
Jak w pełni wykorzystać interfejs API Google Search Console za pomocą wyrażenia regularnego?
Opublikowany: 2022-11-02Google Search Console to niesamowite narzędzie, które dostarcza bezcenne dane wyszukiwania przez prawdziwych użytkowników bezpośrednio z Google. Chociaż wykresy i tabele są przyjazne w obsłudze, duża część danych nie jest dostępna z interfejsu użytkownika.
Jedynym sposobem na dotarcie do tych ukrytych danych jest skorzystanie z interfejsu API i wyodrębnienie wszystkich cennych danych wyszukiwania, które są dla Ciebie dostępne – jeśli wiesz jak. Jest to możliwe dzięki wyrażeniom regularnym.
Oto, jak zmaksymalizować interfejs API Google Search Console za pomocą wyrażeń regularnych, według Erica Wu, wiceprezesa ds. wzrostu produktu w Honey, firmie PayPal, który przemawiał na SMX Advanced.
Diagnozowanie problemów z SEO za pomocą GSC
Pracujesz na stronie internetowej, która przeżywa stagnację lub spadek wzrostu lub spadek aktualizacji rdzenia?
Większość specjalistów SEO zwraca się do Google Search Console (GSC), aby zdiagnozować takie problemy.
(Lub, jeśli pozwalają na to zasoby, możesz nawet użyć płatnego narzędzia, takiego jak Ryte, lub zbudować własną platformę.)
Na szczęście dla społeczności SEO nie brakuje pulpitów nawigacyjnych Looker Studio (wcześniej Google Data Studio) przydatnych do analizy GSC, w tym:
- Bezpłatny pulpit nawigacyjny Aleyda Solis, który wykorzystuje dane GSC do łatwej identyfikacji potencjalnych zmian w rankingu w ostatnich dniach od aktualizacji Google Core.
- Panel monitorowania ruchu w sieci wyszukiwania Google, który teraz pobiera dane o ruchu w Discover i Google News.
- Search Console Explorer Studio Hannah Butler. (A jeśli chcesz bezpośrednio manipulować danymi GSC i szybko uzyskiwać informacje, możesz skorzystać z arkusza Eksploratora Search Console Butlera).
Pulpity nawigacyjne umożliwiają SEO przeglądanie różnych trendów w przeciwieństwie do korzystania z GSC i wykonywania wielu kliknięć w celu uzyskania potrzebnych danych.
Ale jeśli analizujesz witryny firmowe, możesz napotkać pewne przeszkody.
- Zarówno Looker Studio, jak i Arkusze Google ładują się powoli, zwłaszcza gdy masz do czynienia z dużymi witrynami.
- Interfejs GSC ma limit eksportu do 1000 wierszy.
- GSC ma ogromny problem z próbkowaniem. Według Similar.ai zespoły Enterprise SEO pomijają 90% słów kluczowych GSC. A jeśli wiesz, jak wyodrębnić dane, możesz uzyskać 14 razy więcej słów kluczowych.
Przezwyciężenie problemu z próbkowaniem GSC
Explorer for Search to kolejne narzędzie, którego możesz użyć do analizy GSC. Opracowany przez Noah Learnera i zespół Two Octobers opiera się na potokach danych przy użyciu interfejsu API GSC, który następnie przesyła dane do BigQuery (zasadniczo z pominięciem Arkuszy Google i pobierania plików CSV), a następnie wizualizuje informacje za pomocą Data Studio.
Dzięki temu możesz mieć pewność, że docierasz do prawie wszystkich danych.
Nadal istnieje pewne zastrzeżenie z powodu problemu z próbkowaniem GSC, szczególnie w przypadku dużych witryn e-commerce z wieloma różnymi kategoriami. GSC niekoniecznie pokaże wszystkie dane przychodzące z tych katalogów.
Po przeprowadzeniu różnych testów, aby uzyskać jak najwięcej danych z interfejsu API GSC, zespół Similar.ai odkrył sposób na wypełnienie luki w próbkowaniu GSC.
Odkryli, że dodając więcej podkatalogów jako różnych profili w panelu GSC, możesz wyodrębnić jeszcze więcej danych, ponieważ Google dostarcza więcej informacji na tym niższym poziomie.
