
Um guia para diagnosticar problemas comuns de SEO em JavaScript
Publicados: 2023-07-10Sejamos honestos, JavaScript e SEO nem sempre funcionam bem juntos. Para alguns SEOs, o tópico pode parecer envolto em um véu de complexidade.
Bem, boas notícias: quando você remove as camadas, muitos problemas de SEO baseados em JavaScript voltam aos fundamentos de como os rastreadores do mecanismo de pesquisa interagem com o JavaScript em primeiro lugar.
Portanto, se você entender esses fundamentos, poderá se aprofundar nos problemas, entender seu impacto e trabalhar com os desenvolvedores para corrigir os que importam.
Neste artigo, ajudaremos a diagnosticar alguns problemas comuns quando os sites são construídos em estruturas JS. Além disso, detalharemos o conhecimento básico que todo SEO técnico precisa quando se trata de renderização.
Resumindo
Antes de entrarmos nas coisas mais granulares, vamos falar sobre o quadro geral.
Para que um mecanismo de pesquisa entenda o conteúdo alimentado por JavaScript, ele precisa rastrear e renderizar a página.
O problema é que os mecanismos de pesquisa têm poucos recursos para usar, então eles precisam ser seletivos sobre quando vale a pena usá-los. Não é certo que uma página será renderizada, mesmo que o rastreador a envie para a fila de renderização.
Se ele optar por não renderizar a página ou não conseguir renderizar o conteúdo corretamente, pode ser um problema.
Tudo se resume a como o front-end atende o HTML na resposta inicial do servidor.
Quando uma URL é criada no navegador, um front-end como React, Vue ou Gatsby gerará o HTML para a página. Um crawler verifica se aquele HTML já está disponível no servidor (HTML “pré-renderizado”) antes de enviar a URL para aguardar a renderização para que possa olhar o conteúdo resultante.
A disponibilidade de qualquer HTML pré-renderizado depende de como o front-end está configurado. Ele gerará o HTML por meio do servidor ou no navegador do cliente.
Renderização do lado do servidor
O nome diz tudo. Em uma configuração SSR, o rastreador é alimentado com uma página HTML totalmente renderizada sem exigir execução e renderização JS extras.
Portanto, mesmo que a página não seja renderizada, o mecanismo de pesquisa ainda pode rastrear qualquer HTML, contextualizar a página (metadados, cópia, imagens) e entender sua relação com outras páginas (breadcrumbs, URL canônico, links internos).
Renderização do lado do cliente
No CSR, o HTML é gerado no navegador junto com todos os componentes JavaScript. O JavaScript precisa ser renderizado antes que o HTML esteja disponível para rastreamento.
Se o serviço de renderização optar por não renderizar uma página enviada para a fila, a cópia, os URLs internos, os links de imagens e até mesmo os metadados permanecerão indisponíveis para os rastreadores.
Como resultado, os mecanismos de pesquisa têm pouco ou nenhum contexto para entender a relevância de uma URL para as consultas de pesquisa.
Observação : pode haver uma mistura de HTML que é exibida na resposta HTML inicial, bem como HTML que exige que o JS seja executado para renderizar (aparecer). Depende de vários fatores, sendo os mais comuns a estrutura, como os componentes individuais do site são construídos e a configuração do servidor.
O kit de ferramentas de SEO JavaScript
Certamente existem ferramentas que ajudarão a identificar problemas de SEO relacionados a JavaScript.
Você pode fazer muitas investigações usando as ferramentas do navegador e o Google Search Console. Aqui está a lista que compõe um kit de ferramentas sólido:
- Exibir código-fonte: clique com o botão direito do mouse em uma página e clique em "exibir código-fonte" para ver o HTML pré-renderizado da página (a resposta inicial do servidor).
