
Spark vs Hadoop: które ramy Big Data poprawią Twój biznes?
Opublikowany: 2019-09-24„Dane to paliwo cyfrowej gospodarki”
Współczesne firmy polegają na stercie danych, aby lepiej zrozumieć swoich konsumentów i rynek, technologie takie jak Big Data nabierają ogromnego rozpędu.
Big Data, podobnie jak sztuczna inteligencja, nie tylko znalazła się na liście najlepszych trendów technologicznych na 2020 rok , ale oczekuje się, że zostanie przyjęta zarówno przez start-upy, jak i firmy z listy Fortune 500, aby cieszyć się wykładniczym wzrostem biznesu i zapewnić wyższą lojalność klientów. Wyraźną wskazówką jest to, że przewiduje się, że rynek Big Data osiągnie 103 miliardy dolarów do 2027 roku.
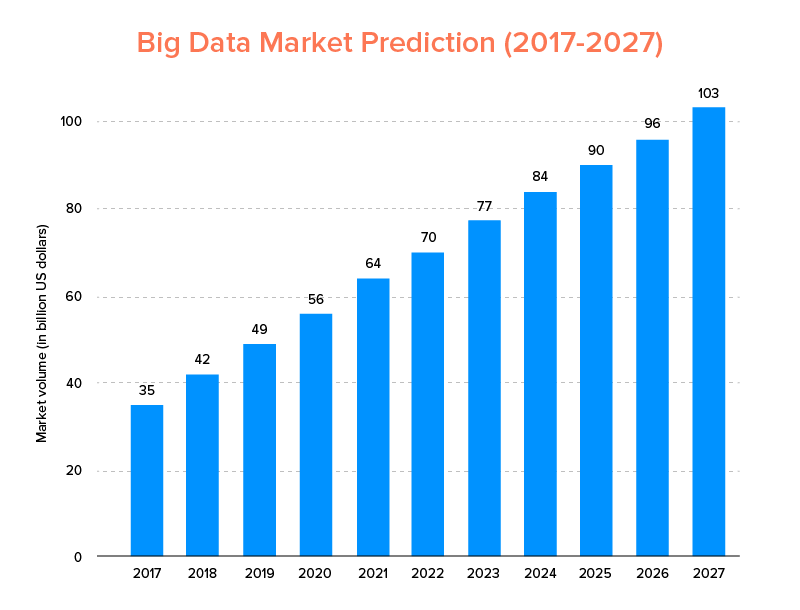
Teraz, chociaż z jednej strony wszyscy są bardzo zmotywowani do zastąpienia swoich tradycyjnych narzędzi do analizy danych Big Data – tym, które przygotowuje grunt pod rozwój Blockchain i AI, są również zdezorientowani, jeśli chodzi o wybór odpowiedniego narzędzia Big Data. Stają przed dylematem wyboru między Apache Hadoop i Spark – dwoma tytanami świata Big Data.
Biorąc więc pod uwagę tę myśl, dzisiaj omówimy artykuł na temat Apache Spark vs Hadoop i pomożemy Ci określić, która z nich jest odpowiednią opcją dla Twoich potrzeb.
Ale najpierw zróbmy krótkie wprowadzenie, czym są Hadoop i Spark.
Apache Hadoop to platforma typu open source, rozproszona i oparta na języku Java, która umożliwia użytkownikom przechowywanie i przetwarzanie dużych zbiorów danych w wielu klastrach komputerów przy użyciu prostych konstrukcji programistycznych. Składa się z różnych modułów, które współpracują ze sobą, aby zapewnić ulepszone wrażenia, które są:-
- Hadoop Wspólne
- Rozproszony system plików Hadoop (HDFS)
- Hadoop YARN
- Mapa HadoopReduce
Natomiast Apache Spark to platforma open source do przetwarzania dużych zbiorów danych w rozproszonych klastrach, która jest „łatwa w użyciu” i oferuje szybsze usługi.
Te dwie struktury Big Data są wspierane przez wiele dużych firm ze względu na zestaw możliwości, jakie oferują.
