
SEO de entidades: o guia definitivo
Publicados: 2023-04-06Este artigo foi co-escrito por Andrew Ansley .
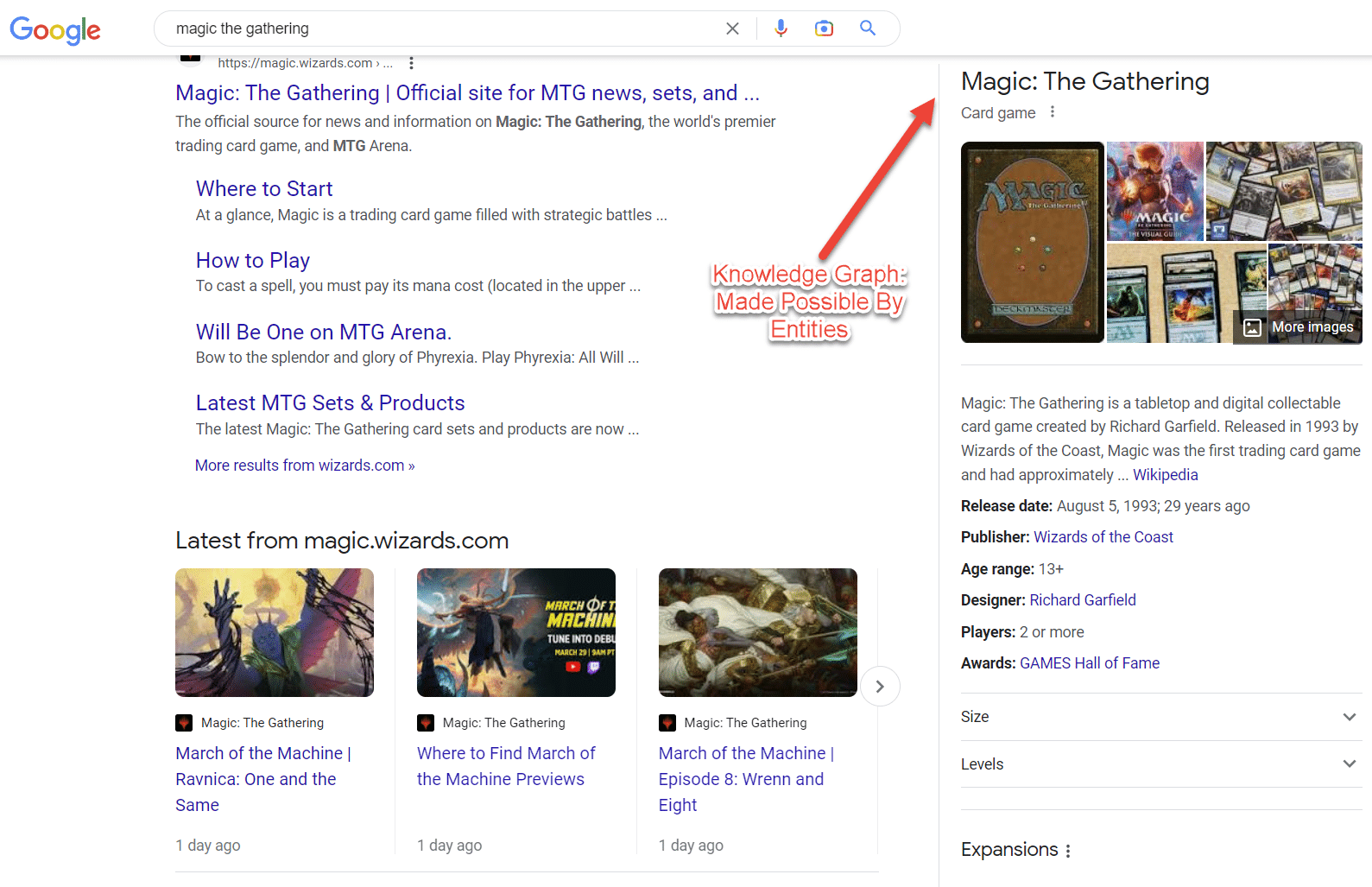
Coisas, não cordas. Se você nunca ouviu isso antes, vem de uma famosa postagem no blog do Google que anunciou o Knowledge Graph.
