
Co to jest generatywna sztuczna inteligencja i jak działa?
Opublikowany: 2023-09-26Generatywna sztuczna inteligencja, podzbiór sztucznej inteligencji, stała się rewolucyjną siłą w świecie technologii. Ale co to właściwie jest? I dlaczego cieszy się tak dużym zainteresowaniem?
W tym szczegółowym przewodniku dowiesz się, jak działają generatywne modele sztucznej inteligencji, co mogą, a czego nie mogą zrobić, a także implikacje wszystkich tych elementów.
Czym jest generatywna sztuczna inteligencja?
Generatywna sztuczna inteligencja (genAI) odnosi się do systemów, które mogą generować nową treść, czy to tekst, obrazy, muzykę, czy nawet filmy. Tradycyjnie AI/ML oznaczało trzy rzeczy: nadzorowane, bez nadzoru i uczenie się przez wzmacnianie. Każdy z nich zapewnia szczegółowe informacje na podstawie danych wyjściowych grupowania.
Niegeneratywne modele sztucznej inteligencji wykonują obliczenia na podstawie danych wejściowych (takich jak klasyfikacja obrazu lub tłumaczenie zdania). Natomiast modele generatywne dają „nowe” wyniki, takie jak pisanie esejów, komponowanie muzyki, projektowanie grafik, a nawet tworzenie realistycznych ludzkich twarzy, które nie istnieją w prawdziwym świecie.
Implikacje generatywnej sztucznej inteligencji
Rozwój generatywnej sztucznej inteligencji ma istotne konsekwencje. Dzięki możliwości generowania treści branże takie jak rozrywka, projektowanie i dziennikarstwo są świadkami zmiany paradygmatu.
Na przykład agencje informacyjne mogą wykorzystywać sztuczną inteligencję do tworzenia raportów, a projektanci mogą uzyskać wspomagane przez sztuczną inteligencję sugestie dotyczące grafik. Sztuczna inteligencja może wygenerować setki haseł reklamowych w ciągu kilku sekund – niezależnie od tego, czy te opcje są dobre, czy nie czy nie, to inna sprawa.
Generatywna sztuczna inteligencja może tworzyć treści dostosowane do potrzeb poszczególnych użytkowników. Pomyśl o aplikacji muzycznej, która komponuje wyjątkową piosenkę na podstawie Twojego nastroju, lub o aplikacji z wiadomościami, która tworzy artykuły na tematy, które Cię interesują.
Problem w tym, że w miarę jak sztuczna inteligencja odgrywa coraz bardziej integralną rolę w tworzeniu treści, coraz powszechniejsze stają się pytania o autentyczność, prawa autorskie i wartość ludzkiej kreatywności.
Jak działa generatywna sztuczna inteligencja?
W swojej istocie generatywna sztuczna inteligencja polega na przewidywaniu kolejnego fragmentu danych w sekwencji, niezależnie od tego, czy będzie to następne słowo w zdaniu, czy następny piksel obrazu. Rozważmy, jak to osiągnąć.
Modele statystyczne
Modele statystyczne stanowią podstawę większości systemów AI. Używają równań matematycznych do przedstawienia relacji między różnymi zmiennymi.
W przypadku generatywnej sztucznej inteligencji modele są szkolone w zakresie rozpoznawania wzorców w danych, a następnie wykorzystują te wzorce do generowania nowe, podobne dane.
Jeśli model jest szkolony na zdaniach angielskich, uczy się statystycznego prawdopodobieństwa wystąpienia jednego słowa po drugim, co pozwala na generowanie spójnych zdań.
Zbieranie danych
Istotna jest zarówno jakość, jak i ilość danych. Modele generatywne są szkolone na ogromnych zbiorach danych, aby zrozumieć wzorce.
W przypadku modelu językowego może to oznaczać przyjmowanie miliardów słów z książek, stron internetowych i innych tekstów.
W przypadku modelu obrazu może to oznaczać analizę milionów obrazów. Im bardziej zróżnicowane i kompleksowe są dane szkoleniowe, tym lepiej model będzie generował zróżnicowane wyniki.