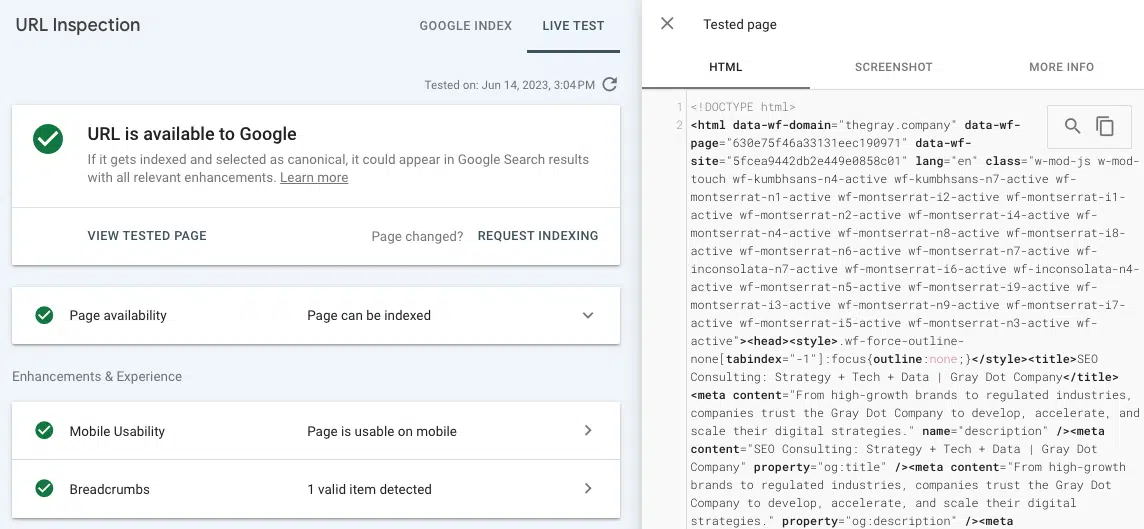
- Testar URL ativo (inspeção de URL): visualize uma captura de tela, HTML e outros detalhes importantes de uma página renderizada na guia de inspeção de URL do Google Search Console. (Muitos problemas de renderização podem ser encontrados comparando o HTML pré-renderizado de “visualizar código-fonte” com o HTML renderizado ao testar a URL ativa no GSC.)
- Ferramentas do desenvolvedor do Chrome: clique com o botão direito do mouse em uma página e escolha "Inspecionar" para abrir as ferramentas para visualizar erros de JavaScript e muito mais.
- Wappalyzer: veja a pilha na qual qualquer site é construído e busque informações específicas da estrutura instalando esta extensão gratuita do Chrome.
Problemas comuns de SEO em JavaScript
Problema 1: o HTML pré-renderizado está universalmente indisponível
Além das implicações negativas para rastreamento e contextualização mencionadas anteriormente, há também a questão do tempo e dos recursos que um mecanismo de pesquisa pode levar para renderizar uma página.
Se o rastreador optar por colocar uma URL no processo de renderização, ela terminará na fila de renderização. Isso acontece porque um rastreador pode detectar uma disparidade entre a estrutura HTML pré-renderizada e renderizada. (O que faz muito sentido se não houver HTML pré-renderizado!)
Não há garantia de quanto tempo uma URL espera pelo serviço de renderização da web. A melhor maneira de influenciar o WRS para uma renderização oportuna é garantir que haja sinais de autoridade importantes no local, ilustrando a importância de uma URL (por exemplo, links na navegação superior, muitos links internos, referenciados como canônicos). Isso fica um pouco complicado porque os sinais de autoridade também precisam ser rastreados.
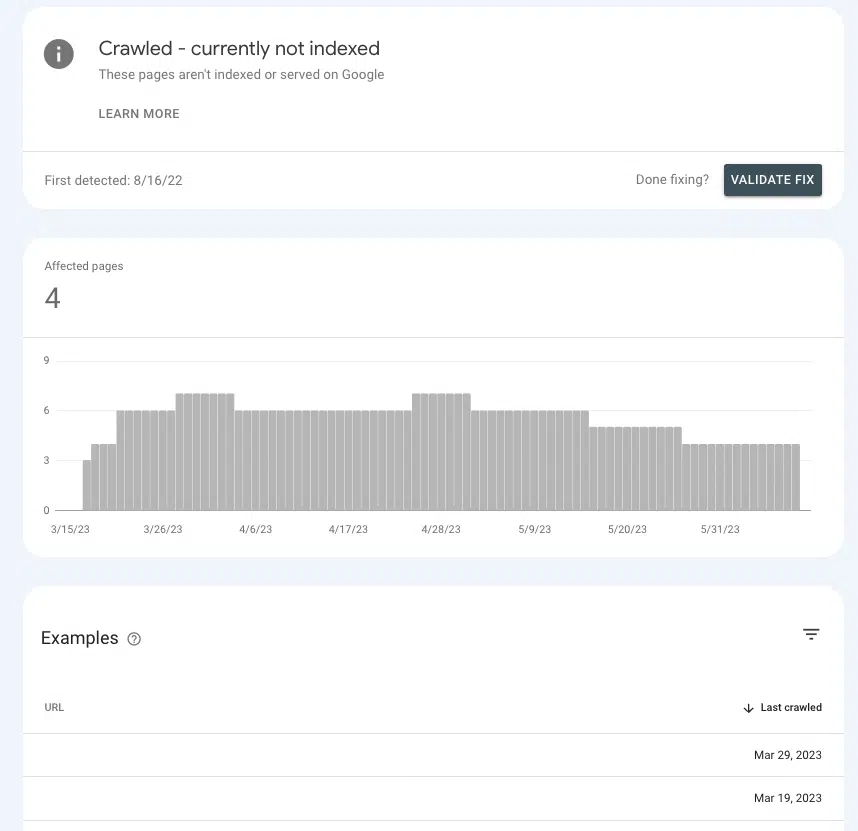
No Google Search Console, é possível saber se você está enviando os sinais de autoridade corretos para as páginas-chave ou fazendo com que elas fiquem no limbo.
