
Jak Google może identyfikować i oceniać autorów za pośrednictwem EEAT
Opublikowany: 2023-04-17Google przywiązuje większą wagę do źródła treści, w szczególności do autora, przy ustalaniu rankingu wyników wyszukiwania. Wprowadzenie Perspektyw, O tym wyniku i O tym autorze w SERP jasno to wyjaśnia.
Z tego artykułu dowiesz się, jak Google może potencjalnie oceniać fragmenty treści na podstawie doświadczenia, wiedzy, autorytetu i wiarygodności ich autorów (EEAT).
EEAT: ofensywa jakości Google
Google podkreśliło znaczenie koncepcji EEAT dla poprawy jakości wyników wyszukiwania i doświadczenia użytkownika w SERP.
Istotną rolę odgrywają czynniki na stronie, takie jak ogólna jakość treści, sygnały linków (tj. PageRank i teksty zakotwiczeń) oraz sygnały na poziomie jednostki.
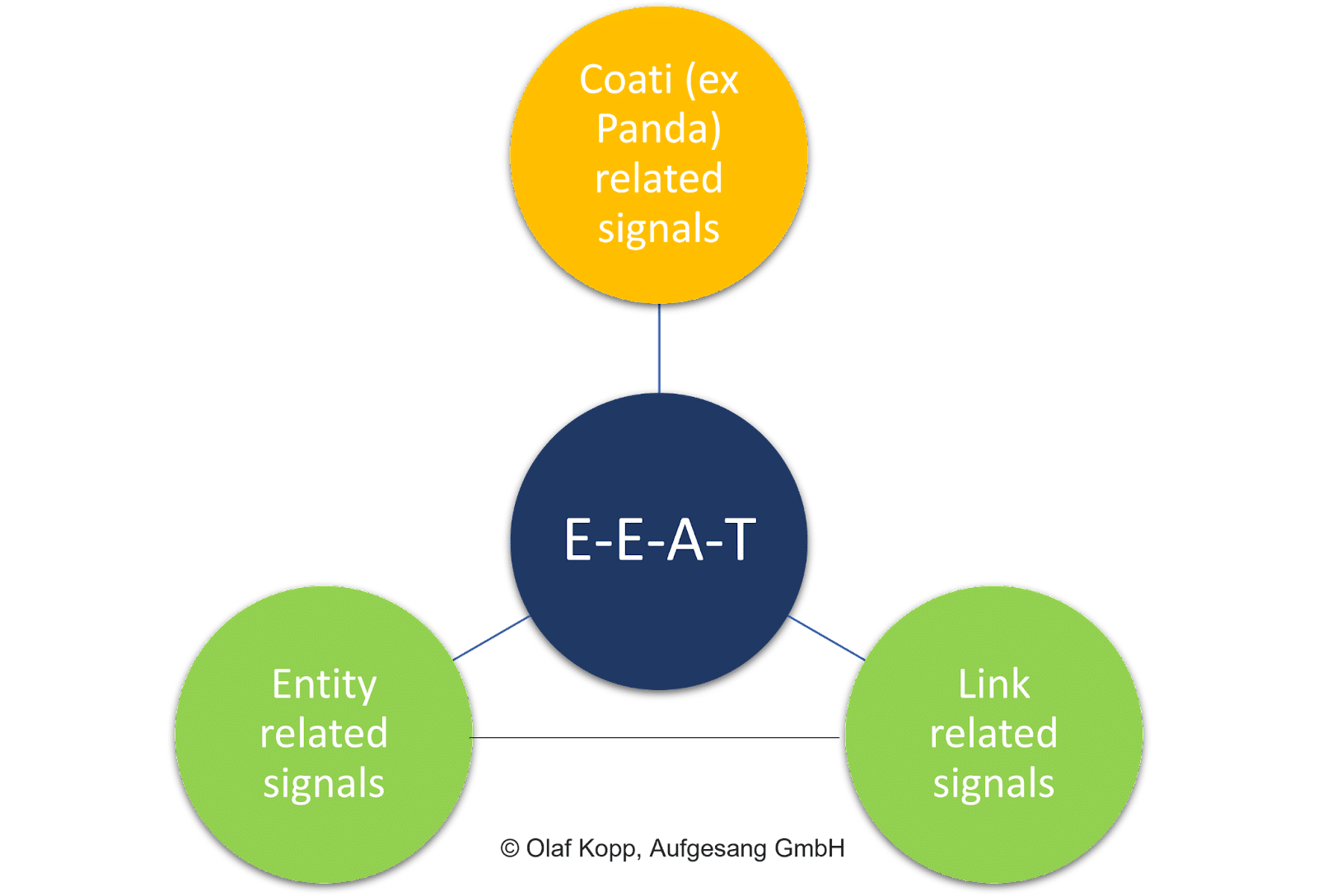
W przeciwieństwie do punktacji dokumentów, ocena poszczególnych treści nie jest celem EEAT.
Koncepcja posiada odniesienie tematyczne związane z domeną i podmiotem pomysłodawcą. Jest to niezależne od intencji wyszukiwania i samej treści.
