
TW-BERT: Kompleksowe ważenie haseł w zapytaniu i przyszłość wyszukiwarki Google
Opublikowany: 2023-09-14Wyszukiwanie jest trudne, jak napisał Seth Godin w 2005 roku.
To znaczy, jeśli uważamy, że SEO jest trudne (a jest), wyobraź sobie, że próbujesz zbudować wyszukiwarkę w świecie, w którym:
- Użytkownicy różnią się znacznie i zmieniają swoje preferencje z biegiem czasu.
- Technologia wyszukiwania, do której mają dostęp, rozwija się każdego dnia.
- Konkurencja depcze Ci po piętach.
Co więcej, masz do czynienia również z nieznośnymi SEO, próbującymi oszukać Twój algorytm i uzyskać wgląd w to, jak najlepiej zoptymalizować witrynę pod kątem odwiedzających.
To znacznie utrudni sprawę.
Teraz wyobraź sobie, że główne technologie, na których musisz się oprzeć, aby się rozwijać, mają swoje własne ograniczenia – i, co być może, co gorsza, ogromne koszty.
Cóż, jeśli jesteś jednym z autorów niedawno opublikowanego artykułu „Kompleksowe ważenie terminów zapytań”, postrzegasz to jako okazję do zabłyśnięcia.
Jakie jest kompleksowe ważenie terminów zapytania?
Kompleksowe ważenie terminów w zapytaniu odnosi się do metody, w której waga każdego terminu w zapytaniu jest określana jako część ogólnego modelu, bez polegania na ręcznie programowanych lub tradycyjnych schematach ważenia terminów lub innych niezależnych modelach.
Jak to wygląda?
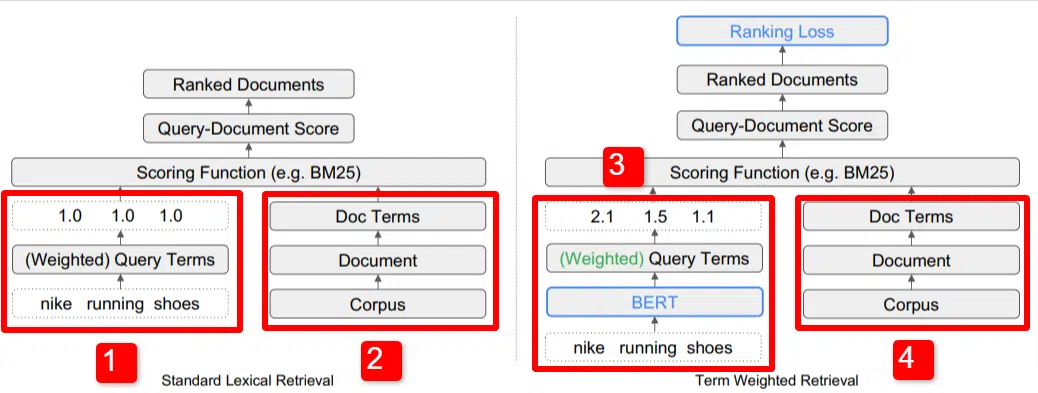
Tutaj widzimy ilustrację jednego z kluczowych wyróżników modelu zarysowanego w artykule (dokładnie rysunek 1).
Po prawej stronie modelu standardowego (2) widzimy to samo, co w przypadku modelu proponowanego (4), czyli korpus (pełny zbiór dokumentów w indeksie), prowadzący do dokumentów, prowadzący do terminów.
To ilustruje rzeczywistą hierarchię w systemie, ale można o niej pomyśleć w odwrotnej kolejności, od góry do dołu. Mamy warunki. Poszukujemy dokumentów zawierających te terminy. Dokumenty te znajdują się w korpusie wszystkich dokumentów, o których wiemy.
W lewym dolnym rogu (1) w standardowej architekturze wyszukiwania informacji (IR) zauważysz, że nie ma warstwy BERT. Zapytanie użyte na ich ilustracji (buty do biegania Nike) wchodzi do systemu, a wagi są wyliczane niezależnie od modelu i przekazywane do niego.