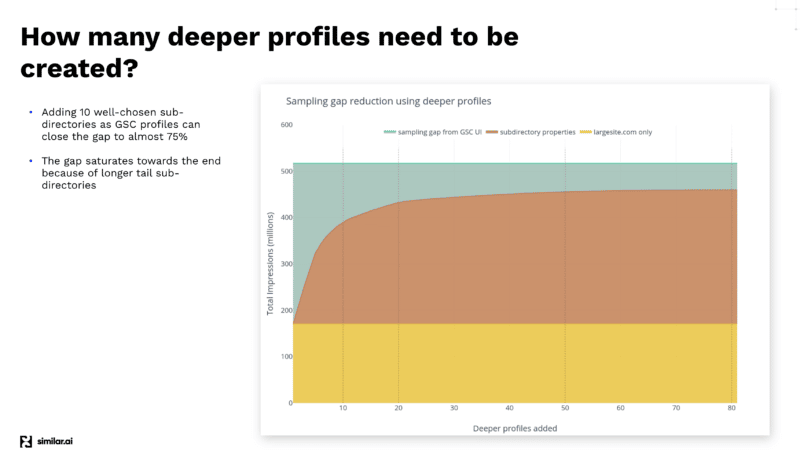
Na przykład, jeśli patrzysz na example.com/televisions i dodajesz „telewizje” jako podkatalog w swoim profilu GSC, Google poda Ci tylko słowa kluczowe i informacje o kliknięciach dla tego podkatalogu i w dół.
A dodając wiele różnych podkatalogów, możesz wyodrębnić znacznie więcej informacji.
To rozwiązuje problem próbkowania, ale możesz uzyskać jeszcze więcej danych, używając wyrażeń regularnych.
Uzyskiwanie większej ilości danych GSC za pomocą wyrażeń regularnych
Wyrażenie regularne lub wyrażenie regularne to potężne narzędzie do zrozumienia danych.
W kwietniu 2021 r. Google dodał obsługę wyrażeń regularnych do GSC – dając SEO więcej sposobów na wycinanie i dzielenie organicznych danych wyszukiwania.
Wiele razy dane nie są przydatne, chyba że możesz je zrozumieć. A regex pomaga wydobyć praktyczne spostrzeżenia z bogatych danych GSC.
Ale jakkolwiek potężny może być, regex może być trudny do nauczenia.
Najlepszym miejscem do zrozumienia i zagłębienia się w wyrażenia regularne jest oficjalna dokumentacja Google na GitHub. (Google używa w swoich produktach RE2, co jest posmakiem wyrażenia regularnego).
Chociaż wyrażenie regularne jest dostępne we wszystkich rodzajach różnych języków programowania, znajdziesz je prawie wszędzie, nawet dla tych, którzy modyfikują pliki .htaccess.
W kilku następnych sekcjach znajdują się przypadki użycia lewarowania wyrażenia regularnego dla GSC.
Zapytania informacyjne o wyrażeniach regularnych
Patrząc na rzeczywiste zapytania informacyjne w GSC, zazwyczaj chcesz zrozumieć:
- W jaki sposób ludzie faktycznie przychodzą do Twojej witryny?
- Jakie pytania wyciągają?
Spojrzenie na te rzeczy z jednorazowego punktu widzenia w GSC może być trudne.
Zawsze szukasz słów „co”, „jak”, „dlaczego”, a następnie „kiedy”.
Istnieje kilka sposobów na to, aby wyodrębnianie zapytań informacyjnych było mniej żmudne za pomocą wyrażenia regularnego.
Daniel K. Cheung udostępnił ciąg regex, który pokaże wszystkie zapytania zawierające „co”, „jak”, „dlaczego” i „kiedy”, które uzyskały kliknięcie lub wyświetlenie:
-
"what|how|why|when"
A ten ciąg regex udostępniony przez Steve'a Totha podnosi poprzedni przykład o wyższy poziom:
-
^(who|what|where|when|why|how)[" "]
Możesz użyć tego ciągu, jeśli chcesz przechwytywać zapytania oparte na pytaniach, które zaczynają się od „kto”, „co”, „gdzie”, „kiedy”, „dlaczego” i „jak”, po których następuje spacja.
To świetna lista do wykorzystania, gdy szukasz dowolnego rodzaju słowa, które mogłoby rozpocząć pytanie:
- są, mogą, nie mogą, mogły, nie mogły, zrobiły, nie zrobiły, nie zrobiły, były, nie były, co, kiedy, gdzie, kto, kogo, czyj, dlaczego, będzie, nie będzie, nie chciał, nie chciał
Umieszczenie tego wszystkiego w formie wyrażeń regularnych wyglądałoby mniej więcej tak:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
W tym 178-znakowym ciągu:
- Masz karetkę (
^), która mówi, że zapytanie musi zaczynać się od tego słowa: - Słowa są oddzielone kreskami (
|) zamiast przecinkami. - Wszystkie słowa są ujęte w nawiasy.
