
Instalacja Hadoop przy użyciu Ambari
Opublikowany: 2015-12-11Wszystko, co chcesz wiedzieć o instalacji Hadoop przy użyciu Ambari
Apache Hadoop stał się de facto strukturą oprogramowania do niezawodnego, skalowalnego, rozproszonego przetwarzania na dużą skalę. W przeciwieństwie do innych systemów obliczeniowych, przenosi obliczenia do danych, zamiast wysyłać dane do obliczeń. Hadoop został stworzony w 2006 roku w Yahoo przez Doug Cutting na podstawie artykułu opublikowanego przez Google. W miarę dojrzewania Hadoop przez lata do jego ekosystemu dodano wiele nowych komponentów i narzędzi, aby zwiększyć jego użyteczność i funkcjonalność. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop itp., aby wymienić tylko kilka.
Dlaczego Ambari?
Wraz z rosnącą popularnością Hadoop, wielu programistów korzysta z tej technologii, aby spróbować jej. Ale jak mówią, Hadoop nie jest dla ludzi o słabych nerwach, wielu programistów nie mogło nawet przekroczyć bariery instalacji Hadoopa. Wiele dystrybucji oferuje wstępnie zainstalowaną piaskownicę maszyny wirtualnej, aby wypróbować różne rzeczy, ale nie daje to wrażenia przetwarzania rozproszonego. Jednak instalacja wielowęzłowej nie jest łatwym zadaniem, a przy rosnącej liczbie komponentów bardzo trudno jest poradzić sobie z tak wieloma parametrami konfiguracyjnymi. Na szczęście Apache Ambari przybywa nam na ratunek!
Co to jest Ambari?
Apache Ambari to narzędzie internetowe do udostępniania, zarządzania i monitorowania klastrów Apache Hadoop. Ambari udostępnia pulpit nawigacyjny do przeglądania kondycji klastra, takich jak mapy cieplne i możliwość wizualnego wyświetlania aplikacji MapReduce, Pig i Hive wraz z funkcjami diagnozowania ich charakterystyk wydajności w sposób przyjazny dla użytkownika. Posiada bardzo prosty i interaktywny interfejs użytkownika do instalowania różnych narzędzi i wykonywania różnych zadań związanych z zarządzaniem, konfiguracją i monitorowaniem. Poniżej przeprowadzimy Cię przez różne etapy instalacji Hadoop i różnych komponentów ekosystemu w klastrze wielowęzłowym.
Poniżej przedstawiono architekturę Ambari
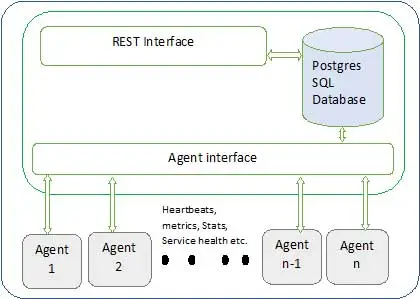
Ambari ma dwa składniki
- Serwer Ambari — jest to główny proces, który komunikuje się z agentami Ambari zainstalowanymi na każdym węźle uczestniczącym w klastrze. Ma to instancję bazy danych postgres, która służy do przechowywania wszystkich metadanych związanych z klastrem.
- Ambari Agent — są to działające agenty dla Ambari na każdym węźle. Każdy agent okresowo wysyła swój własny stan zdrowia wraz z różnymi metrykami, stanem zainstalowanych usług i wieloma innymi informacjami. Zgodnie z tym pan decyduje o kolejnej akcji i przekazuje agentowi do działania.
Jak zainstalować Ambari ?
Instalacja Ambari to proste zadanie za pomocą kilku poleceń.
Omówimy instalację Ambari i konfigurację klastra. Zakładamy, że mamy 4 węzły. Węzeł1, Węzeł2, Węzeł3 i Węzeł4. I wybieramy Node1 jako nasz serwer Ambari.
Są to kroki instalacji w systemie opartym na RHEL, w przypadku Debiana i innych systemów kroki będą się niewiele różnić.
- Instalacja Ambari: –
Z węzła serwera Ambari (Węzeł 1, jak zdecydowaliśmy)
i. Pobierz publiczne repozytorium Ambari