Falta apenas um mês para o 11º aniversário do anúncio, mas muitos ainda lutam para entender o que realmente significa “coisas, não strings” para SEO.
A citação é uma tentativa de transmitir que o Google entende as coisas e não é mais um simples algoritmo de detecção de palavras-chave.
Em maio de 2012, pode-se argumentar que a entidade SEO nasceu. O aprendizado de máquina do Google, auxiliado por bases de conhecimento semiestruturadas e estruturadas, pode entender o significado por trás de uma palavra-chave.
A natureza ambígua da linguagem finalmente teve uma solução de longo prazo.
Então, se as entidades são importantes para o Google há mais de uma década, por que os SEOs ainda estão confusos sobre as entidades?
Boa pergunta. Vejo quatro razões:
- O termo Entity SEO não tem sido usado amplamente o suficiente para que os SEOs se sintam confortáveis com sua definição e, portanto, incorporem-no em seu vocabulário.
- A otimização para entidades se sobrepõe muito aos antigos métodos de otimização focados em palavras-chave. Como resultado, as entidades são confundidas com palavras-chave. Além disso, não ficou claro como as entidades desempenham um papel no SEO, e a palavra “entidades” às vezes é intercambiável com “tópicos” quando o Google fala sobre o assunto.
- Entender entidades é uma tarefa chata. Se você deseja um conhecimento profundo das entidades, precisará ler algumas patentes do Google e conhecer os fundamentos do aprendizado de máquina. Entity SEO é uma abordagem muito mais científica para SEO – e a ciência simplesmente não é para todos.
- Embora o YouTube tenha impactado massivamente a distribuição de conhecimento, ele nivelou a experiência de aprendizado para muitos assuntos. Os criadores de conteúdo com mais sucesso na plataforma historicamente seguiram o caminho mais fácil ao educar seu público. Como resultado, os criadores de conteúdo não dedicaram muito tempo às entidades até recentemente. Por causa disso, você precisa aprender sobre entidades de pesquisadores de PNL e, em seguida, aplicar o conhecimento ao SEO. Patentes e trabalhos de pesquisa são fundamentais. Mais uma vez, isso reforça o primeiro ponto acima.
Este artigo é uma solução para todos os quatro problemas que impediram os SEOs de dominar totalmente uma abordagem baseada em entidade para SEO.
Ao ler isso, você aprenderá:
- O que é uma entidade e por que ela é importante.
- A história da busca semântica.
- Como identificar e usar entidades na SERP.
- Como usar entidades para classificar o conteúdo da web.
Por que as entidades são importantes?
Entity SEO é o futuro de onde os mecanismos de pesquisa estão indo em relação à escolha de qual conteúdo classificar e determinar seu significado.
Combine isso com a confiança baseada no conhecimento e acredito que o SEO da entidade será o futuro de como o SEO será feito nos próximos dois anos.
Exemplos de entidades
Então, como você reconhece uma entidade?
A SERP tem vários exemplos de entidades que você provavelmente já viu.
Os tipos mais comuns de entidades estão relacionados a locais, pessoas ou empresas.
Talvez o melhor exemplo de entidades na SERP sejam os clusters de intenção. Quanto mais um tópico é compreendido, mais esses recursos de pesquisa surgem.
Curiosamente, uma única campanha de SEO pode alterar a aparência da SERP quando você sabe como executar campanhas de SEO focadas na entidade.
As entradas da Wikipédia são outro exemplo de entidades. A Wikipedia fornece um ótimo exemplo de informações associadas a entidades.
Como você pode ver no canto superior esquerdo, a entidade tem todos os tipos de atributos associados a “peixes”, desde sua anatomia até sua importância para os humanos.
Embora a Wikipedia contenha muitos pontos de dados sobre um tópico, ela não é exaustiva.
O que é uma entidade?
Uma entidade é um objeto ou coisa exclusivamente identificável, caracterizado por seu(s) nome(s), tipo(s), atributos e relacionamentos com outras entidades. Uma entidade só é considerada existente quando existe em um catálogo de entidades.
Os catálogos de entidades atribuem um ID exclusivo a cada entidade. Minha agência possui soluções programáticas que usam o ID exclusivo associado a cada entidade (serviços, produtos e marcas estão incluídos).