- Jest ukośnik odwrotny i „s” (
\s), które oznaczają spację po słowie.
To jest dobre, ale może też być nużące.
Poniżej Wu uprościł poprzednią listę słów, aby była bardziej przyjazna dla wyrażeń regularnych i krótsza, co jest idealne do kopiowania i wklejania. Utrzymanie go w ten sposób pomaga również w wydajności.
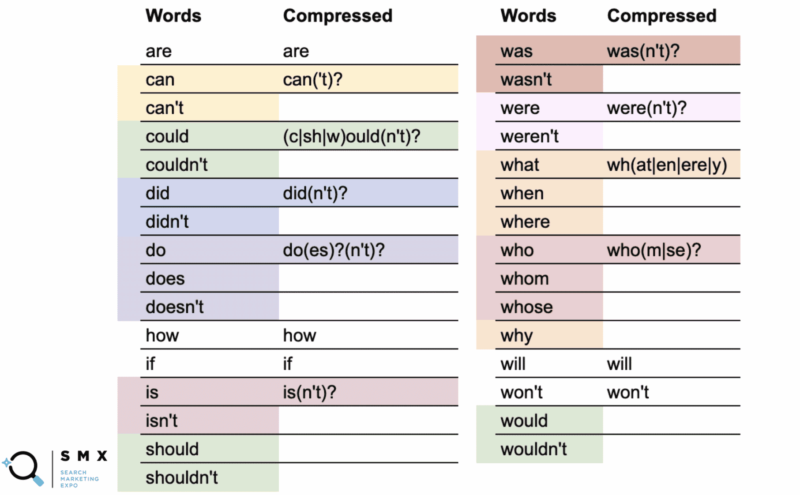
W pierwszej kolumnie znajdują się zwykłe słowa, aw drugiej skompresowane wyrażenie regularne.
Na przykład słowo „can” używa wersji skompresowanej can('t)? .
Znak zapytania wskazuje, że wszystko w nawiasach jest opcjonalne. Skompresowana składnia pozwala objąć zarówno słowo „można”, jak i „nie mogę”.
Co ciekawsze, możesz to zrobić za pomocą opcji Mogę/Nie, Powinienem/Nie powinienem i Nie zrobiłbym tego, gdy część -ould słów jest wspólną podstawą, np. (c|sh|w)ould(n't)? . Ten krótki ciąg obejmuje wszystkie sześć z tych przypadków.
Podczas gdy uproszczenie tej długiej listy słów sprawiło, że ciąg jest mniej czytelny, wspaniałe jest to, że pasuje on bardziej do pola regex i umożliwia łatwiejsze kopiowanie i wklejanie.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Jeśli pójdziesz o krok dalej, możesz skompresować go jeszcze bardziej. W tym przypadku Wu zmniejszył liczbę znaków ze 135 do 113 znaków.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Wyrażenia regularne mogą być naprawdę skomplikowane. Jeśli otrzymujesz ciąg regex od kogoś innego i chciałbyś odróżnić, co robi, możesz użyć Regexper, aby pomóc sobie to zwizualizować.
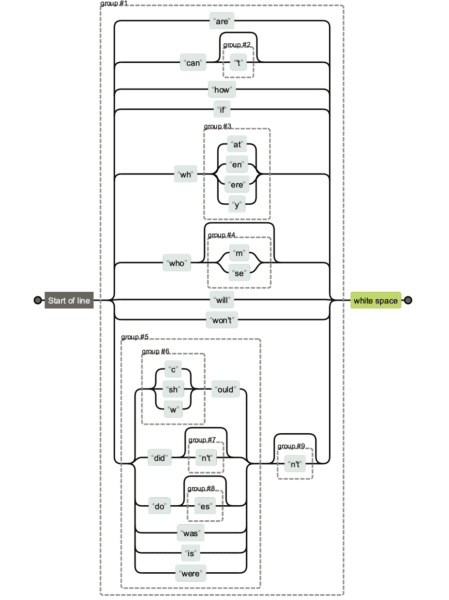
Poniżej zobaczysz porównanie różnych wersji ciągów regularnych. Łatwiej jest utrzymać pierwszy i oczywiście trudniej utrzymać i czytać ostatni.

