
Uma jornada de teste E2E Parte 1: STUI para WebdriverIO
Publicados: 2019-11-21Nota: Este é um post de #frontend@twiliosendgrid. Para outras postagens de engenharia, acesse o blog técnico.
À medida que a arquitetura front-end do SendGrid começou a amadurecer em nossos aplicativos da Web, queríamos adicionar outro nível de teste além de nossa unidade usual e camada de teste de integração. Buscamos construir novas páginas e funcionalidades com cobertura de testes E2E (end-to-end) com ferramentas de automação de navegadores.
Desejávamos automatizar os testes da perspectiva do cliente e evitar testes de regressão manual sempre que possível para quaisquer grandes mudanças que pudessem ocorrer em qualquer parte da pilha. Tínhamos, e ainda temos, o seguinte objetivo: fornecer uma maneira de escrever testes de automação E2E consistentes, depuráveis, sustentáveis e valiosos para nossos aplicativos front-end e integrar com CICD (integração contínua e implantação contínua).
Experimentamos várias abordagens técnicas até finalizarmos nossa solução ideal para testes E2E. Em alto nível, isso resume nossa jornada:
- Construindo nossa própria solução Ruby Selenium personalizada, SiteTestUI aka STUI
- Transição de STUI para um WebdriverIO baseado em nó
- Não estar satisfeito com nenhuma das configurações e finalmente migrar para o Cypress
Esta postagem do blog é uma das duas partes que documentam e destacam nossas experiências, lições aprendidas e trocas com cada uma das abordagens usadas ao longo do caminho para guiar você e outros desenvolvedores sobre como conectar testes E2E com padrões úteis e estratégias de teste.
A primeira parte abrange nossas dificuldades iniciais com o STUI, como migramos para o WebdriverIO e ainda experimentamos muitas quedas semelhantes ao STUI. Veremos como escrevemos os testes com o WebdriverIO, Dockerizamos os testes para serem executados em um contêiner e, eventualmente, integramos os testes com o Buildkite, nosso provedor de CICD.
Se você quiser pular para onde estamos com os testes E2E hoje, vá em frente para a parte dois, que passa por nossa migração final de STUI e WebdriverIO para Cypress e como a configuramos em diferentes equipes.
TLDR: Nós experimentamos dores e lutas semelhantes com ambas as soluções de wrapper Selenium, STUI e WebdriverIO, que eventualmente começamos a procurar alternativas no Cypress. Aprendemos várias lições perspicazes para lidar com a escrita de testes E2E e a integração com o Docker e o Buildkite.
Índice:
Primeira incursão no teste E2E: siteTESUI aka STUI
Mudando de STUI para WebdriverIO
Etapa 1: decidir sobre dependências para WebdriverIO
Etapa 2: configurações e scripts de ambiente
Etapa 3: Implementando Testes ENE Localmente
Etapa 4: Dockerizando todos os testes
Etapa 5: Integração com o CICD
Trocas com WebdriverIo
Movendo-se para o Cipreste
Primeira incursão no teste E2E: SiteTestUI aka STUI
Ao procurar inicialmente uma ferramenta de automação de navegador, nossos SDETs (engenheiros de desenvolvimento de software em teste) mergulharam em nossa própria solução interna personalizada construída com Ruby e Selenium, especificamente Rspec e uma estrutura Selenium personalizada chamada Gridium. Valorizamos seu suporte entre navegadores, a capacidade de configurar nossas próprias integrações personalizadas com o TestRail para nossos casos de teste de engenharia de QA (Quality Assurance) e a ideia de criar o repositório ideal para todas as equipes de frontend escreverem testes E2E em um local e serem executar em um cronograma.
Como um desenvolvedor frontend ansioso para escrever alguns testes E2E pela primeira vez com as ferramentas que os SDETs construíram para nós, começamos a implementar testes para as páginas que já lançamos e ponderamos como configurar corretamente os usuários e os dados de sementes para focar em partes do o recurso que queríamos testar. Aprendemos algumas coisas ótimas ao longo do caminho, como formar objetos de página para organizar funcionalidades auxiliares e seletores de elementos com os quais desejamos interagir por página e começamos a formar especificações que seguiam esta estrutura:
Gradualmente, construímos conjuntos de testes substanciais em diferentes equipes no mesmo repositório seguindo padrões semelhantes, mas logo experimentamos muitas frustrações que retardariam imensamente nosso progresso para novos desenvolvedores e colaboradores consistentes do STUI, como:
- Colocar em funcionamento exigiu tempo e esforço consideráveis para instalar todos os drivers do navegador, dependências do Ruby Gem e versões corretas antes mesmo de executar as suítes de teste. Às vezes, tínhamos que descobrir por que os testes seriam executados na máquina de uma pessoa versus a máquina de outra pessoa e como suas configurações diferem.
- Os conjuntos de testes proliferaram e funcionaram por horas até a conclusão. Como todas as equipes contribuíram para o mesmo repositório, executar todos os testes em série significava esperar várias horas para que o conjunto de testes geral fosse executado e várias equipes empurrando o novo código potencialmente levavam a outro teste quebrado em outro lugar.
- Ficamos frustrados com os seletores CSS esquisitos e os seletores XPath complicados . Esta imagem abaixo explica o suficiente como o uso do XPath pode tornar as coisas mais complicadas e essas foram algumas das mais simples.

- Testes de depuração eram dolorosos . Tivemos problemas para depurar saídas de erros vagos e geralmente não tínhamos ideia de onde e como as coisas falhavam. Só podíamos executar os testes repetidamente e observar o navegador para deduzir onde ele possivelmente falhou e qual código foi responsável por isso. Quando um teste falhou em um ambiente Docker no CICD sem muito o que observar além das saídas do console, tivemos dificuldades para reproduzir localmente e resolver o problema.
