
Szacowanie czasu, kosztów i wyników projektu aplikacji ML
Opublikowany: 2019-11-20Wyobraź sobie, że zamierzasz kupić w sklepie spersonalizowany portfel.
Chociaż wiesz, jakiego rodzaju portfela potrzebujesz, ale nie znasz kosztów ani czasu potrzebnego na uzyskanie dostosowanej wersji.
To samo dotyczy projektów uczenia maszynowego. Aby pomóc Ci rozwiązać ten dylemat, udostępniliśmy szczegółowe informacje, dzięki którym projekt będzie udany.
Uczenie maszynowe jest jak moneta, która ma dwie strony .
Z jednej strony pomaga wyeliminować niepewności z procesów. Ale z drugiej strony jego rozwój jest pełen niepewności.
Podczas gdy efektem końcowym prawie każdego projektu uczenia maszynowego (ML) jest rozwiązanie, które usprawnia firmy i usprawnia procesy; jego część rozwojowa ma do opowiedzenia zupełnie inną historię.
Mimo że ML odegrał ogromną rolę w zmianie historii zysków i modelu biznesowego kilku uznanych marek aplikacji mobilnych, nadal działa w początkach. Ta nowość z kolei sprawia, że twórcom aplikacji mobilnych jeszcze trudniej jest obsłużyć plan projektu ML i przygotować go do produkcji, mając na uwadze ograniczenia czasowe i kosztowe.
Rozwiązaniem ( prawdopodobnie jedynym rozwiązaniem ) tej trudności jest czarno-białe oszacowanie czasu, kosztów i rezultatów projektu aplikacji do uczenia maszynowego.
Ale zanim przejdziemy do tych odcinków, przyjrzyjmy się najpierw, co sprawia, że trudność i palenie nocnych świec jest tego warte.
Dlaczego Twoja aplikacja potrzebuje platformy uczenia maszynowego?
Być może zastanawiasz się, dlaczego mówimy o frameworku w środku szacowania czasu, kosztów i rezultatów.
Ale prawdziwy powód czasu i kosztów leży tutaj, który informuje nas o motywach rozwoju aplikacji. Niezależnie od tego, czy potrzebujesz uczenia maszynowego do:
Za oferowanie spersonalizowanego doświadczenia
Do włączenia wyszukiwania zaawansowanego m
Do przewidywania zachowania użytkownika
Dla lepszego bezpieczeństwa
Dla głębokiego zaangażowania użytkowników
Z tych powodów czas, koszt i wynik będą odpowiednio zależeć.
Rodzaje modeli uczenia maszynowego
Jaki model byś rozważył, aby dostosować czas i koszt? Jeśli nie wiesz, udostępniliśmy informacje, które pomogą Ci zrozumieć i wybrać modele, w zależności od Twoich wymagań i budżetu.
Uczenie maszynowe w różnych przypadkach użycia można podzielić na trzy typy modeli, które odgrywają rolę w przekształcaniu podstawowych aplikacji w inteligentne aplikacje mobilne – nadzorowane, nienadzorowane i wzmacniane. Wiedza o tym, co oznaczają te modele uczenia maszynowego, pomaga zdefiniować sposób tworzenia aplikacji obsługującej ML.
Nadzorowana nauka
Jest to proces, w którym system otrzymuje dane, w których wejścia algorytmu i ich wyjścia są odpowiednio oznakowane. Ponieważ informacje wejściowe i wyjściowe są oznakowane, system jest szkolony do identyfikowania wzorców danych w algorytmie.
Staje się tym korzystniejsza, że jest wykorzystywana do przewidywania wyniku na podstawie przyszłych danych wejściowych. Przykładem tego jest sytuacja, w której media społecznościowe rozpoznają czyjąś twarz po oznaczeniu na zdjęciu.
Nauka nienadzorowana
W przypadku uczenia nienadzorowanego dane są wprowadzane do systemu, ale jego wyjścia nie są etykietowane jak w przypadku modelu nadzorowanego. Pozwala systemowi identyfikować dane i określać wzorce z informacji. Po zapisaniu wzorców wszystkie przyszłe dane wejściowe są przypisane do wzorca w celu wygenerowania danych wyjściowych.