Ale czasami liczba znaków naprawdę ma znaczenie, zwłaszcza gdy masz dłuższe wyrażenia regularne.
Według rzecznika wyszukiwarki Google Daniela Waisberga limity filtra Regex dla GSC to 4096 znaków.
Wydaje się, że to całkiem sporo. Jeśli jednak masz witrynę e-commerce i musisz dodać nazwy domen, subdomeny lub dłuższe katalogi, najprawdopodobniej osiągniesz ten limit.
Zapytania marki Regex
Innym przypadkiem, w którym możesz zacząć osiągać limit znaków regex w GSC, jest użycie go do zapytań związanych z marką.
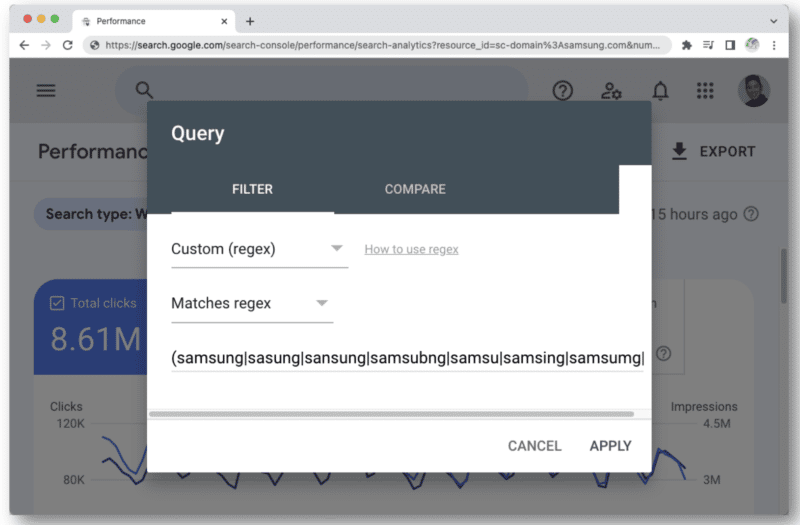
Kiedy myślisz o wszystkich rodzajach błędów pisowni nazwy marki, które dana osoba może wpisać, szybko natkniesz się na liczbę 4096 znaków. Na przykład:
- aamaung, damsung, mamsang, sam sung, samaung, samdung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag, samsubg, samsubng, samsug, samsug, , samsun g, samsunb, samsund, samsund, samsunh, samsunt…
W tym właśnie pomaga zrozumienie wyrażenia regularnego. Za pomocą tego ciągu możesz uchwycić nazwę marki „samsung” wraz z błędami pisowni:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Często zdarza się, że ludzie błędnie wpisują środkowe części słowa. Ale ogólnie rzecz biorąc, mają prawidłowy format i długość, dzięki czemu możesz podejść do swojej składni w ten sposób.
W przypadku błędów pisowni w zapytaniu dotyczącym marki rozważ następujące kwestie:

- Główne litery tworzące zapytanie o markę.
- Spółgłoski .
- Litery otaczające twarde spółgłoski .

Na czerwono znajdują się twarde spółgłoski, których ludzie zwykle nie tęsknią, gdy wpisują nazwę marki. To są główne litery, które składają się na tę konkretną markę. W przypadku „samsung” „s” na początku, „m” w środku, a następnie „n” i „g” na końcu.
Niebieskie litery otaczające te główne spółgłoski na klawiaturze to te, które ludzie zazwyczaj błędnie wpisują. W przykładzie wokół „s” widzisz „a”, „d” i „z”. (Chociaż układ jest inny dla międzynarodowych klawiatur, koncepcja jest nadal taka sama.)
Powyższy ciąg regex przechwytuje wszystkie możliwe warianty „samsunga”.
Inna ważna sztuczka znajduje się w [az\s]{1,4} .
W formie wyrażeń regularnych to w zasadzie mówi: „Chcę dopasować dowolną literę „a” do „z” lub spację od jednego do czterech razy.
Przechwytuje to wszystkie dziwne błędy pisowni, które mogą się zdarzyć w środku zapytania dotyczącego marki – gdy dana osoba może potencjalnie kilkakrotnie nacisnąć ten sam klawisz lub przypadkowo nacisnąć spację.
