
Apache Apex – Uma introdução
Publicados: 2015-12-29O Apache Hadoop tornou-se uma estrutura de software de fato para computação confiável, escalável, distribuída e em grande escala. Desde a sua criação, o Hadoop tem sido a estrutura de primeira escolha para processamento em lote. De grandes bancos a gigantes do varejo online, todos estão usando o Hadoop para geração de relatórios periódicos, cálculos e muitos outros casos de uso. Normalmente, esses casos de uso são processos orientados a lotes e exigem algumas horas antes de obtermos significado dos dados. O mundo rápido de hoje exige significado ou ações de dados brutos quase no momento em que são gerados. Isso levou a um conceito de processamento de fluxo. Embora o Hadoop não seja originalmente considerado adequado para processamento de fluxo, a invenção do YARN (Hadoop 2.0) o tornou um bom candidato a ele. Atualmente, existem várias estruturas de processamento de fluxo no ecossistema Hadoop e o Apex é um novo que entra nesse mercado lotado.
O que é Apache Apex?
O Apache Apex é uma plataforma nativa baseada em YARN que ajuda o desenvolvedor de aplicativos a escrever aplicativos orientados a fluxo, bem como orientados a lote. Ele foi projetado para processar dados em movimento, de maneira distribuída, de alto desempenho e tolerante a falhas. A cobertura disso é a API fácil, que permite que os usuários escrevam seu código java com conhecimento limitado de processamento de fluxo.
O Apex é baseado em especificações funcionais e operacionais separadas, em vez de combiná-las. Isso faz com que os desenvolvedores de aplicativos se concentrem em escrever Funções Definidas pelo Usuário sem ter que pensar em como elas operarão em ambiente distribuído.
O Apache Apex possui uma rica biblioteca de funções comumente usadas. Estes são adicionados como parte da biblioteca Apache Apex-Malhar. Esta biblioteca possui operadores para acessar diferentes sistemas de arquivos, bancos de dados, filas de mensagens. A comunidade está agregando o dia a dia das operadoras facilitando a vida dos desenvolvedores de aplicativos.
Quais são os principais blocos do Apache Apex?
A arquitetura do Apex é muito simples. O Apex tem Malhar, uma biblioteca de operadores e mecanismo principal para trabalhar. O núcleo do Apex pode ser descrito da seguinte forma, eles são frequentemente referidos como blocos principais do Apache Apex.
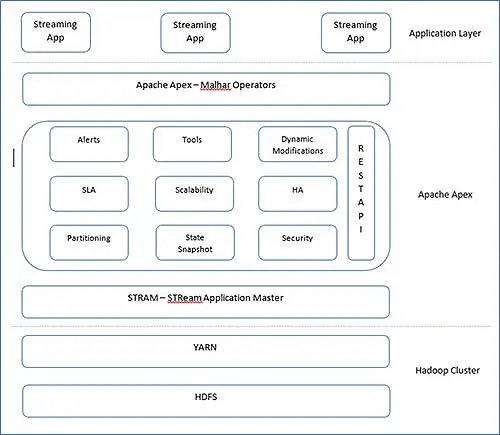
Você pode separar claramente as camadas e obter uma visão geral onde ela se encaixa. Vejamos informações sobre esses blocos.
- StrAM ( Mestre de Aplicação de Fluxo)
StrAM é um mestre de aplicativos YARN. Sua responsabilidade inclui o lançamento de aplicativos de fluxo, alocação de recursos, agendamento de DAGs lógicos. Junto com essas operações YARN, StrAM inicializa operadores, fluxos. StrAM também reúne estatísticas de seus filhos. - Instantâneo do estado
As estruturas de processamento de fluxo não podiam perder os resultados processados. Além disso, eles devem saber quanto processaram para processar corretamente os registros após a recuperação da falha. Portanto, periodicamente, a indicação de verificação é importante no processamento de fluxo. No Apex, o StrAM acompanha a marcação de verificação e, no limite do operador, a marcação de verificação é realizada periodicamente no HDFS. - API REST
StrAM é o ponto de acesso para a API REST. Ferramentas externas podem acessar essa API REST e se integrar com qualquer aplicativo externo. - Ferramentas
Apex fornece CLI para iniciar e monitorar aplicativos Apex. Mesmo nós podemos construir o nosso próprio com a ajuda de APIs REST. Junto com a CLI, o aplicativo pode configurar com scripts de configuração estática para inicialização automatizada. - Particionamento
- Modificações dinâmicas
- Análise de SLA
O Apache Apex faz análises de SLA por conta própria periodicamente. Ele faz análises de latência, gargalo e throughput e adiciona mais recursos para atender ao SLA configurado. - Segurança
- Alta disponibilidade
O Apache Apex utiliza a funcionalidade de reinicialização do YARN e reinicia a partir do último estado de verificação. - Malhar
Apache Apex –Malhar é uma biblioteca de operadores com vários operadores. Esses operadores são classificados em - Operadores de entrada/saída -
Sob esta categoria, atualmente Malhar tem operadores para ler/escrever de - Sistema de arquivo
- RDBMS
- Armazenamentos NoSQL
- Filas de mensagens
- Bancos de dados na memória
- Mídia social
- Operadores de Computação -
- Correspondência de padrões
- Estatísticas e matemática
- Aprendizado de máquina
- Analisadores
- Mídia social
- Servidores de buffer
O Apex fornece particionamento baseado em chaves e balanceamento de carga dinâmico. Até mesmo o usuário pode definir seu próprio esquema de particionamento.