Przykład tego modelu można zobaczyć w przypadkach, gdy media społecznościowe podają znajomym sugestie na podstawie kilku znanych danych, takich jak demografia, wykształcenie itp.
Nauka wzmacniania
Podobnie jak w przypadku uczenia nienadzorowanego, dane, które są przekazywane do systemu w uczeniu ze wzmocnieniem, również nie są oznakowane. Oba typy uczenia maszynowego różnią się na tej podstawie, że gdy zostaną wygenerowane prawidłowe dane wyjściowe, system otrzymuje informację, że dane wyjściowe są prawidłowe. Ten rodzaj uczenia się umożliwia systemowi uczenie się na podstawie otoczenia i doświadczeń.
Przykład tego można zobaczyć w Spotify. Aplikacja Spotify rekomenduje utwory , które użytkownicy muszą następnie albo kciuki w górę, albo kciuki w dół. Na podstawie dokonanej selekcji aplikacja Spotify uczy się gustów muzycznych użytkowników.
Cykl życia projektu uczenia maszynowego
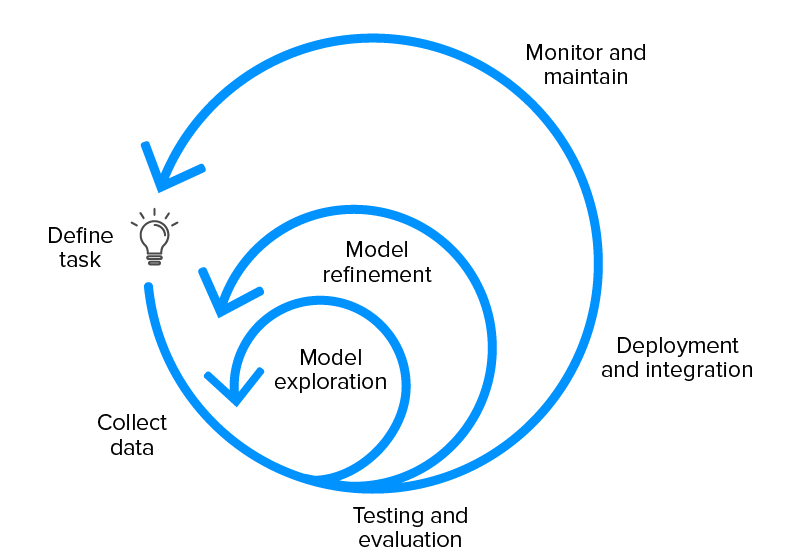
Cykl życia osi czasu elementów projektu uczenia maszynowego zwykle wygląda tak:
Konfiguracja planu projektu ML
- Zdefiniuj zadanie i wymagania
- Określ wykonalność projektu
- Omów ogólne kompromisy modelu
- Utwórz bazę kodu projektu
Gromadzenie i etykietowanie danych
- Utwórz dokumentację oznakowania
- Zbuduj potok pozyskiwania danych
- Walidacja jakości danych
Eksploracja modeli
- Ustal punkt odniesienia dla wydajności modelu
- Utwórz prosty model z początkowym potokiem danych
- Wypróbuj równoległe pomysły na wczesnych etapach
- Znajdź model SoTA dla problematycznej domeny, jeśli istnieje, i odtwórz wyniki.
Udoskonalenie modelu
- Wykonuj optymalizacje zorientowane na model
- Debuguj modele wraz ze wzrostem złożoności
- Przeprowadź analizę błędów w celu wykrycia trybów awarii.
Testuj i oceniaj
- Oceń model na rozkładzie testów
- Sprawdź ponownie metrykę oceny modelu, upewniając się, że napędza ona pożądane zachowanie użytkownika
- Napisz testy dla – funkcji wnioskowania modelu, potoku danych wejściowych, jawnych scenariuszy oczekiwanych w produkcji.
Wdrożenie modelu
- Ujawnij model przez REST API
- Wdróż nowy model na podzbiorze użytkowników, aby upewnić się, że wszystko jest płynne przed ostatecznym wdrożeniem.
- Możliwość przywrócenia modeli do poprzedniej wersji
- Monitoruj dane na żywo.
