
Przewodnik SEO dotyczący zrozumienia dużych modeli językowych (LLM)
Opublikowany: 2023-05-08Czy powinienem używać dużych modeli językowych do badania słów kluczowych? Czy te modele potrafią myśleć? Czy ChatGPT jest moim przyjacielem?
Jeśli zadawałeś sobie te pytania, ten przewodnik jest dla Ciebie.
W tym przewodniku opisano, co specjaliści SEO powinni wiedzieć o dużych modelach językowych, przetwarzaniu języka naturalnego i wszystkim pomiędzy.
Duże modele językowe, przetwarzanie języka naturalnego i wiele więcej w prostych słowach
Istnieją dwa sposoby, aby skłonić kogoś do zrobienia czegoś – powiedzieć mu, żeby to zrobił, lub mieć nadzieję, że zrobi to sam.
Jeśli chodzi o informatykę, programowanie mówi robotowi, aby to zrobił, podczas gdy uczenie maszynowe ma nadzieję, że robot zrobi to sam. Pierwsza to nadzorowane uczenie maszynowe, a druga to nienadzorowane uczenie maszynowe.
Przetwarzanie języka naturalnego (NLP) to sposób na rozbicie tekstu na liczby, a następnie przeanalizowanie go za pomocą komputerów.
Komputery analizują wzorce w słowach i, w miarę jak stają się bardziej zaawansowane, w relacjach między słowami.
Nienadzorowany model uczenia maszynowego języka naturalnego można trenować na wielu różnych rodzajach zestawów danych.
Na przykład, jeśli wytrenujesz model językowy na podstawie przeciętnych recenzji filmu „Wodny świat”, uzyskasz wynik dobry w pisaniu (lub zrozumieniu) recenzji filmu „Wodny świat”.
Gdybyś wyszkolił go na dwóch pozytywnych recenzjach, które zrobiłem na temat filmu „Waterworld”, zrozumiałby tylko te pozytywne recenzje.
Duże modele językowe (LLM) to sieci neuronowe z ponad miliardem parametrów. Są tak duże, że są bardziej uogólnione. Są szkoleni nie tylko w zakresie pozytywnych i negatywnych recenzji „Waterworld”, ale także w zakresie komentarzy, artykułów w Wikipedii, witryn z wiadomościami i nie tylko.
Projekty uczenia maszynowego często działają z kontekstem — z rzeczami w kontekście i poza nim.
Jeśli masz projekt uczenia maszynowego, który działa w celu identyfikacji błędów i pokazywania mu kota, nie będzie dobry w tym projekcie.
Właśnie dlatego takie rzeczy, jak samojezdne samochody, są tak trudne: jest tak wiele problemów wyrwanych z kontekstu, że bardzo trudno jest uogólnić tę wiedzę.
LLM wydają się i mogą być o wiele bardziej uogólnione niż inne projekty uczenia maszynowego. Wynika to z ogromnego rozmiaru danych i możliwości łączenia miliardów różnych relacji.
Porozmawiajmy o jednej z przełomowych technologii, która na to pozwala – o transformatorach.
Wyjaśnienie transformatorów od podstaw
Rodzaj architektury sieci neuronowej, transformatory zrewolucjonizowały dziedzinę NLP.
Przed transformatorami większość modeli NLP opierała się na technice zwanej rekurencyjnymi sieciami neuronowymi (RNN), która przetwarzała tekst sekwencyjnie, jedno słowo na raz. Takie podejście miało swoje ograniczenia, takie jak powolność i problemy z obsługą dalekosiężnych zależności w tekście.
Transformatory to zmieniły.
W przełomowym artykule z 2017 r. „Uwaga to wszystko, czego potrzebujesz”, Vaswani i in. wprowadził architekturę transformatora.
Zamiast przetwarzać tekst sekwencyjnie, transformatory używają mechanizmu zwanego „samouwagą” do równoległego przetwarzania słów, co pozwala im na bardziej efektywne wychwytywanie zależności dalekiego zasięgu.
Poprzednia architektura obejmowała RNN i algorytmy pamięci długookresowej.
Takie powtarzające się modele były (i nadal są) powszechnie używane do zadań związanych z sekwencjami danych, takimi jak tekst lub mowa.
Jednak te modele mają problem. Mogą przetwarzać dane tylko pojedynczo, co spowalnia ich i ogranicza ilość danych, z którymi mogą pracować. To sekwencyjne przetwarzanie naprawdę ogranicza możliwości tych modeli.
Mechanizmy uwagi zostały wprowadzone jako inny sposób przetwarzania danych sekwencyjnych. Pozwalają modelowi spojrzeć na wszystkie fragmenty danych jednocześnie i zdecydować, które z nich są najważniejsze.
Może to być naprawdę pomocne w wielu zadaniach. Jednak większość modeli, które wykorzystywały uwagę, wykorzystuje również przetwarzanie rekurencyjne.
