
Café da manhã com um bilhão de e-mails
Publicados: 2020-02-05Uma Black Friday tranquila é tudo o que pedimos
No momento em que tomei meu café da manhã por volta das 8h do horário padrão do Pacífico (PST) todos os dias durante o fim de semana da Black Friday, o Twilio SendGrid já havia processado mais de 1 bilhão de e-mails conforme calculado no horário padrão do leste dos EUA (EST).
Analisando as estatísticas, processamos mais de 16,5 bilhões de e-mails do Dia de Ação de Graças até a Cyber Monday e mais de 22,3 bilhões na semana que começa na terça-feira antes do Dia de Ação de Graças. São números muito bons para o negócio. Do ponto de vista de uma organização de engenharia, fazer isso sem nenhum alerta ou qualquer experiência degradada do cliente foi incrivelmente satisfatório.
Recomendo a leitura deste artigo do blog, Scaling Our Infrastructure for 4+ Billion Emails in a Single Day , escrito por minha colega Sara Saedinia, que fala sobre a importância de operar sem problemas nessa escala para nossos negócios e para as empresas que dependem de nós. Aqui, vou me concentrar em nossos preparativos que tornaram o fim de semana mais crítico do ano para nossos clientes de e-mail o mais tranquilo até agora.
Como tornamos este fim de semana perfeito na Black Friday? Lidar com nossos maiores dias de envio requer planejamento diligente, vários testes de variação de região, dezenas de pessoas analisando dados e estreitando os ciclos de feedback à medida que validamos melhorias em nossos sistemas com base em observações de telemetria. Ainda temos mais automação e melhorias que faremos para garantir que continuemos a encantar nossos clientes e enviar as comunicações certas para os destinatários certos com rapidez.
Entendendo nosso negócio
O modelo de negócios do SendGrid exige que estejamos sempre ativos — não temos janelas de manutenção para aceitar e entregar correspondências. Nossos clientes precisam de um serviço confiável que aceite e entregue correspondências sem interrupção. Isso significa que todas as alterações de nossa infraestrutura, hardware e software, precisam ser feitas enquanto continuamos processando e entregando e-mails sem nenhum atraso perceptível.
O número de e-mails que processamos cresceu tremendamente nos últimos anos, como mostra o gráfico a seguir.
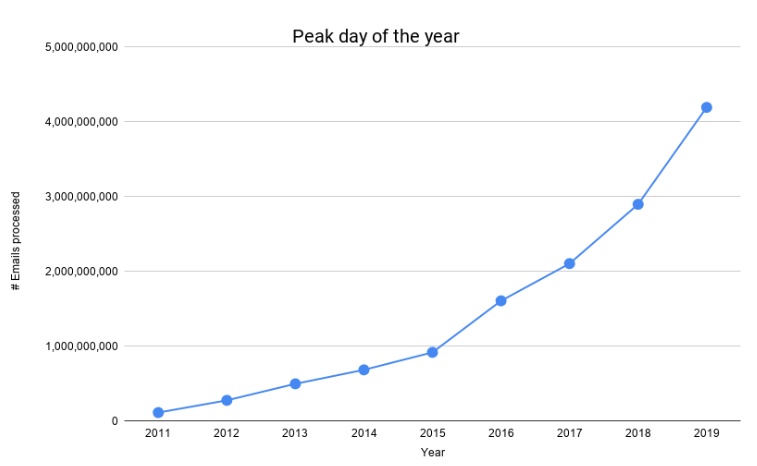
Tivemos nosso primeiro dia de 1B em meados de 2016 e tivemos nosso primeiro dia de 4B nesta Black Friday. Ou seja, um crescimento de 400% em menos de 4 anos. Para levar em conta nossa escala cada vez maior, manter nossos custos gerenciáveis e fornecer maior confiabilidade para nossos clientes, tivemos que reprojetar e evoluir nosso pipeline de processamento de correio.
Black Friday está chegando
As pessoas me perguntam: “Por que a Black Friday e a Cyber Monday são tão importantes para você?” Nesta Cyber Monday, processamos 45% mais e-mails do que o pico do ano anterior. A Black Friday é um dos eventos de varejo e gastos mais importantes dos Estados Unidos. Tradicionalmente, é o dia em que os varejistas estarão no preto (positivo líquido) para o ano. O marketing por e-mail e o uso de e-mails transacionais tornaram-se críticos para todas as empresas.
De varejistas a empresas que fornecem automação de marketing, ter problemas para entregar e-mails de forma confiável no fim de semana da Black Friday pode resultar em perda significativa de receita. Como resultado, este fim de semana é muitas vezes um fim de semana que define negócios para nós. Fazemos o possível para facilitar ao máximo nossos engenheiros, agentes de suporte, gerentes de sucesso do cliente, executivos e, o mais importante, para nossos clientes.