Ostatecznie EEAT jest czynnikiem wpływającym, niezależnym od wyszukiwanych haseł.
EEAT odnosi się głównie do obszarów tematycznych i jest rozumiany jako warstwa ewaluacyjna, która ocenia zbiory treści i sygnały poza stroną w odniesieniu do podmiotów takich jak firmy, organizacje, ludzie i ich domeny.
Znaczenie autora jako źródła treści
Na długo przed (E-)EAT Google próbował uwzględniać ocenę źródeł treści w rankingach wyszukiwania. Na przykład aktualizacja Vince'a z 2009 roku dała treściom tworzonym przez markę przewagę w rankingu.
Poprzez projekty takie jak Knol czy Google+, które już dawno się zakończyły, Google próbowało zbierać sygnały dotyczące ocen autorów (tj. za pomocą wykresu społecznościowego i ocen użytkowników).
W ciągu ostatnich 20 lat kilka patentów Google bezpośrednio lub pośrednio odnosiło się do platform treści, takich jak Knol, oraz sieci społecznościowych, takich jak Google+.
Ocena pochodzenia lub autora treści zgodnie z kryteriami EEAT jest kluczowym krokiem do dalszego podnoszenia jakości wyników wyszukiwania.
Przy obfitości treści generowanych przez sztuczną inteligencję i klasycznego spamu nie ma sensu, aby Google umieszczał gorsze treści w indeksie wyszukiwania.
Im więcej treści indeksuje i musi przetworzyć podczas wyszukiwania informacji, tym większa jest wymagana moc obliczeniowa.
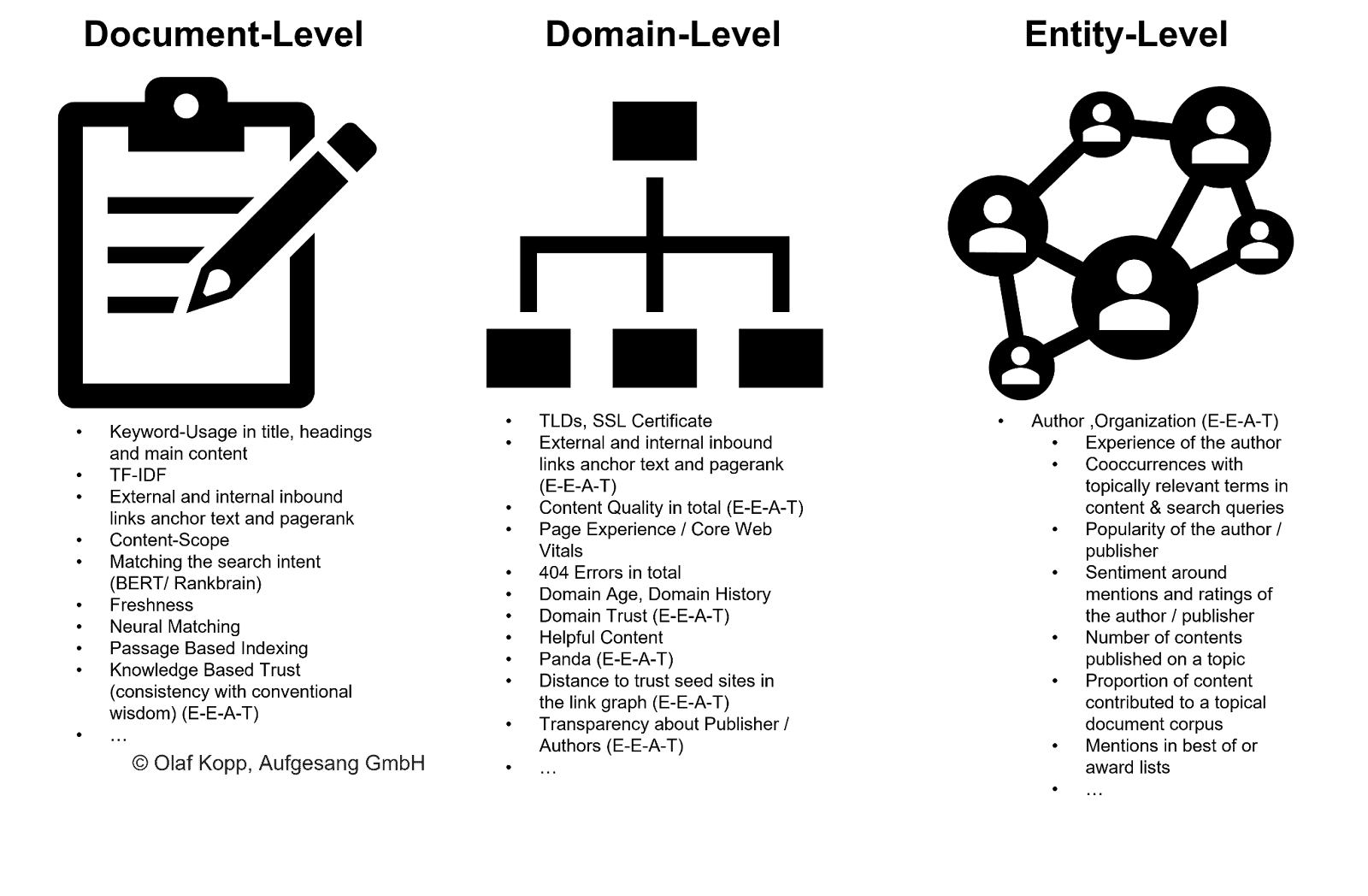
EEAT może pomóc Google w uszeregowaniu w oparciu o podmiot, domenę i poziom autora stosowany na szerszą skalę bez konieczności indeksowania każdego fragmentu treści.