Dodatkowo nazwa marki ma określoną długość („samsung” ma siedem znaków). Ludzie prawdopodobnie nie napiszą 20-50 znaków.
W tym wyrażeniu regularnym zgadujemy, że między „s” i „m” w „samsung” ktoś błędnie wpisze 1–4 znaki. A potem od „m” do „g” na końcu będą błędnie wpisywać 1–6 znaków, ze spacjami.
Dodanie tego wszystkiego umożliwia kompleksowe uchwycenie wielu odmian zapytania markowego.
Inną rzeczą, na którą należy zwrócić uwagę, jest to, że nazwa marki może pojawić się w różnych częściach zapytania.

Musimy więc upewnić się, że sama nazwa marki jest uchwycona. Powinno to być:
- Na początku zapytania.
- W środku zapytania (więc otoczone spacjami).
- Lub na końcu zapytania.
Wyrażenie regularne dla tego jest następujące:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Przechwytuje to wszystkie zapytania, w których nazwa marki „samsung” znajduje się na początku, w środku lub na końcu.
- Początek ciągu =
^ - Otoczony spacjami =
\s - Koniec ciągu =
$
Post JC Chouinarda, Regular Expressions (RegEx) w Google Search Console, zagłębia się jeszcze głębiej w przykłady regexów.
Regex i GSC API w akcji
Wyrażenia regularne przydały się Wu i jego zespołowi, gdy pracowali z klientem, który napotkał spadki ruchu po aktualizacji rdzenia.
Po przyjrzeniu się różnym problemom w witrynie e-commerce odkryli, że problem dotyczył niektórych stron ze szczegółami produktów.
Musieli segmentować typy stron do analizy w GSC. Było to jednak złożone zadanie ze względu na różne struktury adresów URL dla produktów amerykańskich i międzynarodowych.

Międzynarodowe adresy URL produktów w witrynie zawierały kody języka i kraju, podczas gdy adresy URL produktów w Stanach Zjednoczonych nie zawierały.
Nawet użycie składni regex było trudne, ponieważ litery i myślniki istnieją w slug produktu, kategoriach i podkategoriach. Dodatkowo musieli odfiltrować międzynarodowe adresy URL produktów, aby przechwytywać tylko strony z USA.
Aby uzyskać wszystkie strony docelowe + strony ze szczegółami produktów w USA ( nie strony i18n), wymyślili następujące ciągi wyrażeń regularnych:
Uwzględnij: /([^/]+/){1,2}p?
Wyklucz: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Oto podział:

Zespół chciał dopasować kategorię, podkategorię i wszystkie produkty, więc zawierały:
- Dowolny znak, który nie jest ukośnikiem =
[^/]+ - 1 lub 2 katalogi =
/){1,2} - Czasami następuje slug produktu =
p?
Daszek ( ^ ) zazwyczaj oznacza początek ciągu. Ale kiedy znajduje się w nawiasach (tak jak w [^/] ), oznacza to negację (tj. „nic w tym polu”).
Więc ten ciąg /([^/]+/){1,2}p? oznacza „Chcę dowolną liczbę znaków, która nie jest ukośnikiem, prowadząca do ukośnika (oznaczającego katalog), a czasami poprzedzona literą „p” (przedrostek informacji o produkcie).”
Jednocześnie zespół nie chciał dopasować kombinacji kraju i języka, która również zawierała litery i myślniki, więc wykluczyli:
- Dowolny katalog dwuliterowy =
[a-zA-Z]{2} - Kombinacja 2-literowa + 2-literowa lang-kraj =
[a-zA-Z]{2}-[a-zA-Z]{2}
Tworzenie wyrażenia regularnego pasującego do wszystkich kodów języka i kraju byłoby żmudne ze względu na wszystkie możliwe kombinacje, więc nie byli w stanie podejść do tego w taki sposób, jak w przypadku zapytań informacyjnych (gdzie wykluczono każdy typ kombinacji).
Ale nawet po utworzeniu tych ciągów wyrażeń regularnych mieli problem.
W Google Search Console jest tylko jedno pole do wklejenia ciągu regularnego. Musisz wybrać opcję Pasuje do wyrażenia regularnego lub Nie pasuje do wyrażenia regularnego – nie możesz używać obu jednocześnie.
