
Eficácia do rastreamento: como melhorar a otimização do rastreamento
Publicados: 2022-10-27Não é garantido que o Googlebot rastreie todos os URLs que puder acessar em seu site. Pelo contrário, a grande maioria dos sites está perdendo um pedaço significativo de páginas.
A realidade é que o Google não tem recursos para rastrear todas as páginas que encontra. Todos os URLs que o Googlebot descobriu, mas ainda não rastreou, juntamente com os URLs que pretende rastrear novamente são priorizados em uma fila de rastreamento.
Isso significa que o Googlebot rastreia apenas aqueles que recebem prioridade alta o suficiente. E como a fila de rastreamento é dinâmica, ela muda continuamente conforme o Google processa novos URLs. E nem todos os URLs entram no final da fila.
Então, como você garante que os URLs do seu site sejam VIPs e ultrapassem a linha?
O rastreamento é extremamente importante para SEO

Para que o conteúdo ganhe visibilidade, o Googlebot precisa rastreá-lo primeiro.
Mas os benefícios são mais sutis do que isso, porque quanto mais rápido uma página é rastreada, quando ela é:
- Criado , mais cedo o novo conteúdo pode aparecer no Google. Isso é especialmente importante para estratégias de conteúdo com tempo limitado ou primeiro no mercado.
- Atualizado , mais cedo o conteúdo atualizado pode começar a afetar as classificações. Isso é especialmente importante tanto para estratégias de republicação de conteúdo quanto para táticas técnicas de SEO.
Como tal, o rastreamento é essencial para todo o seu tráfego orgânico. No entanto, muitas vezes se diz que a otimização de rastreamento só é benéfica para sites grandes.
Mas não é sobre o tamanho do seu site, a frequência do conteúdo é atualizado ou se você tem exclusões “Descoberto – atualmente não indexado” no Google Search Console.
A otimização de rastreamento é benéfica para todos os sites. O equívoco de seu valor parece estimular medições sem sentido, especialmente o orçamento de rastreamento.
O orçamento de rastreamento não importa

Muitas vezes, o rastreamento é avaliado com base no orçamento de rastreamento. Este é o número de URLs que o Googlebot rastreará em um determinado período de tempo em um site específico.
O Google diz que é determinado por dois fatores:
- Limite da taxa de rastreamento (ou o que o Googlebot pode rastrear): a velocidade com que o Googlebot pode buscar os recursos do site sem afetar o desempenho do site. Essencialmente, um servidor responsivo leva a uma taxa de rastreamento mais alta.
- Demanda de rastreamento (ou o que o Googlebot deseja rastrear): o número de URLs que o Googlebot visita durante um único rastreamento com base na demanda de (re)indexação, impactada pela popularidade e obsolescência do conteúdo do site.
Depois que o Googlebot “gasta” seu orçamento de rastreamento, ele para de rastrear um site.
O Google não fornece um valor para o orçamento de rastreamento. O mais próximo disso é mostrar o total de solicitações de rastreamento no relatório de estatísticas de rastreamento do Google Search Console.
Muitos SEOs, inclusive eu no passado, se esforçaram muito para tentar inferir o orçamento de rastreamento.
As etapas frequentemente apresentadas são algo como:
- Determine quantas páginas rastreáveis você tem em seu site, geralmente recomendando olhar para o número de URLs em seu sitemap XML ou executar um rastreador ilimitado.
- Calcule a média de rastreamentos por dia exportando o relatório Estatísticas de rastreamento do Google Search Console ou com base nas solicitações do Googlebot em arquivos de registro.
- Divida o número de páginas pela média de rastreamentos por dia. Costuma-se dizer que, se o resultado for acima de 10, concentre-se na otimização do orçamento de rastreamento.
No entanto, esse processo é problemático.
Não apenas porque assume que cada URL é rastreado uma vez, quando na realidade alguns são rastreados várias vezes, outros não.
Não apenas porque assume que um rastreamento é igual a uma página. Quando, na realidade, uma página pode exigir muitos rastreamentos de URL para buscar os recursos (JS, CSS, etc) necessários para carregá-la.
Mas o mais importante, porque quando é reduzido a uma métrica calculada, como rastreamentos médios por dia, o orçamento de rastreamento não passa de uma métrica de vaidade.
Qualquer tática voltada para a “otimização do orçamento de rastreamento” (ou seja, com o objetivo de aumentar continuamente a quantidade total de rastreamento) é uma tarefa tola.
Por que você deveria se preocupar em aumentar o número total de rastreamentos se ele for usado em URLs sem valor ou em páginas que não foram alteradas desde o último rastreamento? Esses rastreamentos não ajudarão no desempenho de SEO.