Se uma palavra ou frase não estiver dentro de um catálogo existente, isso não significa que a palavra ou frase não seja uma entidade, mas normalmente você pode saber se algo é uma entidade por sua existência no catálogo.
É importante observar que a Wikipedia não é o fator decisivo sobre se algo é uma entidade, mas a empresa é mais conhecida por seu banco de dados de entidades.
Qualquer catálogo pode ser usado quando se fala de entidades. Normalmente, uma entidade é uma pessoa, lugar ou coisa, mas ideias e conceitos também podem ser incluídos.
Alguns exemplos de catálogos de entidades incluem:
- Wikipédia
- Wikidados
- DBpedia
- Freebase
- Yago

As entidades ajudam a preencher a lacuna entre os mundos de dados não estruturados e estruturados.
Eles podem ser usados para enriquecer semanticamente textos não estruturados, enquanto fontes textuais podem ser utilizadas para preencher bases de conhecimento estruturadas.
Reconhecer menções de entidades no texto e associar essas menções com as entradas correspondentes em uma base de conhecimento é conhecido como tarefa de vinculação de entidades.
As entidades permitem uma melhor compreensão do significado do texto, tanto para humanos quanto para máquinas.
Embora os humanos possam resolver com relativa facilidade a ambigüidade das entidades com base no contexto em que são mencionadas, isso apresenta muitas dificuldades e desafios para as máquinas.
A entrada da base de conhecimento de uma entidade resume o que sabemos sobre essa entidade.
Como o mundo está em constante mudança, novos fatos também estão surgindo. Acompanhar essas mudanças requer um esforço contínuo de editores e gerentes de conteúdo. Esta é uma tarefa exigente em escala.
Ao analisar o conteúdo dos documentos em que as entidades são mencionadas, o processo de descoberta de novos fatos ou fatos que precisam ser atualizados pode ser suportado ou mesmo totalmente automatizado.
Os cientistas se referem a isso como o problema da população da base de conhecimento, e é por isso que a vinculação de entidades é importante.
As entidades facilitam a compreensão semântica da necessidade de informação do usuário, conforme expressa pela consulta de palavra-chave e o conteúdo do documento. As entidades, portanto, podem ser usadas para melhorar as representações de consultas e/ou documentos.
No artigo de pesquisa Extended Named Entity, o autor identifica cerca de 160 tipos de entidade. Aqui estão duas das sete capturas de tela da lista.


Certas categorias de entidades são definidas com mais facilidade, mas é importante lembrar que conceitos e ideias são entidades. Essas duas categorias são muito difíceis para o Google escalar por conta própria.
Você não pode ensinar o Google com apenas uma única página ao trabalhar com conceitos vagos. A compreensão da entidade requer muitos artigos e muitas referências sustentadas ao longo do tempo.
Histórico do Google com entidades
Em 16 de julho de 2010, o Google comprou o Freebase. Esta compra foi o primeiro grande passo que deu origem ao atual sistema de busca de entidades.

Depois de investir no Freebase, o Google percebeu que o Wikidata tinha uma solução melhor. O Google então trabalhou para fundir o Freebase no Wikidata, uma tarefa que foi muito mais difícil do que o esperado.
Cinco cientistas do Google escreveram um artigo intitulado “From Freebase to Wikidata: The Great Migration”. Os principais tópicos incluem.
“O Freebase é construído sobre as noções de objetos, fatos, tipos e propriedades. Cada objeto Freebase tem um identificador estável chamado “mid” (para Machine ID).
“O modelo de dados do Wikidata baseia-se nas noções de item e declaração. Um item representa uma entidade, tem um identificador estável chamado “qid” e pode ter rótulos, descrições e aliases em vários idiomas; declarações adicionais e links para páginas sobre a entidade em outros projetos da Wikimedia – principalmente a Wikipedia. Ao contrário do Freebase, as declarações do Wikidata não visam codificar fatos verdadeiros, mas afirmações de diferentes fontes, que também podem se contradizer…”
As entidades são definidas nessas bases de conhecimento, mas o Google ainda precisava construir seu conhecimento de entidade para dados não estruturados (ou seja, blogs).
O Google fez parceria com o Bing e o Yahoo e criou o Schema.org para realizar essa tarefa.