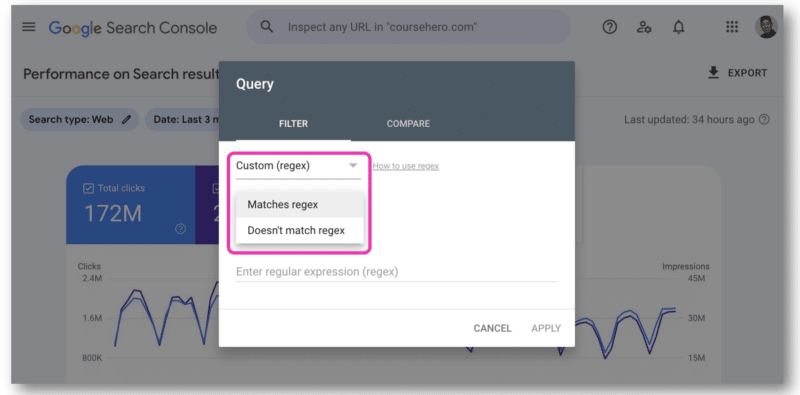
Tutaj przydał się interfejs API GSC, który umożliwia łączenie ciągów wyrażeń regularnych.
W dokumentacji interfejsu API Google Search Console znajduje się link Wypróbuj teraz .
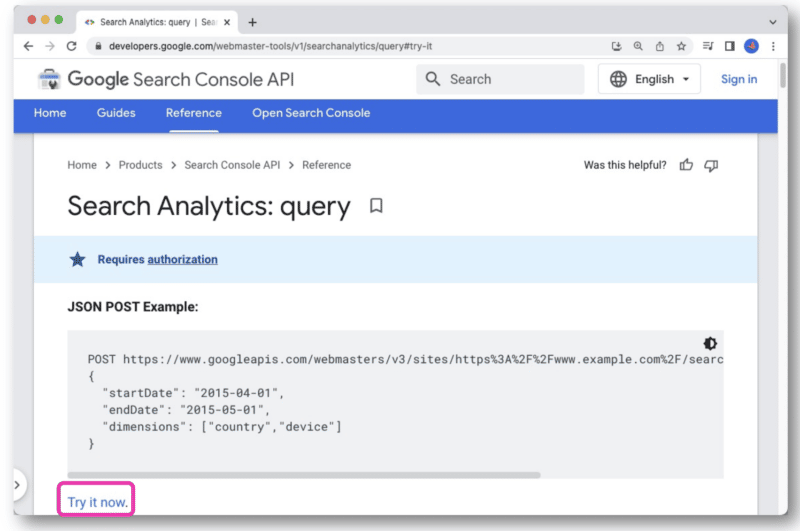
Po kliknięciu otworzy się konsola, która pozwala wybrać witrynę i wysłać żądanie API za pośrednictwem widoku internetowego.
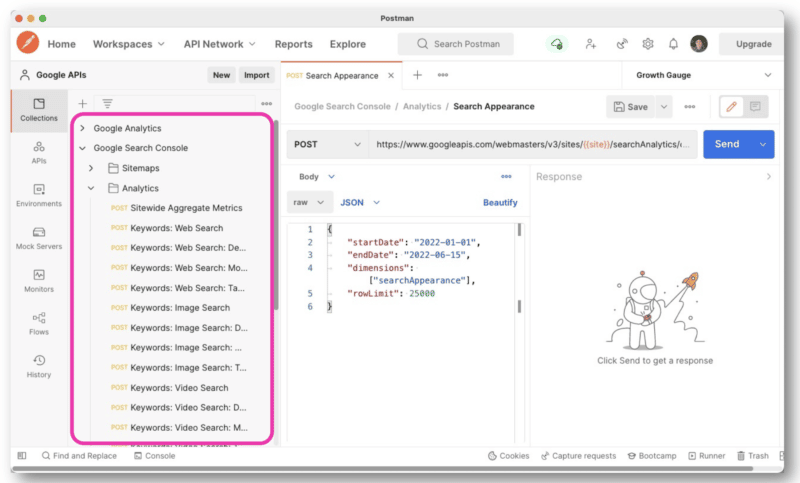
Ale aby lepiej zarządzać zapytaniami API, Wu zaleca używanie Postmana na pulpicie lub Paw (który jest natywny dla komputerów Mac).
Postman umożliwia tworzenie zapytań i zapisywanie ich na później. A jeśli masz dostęp do innych witryn, nie musisz za każdym razem tworzyć nowego zapytania. Po prostu zamień nazwę witryny ze zmienną, a następnie wyślij wiele żądań.
Z drugiej strony Łapa jest znacznie łatwiejsza do przejrzenia i wykorzystania.