Além disso, qualquer um que já tenha analisado as estatísticas de rastreamento sabe que elas flutuam, muitas vezes de forma bastante selvagem, de um dia para outro, dependendo de vários fatores. Essas flutuações podem ou não se correlacionar com a (re) indexação rápida de páginas relevantes para SEO.
Um aumento ou queda no número de URLs rastreados não é inerentemente bom nem ruim.
A eficácia do rastreamento é um KPI de SEO

Para a(s) página(s) que você deseja indexar, o foco não deve ser se ela foi rastreada, mas sim a rapidez com que foi rastreada após ser publicada ou alterada significativamente.
Essencialmente, o objetivo é minimizar o tempo entre a criação ou atualização de uma página relevante para SEO e o próximo rastreamento do Googlebot. Eu chamo esse atraso de eficácia de rastreamento.
A maneira ideal de medir a eficácia do rastreamento é calcular a diferença entre a data e hora de criação ou atualização do banco de dados e o próximo rastreamento do Googlebot do URL dos arquivos de registro do servidor.
Se for difícil obter acesso a esses pontos de dados, você também pode usar como proxy a data da última modificação do sitemap XML e os URLs de consulta na API de inspeção de URL do Google Search Console para seu último status de rastreamento (até um limite de 2.000 consultas por dia).
Além disso, usando a API de inspeção de URL, você também pode acompanhar quando o status da indexação muda para calcular a eficácia da indexação para URLs recém-criados, que é a diferença entre publicação e indexação bem-sucedida.
Porque rastrear sem afetar o fluxo no status de indexação ou processar uma atualização do conteúdo da página é apenas um desperdício.
A eficácia do rastreamento é uma métrica acionável porque, à medida que diminui, o conteúdo mais crítico para SEO pode ser exibido para seu público no Google.
Você também pode usá-lo para diagnosticar problemas de SEO. Analise os padrões de URL para entender a rapidez com que o conteúdo de várias seções do seu site está sendo rastreado e se é isso que está impedindo o desempenho orgânico.
Se você perceber que o Googlebot está demorando horas, dias ou semanas para rastrear e indexar seu conteúdo recém-criado ou atualizado recentemente, o que você pode fazer a respeito?
Obtenha a pesquisa diária de newsletters em que os profissionais de marketing confiam.
Consulte os termos.
7 etapas para otimizar o rastreamento
A otimização de rastreamento tem tudo a ver com orientar o Googlebot a rastrear URLs importantes rápido quando são (re)publicados. Siga os sete passos abaixo.
1. Garanta uma resposta rápida e saudável do servidor
Um servidor de alto desempenho é fundamental. O Googlebot desacelerará ou interromperá o rastreamento quando:
- O rastreamento do seu site afeta o desempenho. Por exemplo, quanto mais eles rastrearem, mais lento será o tempo de resposta do servidor.
- O servidor responde com um número notável de erros ou tempos limite de conexão.
Por outro lado, melhorar a velocidade de carregamento da página, permitindo a veiculação de mais páginas, pode levar o Googlebot a rastrear mais URLs no mesmo período de tempo. Esse é um benefício adicional além da velocidade da página, sendo uma experiência do usuário e um fator de classificação.
Se você ainda não o faz, considere o suporte para HTTP/2, pois permite solicitar mais URLs com uma carga semelhante nos servidores.
No entanto, a correlação entre o desempenho e o volume de rastreamento é apenas até certo ponto . Depois de ultrapassar esse limite, que varia de site para site, é improvável que ganhos adicionais no desempenho do servidor se relacionem com um aumento no rastreamento.
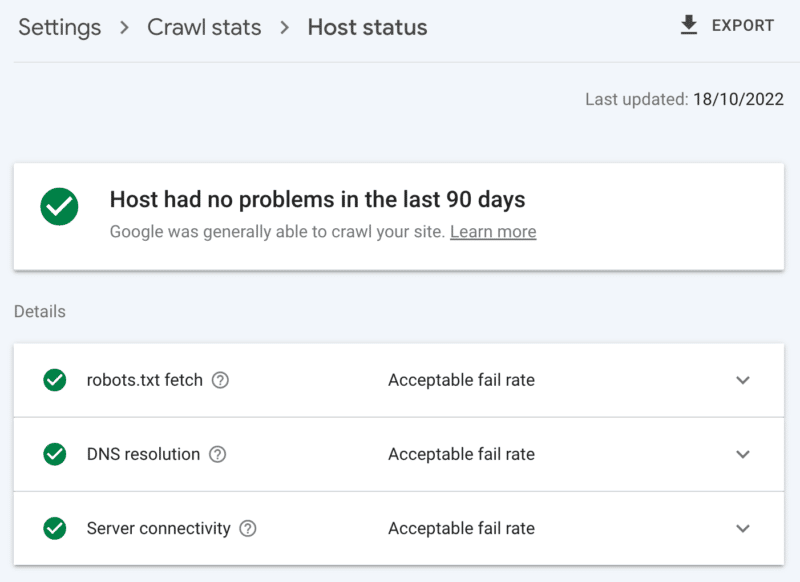
Como verificar a integridade do servidor
O relatório de estatísticas de rastreamento do Google Search Console:
- Status do host: mostra marcas verdes.
