
Jak używać encji Google i GPT-4 do tworzenia konspektów artykułów
Opublikowany: 2023-06-06W tym artykule dowiesz się, jak korzystać ze skrobania i Grafu wiedzy Google, aby wykonać zautomatyzowaną inżynierię podpowiedzi, która generuje zarys i podsumowanie artykułu, który, jeśli jest dobrze napisany, będzie zawierał wiele kluczowych składników, aby uzyskać dobrą pozycję.
U podstaw rzeczy mówimy GPT-4, aby stworzył konspekt artykułu na podstawie słowa kluczowego i najlepszych elementów, które znaleźli na wybranej przez ciebie stronie o dobrej pozycji w rankingu.
Podmioty są uporządkowane według ich wyniku istotności.
„Dlaczego wynik istotności?” możesz zapytać.
Google opisuje istotność w swoich dokumentach API jako:
„Wynik istotności dla jednostki dostarcza informacji o znaczeniu lub centralnej pozycji tej jednostki w całym tekście dokumentu. Wyniki bliższe 0 są mniej istotne, podczas gdy wyniki bliższe 1,0 są bardzo istotne”.
Wydaje się to całkiem niezłą miarą do wpływania na to, które jednostki powinny istnieć w treści, którą możesz chcieć napisać, prawda?
Pierwsze kroki
Możesz to zrobić na dwa sposoby:
- Poświęć około 5 minut (może 10, jeśli musisz skonfigurować komputer) i uruchom skrypty ze swojego komputera lub…
- Przejdź do utworzonego przeze mnie Colab i od razu zacznij się bawić.
Jestem stronniczy w stosunku do pierwszego, ale skoczyłem też do Colab lub dwóch w ciągu dnia. 😀
Zakładając, że nadal tu jesteś i chcesz skonfigurować to na własnej maszynie, ale nie masz jeszcze zainstalowanego Pythona ani IDE (zintegrowanego środowiska programistycznego), najpierw skieruję cię do krótkiej lektury na temat konfigurowania komputera do użytku Notatnik Jupytera. Nie powinno to zająć więcej niż około 5 minut.
A teraz czas ruszać!
Używanie encji Google i GPT-4 do tworzenia konspektów artykułów
Aby ułatwić śledzenie, zamierzam sformatować wskazówki w następujący sposób:
- Krok : krótki opis kroku, na którym się znajdujemy.
- Kod : kod do wykonania tego kroku.
- Wyjaśnienie : Krótkie wyjaśnienie, co robi kod.
Krok 1: Powiedz mi, czego chcesz
Zanim przejdziemy do tworzenia konturów, musimy zdefiniować, czego chcemy.
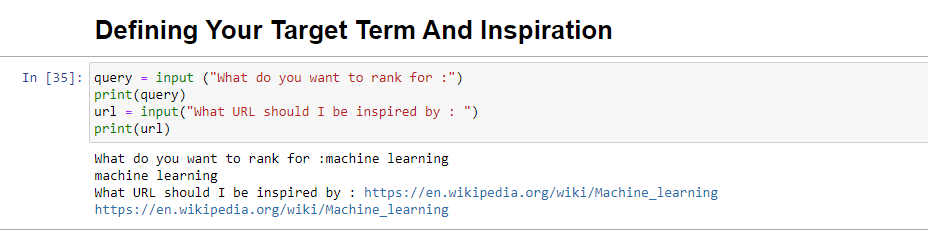
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)Po uruchomieniu ten blok poprosi użytkownika (prawdopodobnie Ciebie) o wprowadzenie zapytania, dla którego artykuł ma być uszeregowany/o którym będzie, a także da ci miejsce na umieszczenie adresu URL artykułu, który chcesz kawałek, którym można się zainspirować.
Sugerowałbym artykuł, który ma dobrą pozycję w rankingu, jest w formacie, który będzie odpowiedni dla Twojej witryny i który Twoim zdaniem zasługuje na rankingi wyłącznie na podstawie wartości artykułu, a nie tylko siły witryny.
Po uruchomieniu będzie wyglądać tak:
Krok 2: Instalowanie wymaganych bibliotek
Następnie musimy zainstalować wszystkie biblioteki, których będziemy używać, aby magia się wydarzyła.
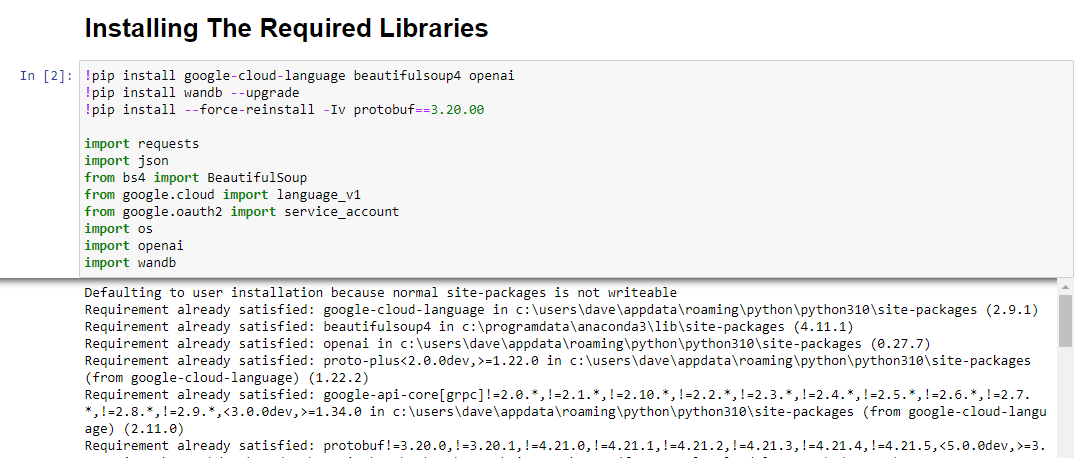
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbInstalujemy następujące biblioteki:
- Żądania : ta biblioteka umożliwia wysyłanie żądań HTTP w celu pobrania treści ze stron internetowych lub internetowych interfejsów API.