- Encontramos bugs e lentidão do Selenium . Os testes foram executados lentamente devido a todas as solicitações enviadas do servidor para o navegador e, às vezes, nossos testes travavam completamente ao tentar selecionar muitos elementos na página ou por motivos desconhecidos durante as execuções de teste.
- Mais tempo foi gasto corrigindo e ignorando testes e execuções de teste de compilação agendadas quebradas começaram a ser ignoradas. Os testes não forneceram valor em realmente significar erros verdadeiros no sistema.
- Nossas equipes de front-end se sentiram desconectadas dos testes E2E, pois existiam em um repositório separado dos respectivos aplicativos da web. Muitas vezes precisávamos ter os dois repositórios abertos ao mesmo tempo e continuar a olhar para frente e para trás entre as bases de código, além das guias do navegador, quando os testes eram executados.
- As equipes de front-end não gostavam de mudar o contexto de escrever código em JavaScript ou TypeScript diariamente para Ruby e ter que reaprender a escrever testes sempre que contribuíam para o STUI.
- Como foi a primeira vez para muitos de nós ao contribuir para o teste, caímos em muitos antipadrões , como criar estado por meio da interface do usuário para fazer login, não fazer desmontagem ou configuração suficiente por meio da API e não ter documentação suficiente a seguir para o que faz um grande teste.
Apesar de nosso progresso em escrever um número considerável de testes E2E para muitas equipes diferentes em um repositório e aprender alguns padrões úteis para levar conosco, tivemos dores de cabeça com a experiência geral do desenvolvedor, vários pontos de falha e falta de testes valiosos e estáveis para verificar toda a nossa pilha.
Valorizamos uma maneira de capacitar outros desenvolvedores front-end e QAs para construir seus próprios conjuntos de testes E2E estáveis com JavaScript que reside em seu próprio código de aplicativo para promover a reutilização, proximidade e propriedade dos testes. Isso nos levou a investigar o WebdriverIO, uma estrutura Selenium baseada em JavaScript para testes de automação do navegador, como nosso substituto inicial para STUI, a solução interna personalizada do Ruby Selenium.
Mais tarde, experimentaríamos suas quedas e, eventualmente, passaríamos para o Cypress (avançar para a Parte 2 aqui se as coisas do WebdriverIO não agradarem a você), mas ganhamos uma experiência inestimável com o estabelecimento de infraestrutura padronizada no repositório de cada equipe, integrando testes E2E no CICD para nosso front-end equipes e adotando padrões técnicos que valem a pena documentar em nossa jornada e para que outros saibam quem pode estar prestes a entrar no WebdriverIO ou em qualquer outra solução de teste E2E.
Mudando de STUI para WebdriverIO

Ao embarcar no WebdriverIO para aliviar as frustrações que experimentamos, experimentamos fazer com que cada equipe de frontend convertesse seus testes de automação existentes escritos com a abordagem Ruby Selenium para testes WebdriverIO em JavaScript ou TypeScript e comparasse estabilidade, velocidade, experiência do desenvolvedor e manutenção geral de Os testes.
Para alcançar nossa configuração ideal de ter testes E2E residindo nos repositórios de aplicativos das equipes de front-end e executados em CICD e pipelines agendados, recapitulamos as etapas a seguir que geralmente se aplicam a qualquer equipe que deseje integrar uma estrutura de teste E2E com objetivos semelhantes :
- Instalando e escolhendo dependências para conectar com a estrutura de teste
- Estabelecendo configurações de ambiente e comandos de script
- Implementando testes E2E que passam localmente em diferentes ambientes
- Dockerizando os testes
- Integrando testes Dockerized com o provedor CICD
Etapa 1: decidir sobre dependências para WebdriverIO
O WebdriverIO oferece aos desenvolvedores a flexibilidade de escolher entre muitas estruturas, repórteres e serviços para iniciar o executor de testes. Isso exigiu muitos ajustes e pesquisas para que as equipes se decidissem por certas bibliotecas para começar.
Como o WebdriverIO não é prescritivo sobre o que usar, ele abriu as portas para que as equipes de front-end tivessem bibliotecas e configurações variadas, embora os testes principais gerais fossem consistentes no uso da API do WebdriverIO.
Optamos por permitir que cada uma das equipes de front-end personalizasse com base em suas preferências e, normalmente, usamos o Mocha como estrutura de teste, o Mochawesome como o repórter, o serviço Selenium Standalone e o suporte ao Typescript. Escolhemos Mocha e Mochawesome devido à familiaridade de nossas equipes e experiência anterior com Mocha, mas outras equipes decidiram usar outras alternativas também.
Etapa 2: configurações e scripts de ambiente
Depois de decidir sobre a infraestrutura do WebdriverIO, precisávamos de uma maneira de executar nossos testes do WebdriverIO com configurações variadas para cada ambiente. Aqui está uma lista que ilustra a maioria dos casos de uso de como queríamos executar esses testes e por que desejamos apoiá-los:
- Contra um servidor de desenvolvimento Webpack rodando em localhost (ou seja, http://localhost:8000) e esse servidor de desenvolvimento seria apontado para uma determinada API de ambiente como teste ou teste (ou seja, https://testing.api.com ou https:// staging.api. com).
