
Czy Google używa systemu podobnego do ChatGPT do wykrywania spamu i treści AI oraz do klasyfikowania witryn?
Opublikowany: 2023-02-01Nagłówek celowo wprowadza w błąd – ale tylko w zakresie używania terminu „ChatGPT”.
„Podobny do ChatGPT” natychmiast pozwala ci, czytelniku, poznać rodzaj technologii, o której mówię, zamiast opisywać system jako „model generowania tekstu, taki jak GPT-2 lub GPT-3”. (Ponadto ten ostatni naprawdę nie byłby tak klikalny…)
W tym artykule przyjrzymy się starszemu, ale bardzo istotnemu artykułowi Google z 2020 r., „Modele generatywne to nienadzorowane predyktory jakości strony: badanie na kolosalną skalę”.
O czym jest papier?
Zacznijmy od opisu autorów. Tak wprowadzają do tematu:
„Wielu wyraziło obawy dotyczące potencjalnych zagrożeń związanych z generatorami tekstu neuronowego w środowisku naturalnym, głównie ze względu na ich zdolność do tworzenia tekstu wyglądającego jak człowiek na dużą skalę.
Klasyfikatory przeszkolone w rozróżnianiu tekstu generowanego przez człowieka i maszynę zostały ostatnio wykorzystane do monitorowania obecności tekstu generowanego maszynowo w sieci [29]. Niewiele jednak włożono w zastosowanie tych klasyfikatorów do innych zastosowań, pomimo ich atrakcyjnej właściwości polegającej na tym, że nie wymagają żadnych etykiet — jedynie korpus tekstu ludzkiego i model generatywny. W tej pracy pokazujemy poprzez rygorystyczną ocenę ludzi, że gotowe dyskryminatory ludzi i maszyn służą jako potężne klasyfikatory jakości strony . Oznacza to, że teksty, które wydają się generowane maszynowo, są zwykle niespójne lub niezrozumiałe. Aby zrozumieć występowanie niskiej jakości stron w środowisku naturalnym, stosujemy klasyfikatory do próby pół miliarda angielskich stron internetowych”.
Zasadniczo mówią, że odkryli, że te same klasyfikatory opracowane w celu wykrywania kopii opartych na sztucznej inteligencji, przy użyciu tych samych modeli do ich generowania, mogą być z powodzeniem wykorzystywane do wykrywania treści niskiej jakości.
Oczywiście pozostawia to nas z ważnym pytaniem:
Czy jest to związek przyczynowy (tj. czy system wykrywa go, ponieważ jest w tym naprawdę dobry) czy korelacja (tj. czy duża część obecnego spamu jest tworzona w sposób, który można łatwo obejść za pomocą lepszych narzędzi)?
Zanim jednak to zbadamy, przyjrzyjmy się niektórym pracom autorów i ich odkryciom.
Ustawić
Dla porównania, w swoim eksperymencie wykorzystali:
- Dwa modele generowania tekstu , oparty na OpenAI detektor GPT-2 RoBERTa (detektor wykorzystujący model RoBERTa z wyjściem GPT-2 i przewidujący, czy jest on prawdopodobnie generowany przez sztuczną inteligencję, czy nie) oraz model GLTR, który ma również dostęp do wyjście GPT-2 i działa podobnie.
Możemy zobaczyć przykład wyjścia tego modelu na treści, którą skopiowałem z powyższego artykułu:
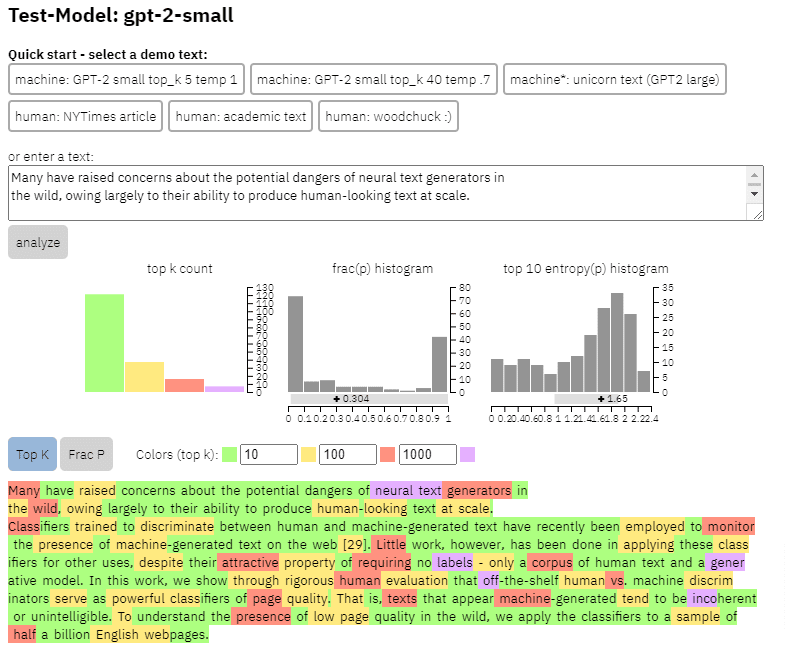
- Trzy zestawy danych Web500M (losowe pobieranie próbek z 500 milionów anglojęzycznych stron internetowych), GPT-2 Output (250 tys. do wykrywania fałszywych wiadomości).