Vá para Páginas > Indexação de página > Rastreado – atualmente não indexado e procure a presença de páginas prioritárias na lista.
Se eles estão na sala de espera, é porque o Google não pode verificar se eles são importantes o suficiente para gastar recursos.
Causas comuns
Configurações padrão
Os front-ends mais populares vêm “prontos para uso” configurados para renderização do lado do cliente, portanto, há uma boa chance de que as configurações padrão sejam as culpadas.
Se você está se perguntando por que a maioria dos front-ends é padronizada para CSR, é por causa dos benefícios de desempenho. Os desenvolvedores nem sempre adoram o SSR, porque ele pode limitar as possibilidades de acelerar um site e implementar certos elementos interativos (por exemplo, transições únicas entre as páginas).
Aplicativo de página única
Se um site for um aplicativo de página única, ele será totalmente agrupado em JavaScript e gerará todos os componentes de uma página no navegador (também conhecido como tudo), renderizado no lado do cliente e novas páginas serão exibidas sem recarregar).
Isso tem algumas implicações negativas, talvez a mais importante seja que as páginas são potencialmente indetectáveis.
Isso não quer dizer que seja impossível configurar um SPA de uma maneira mais amigável ao SEO. Mas é provável que haja algum trabalho de desenvolvimento significativo necessário para que isso aconteça.
Problema 2: algum conteúdo da página está inacessível para rastreadores
Conseguir que um mecanismo de pesquisa renderize uma URL é ótimo, desde que todos os elementos estejam disponíveis para rastreamento. E se estiver renderizando a página, mas houver seções de uma página que não estão acessíveis?
Por exemplo, um SEO faz uma análise de link interno e encontra pouco ou nenhum link interno relatado para um URL vinculado a várias páginas.
Se o link não aparecer no HTML renderizado da ferramenta Test Live URL, é provável que ele seja exibido em recursos JavaScript que o Google não consegue acessar.
Para restringir o culpado, seria uma boa ideia procurar semelhanças em termos de onde o conteúdo da página ausente ou os links internos estão na página entre os URLs.
Por exemplo, se for um link de FAQ que aparece na mesma seção de cada página de produto, isso ajuda bastante os desenvolvedores a restringir uma correção.
Causas comuns
Erros de JavaScript
Vamos começar com um aviso aqui. A maioria dos erros de JavaScript que você encontra não importa para SEO.
Portanto, se você for à caça de erros, levar uma longa lista ao seu desenvolvedor e iniciar a conversa com “O que são todos esses erros?”, eles podem não receber tudo tão bem.
Aproxime-se do “porquê” falando com o problema, para que eles possam ser os especialistas em JavaScript (porque eles são!).
Com isso dito, existem erros de sintaxe que podem tornar o restante da página inanalisado (por exemplo, “bloqueio de renderização”). Quando isso ocorre, o renderizador não consegue separar os elementos HTML individuais, estruturar o conteúdo no DOM ou entender os relacionamentos.
Geralmente, esses tipos de erros são reconhecíveis porque também têm algum tipo de efeito na visualização do navegador.