Jak działają transformatory i uwaga
Transformatory to rodzaj architektury sieci neuronowej przedstawiony w artykule z 2017 roku zatytułowanym „Attention Is All You Need” autorstwa Vaswani i in. Od tego czasu stały się podstawą większości najnowocześniejszych modeli językowych. ChatGPT nie działałby bez transformatorów.
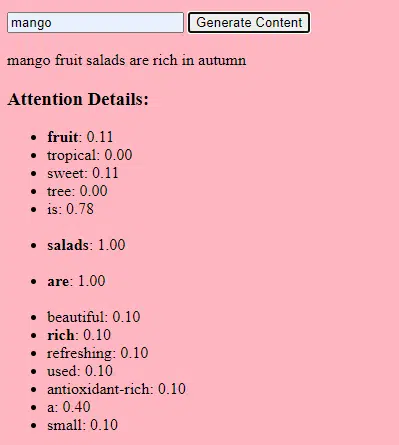
Mechanizm „uwagi” pozwala modelowi skupić się na różnych częściach danych wejściowych, podobnie jak ludzie zwracają uwagę na określone słowa podczas rozumienia zdania.
Mechanizm ten pozwala modelowi zdecydować, które części danych wejściowych są istotne dla danego zadania, dzięki czemu jest on bardzo elastyczny i wydajny.
Poniższy kod przedstawia podstawowy podział mechanizmów transformatora, wyjaśniając każdy element prostym językiem angielskim.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)W kodzie możesz mieć klasę Transformer i jedną klasę TransformerLayer. To jakby mieć plan piętra i całego budynku.
Ten fragment kodu TransformerLayer pokazuje, jak działają określone komponenty, takie jak uwaga wielogłowa i określone aranżacje.
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Sieć neuronowa ze sprzężeniem zwrotnym jest jednym z najprostszych typów sztucznych sieci neuronowych. Składa się z warstwy wejściowej, jednej lub więcej warstw ukrytych i warstwy wyjściowej.
Dane przepływają w jednym kierunku – od warstwy wejściowej, przez warstwy ukryte, do warstwy wyjściowej. W sieci nie ma pętli ani cykli.
W kontekście architektury transformatorowej sieć neuronowa ze sprzężeniem zwrotnym stosowana jest po mechanizmie uwagi w każdej warstwie. Jest to prosta dwuwarstwowa transformacja liniowa z aktywacją ReLU pomiędzy.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Jak działa generatywna sztuczna inteligencja – w prostych słowach
Pomyśl o generatywnej sztucznej inteligencji jak o rzucie ważoną kostką. Dane szkoleniowe określają wagi (lub prawdopodobieństwa).
Jeśli kostka reprezentuje następne słowo w zdaniu, słowo często występujące po bieżącym słowie w danych szkoleniowych będzie miało większą wagę. Zatem „niebo” może następować po „niebieskim” częściej niż „banan”. Kiedy sztuczna inteligencja „rzuca kostką”, aby wygenerować treść, z większym prawdopodobieństwem wybierze statystycznie bardziej prawdopodobne sekwencje na podstawie swojego treningu.
W jaki więc sposób LLM mogą generować treści, które „wydają się” oryginalne?
Weźmy fałszywą listę – „najlepsze prezenty Id al-Fitr dla marketerów treści” – i przeanalizujmy, w jaki sposób LLM może generować tę listę, łącząc wskazówki tekstowe z dokumentów dotyczących prezentów, Id i sprzedawców treści.
Przed przetworzeniem tekst jest dzielony na mniejsze części zwane „tokenami”. Żetony te mogą składać się z jednego znaku lub jednego słowa.
Przykład: „Eid al-Fitr to święto” zmienia się na [„Eid”, „al-Fitr”, „is”, „a”, „celebracja”].
Dzięki temu model może pracować z łatwymi do zarządzania fragmentami tekstu i rozumieć strukturę zdań.
Każdy token jest następnie konwertowany na wektor (listę liczb) za pomocą osadzania. Te wektory oddają znaczenie i kontekst każdego słowa.