Aby uzyskać dostęp do API, musisz uzyskać klucze API. (Oto pomocny samouczek od Chouinard.)
Gdy uzyskasz te informacje, będziesz mieć swój identyfikator klienta i klucze klienta, które dodasz do uwierzytelniania OAuth 2.0 w programie Postman lub Paw.
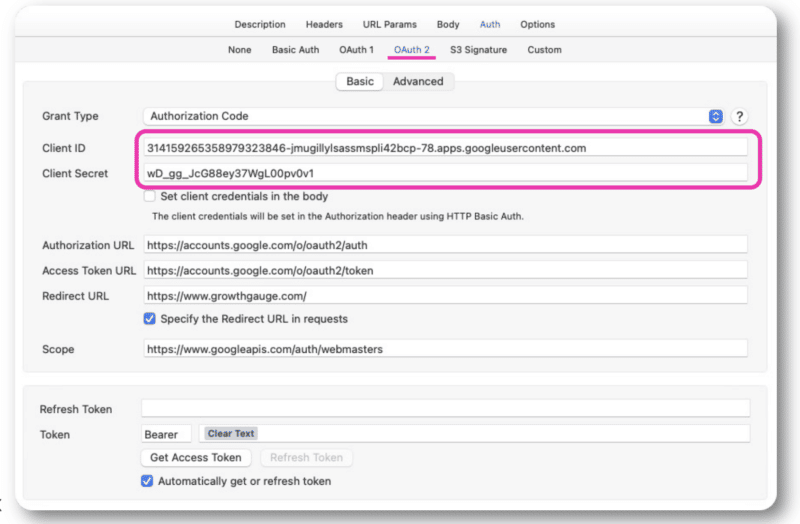
Stamtąd będziesz mógł zalogować się na swoje normalne konto.
Wu wykonywał głównie żądania GSC API przy użyciu ciągów wyrażeń regularnych w Paw. Zapytanie jest wprowadzane w środku interfejsu.
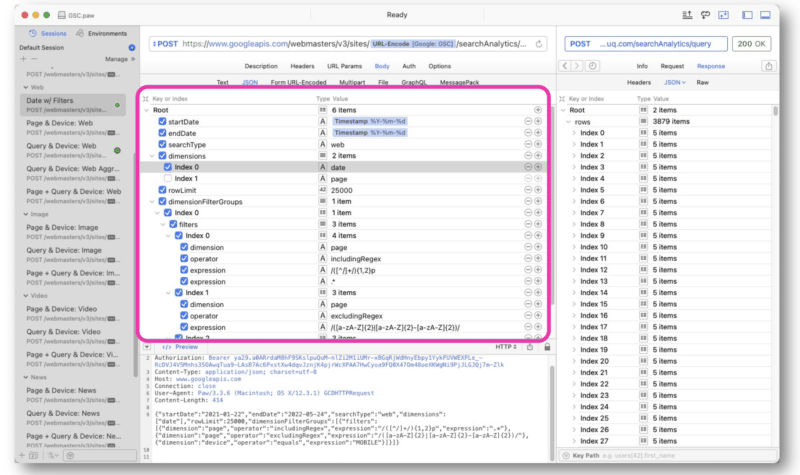
Odpowiedź Google jest podobna do odpowiedzi z widoku internetowego interfejsu GSC API. Dane można następnie wyeksportować w celu przetworzenia.
Ponieważ dane są w formacie JSON, informacje mogą być nieczytelne i trudne do odczytania.

W tym celu możesz użyć darmowego i otwartego procesora JSON wiersza polecenia o nazwie JQ, aby wydrukować informacje.

Dane nie są tak przydatne, dopóki nie umieścisz ich w arkuszu kalkulacyjnym. Pipe w pliku, który wyeksportowałeś z Paw do JQ. Otwórz go, a następnie przeprowadź iterację w każdym rzędzie — zapisując każdy element, aby można go było wyprowadzić do pliku CSV.