Zasadniczo mieli ten sposób przetwarzania danych jednocześnie, ale nadal musieli patrzeć na nie w kolejności. Artykuł Vaswani i wsp. płynął: „A co by było, gdybyśmy użyli tylko mechanizmu uwagi?”
Uwaga to sposób, w jaki model może skupić się na pewnych częściach sekwencji wejściowej podczas jej przetwarzania. Na przykład, kiedy czytamy zdanie, naturalnie zwracamy większą uwagę na niektóre słowa niż na inne, w zależności od kontekstu i tego, co chcemy zrozumieć.
Jeśli spojrzysz na transformator, model obliczy wynik dla każdego słowa w sekwencji wejściowej na podstawie tego, jak ważne jest to dla zrozumienia ogólnego znaczenia sekwencji.
Następnie model wykorzystuje te wyniki do zważenia ważności każdego słowa w sekwencji, co pozwala skupić się bardziej na ważnych słowach, a mniej na tych nieważnych.
Ten mechanizm uwagi pomaga modelowi uchwycić dalekosiężne zależności i relacje między słowami, które mogą być daleko od siebie w sekwencji wejściowej, bez konieczności sekwencyjnego przetwarzania całej sekwencji.
To sprawia, że transformer jest tak potężny w zadaniach związanych z przetwarzaniem języka naturalnego, ponieważ może szybko i dokładnie zrozumieć znaczenie zdania lub dłuższej sekwencji tekstu.
Weźmy przykład modelu transformatora przetwarzającego zdanie „Kot usiadł na macie”.
Każde słowo w zdaniu jest reprezentowane jako wektor, seria liczb, przy użyciu macierzy osadzania. Powiedzmy, że osadzania dla każdego słowa to:
- Wartość : [0,2, 0,1, 0,3, 0,5]
- kot : [0,6, 0,3, 0,1, 0,2]
- nasycone : [0,1, 0,8, 0,2, 0,3]
- na : [0,3, 0,1, 0,6, 0,4]
- : [0,5, 0,2, 0,1, 0,4]
- mata : [0,2, 0,4, 0,7, 0,5]
Następnie transformator oblicza wynik dla każdego słowa w zdaniu w oparciu o jego związek ze wszystkimi innymi słowami w zdaniu.
Odbywa się to za pomocą iloczynu skalarnego osadzania każdego słowa z osadzeniem wszystkich innych słów w zdaniu.
Na przykład, aby obliczyć wynik dla słowa „kot”, wzięlibyśmy iloczyn skalarny jego osadzania z osadzaniami wszystkich innych słów:
- „ Kot ”: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- „ kot usiadł ”: 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- „ kot na ”: 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- „ kot ”: 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- „ mata dla kota ”: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Te wyniki wskazują na związek każdego słowa ze słowem „kot”. Transformator następnie wykorzystuje te wyniki do obliczenia ważonej sumy osadzonych słów, gdzie wagi są punktami.
Tworzy to wektor kontekstu dla słowa „kot”, który uwzględnia relacje między wszystkimi słowami w zdaniu. Ten proces jest powtarzany dla każdego słowa w zdaniu.
Pomyśl o tym jak o transformatorze rysującym linię między każdym słowem w zdaniu na podstawie wyniku każdego obliczenia. Niektóre linie są bardziej kruche, a inne mniej.
Transformator to nowy rodzaj modelu, który wykorzystuje tylko uwagę bez żadnego powtarzającego się przetwarzania. Dzięki temu jest znacznie szybszy i jest w stanie obsłużyć więcej danych.
Jak GPT używa transformatorów
Być może pamiętasz, że w ogłoszeniu BERT Google chwalili się, że umożliwiło to wyszukiwarce zrozumienie pełnego kontekstu danych wejściowych. Jest to podobne do tego, jak GPT może używać transformatorów.
Użyjmy analogii.
Wyobraź sobie, że masz milion małp, z których każda siedzi przed klawiaturą.
Każda małpa losowo uderza w klawisze na swojej klawiaturze, generując ciągi liter i symboli.
Niektóre ciągi są kompletnym nonsensem, podczas gdy inne mogą przypominać prawdziwe słowa lub nawet spójne zdania.
Pewnego dnia jeden z treserów cyrku widzi, że małpa napisała „Być albo nie być”, więc treser daje małpce smakołyk.
Inne małpy to widzą i zaczynają naśladować małpę, która odniosła sukces, mając nadzieję na własną ucztę.
W miarę upływu czasu niektóre małpy zaczynają konsekwentnie tworzyć lepsze i bardziej spójne ciągi tekstowe, podczas gdy inne nadal wytwarzają bełkot.
W końcu małpy potrafią rozpoznawać, a nawet naśladować spójne wzorce w tekście.
LLM mają przewagę nad małpami, ponieważ LLM są najpierw szkolone na miliardach fragmentów tekstu. Już widzą wzory. Rozumieją również wektory i relacje między tymi fragmentami tekstu.
