
Całoroczne studium przypadku SEO: co musisz wiedzieć o Googlebocie
Opublikowany: 2019-08-30Uwaga edytora: Dyrektor generalny robota JetOctopus, Serge Bezborodov, udziela fachowych porad, jak sprawić, by Twoja witryna była atrakcyjna dla Googlebota. Dane w tym artykule są oparte na całorocznych badaniach i 300 milionach zindeksowanych stron.
Kilka lat temu próbowałem zwiększyć ruch w naszej witrynie agregatora ofert pracy z 5 milionami stron. Zdecydowałem się na skorzystanie z usług agencji SEO, spodziewając się, że ruch poszybuje w górę. Ale byłem w błędzie. Zamiast kompleksowego audytu dostałem wróżenie z kart tarota. Dlatego wróciłem do punktu wyjścia i stworzyłem robota sieciowego do kompleksowej analizy SEO na stronie.
Szpieguję Googlebota od ponad roku i teraz jestem gotów podzielić się spostrzeżeniami na temat jego zachowania. Oczekuję, że moje obserwacje przynajmniej wyjaśnią, jak działają roboty indeksujące, a co najwyżej pomogą w efektywnym przeprowadzeniu optymalizacji na stronie. Zebrałem najbardziej znaczące dane, które są przydatne zarówno dla nowej witryny, jak i takiej, która ma tysiące stron.
Czy Twoje strony pojawiają się w SERP?
Aby mieć pewność, które strony znajdują się w wynikach wyszukiwania, należy sprawdzić indeksowalność całej witryny. Jednak analiza każdego adresu URL w witrynie liczącej ponad 10 milionów stron kosztuje fortunę, mniej więcej tyle, co nowy samochód.
Zamiast tego użyjmy analizy plików dziennika. Pracujemy ze stronami internetowymi w następujący sposób: Indeksujemy strony internetowe tak, jak robi to robot wyszukiwania, a następnie analizujemy pliki dziennika, które były gromadzone przez pół roku. Dzienniki pokazują, czy boty odwiedzają witrynę, które strony były indeksowane oraz kiedy i jak często boty odwiedzały strony.
Indeksowanie to proces odwiedzania Twojej witryny przez roboty wyszukujące, przetwarzające wszystkie linki na stronach internetowych i umieszczające je w kolejce do indeksacji. Podczas indeksowania boty porównują właśnie przetworzone adresy URL z tymi, które już znajdują się w indeksie. W ten sposób boty odświeżają dane i dodają/usuwają niektóre adresy URL z bazy danych wyszukiwarki, aby zapewnić użytkownikom najbardziej odpowiednie i aktualne wyniki.
Teraz możemy łatwo wyciągnąć następujące wnioski:
- O ile bot wyszukiwania nie był na adresie URL, ten adres URL prawdopodobnie nie będzie w indeksie.
- Jeśli Googlebot odwiedza adres URL kilka razy dziennie, ten adres URL ma wysoki priorytet i dlatego wymaga Twojej szczególnej uwagi.
W sumie te informacje ujawniają, co uniemożliwia organiczny wzrost i rozwój Twojej witryny. Teraz, zamiast działać na ślepo, Twój zespół może mądrze zoptymalizować stronę internetową.
Pracujemy głównie z dużymi witrynami, ponieważ jeśli Twoja witryna jest mała, Googlebot prędzej czy później zaindeksuje wszystkie Twoje strony internetowe.
I odwrotnie, witryny ze 100,00-plus stron napotykają problem, gdy robot indeksujący odwiedza strony, które są niewidoczne dla webmasterów. Cenny budżet indeksowania może zostać zmarnowany na tych bezużytecznych lub nawet szkodliwych stronach. Jednocześnie bot może nigdy nie znaleźć twoich dochodowych stron, ponieważ w strukturze witryny panuje bałagan.
Budżet indeksowania to ograniczone zasoby, które Googlebot jest gotowy przeznaczyć na Twoją witrynę. Został stworzony, aby nadać priorytet temu, co i kiedy analizować. Wielkość budżetu indeksowania zależy od wielu czynników, takich jak rozmiar Twojej witryny, jej struktura, liczba i częstotliwość zapytań użytkowników itp.