Zalety Hadoop Big Data Framework
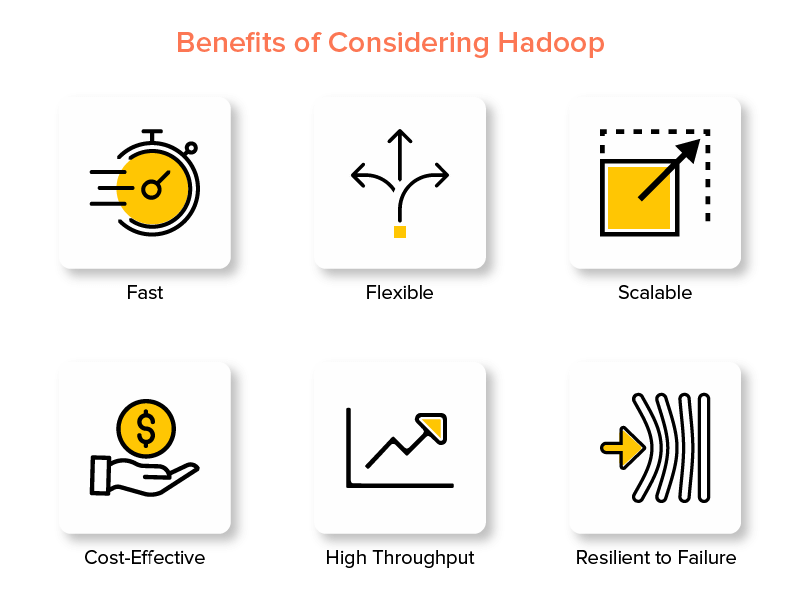
1. Szybko
Jedną z cech Hadoop, która czyni go popularnym w świecie Big Data, jest jego szybkość.
Jego metoda przechowywania opiera się na rozproszonym systemie plików, który przede wszystkim „mapuje” dane niezależnie od lokalizacji w klastrze. Ponadto dane i narzędzia wykorzystywane do przetwarzania danych są zwykle dostępne na tym samym serwerze, co sprawia, że przetwarzanie danych jest bezproblemowe i szybsze.
W rzeczywistości okazało się, że Hadoop może przetwarzać terabajty nieustrukturyzowanych danych w zaledwie kilka minut, a petabajty w godziny.
2. Elastyczny
Hadoop, w przeciwieństwie do tradycyjnych narzędzi do przetwarzania danych, oferuje wysoką elastyczność.
Pozwala firmom gromadzić dane z różnych źródeł (takich jak media społecznościowe, wiadomości e-mail itp.), pracować z różnymi typami danych (zarówno ustrukturyzowanych, jak i nieustrukturyzowanych) oraz uzyskiwać cenne informacje do dalszego wykorzystania do różnych celów (takich jak przetwarzanie logów, analiza kampanii rynkowych, wykrywanie oszustw itp.).
3. Skalowalny
Kolejną zaletą Hadoopa jest to, że jest wysoce skalowalny. Platforma, w przeciwieństwie do tradycyjnych relacyjnych systemów baz danych (RDBMS) , umożliwia firmom przechowywanie i dystrybucję dużych zbiorów danych z setek serwerów działających równolegle.
4. Opłacalny
Apache Hadoop w porównaniu z innymi narzędziami do analizy big data jest znacznie tani. Dzieje się tak, ponieważ nie wymaga żadnej specjalistycznej maszyny; działa na grupie sprzętu towarowego. Ponadto na dłuższą metę łatwiej jest dodać więcej węzłów.
Oznacza to, że jeden przypadek z łatwością zwiększa liczbę węzłów bez przestojów związanych z wymaganiami wstępnego planowania.
5. Wysoka przepustowość
W przypadku platformy Hadoop dane są przechowywane w sposób rozproszony, dzięki czemu małe zadanie jest dzielone równolegle na wiele porcji danych. Ułatwia to firmom wykonanie większej liczby zadań w krótszym czasie, co ostatecznie skutkuje wyższą przepustowością.
6. Odporny na niepowodzenie
Wreszcie, Hadoop oferuje opcje wysokiej odporności na awarie, które pomagają złagodzić konsekwencje awarii. Przechowuje replikę każdego bloku, co umożliwia odzyskanie danych w przypadku awarii dowolnego węzła.
