
Integracja testów Cypress z Dockerem, Buildkite i CICD #frontend@twiliosendgrid
Opublikowany: 2020-12-30Napisaliśmy wiele testów end-to-end (E2E) Cypress, aby sprawdzić, czy nasze aplikacje internetowe nadal działają zgodnie z oczekiwaniami z backendem. Po napisaniu tych testów automatyzacji przeglądarki, chcielibyśmy, aby te testy Cypress były uruchamiane lub uruchamiane w taki sposób, jak nasze testy jednostkowe, zanim scalimy kod i wdrożymy go w określonych środowiskach. To doprowadziło nas na ścieżkę, w której chcieliśmy uruchomić nasze testy Cypress w kontenerze Docker, aby zintegrować się z naszym dostawcą ciągłej integracji (CI) i maszynami, których używamy w chmurze do uruchamiania tych kontenerów.
Jeśli chodzi o przepływy wdrożeniowe, używamy Buildkite jako naszego dostawcy CI. To pozwala nam wygenerować kompilację zautomatyzowanych kroków dla naszej aplikacji w potoku Buildkite, gdy planujemy przenieść kod po całej tablicy. Aby uzyskać więcej kontekstu, potok to miejsce zwykle powiązane z repozytorium aplikacji, w którym możemy przeglądać kompilacje lub wyzwalać kompilacje z określonymi krokami do wykonania podczas tworzenia żądań ściągnięcia, wypychania nowych zmian w kodzie, scalania kodu do masteru i wdrażania w różnych środowiskach . Tworzymy wiele potoków do różnych celów, takich jak wdrożenie, wyzwalane testy Cypress i określone testy Cypress działające zgodnie z harmonogramem.
W tym wpisie na blogu założono, że już wcześniej pisałeś testy Cypress i masz uruchomione pewne testy, ale chcesz mieć pomysły na uruchamianie tych testów przez cały czas w przepływach programowania i wdrażania. Jeśli zamiast tego chcesz uzyskać więcej informacji na temat pisania testów Cypress, możesz sprawdzić ten wcześniejszy wpis na blogu, a następnie wrócić do niego, gdy będziesz miał coś do uruchomienia.
Naszym celem jest przedstawienie pomysłów, jak zintegrować testy Cypress w kontenerze Docker z dostawcą CI, przyglądając się, jak zrobiliśmy to za pomocą Docker Compose i Buildkite w naszym potoku wdrożeniowym. Te pomysły można rozszerzyć w swojej infrastrukturze, aby zastosować strategie, polecenia i zmienne środowiskowe podczas uruchamiania testów Cypress.
Nasz standardowy przepływ CICD
W naszym standardowym przepływie rozwoju i wdrażania konfigurujemy dwa potoki:
- Pierwsza obsługuje nasze kroki wdrażania, gdy wypychamy kod.
- Druga powoduje, że nasze testy Cypress są uruchamiane równolegle i są rejestrowane. Powodzenie lub niepowodzenie tego wpływa na potok wdrażania.
W naszym potoku wdrożeniowym budujemy nasze zasoby aplikacji internetowych, przeprowadzamy testy jednostkowe i wykonujemy kroki, aby wyzwolić wybrane testy Cypress przed wdrożeniem w każdym środowisku. Upewniamy się, że mijają, zanim odblokujemy możliwość rozmieszczenia przycisku. Te wyzwolone testy Cypress w drugim potoku również działają w kontenerze Dockera i są podłączone do płatnego pulpitu Cypress Dashboard za pomocą klucza nagrywania, dzięki czemu możemy spojrzeć wstecz na filmy, zrzuty ekranu i dane wyjściowe konsoli z tych testów Cypress, aby debugować wszelkie problemy.
Korzystając z wybranych danych wejściowych Buildkite , opracowaliśmy dynamiczną opcję wyboru własnej przygody, aby użytkownicy mogli wybrać „Tak” lub „Nie”, aby zdecydować, które foldery specyfikacji Cypress mają zostać uruchomione i zweryfikowane w miarę wciskania większej ilości kodu. Domyślną odpowiedzią byłoby „Nie” dla wszystkich opcji, ale wartość „Tak” byłaby ścieżką globalną do folderu specyfikacji Cypress.