O Google fornece instruções de esquema para que os gerentes de sites tenham ferramentas que ajudem o Google a entender o conteúdo. Lembre-se, o Google quer se concentrar em coisas, não em strings.
Nas palavras do Google:
“Você pode nos ajudar fornecendo pistas explícitas sobre o significado de uma página para o Google, incluindo dados estruturados na página. Dados estruturados são um formato padronizado para fornecer informações sobre uma página e classificar o conteúdo da página; por exemplo, em uma página de receita, quais são os ingredientes, o tempo e a temperatura de cozimento, as calorias e assim por diante.”
O Google continua dizendo:
“Você deve incluir todas as propriedades necessárias para que um objeto seja elegível para exibição na Pesquisa Google com exibição aprimorada. Em geral, definir mais recursos recomendados pode tornar mais provável que suas informações apareçam nos resultados da Pesquisa com exibição aprimorada. No entanto, é mais importante fornecer menos propriedades recomendadas, mas completas e precisas, em vez de tentar fornecer todas as propriedades recomendadas possíveis com dados menos completos, mal formados ou imprecisos.”
Mais poderia ser dito sobre o esquema, mas basta dizer que o esquema é uma ferramenta incrível para SEOs que procuram tornar o conteúdo da página claro para os mecanismos de pesquisa.
A última peça do quebra-cabeça vem do anúncio do blog do Google intitulado “Melhorando a pesquisa nos próximos 20 anos”.
Relevância e qualidade do documento são as principais ideias por trás deste anúncio. O primeiro método usado pelo Google para determinar o conteúdo de uma página era totalmente focado em palavras-chave.
O Google então adicionou camadas de tópicos à pesquisa. Essa camada foi possibilitada por gráficos de conhecimento e coleta e estruturação sistemáticas de dados na web.
Isso nos leva ao sistema de busca atual. O Google passou de 570 milhões de entidades e 18 bilhões de fatos para 800 bilhões de fatos e 8 bilhões de entidades em menos de 10 anos. À medida que esse número cresce, a pesquisa de entidade melhora.
Como o modelo de entidade é uma melhoria em relação aos modelos de pesquisa anteriores?
Os modelos tradicionais de recuperação de informações (IR) baseados em palavras-chave têm uma limitação inerente de não serem capazes de recuperar documentos (relevantes) que não tenham correspondências de termos explícitos com a consulta.
Se você usar ctrl + f para localizar texto em uma página, usará algo semelhante ao modelo tradicional de recuperação de informações baseado em palavras-chave.
Uma quantidade insana de dados é publicada na web todos os dias.
Simplesmente não é viável para o Google entender o significado de cada palavra, cada parágrafo, cada artigo e cada site.
Em vez disso, as entidades fornecem uma estrutura a partir da qual o Google pode minimizar a carga computacional enquanto melhora a compreensão.
“Os métodos de recuperação baseados em conceito tentam enfrentar esse desafio contando com estruturas auxiliares para obter representações semânticas de consultas e documentos em um espaço de conceito de nível superior. Tais estruturas incluem vocabulários controlados (dicionários e tesauros), ontologias e entidades de um repositório de conhecimento”.
– Pesquisa Orientada a Entidade , Capítulo 8.3
Krisztian Balog, que escreveu o livro definitivo sobre entidades, identifica três soluções possíveis para o modelo tradicional de recuperação de informações.
- Baseado em expansão : usa entidades como fonte para expandir a consulta com diferentes termos.
- Baseado em projeção : A relevância entre uma consulta e um documento é entendida projetando-os em um espaço latente de entidades
- Baseada em entidade : representações semânticas explícitas de consultas e documentos são obtidas no espaço da entidade para aumentar as representações baseadas em termos.
O objetivo dessas três abordagens é obter uma representação mais rica das informações necessárias do usuário, identificando entidades fortemente relacionadas à consulta.
Balog então identifica seis algoritmos associados a métodos baseados em projeção de mapeamento de entidade (métodos de projeção relacionados à conversão de entidades em espaço tridimensional e medição de vetores usando geometria).
- Análise semântica explícita (ESA) : A semântica de uma determinada palavra é descrita por um vetor que armazena as forças de associação da palavra aos conceitos derivados da Wikipédia.