Por quê? Às vezes precisamos fazer alterações em nosso aplicativo da web local, como adicionar seletores mais específicos para nossos testes interagirem com os elementos de maneira mais robusta ou estávamos em andamento no desenvolvimento de um novo recurso e precisávamos ajustar e validar os testes de automação existentes passaria localmente contra nossas novas alterações de código. Sempre que o código do aplicativo mudou e ainda não fizemos push para o ambiente implantado, usamos esse comando para executar nossos testes em nosso aplicativo Web local. - Contra um aplicativo implantado para um determinado ambiente (ou seja, https://testing.app.com ou https://staging.app.com), como teste ou teste
Por quê? Outras vezes, o código do aplicativo não muda, mas podemos ter que alterar nosso código de teste para corrigir alguma falha ou nos sentimos confiantes o suficiente para adicionar ou excluir testes completamente sem fazer nenhuma alteração no frontend. Utilizamos muito esse comando para atualizar ou depurar testes localmente no aplicativo implantado para simular mais de perto como nossos testes são executados em pipelines CICD. - Executando em um contêiner do Docker em um aplicativo implantado para um determinado ambiente, como teste ou preparo
Por quê? Isso se destina a pipelines CICD para que possamos acionar testes E2E para serem executados em um contêiner do Docker, por exemplo, no aplicativo implantado de teste e garantir que eles sejam aprovados antes de implantar o código na produção ou em execuções de teste agendadas em um pipeline dedicado. Ao configurar esses comandos inicialmente, realizamos muitas tentativas e erros para ativar contêineres do Docker com diferentes valores de variáveis de ambiente e testar para ver os testes adequados executados com sucesso antes de conectá-los ao nosso provedor CICD, Buildkite.
Para fazer isso, configuramos um arquivo de configuração de base geral com propriedades compartilhadas e muitos arquivos específicos de ambiente, de modo que cada arquivo de configuração de ambiente se fundiria com o arquivo de base e substituiria ou adicionaria propriedades conforme exigido para execução. Poderíamos ter um arquivo para cada ambiente sem a necessidade de um arquivo base, mas isso levaria a muita duplicação em configurações comuns. Optamos por usar uma biblioteca como o deepmerge para lidar com isso, mas é importante notar que a mesclagem nem sempre é perfeita com objetos aninhados ou matrizes. Sempre verifique as configurações de saída resultantes, pois isso pode levar a um comportamento indefinido quando houver propriedades duplicadas que não foram mescladas corretamente.
Formamos um arquivo de configuração base comum , wdio.conf.js , assim:
Para se adequar ao nosso primeiro caso de uso principal de execução de testes E2E em um servidor de desenvolvimento de webpack local apontado para uma API de ambiente, geramos o arquivo de configuração localhost, wdio.localhost.conf.js , com o seguinte:
Observe que mesclamos o arquivo base e adicionamos as propriedades específicas do localhost ao arquivo para torná-lo mais compacto e fácil de manter. Também usamos o serviço Selenium Standalone para ativar diferentes tipos de navegadores, também conhecidos como recursos.
Para o segundo caso de uso de execução de testes E2E em um aplicativo da Web implantado, configuramos os arquivos de configuração do aplicativo de teste e teste , `wdio.testing.conf.js` e wdio.staging.conf.js , semelhantes a este:
Aqui adicionamos algumas variáveis de ambiente extras aos arquivos de configuração, como credenciais de login para usuários dedicados no teste e atualizamos o `baseUrl` para apontar para o URL do aplicativo de teste implantado.
Para o terceiro caso de uso de execução de testes E2E em um contêiner do Docker em um aplicativo da Web implantado no domínio de nosso provedor CICD, configuramos os arquivos de configuração do CICD, wdio.cicd.testing.conf.js e wdio.cicd.staging.conf.js , assim:
Observe como não usamos mais o serviço Selenium Standalone, pois mais tarde instalaremos o Selenium Chrome, o Selenium Hub e o código do aplicativo em serviços separados em um arquivo Docker Compose. Essa configuração também exibe as mesmas variáveis de ambiente que a configuração de teste, como as credenciais de login e `baseUrl`, pois esperamos executar nossos testes no aplicativo de teste implantado, e a única diferença é que esses testes devem ser executados em um contêiner do Docker .
Com esses arquivos de configuração de ambiente estabelecidos, descrevemos os comandos de script package.json que serviriam como base para nossos testes. Para este exemplo, prefixamos os comandos com “uitest” para denotar testes de interface do usuário com WebdriverIO e porque também encerramos os arquivos de teste com *.uitest.js . Aqui estão alguns comandos de amostra para o ambiente de teste:
Etapa 3: Implementando Testes E2E Localmente
Com todos os comandos de teste em mãos, criamos o escopo de testes em nosso repositório STUI para convertermos em testes WebdriverIO. Nós nos concentramos em testes de página de pequeno e médio porte e começamos a aplicar o padrão de objeto de página para encapsular toda a interface do usuário de cada página de maneira organizada.
Poderíamos ter arquivos estruturados com um monte de funções auxiliares ou literais de objetos ou qualquer outra estratégia, mas a chave era ter uma maneira consistente de entregar testes sustentáveis rapidamente e mantê-los. Se o fluxo da interface do usuário ou os elementos DOM forem alterados para uma página específica, precisamos apenas refatorar o objeto de página relacionado a ele e possivelmente o código de teste para que os testes sejam aprovados novamente.
Implementamos o padrão de objeto de página tendo um objeto de página base com funcionalidade compartilhada a partir da qual todos os outros objetos de página se estenderiam. Tínhamos funções como open para fornecer uma API consistente em todos os nossos objetos de página para “abrir” ou visitar a URL de uma página no navegador. Parecia algo assim:
Implementar os objetos de página específicos seguiu o mesmo padrão de estender a partir da classe base Page e adicionar os seletores a certos elementos com os quais desejávamos interagir ou afirmar e funções auxiliares para executar ações na página.
Observe como usamos a classe base open através de super.open(...) com a rota específica da página para que possamos visitar a página com esta chamada, SomePage.open() . Também exportamos a classe já inicializada para que possamos referenciar os elementos como SomePage.submitButton ou SomePage.tableRows e interagir ou fazer declarações sobre esses elementos com comandos WebdriverIO. Se o objeto de página deveria ser compartilhado e inicializado com suas próprias propriedades de membro em um construtor, também poderíamos exportar a classe diretamente e instanciar o objeto de página nos arquivos de teste com new SomePage(...constructorArgs) .