Wady Hadoop Framework
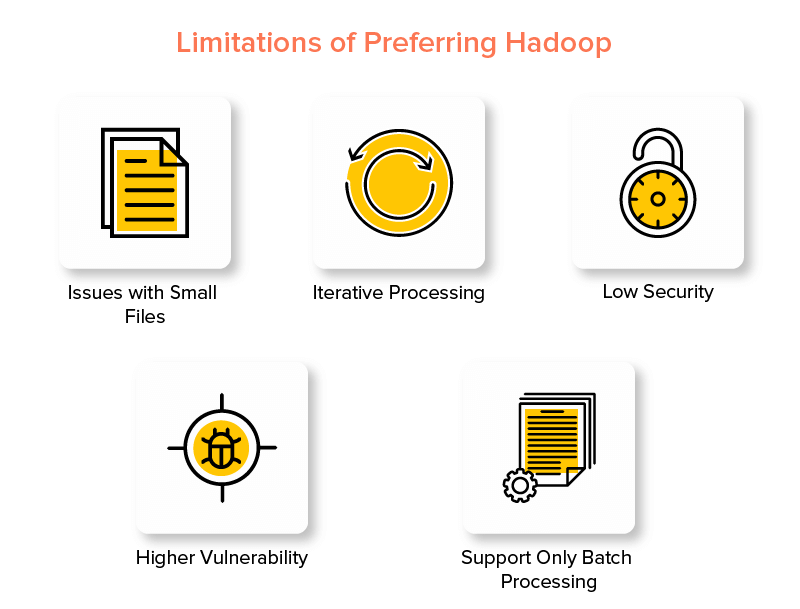
1. Problemy z małymi plikami
Największą wadą rozważania Hadoop do analizy dużych zbiorów danych jest to, że nie ma możliwości wydajnego i skutecznego wspierania losowego odczytu małych plików.
Powodem tego jest to, że mały plik ma stosunkowo mniejszy rozmiar pamięci niż rozmiar bloku HDFS. W takim scenariuszu, jeśli przechowuje się ogromną liczbę małych plików, istnieje większe prawdopodobieństwo przeciążenia NameNode , który przechowuje przestrzeń nazw HDFS, co praktycznie nie jest dobrym pomysłem.
2. Przetwarzanie iteracyjne
Przepływ danych w ramach Big Data Hadoop ma postać łańcucha, tak że dane wyjściowe jednego stają się danymi wejściowymi innego etapu. Natomiast przepływ danych w przetwarzaniu iteracyjnym ma charakter cykliczny.
Z tego powodu Hadoop jest nieodpowiednim wyborem dla rozwiązań opartych na uczeniu maszynowym lub iteracyjnym.
3. Niskie bezpieczeństwo
Inną wadą korzystania z platformy Hadoop jest to, że oferuje niższe funkcje bezpieczeństwa.
Na przykład framework ma domyślnie wyłączony model bezpieczeństwa. Jeśli ktoś korzystający z tego narzędzia Big Data nie wie, jak je włączyć, jego dane mogą być bardziej narażone na kradzież/niewłaściwe wykorzystanie. Ponadto Hadoop nie zapewnia funkcji szyfrowania na poziomie pamięci masowej i sieci, co ponownie zwiększa szanse na zagrożenie wyciekiem danych.
4. Większa podatność
Framework Hadoop jest napisany w Javie, najpopularniejszym, ale mocno eksploatowanym języku programowania. Ułatwia to cyberprzestępcom łatwy dostęp do rozwiązań opartych na Hadoop i niewłaściwe wykorzystanie poufnych danych.
5. Wsparcie tylko dla przetwarzania wsadowego
W przeciwieństwie do różnych innych platform Big Data, Hadoop nie przetwarza danych przesyłanych strumieniowo. Obsługuje tylko przetwarzanie wsadowe , a powodem jest to, że MapReduce nie wykorzystuje maksymalnie pamięci klastra Hadoop.
Chociaż chodzi o Hadoop, jego funkcje i wady, przyjrzyjmy się zaletom i wadom Sparka, aby znaleźć łatwość w zrozumieniu różnicy między nimi.
Korzyści z Apache Spark Framework
1. Dynamiczny w naturze
Ponieważ Apache Spark oferuje około 80 operatorów wysokiego poziomu, może być używany do dynamicznego przetwarzania danych. Można go uznać za odpowiednie narzędzie do tworzenia dużych zbiorów danych do tworzenia równoległych aplikacji i zarządzania nimi.
