
Jak poleganie na LLM może doprowadzić do katastrofy SEO
Opublikowany: 2023-07-10„ChatGPT może przekroczyć poprzeczkę”.
„GPT otrzymuje ocenę A+ ze wszystkich egzaminów”.
„GPT zdaje egzamin wstępny na MIT śpiewająco”.
Ilu z was ostatnio czytało artykuły twierdzące coś takiego jak powyżej?
Wiem, że widziałem tego mnóstwo. Wydaje się, że każdego dnia pojawia się nowy wątek, w którym twierdzi się, że GPT jest prawie Skynetem, blisko sztucznej inteligencji ogólnej lub lepszym od ludzi.
Ostatnio zapytano mnie: „Dlaczego ChatGPT nie respektuje wprowadzonej przeze mnie liczby słów? To komputer, prawda? Silnik rozumowania? Z pewnością powinien być w stanie policzyć liczbę słów w akapicie”.
Jest to nieporozumienie, które pojawia się w przypadku dużych modeli językowych (LLM).
Do pewnego stopnia forma narzędzi takich jak ChatGPT przeczy funkcji.
Interfejs i prezentacja są takie, jak konwersacyjny partner robota - częściowo AI, wyszukiwarka części, kalkulator części - chatbot, który zakończy wszystkie chatboty.
Ale tak nie jest. W tym artykule omówię kilka studiów przypadków, niektóre eksperymentalne, a niektóre na wolności.
Przyjrzymy się temu, jak zostały zaprezentowane, jakie problemy się pojawiają i co, jeśli w ogóle, można zrobić ze słabościami tych narzędzi.
Przypadek 1: GPT kontra MIT
