
Entity SEO: ostateczny przewodnik
Opublikowany: 2023-04-06Ten artykuł został współautorem Andrew Ansleya .
Rzeczy, nie sznurki. Jeśli nie słyszałeś tego wcześniej, pochodzi to ze słynnego posta na blogu Google, który ogłosił Graf wiedzy.
11. rocznica ogłoszenia jest już za miesiąc, ale wielu wciąż nie rozumie, co tak naprawdę oznacza „rzeczy, a nie łańcuchy” dla SEO.
Cytat jest próbą przekazania, że Google rozumie rzeczy i nie jest już prostym algorytmem wykrywania słów kluczowych.
W maju 2012 roku można by argumentować, że narodził się podmiot SEO. Uczenie maszynowe Google, wspomagane przez częściowo ustrukturyzowane i ustrukturyzowane bazy wiedzy, może zrozumieć znaczenie słowa kluczowego.
Dwuznaczna natura języka w końcu znalazła długoterminowe rozwiązanie.
Więc jeśli byty były ważne dla Google od ponad dekady, dlaczego SEO wciąż nie rozumieją bytów?
Dobre pytanie. Widzę cztery powody:
- Entity SEO jako termin nie był używany na tyle szeroko, aby specjaliści SEO przyzwyczaili się do jego definicji i dlatego włączyli go do swojego słownictwa.
- Optymalizacja pod kątem jednostek w dużym stopniu pokrywa się ze starymi metodami optymalizacji skoncentrowanymi na słowach kluczowych. W rezultacie jednostki są mylone ze słowami kluczowymi. Ponadto nie było jasne, w jaki sposób podmioty odgrywają rolę w SEO, a słowo „podmioty” jest czasami używane zamiennie z „tematami”, gdy Google wypowiada się na ten temat.
- Zrozumienie bytów to nudne zadanie. Jeśli chcesz mieć głęboką wiedzę na temat bytów, musisz przeczytać kilka patentów Google i poznać podstawy uczenia maszynowego. Entity SEO to znacznie bardziej naukowe podejście do SEO – a nauka po prostu nie jest dla wszystkich.
- Chociaż YouTube wywarł ogromny wpływ na dystrybucję wiedzy, spłaszczył sposób uczenia się wielu przedmiotów. Twórcy, którzy odnieśli największe sukcesy na platformie, historycznie wybierali łatwą drogę edukowania swoich odbiorców. W rezultacie twórcy treści do niedawna nie poświęcali zbyt wiele czasu podmiotom. Z tego powodu musisz dowiedzieć się o podmiotach od badaczy NLP, a następnie zastosować tę wiedzę w SEO. Kluczowe znaczenie mają patenty i prace badawcze. Po raz kolejny potwierdza to pierwszy punkt powyżej.
Ten artykuł jest rozwiązaniem wszystkich czterech problemów, które uniemożliwiły SEO-m pełne opanowanie podejścia do SEO opartego na jednostkach.
Czytając to dowiesz się:
- Czym jest podmiot i dlaczego jest ważny.
- Historia wyszukiwania semantycznego.
- Jak identyfikować i wykorzystywać podmioty w SERP.
- Jak używać encji do oceniania treści internetowych.
Dlaczego podmioty są ważne?
Entity SEO to przyszłość, do której zmierzają wyszukiwarki, jeśli chodzi o wybór treści do uszeregowania i określenie jej znaczenia.
Połącz to z zaufaniem opartym na wiedzy i wierzę, że SEO podmiotów będzie przyszłością tego, jak SEO jest wykonywane w ciągu najbliższych dwóch lat.
Przykłady podmiotów
Jak więc rozpoznać podmiot?
SERP zawiera kilka przykładów jednostek, które prawdopodobnie widziałeś.
Najpopularniejsze typy encji są związane z lokalizacjami, osobami lub firmami.
Być może najlepszym przykładem encji w SERP są klastry intencji. Im lepiej temat jest rozumiany, tym częściej pojawiają się te funkcje wyszukiwania.
Co ciekawe, pojedyncza kampania SEO może zmienić oblicze SERP, jeśli wiesz, jak przeprowadzić kampanie SEO skoncentrowane na jednostkach.
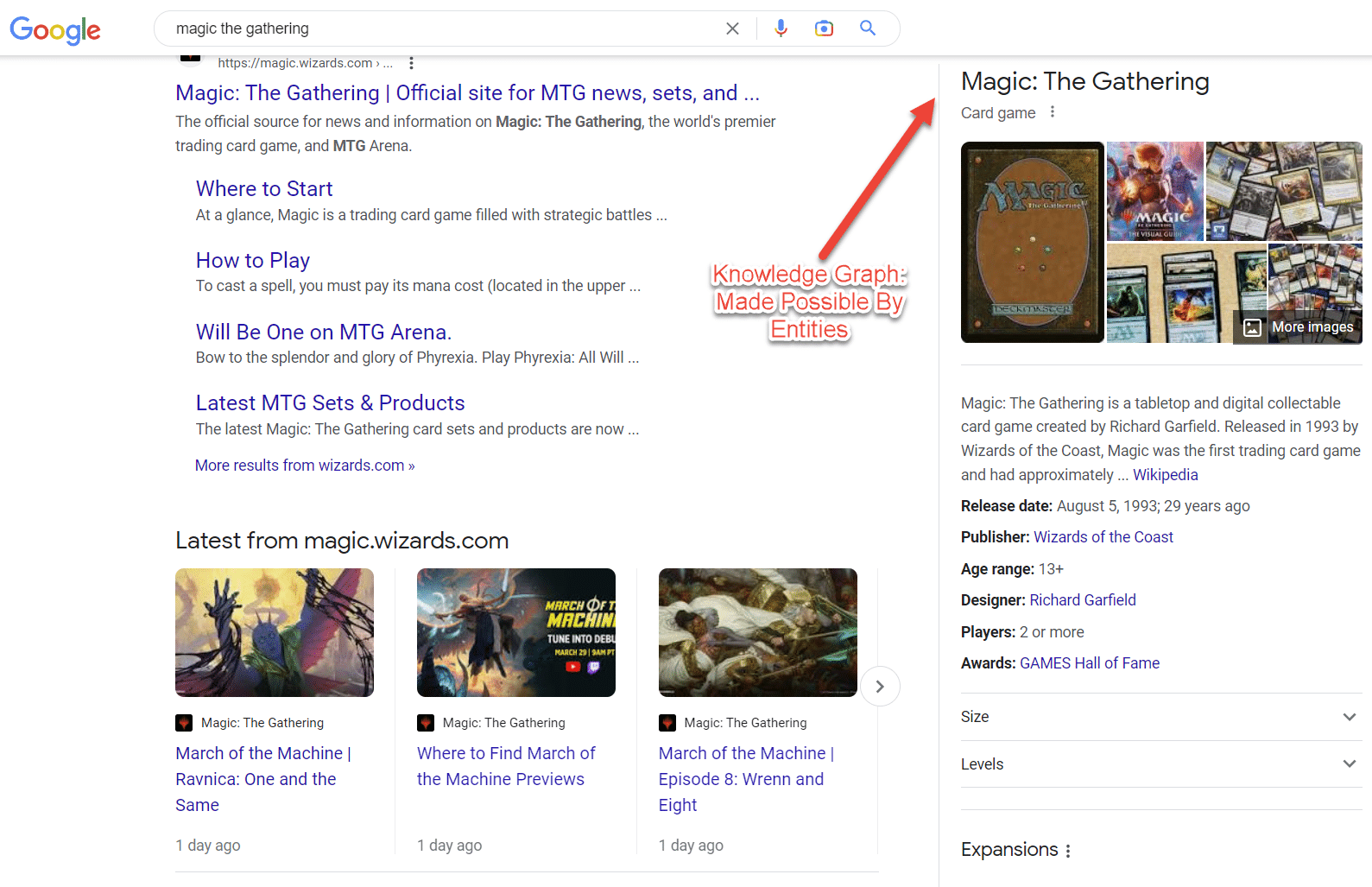
Wpisy w Wikipedii to kolejny przykład podmiotów. Wikipedia zapewnia doskonały przykład informacji związanych z bytami.