Czasami nie chcemy uruchamiać wszystkich testów Cypress, jeśli nasza zmiana kodu nie wpływa na inne strony. Zamiast tego chcemy uruchamiać tylko testy, o których wiemy, że będzie to miało wpływ. Być może będziemy musieli również wdrożyć szybką poprawkę do środowiska produkcyjnego w przypadku pilnego problemu z błędem, ponieważ czujemy się na tyle pewni, że nie uruchamiamy naszych testów Cypress, które mogą zająć od 0 do 10 minut, w zależności od tego, ile testów uruchomimy. Podajemy przykład zarówno wizualnie, jak i w krokach YML dla tej części.
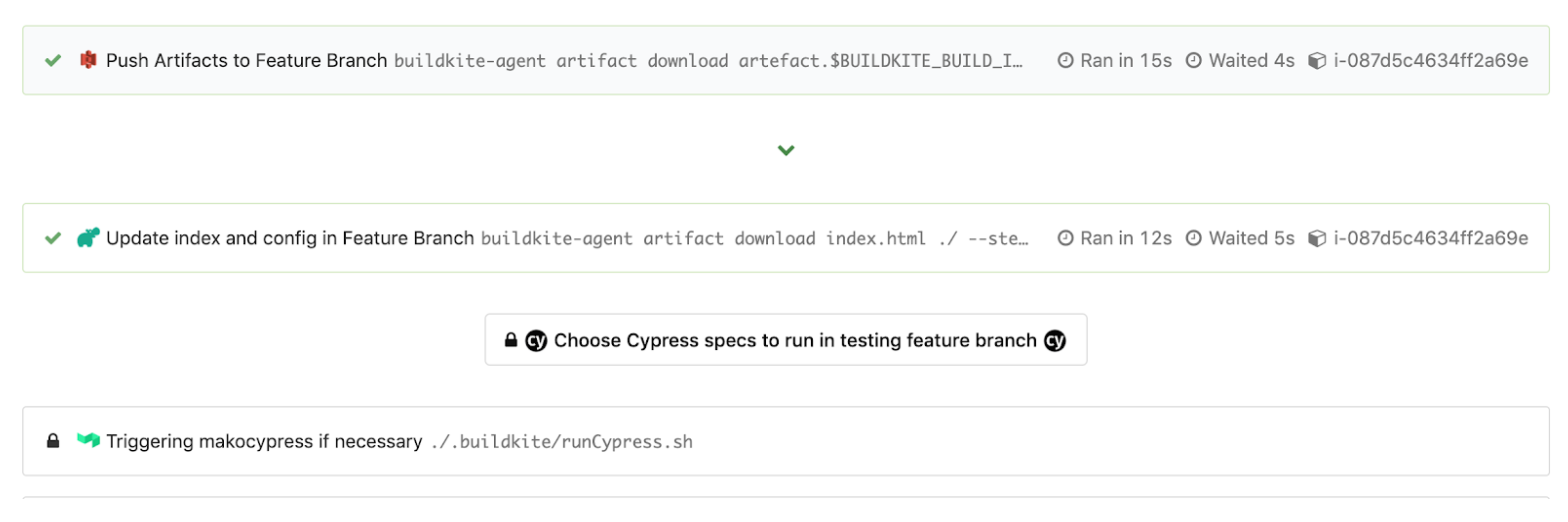
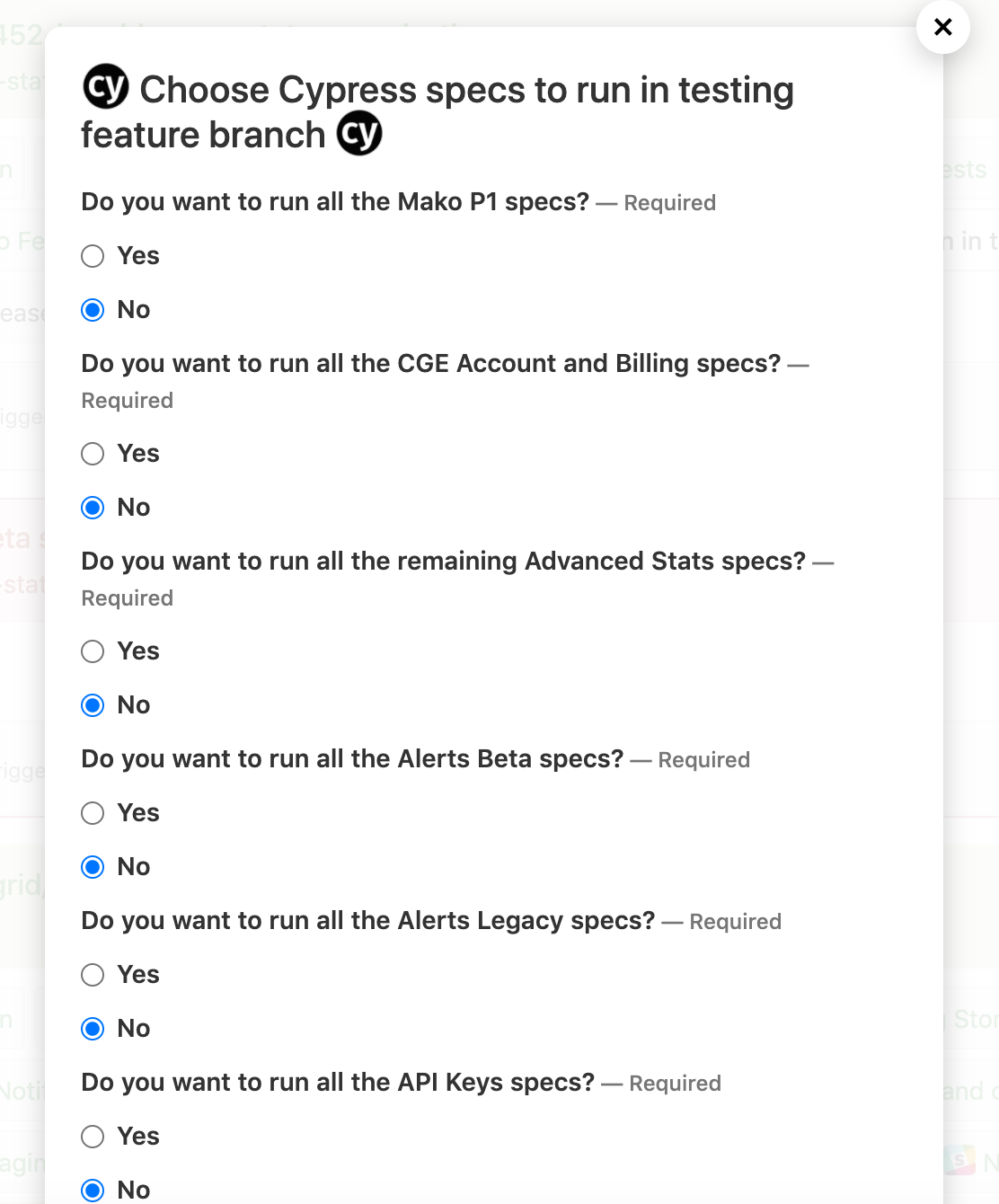
Następnie zaimplementowaliśmy nasz własny skrypt Bash o nazwie runCypress.sh , aby uruchomić go po tym kroku wyboru, aby przeanalizować wybrane wartości "Tak" lub "Nie". Robimy to, aby utworzyć listę oddzielonych przecinkami ścieżek specyfikacji, które należy uruchomić i dodać jako opcję, --spec , do naszego ewentualnego polecenia Cypress, które działa w kontenerze Dockera w wyzwolonym potoku. Eksportujemy zmienne środowiskowe, takie jak utworzona lista specyfikacji w „CYPRESS_SPECS” i bieżące środowisko testowe w „CYPRESS_TEST_ENV”, które mają być używane w potoku, który uruchamiamy na końcu skryptu za buildkite-agent pipeline upload "$DIRNAME"/triggerCypress.yml .