O Apache Apex possui esse recurso muito útil e exclusivo. Ele suporta mudança lógica DAG, mudança de plano de execução física.
O Apex oferece suporte ao Kerberos. Subjacente ao cluster Hadoop seguro, ele pode acessar com integração Kerberos inerente.
Malhar tem muitos operadores que ajudarão na implementação real da lógica de negócios. Esta biblioteca tem
Os servidores de buffer ficam no limite de cada operador. No caso de dados, os servidores de buffer do operador local podem estar após sequências de operadores. O principal objetivo deles é manter os dados temporários nas bordas antes de encaminhar para o próximo. Eles têm um papel importante quando o nó é recuperado de uma falha. Os servidores de buffer carregam dados do último estado de verificação para repetir

O que é o modelo de programação do aplicativo Apex?
Isso apresenta uma estrutura rica e a biblioteca Malhar, o que significa que os desenvolvedores de aplicativos precisam apenas conectar os operadores e iniciar o aplicativo. Portanto, sua aplicação nada mais é do que uma sequência de operadores.
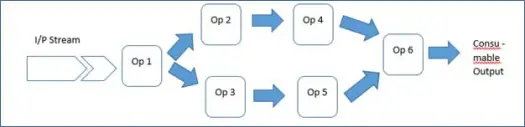
É assim que o framework rico facilita a vida do desenvolvedor. Então, vamos ver como esse aplicativo de demonstração é executado
Demonstração do Apache Apex
Então vamos começar com ' Hello World of Big Data J', uma pequena demonstração de contagem de palavras usando Apache Apex.
Configurando o Apache Apex
Para executar esta demonstração, precisamos configurar o Apex. Você pode instalar o Apache Apex em seu cluster existente ou há uma maneira simples de experimentar, você pode baixar a pré-instalação da sandbox VM do site DataTorrent aqui. Para esta demonstração, usaremos a VM pré-instalada.
Console de interface do usuário do Apex passo a passo
O Apex vem com um console de interface do usuário de design muito intuitivo e bonito, que você pode usar para iniciar, monitorar e gerenciar aplicativos. Ele inclui várias estatísticas sobre os diferentes componentes que são implantados.
Depois, você baixou a sandbox VM, descompacte-a e carregue-a no seu VM player favorito (eu uso o VMWare VM player). Todos os softwares e ferramentas necessários para executar o Apex já estão configurados nesta VM e todos os scripts de inicialização estão configurados para serem executados na inicialização do SO. Portanto, quando sua VM estiver ativa, você terá uma instância em execução do Apache Apex. Agora, para visualizar o console, basta clicar em http://locahost:9090 no seu navegador favorito e fazer login no console. Nome de usuário padrão: a senha para VM de sandbox é dtadmin: dtadmin. Você verá o console como abaixo
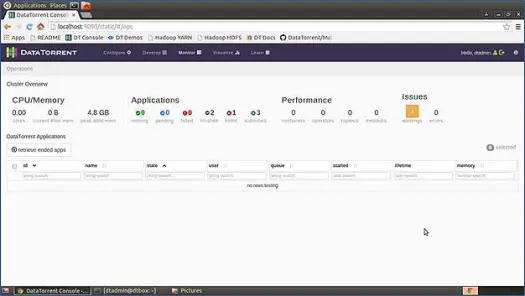
Esta página nos fornece uma visão geral completa de todo o sistema, como uso de CPU e memória, aplicativos, desempenho, problemas etc.
Para implantar um aplicativo, vá para a guia Desenvolver na parte superior da página.
Aqui você pode implantar seus pacotes de aplicativos e gerenciar os esquemas de tupla para os dados dentro do Apex.