Na tym poziomie makro treść można sklasyfikować według jednostki źródłowej i przydzielić z mniejszym lub większym budżetem na indeksowanie. Google może również użyć tej metody do wykluczenia całych grup treści z indeksowania.
Jak Google może identyfikować autorów i przypisywać treści?
Autorzy należą do typu podmiotu osoba. Należy dokonać rozróżnienia między już znanymi podmiotami zarejestrowanymi na Grafie wiedzy a wcześniej nieznanymi lub niezweryfikowanymi podmiotami zarejestrowanymi w repozytorium wiedzy, takim jak Skarbiec wiedzy.
Nawet jeśli jednostki nie zostały jeszcze uchwycone na Grafie wiedzy, Google może rozpoznawać i wyodrębniać jednostki z treści nieustrukturyzowanych za pomocą uczenia maszynowego i modeli językowych. Rozwiązanie nosi nazwę rozpoznawania jednostek (NER) i jest podzadaniem przetwarzania języka naturalnego.
NER rozpoznaje jednostki na podstawie wzorców językowych i przypisuje typy jednostek. Ogólnie rzecz biorąc, rzeczowniki to (nazwane) byty.
Nowoczesne systemy wyszukiwania informacji wykorzystują do tego celu osadzanie słów (Word2Vec).
Wektor liczb reprezentuje każde słowo tekstu lub akapit tekstu, a jednostki mogą być reprezentowane jako wektory węzłów lub osadzania jednostek (Node2Vec/Entity2Vec).
Słowa są przypisywane do klasy gramatycznej (rzeczownik, czasownik, przyimki itp.) poprzez oznaczanie części mowy (POS).
Rzeczowniki są zwykle bytami. Podmioty to byty główne, a przedmioty to byty drugorzędne. Czasowniki i przyimki mogą odnosić jednostki do siebie.
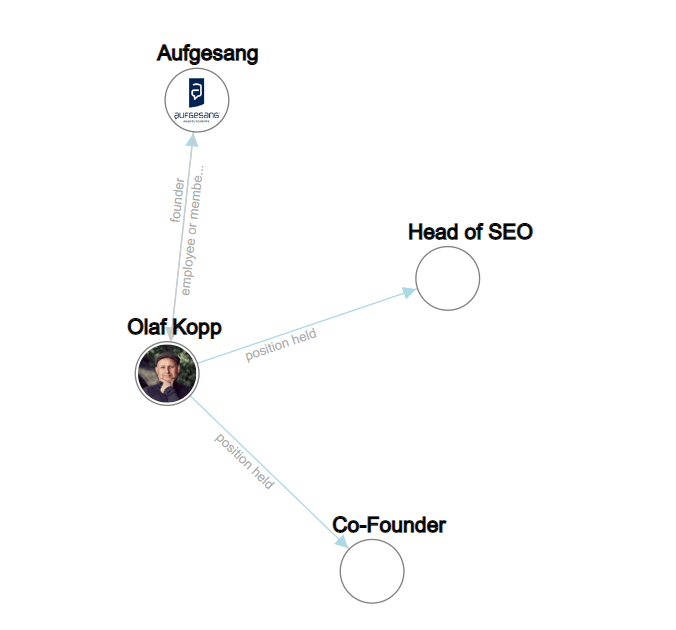
W poniższym przykładzie nazwy podmiotów to „olaf kopp”, „szef seo”, „współzałożyciel” i „aufgesang”. (NN = rzeczownik).
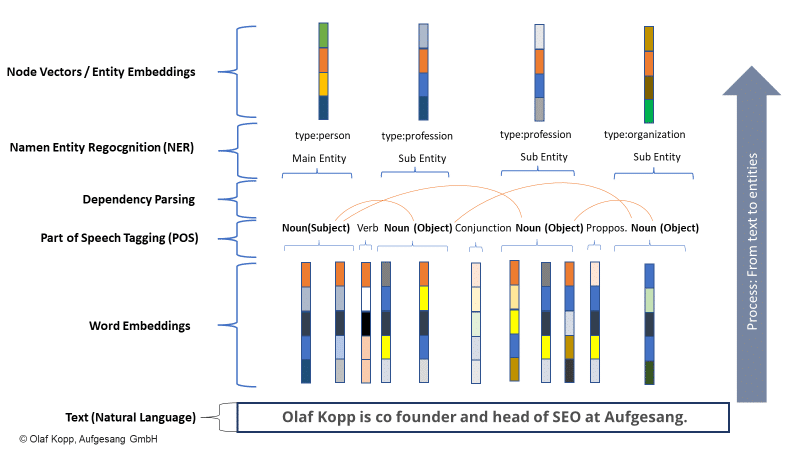
Przetwarzanie języka naturalnego może identyfikować jednostki i określać relacje między nimi.