Além da confirmação visual, também é possível ver erros de JavaScript clicando com o botão direito do mouse na página, escolhendo “inspecionar” e navegando até a guia “Console”.
Obtenha a newsletter diária em que os profissionais de marketing de busca confiam.
Consulte os termos.
O conteúdo requer uma interação do usuário

Uma das coisas mais importantes a lembrar sobre a renderização é que o Google não pode renderizar nenhum conteúdo que exija que os usuários interajam com a página. Ou, para simplificar, não pode “clicar” nas coisas.
Por que isso importa? Pense no nosso velho e fiel amigo, o menu suspenso sanfona, e em quantos sites o usam para organizar conteúdo, como detalhes de produtos e perguntas frequentes.
Dependendo de como o acordeão é codificado, o Google pode não conseguir renderizar o conteúdo no menu suspenso se ele não for preenchido até que o JS seja executado.
Para verificar, você pode “Inspecionar” uma página e ver se o conteúdo “oculto” (o que aparece quando você clica em um acordeão) está no HTML.
Caso contrário, isso significa que o Googlebot e outros rastreadores não veem esse conteúdo na versão renderizada da página.
Problema 3: as seções de um site não estão sendo rastreadas
O Google pode ou não renderizar sua página se rastreá-la e enviá-la para a fila. Se ele não rastrear a página, até mesmo essa oportunidade estará fora de questão.
Para entender se o Google está rastreando páginas, o relatório Estatísticas de rastreamento pode ser útil Configurações > Estatísticas de rastreamento .
Selecione Solicitações de rastreamento: OK (200) para ver todas as instâncias de rastreamento de 200 páginas de status nos últimos três meses. Em seguida, use a filtragem para pesquisar URLs individuais ou diretórios inteiros.
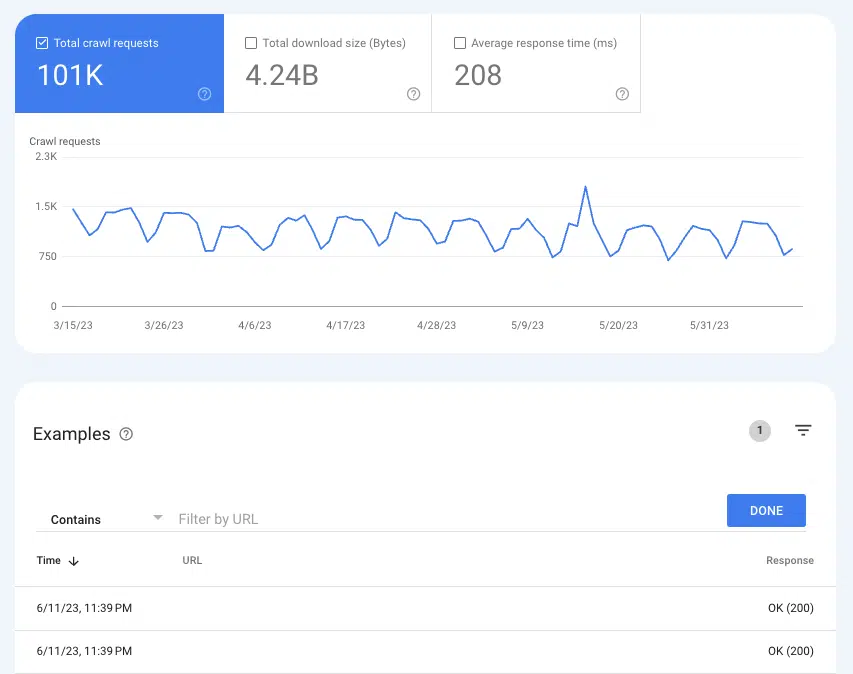
Se os URLs não aparecerem nos logs de rastreamento, há uma boa chance de que o Google não consiga descobrir as páginas e rastreá-las (ou não tenham 200 páginas, o que é um problema totalmente diferente).
Causas comuns
Links internos não são rastreáveis
Os links são os sinais de trânsito que os rastreadores seguem para novas páginas. Essa é uma das razões pelas quais as páginas órfãs são um problema tão grande.
Se você tem um site bem vinculado e está vendo páginas órfãs aparecerem em suas auditorias de site, há uma boa chance de que os links não estejam disponíveis no HTML pré-renderizado.