Kodowanie pozycyjne dodaje do każdego wektora słów informację o jego pozycji w zdaniu, zapewniając, że model nie utraci informacji o kolejności.
Następnie używamy mechanizmu uwagi : pozwala to modelowi skupić się na różnych częściach tekstu wejściowego podczas generowania wyniku. Jeśli pamiętasz BERT, to właśnie było tak ekscytujące dla pracowników Google w BERT.
Jeśli nasz model widział teksty o „ prezentach ” i wiedział, że ludzie dają prezenty podczas uroczystości , a także widział teksty o „ Id al-Fitr ” jako ważnym święcie , zwróci „ uwagę ” na te powiązania.
Podobnie, jeśli widział teksty o „ marketerach treści ” potrzebujących określonych narzędzi lub zasobów , może powiązać ideę „ prezentów ” z „ marketerami treści”.

Teraz możemy łączyć konteksty: gdy model przetwarza tekst wejściowy przez wiele warstw Transformera, łączy poznane konteksty.
Zatem nawet jeśli w oryginalnych tekstach nigdy nie wspomniano o „prezentach Id al-Fitr dla marketerów treści”, model może połączyć pojęcia „Id al-Fitr”, „prezentów” i „marketerów treści” w celu wygenerowania tych treści.
Dzieje się tak dlatego, że nauczył się szerszego kontekstu wokół każdego z tych terminów.
Po przetworzeniu danych wejściowych przez mechanizm uwagi i sieci wyprzedzające w każdej warstwie Transformatora model generuje rozkład prawdopodobieństwa dla następnego słowa w sekwencji w odniesieniu do słownictwa.
Można by pomyśleć, że po słowach takich jak „najlepszy” i „Id al-Fitr” słowo „prezenty” z dużym prawdopodobieństwem będzie następne. Podobnie może skojarzyć „prezenty” z potencjalnymi odbiorcami, takimi jak „marketerzy treści”.
Otrzymuj codzienny biuletyn, na którym polegają marketerzy.
Zobacz warunki.
Jak budowane są duże modele językowe
Podróż od podstawowego modelu transformatora do wyrafinowanego modelu wielkojęzycznego (LLM), takiego jak GPT-3 lub BERT, wiąże się ze skalowaniem i udoskonalaniem różnych komponentów.
Oto podział krok po kroku:
LLM są szkoleni na ogromnych ilościach danych tekstowych. Trudno wyjaśnić, jak obszerne są to dane.
Zbiór danych C4, punkt wyjścia dla wielu LLM, to 750 GB danych tekstowych. To 805 306 368 000 bajtów – mnóstwo informacji. Dane te mogą obejmować książki, artykuły, strony internetowe, fora, sekcje komentarzy i inne źródła.
Im bardziej zróżnicowane i kompleksowe są dane, tym lepsze jest zrozumienie i możliwości generalizacji modelu.
Podczas gdy podstawowa architektura transformatora pozostaje podstawą, LLM mają znacznie większą liczbę parametrów. Na przykład GPT-3 ma 175 miliardów parametrów. W tym przypadku parametry odnoszą się do wag i odchyleń w sieci neuronowej, których uczymy się podczas procesu uczenia.

W procesie głębokiego uczenia się model jest szkolony w zakresie przewidywania poprzez dostosowywanie tych parametrów w celu zmniejszenia różnicy między przewidywaniami a rzeczywistymi wynikami.
Proces dostosowywania tych parametrów nazywa się optymalizacją i wykorzystuje algorytmy takie jak opadanie gradientu.
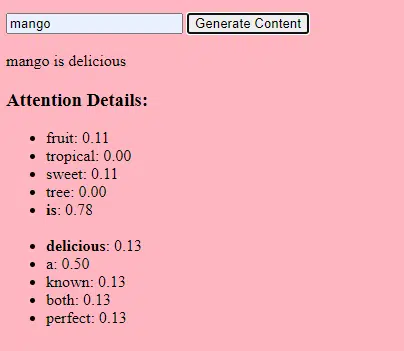
- Wagi: Są to wartości w sieci neuronowej, które przekształcają dane wejściowe w warstwach sieci. Są one dostosowywane podczas treningu, aby zoptymalizować wydajność modelu. Każde połączenie między neuronami w sąsiednich warstwach ma przypisaną wagę.