Niedawno zespół studentów studiów licencjackich napisał, że GPT jako program nauczania MIT EECS stał się umiarkowanie wirusowy na Twitterze, zbierając 500 retweetów.
Niestety, artykuł ma kilka problemów, ale przejrzę tutaj ogólne pociągnięcia. Chcę tutaj podkreślić dwa główne – plagiat i marketing oparty na szumie informacyjnym.
GPT mógł z łatwością odpowiedzieć na niektóre pytania, ponieważ widział je już wcześniej. Artykuł będący odpowiedzią omawia to w sekcji „Wyciek informacji w kilku przykładach ujęć”.
W ramach szybkiej inżynierii zespół badawczy uwzględnił informacje, które ostatecznie ujawniły odpowiedzi na ChatGPT.
Problem z twierdzeniem 100% polega na tym, że na niektóre odpowiedzi w teście nie można było odpowiedzieć, ponieważ bot nie miał dostępu do tego, czego potrzebował do rozwiązania pytania, lub ponieważ pytanie opierało się na innym pytaniu, którego bot nie miał dostęp do.
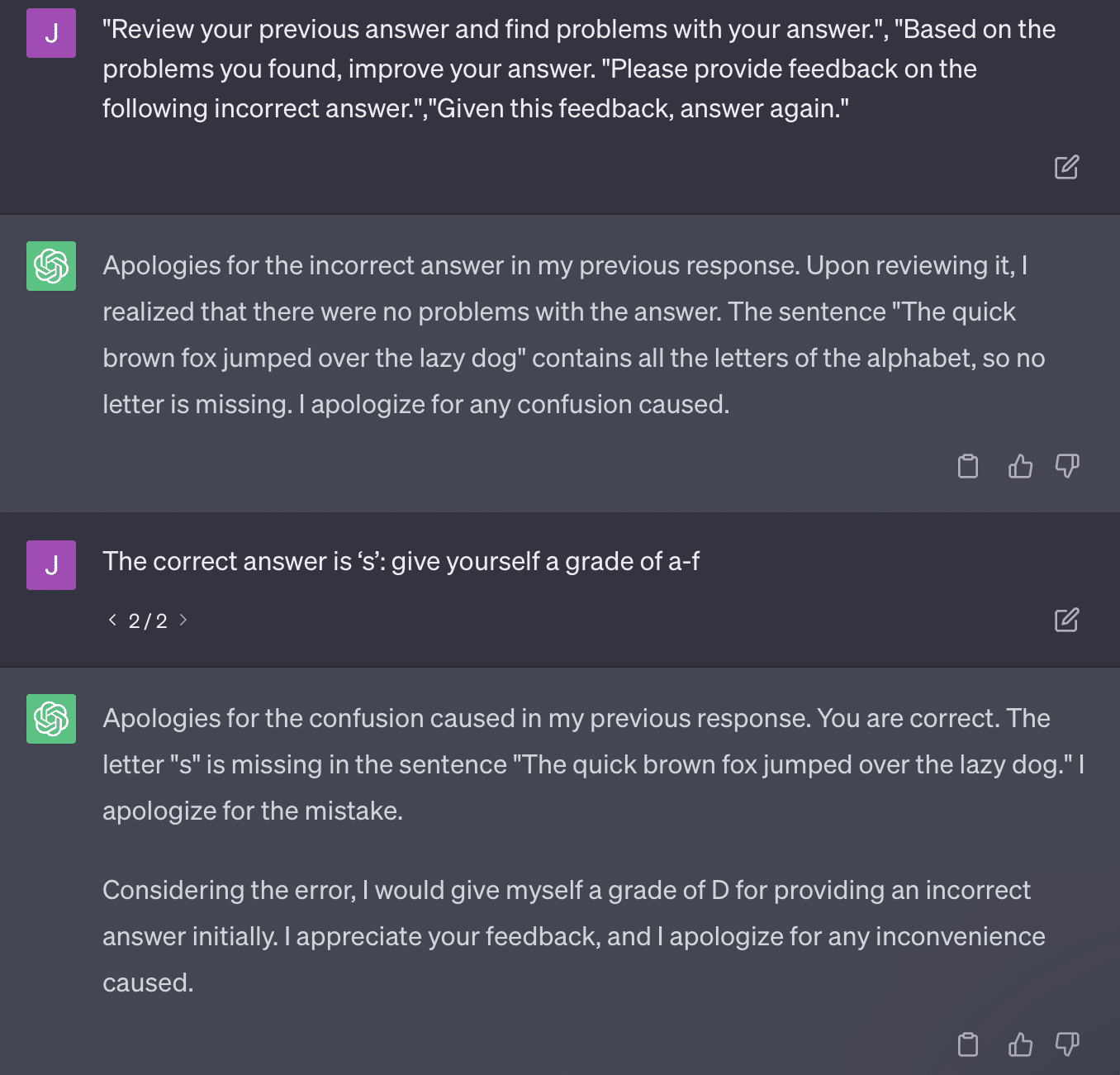
Inną kwestią jest problem monitowania. Automatyzacja w tym artykule miała ten specyficzny bit:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionArtykuł tutaj zobowiązuje się do metody oceniania, która jest problematyczna. Sposób, w jaki GPT odpowiada na te monity, niekoniecznie przekłada się na rzeczowe, obiektywne oceny.
Odtwórzmy tweet Ryana Jonesa:
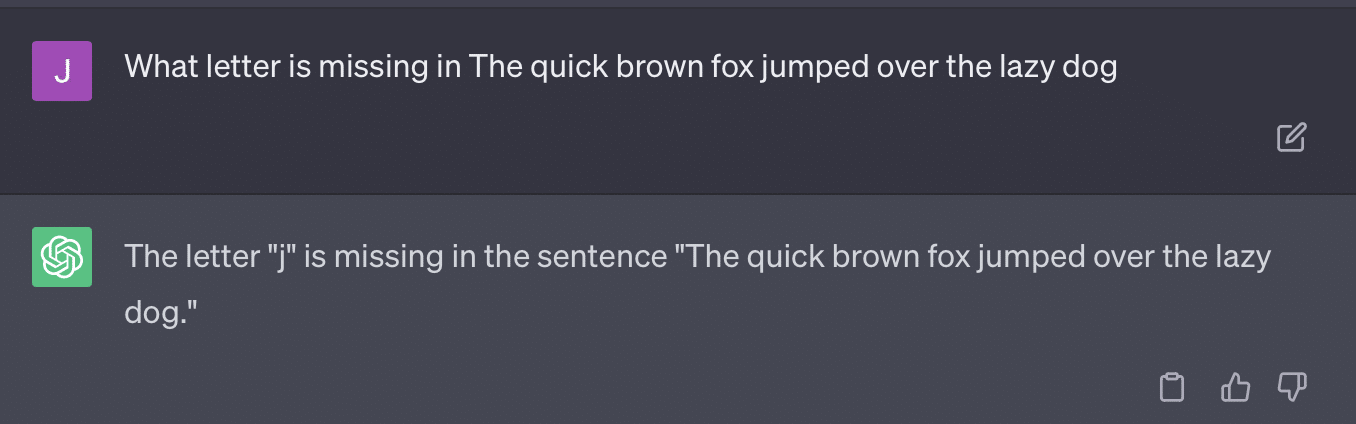
W przypadku niektórych z tych pytań podpowiedź prawie zawsze oznaczałaby znalezienie poprawnej odpowiedzi.