- JSON : Zapewnia funkcje do pracy z danymi JSON, w tym parsowanie ciągów JSON do obiektów Pythona i serializację obiektów Pythona do ciągów JSON.
- BeautifulSoup : Ta biblioteka jest używana do zbierania danych z sieci. Pomaga w analizowaniu i poruszaniu się po dokumentach HTML lub XML oraz wydobywaniu z nich odpowiednich informacji.
- Google.cloud.language_v1 : Jest to biblioteka z Google Cloud, która zapewnia możliwości przetwarzania języka naturalnego. Pozwala na wykonywanie różnych zadań, takich jak analiza nastrojów, rozpoznawanie jednostek i analiza składni danych tekstowych.
- Google.oauth2.service_account : ta biblioteka jest częścią pakietu Google OAuth2 Python. Zapewnia obsługę uwierzytelniania za pomocą Google API przy użyciu konta usługi, co jest sposobem na przyznanie ograniczonego dostępu do zasobów projektu Google Cloud.
- OS : Ta biblioteka umożliwia interakcję z systemem operacyjnym. Umożliwia dostęp do różnych funkcji, takich jak operacje na plikach, zmienne środowiskowe i zarządzanie procesami.
- OpenAI : Ta biblioteka to pakiet Pythona OpenAI. Zapewnia interfejs do interakcji z modelami językowymi OpenAI, w tym GPT-4 (i 3). Umożliwia programistom generowanie tekstu, uzupełnianie tekstu i nie tylko.
- Pandas : Jest to potężna biblioteka do manipulacji i analizy danych. Zapewnia struktury danych i funkcje do wydajnej obsługi i analizy danych strukturalnych, takich jak tabele lub pliki CSV.
- WandB : Ta biblioteka oznacza „Wagi i odchylenia” i jest narzędziem do śledzenia i wizualizacji eksperymentów. Pomaga rejestrować i wizualizować metryki, hiperparametry i inne ważne aspekty eksperymentów uczenia maszynowego.
Po uruchomieniu wygląda to tak:
Otrzymuj codzienny biuletyn wyszukiwania, na którym polegają marketerzy.
Zobacz warunki.
Krok 3: Uwierzytelnianie
Będę musiał zboczyć z nas na chwilę, aby wyruszyć i wprowadzić nasze uwierzytelnienie. Będziemy potrzebować klucza API OpenAI i danych logowania Google Knowledge Graph Search.
To zajmie tylko kilka minut.
Pobieranie interfejsu API OpenAI
Obecnie prawdopodobnie musisz dołączyć do listy oczekujących. Mam szczęście, że mam wcześniejszy dostęp do interfejsu API, dlatego piszę to, aby pomóc Ci skonfigurować usługę, gdy tylko ją uzyskasz.
Obrazy rejestracji pochodzą z GPT-3 i zostaną zaktualizowane dla GPT-4, gdy proces będzie dostępny dla wszystkich.
Zanim będziesz mógł korzystać z GPT-4, będziesz potrzebować klucza API, aby uzyskać do niego dostęp.
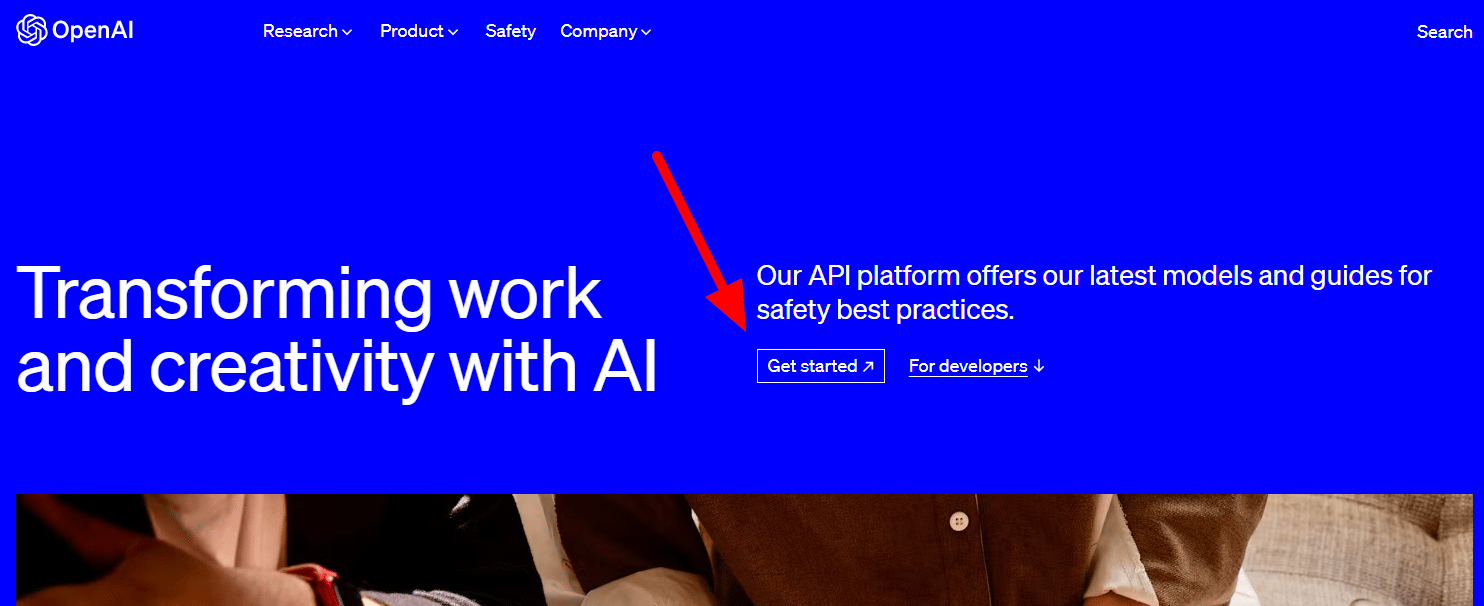
Aby go otrzymać, po prostu przejdź do strony produktu OpenAI i kliknij Rozpocznij .