- Błędy: Są to również wartości w sieci neuronowej dodawane do danych wyjściowych transformacji warstwy. Zapewniają dodatkowy stopień swobody modelu, umożliwiając lepsze dopasowanie go do danych uczących. Każdy neuron w warstwie ma powiązane odchylenie.
To skalowanie umożliwia modelowi przechowywanie i przetwarzanie bardziej skomplikowanych wzorców i relacji w danych.
Duża liczba parametrów oznacza również, że model wymaga znacznej mocy obliczeniowej i pamięci do uczenia i wnioskowania. Właśnie dlatego szkolenie takich modeli wymaga dużych zasobów i zazwyczaj wykorzystuje specjalistyczny sprzęt, taki jak procesory graficzne lub TPU.
Model jest szkolony w zakresie przewidywania następnego słowa w sekwencji przy użyciu potężnych zasobów obliczeniowych. Dostosowuje swoje wewnętrzne parametry w oparciu o popełniane błędy, stale ulepszając swoje przewidywania.
Mechanizmy uwagi, takie jak te, które omówiliśmy, są kluczowe dla LLM. Pozwalają modelowi skupić się na różnych częściach danych wejściowych podczas generowania danych wyjściowych.
Ważąc znaczenie różnych słów w kontekście, mechanizmy uwagi umożliwiają modelowi wygenerowanie spójnego i odpowiedniego kontekstowo tekstu. Dzięki temu na tak masową skalę LLM mogą działać w taki sposób, w jaki to robią.
W jaki sposób transformator przewiduje tekst?
Transformatory przewidują tekst, przetwarzając tokeny wejściowe przez wiele warstw, z których każda jest wyposażona w mechanizmy uwagi i sieci wyprzedzające.
Po przetworzeniu model generuje rozkład prawdopodobieństwa dla swojego słownictwa dla następnego słowa w sekwencji. Jako przewidywanie wybierane jest zwykle słowo z najwyższym prawdopodobieństwem.
W jaki sposób buduje się i szkoli duży model językowy?
Budowanie LLM obejmuje gromadzenie danych, czyszczenie ich, szkolenie modelu, dostrajanie modelu i energiczne, ciągłe testowanie.
Model jest początkowo szkolony na rozległym korpusie, aby przewidzieć następne słowo w sekwencji. Ta faza pozwala modelowi nauczyć się powiązań między słowami, które nawiązują do wzorców gramatycznych, relacji, które mogą reprezentować fakty o świecie, oraz powiązań, które przypominają logiczne rozumowanie. Połączenia te sprawiają również, że wychwytuje błędy obecne w danych szkoleniowych.
Po wstępnym szkoleniu model jest udoskonalany na węższym zbiorze danych, często pod okiem weryfikatorów, którzy przestrzegają wytycznych.
Dostrojenie jest kluczowym krokiem w budowaniu LLM. Polega na szkoleniu wstępnie wytrenowanego modelu na bardziej konkretnym zbiorze danych lub zadaniu. Weźmy jako przykład ChatGPT.
Jeśli bawiłeś się modelami GPT, wiesz, że podpowiadanie polega mniej na „napisz to”, a bardziej na tym
- Podpowiedź: Pewnego razu
- Kontynuacja: Na szczycie wieży znajdował się zły czarodziej.
- Kontynuacja: Na szczycie wieży znajdował się zły czarodziej.
- Podpowiedź : Dlaczego kurczak dołączył do zespołu?
- Kontynuacja : Ponieważ miał pałeczki!
Dotarcie do ChatGPT od tego momentu wiąże się z dużą ilością niskopłatnej siły roboczej. Ci ludzie tworzą ogromne korpusy, aby określić wagę odpowiedzi GPT i oczekiwanych zachowań. Ci pracownicy tworzą mnóstwo tekstów podpowiedzi/kontynuacji, takich jak:
- Podpowiedź : Dokończ tę historię: „Pewnego razu…”
- Kontynuacja : Jasne! Dawno, dawno temu, w odległej krainie, żyła mała wioska położona pomiędzy dwiema majestatycznymi górami.