Jak widać w lewym górnym rogu, istota ma wiele atrybutów związanych z „rybą”, począwszy od anatomii, a skończywszy na znaczeniu dla ludzi.
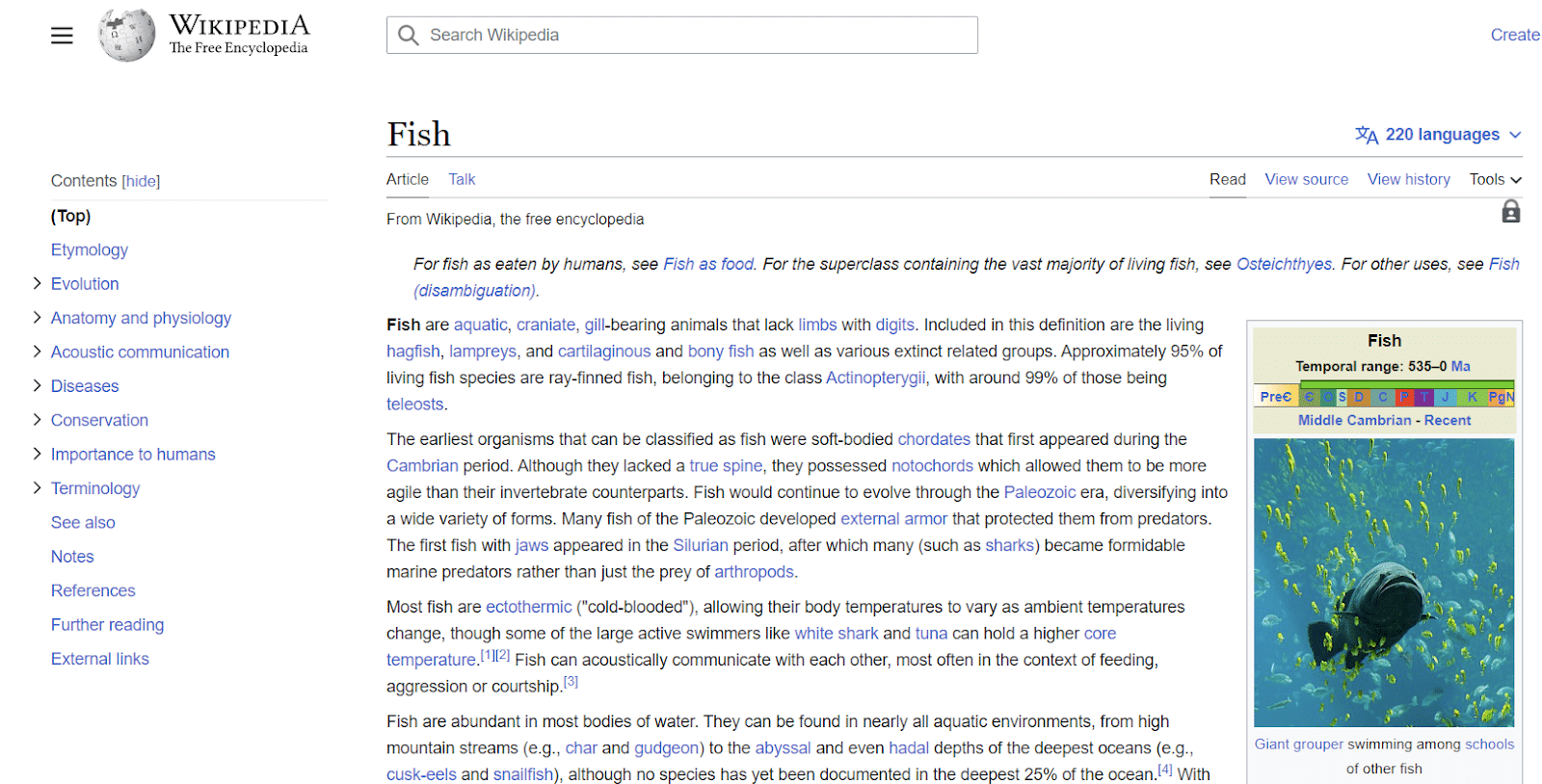
Chociaż Wikipedia zawiera wiele punktów danych na dany temat, w żadnym wypadku nie jest wyczerpująca.
Co to jest podmiot?
Jednostka to jednoznacznie identyfikowalny obiekt lub rzecz charakteryzująca się nazwą (nazwami), typem (typami), atrybutami i relacjami z innymi jednostkami. Uznaje się, że jednostka istnieje tylko wtedy, gdy istnieje w katalogu jednostek.