- The Spam Baseline , klasyfikator przeszkolony w zestawie danych Enron Spam Email Dataset. Użyli tego klasyfikatora do ustalenia liczby jakości języka, którą przypisaliby, więc jeśli model ustalił, że dokument nie jest spamem z prawdopodobieństwem 0,2, przypisany wynik jakości języka (LQ) wynosił 0,2.
Otrzymuj codzienny biuletyn wyszukiwania, na którym polegają marketerzy.
Zobacz warunki.
Na marginesie o rozpowszechnieniu spamu
Chciałem zrobić krótką przerwę, aby przedyskutować kilka interesujących odkryć, na które natknęli się autorzy. Jeden jest zilustrowany na poniższym rysunku (Rysunek 3 z artykułu):
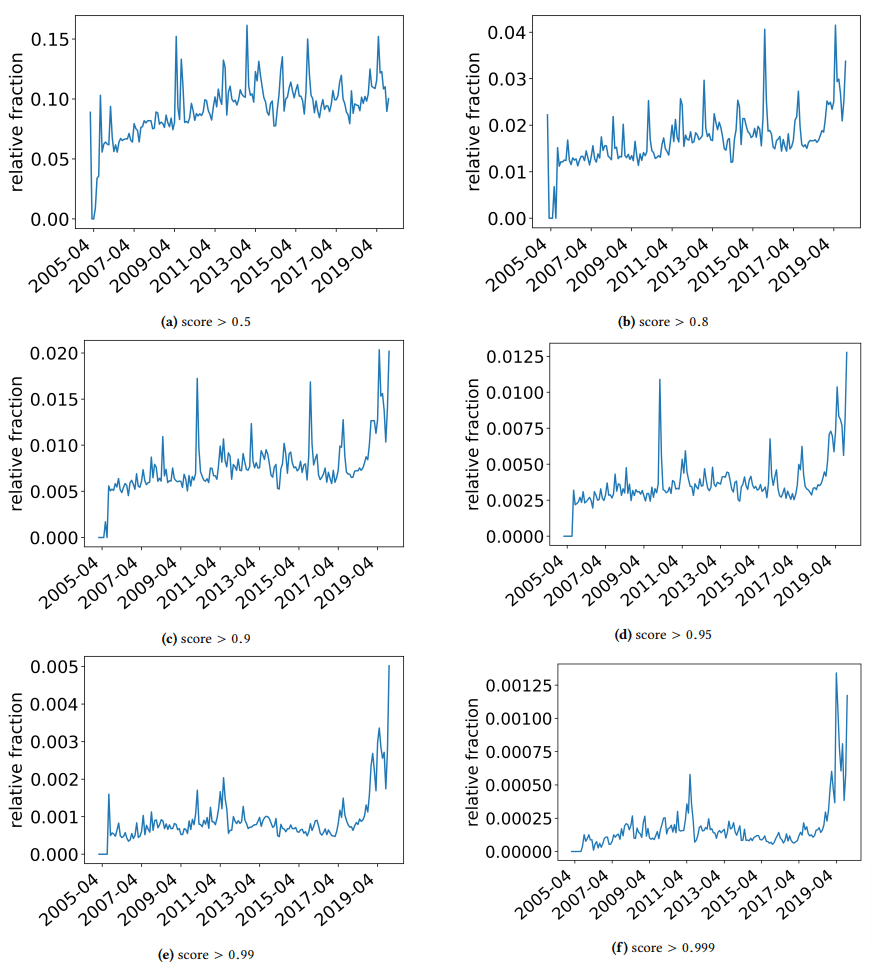
Ważne jest, aby zwrócić uwagę na wynik pod każdym wykresem. Liczba zbliżająca się do 1,0 zbliża się do pewności, że treść jest spamem. Widzimy więc, że począwszy od 2017 r. – i gwałtownie w 2019 r. – dominowała dokumentacja niskiej jakości.
Ponadto odkryli, że wpływ treści niskiej jakości był większy w niektórych sektorach niż w innych (pamiętając, że wyższy wynik odzwierciedla większe prawdopodobieństwo spamu).