Tworzy to przestrzeń semantyczną, która lepiej oddaje i rozumie koncepcję podmiotu.
Więcej na ten temat znajdziesz w artykule „Jak Google wykorzystuje NLP do lepszego zrozumienia zapytań i treści”.
Odpowiednikiem osadzania autora jest osadzanie dokumentu. Osadzone dokumenty są porównywane z wektorami autora za pomocą analizy przestrzeni wektorowej. (Więcej informacji można znaleźć w patencie Google „Generowanie reprezentacji wektorowych dokumentów”).
Wszystkie typy treści mogą być reprezentowane jako wektory, co pozwala na:
- Wektory treści i wektory autorów do porównania w przestrzeniach wektorowych.
- Dokumenty mają być grupowane według podobieństwa.
- Autorzy do przypisania.
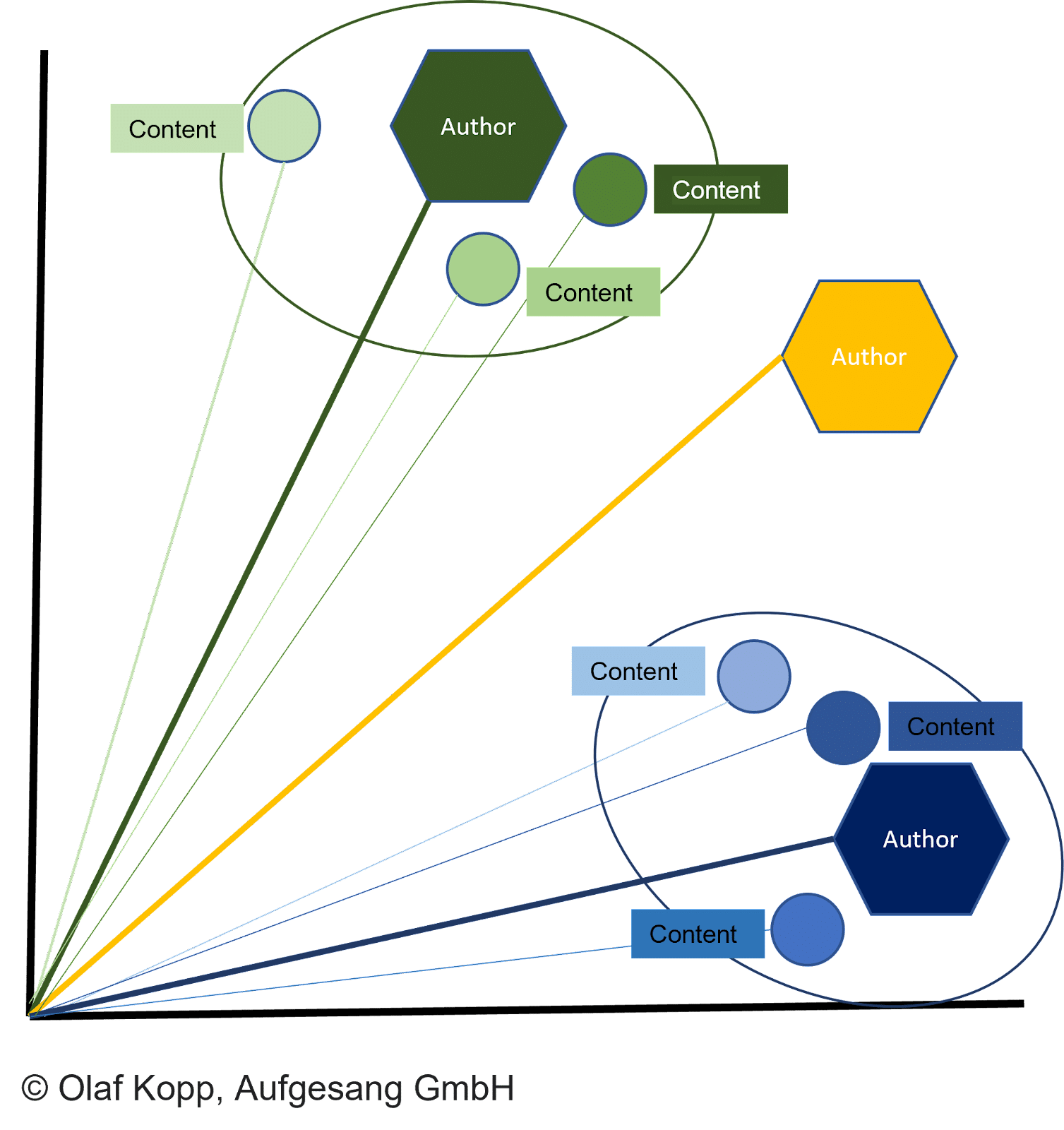
Odległość między wektorami dokumentu a odpowiednim wektorem autora opisuje prawdopodobieństwo, że autor stworzył dokumenty.
Dokument jest przypisywany autorowi, jeśli odległość jest mniejsza niż inne wektory i osiągnięty został określony próg.