Wybierz metodę rejestracji (ja wybrałem Google) i przeprowadź proces weryfikacji. W tym kroku będziesz potrzebować dostępu do telefonu, który może odbierać SMS-y.
Po zakończeniu utworzysz klucz API. Dzięki temu OpenAI może łączyć twoje skrypty z kontem.
Muszą wiedzieć, kto co robi i określić, czy i ile powinni cię obciążyć za to, co robisz.
Cennik OpenAI
Po zarejestrowaniu się otrzymasz kredyt w wysokości 5 USD, który zaprowadzi Cię zaskakująco daleko, jeśli tylko eksperymentujesz.
W chwili pisania tego tekstu przeszłość cenowa, czyli:

Tworzenie klucza OpenAI
Aby utworzyć klucz, kliknij swój profil w prawym górnym rogu i wybierz Wyświetl klucze API .
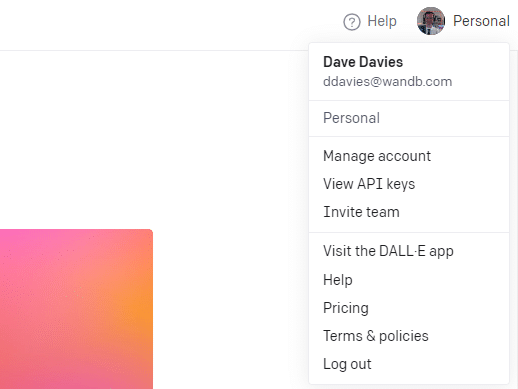
... a następnie utworzysz swój klucz.
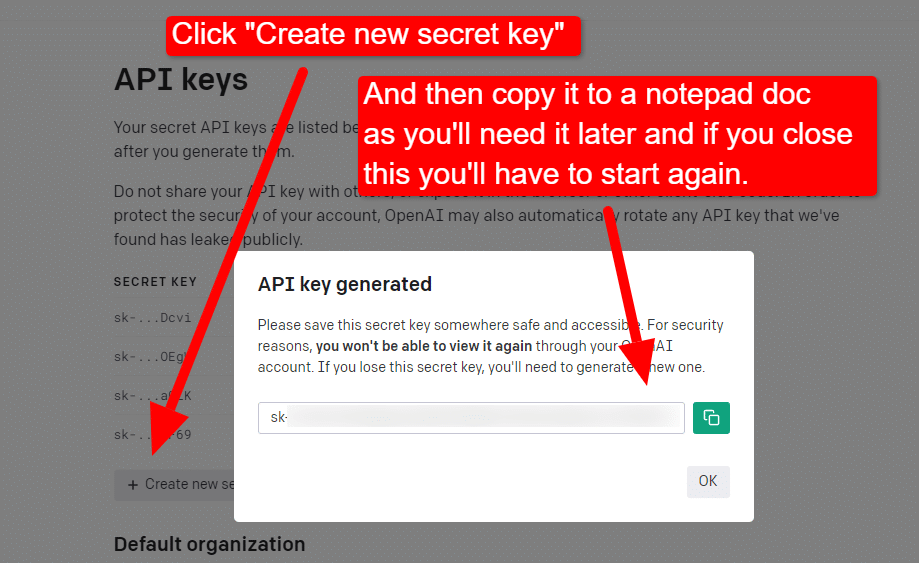
Po zamknięciu lightboxa nie możesz zobaczyć swojego klucza i będziesz musiał go odtworzyć, więc w tym projekcie po prostu skopiuj go do dokumentu Notatnika, aby wkrótce go użyć.
Uwaga: nie zapisuj klucza (dokument Notatnika na komputerze nie jest bardzo bezpieczny). Po chwilowym użyciu zamknij dokument Notatnika bez zapisywania go.
Uzyskiwanie uwierzytelnienia Google Cloud
Najpierw musisz zalogować się na swoje konto Google. (Jesteś na stronie SEO, więc zakładam, że ją masz. 🙂)
Gdy to zrobisz, możesz przejrzeć informacje API Grafu wiedzy, jeśli masz na to ochotę, lub od razu przejść do konsoli interfejsu API i zacząć.
Gdy znajdziesz się przy konsoli:
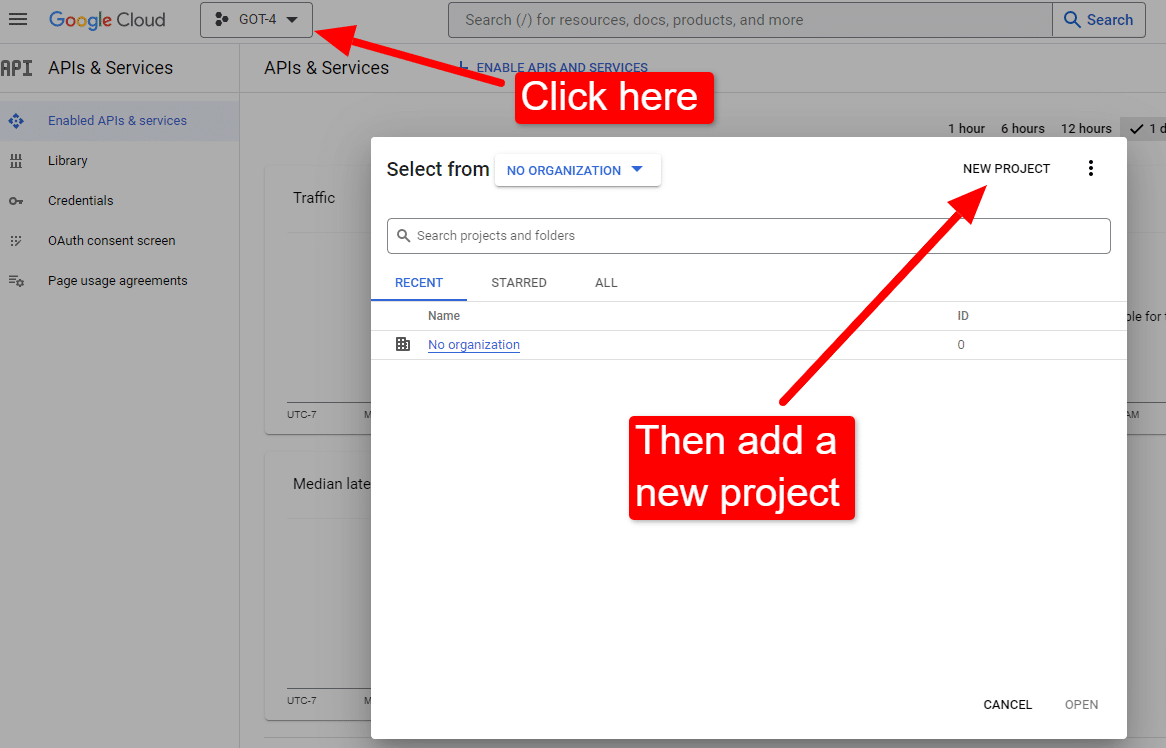
Nazwij to na przykład „Niesamowite artykuły Dave'a”. Wiesz… łatwe do zapamiętania.