- Modelo de espaço de entidade latente (LES) : Baseado em uma estrutura probabilística generativa. A pontuação de recuperação do documento é considerada uma combinação linear da pontuação do espaço da entidade latente e da pontuação de probabilidade da consulta original.
- EsdRank: EsdRank é para classificar documentos, usando uma combinação de recursos de entidade de consulta e documento de entidade. Estes correspondem às noções de projeção de consulta e componentes de projeção de documento do LES, respectivamente, de antes. Usando uma estrutura de aprendizagem discriminativa, sinais adicionais também podem ser incorporados facilmente, como popularidade da entidade ou qualidade do documento
- Classificação semântica explícita (ESR): O modelo de classificação semântica explícita incorpora informações de relacionamento de um gráfico de conhecimento para permitir “correspondência suave” no espaço da entidade.
- Estrutura de dueto palavra-entidade: incorpora interações entre espaços entre representações baseadas em termos e baseadas em entidades, levando a quatro tipos de correspondências: termos de consulta para termos de documento, entidades de consulta para termos de documento, termos de consulta para entidades de documento e entidades de consulta para documentar entidades.
- Modelo de classificação baseado em atenção : Este é de longe o mais complicado de descrever.
Aqui está o que Balog escreve:
“Um total de quatro recursos de atenção são projetados, que são extraídos para cada entidade de consulta. Os recursos de ambiguidade da entidade destinam-se a caracterizar o risco associado a uma anotação de entidade. Estes são: (1) a entropia da probabilidade da forma de superfície estar ligada a diferentes entidades (por exemplo, na Wikipedia), (2) se a entidade anotada é o sentido mais popular da forma de superfície (ou seja, tem a maior semelhança pontuação e (3) a diferença nas pontuações de comunalidade entre os candidatos mais prováveis e os segundos candidatos mais prováveis para a forma de superfície dada. A quarta característica é a proximidade, que é definida como a semelhança de cosseno entre a entidade de consulta e a consulta em um espaço de incorporação . Especificamente, uma incorporação conjunta de termo de entidade é treinada usando o modelo skip-gram em um corpus, onde as menções de entidade são substituídas pelos identificadores de entidade correspondentes. A incorporação da consulta é considerada o centróide das incorporações dos termos da consulta."

Por enquanto, é importante ter familiaridade superficial com esses seis algoritmos centrados na entidade.
A principal conclusão é que existem duas abordagens: projetar documentos em uma camada de entidade latente e anotações explícitas de entidades de documentos.
Três tipos de estruturas de dados
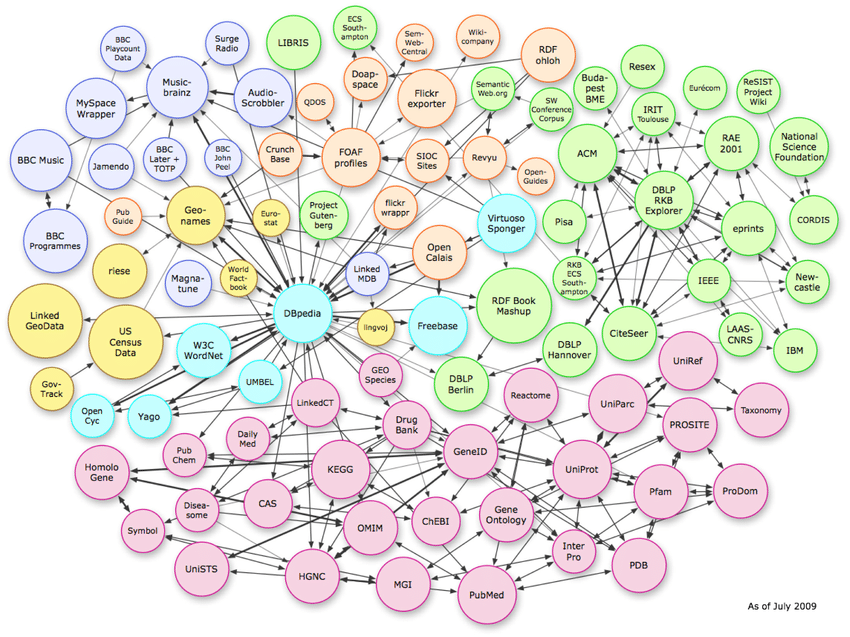
A imagem acima mostra as relações complexas que existem no espaço vetorial. Embora o exemplo mostre as conexões do gráfico de conhecimento, esse mesmo padrão pode ser replicado em um nível de esquema página por página.
