
Jak Apache Spark może dodać skrzydeł analityce linii lotniczych?
Opublikowany: 2015-10-30Światowy przemysł lotniczy nadal szybko się rozwija, ale nie widać jeszcze stałej i solidnej rentowności. Według Międzynarodowego Stowarzyszenia Przewoźników Powietrznych (IATA) branża podwoiła swoje przychody w ciągu ostatniej dekady, z 369 mld USD w 2005 r. do oczekiwanych 727 mld USD w 2015 r.

W sektorze lotnictwa komercyjnego każdy gracz w łańcuchu wartości — lotniska, producenci samolotów, producenci silników odrzutowych, biura podróży i firmy usługowe osiągają porządny zysk.
Wszyscy ci gracze indywidualnie generują wyjątkowo duże ilości danych ze względu na większą rotację transakcji lotniczych. Identyfikacja i uchwycenie popytu jest tutaj kluczem, który daje liniom lotniczym znacznie większe możliwości wyróżnienia się. W związku z tym branże lotnicze mogą wykorzystywać analizy danych big data, aby zwiększyć sprzedaż i poprawić marżę zysku.
Big data to określenie na gromadzenie zbiorów danych tak dużych i złożonych, że ich przetwarzanie nie może być obsługiwane przez tradycyjne systemy przetwarzania danych lub podręczne narzędzia DBMS.
Apache Spark to platforma obliczeniowa typu open source do rozproszonych klastrów zaprojektowana specjalnie z myślą o interaktywnych zapytaniach i algorytmach iteracyjnych.
Abstrakcja Spark DataFrame to obiekt danych tabelarycznych podobny do natywnej ramki danych lub pakietu pandas języka R, ale przechowywany w środowisku klastra.
Według najnowszego badania Fortunes, Apache Spark jest najpopularniejszą technologią 2015 roku.
Największy dostawca Hadoop, Cloudera, również żegna się z Hadoops MapReduce i Hello to Spark .
Tym, co naprawdę daje Sparkowi przewagę nad Hadoop, jest szybkość . Spark obsługuje większość swoich operacji w pamięci – kopiując je z rozproszonej pamięci fizycznej do znacznie szybszej logicznej pamięci RAM. Zmniejsza to ilość czasu poświęcanego na zapisywanie i odczytywanie z wolnych, nieporęcznych mechanicznych dysków twardych, które należy wykonać w systemie Hadoops MapReduce.
Ponadto Spark zawiera narzędzia (przetwarzanie w czasie rzeczywistym, uczenie maszynowe i interaktywny SQL), które są dobrze przygotowane do realizacji celów biznesowych, takich jak analizowanie danych w czasie rzeczywistym poprzez łączenie danych historycznych z podłączonych urządzeń, znanych również jako Internet rzeczy .
Dzisiaj zbierzmy trochę informacji na temat przykładowych danych lotnisk przy użyciu Apache Spark .
W poprzednim blogu widzieliśmy, jak obsługiwać ustrukturyzowane i częściowo ustrukturyzowane dane w Spark przy użyciu nowego interfejsu Dataframes API, a także omówiliśmy, jak wydajnie przetwarzać dane JSON.
W tym blogu dowiemy się, jak wykonywać zapytania danych w DataFrames za pomocą SQL , a także zapisywać dane wyjściowe do systemu plików w formacie CSV.
Korzystanie z biblioteki analizującej Databricks CSV
W tym celu użyję biblioteki analizującej CSV dostarczonej przez Databricks , firmę założoną przez twórców Apache Spark i która obecnie obsługuje Spark Development i dystrybucje.
Społeczność Spark składa się z około 600 współtwórców, którzy sprawiają, że jest to najbardziej aktywny projekt w całej Apache Software Foundation, głównym organie zarządzającym oprogramowaniem open source, pod względem liczby współtwórców.
Biblioteka Spark-csv pomaga nam analizować i przeszukiwać dane csv w Spark. Możemy używać tej biblioteki zarówno do odczytywania, jak i zapisywania danych csv do iz dowolnego systemu plików zgodnego z Hadoop.
Ładowanie danych do Spark DataFrames
Załadujmy nasze pliki wejściowe do Spark DataFrames przy użyciu biblioteki analizującej spark-csv z Databricks.
Możesz użyć tej biblioteki w powłoce Spark, określając –packages com.databricks: spark-csv_2.10:1.0.3
Podczas uruchamiania powłoki, jak pokazano poniżej:
$ bin/spark-shell –pakiety com.databricks:spark-csv_2.10:1.0.3
Pamiętaj, że powinieneś być podłączony do internetu, ponieważ pakiet spark-csv zostanie pobrany automatycznie po wydaniu tego polecenia. Używam Sparka w wersji 1.4.0
Stwórzmy sqlContext z już utworzonym obiektem SparkContext(sc)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Teraz załadujmy nasze dane csv z pliku airports.csv (airport csv github), którego schemat jest jak poniżej
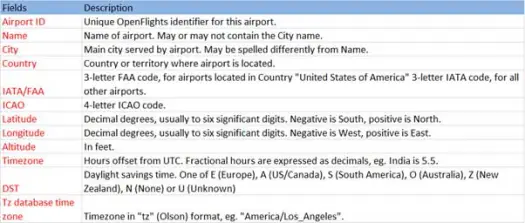
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))Operacja ładowania przeanalizuje plik *.csv przy użyciu biblioteki Databricks spark-csv i zwróci ramkę danych z nazwami kolumn takimi samymi, jak w pierwszym wierszu nagłówka w pliku.
Poniżej znajdują się parametry przekazywane do metody ładowania.
- Źródło : „com.databricks.spark.csv” mówi Sparkowi, że chcemy załadować jako plik csv.
- Opcje:
- ścieżka – ścieżka pliku, w którym się znajduje.
- Header : „header” -> „true” mówi Sparkowi, aby mapował pierwszy wiersz pliku na nazwy kolumn dla wynikowej ramki danych.
Zobaczmy, jaki jest schemat naszego Dataframe
Sprawdź przykładowe dane w naszej ramce danych
scala> airportDF.show