2. Potężny
Ze względu na niskie opóźnienia w przetwarzaniu danych w pamięci i dostępność różnych wbudowanych bibliotek dla algorytmów uczenia maszynowego i analizy wykresów, może poradzić sobie z różnymi wyzwaniami analitycznymi. To sprawia, że jest to potężna opcja Big Data na rynku.
3. Zaawansowana analiza
Inną charakterystyczną cechą Sparka jest to, że nie tylko zachęca do „MAP” i „redukuj”, ale także obsługuje uczenie maszynowe (ML), zapytania SQL, algorytmy wykresów i dane przesyłania strumieniowego. Dzięki temu nadaje się do korzystania z zaawansowanych analiz.
4. Ponowne użycie
W przeciwieństwie do usługi Hadoop, kod Spark można ponownie wykorzystać do przetwarzania wsadowego, uruchamiania zapytań ad hoc w stanie strumienia, dołączania do strumienia danych historycznych i nie tylko.
5. Przetwarzanie strumienia w czasie rzeczywistym
Kolejną zaletą korzystania z Apache Spark jest to, że umożliwia obsługę i przetwarzanie danych w czasie rzeczywistym.
6. Wsparcie wielojęzyczne
Wreszcie, to narzędzie do analizy big data obsługuje wiele języków kodowania, w tym Java, Python i Scala.
Ograniczenia narzędzia Spark Big Data

1. Brak procesu zarządzania plikami
Główną wadą korzystania z Apache Spark jest to, że nie ma własnego systemu zarządzania plikami. Opiera się na innych platformach, takich jak Hadoop, aby spełnić ten wymóg.
2. Kilka algorytmów
Apache Spark pozostaje również w tyle za innymi platformami Big Data, jeśli chodzi o dostępność algorytmów, takich jak odległość Tanimoto.
3. Problem z małymi plikami
Inną wadą używania Sparka jest to, że nie radzi sobie wydajnie z małymi plikami.
Dzieje się tak, ponieważ działa z rozproszonym systemem plików Hadoop (HDFS), który ułatwia zarządzanie ograniczoną liczbą dużych plików z dużą ilością małych plików.
4. Brak automatycznego procesu optymalizacji
W przeciwieństwie do różnych innych platform Big Data i opartych na chmurze, Spark nie ma żadnego automatycznego procesu optymalizacji kodu. Trzeba tylko ręcznie zoptymalizować kod.
5. Nie nadaje się do środowiska wielu użytkowników!
Ponieważ Apache Spark nie może obsługiwać wielu użytkowników jednocześnie, nie działa wydajnie w środowisku wielu użytkowników. Coś, co ponownie zwiększa jego ograniczenia.
Po zapoznaniu się z podstawami obu platform Big Data prawdopodobnie masz nadzieję zapoznać się z różnicami między platformami Spark i Hadoop.
Nie czekajmy więc dalej i przejdźmy do ich porównania, aby zobaczyć, który z nich prowadzi w bitwie „Spark vs Hadoop”.
Spark kontra Hadoop: jak dwa narzędzia Big Data łączą się ze sobą
[identyfikator tabeli=38 /]
1. Architektura
Jeśli chodzi o architekturę Spark i Hadoop, ta ostatnia prowadzi nawet wtedy, gdy obie działają w rozproszonym środowisku obliczeniowym.
Dzieje się tak, ponieważ architektura Hadoop – w przeciwieństwie do Sparka – ma dwa podstawowe elementy – HDFS (Hadoop Distributed File System) i YARN (Yet Another Resource Negotiator). Tutaj HDFS obsługuje przechowywanie dużych zbiorów danych w różnych węzłach, podczas gdy YARN zajmuje się przetwarzaniem zadań poprzez alokację zasobów i mechanizmy planowania zadań. Komponenty te są następnie dzielone na więcej komponentów, aby zapewnić lepsze rozwiązania z usługami, takimi jak odporność na awarie.
2. Łatwość użytkowania
Apache Spark umożliwia programistom wprowadzanie różnych przyjaznych dla użytkownika interfejsów API, takich jak Scala, Python, R, Java i Spark SQL w ich środowisku programistycznym. Ponadto jest wyposażony w tryb interaktywny, który obsługuje zarówno użytkowników, jak i programistów. Dzięki temu jest łatwy w użyciu i ma niską krzywą uczenia się.