Depois que apresentamos os objetos de página com seletores e algumas funcionalidades auxiliares, escrevemos os testes E2E e modelamos normalmente esta fórmula de teste:
- Configure ou destrua através da API o que for necessário para redefinir as condições de teste para o ponto de partida esperado antes de executar os testes reais.
- Faça login em um usuário dedicado para o teste para que, sempre que visitássemos as páginas diretamente, ficássemos logados e não precisássemos passar pela interface do usuário. Criamos uma função auxiliar de
loginsimples que recebe um nome de usuário e uma senha que faz a mesma chamada de API que usamos para nossa página de login e que eventualmente retorna nosso token de autenticação necessário para permanecer conectado e passar os cabeçalhos de solicitações de API protegidas. Outras empresas podem ter ainda mais endpoints internos personalizados ou ferramentas para criar novos usuários com dados e configurações de seed rapidamente, mas nós, infelizmente, não tínhamos um desenvolvido o suficiente. Faríamos à moda antiga e criamos usuários de teste dedicados em nossos ambientes com configurações diferentes por meio da interface do usuário e muitas vezes desmembramos testes para páginas com usuários distintos para evitar conflitos de recursos e permanecer isolados quando os testes são executados em paralelo. Tínhamos que garantir que os usuários de teste dedicados não fossem tocados por outras pessoas, caso contrário, os testes seriam interrompidos quando alguém mexesse em um deles sem saber. - Automatize as etapas como se um usuário final interagisse com o recurso/página. Normalmente, visitaríamos a página que contém nosso fluxo de recursos e começaríamos a seguir as etapas de alto nível que um usuário final faria, como preencher entradas, clicar em botões, aguardar a exibição de modais ou banners e observar tabelas para saídas alteradas conforme resultado da ação. Usando nossos práticos objetos de página e seletores, implementamos rapidamente cada etapa e, como verificações de sanidade ao longo do caminho, afirmaríamos o que o usuário deveria ou não ver na página durante o fluxo de recursos para que certas coisas estivessem se comportando conforme o esperado antes e depois de cada etapa. Também fomos deliberados sobre a escolha de testes de caminho feliz de alto valor e, às vezes, estados de erro comuns facilmente reproduzíveis, adiando o restante dos testes de nível inferior para testes de unidade e integração.
Aqui está um exemplo aproximado do layout geral de nossos testes E2E (esta estratégia aplicada a outros frameworks de teste que tentamos também):

Em uma nota lateral, optamos por não cobrir todas as dicas e truques para as melhores práticas do WebdriverIO e E2E nesta série de postagens do blog, mas falaremos sobre esses tópicos em uma postagem futura do blog, portanto, fique atento!
Etapa 4: Dockerizando todos os testes
Ao executar cada etapa do pipeline Buildkite em uma nova máquina AWS na nuvem, não poderíamos simplesmente chamar “npm run uitests:staging” porque essas máquinas não possuem Node, navegadores, nosso código de aplicativo ou quaisquer outras dependências para realmente executar os testes .
Para resolver isso, agrupamos todas as dependências, como Node, Selenium, Chrome e o código do aplicativo em um contêiner do Docker para que os testes do WebdriverIO sejam executados com êxito. Aproveitamos o Docker e o Docker Compose para montar todos os serviços necessários para começar a funcionar, o que se traduziu em Dockerfiles e docker-compose.yml e muitas experiências com a criação de contêineres Docker localmente para fazer as coisas funcionarem.
Para fornecer mais contexto, não éramos especialistas em Docker, por isso levou um tempo considerável para entender como juntar tudo. Existem várias maneiras de Dockerize testes do WebdriverIO e achamos difícil orquestrar muitos serviços diferentes juntos e filtrar várias imagens do Docker, versões do Compose e tutoriais até que as coisas funcionassem.
Demonstraremos principalmente arquivos detalhados que correspondem a uma das configurações de nossas equipes e esperamos que isso forneça informações para você ou para qualquer pessoa que resolva o problema geral de dockerização de testes baseados em Selenium.
Em alto nível, nossos testes exigiram o seguinte:
- Selenium para executar comandos e se comunicar com um navegador. Empregamos o Selenium Hub para ativar várias instâncias à vontade e baixamos a imagem, “selenium/hub”, para o serviço
selenium-hubno arquivo docker-compose. - Um navegador para ser executado. Criamos instâncias do Selenium Chrome e instalamos a imagem, “selenium/node-chrome-debug”, para o serviço
selenium-chromenodocker-compose.yml file. - Código do aplicativo para executar nossos arquivos de teste com qualquer outro módulo Node instalado. Criamos um novo
Dockerfilepara fornecer um ambiente com o Node para instalar pacotes npm e executar scriptspackage.json, copiar o código de teste e atribuir um serviço dedicado à execução dos arquivos de teste denominadosuitestsno arquivodocker-compose.yml.
Para abrir um serviço com todos os nossos aplicativos e códigos de teste necessários para executar os testes do WebdriverIO, criamos um Dockerfile chamado Dockerfile.uitests e instalamos todos os node_modules e copiamos o código para o diretório de trabalho da imagem em um ambiente Node. Isso seria usado pelo nosso serviço Docker Compose uitests e conseguimos a configuração do Dockerfile da seguinte maneira:
Para trazer o Selenium Hub, o navegador Chrome e o código de teste do aplicativo juntos para que os testes do WebdriverIO sejam executados, descrevemos os serviços selenium-hub , selenium-chrom e e uitest s no arquivo docker-compose.uitests.yml :
Conectamos o Selenium Hub e as imagens do Chrome por meio de variáveis de ambiente, depends_on e expondo portas para serviços. Nossa imagem de código do aplicativo de teste acabaria sendo enviada e extraída de um registro privado do Docker que gerenciamos.