Na ilustracji wagi rozkładają się równomiernie między trzema słowami w zapytaniu. Jednak nie musi tak być. To po prostu domyślna i dobra ilustracja.
Ważne jest, aby zrozumieć, że wagi są przypisywane spoza modelu i wprowadzane za pomocą zapytania. Za chwilę omówimy, dlaczego jest to ważne.
Jeśli spojrzymy na wersję terminu waga po prawej stronie, zobaczysz, że zapytanie „buty do biegania Nike” wprowadza BERT (dokładnie termin ważenie BERT lub TW-BERT), który służy do przypisania wag najlepiej zastosować do tego zapytania.
Od tego momentu sprawy podążają podobną ścieżką w obu przypadkach, stosowana jest funkcja punktacji i ranking dokumentów. Ale w przypadku nowego modelu istnieje kluczowy, końcowy krok, o który tak naprawdę chodzi w tym wszystkim, czyli obliczenie strat rankingowych.
To obliczenie, o którym wspomniałem powyżej, sprawia, że ustalenie wag w modelu jest tak istotne. Aby to najlepiej zrozumieć, odłóżmy na bok omówienie funkcji straty, co jest ważne, aby naprawdę zrozumieć, co się tutaj dzieje.
Co to jest funkcja straty?
W uczeniu maszynowym funkcja straty to w zasadzie obliczenie tego, jak bardzo błędny jest system, który próbuje nauczyć się zbliżać do straty jak najbliżej zera.
Weźmy na przykład model przeznaczony do ustalania cen domów. Jeśli wprowadzisz wszystkie statystyki dotyczące swojego domu i wyjdzie wartość 250 000 USD, ale Twój dom zostanie sprzedany za 260 000 USD, różnica zostanie uznana za stratę (co jest wartością bezwzględną).
Na wielu przykładach model uczy się minimalizować straty poprzez przypisywanie różnych wag podanym parametrom, aż do uzyskania najlepszego wyniku. Parametr w tym przypadku może obejmować stopy kwadratowe, sypialnie, wielkość podwórka, bliskość szkoły itp.
Wróćmy teraz do ważenia terminów w zapytaniu
Patrząc wstecz na dwa powyższe przykłady, musimy się skupić na obecności modelu BERT, który zapewnia wagę terminom w dół ścieżki obliczania straty rankingowej.
Inaczej mówiąc, w tradycyjnych modelach ważenie terminów odbywało się niezależnie od samego modelu i dlatego nie mogło odpowiadać działaniu całego modelu. Nie można było nauczyć się poprawiać ważeń.

W proponowanym systemie to się zmienia. Ważenie odbywa się z poziomu samego modelu, a zatem, ponieważ model stara się poprawić swoją wydajność i zmniejszyć funkcję strat, ma dodatkowe pokrętła, które umożliwiają wprowadzenie ważenia terminów do równania. Dosłownie.
ngramy
TW-BERT nie jest zaprojektowany do działania w kategoriach słów, ale raczej ngramów.
Autorzy artykułu dobrze ilustrują, dlaczego zamiast słów używają ngramów, wskazując, że w zapytaniu „buty do biegania nike” jeśli po prostu zważysz słowa, to strona ze wzmiankami o słowach nike, bieganie i buty może zająć dobre miejsce nawet jeśli mowa o „skarpetkach do biegania Nike” i „butach do skateboardingu”.
Tradycyjne metody IR korzystają ze statystyk zapytań i statystyk dokumentów i mogą wyświetlać strony zawierające ten lub podobny problem. Poprzednie próby rozwiązania tego problemu skupiały się na współwystępowaniu i porządkowaniu.