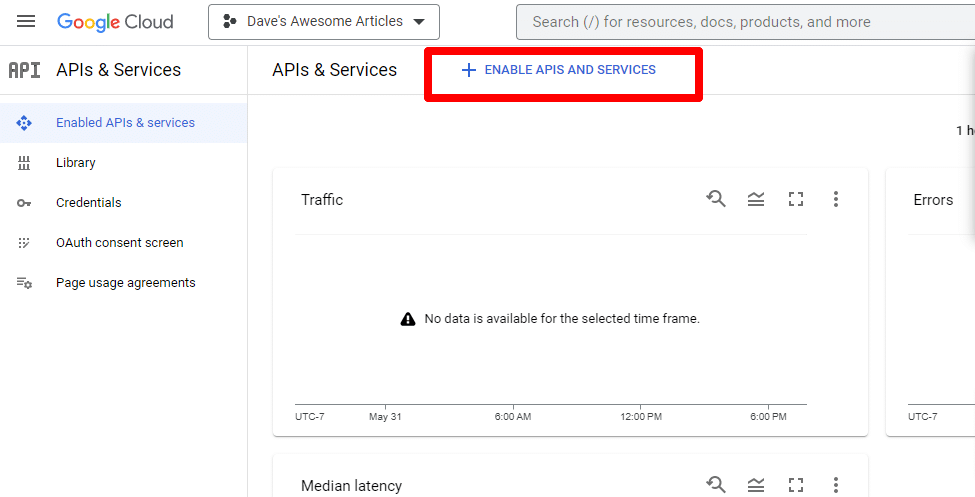
Następnie włącz interfejs API, klikając opcję Włącz interfejsy API i usługi .
Znajdź interfejs API wyszukiwania Grafu wiedzy i włącz go.

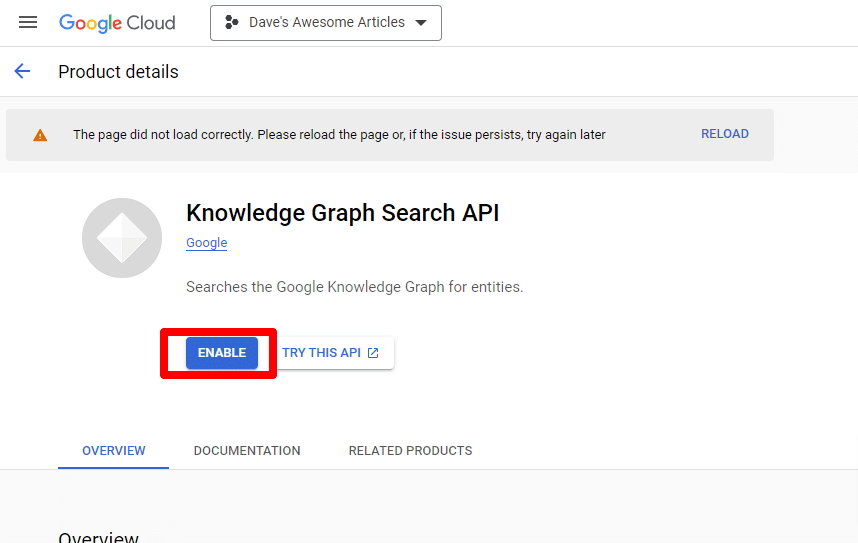
Zostaniesz przeniesiony z powrotem do głównej strony interfejsu API, gdzie możesz utworzyć poświadczenia:
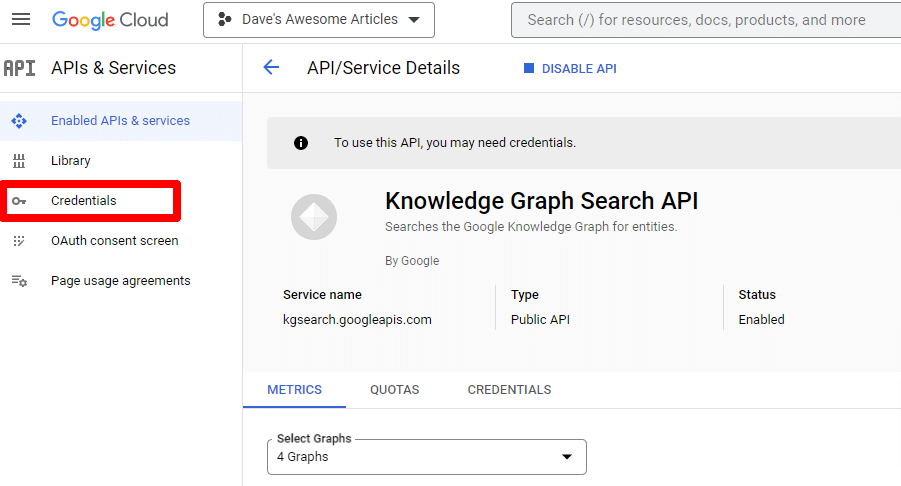
I utworzymy konto usługi.