O Apex fornece um número de aplicativos prontos para uso, que você pode ver listados abaixo:
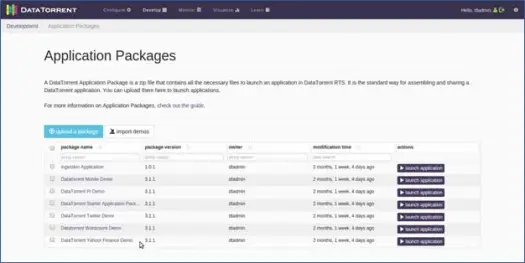
Demonstração de contagem de palavras
Agora, vamos iniciar o aplicativo wordcount. Você pode fazer isso clicando na opção de inicialização do aplicativo ao lado do DataTorrent Wordcount Demo. Em seguida, você pode fornecer um aplicativo diferente e modificar os detalhes de configuração, se necessário (não faremos isso, pois a maioria dos padrões funciona bem, vamos apenas modificar o nome do aplicativo para “MyWordCountDemo”). Você verá uma mensagem informando que o aplicativo foi implantado com sucesso com um link para o aplicativo. Clique nesse link.

Isso abre uma nova página. Aguarde alguns segundos até que o status do aplicativo mude de Aceito para Em execução. Agora você verá uma página cheia de várias estatísticas e informações. As próximas duas capturas de tela os retratam.
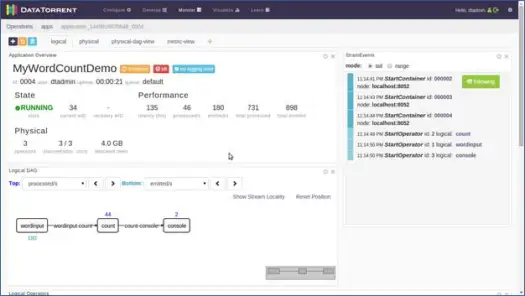
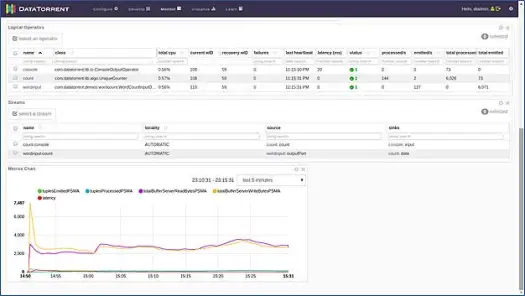
Esta página nos mostra várias informações como visão lógica, física e métrica do aplicativo, juntamente com estatísticas de várias tuplas/registros que são processados pelo aplicativo a cada segundo. Mostra a representação gráfica das tuplas que são emitidas e as latências etc.
Você pode clicar em qualquer operador lógico, inspecionar seus registros e até mesmo gravar uma amostra. Vamos fazer isso para o operador do console. Clique no operador do console e você obterá informações detalhadas sobre o operador conforme abaixo:
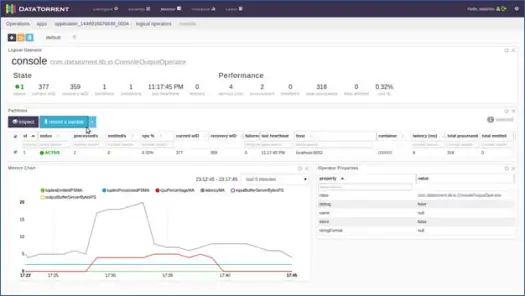
Em seguida, selecione uma das partições e clique em gravar uma amostra.
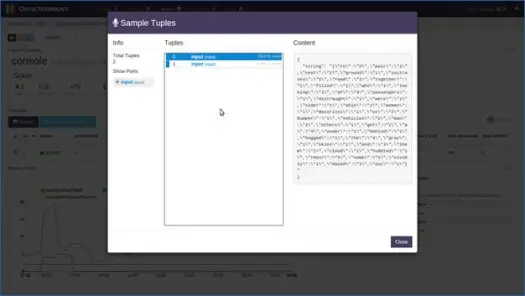
Após alguns segundos, você verá as tuplas preenchidas, clique na tupla para visualizar seu conteúdo. Como você pode ver pelo conteúdo, o aplicativo executou a contagem de palavras nos dados baseados em janelas e havia 2 “para”, 4 “o”, 4 “a” etc. na 0ª tupla de entrada para esta janela. Agora você pode parar o aplicativo clicando em “Shutdown” ou “Kill” na página principal do aplicativo.
É isso, implantamos e executamos com sucesso o aplicativo wordcount.
Conclusão
Então essa foi a introdução de uma nova ferramenta de Streaming – Apache Apex e a execução bem-sucedida de um aplicativo no Apache Apex. O Apache Apex tem muitos recursos salientes que lhe dão uma vantagem sobre outros frameworks existentes que abordarei em posts subsequentes.