Może to również zapobiec utworzeniu dokumentu pod fałszywą flagą. Wektor autora można następnie przypisać do podmiotu autora, jak już opisano, używając nazwiska autora określonego w treści.
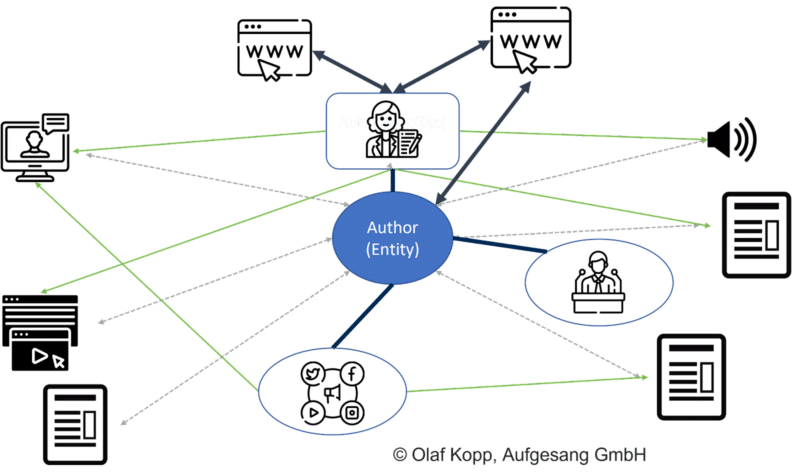
Do ważnych źródeł informacji o autorach należą:
- Wikipedia Artykuły o osobie.
- Profile autorów.
- Profile głośników.
- Profile w mediach społecznościowych.
Jeśli wpiszesz w Google nazwisko osoby typu podmiot, w pierwszych 20 wynikach wyszukiwania znajdziesz wpisy z Wikipedii, profile autora i adresy URL domen bezpośrednio powiązanych z autorem.
W mobilnych SERPach możesz zobaczyć, które źródła Google nawiązuje bezpośrednią relację z jednostką osobową.
Google rozpoznał wszystkie wyniki nad ikonami profili społecznościowych jako źródła z bezpośrednim odniesieniem do podmiotu.

Ten zrzut ekranu zapytania wyszukiwania „olaf kopp” pokazuje, że podmioty są powiązane ze źródłami.
Wyświetla również nowy wariant panelu wiedzy. Wygląda na to, że stałem się częścią beta testów tutaj.
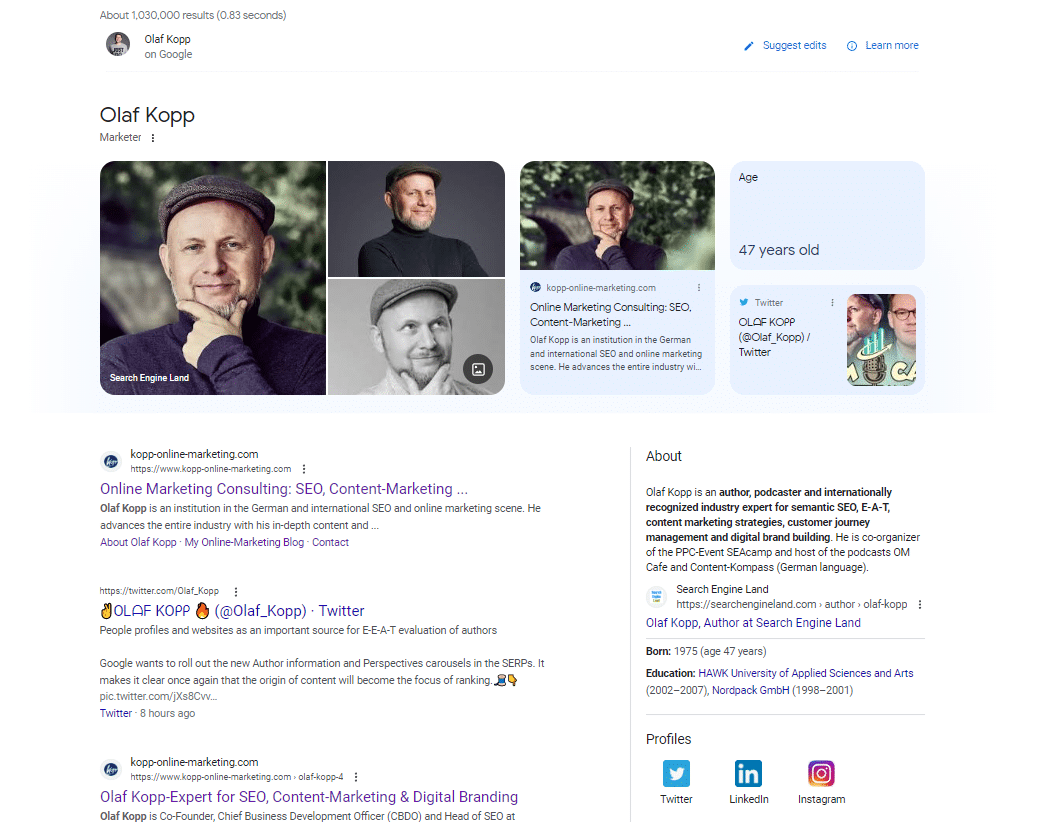
Na tym zrzucie ekranu zobaczysz, że oprócz obrazów i atrybutów (wiek), Google bezpośrednio powiązał moją domenę i profil w mediach społecznościowych z moim podmiotem i udostępnia je w panelu wiedzy.