Katalogi jednostek przypisują każdemu podmiotowi unikalny identyfikator. Moja agencja ma rozwiązania zautomatyzowane, które wykorzystują unikalny identyfikator powiązany z każdym podmiotem (usługi, produkty i marki są uwzględnione).
Jeśli słowo lub fraza nie znajduje się w istniejącym katalogu, nie oznacza to, że słowo lub fraza nie jest jednostką, ale zazwyczaj można stwierdzić, czy coś jest jednostką, po jej istnieniu w katalogu.
Należy zauważyć, że Wikipedia nie decyduje o tym, czy coś jest bytem, ale firma jest najbardziej znana ze swojej bazy danych podmiotów.
Mówiąc o podmiotach, można użyć dowolnego katalogu. Zazwyczaj jednostka to osoba, miejsce lub rzecz, ale można również uwzględnić idee i koncepcje.
Niektóre przykłady katalogów jednostek obejmują:
- Wikipedii
- Wikidane
- DBpedia
- Wolna baza
- Jago

Jednostki pomagają wypełnić lukę między światem danych nieustrukturyzowanych i ustrukturyzowanych.
Można ich używać do semantycznego wzbogacania nieustrukturyzowanego tekstu, podczas gdy źródła tekstowe mogą być wykorzystywane do wypełniania ustrukturyzowanych baz wiedzy.
Rozpoznawanie wzmianek o jednostkach w tekście i kojarzenie tych wzmianek z odpowiednimi wpisami w bazie wiedzy jest znane jako zadanie łączenia jednostek.
Encje pozwalają na lepsze zrozumienie znaczenia tekstu, zarówno dla ludzi, jak i dla maszyn.
Podczas gdy ludzie mogą stosunkowo łatwo rozwiązać niejednoznaczność bytów na podstawie kontekstu, w którym są wymienione, stwarza to wiele trudności i wyzwań dla maszyn.
Wpis bazy wiedzy dotyczący podmiotu podsumowuje naszą wiedzę o tym obiekcie.
Ponieważ świat nieustannie się zmienia, pojawiają się nowe fakty. Nadążanie za tymi zmianami wymaga ciągłego wysiłku ze strony redaktorów i menedżerów treści. Jest to wymagające zadanie na dużą skalę.
Analizując treść dokumentów, w których pojawiają się podmioty, można wspomóc lub nawet w pełni zautomatyzować proces znajdowania nowych faktów lub faktów wymagających aktualizacji.
Naukowcy nazywają to problemem populacji baz wiedzy, dlatego ważne jest łączenie jednostek.
Encje ułatwiają semantyczne zrozumienie potrzeb informacyjnych użytkownika, wyrażonych przez zapytanie kluczowe, oraz treści dokumentu. W ten sposób jednostki mogą być używane do ulepszania reprezentacji zapytań i/lub dokumentów.
W artykule badawczym Extended Named Entity autor identyfikuje około 160 typów jednostek. Oto dwa z siedmiu zrzutów ekranu z listy.


Pewne kategorie jednostek są łatwiejsze do zdefiniowania, ale ważne jest, aby pamiętać, że koncepcje i idee są jednostkami. Te dwie kategorie są bardzo trudne do samodzielnego skalowania przez Google.
Nie możesz uczyć Google tylko jednej strony, gdy pracujesz z niejasnymi pojęciami. Zrozumienie jednostki wymaga wielu artykułów i wielu odniesień utrzymywanych w czasie.
Historia Google z podmiotami
16 lipca 2010 r. firma Google kupiła Freebase. Ten zakup był pierwszym ważnym krokiem, który doprowadził do obecnego systemu wyszukiwania podmiotów.

Po zainwestowaniu we Freebase, Google zdał sobie sprawę, że Wikidata ma lepsze rozwiązanie. Następnie Google pracowało nad połączeniem Freebase z Wikidata, co było zadaniem znacznie trudniejszym niż oczekiwano.
Pięciu naukowców Google napisało artykuł zatytułowany „From Freebase to Wikidata: The Great Migration”. Kluczowe dania na wynos obejmują.
„Freebase opiera się na pojęciach obiektów, faktów, typów i właściwości. Każdy obiekt Freebase ma stabilny identyfikator zwany „mid” (dla identyfikatora maszyny).”
„Model danych Wikidanych opiera się na pojęciach elementu i oświadczenia. Element reprezentuje jednostkę, ma stały identyfikator o nazwie „qid” i może mieć etykiety, opisy i aliasy w wielu językach; dalsze wypowiedzi i linki do stron o podmiocie w innych projektach Wikimedia – przede wszystkim w Wikipedii. W przeciwieństwie do Freebase, oświadczenia Wikidata nie mają na celu zakodowania prawdziwych faktów, ale twierdzeń z różnych źródeł, które również mogą być ze sobą sprzeczne…”
Jednostki są definiowane w tych bazach wiedzy, ale Google nadal musiał budować swoją wiedzę o jednostkach dla danych nieustrukturyzowanych (tj. blogów).
Google nawiązał współpracę z Bing i Yahoo i stworzył Schema.org, aby wykonać to zadanie.
Google zapewnia wskazówki dotyczące schematu, dzięki czemu menedżerowie witryn mogą korzystać z narzędzi, które pomagają Google zrozumieć treść. Pamiętaj, Google chce skupić się na rzeczach, a nie ciągach znaków.
Słowami Google:
„Możesz nam pomóc, przekazując Google wyraźne wskazówki dotyczące znaczenia strony, umieszczając na niej uporządkowane dane. Dane strukturalne to ustandaryzowany format dostarczania informacji o stronie i klasyfikacji zawartości strony; na przykład na stronie przepisu, jakie są składniki, czas i temperatura gotowania, kalorie i tak dalej.
Google kontynuuje, mówiąc:
„Musisz podać wszystkie wymagane właściwości, aby obiekt kwalifikował się do wyświetlania w wyszukiwarce Google z ulepszonym wyświetlaniem. Ogólnie rzecz biorąc, zdefiniowanie większej liczby zalecanych funkcji może zwiększyć prawdopodobieństwo pojawienia się Twoich informacji w wynikach wyszukiwania z ulepszonym wyświetlaniem. Jednak ważniejsze jest dostarczanie mniejszej liczby, ale pełnych i dokładnych zalecanych właściwości, niż próba dostarczania każdej możliwej zalecanej właściwości z mniej kompletnymi, źle sformułowanymi lub niedokładnymi danymi”.
