
Apache Spark: estrela brilhante no firmamento de big data.
Publicados: 2015-09-24- Recomendando milhões de produtos para os clientes certos.
- Acompanhando o histórico de pesquisa e oferecendo preços com desconto para viagens aéreas.
- Comparar as habilidades técnicas da pessoa e sugerir adequadamente as pessoas para se conectar em seu campo.
- Compreender padrões em bilhões de objetos móveis, torres de rede e transações de chamadas e calcular otimizações de rede de telecomunicações ou encontrar brechas na rede.
- Estudando milhões de recursos de sensores e analisando falhas em redes de sensores.
Os dados subjacentes que precisam ser usados para obter resultados corretos para todas as tarefas acima são comparativamente muito grandes. Ele não pode ser tratado de forma eficiente (em termos de espaço e tempo) por sistemas tradicionais.
Todos esses são cenários de big data.
Para coletar, armazenar e fazer cálculos neste tipo de dados volumosos, precisamos de um sistema especializado de computação em cluster. O Apache Hadoop resolveu esse problema para nós.
Oferece um sistema de armazenamento distribuído (HDFS) e plataforma de computação paralela (MapReduce).
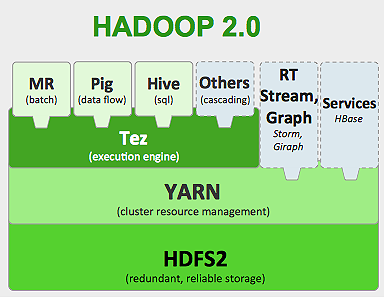
A estrutura do Hadoop funciona como abaixo:
- Divide grandes arquivos de dados em pedaços menores para serem processados por máquinas individuais (Distributing Storage).
- Divide o trabalho mais longo em tarefas menores para serem executadas de forma paralela (Computação Paralela).
- Lida com falhas automaticamente.
Limitações do Hadoop
O Hadoop possui ferramentas especializadas em seu ecossistema para realizar diferentes tarefas. Portanto, se você deseja executar um ciclo de vida de ponta a ponta de um aplicativo, precisa usar várias ferramentas. Por exemplo, para consultas SQL , você usará, hive/pig , para fontes de streaming , você deve usar o streaming embutido do Hadoop ou o Apache Storm (que não faz parte do ecossistema do Hadoop) ou para algoritmos de aprendizado de máquina , você deve usar o Mahout . Integrar todos esses sistemas para construir um único caso de uso de pipeline de dados é uma tarefa e tanto.
No trabalho MapReduce ,
- Todas as saídas de tarefas de mapa são despejadas em discos locais (ou HDFS).
- O Hadoop mescla todos os arquivos spill em um arquivo maior que é classificado e particionado de acordo com o número de redutores.
- E reduzir as tarefas tem que carregá-lo novamente na memória.
Esse processo torna o trabalho mais lento, causando E/S de disco e E/S de rede. Isso também torna o Mapreduce inadequado para processamento iterativo, onde você precisa aplicar algoritmos de aprendizado de máquina ao mesmo grupo de dados repetidamente.
Entre no mundo do Apache Spark:
O Apache Spark é desenvolvido na UC Berkeley AMPLAB em 2009 e em 2010 tornou-se o projeto de código aberto de maior contribuição do Apache até a data.
O Apache Spark é um sistema mais generalizado , onde você pode executar trabalhos em lote e streaming ao mesmo tempo. Ele substitui seu predecessor MapReduce em velocidade, adicionando recursos para processar dados mais rapidamente na memória. Também é mais eficiente em disco. Ele aproveita o processamento de memória usando sua unidade de dados básica RDD (Resilient Distributed Dataset). Eles mantêm o maior número possível de conjuntos de dados na memória para o ciclo de vida completo do trabalho, portanto, economizam em E/S de disco. Alguns dados podem ser derramados no disco após os limites superiores da memória.
O gráfico abaixo mostra o tempo de execução em segundos do Apache Hadoop e do Spark para calcular a regressão logística. O Hadoop levou 110 segundos enquanto o Spark terminou o mesmo trabalho em apenas 0,9 segundos.
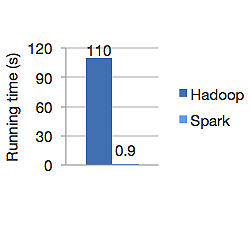
O Spark não armazena todos os dados na memória. Mas se os dados estiverem na memória, ele fará melhor uso do cache LRU para processá-los mais rapidamente. É 100x mais rápido ao computar dados na memória e ainda mais rápido em disco do que o Hadoop.