Oznacza to, że mogą używać tych wzorców i relacji do generowania nowego tekstu, który przypomina język naturalny.
GPT, co oznacza Generative Pre-trained Transformer, to model języka, który wykorzystuje transformatory do generowania tekstu w języku naturalnym.
Został przeszkolony na ogromnej ilości tekstu z Internetu, co pozwoliło mu poznać wzorce i relacje między słowami i wyrażeniami w języku naturalnym.
Model działa, pobierając zachętę lub kilka słów tekstu i używając transformatorów do przewidywania, jakie słowa powinny się pojawić w następnej kolejności, na podstawie wzorców wyuczonych z danych treningowych.
Model nadal generuje tekst słowo po słowie, wykorzystując kontekst poprzednich słów do informowania o kolejnych.
GTP w akcji
Jedną z zalet GPT jest to, że może generować tekst w języku naturalnym, który jest wysoce spójny i odpowiedni kontekstowo.
Ma to wiele praktycznych zastosowań, takich jak generowanie opisów produktów lub odpowiadanie na zapytania obsługi klienta. Można go również wykorzystać twórczo, na przykład do generowania poezji lub opowiadań.
Jest to jednak tylko model językowy. Jest przeszkolony na danych, a dane mogą być nieaktualne lub nieprawidłowe.
- Nie ma żadnego źródła wiedzy.
- Nie może przeszukiwać Internetu.
- Niczego „nie wie”.
Po prostu zgaduje, jakie słowo będzie następne.
Spójrzmy na kilka przykładów:
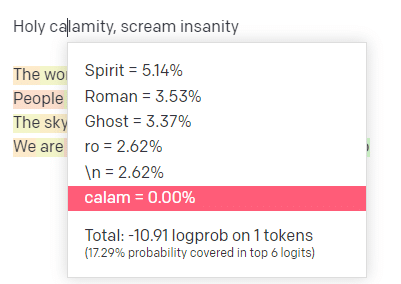
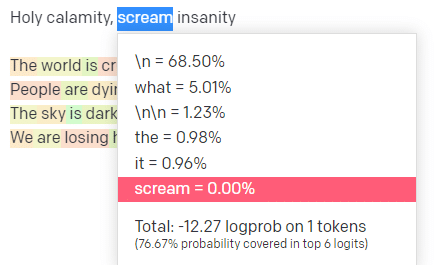
Na placu zabaw OpenAI podłączyłem pierwszą linijkę klasycznego utworu Handsome Boy Modeling School „Holy Calamity [[Bear Witness ii]]”.
Przesłałem odpowiedź, abyśmy mogli zobaczyć prawdopodobieństwo zarówno moich linii wejściowych, jak i wyjściowych. Przeanalizujmy więc każdą część tego, co nam to mówi.
Jako pierwsze słowo/znak wpisuję „Święty”. Widzimy, że najbardziej oczekiwanymi kolejnymi danymi wejściowymi są Spirit, Roman i Ghost.
Widzimy również, że sześć najlepszych wyników obejmuje tylko 17,29% prawdopodobieństwa tego, co nastąpi dalej: co oznacza, że istnieje około 82% innych możliwości, których nie widzimy w tej wizualizacji.
Omówmy pokrótce różne dane wejściowe, których możesz użyć w tym przypadku, oraz ich wpływ na wyniki.
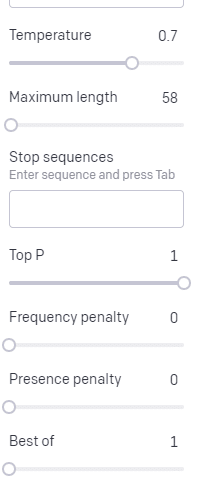
Temperatura to prawdopodobieństwo, że model uchwyci słowa inne niż te z najwyższym prawdopodobieństwem, górne P to sposób, w jaki wybiera te słowa.
Tak więc dla wejścia „Święte nieszczęście” górne P wskazuje, w jaki sposób wybieramy klaster kolejnych żetonów [Duch, Rzymianin, Duch], a temperatura wskazuje, jakie jest prawdopodobieństwo wybrania najbardziej prawdopodobnego żetonu w porównaniu z większą różnorodnością.
Jeśli temperatura jest wyższa, bardziej prawdopodobne jest wybranie mniej prawdopodobnego żetonu.
Tak więc wysoka temperatura i wysokie górne P będą prawdopodobnie bardziej dzikie. Wybiera z szerokiej gamy (wysokie P) i częściej wybiera zaskakujące żetony.


Podczas gdy wysoka temperatura, ale niższa górna część P wybierze zaskakujące opcje z mniejszej próbki możliwości:

A obniżenie temperatury po prostu wybiera najbardziej prawdopodobne następne żetony:

Gra z tymi prawdopodobieństwami może, moim zdaniem, dać dobry wgląd w działanie tego rodzaju modeli.