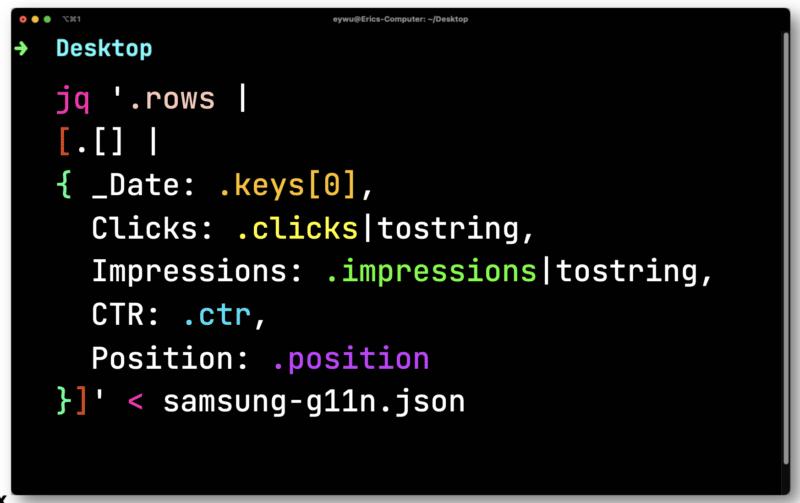
Tutaj musisz przeliczyć kliknięcia i wyświetlenia, które są zmiennoprzecinkowe (liczba z miejscem dziesiętnym). Oba muszą zostać przekonwertowane na ciągi zgodne z CSV.
JQ następnie wypisze następujący, znacznie prostszy format.
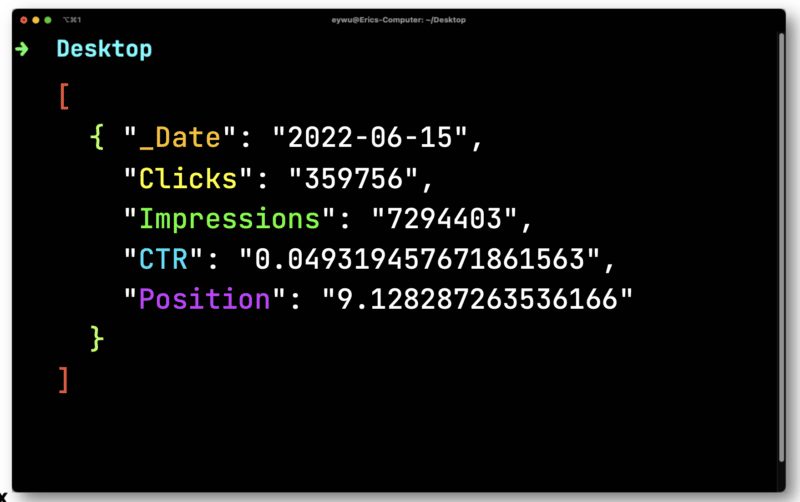
Następnie użyjesz Dasel, aby wziąć ten format, a następnie przekształcić go w CSV.
A oto efekt końcowy.
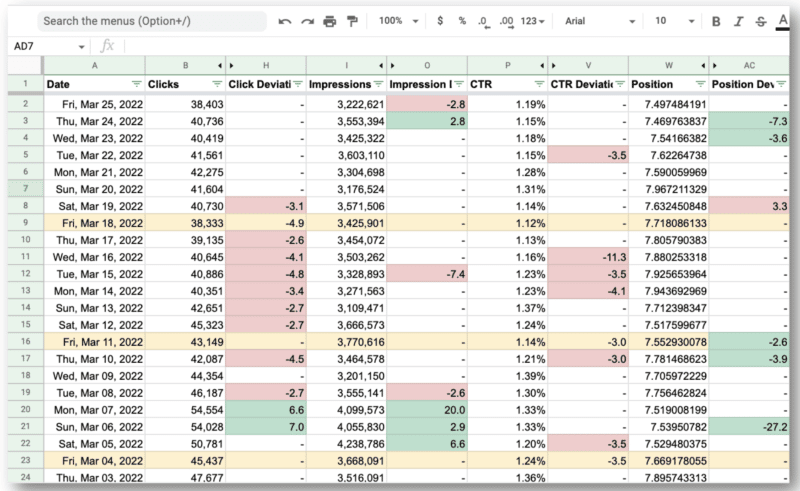
Zdumiewające dla zespołu Wu jest to, że mogli użyć interfejsu API Google Search Console i wyrażeń regularnych do:
- Odfiltruj wszystkie zapytania międzynarodowe i spójrz tylko na Stany Zjednoczone, gdzie miały główne problemy.
- Określ dni, w których witryna miała problemy.
Obejrzyj: Maksymalne wykorzystanie interfejsu API Google Search Console
Poniżej znajduje się pełny film z prezentacji Wu SMX Advanced.