O schemacie można powiedzieć więcej, ale wystarczy powiedzieć, że schemat jest niesamowitym narzędziem dla SEO, którzy chcą, aby zawartość strony była przejrzysta dla wyszukiwarek.
Ostatni element układanki pochodzi z ogłoszenia na blogu Google zatytułowanego „Improving Search for The Next 20 Years”.
Istotność i jakość dokumentów to główne idee stojące za tym ogłoszeniem. Pierwsza metoda zastosowana przez Google do określania zawartości strony była całkowicie skoncentrowana na słowach kluczowych.
Następnie Google dodał warstwy tematyczne do wyszukiwania. Ta warstwa była możliwa dzięki grafom wiedzy oraz systematycznemu zbieraniu i porządkowaniu danych w sieci.
To prowadzi nas do obecnego systemu wyszukiwania. Google przeszedł z 570 milionów podmiotów i 18 miliardów faktów do 800 miliardów faktów i 8 miliardów podmiotów w mniej niż 10 lat. Wraz ze wzrostem tej liczby poprawia się wyszukiwanie jednostek.
W jaki sposób model encji jest ulepszeniem w porównaniu z poprzednimi modelami wyszukiwania?
Tradycyjne modele wyszukiwania informacji oparte na słowach kluczowych (IR) mają nieodłączne ograniczenie polegające na tym, że nie są w stanie pobrać (istotnych) dokumentów, które nie mają wyraźnego dopasowania terminów do zapytania.
Jeśli używasz ctrl + f , aby znaleźć tekst na stronie, używasz czegoś podobnego do tradycyjnego modelu wyszukiwania informacji opartego na słowach kluczowych.
Każdego dnia w sieci publikowana jest niesamowita ilość danych.
Google po prostu nie jest w stanie zrozumieć znaczenia każdego słowa, każdego akapitu, każdego artykułu i każdej witryny.
Zamiast tego jednostki zapewniają strukturę, dzięki której Google może zminimalizować obciążenie obliczeniowe, jednocześnie poprawiając zrozumienie.
„Metody wyszukiwania oparte na pojęciach próbują stawić czoła temu wyzwaniu, opierając się na strukturach pomocniczych w celu uzyskania semantycznych reprezentacji zapytań i dokumentów w przestrzeni pojęciowej wyższego poziomu. Takie struktury obejmują słowniki kontrolowane (słowniki i tezaurusy), ontologie i byty z repozytorium wiedzy”.
– Wyszukiwanie zorientowane na jednostki , rozdział 8.3
Krisztian Balog, który napisał ostateczną książkę o bytach, identyfikuje trzy możliwe rozwiązania tradycyjnego modelu wyszukiwania informacji.
- Oparte na rozszerzeniach : używa encji jako źródła do rozszerzania zapytania o różne terminy.
- Oparte na projekcji : związek między zapytaniem a dokumentem jest rozumiany poprzez rzutowanie ich na ukrytą przestrzeń jednostek
- Oparte na jednostkach : Jawne reprezentacje semantyczne zapytań i dokumentów są uzyskiwane w przestrzeni jednostek w celu rozszerzenia reprezentacji opartych na terminach.
Celem tych trzech podejść jest uzyskanie bogatszej reprezentacji potrzebnych informacji użytkownika poprzez identyfikację podmiotów silnie powiązanych z zapytaniem.
Następnie Balog identyfikuje sześć algorytmów związanych z metodami mapowania jednostek opartymi na projekcji (metody projekcji dotyczą przekształcania jednostek w przestrzeń trójwymiarową i mierzenia wektorów za pomocą geometrii).
- Jawna analiza semantyczna (ESA) : Semantyka danego słowa jest opisana przez wektor przechowujący siłę skojarzenia słowa z pojęciami pochodzącymi z Wikipedii.
- Model przestrzenny encji utajonych (LES) : oparty na generatywnych ramach probabilistycznych. Przyjmuje się, że wynik wyszukiwania dokumentu jest liniową kombinacją wyniku przestrzeni utajonych jednostek i wyniku prawdopodobieństwa pierwotnego zapytania.
- EsdRank: EsdRank służy do oceniania dokumentów przy użyciu kombinacji funkcji encji zapytania i encji-dokumentu. Odpowiadają one wcześniejszym pojęciom projekcji zapytań i projekcji dokumentów LES. Wykorzystując dyskryminacyjne ramy uczenia się, można również łatwo włączyć dodatkowe sygnały, takie jak popularność podmiotu lub jakość dokumentu
- Jawny ranking semantyczny (ESR): jawny model rankingu semantycznego zawiera informacje o relacjach z grafu wiedzy, aby umożliwić „miękkie dopasowanie” w przestrzeni encji.
- Struktura duetu Word-entity: obejmuje międzyprzestrzenne interakcje między reprezentacjami opartymi na terminach i encjach, co prowadzi do czterech typów dopasowań: zapytania dotyczące terminów do warunków dokumentu, zapytania encji do warunków dokumentu, zapytania warunków do encji dokumentu i zapytania encji dokumentować podmioty.
- Model rankingu oparty na uwadze : Jest to zdecydowanie najbardziej skomplikowane do opisania.
Oto, co pisze Balog:
„Zaprojektowano w sumie cztery funkcje uwagi, które są wyodrębniane dla każdej jednostki zapytania. Cechy niejednoznaczności encji mają na celu scharakteryzowanie ryzyka związanego z adnotacją encji. Są to: (1) entropia prawdopodobieństwa powiązania formy powierzchni z różnymi bytami (np. w Wikipedii), (2) czy adnotowana jednostka jest najpopularniejszym znaczeniem formy powierzchni (tj. ma największą powszechność oraz (3) różnica w wynikach podobieństwa między najbardziej prawdopodobnymi i drugimi najbardziej prawdopodobnymi kandydatami dla danej formy powierzchni Czwartą cechą jest bliskość, która jest zdefiniowana jako podobieństwo cosinusowe między jednostką zapytania a zapytaniem w przestrzeni osadzania W szczególności, wspólne osadzanie encji-terminów jest trenowane przy użyciu modelu skip-gram w korpusie, w którym wzmianki encji są zastępowane odpowiednimi identyfikatorami encji.Osadzanie zapytania jest traktowane jako środek ciężkości osadzania terminów zapytania.

Na razie ważne jest, aby mieć podstawową znajomość tych sześciu algorytmów zorientowanych na jednostki.
Głównym wnioskiem jest to, że istnieją dwa podejścia: rzutowanie dokumentów na warstwę ukrytych jednostek i jawne adnotacje jednostek w dokumentach.