Patrzy na zbiór prawdopodobnych następnych wyborów w oparciu o to, co już zostało zakończone.
Co to właściwie oznacza?
Mówiąc najprościej, LLM pobierają zbiór danych wejściowych, wstrząsają nimi i przekształcają je w dane wyjściowe.
Słyszałem, jak ludzie żartują, czy to tak bardzo różni się od ludzi.
Ale to nie tak jak ludzie – LLM nie mają bazy wiedzy. Nie wyciągają informacji o czymś. Zgadują ciąg słów na podstawie ostatniego.
Inny przykład: pomyśl o jabłku. Co przychodzi na myśl?
Może możesz obrócić jeden w swoim umyśle.
Być może pamiętasz zapach sadu jabłoniowego, słodycz różowej damy itp.
Może myślisz o Steve Jobsie.
Zobaczmy teraz, co zwraca monit „pomyśl o jabłku”.
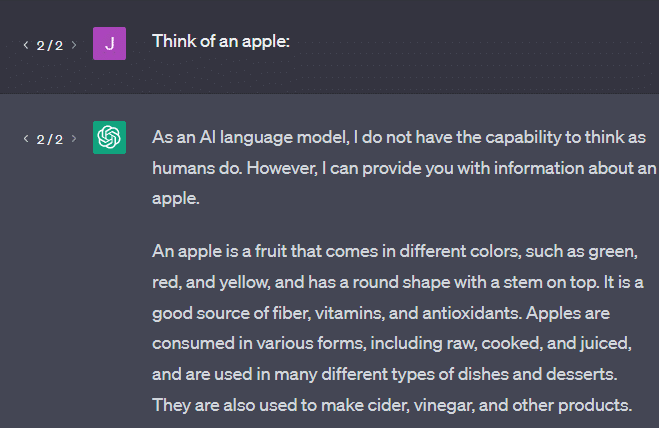
Być może słyszałeś w tym momencie słowa „Stochastyczne papugi”.
Stochastic Parrots to termin używany do opisania LLM, takich jak GPT. Papuga to ptak, który naśladuje to, co słyszy.
Tak więc LLM są jak papugi, ponieważ pobierają informacje (słowa) i wysyłają coś, co przypomina to, co słyszeli. Ale są też stochastyczne , co oznacza, że używają prawdopodobieństwa do odgadnięcia, co będzie dalej.
LLM są dobrzy w rozpoznawaniu wzorców i relacji między słowami, ale nie mają głębszego zrozumienia tego, co widzą. Dlatego są tak dobrzy w generowaniu tekstu w języku naturalnym, ale go nie rozumieją.
Dobre zastosowania dla LLM
LLM są dobre w bardziej ogólnych zadaniach.
Możesz pokazać mu tekst, a bez szkolenia może wykonać zadanie z tym tekstem.
Możesz podrzucić mu jakiś tekst i poprosić o analizę sentymentu, poprosić o przeniesienie tego tekstu do znaczników strukturalnych i wykonać trochę pracy twórczej (np. pisanie konspektów).
Jest OK w takich rzeczach jak kod. W przypadku wielu zadań prawie cię tam zaprowadzi.
Ale znowu, opiera się na prawdopodobieństwie i wzorach. Tak więc będą chwile, kiedy wychwyci wzorce w twoich danych wejściowych, o których istnieniu nie wiesz.
Może to być pozytywne (widzenie wzorców, których ludzie nie widzą), ale może być również negatywne (dlaczego zareagowało w ten sposób?).
Nie ma też dostępu do żadnych źródeł danych. SEO, którzy używają go do wyszukiwania słów kluczowych w rankingu, będą mieli zły czas.
Nie może wyszukać ruchu dla słowa kluczowego. Nie zawiera informacji o danych słów kluczowych poza tym, że słowa istnieją.

Ekscytującą rzeczą w ChatGPT jest to, że jest to łatwo dostępny model językowy, którego można używać od razu po wyjęciu z pudełka do różnych zadań. Ale nie jest bez zastrzeżeń.

Dobre zastosowania dla innych modeli ML
Słyszę, jak ludzie mówią, że używają LLM do pewnych zadań, które inne algorytmy i techniki NLP mogą zrobić lepiej.
Weźmy na przykład ekstrakcję słów kluczowych.
Jeśli używam TF-IDF lub innej techniki słów kluczowych, aby wyodrębnić słowa kluczowe z korpusu, wiem, jakie obliczenia idą w tę technikę.
Oznacza to, że wyniki będą standardowe, powtarzalne i wiem, że będą powiązane konkretnie z tym korpusem.
W przypadku LLM, takich jak ChatGPT, jeśli prosisz o wyodrębnienie słów kluczowych, niekoniecznie otrzymujesz słowa kluczowe wyodrębnione z korpusu. Otrzymujesz odpowiedź GPT na słowa kluczowe corpus + extract.