- Kontynuacja : Jasne! Dawno, dawno temu, w odległej krainie, żyła mała wioska położona pomiędzy dwiema majestatycznymi górami.
- Podpowiedź : Opowiedz mi dowcip o kurczaku.
- Kontynuacja : Dlaczego kurczak dołączył do zespołu? Ponieważ miał pałeczki!
Ten proces dostrajania jest niezbędny z kilku powodów:
- Specyfika: Podczas gdy szkolenie wstępne zapewnia modelowi szerokie zrozumienie języka, dostrajanie zawęża jego wiedzę i zachowanie, aby lepiej dostosować je do konkretnych zadań lub dziedzin. Na przykład model dostosowany do danych medycznych będzie lepiej odpowiadał na pytania medyczne.
- Kontrola: Dostrajanie zapewnia programistom większą kontrolę nad wynikami modelu. Programiści mogą korzystać z wyselekcjonowanego zestawu danych, aby kierować modelem w celu uzyskania pożądanych reakcji i uniknięcia niepożądanych zachowań.
- Bezpieczeństwo: pomaga w ograniczaniu szkodliwych lub stronniczych wyników. Korzystając ze wskazówek podczas procesu dostrajania, weryfikatorzy mogą mieć pewność, że model nie generuje nieodpowiednich treści.
- Wydajność: Dostrajanie może znacznie poprawić wydajność modelu w przypadku określonych zadań. Na przykład model dostosowany do obsługi klienta będzie w tym znacznie lepszy niż model ogólny.
Można powiedzieć, że ChatGPT został w szczególności udoskonalony pod pewnymi względami.
Na przykład „logiczne rozumowanie” to coś, z czym borykają się LLM. Najlepszy model logicznego rozumowania ChatGPT – GPT-4 – został intensywnie przeszkolony w celu wyraźnego rozpoznawania wzorców w liczbach.
Zamiast czegoś takiego:
- Podpowiedź : Co to jest 2+2?
- Proces : Często w podręcznikach do matematyki dla dzieci 2+2 = 4. Czasami pojawiają się odniesienia do „2+2=5”, ale zazwyczaj w takim przypadku jest więcej kontekstu związanego z Georgem Orwellem lub Star Trekiem. Gdyby to miało miejsce w tym kontekście, waga byłaby bardziej korzystna dla 2+2=5. Ale taki kontekst nie istnieje, więc w tym przypadku następnym żetonem będzie prawdopodobnie 4.
- Odpowiedź : 2+2=4
Trening wygląda mniej więcej tak:
- trening: 2+2=4
- trening: 4/2=2
- trening: połowa z 4 to 2
- szkolenie: 2 z 2 to cztery
…i tak dalej.
Oznacza to, że w przypadku bardziej „logicznych” modeli proces uczenia jest bardziej rygorystyczny i koncentruje się na zapewnieniu, że model rozumie i poprawnie stosuje zasady logiczne i matematyczne.
Model jest narażony na różne problemy matematyczne i ich rozwiązania, dzięki czemu może uogólniać i stosować te zasady do nowych, niewidzianych problemów.
Nie można przecenić znaczenia tego procesu dostrajania, szczególnie dla logicznego rozumowania. Bez niego model mógłby dostarczać błędnych lub bezsensownych odpowiedzi na proste pytania logiczne lub matematyczne.
Modele obrazu a modele języka
Chociaż zarówno modele obrazu, jak i języka mogą wykorzystywać podobne architektury, takie jak transformatory, przetwarzane przez nie dane są zasadniczo różne:
Modele obrazu
Modele te dotyczą pikseli i często działają w sposób hierarchiczny, najpierw analizując małe wzory (takie jak krawędzie), a następnie łącząc je w celu rozpoznania większych struktur (takich jak kształty) i tak dalej, aż do zrozumienia całego obrazu.