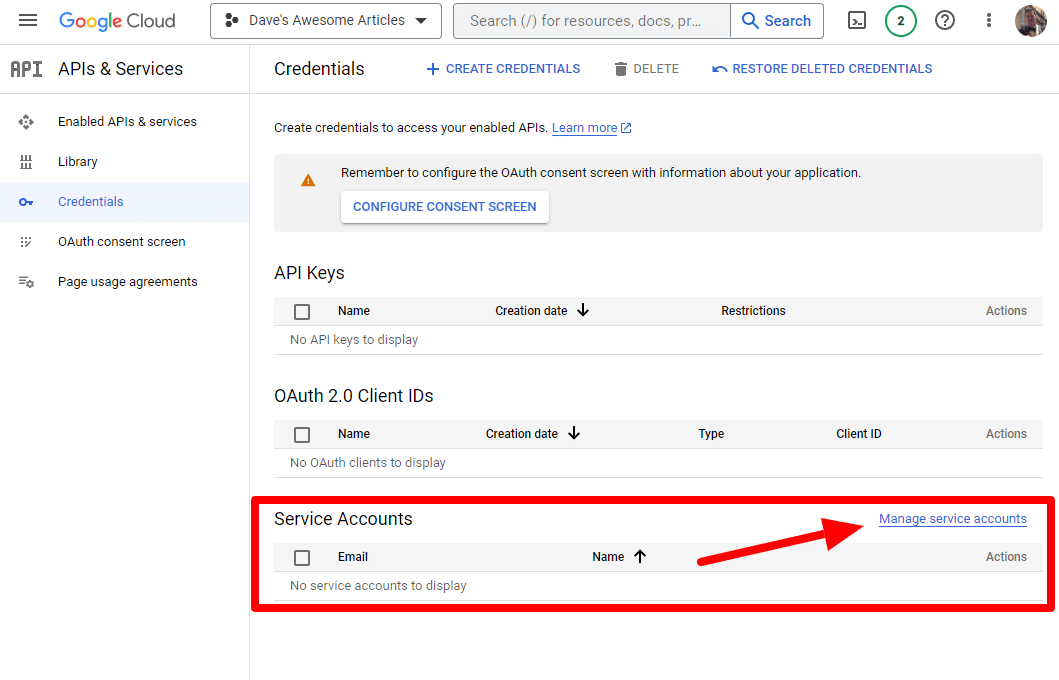
Po prostu utwórz konto usługi:
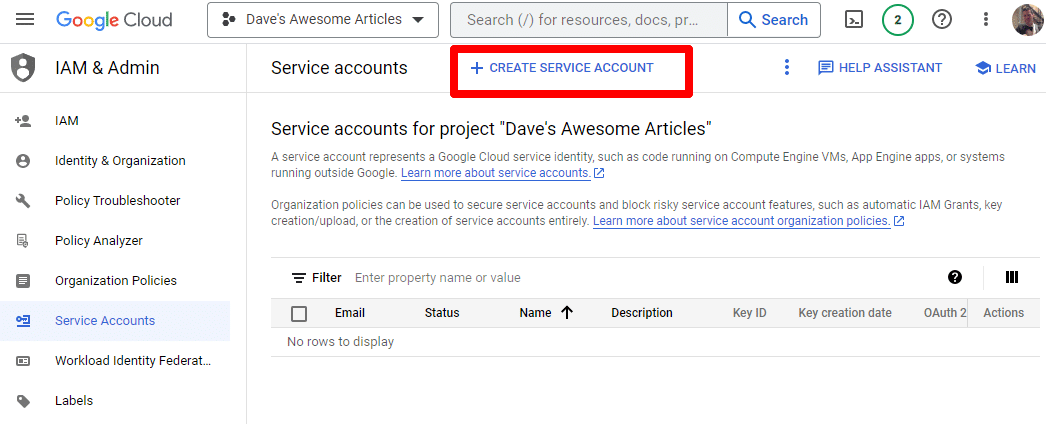
Podaj wymagane informacje:
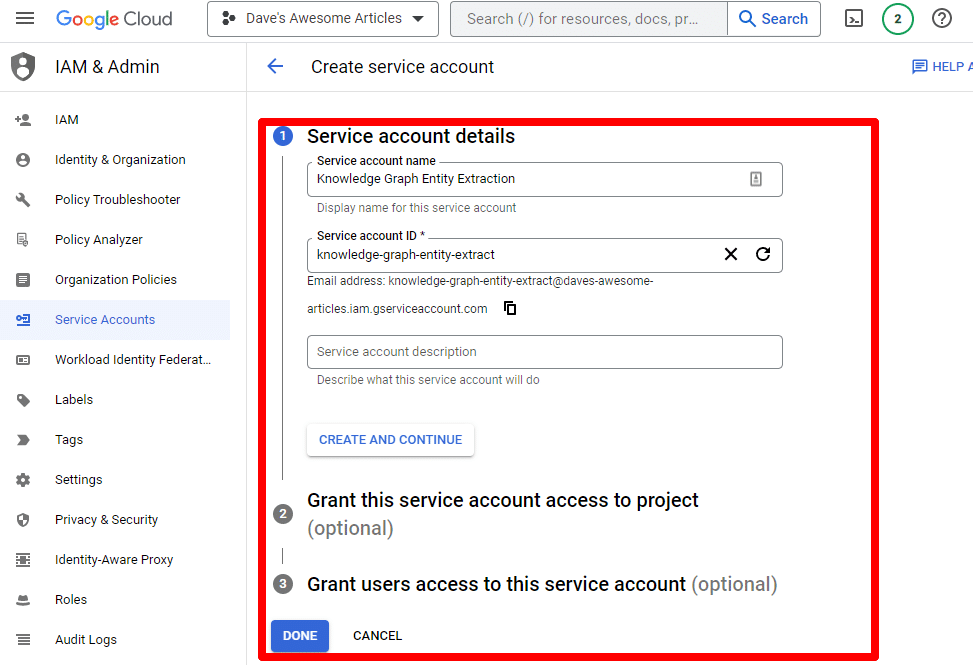
(Musisz nadać mu nazwę i nadać mu uprawnienia właściciela).