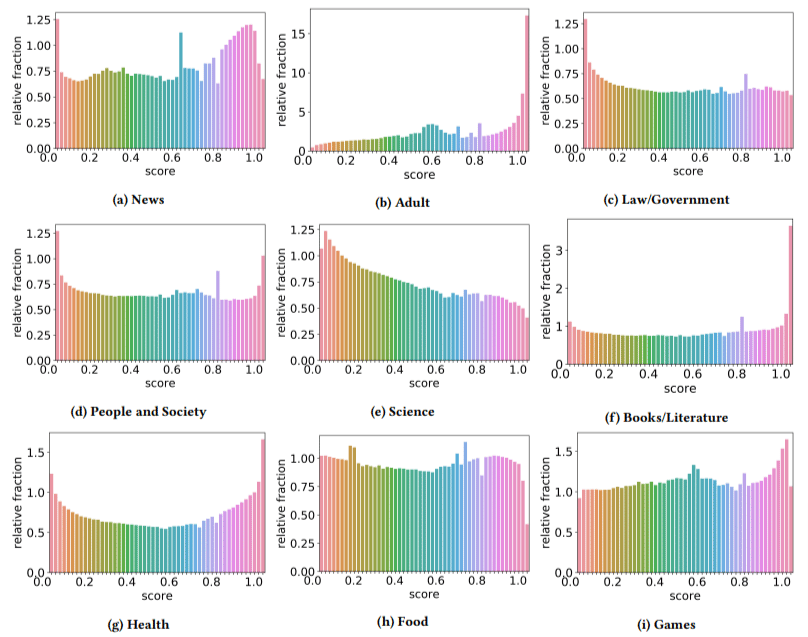
Podrapałem się po głowie nad kilkoma z nich. Dorosły miał oczywiście sens.
Ale książki i literatura były trochę niespodzianką. I tak samo było ze zdrowiem – dopóki autorzy nie wymienili Viagry i innych witryn „produktów zdrowotnych dla dorosłych” jako „zdrowia”, a farmy esejów jako „literatura” – to znaczy.
Ich ustalenia
Oprócz tego, o czym rozmawialiśmy o sektorach i skoku w 2019 r., autorzy znaleźli również wiele interesujących rzeczy, z których SEO mogą się uczyć i o których muszą pamiętać, zwłaszcza gdy zaczynamy opierać się na narzędziach takich jak ChatGPT.
- Treści niskiej jakości są zwykle krótsze (maksymalnie 3000 znaków).
- Systemy wykrywania przeszkolone w określaniu, czy tekst został napisany przez maszynę, czy nie, są również dobre w klasyfikowaniu treści niskiego i wysokiego poziomu.
- Nazywają nasze treści przeznaczone do rankingów jako konkretnego winowajcę, chociaż podejrzewam, że odnoszą się do śmieci, o których wszyscy wiemy, że nie powinny tam być.
Autorzy nie twierdzą, że jest to ostateczne rozwiązanie, ale raczej punkt wyjścia i jestem pewien, że przesunęli poprzeczkę do przodu w ciągu ostatnich kilku lat.
Uwaga dotycząca treści generowanych przez sztuczną inteligencję
Modele językowe również rozwijały się przez lata. Chociaż GPT-3 istniał, kiedy pisano ten artykuł, detektory, których używali, były oparte na GPT-2, który jest znacznie gorszym modelem.
GPT-4 jest prawdopodobnie tuż za rogiem, a Google Sparrow ma zostać wydany jeszcze w tym roku. Oznacza to, że nie tylko technologia jest coraz lepsza po obu stronach pola bitwy (generatory treści kontra wyszukiwarki), ale kombinacje będą łatwiejsze do wykorzystania w grze.
Czy Google może wykryć treści utworzone przez Sparrowa lub GPT-4? Może.
Ale co powiesz na to, że został wygenerowany za pomocą Sparrowa, a następnie wysłany do GPT-4 z monitem o przepisanie?
Innym czynnikiem, o którym należy pamiętać, jest to, że techniki zastosowane w tym artykule są oparte na modelach autoregresyjnych. Mówiąc najprościej, przewidują wynik dla słowa na podstawie tego, co przewidywaliby, że to słowo otrzyma te, które je poprzedzały.
W miarę jak modele osiągają wyższy stopień wyrafinowania i zaczynają tworzyć pełne pomysły naraz, a nie słowo, po którym następuje drugie, wykrywanie AI może się poślizgnąć.
Z drugiej strony wykrywanie po prostu gównianych treści powinno nasilać się – co może oznaczać, że jedyna treść „niskiej jakości”, która zwycięży, jest generowana przez sztuczną inteligencję.
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.