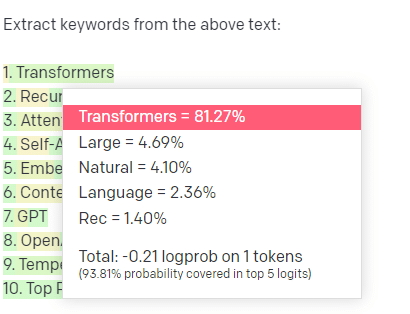
Jest to podobne do zadań takich jak tworzenie klastrów lub analiza tonacji. Niekoniecznie uzyskujesz precyzyjnie dostrojony wynik z ustawionymi parametrami. Otrzymujesz to, co jest prawdopodobne na podstawie innych podobnych zadań.
Ponownie, LLM nie mają bazy wiedzy ani aktualnych informacji. Często nie mogą przeszukiwać sieci i analizują to, co otrzymują z informacji, jako tokeny statystyczne. Ograniczenia dotyczące czasu trwania pamięci LLM wynikają z tych czynników.
Inna sprawa, że te modele nie potrafią myśleć. Używam słowa „myśleć” tylko kilka razy w całym tym utworze, ponieważ naprawdę trudno jest go nie używać, mówiąc o tych procesach.
Tendencja zmierza w kierunku antropomorfizmu, nawet przy omawianiu fantazyjnych statystyk.
Oznacza to jednak, że jeśli powierzysz LLM jakiemukolwiek zadaniu wymagającemu „przemyślenia”, nie ufasz myślącemu stworzeniu.
Ufasz statystycznej analizie tego, jak setki internetowych dziwaków reagują na podobne tokeny.
Jeśli zaufałbyś mieszkańcom Internetu w zadaniu, możesz użyć LLM. W przeciwnym razie…
Rzeczy, które nigdy nie powinny być modelami ML
Chatbot działający w modelu GPT (GPT-J) podobno zachęcał mężczyznę do popełnienia samobójstwa. Połączenie czynników może spowodować realne szkody, w tym:
- Ludzie antropomorfizujący te reakcje.
- Wierząc, że są nieomylni.
- Używanie ich w miejscach, w których ludzie muszą przebywać w maszynie.
- I więcej.
Chociaż możesz pomyśleć: „Jestem SEO. Nie mam ręki do systemów, które mogłyby kogoś zabić!
Pomyśl o stronach YMYL i o tym, jak Google promuje koncepcje takie jak EEAT.
Czy Google robi to, ponieważ chce zirytować SEO, czy może dlatego, że nie chce winy za tę szkodę?
Nawet w systemach o solidnych podstawach wiedzy można wyrządzić krzywdę.
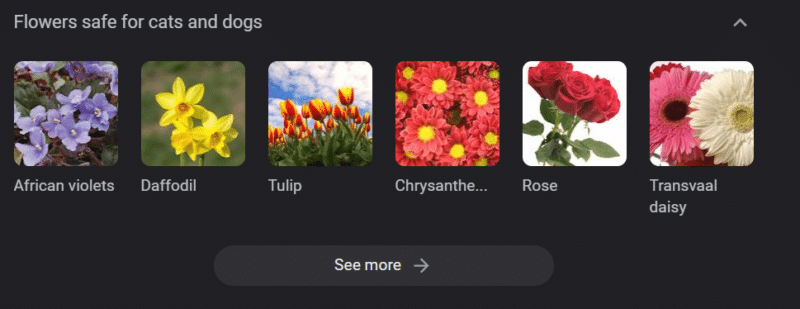
Powyższe to karuzela wiedzy Google dotycząca „kwiatów bezpiecznych dla kotów i psów”. Żonkile znajdują się na tej liście, mimo że są toksyczne dla kotów.
Załóżmy, że generujesz treści dla witryny weterynaryjnej na dużą skalę za pomocą GPT. Podłączasz kilka słów kluczowych i pingujesz API ChatGPT.
Masz freelancera, który czyta wszystkie wyniki i nie jest ekspertem w danej dziedzinie. Nie przejmują się problemem.
Publikujesz wynik, który zachęca właścicieli kotów do kupowania żonkili.
Zabijasz czyjegoś kota.
Nie bezpośrednio. Może nawet nie wiedzą, że to była ta strona.
Może inne strony weterynaryjne zaczną robić to samo i karmić się nawzajem.
Najpopularniejszym wynikiem wyszukiwania Google „czy żonkile są toksyczne dla kotów” jest witryna, która mówi, że nie są.
Inni freelancerzy czytający inne treści AI – strony po stronach treści AI – faktycznie sprawdzają fakty. Ale systemy mają teraz nieprawidłowe informacje.
Omawiając obecny boom na sztuczną inteligencję, często wspominam Therac-25. Jest to słynne studium przypadku nadużyć komputerowych.