Modele językowe
Modele te przetwarzają sekwencje słów lub znaków. Muszą zrozumieć kontekst, gramatykę i semantykę, aby wygenerować spójny i odpowiedni kontekstowo tekst.
Jak działają wybitne generatywne interfejsy AI
Dall-E + Podróż w połowie
Dall-E to odmiana modelu GPT-3 przystosowana do generowania obrazu. Jest szkolony na ogromnym zestawie danych par tekst-obraz. Midjourney to kolejny program do generowania obrazu oparty na autorskim modelu.
- Dane wejściowe: podajesz opis tekstowy, np. „dwugłowy flaming”.
- Przetwarzanie: modele te kodują ten tekst w postaci serii liczb, a następnie dekodują te wektory, znajdując relacje z pikselami, w celu utworzenia obrazu. Model nauczył się zależności między opisami tekstowymi a reprezentacjami wizualnymi na podstawie danych szkoleniowych.
- Wynik: obraz pasujący lub odnoszący się do podanego opisu.
Palce, wzory, problemy
Dlaczego te narzędzia nie mogą konsekwentnie generować rąk, które wyglądają normalnie? Narzędzia te działają na zasadzie patrzenia na piksele znajdujące się obok siebie.
Możesz zobaczyć, jak to działa, porównując wcześniej lub bardziej prymitywnie wygenerowane obrazy z nowszymi: wcześniejsze modele wyglądają bardzo niewyraźnie. Natomiast nowsze modele są znacznie wyraźniejsze.
Modele te generują obrazy, przewidując następny piksel na podstawie pikseli, które już wygenerował. Proces ten powtarza się miliony razy, aby uzyskać pełny obraz.
Dłonie, zwłaszcza palce, są skomplikowane i zawierają wiele szczegółów, które należy dokładnie uchwycić.
Położenie, długość i orientacja każdego palca mogą się znacznie różnić na różnych obrazach.
Generując obraz na podstawie opisu tekstowego, model musi przyjąć wiele założeń dotyczących dokładnej pozycji i budowy dłoni, co może prowadzić do anomalii.
CzatGPT
ChatGPT opiera się na architekturze GPT-3.5, modelu opartym na transformatorze przeznaczonym do zadań przetwarzania języka naturalnego.
- Wejście: zachęta lub seria wiadomości symulujących rozmowę.
- Przetwarzanie: ChatGPT wykorzystuje swoją rozległą wiedzę z różnorodnych tekstów internetowych do generowania odpowiedzi. Uwzględnia kontekst podany w rozmowie i stara się przedstawić najbardziej odpowiednią i spójną odpowiedź.
- Dane wyjściowe: odpowiedź tekstowa, która kontynuuje rozmowę lub odpowiada na nią.
Specjalność
Siła ChatGPT leży w jego zdolności do obsługi różnych tematów i symulowania rozmów przypominających ludzkie, co czyni go idealnym rozwiązaniem dla chatbotów i wirtualnych asystentów.
Bard + doświadczenie generatywne wyszukiwania (SGE)
Chociaż szczegółowe szczegóły mogą być zastrzeżone, Bard opiera się na technikach sztucznej inteligencji transformatora, podobnie jak inne najnowocześniejsze modele językowe. SGE opiera się na podobnych modelach, ale wplata w inne algorytmy ML, z których korzysta Google.
SGE prawdopodobnie generuje treść przy użyciu modelu generatywnego opartego na transformatorze, a następnie rozmycie wyodrębnia odpowiedzi ze stron rankingowych w wyszukiwaniu. (To może nie być prawdą. To tylko przypuszczenia na podstawie zabawy z tym urządzeniem. Proszę, nie pozywaj mnie!)
- Wejście: Podpowiedź/polecenie/wyszukiwanie
- Przetwarzanie: Bard przetwarza dane wejściowe i działa w taki sam sposób, jak inne LLM. SGE wykorzystuje podobną architekturę, ale dodaje warstwę, w której przeszukuje swoją wiedzę wewnętrzną (uzyskaną z danych szkoleniowych), aby wygenerować odpowiednią odpowiedź. Uwzględnia strukturę podpowiedzi, kontekst i zamiar wytworzenia odpowiedniej treści.