Natomiast mówiąc o Hadoop, oferuje dodatki wspierające użytkowników, ale nie tryb interaktywny. To sprawia, że Spark wygrywa z Hadoop w tej bitwie „big data”.
3. Tolerancja błędów i bezpieczeństwo
Chociaż zarówno Apache Spark, jak i Hadoop MapReduce zapewniają odporność na awarie, ten ostatni wygrywa bitwę.
Dzieje się tak dlatego, że na wypadek awarii procesu w trakcie działania w środowisku Spark trzeba zacząć od zera. Ale jeśli chodzi o Hadoop, mogą kontynuować od momentu samej katastrofy.
4. Wydajność
Jeśli chodzi o rozważenie wydajności Spark vs MapReduce, ta pierwsza wygrywa z drugą.
Platforma Spark może działać 10 razy szybciej na dysku i 100 razy w pamięci. Dzięki temu można zarządzać 100 TB danych 3 razy szybciej niż Hadoop MapReduce.
5. Przetwarzanie danych
Kolejnym czynnikiem, który należy wziąć pod uwagę podczas porównywania Apache Spark i Hadoop, jest przetwarzanie danych.
Podczas gdy Apache Hadoop oferuje tylko możliwość przetwarzania wsadowego, inne ramy Big Data umożliwiają pracę z przetwarzaniem interaktywnym, iteracyjnym, strumieniowym, graficznym i wsadowym. Coś, co dowodzi, że Spark jest lepszą opcją, aby cieszyć się lepszymi usługami przetwarzania danych.
6. Kompatybilność
Zgodność Spark i Hadoop MapReduce jest nieco taka sama.
Chociaż czasami oba frameworki Big Data działają jako samodzielne aplikacje, mogą również ze sobą współpracować. Spark może działać wydajnie na Hadoop YARN, podczas gdy Hadoop może łatwo zintegrować się z Sqoop i Flume. Z tego powodu oba obsługują wzajemnie źródła danych i formaty plików.
7. Bezpieczeństwo
Środowisko Spark jest obciążone różnymi funkcjami bezpieczeństwa, takimi jak rejestrowanie zdarzeń i używanie filtrów serwletów javax do ochrony interfejsów użytkownika. Ponadto zachęca do uwierzytelniania za pomocą współdzielonego klucza tajnego i może wykorzystać potencjał uprawnień do plików HDFS, szyfrowania między trybami i Kerberos po zintegrowaniu z YARN i HDFS.
Natomiast Hadoop obsługuje uwierzytelnianie Kerberos , uwierzytelnianie stron trzecich, konwencjonalne uprawnienia do plików, listy kontroli dostępu i nie tylko, co ostatecznie zapewnia lepsze wyniki w zakresie bezpieczeństwa.
Tak więc, biorąc pod uwagę porównanie Spark vs Hadoop pod względem bezpieczeństwa, to ostatnie prowadzi.
8. Opłacalność
Porównując Hadoop i Spark, ten pierwszy potrzebuje więcej pamięci na dysku, podczas gdy drugi wymaga więcej pamięci RAM. Ponadto, ponieważ Spark jest całkiem nowy w porównaniu do Apache Hadoop, deweloperzy pracujący ze Sparkiem są rzadsi.
To sprawia, że praca ze Sparkiem jest kosztowną sprawą. Oznacza to, że Hadoop oferuje opłacalne rozwiązania, gdy skupia się na kosztach Hadoop vs Spark.
9. Zakres rynku
Chociaż zarówno Apache Spark, jak i Hadoop są wspierane przez duże firmy i były wykorzystywane do różnych celów, ten drugi jest liderem pod względem zakresu rynkowego.