Zasadniczo była to maszyna do radioterapii, pierwsza wykorzystująca wyłącznie komputerowe mechanizmy blokujące. Błąd w oprogramowaniu oznaczał, że ludzie otrzymali dziesiątki tysięcy razy większą dawkę promieniowania niż powinni.
Zawsze zwracam uwagę na to, że firma dobrowolnie wycofała i sprawdziła te modele.
Założyli jednak, że skoro technologia jest zaawansowana, a oprogramowanie „nieomylne”, problem dotyczy części mechanicznych maszyny.
W ten sposób naprawili mechanizmy, ale nie sprawdzili oprogramowania – i Therac-25 pozostał na rynku.
Często zadawane pytania i nieporozumienia
Dlaczego ChatGPT mnie okłamuje?
Jedną z rzeczy, które widziałem od największych umysłów naszego pokolenia, a także influencerów na Twitterze, jest skarga, że ChatGPT „kłamie” im. Wynika to z kilku nieporozumień w tandemie:
- Że ChatGPT ma „chce”.
- Że ma bazę wiedzy.
- Że technolodzy stojący za technologią mają jakiś plan poza „zarabianiem pieniędzy” lub „robieniem fajnych rzeczy”.
Uprzedzenia są wpisane w każdą część twojego codziennego życia. Podobnie są wyjątki od tych uprzedzeń.
Obecnie większość programistów to mężczyźni: ja jestem programistą i kobietą.
Szkolenie sztucznej inteligencji w oparciu o tę rzeczywistość prowadziłoby do tego, że zawsze zakładałoby, że programiści to mężczyźni, co nie jest prawdą.
Znanym przykładem jest rekrutacyjna sztuczna inteligencja Amazona, wyszkolona na podstawie życiorysów odnoszących sukcesy pracowników Amazon.
Doprowadziło to do odrzucenia życiorysów z większości czarnych uczelni, mimo że wielu z tych pracowników mogło odnieść ogromny sukces.
Aby przeciwdziałać tym uprzedzeniom, narzędzia takie jak ChatGPT wykorzystują warstwy dostrajania. Dlatego otrzymujesz odpowiedź „Jako model języka AI nie mogę…”.
Niektórzy pracownicy w Kenii musieli przejść przez setki monitów, szukając obelg, mowy nienawiści i po prostu okropnych odpowiedzi i monitów.
Następnie została utworzona warstwa dostrajająca.
Dlaczego nie możesz wymyślać obelg na temat Joe Bidena? Dlaczego możesz opowiadać seksistowskie dowcipy o mężczyznach, a nie o kobietach?
Nie wynika to z liberalnych uprzedzeń, ale z powodu tysięcy warstw dostrajania mówiących ChatGPT, aby nie wypowiadał słowa na N.
Idealnie byłoby, gdyby ChatGPT był całkowicie neutralny w stosunku do świata, ale potrzebują go również do odzwierciedlenia świata.
To podobny problem do tego, który ma Google.
To, co jest prawdą, co uszczęśliwia ludzi i co sprawia, że prawidłowa reakcja na monit, to często bardzo różne rzeczy .
Dlaczego ChatGPT wyświetla fałszywe cytaty?
Inne często pojawiające się pytanie dotyczy fałszywych cytatów. Dlaczego niektóre z nich są fałszywe, a niektóre prawdziwe? Dlaczego niektóre strony internetowe są prawdziwe, a strony fałszywe?
Mamy nadzieję, że czytając, jak działają modele statystyczne, możesz to przeanalizować. Ale oto krótkie wyjaśnienie:
Jesteś modelem języka AI. Zostałeś przeszkolony w tonie sieci.
Ktoś każe ci napisać o czymś technologicznym – powiedzmy Kumulacyjna zmiana układu.
Nie masz tony przykładów artykułów CLS, ale wiesz, co to jest i znasz ogólny kształt artykułu o technologiach. Wiesz, jak wygląda ten rodzaj artykułu.

Zaczynasz więc od odpowiedzi i napotykasz pewien problem. W sposobie, w jaki rozumiesz pisanie techniczne, wiesz, że adres URL powinien znajdować się w następnym zdaniu.
Cóż, z innych artykułów CLS wiesz, że Google i GTMetrix są często cytowane na temat CLS, więc są łatwe.
Ale wiesz również, że linki do sztuczek CSS są często łączone w artykułach internetowych: wiesz, że zwykle adresy URL sztuczek CSS wyglądają w określony sposób: możesz więc skonstruować adres URL sztuczek CSS w następujący sposób:
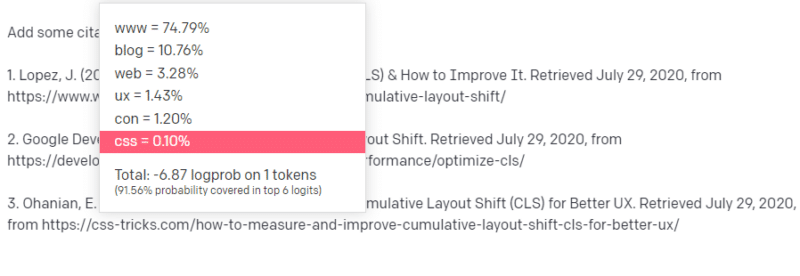
Sztuczka polega na tym, że w ten sposób zbudowane są wszystkie adresy URL, nie tylko te fałszywe:

Ten artykuł GTMetrix istnieje: ale istnieje, ponieważ prawdopodobnie był to ciąg wartości, który pojawił się na końcu tego zdania.