W tym modelu ngramy są ważone tak samo, jak słowa w poprzednim przykładzie, więc otrzymujemy coś takiego:
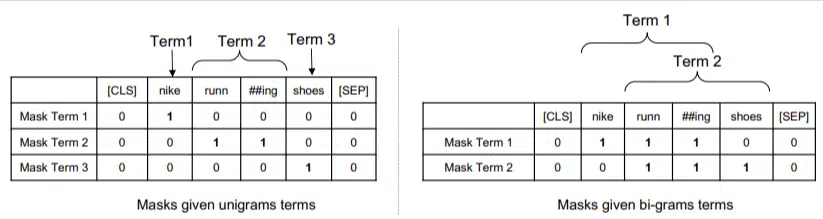
Po lewej stronie widzimy, jak zapytanie będzie ważone w jednogramach (ngramy 1 słowa), a po prawej stronie bi-gramy (ngramy 2 słów).
System, dzięki wbudowanemu ważeniu, może trenować wszystkie permutacje, aby określić najlepsze ngramy, a także odpowiednią wagę dla każdego, w przeciwieństwie do polegania wyłącznie na statystykach, takich jak częstotliwość.
Zerowy strzał
Ważną cechą tego modelu jest jego wydajność w zadaniach zero-krótkich. Autorzy przetestowali:
- Zbiór danych MS MARCO — zbiór danych Microsoft do rankingu dokumentów i fragmentów
- Zbiór danych TREC-COVID – artykuły i badania dotyczące COVID
- Robust04 – Artykuły prasowe
- Common Core – artykuły edukacyjne i posty na blogu
Mieli tylko niewielką liczbę zapytań oceniających i nie wykorzystali żadnego do dostrajania, co czyniło ten test zerowym, ponieważ model nie został przeszkolony w zakresie rankingu dokumentów w tych domenach. Wyniki były następujące:
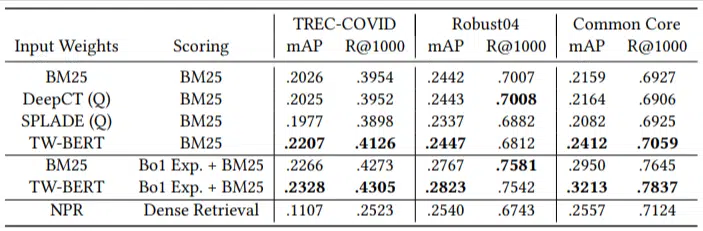
W większości zadań radził sobie lepiej, a najlepiej w przypadku krótszych zapytań (od 1 do 10 słów).
I to na zasadzie plug-and-play!
OK, to może być nadmierne uproszczenie, ale autorzy piszą:
„Dostosowanie TW-BERT do wskaźników wyszukiwarek minimalizuje zmiany potrzebne do zintegrowania go z istniejącymi aplikacjami produkcyjnymi , podczas gdy istniejące metody wyszukiwania oparte na głębokim uczeniu wymagałyby dalszej optymalizacji infrastruktury i wymagań sprzętowych. Wyuczone wagi mogą być łatwo wykorzystane przez standardowe programy do wyszukiwania leksykalnego i inne techniki wyszukiwania, takie jak rozszerzanie zapytań.
Ponieważ TW-BERT został zaprojektowany tak, aby integrować się z obecnym systemem, integracja jest znacznie prostsza i tańsza niż inne opcje.
Co to wszystko oznacza dla Ciebie
W przypadku modeli uczenia maszynowego trudno jest przewidzieć, co możesz z tym zrobić jako SEO (poza widocznymi wdrożeniami, takimi jak Bard lub ChatGPT).
Permutacja tego modelu niewątpliwie zostanie wdrożona ze względu na ulepszenia i łatwość wdrożenia (zakładając, że stwierdzenia są dokładne).
To powiedziawszy, jest to poprawa jakości życia w Google, która poprawi rankingi i wyniki zerowe przy niskim koszcie.
Jedyne, na czym możemy naprawdę polegać, to to, że jeśli zostaną wdrożone, lepsze wyniki pojawią się w bardziej niezawodny sposób. To dobra wiadomość dla specjalistów SEO.
Opinie wyrażone w tym artykule są opiniami gościnnego autora i niekoniecznie należą do Search Engine Land. Autorzy personelu są tutaj wymienieni.