Preparando-se para a Black Friday
Então, como nos preparamos para a Black Friday? Compramos camisetas! (E fazer uma tonelada de trabalho.) Leia sobre como nos preparamos.
Membros do escritório Twilio SendGrid Irvine

Alguns dos membros do escritório Twilio SendGrid Denver.

Estatísticas
Vamos começar com algumas estatísticas:
- Processou mais de 4,1 bilhões de e-mails na Black Friday e mais de 4,2 bilhões de e-mails na Cyber Monday
- Processou mais de 16,5 bilhões de e-mails do Dia de Ação de Graças até a Cyber Monday
- Processou mais de 315 milhões de e-mails durante o horário de pico
- Black Friday e Cyber Monday, cada uma teve 8 horas sucessivas processando 220 milhões de e-mails ou mais
- Tudo isso com um tempo médio de entrega de e-mails de ponta a ponta em 1,9 segundos
- Em média, emitimos aproximadamente 5,5 eventos por mensagem. Com base nisso, nossos sistemas emitiram e processaram mais de 91 bilhões de eventos do Dia de Ação de Graças à Cyber Monday, 23B+ somente na Cyber Monday
Os desafios
Escala nunca antes vista : A escala que visamos testar deve corresponder à nossa carga de pico prevista. Quando fizemos nosso primeiro teste para a preparação do ano passado no início de abril, nosso volume médio durante a semana foi menos da metade de nossa previsão de pico. Nossos picos horários não eram nem metade do que estaríamos testando.
Gerenciando nossos ambientes : O e-mail é um fluxo de trabalho com estado: é necessário acompanhar o estado de uma mensagem. Assim, à medida que a mensagem se move pelo pipeline, rastreamos se ela é rejeitada ou adiada e evitamos a duplicação. Como tal, nosso pipeline de e-mail é uma nuvem híbrida e uma arquitetura local, e o dimensionamento automático não é uma solução mágica. Nosso desafio é maximizar a eficiência de nossos serviços de data center enquanto preparamos a capacidade para lidar com grandes picos de volume sem afetar o custo para os clientes.
A escala não é linear : nem todos os sistemas escalam linearmente. Como nossa escala prevista é muito maior do que quando começamos a testar, não podemos simplesmente calcular nossas necessidades de hardware por meio de um modelo matemático simples. Também é importante lembrar que escalar serviços cegamente sobrecarregaria dependências, e dependências como o banco de dados não escalam da mesma forma que nosso agente de transferência de correio (MTA).
Equilibrando nossos investimentos : À medida que continuamos inovando, garantindo que atendemos às necessidades dos clientes relacionadas à entrega de e-mails, entendemos que nossos recursos não fornecem nenhum valor a nossos clientes se não estiverem acessíveis e funcionando conforme necessário. Temos que encontrar um equilíbrio e investir adequadamente em testar, aprender, atualizar e melhorar nossos sistemas para serem confiáveis e resilientes em nossa escala. Fazer isso com eficiência nos permite continuar investindo em inovação.

Como o fizemos?
Fizemos isso juntos, como uma equipe. De braços dados, como dizemos. Nossos preparativos este ano, de abril a novembro, envolveram a participação de mais de 100 membros em muitas equipes. Modelar previsões de pico, definir critérios de observabilidade, aprender com nossas observações, projetar as mudanças necessárias, planejar e gerenciar requer várias habilidades de várias pessoas.
Confiamos um no outro enquanto nos mantemos honestos, mantendo o foco e cumprindo nossos objetivos.
Um processo eficaz e em constante aperfeiçoamento foi nosso amigo.
Planejamento
Temos três data centers para processar os e-mails dos clientes. Para planejar uma escala não alcançada, validamos que podemos lidar com nosso tráfego de pico projetado com apenas dois data centers disponíveis. Para atender ao nosso SLA de alta disponibilidade, nossa infraestrutura possui failover de região integrado. Isso significa que temos a capacidade de fazer failover de tráfego entre regiões.
Aproveitamos esse recurso com uma cadência frequente ao longo do ano como um procedimento operacional padrão e o aceleramos como parte de nossos esforços para demonstrar que somos capazes de atender aos volumes de pico da Black Friday/Cyber Monday, mantendo a qualidade do serviço. Se a telemetria do sistema se aproximar do limite de nosso objetivo de nível de serviço (SLO), poderemos aproveitar rapidamente várias regiões para retomar o estado nominal. Em seguida, aproveitamos a telemetria coletada para determinar onde precisamos fazer alterações.
Em um esforço paralelo, começamos a revisar e solidificar nossos Objetivos de Nível de Serviço (SLOs) que nos fornecem uma meta numérica precisa para a disponibilidade do sistema e nossos Indicadores de Nível de Serviço (SLIs), que nos fornecem a frequência de testes bem-sucedidos em nossos sistemas.