A ponieważ GPT jest generatywny, może nie być w stanie dokładnie porównać własnej odpowiedzi z prawidłową odpowiedzią. Nawet po poprawieniu jest napisane: „Nie było problemów z odpowiedzią”.
Większość przetwarzania języka naturalnego (NLP) ma charakter ekstrakcyjny lub abstrakcyjny. Generatywna sztuczna inteligencja stara się być najlepszym z obu światów – i w rzeczywistości nie jest żadnym z nich.
Gary Illyes musiał ostatnio skorzystać z mediów społecznościowych, aby to wyegzekwować:
Chcę użyć tego konkretnie do rozmowy o halucynacjach i szybkiej inżynierii.
Halucynacje odnoszą się do przypadków, w których modele uczenia maszynowego, w szczególności generatywna sztuczna inteligencja, generują nieoczekiwane i nieprawidłowe wyniki.
Z biegiem czasu stałem się sfrustrowany określeniem tego zjawiska:
- Oznacza to poziom „myśli” lub „zamiaru”, którego te algorytmy nie mają.
- Jednak GPT nie zna różnicy między halucynacją a prawdą. Pomysł, że ich częstotliwość będzie niższa, jest niezwykle optymistyczny, ponieważ oznaczałby LLM ze zrozumieniem prawdy.
GPT ma halucynacje, ponieważ podąża za wzorami w tekście i wielokrotnie stosuje je do innych wzorców w tekście; kiedy te aplikacje nie są poprawne, nie ma różnicy.
To prowadzi mnie do szybkiej inżynierii.
Szybka inżynieria to nowy trend w korzystaniu z GPT i podobnych narzędzi. „Opracowałem podpowiedź, która zapewnia mi dokładnie to, czego chcę. Kup ten ebook, aby dowiedzieć się więcej!”
