
Ekosystem Hadoop i jego składniki
Opublikowany: 2015-04-23Big Data to modne słowo krążące w branży IT od 2008 roku. Ilość danych generowanych przez sieci społecznościowe, produkcję, handel detaliczny, giełdy, telekomunikację, ubezpieczenia, bankowość i opiekę zdrowotną przekracza nasze wyobrażenia.
Przed pojawieniem się Hadoop przechowywanie i przetwarzanie dużych zbiorów danych było dużym wyzwaniem. Ale teraz, gdy Hadoop jest dostępny, firmy zdały sobie sprawę z wpływu Big Data na biznes i tego, jak zrozumienie tych danych będzie napędzać wzrost. Na przykład:
• Sektory bankowe mają większą szansę na zrozumienie lojalnych klientów, osób niespłacających kredytów i transakcji oszustw.
• Sektory handlu detalicznego mają teraz wystarczającą ilość danych do prognozowania popytu.
• Sektory produkcyjne nie muszą polegać na kosztownych mechanizmach testowania jakości. Przechwytywanie danych z czujników i analizowanie ich ujawniłoby wiele wzorców.
• E-Commerce, sieci społecznościowe mogą personalizować strony w oparciu o zainteresowania klientów.
• Giełdy generują ogromne ilości danych, a ich korelacja od czasu do czasu ujawni piękne spostrzeżenia.
Big Data ma wiele przydatnych i wnikliwych zastosowań.
Hadoop to prosta odpowiedź na przetwarzanie Big Data. Ekosystem Hadoop to połączenie technologii, które mają dużą przewagę w rozwiązywaniu problemów biznesowych.
Pozwól nam zrozumieć komponenty w Hadoop Ecosystem, aby zbudować właściwe rozwiązania dla danego problemu biznesowego.
Ekosystem Hadoop:
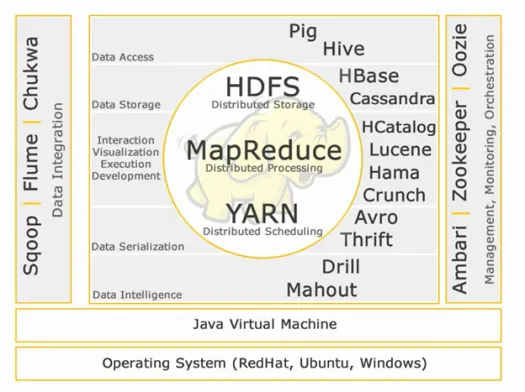

Rdzeń Hadoopa:
HDFS:
HDFS to skrót od Hadoop Distributed File System do zarządzania dużymi zestawami danych o dużej objętości, prędkości i różnorodności. HDFS implementuje architekturę master-slave. Master to nazwa węzła, a slave to węzeł danych.
Cechy:
• Skalowalny
• Niezawodny
• Sprzęt towarowy
HDFS jest dobrze znany z przechowywania Big Data.
Zmniejszenie mapy:
Map Reduce to model programowania przeznaczony do przetwarzania rozproszonych danych o dużej objętości. Platforma jest zbudowana przy użyciu Javy dla lepszej obsługi wyjątków. Map Reduce zawiera dwa demony, Job tracker i Task Tracker.
Cechy:
• Programowanie funkcjonalne.
• Działa bardzo dobrze na Big Data.
• Potrafi przetwarzać duże zbiory danych.
Map Reduce to główny komponent znany z przetwarzania dużych zbiorów danych.
PRZĘDZA:
YARN to skrót od Yet Another Resource Negotiator. Jest również nazywany MapReduce 2(MRv2). Dwie główne funkcje Job Tracker w MRv1, zarządzanie zasobami i planowanie/monitorowanie zadań są podzielone na oddzielne demony, którymi są ResourceManager, NodeManager i ApplicationMaster.
Cechy:
• Lepsze zarządzanie zasobami.
• Skalowalność
• Dynamiczna alokacja zasobów klastra.
Dostęp do danych:
Świnia:
Apache Pig to język wysokiego poziomu zbudowany na bazie MapReduce do analizy dużych zestawów danych za pomocą prostych programów do analizy danych adhoc. Pig jest również znany jako język przepływu danych. Jest bardzo dobrze zintegrowany z Pythonem. Jest początkowo rozwijany przez yahoo.
Istotne cechy świni:
• Łatwość programowania
• Możliwości optymalizacji
• Rozszerzalność.
Skrypty Pig zostaną wewnętrznie przekonwertowane na programy do redukcji map.

Ul:
Apache Hive to kolejna infrastruktura wysokiego poziomu języka zapytań i hurtowni danych zbudowana na bazie Hadoop w celu zapewnienia podsumowania, zapytań i analizy danych. Jest początkowo rozwijany przez yahoo i udostępniany jako open source.
Istotne cechy ula:
• SQL podobny do języka zapytań o nazwie HQL.
• Partycjonowanie i tworzenie segmentów w celu szybszego przetwarzania danych.
• Integracja z narzędziami do wizualizacji, takimi jak Tableau.
Zapytania Hive wewnętrznie zostaną przekonwertowane na programy do redukcji map.
Jeśli chcesz zostać analitykiem big data, te dwa języki wysokiego poziomu są koniecznością!

Przechowywanie danych:
Hbase:
Apache HBase to baza danych NoSQL stworzona do obsługi dużych tabel z miliardami wierszy i milionami kolumn na standardowych maszynach sprzętowych Hadoop. Korzystaj z Apache Hbase, gdy potrzebujesz losowego dostępu do odczytu/zapisu w czasie rzeczywistym do swoich Big Data.
Cechy:
• Ściśle spójne czyta i zapisuje. W operacjach pamięciowych.
• Łatwy w użyciu Java API dla dostępu klienta.
• Dobrze zintegrowany ze świnią, ulem i łyżką.
• Jest spójnym i odpornym na partycje systemem w twierdzeniu CAP.