Teraz mamy nasze konto usługi. Pozostaje tylko stworzyć nasz klucz.
Kliknij trzy kropki pod Czynnościami i kliknij Zarządzaj kluczami .
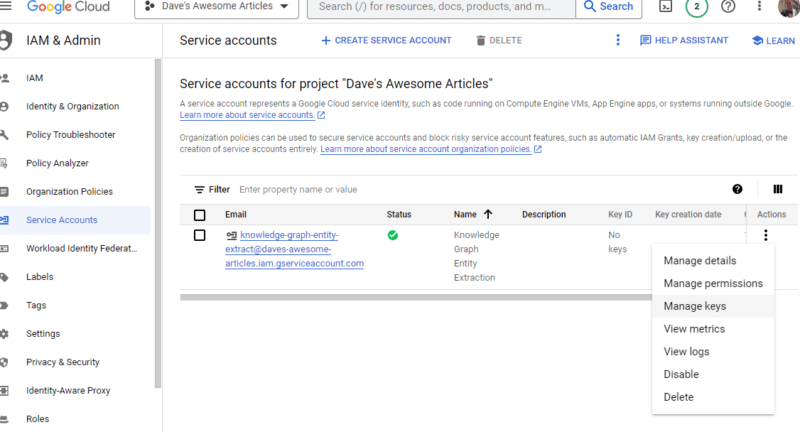
Kliknij Dodaj klucz, a następnie Utwórz nowy klucz :
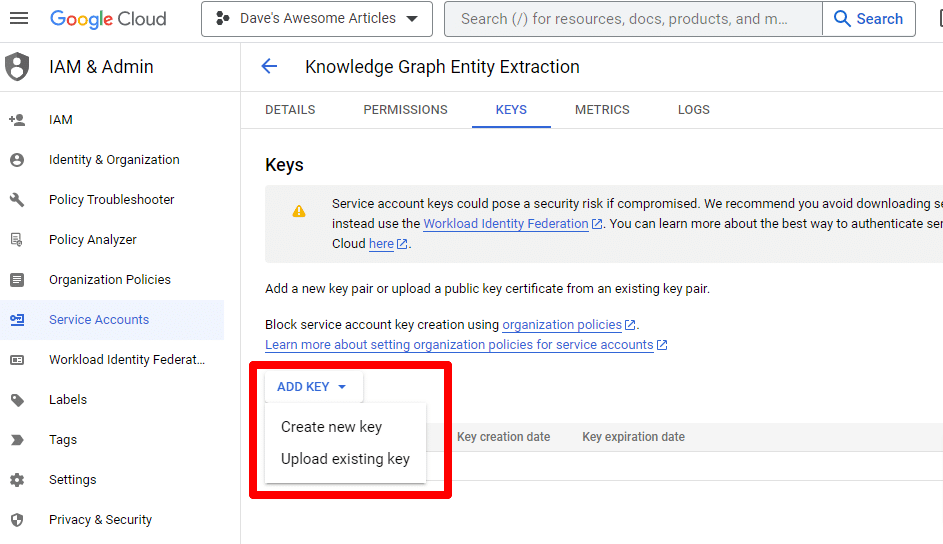
Typ klucza to JSON.
Natychmiast zobaczysz, że jest pobierany do domyślnej lokalizacji pobierania.
Ten klucz zapewni dostęp do twoich interfejsów API, więc chroń go, podobnie jak interfejs API OpenAI.
Dobra… i wracamy. Chcesz kontynuować pracę z naszym skryptem?
Teraz, gdy już je mamy, musimy zdefiniować nasz klucz API i ścieżkę do pobranego pliku. Kod do tego to:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") Zastąpisz YOUR_OPENAI_API_KEY własnym kluczem.
Zastąpisz również /PATH-TO-FILE/FILENAME.JSON ścieżką do właśnie pobranego klucza konta usługi, w tym nazwą pliku.
Uruchom komórkę i jesteś gotowy, aby przejść dalej.
Krok 4: Utwórz funkcje
Następnie utworzymy funkcje, aby:
- Zeskrob stronę internetową, którą weszliśmy powyżej.
- Przeanalizuj zawartość i wyodrębnij jednostki.
- Wygeneruj artykuł za pomocą GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()To jest dokładnie to, co opisują komentarze. Tworzymy trzy funkcje do celów opisanych powyżej.
Bystre oczy zauważą:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, Możesz edytować treść ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) i opisz rolę, jaką ma pełnić ChatGPT. Możesz także dodać ton (np. „Jesteś przyjaznym pisarzem…”).
Krok 5: Zeskrob adres URL i wydrukuj encje
Teraz brudzimy sobie ręce. Czas na:
- Zeskrob adres URL, który wpisaliśmy powyżej.
- Wyciągnij całą treść, która znajduje się w znacznikach akapitu.
- Uruchom go przez Google Knowledge Graph API.
- Wyprowadź jednostki, aby uzyskać szybki podgląd.