To polecenie doda repozytorium Hortonworks Ambari do yum, który jest domyślnym menedżerem pakietów dla systemów RHEL.
ii. Zainstaluj Ambari RPMS

Zajmie to trochę czasu i zainstaluje Ambari w tym systemie.

iii. Konfiguracja serwera Ambari
Następną rzeczą do zrobienia po instalacji Ambari jest skonfigurowanie Ambari i skonfigurowanie go do aprowizacji klastra.
Następny krok zajmie się tym


iv. Uruchom serwer i zaloguj się do internetowego interfejsu użytkownika
Uruchom serwer za pomocą

Teraz możemy uzyskać dostęp do internetowego interfejsu użytkownika Ambari (hostowanego na porcie 8080).
Zaloguj się do Ambari z domyślną nazwą użytkownika „admin” i domyślnym hasłem „admin”
Konfigurowanie klastra Hadoop
1. Strona docelowa
Kliknij „Uruchom kreatora instalacji”, aby rozpocząć konfigurację klastra
2. Nazwa klastra
Nadaj klastrowi dobrą nazwę.
Uwaga: To jest tylko prosta nazwa klastra, nie jest ona tak istotna, więc nie przejmuj się tym i wybierz dla niej dowolną nazwę.
3. Wybór stosu
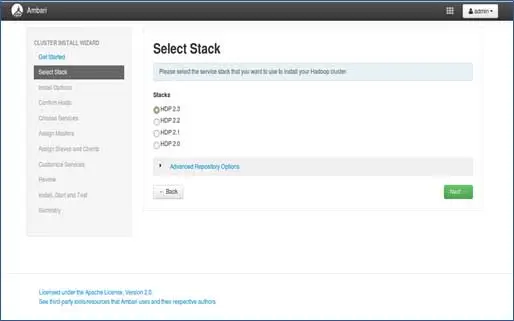
Ta strona zawiera listę stosów dostępnych do zainstalowania. Każdy stos jest wstępnie zapakowany w komponent ekosystemu Hadoop. Te stosy pochodzą z Hortonworks. (Możemy też zainstalować zwykły Hadoop. Omówimy to w późniejszych postach).
4. Hosts Entry i SSH key entry
Przed przejściem dalej w tym kroku powinniśmy mieć konfigurację bez hasła SSH dla wszystkich uczestniczących węzłów.

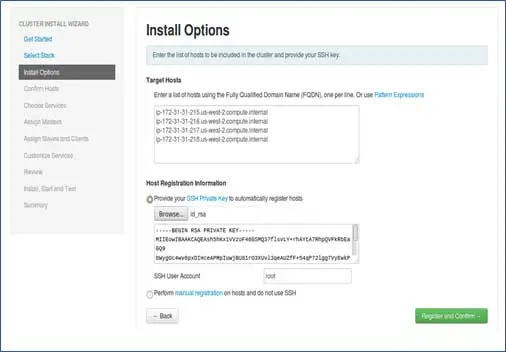
Dodaj nazwy hostów węzłów, pojedynczy wpis w każdym wierszu. [ Dodaj nazwę FQDN, którą można uzyskać za pomocą polecenia hostname –f]. Wybierz klucz prywatny używany podczas ustawiania hasła bez SSH i nazwy użytkownika, za pomocą którego utworzono klucz prywatny.
5. Status rejestracji hostów
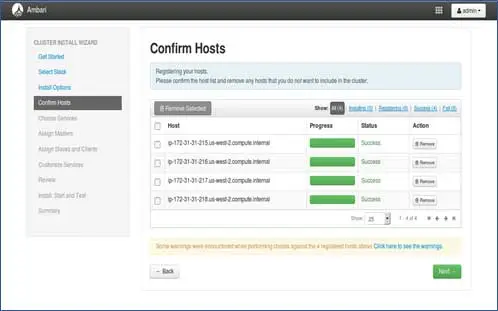
Możesz zobaczyć niektóre operacje, które są wykonywane, te operacje obejmują ustawianie Ambari-agent na każdym węźle, tworzenie podstawowych ustawień na każdym węźle. Gdy zobaczymy WSZYSTKIE ZIELONE, jesteśmy gotowi, aby przejść dalej. Czasami może to zająć trochę czasu, ponieważ instaluje kilka pakietów.