Konserwacja modelu
- Przeszkol ponownie model, aby zapobiec przestarzałości modelu
- Poinformuj zespół, jeśli dojdzie do przeniesienia własności modelu
Jak oszacować zakres projektu uczenia maszynowego?
Zespół Appinventiv Machine Learning po zapoznaniu się z typem uczenia maszynowego i cyklem rozwojowym , definiuje oszacowanie projektu aplikacji Machine Learning w następujących fazach:
Faza 1 – Odkrycie (7 do 14 dni)
Mapa drogowa projektu ML zaczyna się od zdefiniowania problemu. Analizuje problemy i nieefektywności operacyjne, którymi należy się zająć.
Celem jest tutaj zidentyfikowanie wymagań i sprawdzenie, czy uczenie maszynowe spełnia cele biznesowe . Etap ten wymaga od naszych inżynierów spotkania się z ludźmi biznesu po stronie klienta, aby zrozumieć ich wizję w zakresie problemów, które chcą rozwiązać.
Po drugie, zespół programistów powinien określić, jakie dane posiada i czy będzie musiał je pobrać z usług zewnętrznych.
Następnie programiści muszą ocenić, czy są w stanie nadzorować algorytmy – czy zwraca poprawną odpowiedź za każdym razem, gdy dokonywana jest prognoza.
Deliverable — stwierdzenie problemu, które określiłoby, czy projekt jest trywialny, czy też będzie złożony.
Faza 2 – Eksploracja (6 do 8 tygodni)
Celem tego etapu jest zbudowanie dowodu koncepcji, który można następnie zainstalować jako API. Po przeszkoleniu modelu bazowego nasz zespół ekspertów ML szacuje wydajność rozwiązania gotowego do produkcji.
Ten etap daje nam jasność, jakiej wydajności należy się spodziewać w przypadku metryk zaplanowanych na etapie odkrywania.
Produkt dostarczany — dowód koncepcji
Faza 3 – Rozwój (4+ miesiące)
Jest to etap, w którym zespół pracuje iteracyjnie, aż do uzyskania odpowiedzi gotowej do produkcji. Ponieważ do momentu osiągnięcia tego etapu przez projekt istnieje znacznie mniej niepewności, oszacowanie staje się bardzo precyzyjne.
Ale jeśli wynik nie ulegnie poprawie, programiści musieliby zastosować inny model lub przerobić dane, a nawet zmienić metodę, jeśli zajdzie taka potrzeba.
Na tym etapie nasi programiści pracują w sprintach i decydują, co należy zrobić po każdej indywidualnej iteracji. Wyniki każdego sprintu można skutecznie przewidzieć.
Chociaż wynik sprintu można skutecznie przewidzieć, planowanie sprintów z wyprzedzeniem może być błędem w przypadku uczenia maszynowego, ponieważ będziesz pracować na niezbadanych wodach.

Dostarczalne – gotowe do produkcji rozwiązanie ML
Faza 4 – Doskonalenie (ciągłe)
Po wdrożeniu decydenci prawie zawsze spieszą się z zakończeniem projektu, aby zaoszczędzić koszty. Chociaż formuła działa w 80% projektów, to samo nie dotyczy aplikacji uczenia maszynowego.
Dzieje się tak, że dane zmieniają się na całej osi czasu projektu uczenia maszynowego. To jest powód, dla którego model AI musi być stale monitorowany i przeglądany – aby uchronić go przed degradacją i zapewnić bezpieczną sztuczną inteligencję umożliwiającą tworzenie aplikacji mobilnych .
Projekty zorientowane na Machine Learning wymagają czasu na osiągnięcie satysfakcjonujących rezultatów. Nawet jeśli zauważysz, że Twoje algorytmy od samego początku przewyższają testy porównawcze, istnieje duże prawdopodobieństwo, że będą to jedno uderzenie, a program może się zgubić, gdy zostanie użyty na innym zbiorze danych.
Czynniki wpływające na całkowity koszt
Sposób tworzenia systemu uczenia maszynowego ma pewne cechy wyróżniające, takie jak kwestie związane z danymi i czynniki związane z wydajnością, które decydują o ostatnim wydatku.
Kwestie związane z danymi
Rozwój niezawodnego uczenia maszynowego zależy nie tylko od fenomenalnego kodowania, ale kluczową rolę odgrywa również jakość i ilość informacji szkoleniowych.