Construiríamos a imagem do Docker para o código de teste durante o CICD com determinadas variáveis de ambiente como VERSION e PIPELINE_SUFFIX para referenciar as imagens por uma tag e um nome mais específico. Em seguida, iniciaríamos os serviços do Selenium e executaríamos comandos por meio do serviço uitests para executar os testes do WebdriverIO.
À medida que construímos nossos arquivos do Docker Compose, aproveitamos os comandos úteis como docker-compose up e docker-compose down com o Mac Docker instalado em nossas máquinas para testar localmente se nossas imagens tinham as configurações adequadas e funcionavam sem problemas antes da integração com o Buildkite. Documentamos todos os comandos necessários para construir as imagens marcadas, enviá-las para o registro, puxá-las para baixo e executar os testes de acordo com os valores das variáveis de ambiente.
Etapa 5: Integração com o CICD
Depois que estabelecemos os comandos funcionais do Docker e nossos testes foram executados com sucesso em um contêiner do Docker em diferentes ambientes, começamos a integrar com o Buildkite, nosso provedor CICD.
A Buildkite forneceu maneiras de executar etapas em um arquivo .yml em nossas máquinas da AWS com scripts Bash e variáveis de ambiente definidas por meio do código ou da interface do usuário de configurações do Buildkite para o pipeline do nosso repositório.
O Buildkite também nos permitiu acionar esse pipeline de teste de nosso pipeline de implantação principal com variáveis de ambiente exportadas e reutilizaríamos essas etapas de teste para outros pipelines de teste isolados que seriam executados em um cronograma para nosso controle de qualidade monitorar e analisar.
Em alto nível, nossos pipelines Buildkite de teste para WebdriverIO e Cypress posteriores compartilharam as seguintes etapas semelhantes:
- Configure as imagens do Docker . Crie, marque e envie as imagens do Docker necessárias para os testes para o registro para que possamos descarregá-las em uma etapa posterior.
- Execute os testes com base nas configurações de variáveis de ambiente . Puxe para baixo as imagens do Docker marcadas para a compilação específica e execute os comandos adequados em um ambiente implantado para executar conjuntos de testes selecionados das variáveis de ambiente definidas.
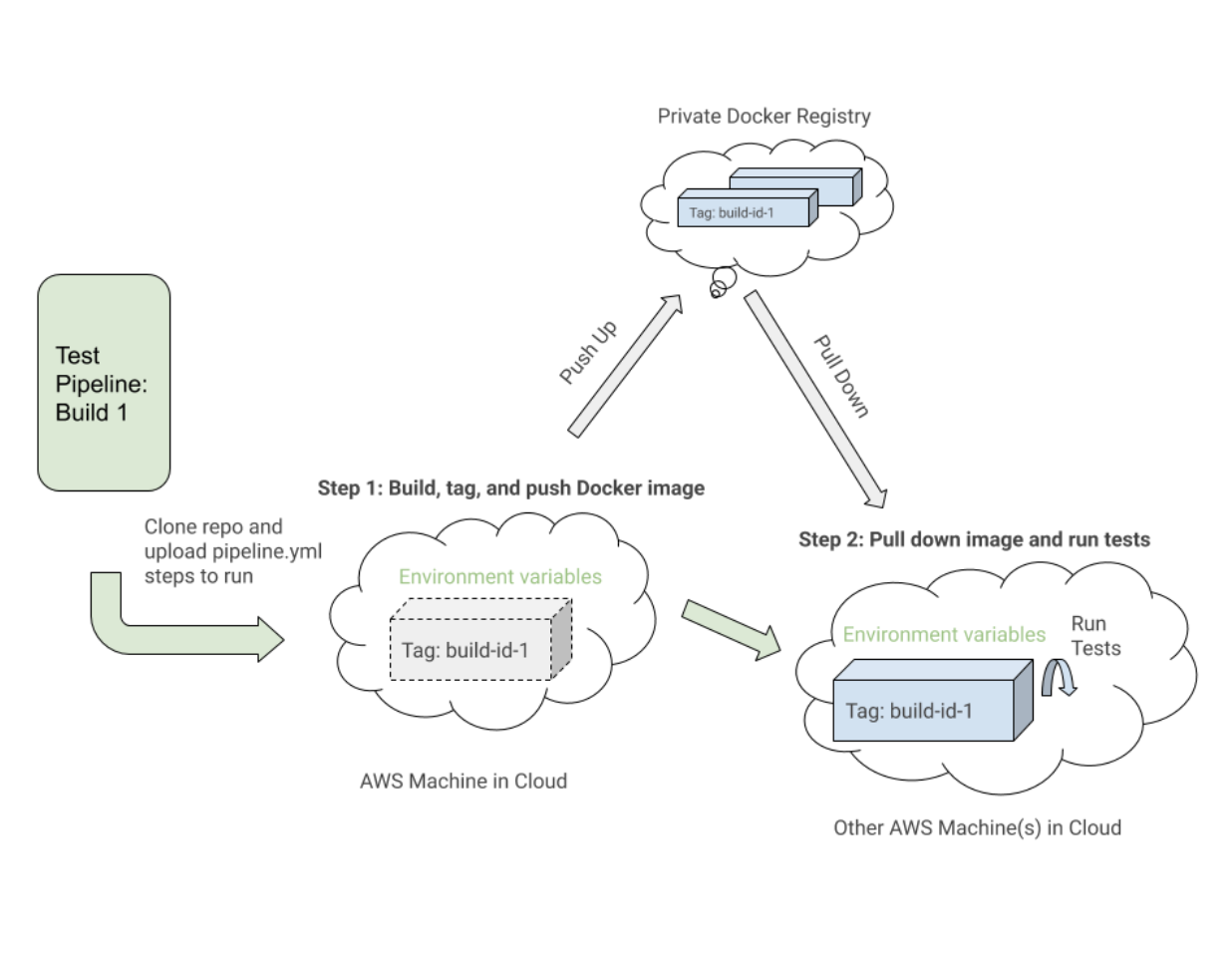
Aqui está um exemplo próximo de um arquivo pipeline.uitests.yml que demonstra a configuração das imagens do Docker na etapa “Build UITests Docker Image” e a execução dos testes na etapa “Run Webdriver tests against Chrome”:
Uma coisa a notar é a primeira etapa, “Build UITests Docker Image”, e como ele configura as imagens do Docker para o teste. Ele usou o comando de build do Docker Compose para compilar o serviço uitests com todo o código de teste do aplicativo e o marcou com a variável de ambiente latest e ${VERSION} para que possamos eventualmente extrair essa mesma imagem com a tag apropriada para esta compilação em um futuro degrau.
