak nie jest, oznacza to, że Googlebot i inne roboty indeksujące nie widzą tej treści w wyrenderowanej wersji strony.
Problem 3: Sekcje witryny nie są indeksowane
Google może, ale nie musi, renderować Twoją stronę, jeśli ją zaindeksuje i wyśle do kolejki. Jeśli strona nie zostanie zaindeksowana, nawet ta okazja jest nieważna.
Aby dowiedzieć się, czy Google indeksuje strony, przydatny może być raport Statystyki indeksowania Ustawienia > Statystyki indeksowania .
Wybierz Żądania indeksowania: OK (200), aby zobaczyć wszystkie wystąpienia indeksowania 200 stron stanu w ciągu ostatnich trzech miesięcy. Następnie użyj filtrowania, aby wyszukać pojedyncze adresy URL lub całe katalogi.
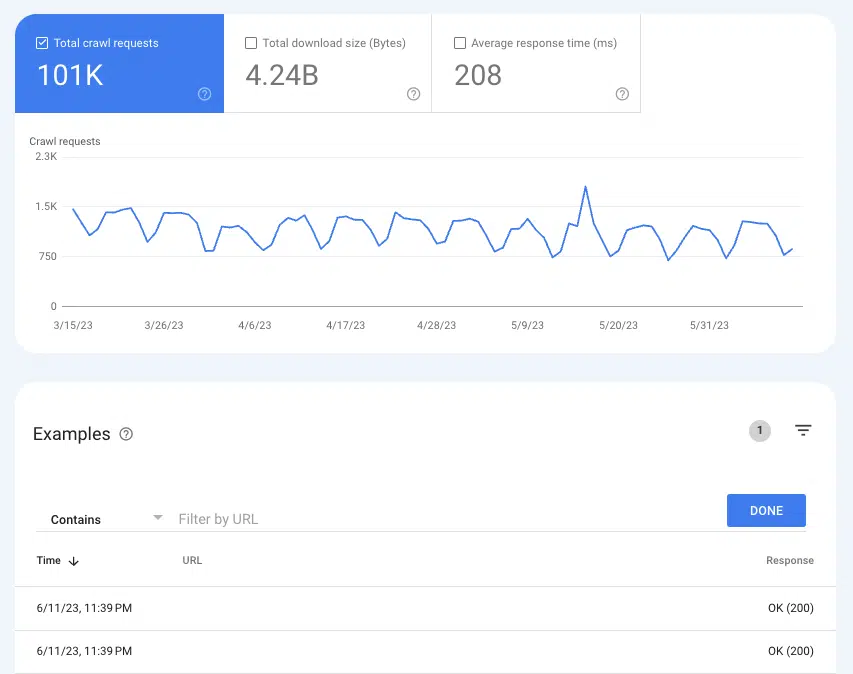
Jeśli adresy URL nie pojawiają się w dziennikach indeksowania, istnieje duże prawdopodobieństwo, że Google nie może wykryć stron i ich zaindeksować (lub nie jest to 200 stron, co jest zupełnie innym problemem).
Najczęstsze przyczyny
Linków wewnętrznych nie można indeksować
Linki to znaki drogowe, którymi roboty indeksujące podążają do nowych stron. To jeden z powodów, dla których strony osierocone są tak dużym problemem.
Jeśli masz witrynę z dobrymi linkami i podczas kontroli witryny pojawiają się strony osierocone, istnieje duża szansa, że dzieje się tak dlatego, że linki nie są dostępne w wstępnie wyrenderowanym kodzie HTML.
Łatwym sposobem sprawdzenia jest przejście do adresu URL prowadzącego do zgłoszonej strony osieroconej. Kliknij stronę prawym przyciskiem myszy i kliknij „wyświetl źródło”.
Następnie użyj CMD + f, aby wyszukać adres URL strony osieroconej. Jeśli nie pojawia się we wstępnie wyrenderowanym kodzie HTML, ale pojawia się na stronie podczas renderowania w przeglądarce, przejdź od razu do numeru czwartego.
Mapa witryny XML nie została zaktualizowana
Mapa witryny XML ma kluczowe znaczenie dla pomocy Google w odkrywaniu nowych stron i ustalaniu, którym adresom URL nadać priorytet podczas indeksowania.
Bez mapy witryny XML odnajdywanie stron jest możliwe tylko za pomocą linków.
Tak więc w przypadku witryn bez wstępnie wyrenderowanego kodu HTML przestarzała lub brakująca mapa witryny oznacza czekanie, aż Google wyrenderuje strony, skorzysta z wewnętrznych linków do innych stron, ustawi je w kolejce, wyrenderuje, skorzysta z ich linków itd.