Być może zauważyłeś, jak eksportujemy również zmienną środowiskową „ASYNC”. W Buildkite możesz wybrać, aby wyzwalany krok kompilacji blokował lub nie blokował pod względem sukcesu lub porażki. Jeśli „ASYNC” jest ustawione na wartość true, nasze główne kroki potoku wdrażania będą nadal działać i nie będą czekać na zakończenie wyzwalanych testów Cypress w innym potoku. Powodzenie lub niepowodzenie potoku nie wpływa na powodzenie lub niepowodzenie potoku wdrażania.
Jeśli ustawimy „ASYNC” na wartość false, nasze główne kroki potoku wdrażania będą blokowane do czasu zakończenia wyzwalanych testów Cypress w innym potoku. Powodzenie lub niepowodzenie wyzwolonej kompilacji prowadzi do ogólnego sukcesu lub niepowodzenia potoku wdrażania, po którym następuje.
Gdy nasz kod nadal znajduje się w gałęzi funkcji z otwartym żądaniem ściągnięcia, lubimy wprowadzać więcej zmian, uruchamiać niektóre testy Cypress i sprawdzać, jak się zachowują. Jednak nie zawsze chcemy blokować uruchamianie pozostałych kroków potoku wdrażania, jeśli wyzwalane testy zakończą się niepowodzeniem, ponieważ po drodze jest potencjalnie więcej zmian. W tym scenariuszu ustawiamy „ASYNC” na false, aby nie blokować, jeśli testy Cypress zakończą się niepowodzeniem. W przypadku, gdy już połączyliśmy nasze żądanie ściągnięcia z głównym i wdrożyliśmy do przemieszczania, ale chcemy wyzwolić testy Cypress przed wdrożeniem do produkcji, ustawiliśmy „ASYNC” na true, ponieważ chcemy, aby testy Cypress zawsze przechodziły przed przejściem do produkcji .
Wracając do runCypress.sh , przypominamy, że skrypt uruchamia drugi potok, wywołując plik triggerCypress.yml z przypisanymi wartościami zmiennych środowiskowych. Plik triggerCypress.yml wygląda mniej więcej tak. Zauważysz, że krok „wyzwalacza” i interpolacja wartości do komunikatów kompilacji są pomocne przy debugowaniu i dynamicznych nazwach kroków.
Niezależnie od tego, czy uruchamiamy testy Cypress z naszego potoku wdrożeniowego do oddzielnego potoku wyzwalającego, czy uruchamiamy testy Cypress zgodnie z harmonogramem w dedykowanym potoku, wykonujemy i ponownie wykorzystujemy te same kroki, zmieniając tylko wartości zmiennych środowiskowych.
Te kroki obejmują:
- Tworzenie obrazu Dockera za pomocą najnowszego tagu i unikalnego tagu wersji
- Przenoszenie obrazu Dockera do naszego prywatnego rejestru
- Przeciągnięcie tego samego obrazu w dół, aby uruchomić nasze testy Cypress na podstawie naszych wartości zmiennych środowiskowych w kontenerze Docker
Te kroki są opisane w pliku pipeline.cypress.yml w następujący sposób:

Gdy uruchomimy testy Cypress, uruchomi to oddzielną kompilację w potoku wyzwalacza Cypress. W zależności od sukcesu lub niepowodzenia kompilacji, uruchomienie testowe Cypress zablokuje lub umożliwi nam wdrożenie w środowisku produkcyjnym, gdy przechodzimy od etapu do produkcji w przypadku kompilacji gałęzi głównej.