Cada etapa pode ser executada em uma máquina diferente na nuvem AWS em algum lugar, portanto, as tags identificam exclusivamente a imagem para a execução específica do Buildkite. Depois de marcar a imagem, enviamos a imagem mais recente e com a versão marcada para nosso registro privado do Docker para ser reutilizada.
Na etapa "Executar testes do Webdriver no Chrome", retiramos a imagem que construímos, marcamos e enviamos na primeira etapa e iniciamos os serviços Selenium Hub, Chrome e testes. Com base em variáveis de ambiente como $UITESTENV e $UITESTSUITE , escolheríamos o tipo de comando a ser executado como npm run uitest: e os conjuntos de teste a serem executados para essa compilação específica do Buildkite, como --suite $UITESTSUITE .
Essas variáveis de ambiente seriam definidas por meio das configurações de pipeline do Buildkite ou seriam acionadas dinamicamente a partir de um script Bash que analisaria um campo de seleção do Buildkite para determinar quais suítes de teste executar e em qual ambiente.
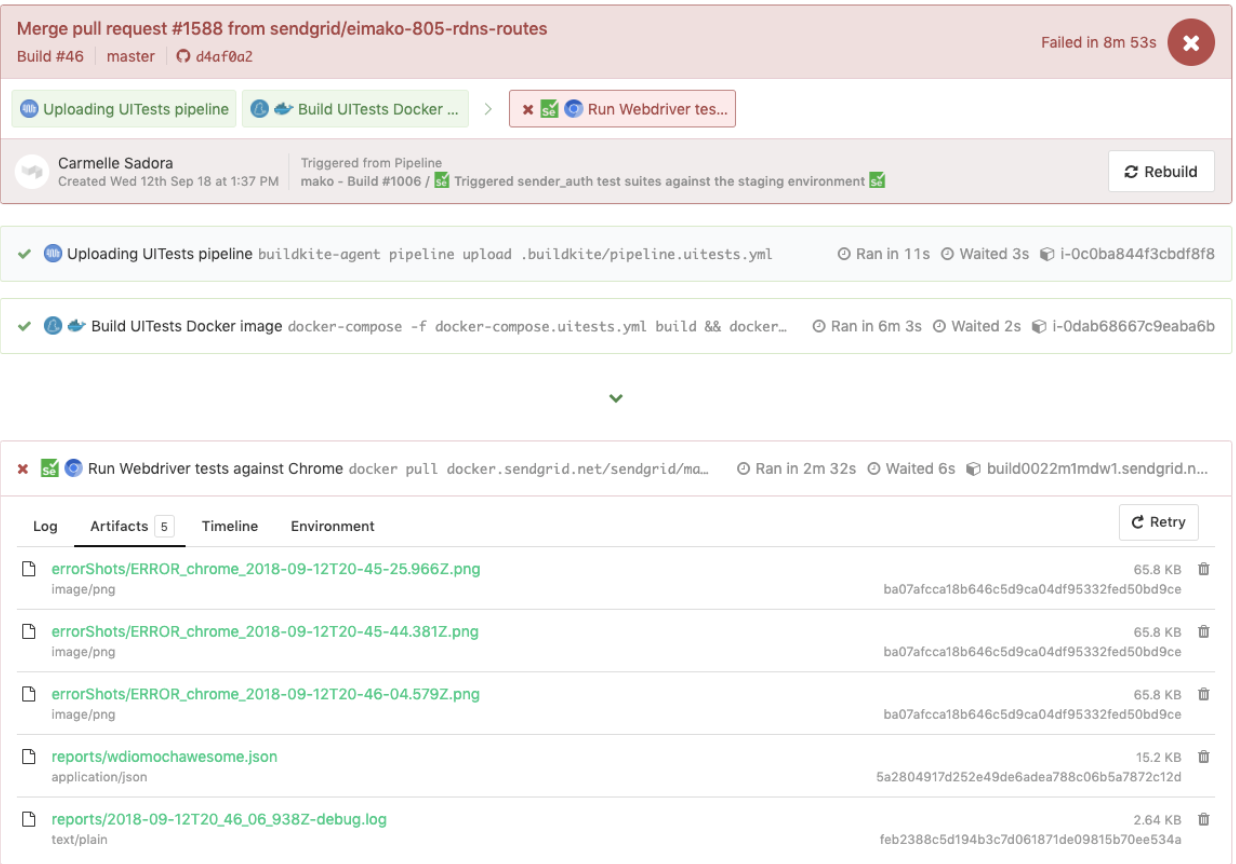
Aqui está um exemplo de testes WebdriverIO acionados em um pipeline de testes dedicado, que também reutilizou o mesmo arquivo pipeline.uitests.yml , mas com variáveis de ambiente definidas onde o pipeline foi acionado. Esta compilação falhou e teve capturas de tela de erro para que possamos dar uma olhada na guia Artifacts e a saída do console na guia Logs . Lembre-se dos artifact_paths no pipeline.uitests.yml (https://gist.github.com/alfredlucero/71032a82f3a72cb2128361c08edbcff2#file-pipeline-uitests-yml-L38), configurações de capturas de tela para `mochawesome` no `wdio.conf.js ` (https://gist.github.com/alfredlucero/4ee280be0e0674048974520b79dc993a#file-wdio-conf-js-L39), e montagem dos volumes no serviço `uitests` no `docker-compose.utests.yml` (https://gist.github.com/alfredlucero/d2df4533a4a49d5b2f2c4a0eb5590ff8#file-docker-compose-yml-L32)?