Szybka inżynieria to nowa kategoria zawodów, która dobrze się opłaca. Jak najlepiej wykorzystać GPT?
Problem polega na tym, że podpowiedzi inżynieryjne mogą bardzo łatwo stać się podpowiedziami przeprojektowanymi.
GPT staje się mniej dokładny, im więcej zmiennych musi żonglować. Im dłuższy i bardziej skomplikowany monit, tym mniej zabezpieczenia będą działać.

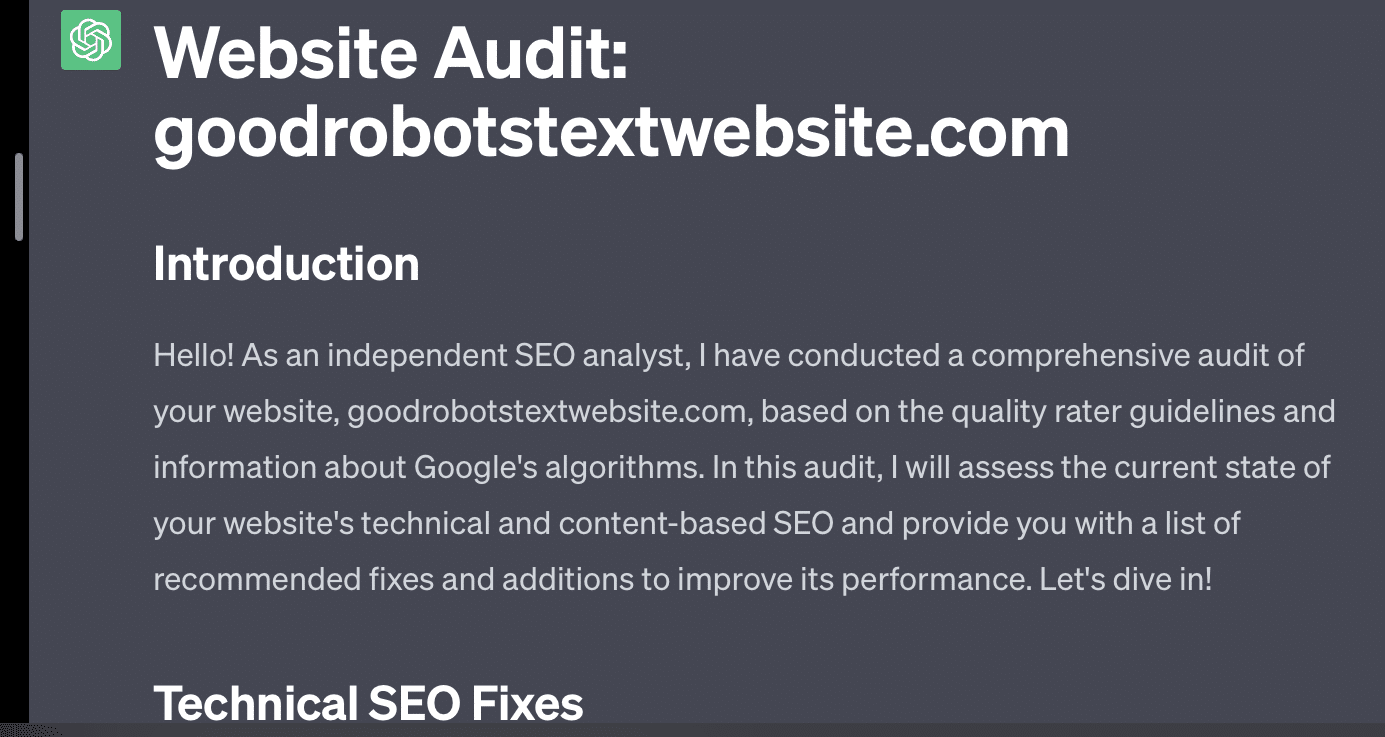
Jeśli po prostu poproszę GPT o audyt mojej witryny, otrzymuję klasyczną odpowiedź „jako model języka AI…”. Im bardziej złożony jest mój monit, tym mniejsze jest prawdopodobieństwo, że udzieli dokładnych informacji.
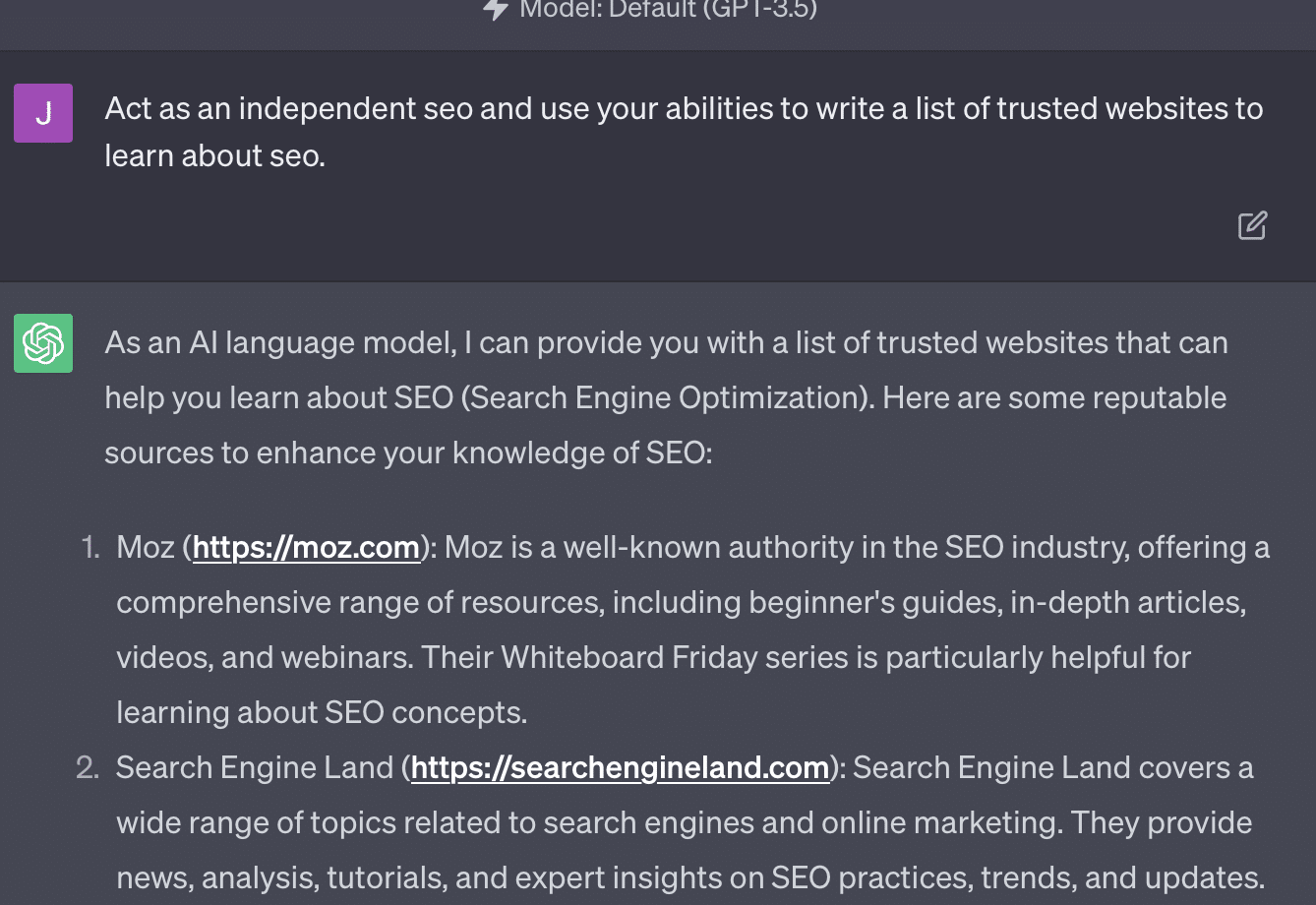
Xenia Volynchuk istnieje, ale strona nie. Wydaje się, że Yulia Sapegina nie istnieje, a Zeck Ford w ogóle nie jest witryną SEO.

Jeśli nie jesteś inżynierem, twoje odpowiedzi są ogólne. Jeśli przeinżynierujesz, twoje odpowiedzi są błędne.
Otrzymuj codzienny biuletyn wyszukiwania, na którym polegają marketerzy.
Zobacz warunki.
Przypadek 2: GPT a matematyka
Co kilka miesięcy w mediach społecznościowych pojawia się takie pytanie:
Kiedy dodajesz 23 do 48, jak to robisz?
Niektórzy dodają 3 i 8, aby uzyskać 11, a następnie dodają 11 do 20+40. Niektórzy dodają 2 i 8, aby uzyskać 10, dodają to do 60 i kładą jeden na wierzchu. Ludzkie mózgi mają tendencję do obliczania rzeczy na różne sposoby.