Zasadniczo chcesz zobaczyć wszystko na tym etapie. Jeśli nic nie widzisz, sprawdź inną witrynę.
content = scrape_url(url) entities = analyze_content(content)Możesz zobaczyć, że pierwsza linia wywołuje funkcję, która usuwa adres URL, który wprowadziliśmy jako pierwszy. Drugi wiersz analizuje zawartość w celu wyodrębnienia encji i kluczowych metryk.
Część funkcji analysis_content drukuje również listę znalezionych jednostek w celu szybkiego odniesienia i weryfikacji.
Krok 6: Przeanalizuj jednostki
Kiedy po raz pierwszy zacząłem bawić się scenariuszem, zacząłem od 20 elementów i szybko odkryłem, że zwykle jest ich za dużo. Ale czy wartość domyślna (10) jest poprawna?
Aby się tego dowiedzieć, zapiszemy dane w tabelach W&B w celu łatwej oceny. Będzie przechowywać dane przez czas nieokreślony do przyszłej oceny.
Najpierw musisz poświęcić około 30 sekund na rejestrację. (Nie martw się, to nic nie kosztuje!) Możesz to zrobić na https://wandb.ai/site.
Gdy już to zrobisz, kod, który to zrobi, to:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()Po uruchomieniu dane wyjściowe wyglądają następująco:
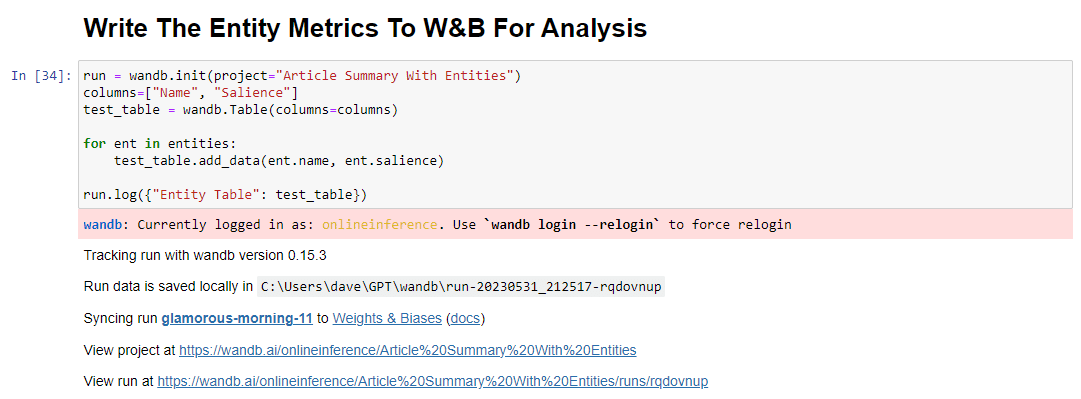
A kiedy klikniesz link, aby wyświetlić swój bieg, znajdziesz:
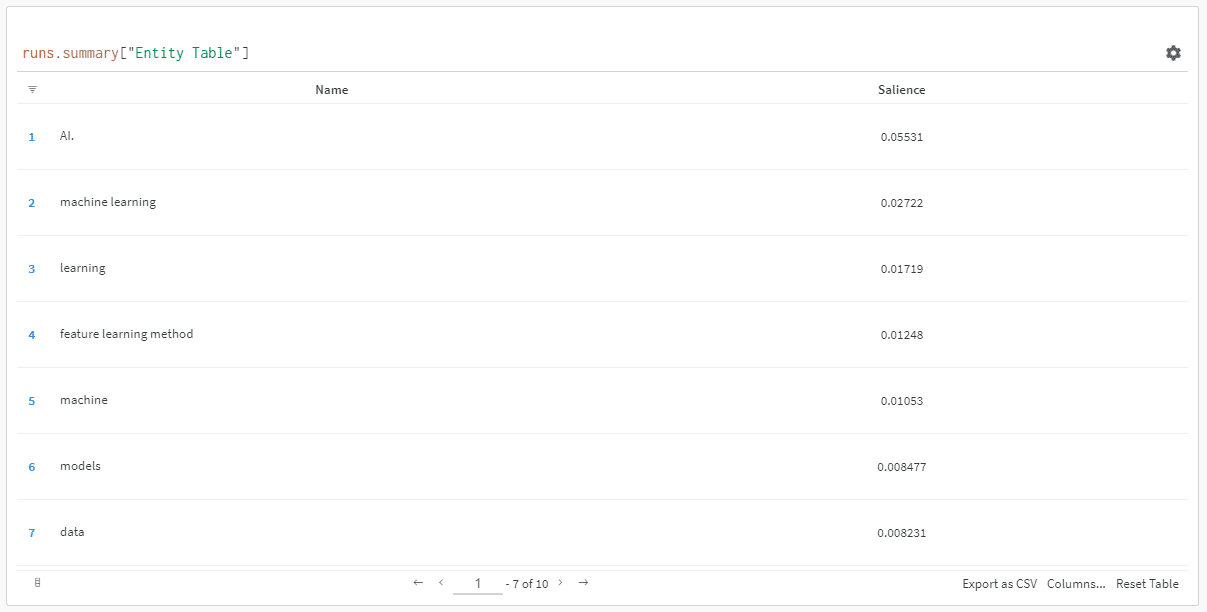
Możesz zauważyć spadek wyniku istotności. Pamiętaj, że ten wynik oblicza, jak ważne jest to hasło dla strony, a nie dla zapytania.
Przeglądając te dane, możesz dostosować liczbę jednostek na podstawie istotności lub tylko wtedy, gdy pojawią się nieistotne terminy.