Conseguimos conectar as capturas de tela para serem acessíveis por meio da interface do usuário do Buildkite para fazer o download diretamente e ver imediatamente para ajudar nos testes de depuração, conforme mostrado abaixo.
Outro exemplo de testes do WebdriverIO em execução em um pipeline separado em um agendamento para uma página específica usando o arquivo pipeline.uitests.yml , exceto com variáveis de ambiente já configuradas nas configurações de pipeline do Buildkite, é exibido abaixo.
É importante observar que cada provedor de CICD tem diferentes funcionalidades e maneiras de integrar etapas em algum tipo de processo de implantação ao mesclar um novo código, seja por meio de arquivos .yml com sintaxe específica, configurações de GUI, scripts Bash ou qualquer outro meio.
Quando mudamos do Jenkins para o Buildkite, melhoramos drasticamente a capacidade das equipes de definir seus próprios pipelines em suas respectivas bases de código, paralelizando etapas em máquinas de dimensionamento sob demanda e utilizando comandos mais fáceis de ler.
Independentemente do provedor CICD que você pode usar, as estratégias de integração dos testes serão semelhantes na configuração das imagens do Docker e na execução dos testes com base em variáveis de ambiente para portabilidade e flexibilidade.
Trocas com WebdriverIO
Depois de converter um número considerável de testes personalizados da solução Ruby Selenium para testes WebdriverIO e integrar com Docker e Buildkite, melhoramos em algumas áreas, mas ainda sentimos dificuldades semelhantes ao sistema antigo que nos levou à próxima e última parada com Cypress para nossa solução de teste E2E.
Aqui está uma lista de alguns dos profissionais que encontramos em nossas experiências com o WebdriverIO em comparação com a solução Ruby Selenium personalizada:
- Os testes foram escritos puramente em JavaScript ou TypeScript em vez de Ruby . Isso significou menos alternância de contexto entre linguagens e menos tempo gasto reaprender Ruby toda vez que escrevíamos testes E2E.
- Colocamos testes com código de aplicativo em vez de em um repositório compartilhado Ruby. Não nos sentimos mais dependentes da falha dos testes de outras equipes e assumimos uma propriedade mais direta dos testes E2E para nossos recursos em nossos repositórios.
- Apreciamos a opção de teste entre navegadores . Com o WebdriverIO, pudemos realizar testes em diferentes recursos ou navegadores, como Chrome, Firefox e IE, embora nos concentrássemos principalmente em executar nossos testes no Chrome, já que mais de 80% de nossos usuários visitaram nosso aplicativo por meio do Chrome.
- Consideramos a possibilidade de integração com serviços de terceiros . A documentação do WebdriverIO explicou como integrar-se a serviços de terceiros, como BrowserStack e SauceLabs, para ajudar a cobrir nosso aplicativo em todos os dispositivos e navegadores.
- Tivemos a flexibilidade de escolher nosso próprio executor de testes, repórter e serviços . O WebdriverIO não era prescritivo com o que usar, então cada equipe tomou a liberdade de decidir se deveria ou não usar coisas como Mocha e Chai ou Jest e outros serviços. Isso também pode ser interpretado como um contra, pois as equipes começaram a se desviar da configuração umas das outras e exigiu uma quantidade considerável de tempo para experimentar cada uma das opções para escolhermos.
- A API do WebdriverIO, a CLI e a documentação eram úteis o suficiente para escrever testes e integrar-se ao Docker e ao CIC D. Poderíamos ter muitos arquivos de configuração diferentes, agrupar especificações, executar testes por meio da linha de comando e escrever testes seguindo o padrão de objeto de página. No entanto, a documentação poderia ser mais clara e tivemos que investigar muitos bugs estranhos. Mesmo assim, conseguimos converter nossos testes da solução Ruby Selenium.
Fizemos progressos em muitas áreas que não existiam na solução Ruby Selenium anterior, mas encontramos muitos obstáculos que nos impediram de usar o WebdriverIO, como o seguinte:
- Como o WebdriverIO ainda era baseado em Selenium , experimentamos muitos tempos limite, travamentos e bugs estranhos, lembrando-nos de flashbacks negativos com nossa antiga solução Ruby Selenium. Às vezes, nossos testes travavam completamente quando selecionávamos muitos elementos na página e os testes eram executados mais lentamente do que gostaríamos. Tivemos que descobrir soluções alternativas para muitos problemas do Github ou evitar certas metodologias ao escrever testes.