W zależności od używanego interfejsu użytkownika możesz mieć dostęp do wtyczek, które mogą tworzyć dynamiczne mapy witryn XML.
Często wymagają dostosowania, dlatego ważne jest, aby specjaliści ds. SEO skrupulatnie dokumentowali wszelkie adresy URL, które nie powinny znajdować się w mapie witryny, oraz logikę wyjaśniającą, dlaczego tak się dzieje.
Powinno to być stosunkowo łatwe do zweryfikowania, uruchamiając mapę witryny za pomocą ulubionego narzędzia SEO.
Problem 4: Brakuje linków wewnętrznych
Niedostępność wewnętrznych linków do robotów indeksujących to nie tylko potencjalny problem z wykrywaniem, ale także problem z kapitałem własnym. Ponieważ linki przekazują wartość SEO z referencyjnego adresu URL do docelowego adresu URL, są ważnym czynnikiem zwiększania zarówno autorytetu strony, jak i domeny.
Świetnym przykładem są linki ze strony głównej. Jest to zazwyczaj najbardziej autorytatywna strona w witrynie internetowej, więc link do innej strony ze strony głównej ma dużą wagę.
Jeśli tych linków nie można zindeksować, to trochę tak, jakbyś miał zepsuty miecz świetlny. Jedno z najpotężniejszych narzędzi staje się bezużyteczne (zamierzona gra słów).
Najczęstsze przyczyny
Aby uzyskać dostęp do linku, wymagana jest interakcja użytkownika
Przykład akordeonu, którego użyliśmy wcześniej, to tylko jeden przypadek, w którym treść jest ukryta za interakcją użytkownika. Innym, który może mieć szerokie implikacje, jest paginacja z nieskończonym przewijaniem – szczególnie w przypadku witryn e-commerce z obszernymi katalogami produktów.
W konfiguracji z nieskończonym przewijaniem niezliczone produkty na stronie z listą produktów (kategorią) nie ładują się, chyba że użytkownik przewinie poza określony punkt (leniwe ładowanie) lub kliknie przycisk „pokaż więcej”.
Więc nawet jeśli JavaScript jest renderowany, robot indeksujący nie może uzyskać dostępu do wewnętrznych linków do produktów, które jeszcze nie zostały załadowane. Jednak ładowanie wszystkich tych produktów na jednej stronie negatywnie wpłynęłoby na wygodę użytkownika ze względu na słabą wydajność strony.
Z tego powodu specjaliści ds. SEO na ogół preferują prawdziwą paginację, w której każda strona wyników ma odrębny, możliwy do indeksowania adres URL.
Witryna może optymalizować ładowanie z opóźnieniem i dodawać wszystkie produkty do wstępnie wyrenderowanego kodu HTML, ale może to prowadzić do różnic między wyrenderowanym i wstępnie wyrenderowanym kodem HTML.
W rzeczywistości stwarza to powód do wysyłania większej liczby stron do kolejki renderowania i zmuszania robotów indeksujących do cięższej pracy niż jest to konieczne – a wiemy, że nie jest to dobre dla SEO.
Jako minimum postępuj zgodnie z zaleceniami Google dotyczącymi optymalizacji nieskończonego przewijania.
Linki nieprawidłowo zakodowane
Gdy Google indeksuje witrynę lub renderuje adres URL w kolejce, pobiera bezstanową wersję strony. To w dużej mierze powód, dla którego tak ważne jest używanie odpowiednich tagów href i kotwic (struktura łącząca, którą widzisz najczęściej). Robot indeksujący nie może śledzić formatów linków, takich jak router, span lub onClick.
Może śledzić:
- <a href="https://example.com">
- <a href="/względna/ścieżka/plik">
Nie można obserwować:
- <a routerLink="jakiś/ścieżka">
- <span href="https://example.com">
- <a>
Dla celów programisty są to prawidłowe sposoby kodowania łączy. Implikacje SEO to dodatkowa warstwa kontekstu, a ich zadaniem nie jest wiedzieć – to SEO.
Ogromną częścią pracy dobrego SEO jest zapewnienie programistom tego kontekstu poprzez dokumentację.
Problem 5: brakuje metadanych
Na stronie HTML metadane, takie jak tytuł, opis, kanoniczny adres URL i metatag robots, są zagnieżdżone w nagłówku.
Z oczywistych powodów brak metadanych jest szkodliwy dla SEO, ale jeszcze bardziej dla SPA. Elementy takie jak kanoniczny adres URL odnoszący się do samego siebie są kluczowe dla zwiększenia szans strony JS na pomyślne przejście przez kolejkę renderowania.
Spośród wszystkich elementów, które powinny być obecne w prerenderowanym kodzie HTML, głowa jest najważniejsza dla indeksacji.