Para entender as entidades, é importante conhecer os três tipos de estruturas de dados que os algoritmos usam.
- Usando descrições de entidades não estruturadas , as referências a outras entidades devem ser reconhecidas e sem ambiguidades. Bordas direcionadas (hiperlinks) são adicionadas de cada entidade a todas as outras entidades mencionadas em sua descrição.
- Em um ambiente semi-estruturado (ou seja, Wikipedia), links para outras entidades podem ser explicitamente fornecidos.
- Ao trabalhar com dados estruturados , os triplos RDF definem um gráfico (isto é, o gráfico do conhecimento). Especificamente, os recursos de assunto e objeto (URIs) são nós e os predicados são arestas.
O problema com um contexto semiestruturado e perturbador para pontuação de IR é que, se um documento não estiver configurado para um único tópico, a pontuação de IR pode ser diluída pelos dois contextos diferentes, resultando em uma classificação relativa perdida para outro documento textual.
A diluição do escore de RI envolve relações lexicais mal estruturadas e proximidade de palavras ruins.
As palavras relevantes que se completam devem ser usadas próximas a um parágrafo ou seção do documento para sinalizar o contexto com mais clareza para aumentar a pontuação de IR.
A utilização de atributos e relacionamentos de entidades produz melhorias relativas na faixa de 5 a 20%. A exploração de informações do tipo entidade é ainda mais recompensadora, com melhorias relativas que variam de 25% a mais de 100%.
A anotação de documentos com entidades pode trazer estrutura para documentos não estruturados, o que pode ajudar a preencher bases de conhecimento com novas informações sobre entidades.
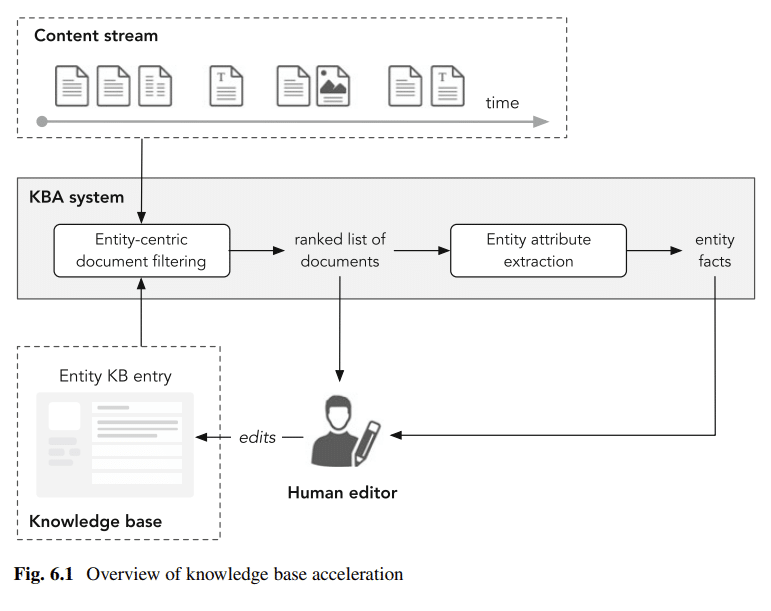
Usando a Wikipedia como sua estrutura de SEO de entidade
Estrutura das páginas da Wikipédia
- Título (E.)
- Seção de chumbo (II.)
- Links de desambiguação (II.a)
- Infobox (II.b)
- Texto introdutório (II.c)
- Índice (III.)
- Conteúdo corporal (IV.)
- Apêndices e matéria de fundo (V.)
- Referências e notas (Va)
- Links externos (Vb)
- Categorias (VC)
A maioria dos artigos da Wikipédia inclui um texto introdutório, o “lead”, um breve resumo do artigo – normalmente, não mais do que quatro parágrafos. Isso deve ser escrito de uma forma que crie interesse no artigo.
A primeira frase e o parágrafo de abertura têm uma importância especial. A primeira frase “pode ser considerada como a definição da entidade descrita no artigo”. O primeiro parágrafo oferece uma definição mais elaborada sem muitos detalhes.