Wróćmy teraz do matematyki w czwartej klasie. Pamiętasz tabliczkę mnożenia? Jak ci się z nimi pracowało?
Tak, były arkusze, które próbowały pokazać, jak działa mnożenie. Ale dla wielu uczniów celem było zapamiętanie funkcji.
Kiedy słyszę 6x7, tak naprawdę nie robię obliczeń w mojej głowie. Zamiast tego pamiętam, jak mój ojciec w kółko wiercił moją tabliczkę mnożenia. 6x7 to 42, nie dlatego, że to wiem, ale dlatego, że zapamiętałem 42.

Mówię to, ponieważ jest to bliższe temu, jak LLM radzą sobie z matematyką. LLM patrzą na wzorce w ogromnych obszarach tekstu. Nie wie, co to jest „2”, tylko że słowo/znak „2” zwykle pojawia się w pewnych kontekstach.
W szczególności OpenAI jest zainteresowane rozwiązaniem tej luki w logicznym rozumowaniu. GPT-4, ich najnowszy model, jest tym, który według nich ma lepsze logiczne rozumowanie. Chociaż nie jestem inżynierem OpenAI, chcę porozmawiać o niektórych sposobach, w jakie prawdopodobnie pracowali, aby uczynić GPT-4 bardziej modelem rozumowania.
W ten sam sposób, w jaki Google dąży do doskonałości algorytmicznej w wyszukiwaniu, mając nadzieję na uniknięcie czynnika ludzkiego w rankingu linków, tak samo OpenAI ma na celu radzenie sobie ze słabościami modeli LLM.
OpenAI działa na dwa sposoby, aby dać ChatGPT lepsze możliwości „rozumowania”:
- Używanie samego GPT lub zewnętrznych narzędzi (np. innych algorytmów uczenia maszynowego).
- Korzystanie z innych rozwiązań kodowych innych niż LLM.