Ponieważ nie ma o mnie artykułu w Wikipedii, opis O mnie pochodzi z profilu autora w Search Engine Land w USA i profilu autora na stronie agencji w Niemczech.
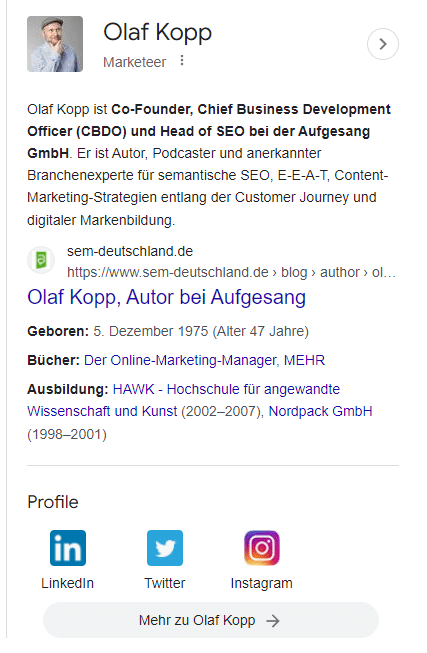
Profile osobiste w internecie pomagają Google umieszczać autorów w kontekście oraz identyfikować profile i domeny w mediach społecznościowych powiązane z autorem.
Pola autorów lub kolekcje autorów w profilach autorów pomagają Google przypisywać treści autorom. Nazwisko autora jest niewystarczające jako identyfikator, ponieważ mogą pojawić się niejasności.
Należy zwracać uwagę na opisy wszystkich autorów, aby zapewnić spójność. Google może ich użyć do sprawdzenia ważności podmiotu w porównaniu do siebie.
Otrzymuj codzienny biuletyn wyszukiwania, na którym polegają marketerzy.
Zobacz warunki.
Ciekawe patenty Google na ocenę autorów EEAT
Poniższe patenty dają wgląd w możliwe metodologie, w jaki Google identyfikuje autorów, przypisuje im treści i ocenia je pod kątem EEAT.
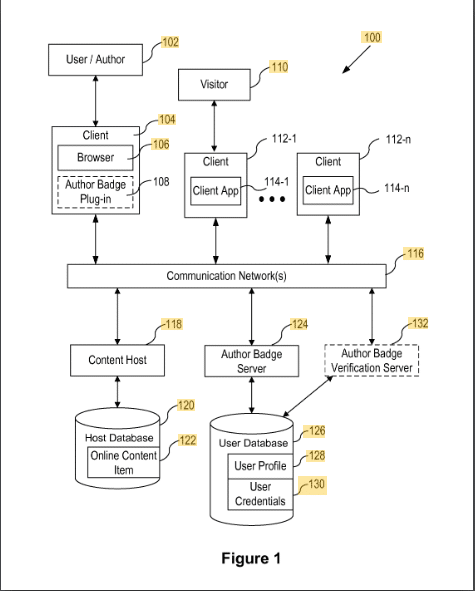
Odznaki autora treści
Ten patent opisuje, w jaki sposób treść jest przypisywana autorom za pomocą plakietki.

Treść jest przypisywana do plakietki autora za pomocą identyfikatora, takiego jak adres e-mail lub nazwisko autora. Weryfikacja odbywa się za pomocą dodatku w przeglądarce autora.
Generowanie wektorów autorskich
Google podpisał ten patent w 2016 r. na okres do 2036 r. Jednak zgłoszenia patentowe złożono tylko w USA, co sugeruje, że nie jest on jeszcze używany w wyszukiwarkach Google na całym świecie.
Patent opisuje, w jaki sposób autorzy są reprezentowani jako wektory na podstawie danych treningowych.
Wektor staje się unikalnymi parametrami identyfikowanymi na podstawie typowego stylu pisania autora i doboru słów.
W ten sposób można do nich przypisać treści, które nie zostały wcześniej przypisane autorowi, lub pogrupować podobnych autorów w klastry.
Ranking treści można następnie dostosować dla jednego lub większej liczby autorów na podstawie zachowania użytkownika w przeszłości podczas wyszukiwania (na przykład w Discover).
W związku z tym treści od autorów, których już odkryto, oraz treści autorstwa podobnych autorów będą miały wyższą pozycję w rankingu.
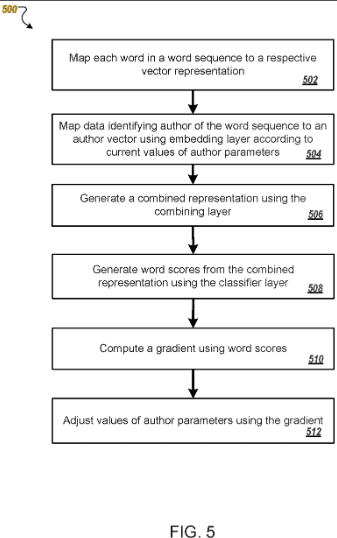
Ten patent opiera się na tak zwanych osadzaniach, takich jak autorzy i osadzania słów.