Pamiętaj, że robot wyszukiwania nie jest zainteresowany całkowitym indeksowaniem Twojej witryny.
Głównym celem bota wyszukiwarki jest udzielanie użytkownikom najbardziej trafnych odpowiedzi przy minimalnych stratach zasobów.Bot indeksuje tyle danych, ile potrzebuje do głównego celu. Tak więc Twoim zadaniem jest pomóc botowi wybrać najbardziej użyteczną i dochodową zawartość.
Szpiegowanie Googlebota
W ciągu ostatniego roku przeskanowaliśmy ponad 300 milionów adresów URL i 6 miliardów wierszy dziennika w dużych witrynach internetowych. Na podstawie tych danych prześledziliśmy zachowanie Googlebota, aby pomóc odpowiedzieć na następujące pytania:
- Jakie rodzaje stron są ignorowane?
- Które strony są często odwiedzane?
- Co jest warte uwagi dla bota?
- Co nie ma wartości?
Poniżej znajduje się nasza analiza i wnioski, a nie przepisanie wskazówek Google dla webmasterów. W rzeczywistości nie dajemy żadnych niesprawdzonych i nieuzasadnionych rekomendacji. Dla Twojej wygody każdy punkt jest oparty na rzeczywistych statystykach i wykresach.
Przejdźmy do sedna i dowiedzmy się:
- Co jest naprawdę ważne dla Googlebota?
- Co decyduje o tym, czy bot odwiedza stronę, czy nie?
Zidentyfikowaliśmy następujące czynniki:
Odległość od indeksu
DFI oznacza odległość od indeksu i określa, jak daleko w kliknięciach znajduje się adres URL głównego/głównego/indeksowanego adresu URL. To jedno z najważniejszych kryteriów, które wpływa na częstotliwość odwiedzin Googlebota. Oto film edukacyjny, aby dowiedzieć się więcej o DFI .
Zauważ, że DFI nie jest liczbą ukośników w katalogu URL, jak na przykład:
site.com / sklep /iphone/iphoneX.html – DFI – 3
Tak więc DFI jest liczone dokładnie przez KLIKNIĘCIA ze strony głównej
https://site.com/shop/iphone/iphoneX.html
https://site.com Katalog iPhone'ów → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
Poniżej możesz zobaczyć, jak zainteresowanie Googlebota adresem URL z jego DFI stopniowo malało w ciągu ostatniego miesiąca i ostatnich sześciu miesięcy.
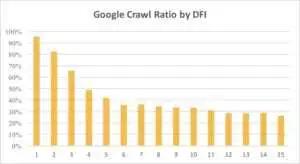
Jak widać, jeśli DFI wynosi 5 t0 6, Googlebot indeksuje tylko połowę stron internetowych. A odsetek przetworzonych stron zmniejsza się, jeśli DFI jest większy. Wskaźniki w tabeli zostały ujednolicone dla 18 milionów stron. Pamiętaj, że dane mogą się różnić w zależności od niszy danej witryny.
Co robić?
Oczywiste jest, że najlepszą strategią w tym przypadku jest unikanie DFI dłuższych niż 5, zbudowanie łatwej w nawigacji struktury witryny, zwrócenie szczególnej uwagi na linki itp.
Prawda jest taka, że te środki są naprawdę czasochłonne dla 100,oo-plus stron internetowych. Zwykle duże strony internetowe mają długą historię przeprojektowywania i migracji. Dlatego webmasterzy nie powinni po prostu usuwać stron z DFI 10, 12 czy nawet 30. Ponadto wstawienie jednego linku z często odwiedzanych stron nie rozwiąże problemu.
Optymalnym sposobem radzenia sobie z długimi DFI jest sprawdzenie i oszacowanie, czy te adresy URL są trafne, opłacalne i jakie pozycje zajmują w SERP.
Strony z długim DFI, ale dobrymi pozycjami w SERP, mają duży potencjał. Aby zwiększyć ruch na stronach wysokiej jakości, webmasterzy powinni wstawiać linki z kolejnych stron. Jeden do dwóch linków nie wystarczą do namacalnego postępu.