- Brak odpowiednich danych
- Złożone procedury ekstrakcji, transformacji, ładowania
- Przetwarzanie nieustrukturyzowanych danych
Problemy związane z wydajnością
Odpowiednia wydajność algorytmu to kolejny ważny czynnik kosztowy, ponieważ wysokiej jakości algorytm wymaga kilku rund sesji strojenia.
- Dokładność waha się
- Wydajność algorytmów przetwarzania
Jak szacujemy koszt projektu uczenia maszynowego?
Kiedy mówimy o szacowaniu kosztów projektu uczenia maszynowego, ważne jest, aby najpierw określić, o jakim typie projektu jest mowa.
Istnieją głównie trzy typy projektów uczenia maszynowego , które odgrywają rolę w odpowiedzi na pytanie, ile kosztuje uczenie maszynowe:
Po pierwsze – ten typ ma już rozwiązanie – zarówno architektura modelu, jak i zbiór danych już istnieją. Tego typu projekty są praktycznie bezpłatne, więc nie będziemy o nich mówić.
Po drugie – te projekty wymagają badań fundamentalnych – zastosowania ML w zupełnie nowej domenie lub na innych strukturach danych w porównaniu z modelami głównego nurtu. Koszt tego typu projektów to zazwyczaj taki , na który większość startupów nie może sobie pozwolić.
Po trzecie – na tych właśnie będziemy się skupiać w naszych kosztorysach. Tutaj bierzesz architekturę modelu i algorytmy, które już istnieją, a następnie zmieniasz je, aby pasowały do danych, nad którymi pracujesz.
Przejdźmy teraz do części, w której szacujemy koszt projektu ML.
Koszt danych
Dane to podstawowa waluta projektu uczenia maszynowego. Maksimum rozwiązań i badań koncentruje się na odmianach nadzorowanego modelu uczenia się. Powszechnie wiadomo , że im głębiej idzie nauka nadzorowana, tym większe zapotrzebowanie na dane z adnotacjami, a co za tym idzie, tym wyższy jest koszt opracowania aplikacji do uczenia maszynowego .
Teraz, podczas gdy usługi takie jak Scale i Amazon's Mechanical Turk mogą pomóc w gromadzeniu danych i opatrywaniu ich adnotacjami, co z jakością?
Sprawdzenie, a następnie poprawienie próbek danych może być niezwykle czasochłonne. Rozwiązanie problemu jest dwojakie – zlecaj gromadzenie danych na zewnątrz lub udoskonalaj je wewnętrznie.
Większość prac związanych z walidacją i udoskonalaniem danych należy zlecić na zewnątrz, a następnie wyznaczyć jedną lub dwie osoby w firmie do czyszczenia próbek danych i oznaczania ich.
Koszt badań
Część badawcza projektu, jak wspomnieliśmy powyżej, dotyczy studium wykonalności na poziomie podstawowym, wyszukiwania algorytmów i fazy eksperymentów. Informacje, które zwykle pojawiają się w Warsztacie Dostawy Produktów . Zasadniczo etap eksploracyjny to etap, przez który przechodzi każdy projekt przed jego produkcją.
Ukończenie etapu z najwyższą perfekcją to proces, do którego dołączona jest dołączona liczba w kosztach wdrożenia dyskusji ML.
Koszt produkcji
Część produkcyjna kosztów projektu uczenia maszynowego składa się z kosztu infrastruktury, kosztu integracji i kosztu konserwacji. Z tych kosztów będziesz musiał ponieść najmniejsze wydatki na obliczenia w chmurze. Ale to również będzie się różnić w zależności od złożoności jednego algorytmu.
Koszt integracji różni się w zależności od przypadku użycia. Zazwyczaj wystarczy umieścić punkt końcowy API w chmurze i udokumentować go, aby następnie był używany przez resztę systemu.
Jednym z kluczowych czynników, który ludzie zwykle przeoczają podczas opracowywania projektu uczenia maszynowego, jest potrzeba przekazywania ciągłego wsparcia przez cały cykl życia projektu. Dane przychodzące z interfejsów API muszą zostać odpowiednio wyczyszczone i opatrzone adnotacjami. Następnie modele muszą zostać przeszkolone na nowych danych i przetestowane, wdrożone.