Trzy typy struktur danych
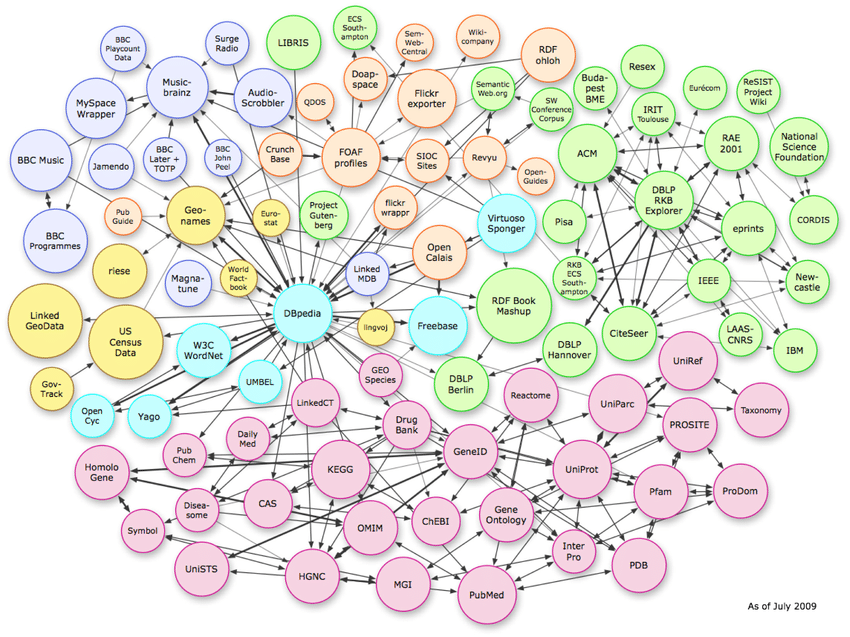
Powyższy obrazek pokazuje złożone relacje istniejące w przestrzeni wektorowej. Chociaż przykład pokazuje połączenia grafu wiedzy, ten sam wzorzec można replikować na poziomie schematu strona po stronie.
Aby zrozumieć byty, ważna jest znajomość trzech typów struktur danych, z których korzystają algorytmy.
- Używając nieustrukturyzowanych opisów jednostek , odniesienia do innych jednostek muszą być rozpoznane i ujednoznacznione. Skierowane krawędzie (hiperłącza) są dodawane z każdego elementu do wszystkich innych elementów wymienionych w jego opisie.
- W ustawieniach częściowo ustrukturyzowanych (tj. Wikipedia) linki do innych podmiotów mogą być podane wprost.
- Podczas pracy z danymi strukturalnymi , trójki RDF definiują graf (tj. graf wiedzy). W szczególności zasoby podmiotów i obiektów (URI) to węzły, a predykaty to krawędzie.
Problem z częściowo ustrukturyzowanym i rozpraszającym kontekstem dla wyniku IR polega na tym, że jeśli dokument nie jest skonfigurowany dla jednego tematu, wynik IR może zostać osłabiony przez dwa różne konteksty, co skutkuje utratą względnej rangi na rzecz innego dokumentu tekstowego.
Rozcieńczenie wyniku IR obejmuje słabo ustrukturyzowane relacje leksykalne i bliskość złych słów.
Odpowiednie słowa, które wzajemnie się uzupełniają, powinny być używane ściśle w akapicie lub sekcji dokumentu, aby wyraźniej zasygnalizować kontekst i zwiększyć wynik IR.
Wykorzystanie atrybutów i relacji jednostek daje względną poprawę w zakresie 5–20%. Wykorzystywanie informacji typu podmiot jest jeszcze bardziej satysfakcjonujące, a względne ulepszenia wahają się od 25% do ponad 100%.
Dodawanie adnotacji do dokumentów z encjami może nadać strukturę nieustrukturyzowanym dokumentom, co może pomóc w zapełnianiu baz wiedzy nowymi informacjami o encjach.
Korzystanie z Wikipedii jako struktury SEO dla Twojej jednostki
Struktura stron Wikipedii
- Tytuł (I.)
- Sekcja ołowiu (II.)
- Linki ujednoznaczniające (II.a)
- Infobox (II.b)
- Tekst wprowadzający (II.c)
- Spis treści (III.)
- Zawartość ciała (IV.)
- Dodatki i sprawa dolna (V.)
- Odniesienia i uwagi (Va)
- Linki zewnętrzne (Vb)
- Kategorie (Vc)
Większość artykułów w Wikipedii zawiera tekst wprowadzający, „ołów”, krótkie streszczenie artykułu – zazwyczaj nie dłuższe niż cztery akapity. Powinno to być napisane w sposób, który wzbudzi zainteresowanie artykułem.
Pierwsze zdanie i akapit otwierający mają szczególne znaczenie. Pierwsze zdanie „można traktować jako definicję podmiotu opisanego w artykule”. Pierwszy akapit zawiera bardziej rozbudowaną definicję bez zbytniej szczegółowości.
Wartość linków wykracza poza cele nawigacyjne; wychwytują relacje semantyczne między artykułami. Ponadto teksty zakotwiczeń są bogatym źródłem wariantów nazw podmiotów. Linki do Wikipedii mogą być wykorzystywane między innymi do identyfikacji i ujednoznacznienia wzmianek o podmiotach w tekście.
- Podsumuj kluczowe fakty dotyczące podmiotu (infobox).
- Krótkie wprowadzenie.
- Linki wewnętrzne. Kluczową zasadą obowiązującą redaktorów jest umieszczanie odnośników tylko do pierwszego wystąpienia encji lub pojęcia.
- Uwzględnij wszystkie popularne synonimy jednostki.
- Oznaczenie strony kategorii.
- Szablon nawigacji.
- Bibliografia.
- Specjalne narzędzia analizujące do zrozumienia stron Wiki.
- Wiele typów mediów.
Jak zoptymalizować pod kątem encji
Poniżej przedstawiono kluczowe kwestie, które należy wziąć pod uwagę podczas optymalizacji jednostek pod kątem wyszukiwania:
- Włączenie semantycznie powiązanych słów na stronie.
- Częstotliwość słów i fraz na stronie.
- Organizacja pojęć na stronie.
- W tym dane nieustrukturyzowane, dane częściowo ustrukturyzowane i dane ustrukturyzowane na stronie.
- Pary podmiot-predykat-przedmiot (SPO).