Kasandra:
Cassandra to baza danych NoSQL zaprojektowana z myślą o liniowej skalowalności i wysokiej dostępności. Cassandra opiera się na modelu klucz-wartość. Opracowany przez Facebooka i znany z szybszego reagowania na zapytania.
Cechy:
• Indeksy kolumn
• Wsparcie dla denormalizacji
• Zmaterializowane poglądy
• Potężne wbudowane buforowanie.

Interakcja – Wizualizacja – wykonanie – opracowanie:
Katalog:

HCatalog to warstwa zarządzania tabelami, która zapewnia integrację metadanych gałęzi dla innych aplikacji Hadoop. Umożliwia użytkownikom korzystającym z różnych narzędzi do przetwarzania danych, takich jak Apache pig, Apache MapReduce i Apache Hive, łatwiejsze odczytywanie i zapisywanie danych.
Cechy:
• Widok tabelaryczny dla różnych formatów.
• Powiadomienia o dostępności danych.
• REST API dla systemów zewnętrznych w celu uzyskania dostępu do metadanych.
Lucen:
Apache LuceneTM to wydajna, w pełni funkcjonalna biblioteka do wyszukiwania tekstu napisana w całości w Javie. Jest to technologia odpowiednia dla prawie każdej aplikacji, która wymaga wyszukiwania pełnotekstowego, zwłaszcza międzyplatformowego.
Cechy:
• Skalowalny, wysoki – indeksowanie wydajności.
• Potężne, dokładne i wydajne algorytmy wyszukiwania.
• Rozwiązanie wieloplatformowe.
Hama:
Apache Hama to rozproszona platforma oparta na obliczeniach Bulk Synchronous Parallel (BSP). Potrafi i jest dobrze znany z ogromnych obliczeń naukowych, takich jak algorytmy macierzowe, grafowe i sieciowe.
Cechy:
• Prosty model programowania
• Dobrze nadaje się do algorytmów iteracyjnych
• Obsługiwana przędza
• Wspólne filtrowanie nienadzorowanego uczenia maszynowego.
• Grupowanie K-średnich.
Schrupać:
Apache Crunch jest stworzony do potokowania programów MapReduce, które są proste i wydajne. Ta struktura jest używana do pisania, testowania i uruchamiania potoków MapReduce.
Cechy:
• Koncentracja na programistach.
• Minimalne abstrakcje
• Elastyczny model danych.
Serializacja danych:
Awro:
Apache Avro to platforma serializacji danych, która jest neutralna językowo. Zaprojektowany z myślą o przenośności języka, dzięki czemu dane mogą potencjalnie przeżyć język, aby go czytać i pisać.

Oszczędność:
Thrift to język opracowany do tworzenia interfejsów do interakcji z technologiami zbudowanymi na Hadoop. Służy do definiowania i tworzenia usług dla wielu języków.
Analiza danych:
Wiertarka:
Apache Drill to silnik zapytań SQL o niskim opóźnieniu dla Hadoop i NoSQL.
Cechy:
• Zwinność
• Elastyczność
• Znajomość.

Kornak:
Apache Mahout to skalowalna biblioteka uczenia maszynowego przeznaczona do tworzenia analiz predykcyjnych w Big Data. Mahout ma teraz implementacje Apache Spark dla szybszego przetwarzania pamięci.
Cechy:
• Filtrowanie zespołowe.
• Klasyfikacja
• Grupowanie
• Redukcja wymiarowości

Integracja danych:
Apache Sqoop:

Apache Sqoop to narzędzie przeznaczone do masowych transferów danych pomiędzy relacyjnymi bazami danych a Hadoop.
Cechy:
• Import i eksport do iz HDFS.
• Import i eksport do iz Hive.
• Import i eksport do HBase.
Apache Flume:
Flume to rozproszona, niezawodna i dostępna usługa do wydajnego gromadzenia, agregowania i przenoszenia dużych ilości danych dziennika.
Cechy:
• Krzepki
• Odporne na uszkodzenia
• Prosta i elastyczna architektura oparta na strumieniowych przepływach danych.

Apache Chukwa:
Skalowalny kolektor logów używany do monitorowania dużych rozproszonych systemów plików.
Cechy:
• Skaluje do tysięcy węzłów.
• Niezawodna dostawa.
• Powinien mieć możliwość przechowywania danych przez czas nieokreślony.

Zarządzanie, monitorowanie i orkiestracja:
Apache Ambari:
Ambari zaprojektowano w celu uproszczenia zarządzania hadoop przez udostępnienie interfejsu do aprowizacji, zarządzania i monitorowania klastrów Apache Hadoop.
Cechy:
• Zapewnij klaster Hadoop.
• Zarządzaj klastrem Hadoop.
• Monitoruj klaster Hadoop.

Opiekun zoo Apache:
Zookeeper to scentralizowana usługa przeznaczona do przechowywania informacji konfiguracyjnych, nazewnictwa, zapewniania rozproszonej synchronizacji i świadczenia usług grupowych.
Cechy:
• Serializacja
• Atomowość
• Niezawodność
• Proste API

Apache Oozie:
Oozie to system planowania przepływu pracy do zarządzania zadaniami Apache Hadoop.
Cechy:
• Skalowalny, niezawodny i rozszerzalny system.
• Obsługuje kilka typów zadań Hadoop, takich jak Map-Reduce, Hive, Pig i Sqoop.
• Prosty i łatwy w użyciu.

W kolejnych artykułach szczegółowo omówimy poszczególne komponenty. Bądźcie czujni.