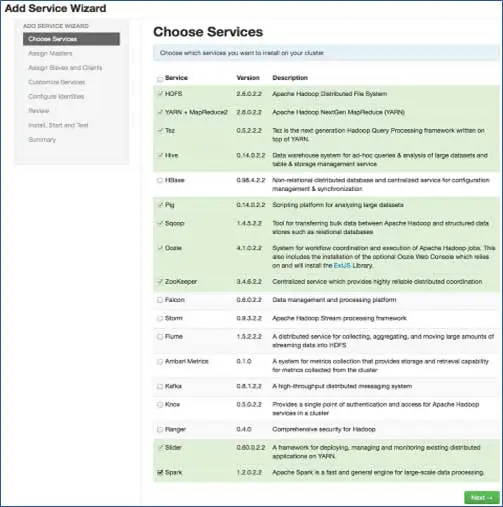
6. Wybierz usługi, które chcesz zainstalować
Zgodnie z wybranymi stosami w kroku 3 mamy liczbę usług, które możemy zainstalować w klastrze. Możesz wybrać ten, który chcesz. Ambari inteligentnie wybiera usługi zależne, jeśli ich nie wybrano. Na przykład wybrałeś HBase, ale nie Zookeeper, wyświetli to samo i doda Zookeeper również do klastra.
7. Mapowanie usług głównych za pomocą węzłów
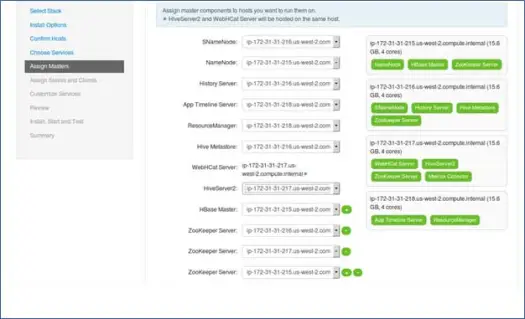
Jak wiesz, ekosystem Hadoop posiada narzędzia oparte na architekturze master-slave. W tym kroku skojarzymy procesy główne z węzłem. Tutaj upewnij się, że odpowiednio zrównoważyłeś swój klaster. Pamiętaj też, że podstawowe i dodatkowe usługi, takie jak Namenode i Secondary Namenode, nie znajdują się na tej samej maszynie.