- Dokumenty internetowe w witrynie, które działają jak strony książki.
- Organizacja dokumentów internetowych na stronie internetowej.
- Dołącz pojęcia do dokumentu internetowego, które są znanymi cechami encji.
Ważna uwaga: Gdy nacisk kładzie się na relacje między jednostkami, baza wiedzy jest często określana jako graf wiedzy.
Ponieważ intencja jest analizowana w połączeniu z dziennikami wyszukiwania użytkowników i innymi fragmentami kontekstu, to samo wyszukiwane wyrażenie osoby 1 może wygenerować inny wynik niż osoba 2. Osoba ta może mieć inny zamiar z dokładnie tym samym zapytaniem.
Jeśli Twoja strona obejmuje oba typy intencji, jest lepszym kandydatem do rankingu internetowego. Możesz użyć struktury baz wiedzy, aby kierować szablonami intencji zapytań (jak wspomniano w poprzedniej sekcji).
Ludzie też pytają, ludzie szukają i autouzupełnianie są semantycznie powiązane z przesłanym zapytaniem i albo zagłębiają się w bieżący kierunek wyszukiwania, albo przechodzą do innego aspektu zadania wyszukiwania.
Wiemy o tym, więc jak możemy to zoptymalizować?
Twoje dokumenty powinny zawierać jak najwięcej wariantów intencji wyszukiwania. Twoja witryna powinna zawierać wszystkie odmiany intencji wyszukiwania dla Twojego klastra. Grupowanie opiera się na trzech typach podobieństw:
- Podobieństwo leksykalne.
- Podobieństwo semantyczne.
- Kliknij podobieństwo.
Zakres tematyczny
Co to jest –> Lista atrybutów –> Sekcja poświęcona każdemu atrybutowi –> Każda sekcja prowadzi do artykułu w pełni poświęconego danemu tematowi –> Należy określić odbiorców i zdefiniować definicje dla podsekcji –> Co należy wziąć pod uwagę ? –> Jakie są korzyści? –> Korzyści z modyfikatora –> Co to jest ___ –> Co robi? –> Jak to zrobić –> Jak to zrobić –> Kto może to zrobić –> Link z powrotem do wszystkich kategorii

Google oferuje narzędzie, które zapewnia wynik istotności (podobny do tego, w jaki sposób używamy słowa „siła” lub „pewność siebie”), który informuje, jak Google widzi treść.

Powyższy przykład pochodzi z artykułu Search Engine Land o podmiotach z 2018 roku.
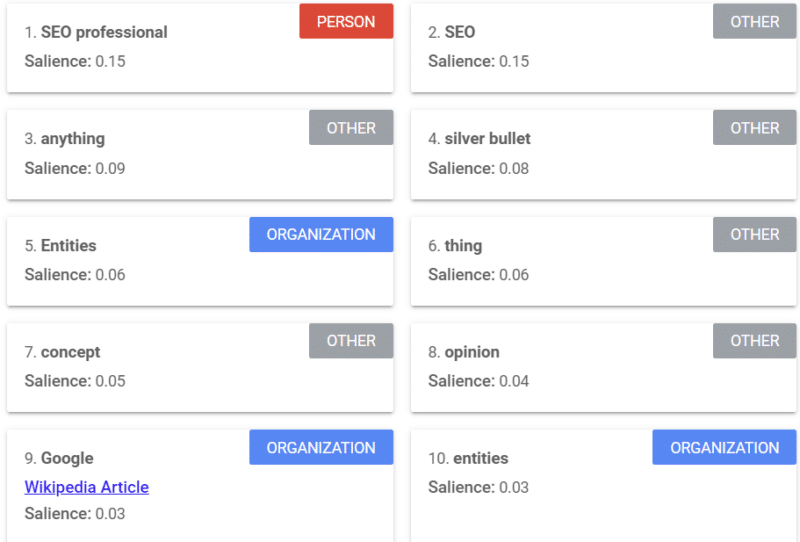
Na przykładzie możesz zobaczyć osoby, inne osoby i organizacje. Narzędziem jest interfejs API języka naturalnego Google Cloud.
Każde słowo, zdanie i akapit mają znaczenie, gdy mówimy o bycie. Sposób, w jaki organizujesz swoje myśli, może zmienić sposób rozumienia Twoich treści przez Google.
Możesz dołączyć słowo kluczowe dotyczące SEO, ale czy Google rozumie to słowo kluczowe tak, jak chcesz, aby było rozumiane?
Spróbuj umieścić akapit lub dwa w narzędziu oraz zreorganizować i zmodyfikować przykład, aby zobaczyć, jak zwiększa on lub zmniejsza wyrazistość.
To ćwiczenie, zwane „ujednoznacznieniem”, jest niezwykle ważne dla bytów. Język jest wieloznaczny, więc musimy sprawić, by nasze słowa były mniej dwuznaczne dla Google.
Nowoczesne podejścia do ujednoznaczniania uwzględniają trzy rodzaje dowodów:
Priorytetowe znaczenie podmiotów i wzmianek.
Podobieństwo kontekstowe między tekstem otaczającym wzmiankę a podmiotem kandydującym oraz spójność wszystkich decyzji dotyczących powiązań podmiotów w dokumencie.
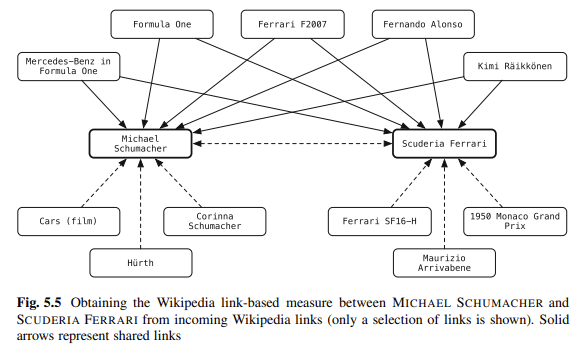
Schemat jest jednym z moich ulubionych sposobów ujednoznaczniania treści. Łączysz podmioty na swoim blogu z repozytoriami wiedzy. Balog mówi:
„[Powiązanie jednostek w nieustrukturyzowanym tekście z ustrukturyzowanym repozytorium wiedzy może znacznie wzmocnić użytkowników w ich czynnościach związanych z konsumpcją informacji”.
Na przykład czytelnicy dokumentu mogą jednym kliknięciem uzyskiwać informacje kontekstowe lub podstawowe oraz uzyskiwać łatwy dostęp do powiązanych elementów.