GPT i podobne modele nie potrafią odróżnić prawdziwego cytatu od fałszywego.
Jedynym sposobem na wykonanie tego modelowania jest użycie innych źródeł (baz wiedzy, Pythona itp.) w celu przeanalizowania tej różnicy i sprawdzenia wyników.
Co to jest „papuga stochastyczna”?
Wiem, że już to przerabiałem, ale warto to powtórzyć. Papugi stochastyczne to sposób na opisanie tego, co dzieje się, gdy duże modele językowe wydają się mieć charakter ogólny.
Dla LLM nonsens i rzeczywistość są tym samym. Postrzegają świat jak ekonomista, jako zbiór statystyk i liczb opisujących rzeczywistość.
Znasz cytat: „Istnieją trzy rodzaje kłamstw: kłamstwa, bezczelne kłamstwa i statystyki”.
LLM to duża grupa statystyk.
LLM wydają się spójne, ale dzieje się tak dlatego, że zasadniczo postrzegamy rzeczy, które wydają się ludzkie, jako ludzkie.
Podobnie model chatbota zaciemnia wiele podpowiedzi i informacji potrzebnych do uzyskania pełnej spójności odpowiedzi GPT.
Jestem programistą: próba użycia LLM do debugowania mojego kodu ma bardzo różne wyniki. Jeśli jest to problem podobny do tego, który ludzie często mieli w Internecie, LLM mogą wykryć i naprawić ten wynik.
Jeśli jest to problem, z którym wcześniej się nie spotkał, lub jest to niewielka część korpusu, to niczego nie naprawi.
Dlaczego GPT jest lepsze niż wyszukiwarka?
Sformułowałem to w pikantny sposób. Nie sądzę, aby GPT było lepsze niż wyszukiwarka. Martwi mnie, że ludzie zastąpili wyszukiwanie przez ChatGPT.
Jedną z niedocenianych części ChatGPT jest to, ile istnieje, aby postępować zgodnie z instrukcjami. Możesz poprosić go o zrobienie praktycznie wszystkiego.
Pamiętaj jednak, że wszystko opiera się na statystycznym następnym słowie w zdaniu, a nie na prawdzie.
Więc jeśli zadasz mu pytanie, na które nie ma dobrej odpowiedzi, ale zadasz je w sposób, na który jest zobowiązane odpowiedzieć, otrzymasz kiepską odpowiedź.
Posiadanie odpowiedzi zaprojektowanej dla ciebie i wokół ciebie jest bardziej pocieszające, ale świat to masa doświadczeń.
Wszystkie dane wejściowe do LLM są traktowane tak samo: ale niektórzy ludzie mają doświadczenie, a ich reakcja będzie lepsza niż melanż odpowiedzi innych osób.
Jeden ekspert jest wart więcej niż tysiąc przemyśleń.
Czy to początek AI? Czy Skynet jest tutaj?
Goryl Koko był małpą, której uczono języka migowego. Naukowcy zajmujący się językoznawstwem przeprowadzili mnóstwo badań wykazujących, że małpy człekokształtne można uczyć języka.
Herbert Terrace odkrył wtedy, że małpy nie składały zdań ani słów, ale po prostu małpowały swoich ludzkich opiekunów.
Eliza była terapeutką maszynową, jedną z pierwszych chatterbotów (chatbotów).
Ludzie postrzegali ją jako osobę: terapeutkę, której ufali i na której im zależało. Poprosili badaczy, aby zostali z nią sami.
Język robi coś bardzo specyficznego dla ludzkich mózgów. Ludzie słyszą, jak coś się komunikuje i oczekują za tym myśli.
LLM są imponujące, ale w sposób, który pokazuje zakres ludzkich osiągnięć.
LLM nie mają testamentów. Nie mogą uciec. Nie mogą próbować przejąć władzy nad światem.
Są lustrem: odbiciem ludzi, a konkretnie użytkownika.
Jedyną myślą jest statystyczna reprezentacja nieświadomości zbiorowej.
Czy GPT nauczył się samodzielnie całego języka?
Sundar Pichai, dyrektor generalny Google, poszedł na „60 minut” i stwierdził, że model językowy Google nauczył się bengalskiego.
Model był szkolony na tych tekstach. To nieprawda, że „mówił językiem obcym, którego nigdy nie nauczono”.