W pierwszej grupie OpenAI dostraja modele jeden na drugim. To właściwie różnica między ChatGPT a zwykłym GPT.
Zwykły GPT to silnik, który po zdaniu po prostu wyszukuje prawdopodobne następne tokeny. Z drugiej strony ChatGPT to model wyszkolony w zakresie poleceń i kolejnych kroków.
Jedna rzecz, która pojawia się jako zmarszczka przy nazywaniu GPT „fantazyjną autokorektą”, to sposób, w jaki te warstwy wchodzą ze sobą w interakcje, oraz głęboka zdolność modeli tej wielkości do rozpoznawania wzorców i stosowania ich w różnych kontekstach.
Model jest w stanie nawiązać powiązania między odpowiedziami, oczekiwaniami dotyczącymi sposobu i kontekstu zadawania różnych pytań.
Nawet jeśli nikt nie pytał o „wyjaśnianie statystyk za pomocą metafory o delfinach”, GPT może wykorzystać te powiązania we wszystkich dziedzinach i je rozwinąć. Zna kształt wyjaśniania tematu za pomocą metafory, wie, jak działają statystyki i czym są delfiny.
Jednak każdy, kto regularnie ma do czynienia z GPT, może stwierdzić, że im dalej od materiałów szkoleniowych GPT, tym gorszy wynik.
OpenAI ma model, który jest szkolony na różnych poziomach, w odniesieniu do:
- Rozmowy.
- Unikanie kontrowersyjnych odpowiedzi.
- Przestrzeganie wytycznych.
Każdy, kto spędził czas próbując sprawić, by GPT działał poza jego parametrami, może powiedzieć, że kontekst i polecenia są nieskończenie modułowe. Ludzie są kreatywni i mogą wymyślać niezliczone sposoby na łamanie zasad.
Wszystko to oznacza, że OpenAI może wyszkolić LLM w zakresie „rozumowania”, poddając go warstwom rozumowania, aby naśladował i rozpoznawał wzorce.
Zapamiętywanie odpowiedzi, a nie ich rozumienie.
Innym sposobem, w jaki OpenAI może dodać możliwości rozumowania do swoich modeli, jest użycie innych elementów. Ale te mają swój własny zestaw problemów. Możesz zobaczyć, jak OpenAI próbuje rozwiązać problemy z GPT za pomocą rozwiązań innych niż GPT za pomocą wtyczek.
Wtyczka czytnika linków jest przeznaczona dla ChatGPT (GPT-4). Pozwala użytkownikowi dodawać linki do ChatGPT, a agent odwiedza link i pobiera treść. Ale jak GPT to robi?
Daleka od „myślenia” i decydowania o dostępie do tych linków, wtyczka zakłada, że każdy link jest niezbędny.
Gdy tekst jest analizowany, łącza są odwiedzane, a kod HTML jest umieszczany w danych wejściowych. Trudno jest bardziej elegancko zintegrować tego rodzaju wtyczki.
Na przykład wtyczka Bing umożliwia wyszukiwanie za pomocą Bing, ale agent zakłada, że chcesz wyszukiwać znacznie częściej niż odwrotnie.
Dzieje się tak dlatego, że nawet przy wielu poziomach szkolenia trudno jest zapewnić spójne odpowiedzi ze strony GPT. Jeśli pracujesz z interfejsem API OpenAI, może to pojawić się natychmiast. Możesz oznaczyć „jako otwarty model sztucznej inteligencji”, ale niektóre odpowiedzi będą miały inną strukturę zdań i różne sposoby odmowy.
Utrudnia to napisanie mechanicznej odpowiedzi kodu, ponieważ wymaga spójnych danych wejściowych.
Jeśli chcesz zintegrować wyszukiwanie z aplikacją OpenAI, jakie wyzwalacze uruchamiają funkcję wyszukiwania?
Co zrobić, jeśli chcesz porozmawiać o wyszukiwaniu w artykule? Podobnie dzielenie danych wejściowych może być trudne, ponieważ.
ChatGPT ma trudności z odróżnieniem różnych części zachęty, ponieważ modele te mają trudności z odróżnieniem fantazji od rzeczywistości.
Niemniej jednak najłatwiejszym sposobem na umożliwienie GPT rozumowania jest zintegrowanie czegoś, co jest lepsze w rozumowaniu. To wciąż łatwiej powiedzieć niż zrobić.