Odpytywanie danych CSV przy użyciu tabel tymczasowych:

Aby wykonać zapytanie względem tabeli, wywołujemy metodę sql() w SQLContext.
Stworzyliśmy DataFrame lotnisk i załadowaliśmy dane CSV, aby odpytywać te dane DF, musimy je zarejestrować jako tymczasową tabelę o nazwie lotniska.
>
scala> airportDF.registerTempTable("airports")
Sprawdźmy, ile lotnisk znajduje się w południowo-wschodniej części naszego zbioru danych
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Możemy wykonywać agregacje w zapytaniach sql na Spark
Dowiemy się, ile unikalnych miast ma lotniska w każdym kraju
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Jaka jest średnia wysokość (w stopach) lotnisk w każdym kraju?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Teraz, aby dowiedzieć się w każdej strefie czasowej, ile lotnisk działa?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Możemy również obliczyć średnią szerokość i długość geograficzną dla tych lotnisk w każdym kraju
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Policzmy, ile jest różnych DST
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Zapisywanie danych w formacie CSV
Do tej pory ładowaliśmy i przeszukiwaliśmy dane csv. Teraz zobaczymy, jak zapisać wyniki w formacie CSV z powrotem do systemu plików.
Załóżmy, że chcemy wysłać raport do klienta o wszystkich lotniskach w północno-zachodniej części wszystkich krajów.
Obliczmy to najpierw.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
I zapisz go w pliku CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Poniżej znajdują się parametry przekazywane do metody save.
- Źródło : to samo, co metoda ładowania com.databricks.spark.csv , która nakazuje Sparkowi zapisanie danych jako csv.
- SaveMode : Pozwala użytkownikowi z góry określić, co należy zrobić, jeśli podana ścieżka wyjściowa już istnieje. Aby istniejące dane nie zostały przez pomyłkę utracone/nadpisane. Możesz zgłosić błąd, dopisać lub nadpisać. Tutaj zgłosiliśmy błąd ErrorIfExists , ponieważ nie chcemy nadpisywać żadnego istniejącego pliku.
- Opcje : te opcje są takie same jak te, które przekazaliśmy do metody ładowania . Opcje:
- path – ścieżka pliku, w której ma być przechowywany.
- Header : "header" -> "true" mówi Sparkowi, aby mapował nazwy kolumn ramki danych do pierwszego wiersza wynikowego pliku wyjściowego.
Konwertowanie innych formatów danych do CSV
Za pomocą tej biblioteki możemy również przekonwertować dowolny inny format danych, taki jak JSON, parkiet, tekst na CSV.
W poprzednim blogu stworzyliśmy dane json. możesz go znaleźć na github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
po prostu zapiszmy to jako CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Wniosek:
W tym poście zebraliśmy kilka spostrzeżeń na temat danych lotnisk za pomocą interaktywnych zapytań SparkSQL
i zbadana biblioteka parsowania csv od Spark
W następnym blogu zajmiemy się bardzo ważnym komponentem Sparka, czyli Spark Streamingiem.
Spark Streaming pozwala użytkownikom gromadzić dane w czasie rzeczywistym w Spark i przetwarzać je na bieżąco oraz natychmiast udostępniać wyniki.