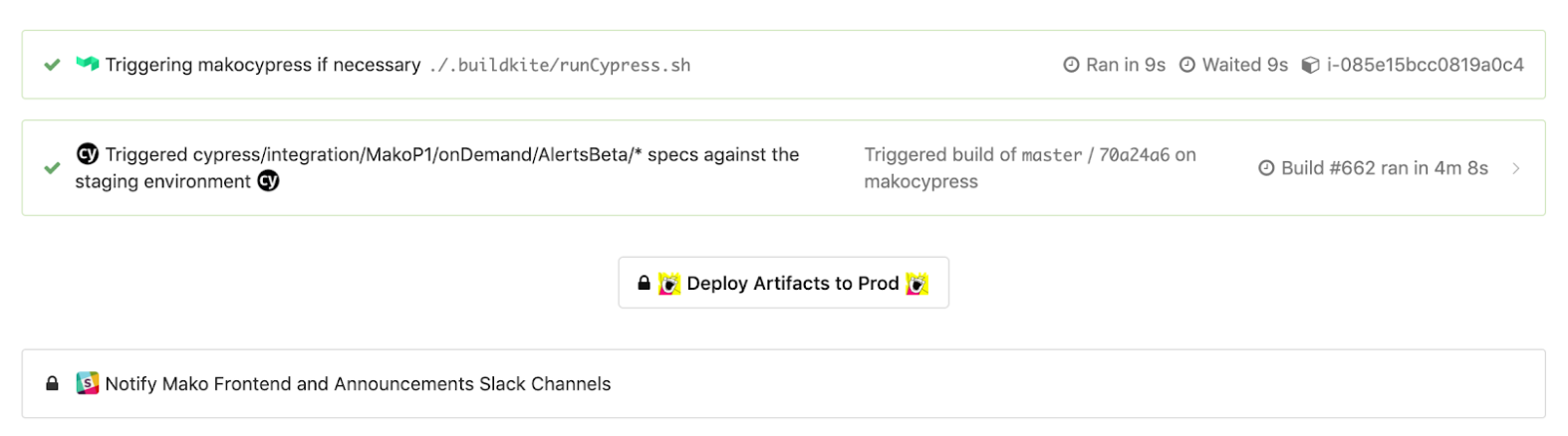
Kliknięcie kroku „Wyzwolony cyprys/integracja/…” przeniesie Cię do kompilacji wyzwolonego potoku z takim widokiem, aby zobaczyć, jak przebiegły testy.
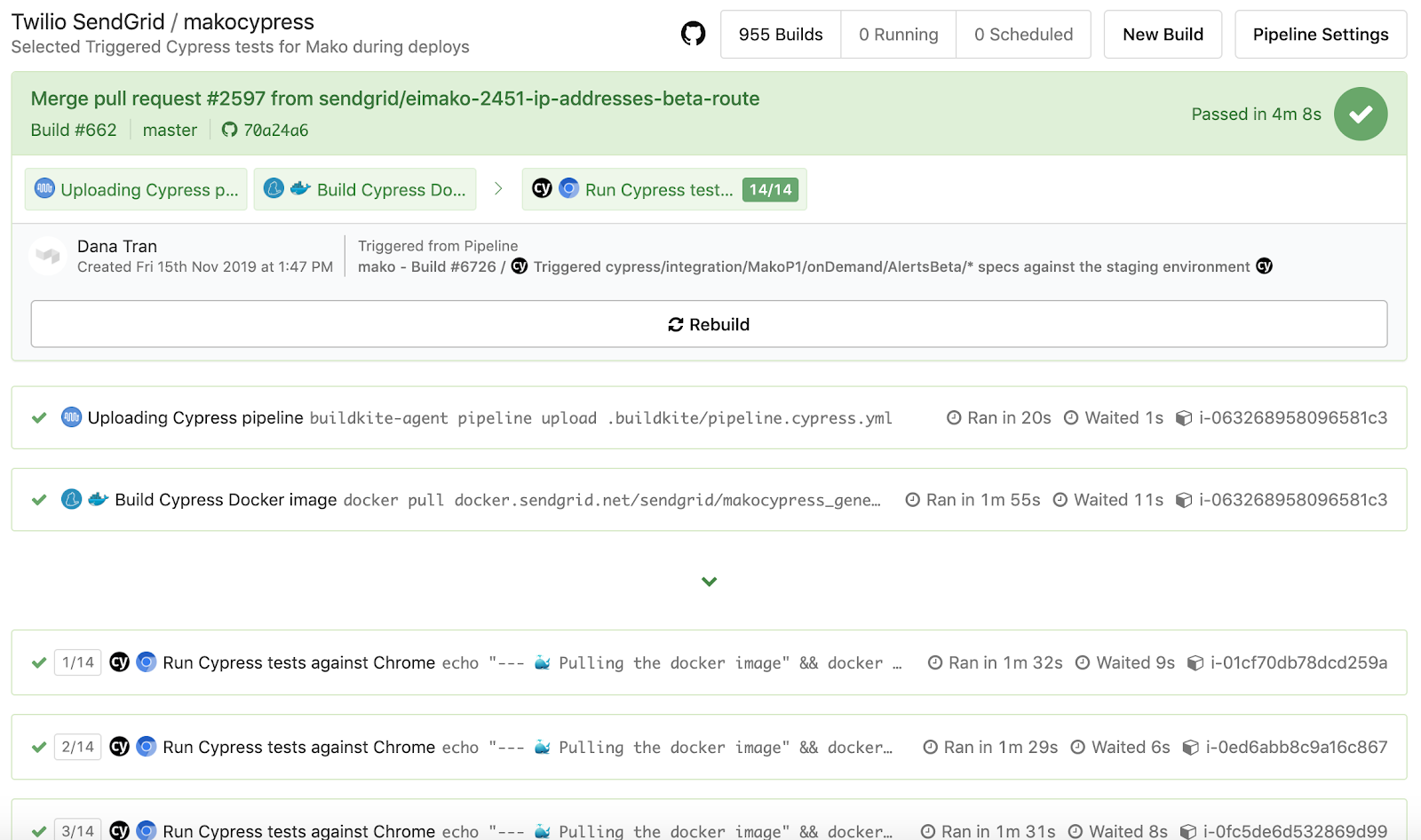
Jeśli jesteś ciekawy, w jaki sposób jest połączona część Docker, nasze Dockerfile.cypress i docker-compose.cypress.yml używają tych zmiennych środowiskowych wyeksportowanych z naszych potoków, aby następnie użyć odpowiedniego polecenia Cypress z package.json naszej aplikacji, wskazując po prawej stronie środowisko testowe i uruchamianie wybranych plików specyfikacji. Poniższe fragmenty obrazują nasze ogólne podejście, które możesz rozwijać i ulepszać, aby być bardziej elastycznym.
Poza testami przeprowadzanymi podczas naszych zwykłych cykli integracji i wdrażania, stworzyliśmy dedykowane potoki Buildkite. Te potoki działają zgodnie z harmonogramem ważnych testów w naszym środowisku przejściowym, aby upewnić się, że nasze usługi frontendowe i backendowe działają