O modelo de armazenamento de dados distribuído do Spark, conjuntos de dados distribuídos resilientes (RDD), garante a tolerância a falhas que, por sua vez, minimiza a E/S da rede. Spark paper diz:

"Os RDDs atingem a tolerância a falhas por meio de uma noção de linhagem: se uma partição de um RDD for perdida, o RDD terá informações suficientes sobre como foi derivado de outros RDDs para poder reconstruir apenas essa partição."
Portanto, você não precisa replicar dados para obter tolerância a falhas.
No Spark MapReduce, a saída dos mapeadores é mantida no cache de buffer do sistema operacional e os redutores a puxam para o lado e a gravam diretamente na memória, ao contrário do Hadoop, onde a saída é derramada no disco e a lê novamente.
O cache de memória do Spark o torna adequado para algoritmos de aprendizado de máquina em que você precisa usar os mesmos dados repetidamente. O Spark pode executar trabalhos complexos, pipelines de dados de várias etapas usando Direct Acyclic Graph (DAGs).
Spark é escrito em Scala e roda em JVM (Java Virtual Machine). O Spark oferece APIs de desenvolvimento para linguagens Java, Scala, Python e R. O Spark é executado no Hadoop YARN, Apache Mesos e possui seu próprio gerenciador de cluster autônomo.
Em 2014 garantiu o 1º lugar no recorde mundial de classificação de dados de 100 TB (1 trilhão de registros) benchmark em apenas 23 minutos, enquanto o recorde anterior do Hadoop pelo Yahoo era de cerca de 72 minutos. Isso prova que os dados classificados são 3 vezes mais rápidos e com 10 vezes menos máquinas. Toda a classificação aconteceu no disco (HDFS), sem realmente usar o recurso de cache na memória do Spark.
Ecossistema de faísca
O Spark destina-se a fazer análises avançadas de uma só vez, oferecendo os seguintes componentes:
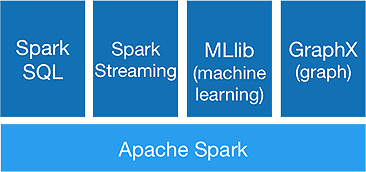
1. Núcleo de faísca:
A API central do Spark é a base da estrutura Apache Spark, que lida com agendamento de tarefas, distribuição de tarefas, gerenciamento de memória, operações de E/S e recuperação de falhas. A principal unidade de dados lógicos no spark é chamada de RDD (Resilient Distributed Dataset), que armazena dados de forma distribuída para serem processados em paralelo posteriormente. Ele calcula as operações preguiçosamente. Portanto, a memória não precisa ser ocupada o tempo todo, e outros trabalhos podem utilizá-la.
2.Spark SQL:
Ele oferece recursos de consulta interativa com baixa latência. A nova API DataFrame pode conter dados estruturados e semiestruturados e permitir que todas as operações e funções SQL façam cálculos.
3. Transmissão de faísca:
Ele fornece APIs de streaming em tempo real , que coletam e processam dados em micro lotes.
Ele usa Dstreams, que nada mais é do que uma sequência contínua de RDDs , para calcular a lógica de negócios nos dados recebidos e gerar resultados imediatamente.
4.MLlib :
É a biblioteca de aprendizado de máquina do Spark (quase 9 vezes mais rápido que o Mahout) que fornece aprendizado de máquina, bem como algoritmos estatísticos como classificação, regressão, filtragem colaborativa etc.
5.GráficoX :
A API GraphX fornece recursos para lidar com gráficos e realizar cálculos paralelos a gráficos. Inclui algoritmos de gráfico como PageRank e várias funções para analisar gráficos.
O Spark marcará o fim da Era Hadoop?
Spark ainda é um sistema jovem, não tão maduro quanto o Hadoop. Não existe uma ferramenta para NOSQL como o HBase. Considerando o alto requisito de memória para processamento de dados mais rápido, você não pode realmente dizer que ele roda em hardware comum. O Spark não possui sistema de armazenamento próprio. Ele depende do HDFS para isso.
Portanto, o Hadoop MapReduce ainda é bom para determinados trabalhos em lote, que não incluem muito pipeline de dados.
“A nova tecnologia nunca substitui completamente a antiga; ambos preferem coexistir.”
Conclusão
Neste blog, analisamos por que você precisa de uma ferramenta como o Spark, o que torna o sistema de computação em cluster mais rápido e seus principais componentes. Na próxima parte, aprofundaremos os RDDs, transformações e ações da API principal do Spark.