- Erros 5xx: Constituem menos de 1%.
- Gráfico de tempo de resposta do servidor: tendência abaixo de 300 milissegundos.
2. Limpe o conteúdo de baixo valor
Se uma quantidade significativa de conteúdo do site estiver desatualizada, duplicada ou de baixa qualidade, isso causará concorrência pela atividade de rastreamento, possivelmente atrasando a indexação de conteúdo novo ou a reindexação de conteúdo atualizado.

Além disso, a limpeza regular de conteúdo de baixo valor também reduz o inchaço do índice e a canibalização de palavras-chave e é benéfico para a experiência do usuário, isso é um acéfalo de SEO.
Mesclar conteúdo com um redirecionamento 301, quando você tiver outra página que possa ser vista como uma substituição clara; entender isso custará o dobro do rastreamento para processamento, mas é um sacrifício que vale a pena para o valor do link.
Se não houver conteúdo equivalente, o uso de um 301 resultará apenas em um soft 404. Remova esse conteúdo usando um código de status 410 (melhor) ou 404 (segundo próximo) para fornecer um sinal forte para não rastrear o URL novamente.
Como verificar conteúdo de baixo valor
O número de URLs nas páginas do Google Search Console relata exclusões 'rastreadas – atualmente não indexadas'. Se for alto, revise as amostras fornecidas para padrões de pasta ou outros indicadores de problemas.
3. Revise os controles de indexação
Rel=links canônicos são uma forte dica para evitar problemas de indexação, mas muitas vezes são muito confiáveis e acabam causando problemas de rastreamento, pois cada URL canonizado custa pelo menos dois rastreamentos, um para si e outro para seu parceiro.
Da mesma forma, as diretivas de robôs noindex são úteis para reduzir o inchaço do índice, mas um grande número pode afetar negativamente o rastreamento – portanto, use-as apenas quando necessário.
Em ambos os casos, pergunte-se:
- Essas diretivas de indexação são a maneira ideal de lidar com o desafio de SEO?
- Algumas rotas de URL podem ser consolidadas, removidas ou bloqueadas no robots.txt?
Se você estiver usando, reconsidere seriamente o AMP como uma solução técnica de longo prazo.
Com a atualização da experiência da página com foco nos principais elementos vitais da Web e a inclusão de páginas não AMP em todas as experiências do Google, desde que você atenda aos requisitos de velocidade do site, verifique se o AMP vale o rastreamento duplo.
Como verificar a dependência excessiva de controles de indexação
O número de URLs no relatório de cobertura do Google Search Console categorizados nas exclusões sem um motivo claro:
- Página alternativa com tag canônica adequada.
- Excluído pela tag noindex.
- Duplicado, o Google escolheu canônico diferente do usuário.
- URL enviado duplicado não selecionado como canônico.
4. Diga aos spiders dos mecanismos de pesquisa o que rastrear e quando
Uma ferramenta essencial para ajudar o Googlebot a priorizar URLs de sites importantes e comunicar quando essas páginas são atualizadas é um mapa do site XML.
Para uma orientação eficaz do rastreador, certifique-se de:
- Inclua apenas URLs que sejam indexáveis e valiosas para SEO – geralmente, 200 códigos de status, páginas de conteúdo original e canônicas com uma tag de robôs “index,follow” para as quais você se preocupa com sua visibilidade nas SERPs.
- Inclua tags de carimbo de data/hora <lastmod> precisas nos URLs individuais e no próprio mapa do site o mais próximo possível do tempo real.