poprawnie. Ponownie wykorzystaliśmy podobne kroki potoku, dostosowaliśmy niektóre wartości zmiennych środowiskowych w ustawieniach potoku Buildkite i ustawiliśmy harmonogram crona, aby działał w zaplanowanym czasie. Pomaga nam to wyłapać wiele błędów i problemów ze środowiskiem pomostowym, ponieważ nadal monitorujemy, jak dobrze radzą sobie nasze testy i czy cokolwiek w dół strumienia lub z naszych własnych pchnięć kodu mogło doprowadzić do niepowodzenia testów.
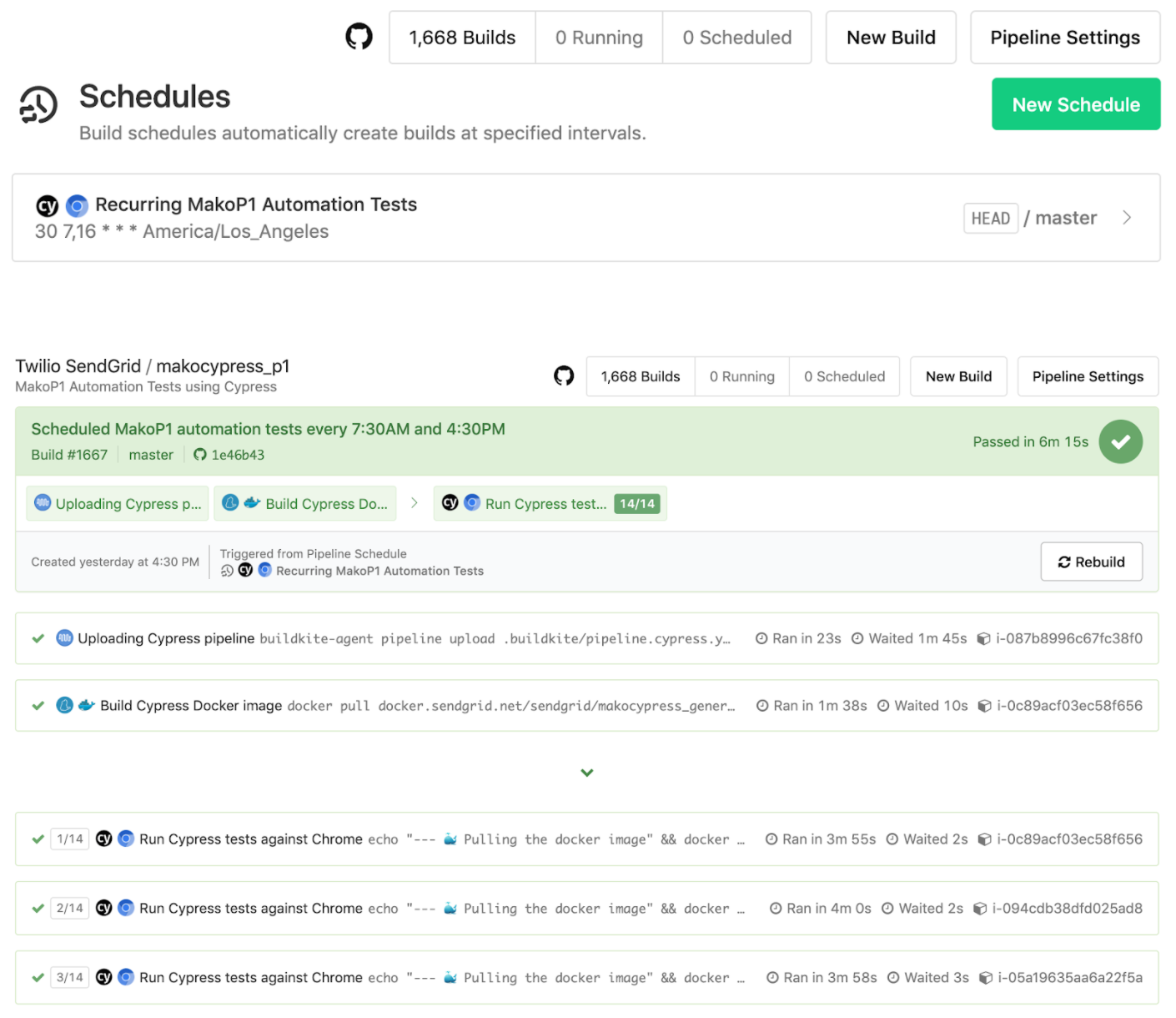
Równoległość
Używamy również flagi równoległości, aby skorzystać z liczby maszyn AWS, które możemy uruchomić z naszej kolejki agentów kompilacji skonfigurowanych przez nasz zespół operacyjny. Z tą flagą równoległości Cypress automagicznie wyświetla pewną liczbę maszyn w oparciu o liczbę, którą ustawiliśmy we właściwości „równoległości” Buildkite.
Udało nam się przeprowadzić ponad 200 testów w około 5 minut dla jednego z naszych repozytoriów aplikacji.
Następnie rozkłada wszystkie testy Cypressa, aby działały równolegle na tych maszynach, zachowując rejestrację każdego z testów dla określonego przebiegu kompilacji. To radykalnie przyspieszyło nasze czasy testów!
Oto kilka wskazówek dotyczących równoległości testów Cyprysa:
- Postępuj zgodnie z sugestiami w usłudze Dashboard, aby uzyskać optymalną liczbę maszyn i ustaw liczbę maszyn w zmiennej środowiskowej, aby uzyskać elastyczność w potokach.
- Podziel na mniejsze pliki testowe, zwłaszcza dzieląc dłuższe testy na porcje, które możemy lepiej zrównoleglać na różnych maszynach.
- Upewnij się, że testy Cypress są izolowane i nie wpływają na siebie nawzajem ani nie są od siebie zależne. Gdy masz do czynienia z przepływami związanymi z aktualizacją, tworzeniem lub usuwaniem, używaj oddzielnych użytkowników i zasobów danych, aby uniknąć wpadania w testy na siebie i uruchamiania się w warunkach wyścigu. Twoje pliki testowe mogą działać w dowolnej kolejności, więc upewnij się, że nie stanowi to problemu podczas uruchamiania wszystkich testów.