Obecnie osadzanie jest standardem technologicznym w głębokim uczeniu się i przetwarzaniu języka naturalnego.
Dlatego oczywiste jest, że Google takie metody będą również wykorzystywane do rozpoznawania i atrybucji autorów.
Ocena reputacji autora
Ten patent został po raz pierwszy podpisany przez Google w 2008 r. i ma minimalny okres obowiązywania 2029 r. Ten patent pierwotnie odnosi się do dawno zamkniętego projektu Google Knol.
Dlatego tym bardziej ekscytujące jest to, dlaczego Google zwróciło to ponownie w 2017 roku pod nowym tytułem Zarabianie na treściach online. Knol został zamknięty przez Google w 2012 roku.
Patent dotyczy określenia wyniku reputacji. W tym celu można wziąć pod uwagę następujące czynniki:
- Poziom kadru autora.
- Publikacje w renomowanych mediach.
- Liczba publikacji.
- Wiek ostatnich wydań.
- Jak długo autor oficjalnie pracuje jako autor.
- Liczba linków generowanych przez treść autora.
Autor może mieć wiele punktów reputacji na temat i mieć kilka aliasów na obszar tematyczny.
Wiele punktów poruszonych w patencie dotyczy zamkniętej platformy, takiej jak Knol. Dlatego ten patent powinien w tym momencie wystarczyć.
Ranga agenta
Ten patent Google został po raz pierwszy podpisany w 2005 roku i ma minimalny okres obowiązywania do 2026 roku.
Oprócz USA został zarejestrowany również w Hiszpanii, Kanadzie i na całym świecie, co sprawia, że prawdopodobnie będzie używany w wyszukiwarce Google.
Patent opisuje, w jaki sposób treści cyfrowe są przypisywane agentowi (wydawcy i/lub autorowi). Ta zawartość jest uszeregowana między innymi na podstawie rangi agenta.
Ranking agenta jest niezależny od intencji wyszukiwania zapytania i jest określany na podstawie dokumentów przypisanych do agenta i ich linków zwrotnych.
Ranking agenta odnosi się wyłącznie do jednego zapytania, grupy zapytań lub całych obszarów tematycznych.
„Range agentów można opcjonalnie obliczać w odniesieniu do wyszukiwanych haseł lub kategorii wyszukiwanych haseł. Na przykład wyszukiwane hasła (lub ustrukturyzowane zbiory wyszukiwanych haseł, tj. zapytania) można podzielić na tematy, np. specjalizacje sportowe lub medyczne, a agent może mieć inną rangę w odniesieniu do każdego tematu.
Wiarygodność autora treści internetowych
Ten patent Google został po raz pierwszy podpisany w 2008 r. i ma minimalny okres obowiązywania 2029 r., a do tej pory został zarejestrowany tylko w USA.
Justin Lawyer opracował go w taki sam sposób, jak Wynik Reputacji Patentowej autora i jest bezpośrednio związany z wykorzystaniem w wyszukiwaniach.
W patencie można znaleźć podobne punkty jak we wspomnianym wyżej patencie.
Dla mnie to najbardziej ekscytujący patent na ocenianie autorów pod kątem zaufania i autorytetu.
Ten patent odnosi się do różnych czynników, które można wykorzystać do algorytmicznego określenia wiarygodności autora.
Opisuje, w jaki sposób wyszukiwarka może uszeregować dokumenty pod wpływem współczynnika wiarygodności autora i wyniku reputacji.
Autor może mieć wiele punktów reputacji w zależności od liczby różnych tematów, na które publikuje treści.
Ocena reputacji autora jest niezależna od wydawcy.
Ponownie w tym patencie znajduje się odniesienie do linków jako możliwego czynnika w ocenie EEAT. Liczba linków do opublikowanych treści może mieć wpływ na ocenę reputacji autora.
Wymieniono następujące możliwe sygnały dotyczące wyniku reputacji:
- Jak długo autor tworzy treści w danej dziedzinie.
- Świadomość autora.
- Oceny opublikowanych treści przez użytkowników.
- Jeśli inny wydawca publikuje autorskie treści z ponadprzeciętnymi ocenami.
- Ilość treści opublikowanych przez autora.
- Jak dawno temu autor ostatnio opublikował.
- Oceny poprzednich publikacji autora na podobny temat.
Inne ciekawe informacje o punktacji reputacji z patentu:
- Autor może mieć wiele punktów reputacji w zależności od liczby różnych tematów, na które publikuje treści.
- Ocena reputacji autora jest niezależna od wydawcy.
- Ocena reputacji może zostać obniżona, jeśli powielone treści lub fragmenty zostaną opublikowane wiele razy.
- Liczba linków do publikowanych treści może wpływać na ocenę reputacji.