O Google não verifica um mapa do site sempre que um site é rastreado. Portanto, sempre que for atualizado, é melhor enviar um ping para a atenção do Google. Para fazer isso, envie uma solicitação GET em seu navegador ou na linha de comando para:
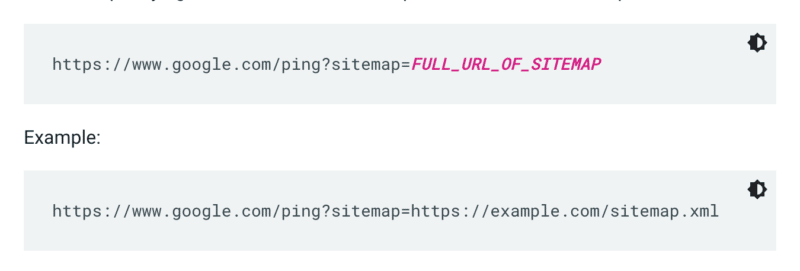
Além disso, especifique os caminhos para o mapa do site no arquivo robots.txt e envie-o ao Google Search Console usando o relatório de mapas do site.
Como regra, o Google rastreará URLs em sitemaps com mais frequência do que outros. Mas mesmo que uma pequena porcentagem de URLs em seu sitemap seja de baixa qualidade, isso pode dissuadir o Googlebot de usá-lo para sugestões de rastreamento.
Sitemaps e links XML adicionam URLs à fila de rastreamento regular. Há também uma fila de rastreamento de prioridade, para a qual existem dois métodos de entrada.
Em primeiro lugar, para aqueles com anúncios de emprego ou vídeos ao vivo, você pode enviar URLs para a API de indexação do Google.
Ou se você quiser chamar a atenção do Microsoft Bing ou Yandex, você pode usar a API IndexNow para qualquer URL. No entanto, em meus próprios testes, isso teve um impacto limitado no rastreamento de URLs. Portanto, se você usar o IndexNow, certifique-se de monitorar a eficácia do rastreamento para o Bingbot.
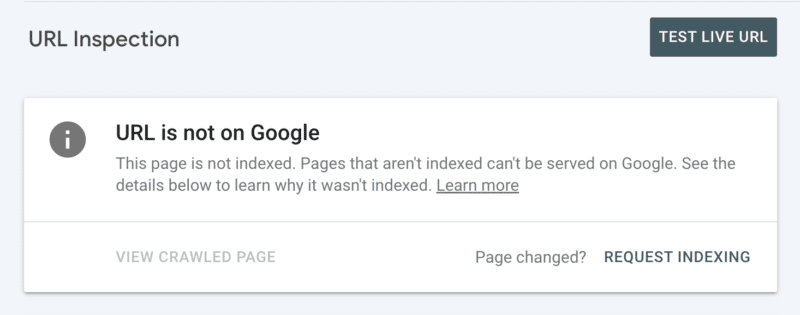
Em segundo lugar, você pode solicitar a indexação manualmente após inspecionar o URL no Search Console. Embora tenha em mente que há uma cota diária de 10 URLs e o rastreamento ainda pode levar algumas horas. É melhor ver isso como um patch temporário enquanto você cava para descobrir a raiz do seu problema de rastreamento.
Como verificar as orientações essenciais de rastreamento do Googlebot
No Google Search Console, seu sitemap XML mostra o status "Sucesso" e foi lido recentemente.
5. Diga aos spiders dos mecanismos de pesquisa o que não devem ser rastreados
Algumas páginas podem ser importantes para os usuários ou para a funcionalidade do site, mas você não deseja que elas apareçam nos resultados de pesquisa. Evite que essas rotas de URL distraiam os rastreadores com uma proibição de robots.txt. Isso pode incluir:
- APIs e CDNs . Por exemplo, se você é cliente da Cloudflare, certifique-se de não permitir a pasta /cdn-cgi/ que é adicionada ao seu site.
- Imagens, scripts ou arquivos de estilo sem importância , se as páginas carregadas sem esses recursos não forem afetadas significativamente pela perda.
- Página funcional , como um carrinho de compras.
- Espaços infinitos , como aqueles criados por páginas de calendário.
- Páginas de parâmetros . Especialmente aqueles de navegação facetada que filtram (por exemplo, ?price-range=20-50), reordenam (por exemplo, ?sort=) ou pesquisam (por exemplo, ?q=), pois cada combinação é contada pelos rastreadores como uma página separada.
Esteja atento para não bloquear completamente o parâmetro de paginação. A paginação rastreável até certo ponto geralmente é essencial para o Googlebot descobrir conteúdo e processar a equidade de links internos. (Confira este webinar da Semrush sobre paginação para saber mais detalhes sobre o porquê.)