Aby dostosować liczbę jednostek, przejdź do komórki funkcji i edytuj:
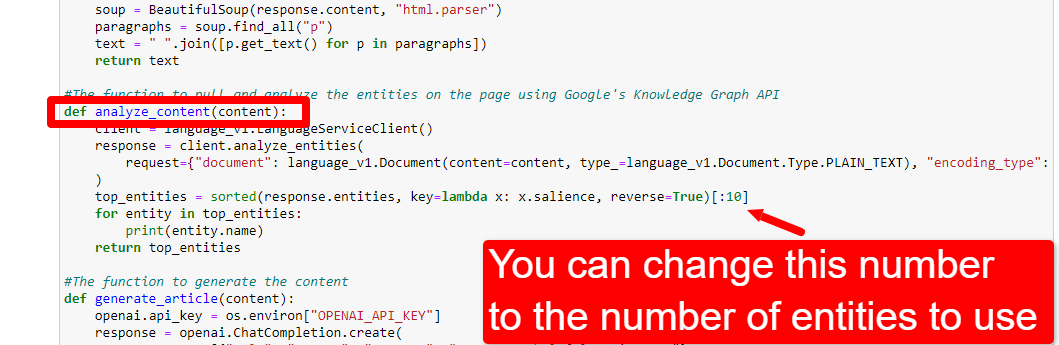
Następnie musisz ponownie uruchomić komórkę i tę, którą uruchomiłeś, aby zeskrobać i przeanalizować zawartość, aby użyć nowej liczby jednostek.
Krok 7: Wygeneruj zarys artykułu
Moment, na który wszyscy czekaliście, to czas na wygenerowanie konspektu artykułu.
Odbywa się to w dwóch częściach. Najpierw musimy wygenerować monit, dodając komórkę:
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)Zasadniczo tworzy to monit o wygenerowanie artykułu:

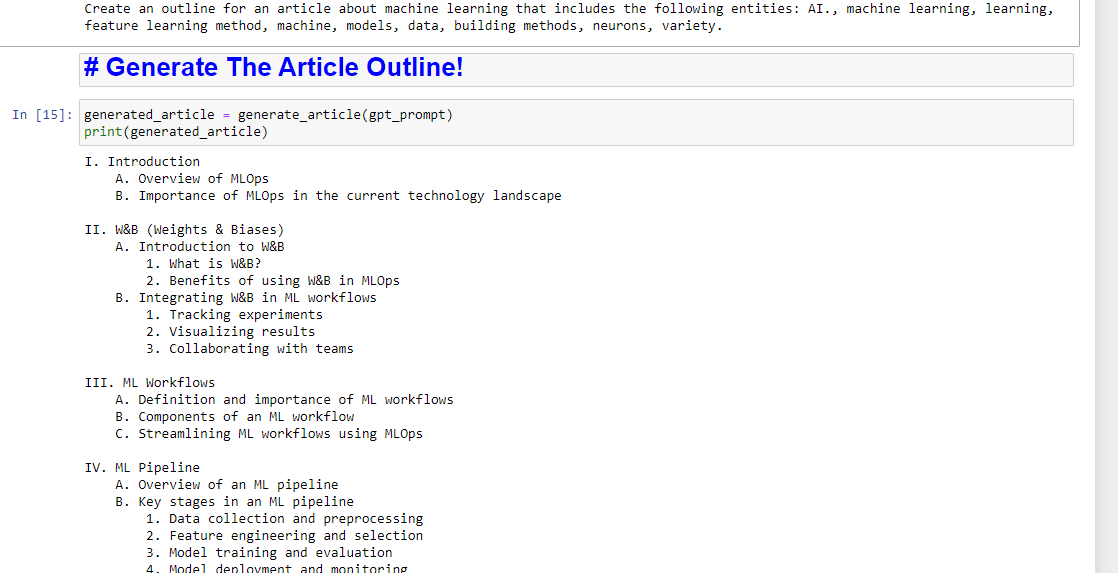
A potem pozostaje już tylko wygenerowanie konspektu artykułu przy użyciu:
generated_article = generate_article(gpt_prompt) print(generated_article)Który wyprodukuje coś takiego:
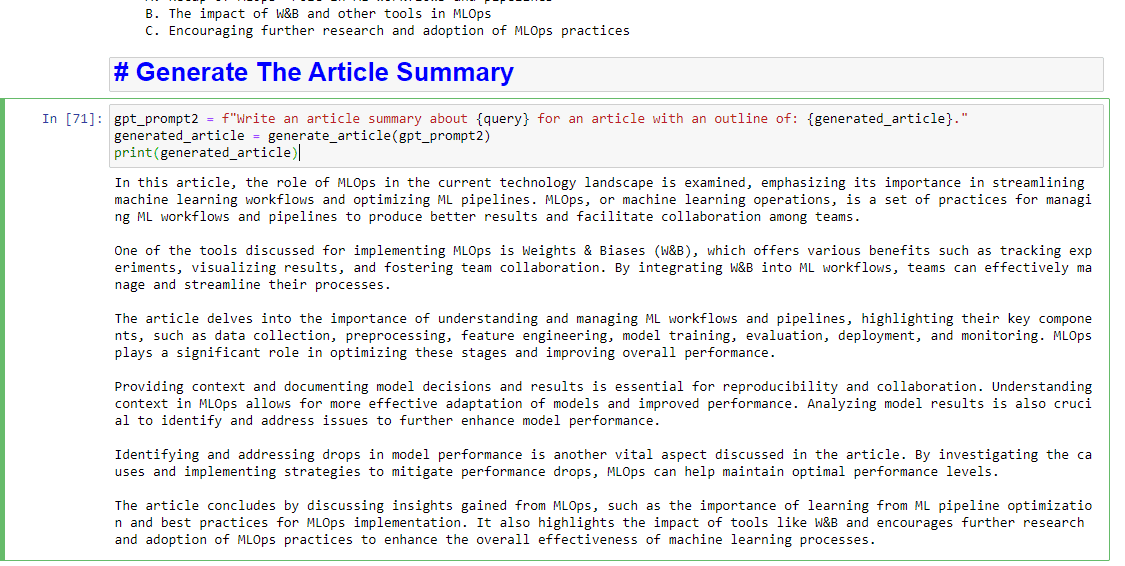
A jeśli chcesz również otrzymać podsumowanie, możesz dodać:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)Który wyprodukuje coś takiego:
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.