Uma maneira fácil de verificar é ir para um URL que tenha um link para a página órfã relatada. Clique com o botão direito do mouse na página e clique em “ver fonte”.
Em seguida, use CMD + f para pesquisar a URL da página órfã. Se ele não aparecer no HTML pré-renderizado, mas aparecer na página quando renderizado no navegador, pule para o problema quatro.
Mapa do site XML não atualizado
O mapa do site XML é crucial para ajudar o Google a descobrir novas páginas e entender quais URLs priorizar em um rastreamento.
Sem o mapa do site XML, a descoberta da página só é possível seguindo os links.
Portanto, para sites sem HTML pré-renderizado, um sitemap desatualizado ou ausente significa esperar que o Google processe páginas, siga links internos para outras páginas, enfileire-os, renderize-os, siga seus links e assim por diante.
Dependendo do front-end que você está usando, você pode ter acesso a plug-ins que podem criar sitemaps XML dinâmicos.
Eles geralmente precisam de personalização, por isso é importante que os SEOs documentem diligentemente quaisquer URLs que não devam estar no mapa do site e a lógica por trás disso.
Isso deve ser relativamente fácil de verificar executando o mapa do site por meio de sua ferramenta de SEO favorita.
Problema 4: links internos estão ausentes
A indisponibilidade de links internos para rastreadores não é apenas um problema de descoberta em potencial, mas também um problema de equidade. Como os links passam a equidade de SEO da URL de referência para a URL de destino, eles são um fator importante no crescimento da autoridade da página e do domínio.
Os links da página inicial são um ótimo exemplo. Geralmente é a página de maior autoridade em um site, portanto, um link para outra página da página inicial tem muito peso.
Se esses links não forem rastreáveis, é como ter um sabre de luz quebrado. Uma de suas ferramentas mais poderosas é inutilizada (trocadilho intencional).
Causas comuns
Interação do usuário necessária para acessar o link
O exemplo do acordeão que usamos anteriormente é apenas uma instância em que o conteúdo fica oculto por trás de uma interação do usuário. Outro que pode ter implicações generalizadas é a paginação de rolagem infinita – especialmente para sites de comércio eletrônico com catálogos substanciais de produtos.
Em uma configuração de rolagem infinita, inúmeros produtos em uma página de listagem de produtos (categoria) não serão carregados, a menos que o usuário role além de um determinado ponto (carregamento lento) ou toque no botão “mostrar mais”.
Portanto, mesmo que o JavaScript seja renderizado, um rastreador não pode acessar os links internos dos produtos que ainda não foram carregados. No entanto, carregar todos esses produtos em uma página afetaria negativamente a experiência do usuário devido ao baixo desempenho da página.
É por isso que os SEOs geralmente preferem a paginação verdadeira, na qual cada página de resultados tem um URL distinto e rastreável.
Embora existam maneiras de um site otimizar o carregamento lento e adicionar todos os produtos ao HTML pré-renderizado, isso levaria a diferenças entre o HTML renderizado e o HTML pré-renderizado.
Efetivamente, isso cria um motivo para enviar mais páginas para a fila de renderização e fazer com que os rastreadores trabalhem mais do que precisam – e sabemos que isso não é bom para SEO.
No mínimo, siga as recomendações do Google para otimizar a rolagem infinita.
Links não codificados corretamente
Quando o Google rastreia um site ou processa um URL na fila, ele está baixando uma versão sem estado de uma página. Essa é uma grande parte da razão pela qual é tão importante usar tags e âncoras href adequadas (a estrutura de links que você vê com mais frequência). Um rastreador não pode seguir formatos de link como roteador, span ou onClick.
Pode seguir:
- <a href="https://example.com">
- <a href="/relative/path/file">
Não pode seguir:
- <a routerLink="algum/caminho">
- <span href="https://example.com">
- <a>
Para fins de desenvolvedor, todas essas são formas válidas de codificar links. As implicações de SEO são uma camada adicional de contexto, e não é trabalho deles saber – é do SEO.
Uma grande parte do trabalho de um bom SEO é fornecer aos desenvolvedores esse contexto por meio da documentação.
Problema 5: faltam metadados
Em uma página HTML, metadados como título, descrição, URL canônica e tag meta robots estão todos aninhados no cabeçalho.