Na poniższym wykresie widać, że Googlebot odwiedza adresy URL częściej, jeśli na stronie znajduje się więcej niż 10 linków.
Spinki do mankietów
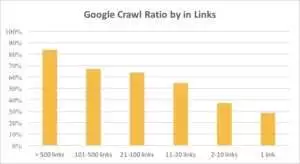
W rzeczywistości im większa witryna, tym bardziej znacząca jest liczba linków na stronach internetowych. Dane te pochodzą w rzeczywistości z ponad miliona stron internetowych.

Jeśli odkryłeś, że na Twoich dochodowych stronach jest mniej niż 10 linków, nie panikuj. Najpierw sprawdź, czy te strony są wysokiej jakości i rentowne. Gdy to zrobisz, wstawiaj linki na wysokiej jakości stronach bez pośpiechu i z krótkimi iteracjami, analizując logi po każdym kroku.
Rozmiar treści
Treść jest jednym z najpopularniejszych aspektów analizy SEO. Oczywiście im bardziej trafna treść znajduje się w Twojej witrynie, tym lepszy współczynnik indeksowania. Poniżej możesz zobaczyć, jak dramatycznie spada zainteresowanie Googlebota stronami zawierającymi mniej niż 500 słów.
Co robić?
Z mojego doświadczenia wynika, że prawie połowa wszystkich stron zawierających mniej niż 500 słów to strony śmieci. Widzieliśmy przypadek, w którym witryna zawierała 70 000 stron, na których wymieniono tylko rozmiary ubrań, więc tylko część tych stron znalazła się w indeksie.
Dlatego najpierw sprawdź, czy naprawdę potrzebujesz tych stron. Jeśli te adresy URL są ważne, należy dodać do nich odpowiednią treść. Jeśli nie masz nic do dodania, po prostu zrelaksuj się i pozostaw te adresy URL bez zmian. Czasem lepiej nic nie robić niż publikować bezużyteczne treści.
Inne czynniki
Następujące czynniki mogą znacząco wpłynąć na współczynnik indeksowania:
Czas ładowania
Szybkość strony internetowej ma kluczowe znaczenie dla indeksowania i rankingu. Bot jest jak człowiek: nie znosi zbyt długiego czekania na załadowanie strony internetowej. Jeśli w Twojej witrynie jest więcej niż milion stron, robot wyszukiwania prawdopodobnie pobierze pięć stron z 1-sekundowym czasem ładowania, zamiast czekać, aż jedna strona załaduje się w 5 sekund.
Co robić?
W rzeczywistości jest to zadanie techniczne i nie ma jednej uniwersalnej metody, takiej jak użycie większego serwera. Główną ideą jest znalezienie wąskiego gardła problemu. Powinieneś zrozumieć, dlaczego strony internetowe ładują się wolno. Dopiero po ujawnieniu przyczyny możesz podjąć działania.
Stosunek unikalnych i szablonowych treści
Ważna jest równowaga między unikalnymi i szablonowymi danymi. Na przykład masz witrynę internetową z odmianami imion zwierząt domowych. Ile istotnych i unikalnych treści możesz naprawdę zebrać na ten temat?
Luna była najpopularniejszym imieniem psa „celebryty”, a następnie Stella, Jack, Milo i Leo.
Roboty wyszukiwania nie lubią wydawać swoich zasobów na tego rodzaju strony.
Co robić?
Zachowaj równowagę. Użytkownicy i boty nie lubią odwiedzać stron ze skomplikowanymi szablonami, mnóstwem linków wychodzących i małą ilością treści.
Strony sieroce
Strony osierocone to adresy URL, których nie ma w strukturze witryny i których nie znasz, ale te strony osierocone mogą być indeksowane przez roboty. Aby było to jasne, spójrz na Koło Eulera na poniższym obrazku:

Możesz zobaczyć normalną sytuację dla młodej witryny, której struktura nie była zmieniana od dłuższego czasu. Ty i robot indeksujący możecie przeanalizować 900 000 stron. Robot indeksujący przetwarza około 500 000 stron, ale nie są one znane Google. Jeśli zindeksujesz te 500 000 adresów URL, Twój ruch na pewno wzrośnie.