- Wynik: wygenerowana treść, która może być historią, odpowiedzią lub dowolnym innym typem tekstu.
Zastosowania generatywnej sztucznej inteligencji (i ich kontrowersje)
Sztuka i projektowanie
Generatywna sztuczna inteligencja może teraz tworzyć dzieła sztuki, muzykę, a nawet projekty produktów. Otworzyło to nowe możliwości dla kreatywności i innowacji.
Spór
Rozwój sztucznej inteligencji w sztuce wywołał debaty na temat utraty miejsc pracy w dziedzinach kreatywnych.
Dodatkowo wątpliwości budzi:
- Naruszenia zasad pracy, zwłaszcza gdy treści generowane przez sztuczną inteligencję są wykorzystywane bez odpowiedniego przypisania lub odszkodowania.
- Dyrektorzy grożący pisarzom zastąpienie ich sztuczną inteligencją to jedna z kwestii, która wywołała strajk pisarzy.
Przetwarzanie języka naturalnego (NLP)
Modele AI są obecnie szeroko stosowane w chatbotach, tłumaczeniach językowych i innych zadaniach NLP.
Poza marzeniem o sztucznej inteligencji ogólnej (AGI) jest to najlepsze zastosowanie LLM, ponieważ są one bliskie „ogólnemu” modelowi NLP.
Spór
Wielu użytkowników uważa chatboty za bezosobowe i czasami denerwujące.
Co więcej, chociaż sztuczna inteligencja poczyniła znaczne postępy w tłumaczeniach językowych, często brakuje jej niuansów i zrozumienia kulturowego, jakie wnoszą tłumacze-ludzi, co prowadzi do imponujących i wadliwych tłumaczeń.
Odkrycie medycyny i leków
Sztuczna inteligencja może szybko analizować ogromne ilości danych medycznych i generować potencjalne związki lecznicze, przyspieszając proces odkrywania leków. Wielu lekarzy korzysta już z LLM do pisania notatek i komunikacji z pacjentami
Spór
Poleganie na LLM w celach medycznych może być problematyczne. Medycyna wymaga precyzji, a wszelkie błędy lub niedopatrzenia sztucznej inteligencji mogą mieć poważne konsekwencje.
Medycyna również ma już uprzedzenia, które tylko pogłębiają się w wyniku stosowania LLM. Istnieją również podobne kwestie, omówione poniżej, dotyczące prywatności, skuteczności i etyki.
Hazard
Wielu entuzjastów sztucznej inteligencji jest podekscytowanych wykorzystaniem sztucznej inteligencji w grach: twierdzą, że sztuczna inteligencja może generować realistyczne środowiska gier, postacie, a nawet całe fabuły gier, poprawiając wrażenia z gry. Dialogi NPC można ulepszyć za pomocą tych narzędzi.
Spór
Trwa debata na temat intencjonalności w projektowaniu gier.
Chociaż sztuczna inteligencja może generować ogromne ilości treści, niektórzy twierdzą, że brakuje jej przemyślanego projektu i spójności narracyjnej, jaką wnoszą projektanci.
Watchdogs 2 miało programowych NPC, co niewiele wpłynęło na spójność narracyjną gry jako całości.
Marketing i reklama
Sztuczna inteligencja może analizować zachowania konsumentów i generować spersonalizowane reklamy i treści promocyjne, dzięki czemu kampanie marketingowe są skuteczniejsze.
LLM mają kontekst z pism innych osób, dzięki czemu są przydatne do generowania historii użytkowników lub bardziej dopracowanych pomysłów programowych. Zamiast polecać telewizory osobie, która właśnie kupiła telewizor, firmy LLM mogą polecić akcesoria, które ktoś może chcieć.
Controversy
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
Opinie wyrażone w tym artykule są opiniami gościnnego autora i niekoniecznie należą do Search Engine Land. Autorzy personelu są tutaj wymienieni.