Adnotacje jednostek mogą być również używane w dalszym przetwarzaniu w celu poprawy wydajności wyszukiwania lub ułatwienia lepszej interakcji użytkownika z wynikami wyszukiwania.
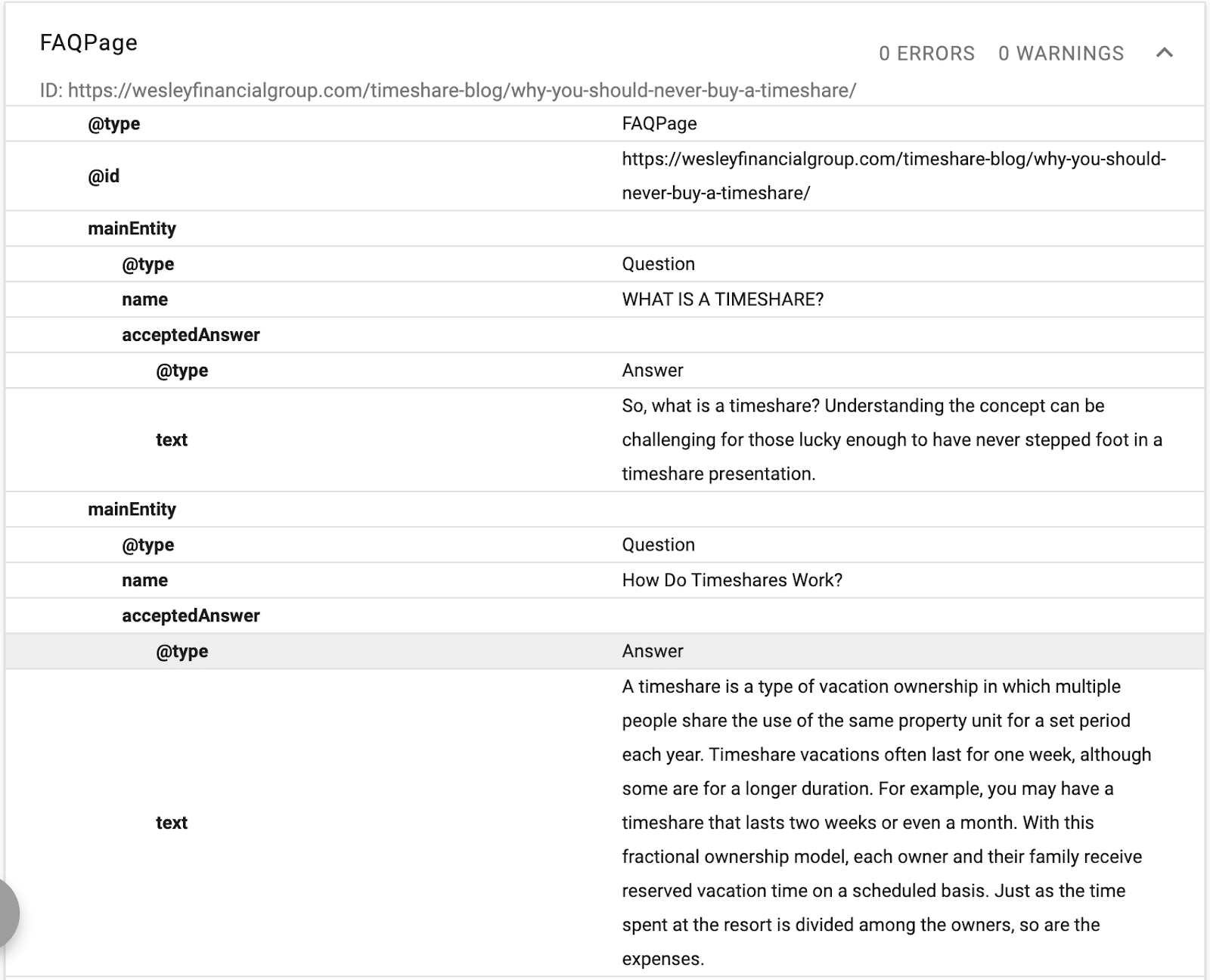
Tutaj możesz zobaczyć, że treść FAQ jest uporządkowana dla Google przy użyciu schematu FAQ.
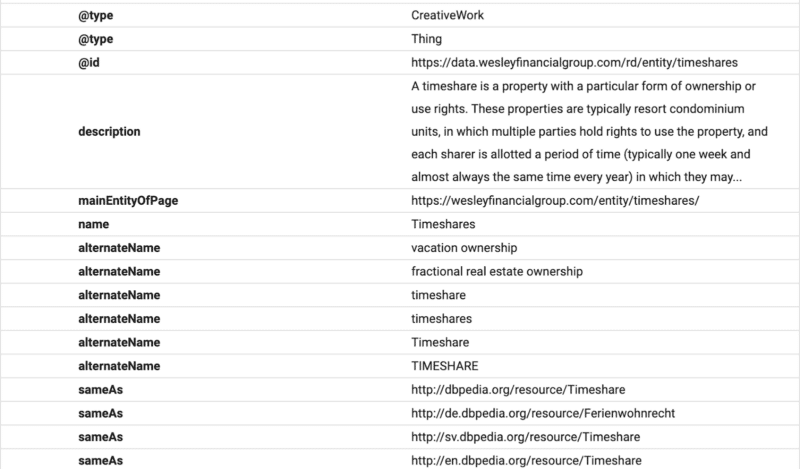
W tym przykładzie możesz zobaczyć schemat zawierający opis tekstu, identyfikator i deklarację głównego elementu strony.
(Pamiętaj, że Google chce zrozumieć hierarchię treści, dlatego H1–H6 są ważne).
Zobaczysz alternatywne nazwy i takie same jak deklaracje. Teraz, gdy Google odczyta treść, będzie wiedział, którą ustrukturyzowaną bazę danych powiązać z tekstem, i będzie miał synonimy i alternatywne wersje słowa powiązanego z podmiotem.
Gdy optymalizujesz za pomocą schematu, optymalizujesz pod kątem NER (rozpoznawanie nazwanych jednostek), znanego również jako identyfikacja jednostek, wyodrębnianie jednostek i dzielenie jednostek.
Chodzi o to, aby zaangażować się w Ujednoznacznianie nazwanych jednostek > Wikifikacja > Łączenie jednostek.