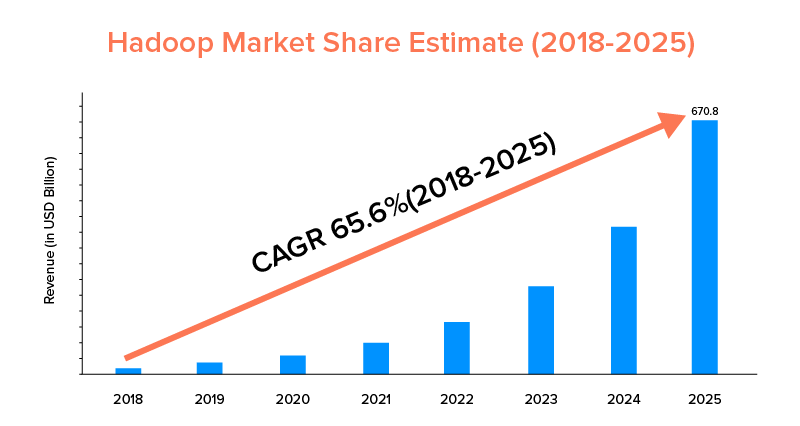
Zgodnie ze statystykami rynkowymi przewiduje się, że rynek Apache Hadoop wzrośnie z CAGR wynoszącym 65,6% w okresie od 2018 do 2025 r., w porównaniu do Sparka z CAGR wynoszącym tylko 33,9%.
Chociaż te czynniki pomogą w określeniu odpowiedniego narzędzia Big Data dla Twojej firmy, warto zapoznać się z ich przypadkami użycia. Więc zajmijmy się tutaj.
Przypadki użycia Apache Spark Framework
To narzędzie Big Data jest wykorzystywane przez firmy, które chcą:
- Przesyłaj i analizuj dane w czasie rzeczywistym.
- Rozkoszuj się mocą uczenia maszynowego.
- Pracuj z interaktywnymi analizami.
- Wprowadź mgłę i przetwarzanie brzegowe do swojego modelu biznesowego.
Przypadki użycia Apache Hadoop Framework
Hadoop jest preferowany przez startupy i przedsiębiorstwa, gdy chcą:-
- Analizuj dane archiwalne.
- Ciesz się lepszymi opcjami handlu finansowego i prognozowania.
- Wykonywanie operacji obejmujących sprzęt towarowy.
- Rozważ Liniowe przetwarzanie danych.
Dzięki temu mamy nadzieję, że zdecydowałeś, który z nich jest zwycięzcą bitwy „Spark vs Hadoop” w odniesieniu do Twojej firmy. Jeśli nie, skontaktuj się z naszymi ekspertami Big Data , aby rozwiać wszelkie wątpliwości i uzyskać wzorowe usługi o wyższym wskaźniku sukcesu.
CZĘSTO ZADAWANE PYTANIA
1. Jakie ramy Big Data wybrać?
Wybór zależy całkowicie od Twoich potrzeb biznesowych. Jeśli koncentrujesz się na wydajności, zgodności danych i łatwości użytkowania, Spark jest lepszy niż Hadoop. Natomiast platforma Big Data Hadoop jest lepsza, gdy koncentrujesz się na architekturze, bezpieczeństwie i opłacalności.
2. Jaka jest różnica między Hadoop i Spark?
Istnieją różne różnice między Sparkiem a Hadoopem. Na przykład:-
- Spark jest 100 razy czynnikiem, który Hadoop MapReduce.
- Podczas gdy Hadoop jest używany do przetwarzania wsadowego, Spark jest przeznaczony do przetwarzania wsadowego, wykresu, uczenia maszynowego i przetwarzania iteracyjnego.
- Spark jest kompaktowy i łatwiejszy niż platforma Big Data Hadoop.
- W przeciwieństwie do Spark Hadoop nie obsługuje buforowania danych.
3. Czy Spark jest lepszy niż Hadoop?
Spark jest lepszy niż Hadoop, gdy skupiasz się głównie na szybkości i bezpieczeństwie. Jednak w innych przypadkach to narzędzie do analizy big data pozostaje w tyle za Apache Hadoop.
4. Dlaczego Spark jest szybszy niż Hadoop?
Spark jest szybszy niż Hadoop ze względu na mniejszą liczbę cykli odczytu/zapisu na dysku i przechowywania danych pośrednich w pamięci.
5. Do czego służy Apache Spark?
Apache Spark służy do analizy danych, gdy ktoś chce-
- Analizuj dane w czasie rzeczywistym.
- Wprowadź ML i Fog Computing do swojego modelu biznesowego.
- Pracuj z interaktywną analityką.