Observações, aprendizados e comunicação
Cada teste forneceu uma grande quantidade de informações. Um dos desafios que enfrentamos foi documentar e comunicar efetivamente as observações entre as equipes de teste rotativas e, em seguida, analisar os dados em vários sistemas. Embora tenhamos painéis de equipe padrão, cada membro pode ter algo específico que observa.
Começamos a fazer uma retrospectiva com as equipes de teste para analisar todas as informações técnicas despejadas para vários serviços gerenciados por várias equipes. Esses retros eram longos e, na maior parte da duração, eram úteis apenas para uma ou duas equipes por teste. Eventualmente, passamos a usar um Slack Thread para notas retrô, economizando 10s de horas humanas de tempo de reunião por teste.
Nossa equipe de gerenciamento de testes envolveu dois gerentes de engenharia, um arquiteto e um engenheiro sênior. Os gerentes foram fundamentais no planejamento e no gerenciamento de dependências, enquanto o pessoal mais técnico ajudou a processar e analisar as informações no nível do sistema de ponta a ponta.
Com base na análise das informações disponíveis, validamos iterativamente que nossos SLIs estavam em estrita conformidade com nossos SLOs. Ajustamos nossos alertas e tornamos alguns alertas críticos mais sensíveis para identificar com antecedência qualquer possível degradação do sistema.
Priorização e implementação
Registramos as alterações propostas e as equipes priorizaram esses tickets. O primeiro desafio aqui foi gerenciar esses tickets em vários quadros de equipe. Outro desafio foi priorizar impiedosamente o trabalho da Black Friday em relação a outras prioridades.
Precisávamos fornecer aos nossos engenheiros a liberdade criativa para encontrar soluções para problemas difíceis. Ao mesmo tempo, tivemos que garantir que essas soluções estivessem alinhadas com nossos planos de longo prazo. Também era muito importante que estivéssemos sempre conscientes de qualquer conflito de interesse, o que significava evitar qualquer solução de curto prazo que pudesse voltar a nos morder.
Validar as mudanças que foram implementadas se tornaria nosso objetivo para os próximos testes.
Manter e acelerar o ritmo à medida que nos aproximamos da Black Friday foi um grande desafio no planejamento e na execução.
A aceleração
Quando entramos em setembro, começamos a executar vários testes de estresse a cada semana. Isso nos exigiu identificar, corrigir e validar problemas mais rapidamente. Também nos proporcionou um ciclo de aprendizado e adaptação muito mais rápido.
Além do teste completo do pipeline de correio, conforme descrito anteriormente, também iniciamos o teste de estresse de nossos serviços de suporte durante o mesmo período. Durante o mesmo período, começamos a realizar testes de carga com um de nossos maiores clientes para garantir que nossos geopods de entrada lidariam com seus envios de rajada previstos durante a temporada de férias sem nenhuma preocupação.
Devido às longas horas e ao desafio de gerenciar o trabalho, nossas equipes estavam ficando esgotadas. Listamos os alertas mais críticos necessários para interromper nosso teste, se necessário, e os tornamos mais sensíveis. Isso nos permitiu começar a fazer nossos testes sem exigir que estivéssemos presentes para monitorar nossos sistemas no início da manhã.
Velocidade com cautela
À medida que nos aproximávamos do final de setembro, havia uma preocupação de que talvez não estivéssemos nos movendo rápido o suficiente na direção certa. Criamos uma equipe de tigres, uma equipe de especialistas que poderia trabalhar em qualquer um dos tickets em várias equipes e que trabalhasse com processos muito mais enxutos em um nível diário.
Fizemos melhorias significativas em nossa infraestrutura operacional, bem como em nosso software de processamento de correio, em preparação para a Black Friday. Essas mudanças estavam sendo expressamente priorizadas e as equipes tinham que trabalhar em grande coordenação entre si. Foi uma ótima experiência para as pessoas colocarem o SendGrid em primeiro lugar. Estávamos fazendo alterações nos aplicativos, infraestrutura e aumentando nossa capacidade de hardware enquanto executamos o mecanismo principal de uma unidade de negócios de uma empresa pública, tudo em ritmo de inicialização. O melhor de tudo, fizemos tudo isso sem nenhuma experiência de serviço degradada para nossos clientes.
Planos futuros
Passamos muitas horas humanas nos preparando para a Black Friday 2019. Nossos aprendizados deste ano nos ajudarão a automatizar grande parte de nossa preparação para a Black Friday e a Cyber Monday em 2020. Estamos ansiosos por mais um ano de sucesso com recordes sem estresse - Quebrando volumes de envio de férias para nossos clientes e nossos funcionários.