Na szczęście ten problem jest dość łatwy do wykrycia, ponieważ spowoduje mnóstwo błędów związanych z brakującymi metadanymi w dowolnym narzędziu SEO używanym przez witrynę do raportowania higieny. Następnie możesz potwierdzić, szukając nagłówka w kodzie źródłowym.
Najczęstsze przyczyny
Brak lub źle skonfigurowany nośnik metadanych
W środowisku JS wtyczka tworzy nagłówek i wstawia do niego metadane. (Najbardziej popularnym przykładem jest React Helmet.) Nawet jeśli wtyczka jest już zainstalowana, zwykle wymaga poprawnej konfiguracji.
Ponownie, jest to obszar, w którym wszystko, co mogą zrobić SEO, to zgłosić problem programiście, wyjaśnić dlaczego i ściśle współpracować w kierunku dobrze udokumentowanych kryteriów akceptacji.
Problem 6: Zasoby nie są indeksowane
Pliki skryptów i obrazy są podstawowymi elementami składowymi w procesie renderowania.
Ponieważ mają one również własne adresy URL, dotyczą ich również prawa indeksowania. Jeśli indeksowanie plików jest zablokowane, Google nie może przeanalizować strony, aby ją wyrenderować.
Aby sprawdzić, czy adresy URL są indeksowane, możesz wyświetlić wcześniejsze żądania w Statystykach indeksowania GSC.
- Obrazy: przejdź do Ustawienia > Statystyki indeksowania > Żądania indeksowania: obraz
- JavaScript: przejdź do Ustawienia > Statystyki indeksowania > Żądania indeksowania: obraz
Najczęstsze przyczyny
Katalog zablokowany przez plik robots.txt
Adresy URL zarówno skryptów, jak i obrazów są zwykle zagnieżdżone we własnej dedykowanej subdomenie lub podfolderze, więc wyrażenie disallow w pliku robots.txt uniemożliwi indeksowanie.
Niektóre narzędzia SEO poinformują Cię, czy jakiekolwiek pliki skryptów lub obrazów są zablokowane, ale problem jest dość łatwy do wykrycia, jeśli wiesz, gdzie są zagnieżdżone Twoje obrazy i pliki skryptów. Możesz poszukać tych struktur adresów URL w pliku robots.txt.
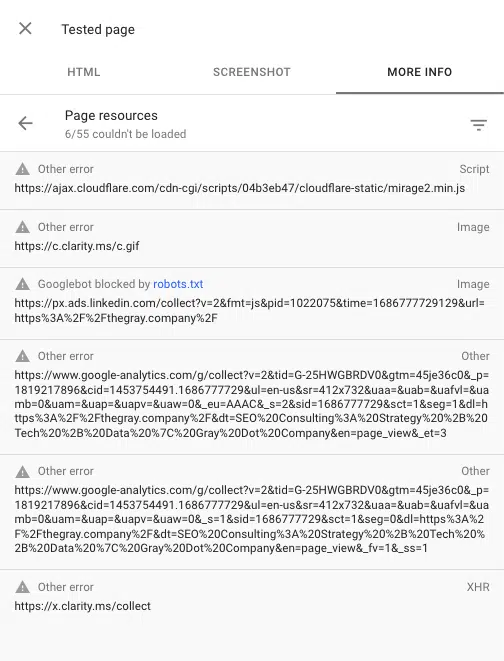
Możesz także zobaczyć wszelkie skrypty zablokowane podczas renderowania strony za pomocą narzędzia do sprawdzania adresów URL w Google Search Console. „Przetestuj aktywny adres URL”, a następnie przejdź do Wyświetl przetestowaną stronę > Więcej informacji > Zasoby strony .
Tutaj możesz zobaczyć wszystkie skrypty, które nie ładują się podczas procesu renderowania. Jeśli plik zostanie zablokowany przez robots.txt, zostanie oznaczony jako taki.
Zaprzyjaźnij się z JavaScriptem
Tak, JavaScript może wiązać się z pewnymi problemami z SEO. Jednak w miarę ewolucji SEO najlepsze praktyki stają się synonimem doskonałego doświadczenia użytkownika.
Doskonałe wrażenia użytkownika często zależą od JavaScript. Tak więc, chociaż zadaniem SEO nie jest kodowanie JavaScript, musimy wiedzieć, w jaki sposób wyszukiwarki wchodzą w interakcje, renderują i używają go.
Dzięki solidnemu zrozumieniu procesu renderowania i niektórych typowych problemów SEO w frameworkach JS jesteś na dobrej drodze do zidentyfikowania problemów i bycia potężnym sprzymierzeńcem swoich programistów.
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.