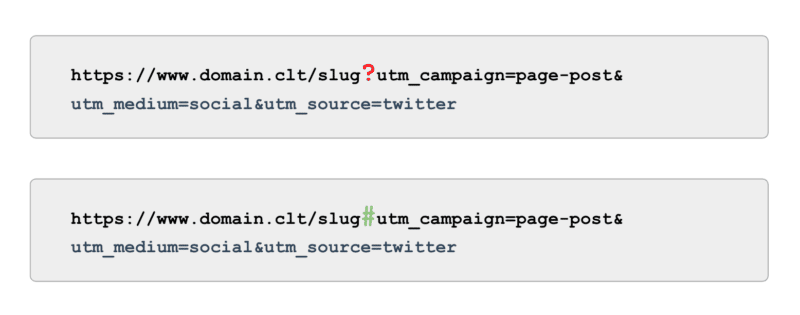
E quando se trata de rastreamento, em vez de usar tags UTM alimentadas por parâmetros (também conhecidos como '?'), use âncoras (também conhecidas como '#'). Ele oferece os mesmos benefícios de relatórios no Google Analytics sem ser rastreável.
Como verificar a orientação do Googlebot para não rastrear
Revise o exemplo de URLs "Indexados, não enviados no mapa do site" no Google Search Console. Ignorando as primeiras páginas da paginação, que outros caminhos você encontra? Eles devem ser incluídos em um sitemap XML, bloqueados de serem rastreados ou permitidos?
Além disso, revise a lista de "Descoberto - atualmente não indexado" - bloqueando no robots.txt qualquer caminho de URL que ofereça pouco ou nenhum valor ao Google.
Para levar isso para o próximo nível, revise todos os rastreamentos de smartphones do Googlebot nos arquivos de log do servidor em busca de caminhos sem valor.
6. Selecione links relevantes
Backlinks para uma página são valiosos para muitos aspectos do SEO, e o rastreamento não é exceção. Mas links externos podem ser desafiadores para certos tipos de página. Por exemplo, páginas profundas como produtos, categorias nos níveis mais baixos da arquitetura do site ou até mesmo artigos.
Por outro lado, os links internos relevantes são:
- Tecnicamente escalável.
- Sinais poderosos para o Googlebot priorizar uma página para rastreamento.
- Particularmente impactante para rastreamento de página profunda.
Breadcrumbs, blocos de conteúdo relacionados, filtros rápidos e uso de tags bem selecionadas são benefícios significativos para a eficácia do rastreamento. Como eles são conteúdo crítico para SEO, certifique-se de que nenhum desses links internos dependa do JavaScript, mas use um link <a> padrão e rastreável.
Tendo em mente que esses links internos também devem agregar valor real para o usuário.
Como verificar links relevantes
Execute um rastreamento manual do seu site completo com uma ferramenta como o SEO spider do ScreamingFrog, procurando por:
- URLs órfãos.
- Links internos bloqueados por robots.txt.
- Links internos para qualquer código de status diferente de 200.
- A porcentagem de URLs não indexáveis vinculados internamente.
7. Audite os problemas de rastreamento restantes
Se todas as otimizações acima forem concluídas e a eficácia do rastreamento permanecer abaixo do ideal, realize uma auditoria detalhada.
Comece analisando as amostras de todas as exclusões restantes do Google Search Console para identificar problemas de rastreamento.
Depois que eles forem resolvidos, vá mais fundo usando uma ferramenta de rastreamento manual para rastrear todas as páginas na estrutura do site, como o Googlebot faria. Faça uma referência cruzada com os arquivos de registro reduzidos aos IPs do Googlebot para entender quais dessas páginas estão e quais não estão sendo rastreadas.
Por fim, inicie a análise do arquivo de log reduzida ao IP do Googlebot por pelo menos quatro semanas de dados, idealmente mais.
Se você não estiver familiarizado com o formato dos arquivos de log, aproveite uma ferramenta de análise de log. Em última análise, esta é a melhor fonte para entender como o Google rastreia seu site.
Depois que sua auditoria for concluída e você tiver uma lista de problemas de rastreamento identificados, classifique cada problema por seu nível esperado de esforço e impacto no desempenho.
Nota : Outros especialistas em SEO mencionaram que os cliques dos SERPs aumentam o rastreamento do URL da página de destino. No entanto, ainda não consegui confirmar isso com testes.
Priorize a eficácia do rastreamento em relação ao orçamento do rastreamento
O objetivo do rastreamento não é obter a maior quantidade de rastreamento nem ter todas as páginas de um site rastreadas repetidamente, é atrair um rastreamento de conteúdo relevante para SEO o mais próximo possível de quando uma página é criada ou atualizada.
No geral, os orçamentos não importam. É no que você investe que conta.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.