Ponadto patent odnosi się do czynnika wiarygodności autorów. Wymieniono następujące czynniki wpływające:
- Zweryfikowane informacje o zawodzie lub roli autora w firmie. Bierze również pod uwagę wiarygodność firmy.
- Związek zawodu z tematyką publikowanych treści.
- Poziom wykształcenia i wyszkolenia autora.
- Doświadczenie autora na podstawie czasu. Im dłużej autor publikuje na dany temat, tym bardziej jest wiarygodny. Doświadczenie autora/wydawcy można określić algorytmicznie dla Google na podstawie daty pierwszej publikacji w danej dziedzinie.
- Liczba opublikowanych treści na dany temat. Jeśli autor publikuje wiele artykułów na dany temat, można założyć, że jest ekspertem i ma pewną wiarygodność.
- Czas, który upłynął do ostatniego wydania. Im więcej czasu minęło od ostatniej publikacji autora na dany temat, tym bardziej spada możliwa ocena reputacji dla tego tematu. Im bardziej aktualna jest treść, tym jest wyższa.
- Wzmianki o autorze/wydawcy na listach nagród i najlepszych.
Systemy i metody re-rankingu wyników wyszukiwania w rankingu
Ten patent Google został po raz pierwszy podpisany w 2013 roku i ma minimalny okres obowiązywania do 2033 roku. Został zarejestrowany w USA i na całym świecie, co sprawia, że Google prawdopodobnie będzie z niego korzystać.
Wśród wynalazców patentu jest Chung Tin Kwok, który był zaangażowany w kilka patentów Google związanych z EEAT.
Patent opisuje, w jaki sposób wyszukiwarki, oprócz odniesień do treści autora, mogą również uwzględniać proporcję, jaką może on wnieść do korpusu dokumentów tematycznych w punktacji autora.
„W niektórych przykładach wykonania określenie oryginalnego wyniku autora dla odpowiedniej jednostki obejmuje: identyfikację wielu części treści w indeksie znanych treści zidentyfikowanych jako powiązane z odpowiednią jednostką, przy czym każda część z wielu części reprezentuje z góry określoną ilość danych w indeksie znanej treści oraz obliczanie procentu z wielu części, które są pierwszymi wystąpieniami części zawartości w indeksie znanej treści”.
Opisuje zmianę rankingu wyników wyszukiwania na podstawie punktacji autora, w tym punktacji cytowań. Punktacja cytowań opiera się na liczbie odniesień do dokumentów autora.
Innym kryterium oceny autorów jest odsetek treści, które autor wniósł do korpusu dokumentów tematycznych.
„[W] niniejszym dokumencie określenie oceny autora dla odpowiedniego podmiotu obejmuje: określenie wyniku cytowania dla odpowiedniego podmiotu, przy czym wynik cytowania odpowiada częstotliwości, z jaką cytowana jest treść powiązana z odpowiednim podmiotem; określenie pierwotnego wyniku autora dla odpowiedniego podmiotu, w którym wynik oryginalnego autora odpowiada procentowi treści powiązanej z odpowiednim podmiotem, który jest pierwszym wystąpieniem treści w indeksie znanych treści; oraz połączenie wyniku cytowania i wyniku oryginalnego autora przy użyciu z góry określonej funkcji w celu uzyskania nota autorska”.
Patent ma na celu identyfikowanie „naśladowców” i degradowanie ich treści w rankingach, ale może też służyć do ogólnej oceny autorów.
Kluczowe czynniki oceny autora
Oprócz możliwych czynników oceny autora wymienionych w powyższych patentach, oto kilka innych do rozważenia (niektóre z nich wymieniłem już w moim artykule „14 sposobów, w jakie Google może ocenić EAT”).
- Ogólna jakość treści na dany temat: Jakość, jaką autor dostarcza na temat swoich treści na temat jako całości, niezależnie od domeny i formatu, może być czynnikiem wpływającym na EEAT. Sygnałami do tego mogą być sygnały użytkownika, linki i inne sygnały jakości na poziomie treści.
- PageRank lub odniesienia do treści autora.
- Współwystępowanie autora w treści (podcasty, filmy, strony internetowe, pliki PDF, książki) z odpowiednimi tematami lub terminami.
- Współwystępowanie autora w wyszukiwanych hasłach z odpowiednimi tematami lub terminami.
Stosowanie EEAT do podmiotów autorskich
Metody uczenia maszynowego umożliwiają rozpoznawanie i mapowanie struktur semantycznych z treści nieustrukturyzowanych na dużą skalę.
Dzięki temu Google może rozpoznać i zrozumieć o wiele więcej podmiotów niż wcześniej pokazano na Grafie wiedzy.
W rezultacie coraz większą rolę odgrywa źródło treści. EEAT może być algorytmicznie stosowany poza dokumentami, treścią i domeną.
Pojęcie może również obejmować podmioty będące autorami treści (tj. autorów i organizacje odpowiedzialne za treść).
Myślę, że w ciągu najbliższych kilku lat zobaczymy jeszcze bardziej znaczący wpływ EEAT na wyszukiwarkę Google. Czynnik ten może być nawet tak samo ważny dla rankingu, jak optymalizacja trafności poszczególnych treści.
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.