O valor dos links vai além dos propósitos de navegação; eles capturam relações semânticas entre artigos. Além disso, os textos âncora são uma rica fonte de variantes de nomes de entidades. Os links da Wikipédia podem ser usados, entre outros, para ajudar a identificar e eliminar a ambiguidade de menções de entidades no texto.
- Resuma os principais fatos sobre a entidade (caixa de informações).
- Breve introdução.
- Links Internos. Uma regra fundamental fornecida aos editores é vincular apenas à primeira ocorrência de uma entidade ou conceito.
- Inclua todos os sinônimos populares de uma entidade.
- Designação da página da categoria.
- Modelo de navegação.
- Referências.
- Ferramentas especiais de análise para entender as páginas do Wiki.
- Vários tipos de mídia.
Como otimizar para entidades
A seguir estão as principais considerações ao otimizar entidades para pesquisa:
- A inclusão de palavras semanticamente relacionadas em uma página.
- Frequência de palavras e frases em uma página.
- A organização de conceitos em uma página.
- Incluindo dados não estruturados, dados semiestruturados e dados estruturados em uma página.
- Pares Sujeito-Predicado-Objeto (SPO).
- Documentos da Web em um site que funcionam como páginas de um livro.
- Organização de documentos da web em um site.
- Inclua conceitos em um documento da Web que sejam recursos conhecidos de entidades.
Observação importante: quando a ênfase está nos relacionamentos entre entidades, uma base de conhecimento é geralmente chamada de gráfico de conhecimento.
Como a intenção está sendo analisada em conjunto com os logs de pesquisa do usuário e outras partes do contexto, a mesma frase de pesquisa da pessoa 1 pode gerar um resultado diferente da pessoa 2. A pessoa pode ter uma intenção diferente com exatamente a mesma consulta.
Se sua página abranger ambos os tipos de intenção, ela é uma candidata melhor para classificação na web. Você pode usar a estrutura de bases de conhecimento para orientar seus modelos de intenção de consulta (conforme mencionado em uma seção anterior).
As pessoas também perguntam, as pessoas pesquisam e o preenchimento automático estão semanticamente relacionados à consulta enviada e se aprofundam na direção de pesquisa atual ou se movem para um aspecto diferente da tarefa de pesquisa.
Sabemos disso, então como podemos otimizar para isso?
Seus documentos devem conter o máximo possível de variações de intenção de pesquisa. Seu site deve conter todas as variações de intenção de pesquisa para seu cluster. O agrupamento depende de três tipos de similaridade:
- Semelhança lexical.
- Similaridade semântica.
- Clique em similaridade.
Cobertura do tópico
O que é –> Lista de atributos –> Seção dedicada a cada atributo –> Cada seção vincula a um artigo totalmente dedicado a esse tópico –> O público deve ser especificado e as definições para a subseção devem ser especificadas –> O que deve ser considerado ? –> Quais são os benefícios? –> Benefícios do modificador –> O que é ___ –> O que ele faz? –> Como conseguir –> Como fazer –> Quem pode fazer –> Link para todas as categorias

O Google oferece uma ferramenta que fornece uma pontuação de relevância (semelhante a como usamos a palavra “força” ou “confiança”) que informa como o Google vê o conteúdo.

O exemplo acima vem de um artigo do Search Engine Land sobre entidades de 2018.
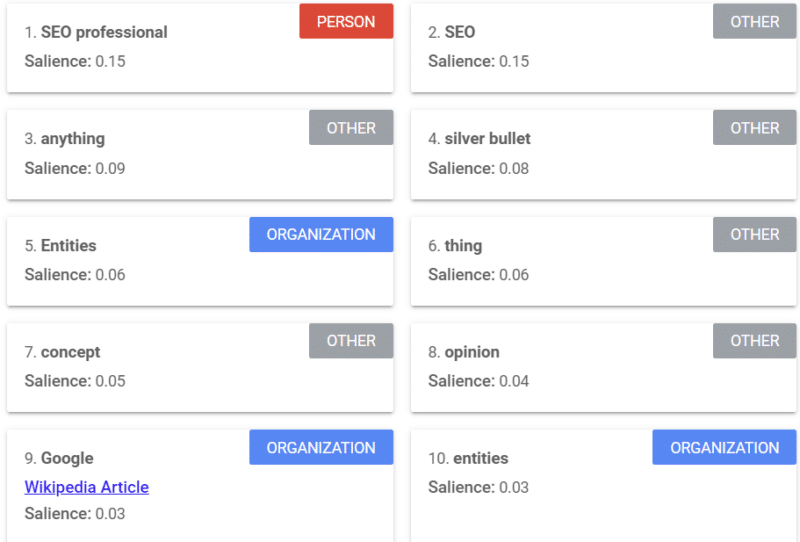
Você pode ver pessoas, outros e organizações no exemplo. A ferramenta é a API de linguagem natural do Google Cloud.