Oprócz punktów wymienionych powyżej istnieją jeszcze dwa czynniki, które mają znaczenie przy szacowaniu kosztów opracowania aplikacji AI/aplikacji ML .
Wyzwania w tworzeniu aplikacji do uczenia maszynowego

Zwykle podczas sporządzania oszacowania projektu aplikacji do uczenia maszynowego uwzględniane są również związane z nim wyzwania rozwojowe . Mogą jednak wystąpić sytuacje, w których wyzwania znajdują się w połowie procesu tworzenia aplikacji opartej na ML. W takich przypadkach automatycznie wzrasta całkowity czas i oszacowanie kosztów.
Wyzwania dla projektów uczenia maszynowego mogą obejmować:
- Decydowanie, jaki zestaw funkcji stanie się funkcjami uczenia maszynowego
- Deficyt talentów w domenie AI i Machine Learning
- Pozyskiwanie zbiorów danych jest drogie
- Osiągnięcie satysfakcjonujących rezultatów wymaga czasu
Wniosek
Oszacowanie siły roboczej i czasu potrzebnego do ukończenia projektu oprogramowania jest stosunkowo łatwe, gdy jest opracowywane na podstawie konstrukcji modułowych i obsługiwane przez doświadczony zespół stosujący podejście Agile . To samo staje się jednak jeszcze trudniejsze, gdy pracujesz nad oszacowaniem czasu i wysiłku, mądrego projektu aplikacji do uczenia maszynowego.
Nawet jeśli cele mogą być dobrze zdefiniowane, nie ma gwarancji, czy model osiągnie pożądany rezultat. Zwykle nie jest możliwe obniżenie zakresu, a następnie uruchomienie projektu w określonych ramach czasowych przez zdefiniowaną wcześniej datę dostawy.
Niezwykle ważne jest, abyś zidentyfikował, że będą niejasności. Podejściem, które może pomóc złagodzić opóźnienia, jest zapewnienie, że dane wejściowe są w odpowiednim formacie dla uczenia maszynowego.
Jednak ostatecznie, bez względu na to, które podejście zamierzasz zastosować, zostanie ono uznane za skuteczne tylko wtedy, gdy nawiążesz współpracę z agencją rozwoju aplikacji Machine Learning, która wie, jak opracowywać i wdrażać złożoność w najprostszej formie.
Często zadawane pytania dotyczące szacowania projektu aplikacji do uczenia maszynowego
P. Dlaczego warto korzystać z uczenia maszynowego podczas tworzenia aplikacji?
Istnieje wiele korzyści, które firmy mogą odnieść dzięki włączeniu uczenia maszynowego do swoich aplikacji mobilnych. Niektóre z najbardziej rozpowszechnionych dotyczą marketingu aplikacji –
- Oferowanie spersonalizowanych doświadczeń
- Zaawansowane wyszukiwanie
- Przewidywanie zachowania użytkownika
- Większe zaangażowanie użytkowników
P. Jak uczenie maszynowe może pomóc Twojej firmie?
Korzyści z uczenia maszynowego dla firm wykraczają poza oznaczenie ich jako marki przełomowej. Sprowadza się to do tego, że ich oferty stają się bardziej spersonalizowane i dostępne w czasie rzeczywistym.
Uczenie maszynowe może być tajną formułą, która przybliża firmy do klientów, dokładnie tak, jak chcą, aby do nich podchodzić.
P. Jak oszacować ROI przy tworzeniu projektu uczenia maszynowego?
Chociaż artykuł pomógłby w ustaleniu oszacowania projektu aplikacji do uczenia maszynowego, obliczanie zwrotu z inwestycji to inna gra. Będziesz musiał również wziąć pod uwagę koszt alternatywny w miksie. Dodatkowo będziesz musiał przyjrzeć się oczekiwaniom, jakie Twoja firma ma od projektu.
P. Która platforma jest lepsza dla projektu ML?
Twój wybór, czy chcesz połączyć się z firmą zajmującą się tworzeniem aplikacji na Androida, czy z programistami iOS, będzie zależał całkowicie od bazy użytkowników i intencji – niezależnie od tego, czy chodzi o zysk, czy o wartość.