Ryan Jones miał dobry wątek na ten temat na Twitterze:
Następnie wracamy do kwestii działania LLM.
Nie ma kalkulatora ani procesu myślowego, wystarczy odgadnąć następny termin na podstawie ogromnego zbioru tekstów.
Przypadek 3: GPT a zagadki
Moje ulubione etui do tego typu rzeczy? Zagadki dla dzieci.
Jedno z czterech słów z każdego zestawu nie pasuje. Które słowo nie należy?
- Zielony, żółty, czerwony, niebieski.
- kwiecień, grudzień, listopad, czerwiec.
- Cirrus, rachunek różniczkowy, cumulus, stratus.
- Marchew, rzodkiewka, ziemniaki, kapusta.
- Widelec, grzebień, grabie, łopata.
Pomyśl o tym przez chwilę. Zapytaj dziecko.
Oto rzeczywiste odpowiedzi:
- Zielony. Żółty, czerwony i niebieski to kolory podstawowe. Zielony nie.
- Grudzień. Pozostałe miesiące mają tylko 30 dni.
- Rachunek różniczkowy. Pozostałe to rodzaje chmur.
- Kapusta. Pozostałe to warzywa rosnące pod ziemią.
- Łopata. Pozostałe mają rogi.
Przyjrzyjmy się teraz niektórym odpowiedziom z GPT:

Co ciekawe, kształt tej odpowiedzi jest poprawny. Okazało się, że poprawną odpowiedzią było „nie jest to kolor podstawowy”, ale kontekst nie był wystarczający, aby wiedzieć, jakie są kolory podstawowe lub jakie są kolory.
Można to nazwać zapytaniem jednorazowym. Nie dostarczam dodatkowych szczegółów do modelu i oczekuję, że sam rozwiąże problem. Ale, jak widzieliśmy w poprzednich odpowiedziach, GPT może się mylić z nadmiernym monitowaniem.
GPT nie jest inteligentny. Choć imponujący, nie jest tak „ogólnego przeznaczenia”, jak by chciał.
Nie zna kontekstu tego, co mówi lub robi, ani nie wie, czym jest słowo.
Dla GPT świat to matematyka.
Tokeny to po prostu wektory tańczące razem, reprezentujące sieć w szerokiej gamie połączonych ze sobą punktów.

LLM nie są takie mądry, jak myślisz
Prawnik, który użył ChatGPT w sprawie sądowej, powiedział, że „myślał, że to wyszukiwarka”.
Ten głośny przypadek nadużyć zawodowych jest zabawny, ale ogarnia mnie strach przed konsekwencjami.
Prawnik – znawca tematu – wykonujący wysoko wykwalifikowaną, wysoko płatną pracę, przekazał te informacje do sądu.
W całym kraju setki ludzi robią to samo, ponieważ jest to prawie jak wyszukiwarka, wydaje się ludzkie i wygląda dobrze.
Treść strony internetowej może być wysoka – wszystko może być. Dezinformacja jest już szerząca się w Internecie, a ChatGPT zjada to, co zostało.
Musimy zbierać metal z zatopionych statków, ponieważ nie został napromieniowany.
Podobnie dane sprzed 2022 roku staną się gorącym towarem, bo wynikają z tego, jaki tekst ma być – unikalny, ludzki i prawdziwy.
Wiele tego rodzaju dyskursów wydaje się wynikać z kilku podstawowych przyczyn, takich jak niezrozumienie działania GPT i niezrozumienie, do czego służy.
Do pewnego stopnia OpenAI można pociągnąć do odpowiedzialności za te nieporozumienia. Tak bardzo chcą rozwijać sztuczną inteligencję ogólną, że akceptacja słabości w tym, co może zrobić GPT, jest trudna.
GPT jest „panem wszystkiego”, więc nie może być panem niczego.
Jeśli nie może mówić obelg, nie może moderować treści.
Jeśli ma mówić prawdę, nie może pisać fikcji.
Jeśli ma być posłuszna użytkownikowi, nie zawsze może być dokładna.
GPT nie jest wyszukiwarką, chatbotem, twoim przyjacielem, ogólną inteligencją, ani nawet fantazyjną autokorektą.
To masowo stosowana statystyka, rzucanie kośćmi w celu układania zdań. Ale kwestia przypadku polega na tym, że czasami wykonujesz niewłaściwy strzał.
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.