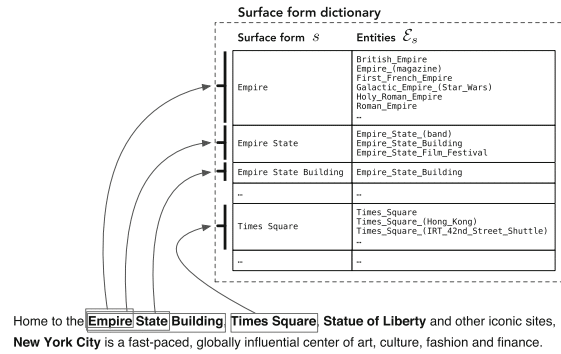
„Pojawienie się Wikipedii ułatwiło rozpoznawanie i ujednoznacznianie podmiotów na dużą skalę, udostępniając obszerny katalog podmiotów wraz z innymi nieocenionymi zasobami (w szczególności hiperłączami, kategoriami oraz stronami przekierowującymi i ujednoznaczniającymi”.
– Wyszukiwanie zorientowane na jednostki
Jak wykraczać poza sugestie narzędzi SEO
Większość SEO używa narzędzi na stronie do optymalizacji treści. Każde narzędzie ma ograniczoną zdolność do identyfikowania unikalnych możliwości treści i sugestii dotyczących głębi treści.
W większości narzędzia na stronie agregują najlepsze wyniki SERP i tworzą średnią do naśladowania.
SEO muszą pamiętać, że Google nie szuka tych samych przerobionych informacji. Możesz kopiować to, co robią inni, ale unikalne informacje są kluczem do zostania witryną zalążkową/autorytetową.
Oto uproszczony opis sposobu, w jaki Google obsługuje nowe treści:
Po znalezieniu dokumentu, który zawiera wzmiankę o danym podmiocie, dokument ten można sprawdzić w celu ewentualnego odkrycia nowych faktów, o które można zaktualizować wpis bazy wiedzy tego podmiotu.
Balog pisze:
„Chcemy pomóc redaktorom być na bieżąco ze zmianami, automatycznie identyfikując treści (artykuły z wiadomościami, posty na blogach itp.), które mogą sugerować modyfikacje wpisów KB określonego zestawu podmiotów będących przedmiotem zainteresowania (tj. podmiotów, którymi dany redaktor jest odpowiedzialny za)."
Każdy, kto ulepszy bazy wiedzy, rozpoznawanie jednostek i możliwość indeksowania informacji, zyska uznanie Google.
Zmiany dokonane w repozytorium wiedzy można prześledzić wstecz do dokumentu jako oryginalnego źródła.
Jeśli dostarczasz treści obejmujące dany temat i dodajesz rzadki lub nowy poziom szczegółowości, Google może sprawdzić, czy Twój dokument zawiera te unikalne informacje.
Ostatecznie te nowe informacje utrzymywane przez pewien czas mogą doprowadzić do tego, że Twoja witryna stanie się autorytetem.
To nie jest autorytatywność oparta na ocenie domeny, ale aktualny zasięg, który moim zdaniem jest o wiele bardziej wartościowy.
Dzięki podejściu podmiotowemu do SEO nie jesteś ograniczony do kierowania słów kluczowych z liczbą wyszukiwań.
Wszystko, co musisz zrobić, to zweryfikować hasło główne (na przykład „wędki muchowe”), a następnie możesz skupić się na kierowaniu odmian intencji wyszukiwania w oparciu o stare, dobre, ludzkie myślenie.
Zaczynamy od Wikipedii. Na przykładzie wędkarstwa muchowego widzimy, że na stronie internetowej poświęconej wędkarstwu powinny znaleźć się co najmniej następujące pojęcia:
- Gatunki ryb, historia, geneza, rozwój, ulepszenia technologiczne, ekspansja, metody wędkarstwa muchowego, casting, spey casting, wędkarstwo muchowe na pstrągi, techniki wędkarstwa muchowego, łowienie w zimnej wodzie, łowienie pstrągów na suchą muchę, nimfy na pstrągi, wody stojące łowienie pstrągów, granie w pstrągi, wypuszczanie pstrągów, wędkarstwo muchowe w słonej wodzie, sprzęt, sztuczne muchy i węzły.
Powyższe tematy pochodzą ze strony wędkarstwa muchowego w Wikipedii. Chociaż ta strona zawiera świetny przegląd tematów, lubię dodawać dodatkowe pomysły na tematy, które pochodzą z tematów powiązanych semantycznie.
Do tematu „ryba” możemy dodać kilka dodatkowych tematów, w tym etymologię, ewolucję, anatomię i fizjologię, komunikację ryb, choroby ryb, ochronę i znaczenie dla ludzi.
Czy ktoś powiązał anatomię pstrąga ze skutecznością niektórych technik połowu?
Czy jedna witryna wędkarska obejmuje wszystkie odmiany ryb, łącząc rodzaje technik połowu, wędki i przynęty dla każdej ryby?
Do tej pory powinieneś być w stanie zobaczyć, jak rozwija się temat. Należy o tym pamiętać, planując kampanię treści.
Nie powtarzaj tylko. Dodać wartość. Być wyjątkowym. Użyj algorytmów wymienionych w tym artykule jako przewodnika.
Wniosek
Ten artykuł jest częścią serii artykułów poświęconych podmiotom. W następnym artykule zagłębię się w działania optymalizacyjne wokół jednostek i niektóre narzędzia skoncentrowane na jednostkach na rynku.
Chcę zakończyć ten artykuł, składając podziękowania dwóm osobom, które wyjaśniły mi wiele z tych koncepcji.
Bill Sławski z SEO by the Sea i Koray Tugbert z Holistic SEO. Chociaż Sławskiego nie ma już z nami, jego wkład nadal ma wpływ na branżę SEO.
Jeśli chodzi o treść artykułu, w dużej mierze polegam na następujących źródłach, ponieważ te źródła są najlepszymi istniejącymi zasobami na ten temat:
- Rozszerzona hierarchia nazwanych jednostek autorstwa Satoshi Ketine, Kiyoshi Sudo i Chikashi Nobata
- Wyszukiwanie zorientowane na jednostki autorstwa Krisztiana Baloga , seria wyszukiwania informacji (INRE, tom 39)
- Przepisywanie zapytań z wykrywaniem jednostek , patent Google
- Udoskonalanie wyszukiwanych haseł , patent Google
- Powiązanie jednostki z wyszukiwanym hasłem , patent Google
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.