Uwaga: nawet młoda witryna zawiera strony (niebieska część na obrazku), których nie ma w strukturze witryny, ale które są regularnie odwiedzane przez bota.
A te strony mogą zawierać śmieci, takie jak bezużyteczne zapytania użytkowników generowane automatycznie.
Ale duże strony internetowe rzadko są tak dokładne. Bardzo często strony z historią wyglądają tak:

Oto inny problem: Google wie więcej o Twojej witrynie niż Ty. Mogą to być usunięte strony, strony w JavaScript lub Ajax, zepsute przekierowania i tak dalej i tak dalej. Kiedyś mieliśmy do czynienia z sytuacją, w której z powodu błędu programisty w mapie witryny pojawiła się lista 500 000 niedziałających linków. Po trzech dniach błąd został znaleziony i naprawiony, ale Googlebot odwiedzał te niedziałające linki przez pół roku!
Tak często Twój budżet indeksowania jest często marnowany na tych stronach sierocych.
Co robić?
Istnieją dwa sposoby rozwiązania tego potencjalnego problemu: Pierwszy jest kanoniczny: posprzątanie bałaganu. Uporządkuj strukturę serwisu, wstaw poprawnie linki wewnętrzne, dodaj strony osierocone do DFI dodając linki z zaindeksowanych stron, ustaw zadanie dla programistów i czekaj na kolejną wizytę Googlebota.
Drugi sposób jest szybki: zbierz listę stron osieroconych i sprawdź, czy są one istotne. Jeśli odpowiedź brzmi „tak”, utwórz mapę witryny z tymi adresami URL i wyślij ją do Google. Ten sposób jest łatwiejszy i szybszy, ale tylko połowa stron osieroconych znajdzie się w indeksie.
Następny poziom
Algorytmy wyszukiwarek poprawiły się przez dwie dekady i naiwnością jest sądzić, że indeksowanie można wyjaśnić za pomocą kilku wykresów.
Zbieramy ponad 200 różnych parametrów dla każdej strony i spodziewamy się, że liczba ta wzrośnie do końca roku. Wyobraź sobie, że Twoja witryna to tabela z 1 milionem wierszy (stron) i pomnóż te wiersze przez 200 kolumn, prosta próbka nie wystarczy do kompleksowego, technicznego audytu. Czy sie zgadzasz?
Postanowiliśmy zajrzeć głębiej i wykorzystaliśmy uczenie maszynowe, aby dowiedzieć się, co wpływa na indeksowanie Googlebotów w każdym przypadku.

Po pierwsze, linki do stron internetowych są kluczowe, podczas gdy treść jest kluczowym czynnikiem dla drugiego.
Głównym celem tego zadania było uzyskanie łatwych odpowiedzi ze skomplikowanych i ogromnych danych: Co w Twojej witrynie ma największy wpływ na indeksację? Które klastry adresów URL są połączone tymi samymi czynnikami? Tak , abyś mógł z nimi współpracować kompleksowo.
Przed pobraniem i analizą logów na naszej stronie agregującej HotWork, opowieść o osieroconych stronach, które są widoczne dla botów, ale nie dla nas, wydawała mi się nierealna. Ale prawdziwa sytuacja zaskoczyła mnie jeszcze bardziej: Crawl pokazał 500 stron z przekierowaniem 301, ale Yandex znalazł 700 000 stron z tym samym kodem statusu.
Zwykle maniacy techniki nie lubią przechowywać plików dziennika, ponieważ te dane „przeciążają” dyski. Ale obiektywnie na większości serwisów, które mają do 10 milionów odwiedzin miesięcznie, podstawowe ustawienie przechowywania logów działa idealnie.
Mówiąc o ilości logów, najlepszym rozwiązaniem jest utworzenie archiwum i pobranie go na Amazon S3-Glacier (można przechowywać 250 GB danych za jedyne 1 USD). Dla administratorów systemu to zadanie jest tak proste, jak zrobienie filiżanki kawy. W przyszłości dzienniki historyczne pomogą wykryć błędy techniczne i oszacować wpływ aktualizacji Google na Twoją witrynę.