Por razões óbvias, a falta de metadados é prejudicial para o SEO, mas ainda mais para os SPAs. Elementos como um URL canônico auto-referenciado são cruciais para melhorar as chances de uma página JS passar com sucesso pela fila de renderização.
De todos os elementos que devem estar presentes no HTML pré-renderizado, o cabeçalho é o mais importante para a indexação.
Felizmente, esse problema é muito fácil de detectar, porque acionará uma abundância de erros por falta de metadados em qualquer ferramenta de SEO que um site use para relatórios de higiene. Em seguida, você pode confirmar procurando a cabeça no código-fonte.
Causas comuns
Veículo de metadados ausente ou mal configurado
Em uma estrutura JS, um plug-in cria o cabeçalho e insere os metadados no cabeçalho. (O exemplo mais popular é o React Helmet.) Mesmo que um plug-in já esteja instalado, ele geralmente precisa ser configurado corretamente.
Novamente, esta é uma área onde todos os SEOs podem fazer é trazer o problema para o desenvolvedor, explicar o porquê e trabalhar de perto para critérios de aceitação bem documentados.
Problema 6: os recursos não estão sendo rastreados
Arquivos de script e imagens são blocos de construção essenciais no processo de renderização.
Como eles também têm seus próprios URLs, as leis de rastreabilidade também se aplicam a eles. Se o rastreamento dos arquivos for bloqueado, o Google não poderá analisar a página para renderizá-la.
Para ver se os URLs estão sendo rastreados, você pode ver as solicitações anteriores nas estatísticas de rastreamento do GSC.
- Imagens: vá para Configurações > Estatísticas de rastreamento > Solicitações de rastreamento: imagem
- JavaScript: vá para Configurações > Estatísticas de rastreamento > Solicitações de rastreamento: imagem
Causas comuns
Diretório bloqueado por robots.txt
Os URLs de script e imagem geralmente se aninham em seus próprios subdomínios ou subpastas dedicados, portanto, uma expressão de proibição no robots.txt impedirá o rastreamento.
Algumas ferramentas de SEO informam se algum script ou arquivo de imagem está bloqueado, mas o problema é muito fácil de detectar se você souber onde suas imagens e arquivos de script estão aninhados. Você pode procurar essas estruturas de URL no robots.txt.
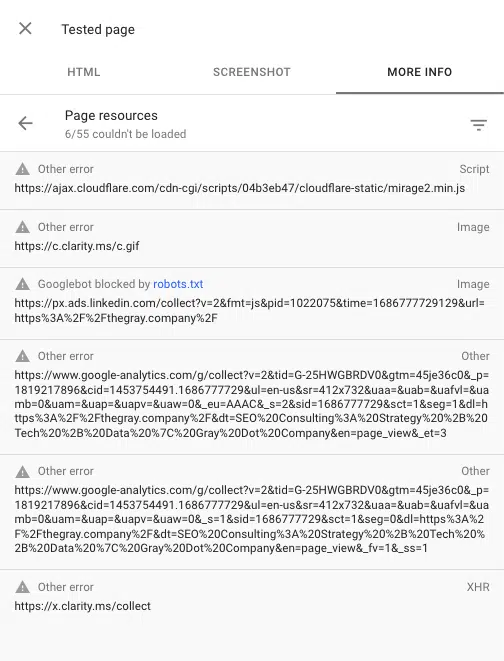
Você também pode ver os scripts bloqueados ao renderizar uma página usando a ferramenta de inspeção de URL no Google Search Console. “Testar URL ao vivo” e vá para Exibir página testada > Mais informações > Recursos da página .
Aqui você pode ver todos os scripts que falham ao carregar durante o processo de renderização. Se um arquivo for bloqueado por robots.txt, ele será marcado como tal.
Faça amizade com JavaScript
Sim, o JavaScript pode trazer alguns problemas de SEO. Mas, à medida que o SEO evolui, as práticas recomendadas estão se tornando sinônimo de uma ótima experiência do usuário.
Uma ótima experiência do usuário geralmente depende do JavaScript. Portanto, embora o trabalho de um SEO não seja codificar JavaScript, precisamos saber como os mecanismos de pesquisa interagem, renderizam e usam.
Com uma sólida compreensão do processo de renderização e alguns problemas comuns de SEO em estruturas JS, você está no caminho certo para identificar os problemas e ser um aliado poderoso para seus desenvolvedores.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.