- W przypadku Buildkite pamiętaj, aby przekazać wartość zmiennej środowiskowej identyfikatora kompilacji Buildkite do opcji
--ci-build-idoprócz opcjiparallel, aby wiedzieć, z którym unikalnym uruchomieniem kompilacji należy powiązać podczas równoległego testowania na różnych maszynach.
Recenzować:
Aby połączyć testy Cypress z dostawcą CI, takim jak Buildkite, będziesz musiał:
- Utwórz obraz Dockera za pomocą kodu aplikacji, używając niezbędnego obrazu podstawowego Cypress i zależności wymaganych do uruchomienia testów w środowisku Node dla niektórych przeglądarek.
- Prześlij obraz Dockera do rejestru z określonymi tagami
- Przeciągnij ten sam obraz w późniejszym etapie
- Uruchom testy Cypress w trybie bezgłowym i z klawiszami nagrywania, jeśli korzystasz z usługi Cypress Dashboard Service.
- Ustaw różne wartości zmiennych środowiskowych i podłącz je do poleceń uruchamianych dla Cypress, aby wyzwolić wybrane testy Cypress w określonym środowisku testowym w tych kontenerach Docker.
Te ogólne kroki można ponownie wykorzystać i zastosować do testów Cypress działających zgodnie z harmonogramem i innych przypadków użycia, takich jak uruchamianie testów w wybranych przeglądarkach oprócz potoków wdrożeniowych. Kluczem jest wykorzystanie możliwości dostawcy CI i skonfigurowanie poleceń tak, aby były elastyczne i konfigurowalne w oparciu o wartości zmiennych środowiskowych.
Skonfiguruj swoje polecenia tak, aby były elastyczne i konfigurowalne na podstawie wartości zmiennych środowiskowych.
Po uruchomieniu testów w Dockerze u dostawcy CI (i jeśli płacisz za usługę pulpitu nawigacyjnego), możesz skorzystać z równoległego wykonywania testów na wielu komputerach. Może zajść konieczność zmodyfikowania istniejących testów i zasobów, aby nie były od siebie zależne, aby uniknąć zderzenia ze sobą testów.
Omówiliśmy również pomysły, które możesz wypróbować samodzielnie, takie jak tworzenie zestawu testów do walidacji interfejsu API zaplecza lub uruchamianie testów w wybranej przeglądarce. W dokumentacji Cypress jest też więcej sposobów na skonfigurowanie ciągłej integracji .
Co więcej, ważne jest, aby uruchamiać te testy Cypress podczas przepływów wdrażania lub zaplanowanych odstępów czasu, aby upewnić się, że środowiska programistyczne działają cały czas zgodnie z oczekiwaniami. Niezliczona ilość razy nasze testy Cypress wykryły problemy związane z usługami backendu, które nie działały lub zostały w jakiś sposób zmienione, co objawia się błędami aplikacji frontendowych. Szczególnie uratowali nas przed nieoczekiwanymi błędami na naszych stronach internetowych po wydaniu nowych zmian w kodzie React.
Utrzymywanie pomyślnych testów i pilne monitorowanie nieudanych testów w naszych środowiskach testowych prowadzi do mniejszej liczby zgłoszeń do pomocy technicznej i bardziej zadowolonych klientów w środowisku produkcyjnym. Utrzymanie zdrowego i stabilnego zestawu testów Cypress podczas wprowadzania nowych zmian w kodzie zapewnia większą pewność, że wszystko działa dobrze i zalecamy, abyś Ty i Twoje zespoły zrobili to samo z testami Cypress.
Aby uzyskać więcej zasobów na temat testów Cypress, zapoznaj się z następującymi artykułami:
- Co wziąć pod uwagę podczas pisania testów E2E
- 1000 stóp Przegląd pisania testów na cyprys
- TypeScript Wszystkie rzeczy w twoich testach cyprysowych
- Radzenie sobie z przepływami wiadomości e-mail w testach cyprysowych
- Pomysły na konfigurację, organizację i konsolidację testów cyprysowych