- A experiência geral do desenvolvedor foi abaixo do ideal . A documentação forneceu uma visão geral de alto nível dos comandos, mas não exemplos suficientes para explicar todas as maneiras de usá-lo. Evitamos escrever testes E2E com Ruby e finalmente conseguimos escrever testes em JavaScript ou TypeScript, mas a API WebdriverIO era um pouco confusa de se lidar. Alguns exemplos comuns foram o uso de
$vs.$$para elementos singulares versus plurais,$('...').waitForVisible(9000, true)para esperar que um elemento não fique visível e outros comandos não intuitivos. Nós experimentamos muitos seletores esquisitos e tivemos que explicitamente$(...).waitForVisible()para tudo. - Os testes de depuração eram extremamente dolorosos e tediosos para desenvolvedores e QAs. Whenever tests failed, we only had screenshots, which would often be blank or not capturing the right moment for us to deduce what went wrong, and vague console error messages that did not point us in the right direction of how to solve the problem and even where the issue occurred. We often had to re-run the tests many times and stare closely at the Chrome browser running the tests to hopefully put things together as to where in the code our tests failed. We used things like
browser.debug()but it often did not work or did not provide enough information. We gradually gathered a bunch of console error messages and mapped them to possible solutions over time but it took lots of pain and headache to get there. - WebdriverIO tests were tough to set up with Docker . We struggled with trying to incorporate it into Docker as there were many tutorials and ways to do things in articles online, but it was hard to figure out a way that worked in general. Hooking up 2 to 3 services together with all these configurations led to long trial and error experiments and the documentation did not guide us enough in how to do that.
- Choosing the test runner, reporter, assertions, and services demanded lots of research time upfront . Since WebdriverIO was flexible enough to allow other options, many teams had to spend plenty of time to even have a solid WebdriverIO infrastructure after experimenting with a lot of different choices and each team can have a completely different setup that doesn't transfer over well for shared knowledge and reuse.
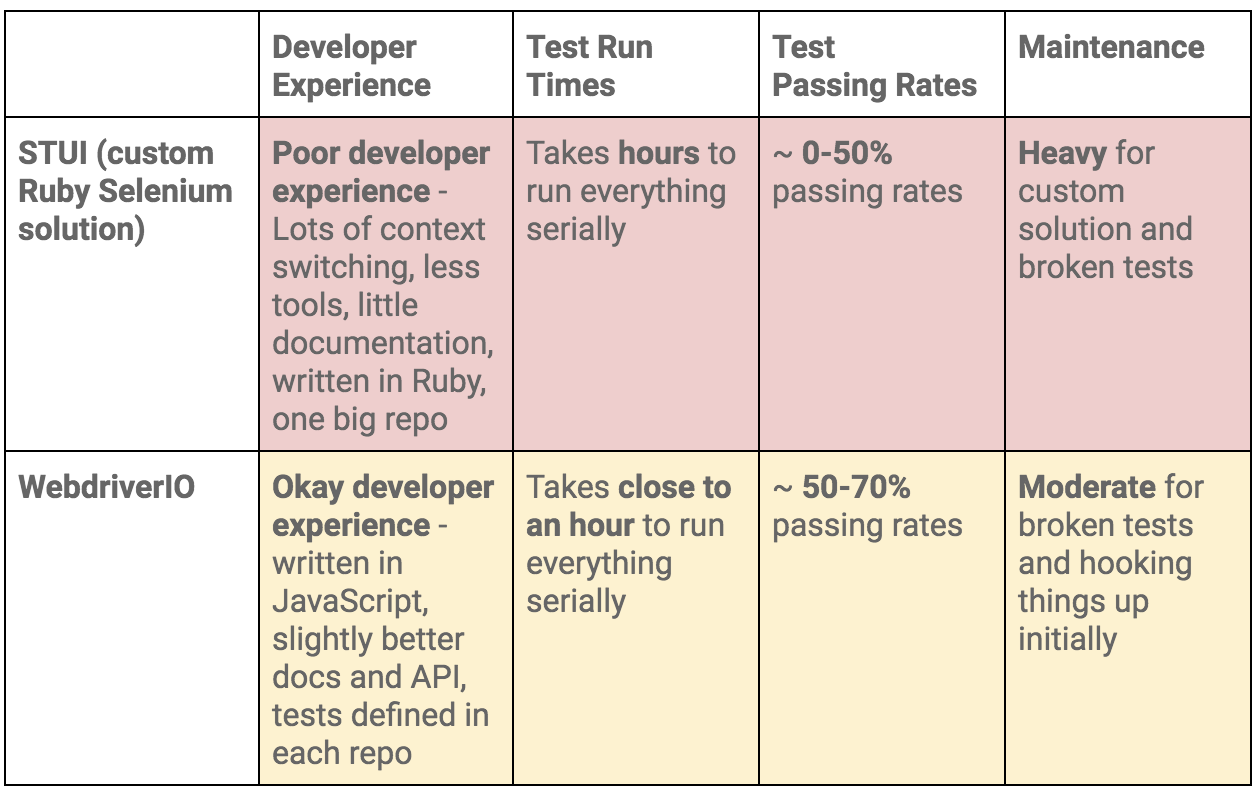
To summarize our WebdriverIO and STUI comparison, we analyzed the overall developer experience (related to tools, writing tests, debugging, API, documentation, etc.), test run times, test passing rates, and maintenance as displayed in this table:
Moving On to Cypress
At the end of the day, our WebdriverIO tests were still flaky and tough to maintain. More time was still spent debugging tests in dealing with weird Selenium issues, vague console errors, and somewhat useful screenshots than actually reaping the benefits of seeing tests fail for when the backend or frontend encountered issues.
We appreciated cross-browser testing and implementing tests in JavaScript, but if our tests could not pass consistently without much headache for even Chrome, then it became no longer worth it and we would then simply have a STUI 2.0.
With WebdriverIO we still strayed from the crucial aspect of providing a way to write consistent, debuggable, maintainable, and valuable E2E automation tests for our frontend applications in our original goal. Overall, we learned a lot about integrating with Buildkite and Docker, using page objects, and outlining tests in a structured way that will transfer over to our final solution with Cypress.
If we felt it was necessary to run our tests in multiple browsers and against various third-party services, we could always circle back to having some tests written with WebdriverIO, or if we needed something fully custom, we would revisit the STUI solution.
Ultimately, neither solution met our main goal for E2E tests, so follow us on our journey in how we migrated from STUI and WebdriverIO to Cypress in part 2 of the blog post series.