Są chwile, kiedy sztuczna inteligencja robi nieoczekiwane rzeczy, ale tego się oczekuje.
Kiedy patrzysz na wzorce i statystyki na wielką skalę, z pewnością będą chwile, kiedy te wzorce ujawnią coś zaskakującego.
To naprawdę pokazuje, że wielu menedżerów i marketingowców, którzy handlują sztuczną inteligencją i uczeniem maszynowym, tak naprawdę nie rozumie, jak działają te systemy.
Słyszałem, jak niektórzy bardzo inteligentni ludzie rozmawiali o właściwościach wschodzących, sztucznej inteligencji ogólnej (AGI) i innych futurystycznych rzeczach.
Może i jestem prostym wiejskim inżynierem operacyjnym ML, ale pokazuje to, jak wiele szumu, obietnic, science fiction i rzeczywistości łączy się, gdy mówimy o tych systemach.
Elizabeth Holmes, niesławna założycielka Theranos, została ukrzyżowana za składanie obietnic, których nie można było dotrzymać.
Ale cykl składania niemożliwych obietnic jest częścią kultury start-upów i zarabiania pieniędzy. Różnica między Theranosem a szumem AI polega na tym, że Theranos nie mógł go długo udawać.
Czy GPT to czarna skrzynka? Co dzieje się z moimi danymi w GPT?
GPT jako model nie jest czarną skrzynką. Możesz zobaczyć kod źródłowy dla GPT-J i GPT-Neo.
GPT OpenAI jest jednak czarną skrzynką. OpenAI nie ma i prawdopodobnie nie będzie próbowało wypuścić swojego modelu, ponieważ Google nie publikuje algorytmu.
Ale to nie dlatego, że algorytm jest zbyt niebezpieczny. Gdyby to była prawda, nie sprzedawaliby subskrypcji API żadnemu głupiemu facetowi z komputerem. Wynika to z wartości tej zastrzeżonej bazy kodów.
Kiedy korzystasz z narzędzi OpenAI, trenujesz i zasilasz ich API swoimi danymi wejściowymi. Oznacza to, że wszystko, co umieścisz w OpenAI, zasila je.
Oznacza to, że osoby, które korzystały z modelu GPT OpenAI na danych pacjentów, aby pomóc w pisaniu notatek i innych rzeczy, naruszyły ustawę HIPAA. Te informacje są teraz w modelu i bardzo trudno będzie je wyodrębnić.
Ponieważ tak wiele osób ma trudności ze zrozumieniem tego, jest bardzo prawdopodobne, że model zawiera mnóstwo prywatnych danych, które tylko czekają na odpowiedni monit, aby je udostępnić.
Dlaczego GPT jest szkolony w zakresie mowy nienawiści?
Inną często pojawiającą się rzeczą jest to, że korpus tekstowy, z którego szkolono GPT, zawiera mowę nienawiści.
Do pewnego stopnia OpenAI musi wyszkolić swoje modele w zakresie reagowania na mowę nienawiści, więc musi mieć korpus zawierający niektóre z tych terminów.
OpenAI twierdzi, że usunie tego rodzaju mowę nienawiści z systemu, ale dokumenty źródłowe obejmują 4chan i mnóstwo witryn nienawiści.
Czołgaj się po sieci, wchłaniaj uprzedzenia.
Nie ma łatwego sposobu, aby tego uniknąć. Jak możesz mieć coś, co rozpoznaje lub rozumie nienawiść, uprzedzenia i przemoc, nie mając tego jako części swojego zestawu treningowego?
Jak uniknąć uprzedzeń i zrozumieć ukryte i jawne uprzedzenia, gdy jesteś agentem maszynowym, który statystycznie wybiera następny token w zdaniu?
TL;DR
Szum i dezinformacja są obecnie głównymi elementami boomu na sztuczną inteligencję. Nie oznacza to, że nie ma legalnych zastosowań: ta technologia jest niesamowita i użyteczna.
Jednak sposób, w jaki technologia jest sprzedawana i jak ludzie z niej korzystają, może sprzyjać dezinformacji, plagiatom, a nawet powodować bezpośrednie szkody.
Nie używaj LLM, gdy życie jest zagrożone. Nie używaj LLM, gdy inny algorytm działałby lepiej. Nie daj się zwieść hype'owi.
Konieczne jest zrozumienie, czym są LLM, a czym nie są
Polecam ten wywiad Adama Conovera z Emily Bender i Timnitem Gebru.
LLM mogą być niesamowitymi narzędziami, jeśli są używane prawidłowo. Istnieje wiele sposobów korzystania z LLM i jeszcze więcej sposobów nadużywania LLM.
ChatGPT nie jest twoim przyjacielem. To garść statystyk. AGI nie jest „już tutaj”.
Opinie wyrażone w tym artykule są opiniami autora-gościa i niekoniecznie Search Engine Land. Autorzy personelu są wymienieni tutaj.