8. Mapowanie niewolników za pomocą węzłów
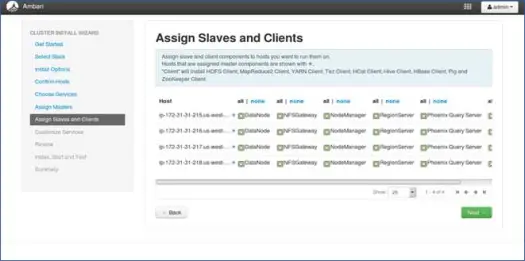
Podobnie jak w przypadku urządzeń nadrzędnych, odwzorowuje usługi podrzędne w węzłach. Ogólnie rzecz biorąc, wszystkie węzły będą miały proces podrzędny działający przynajmniej dla Datanodes i Nodemanagers.
9. Dostosuj usługi
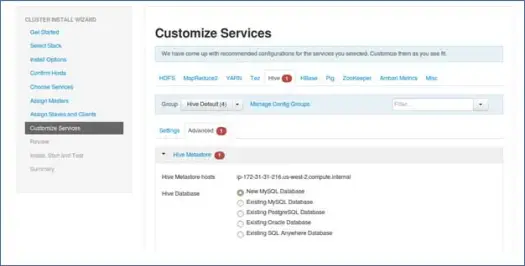
To bardzo ważna strona dla Administratorów.
Tutaj możesz skonfigurować właściwości klastra, aby jak najlepiej dopasować go do swoich przypadków użycia.
Będzie również miał pewne wymagane właściwości, takie jak hasło do metastore Hive (jeśli wybrano hive) itp. Będą one wskazywane czerwonym błędem, takim jak symbole.
10. Przejrzyj i rozpocznij udostępnianie
Upewnij się, że sprawdziłeś konfigurację klastra przed uruchomieniem, ponieważ pozwoli to uniknąć nieświadomego ustawienia błędnych konfiguracji.
11. Uruchom i pozostań z powrotem, aż status zmieni się na ZIELONY.
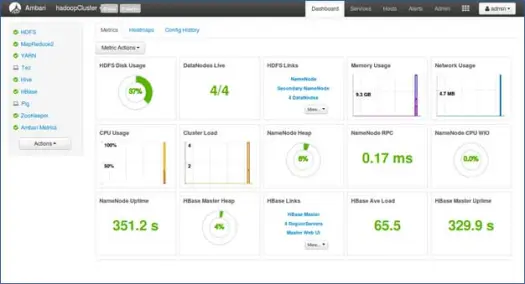
Następne kroki
Tak! Pomyślnie zainstalowaliśmy Hadoop i wszystkie komponenty na wszystkich węzłach klastra. Teraz możemy zacząć zabawę z Hadoop.
Ambari uruchamia zadanie Wordcount MapReduce, aby sprawdzić, czy wszystko działa poprawnie. Sprawdźmy dziennik zadania uruchomionego przez użytkownika ambari-qa.
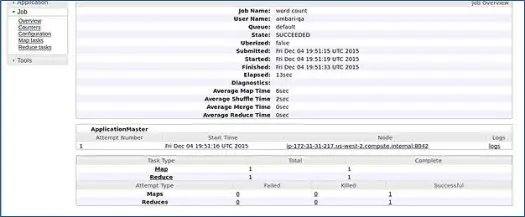
Jak widać na powyższym zrzucie ekranu, zadanie WordCount zostało zakończone pomyślnie. Potwierdza to, że nasz klaster działa prawidłowo.
Wniosek
To wszystko, teraz dowiedzieliśmy się, jak zainstalować Hadoop i jego składniki w klastrze wielowęzłowym za pomocą prostego narzędzia internetowego o nazwie Apache Ambari. Apache Ambari zapewnia nam prostszy interfejs i oszczędza wiele naszych wysiłków związanych z instalacją, monitorowaniem i zarządzaniem, co byłoby bardzo żmudne przy tak wielu komponentach i ich różnych krokach instalacji oraz kontroli monitorowania.
Pozwól, że zostawię cię z hakiem

Instalator Ambari sprawdza /etc/lsb-release, aby uzyskać szczegółowe informacje o systemie operacyjnym. W Linux Mint ten sam plik dla wersji Ubuntu znajduje się w /etc/upstream-release/lsb-release. Aby oszukać instalator, po prostu zastąp pierwszy z drugim (najpierw należy wykonać kopię zapasową pliku).

W pewnym momencie po zakończeniu instalacji możesz przywrócić oryginał za pomocą:

PS To jest hack bez żadnych gwarancji, zadziałał dla mnie, więc pomyślałem, że podzielę się nim z tobą.
Jesteś programistą/programistą i musisz szybko zainstalować Hadoop. Mamy dla Ciebie dobrą wiadomość, Ambari zapewnia sposób, w jaki możesz pominąć cały proces kreatora i ukończony proces instalacji za pomocą jednego skryptu, a ja przyniosę to w następnym poście, więc bądź na bieżąco i do tego czasu Happy Hadooping!