Cada palavra, frase e parágrafo são importantes quando se fala sobre uma entidade. A forma como você organiza seus pensamentos pode mudar a compreensão do Google sobre seu conteúdo.
Você pode incluir uma palavra-chave sobre SEO, mas o Google entende essa palavra-chave da maneira que você deseja?
Tente colocar um ou dois parágrafos na ferramenta e reorganizar e modificar o exemplo para ver como ele aumenta ou diminui a relevância.
Esse exercício, chamado de “desambiguação”, é extremamente importante para as entidades. A linguagem é ambígua, por isso devemos tornar nossas palavras menos ambíguas para o Google.
Abordagens modernas de desambiguação consideram três tipos de evidência:
Prioridade de entidades e menções.
Semelhança contextual entre o texto que envolve a menção e a entidade candidata e coerência entre todas as decisões de vinculação de entidade no documento.
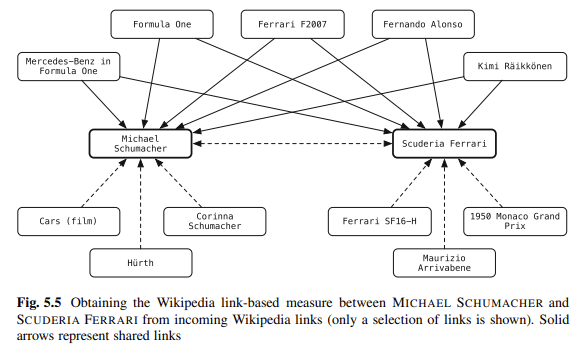
O esquema é uma das minhas formas favoritas de eliminar a ambiguidade do conteúdo. Você está vinculando entidades em seu blog a repositórios de conhecimento. Balog diz:
“[L]inking entidades em texto não estruturado para um repositório de conhecimento estruturado pode capacitar muito os usuários em suas atividades de consumo de informações.”
Por exemplo, os leitores de um documento podem obter informações contextuais ou básicas com um único clique e podem obter acesso fácil a entidades relacionadas.
As anotações de entidade também podem ser usadas no processamento downstream para melhorar o desempenho da recuperação ou para facilitar uma melhor interação do usuário com os resultados da pesquisa.
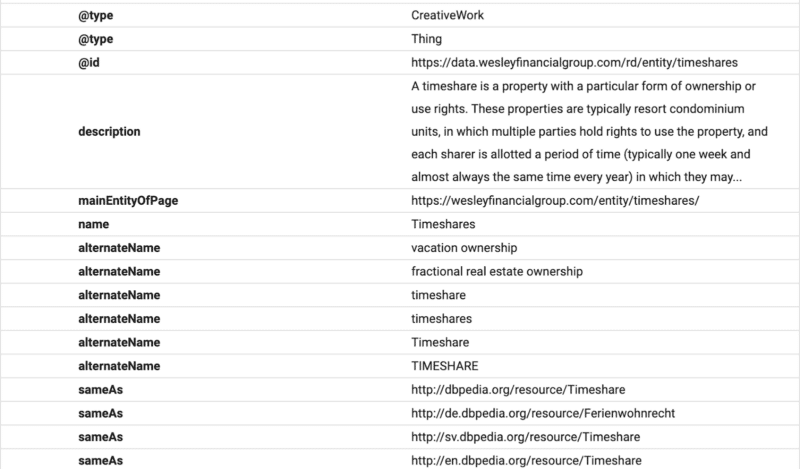
Aqui você pode ver que o conteúdo do FAQ está estruturado para o Google usando o esquema do FAQ.
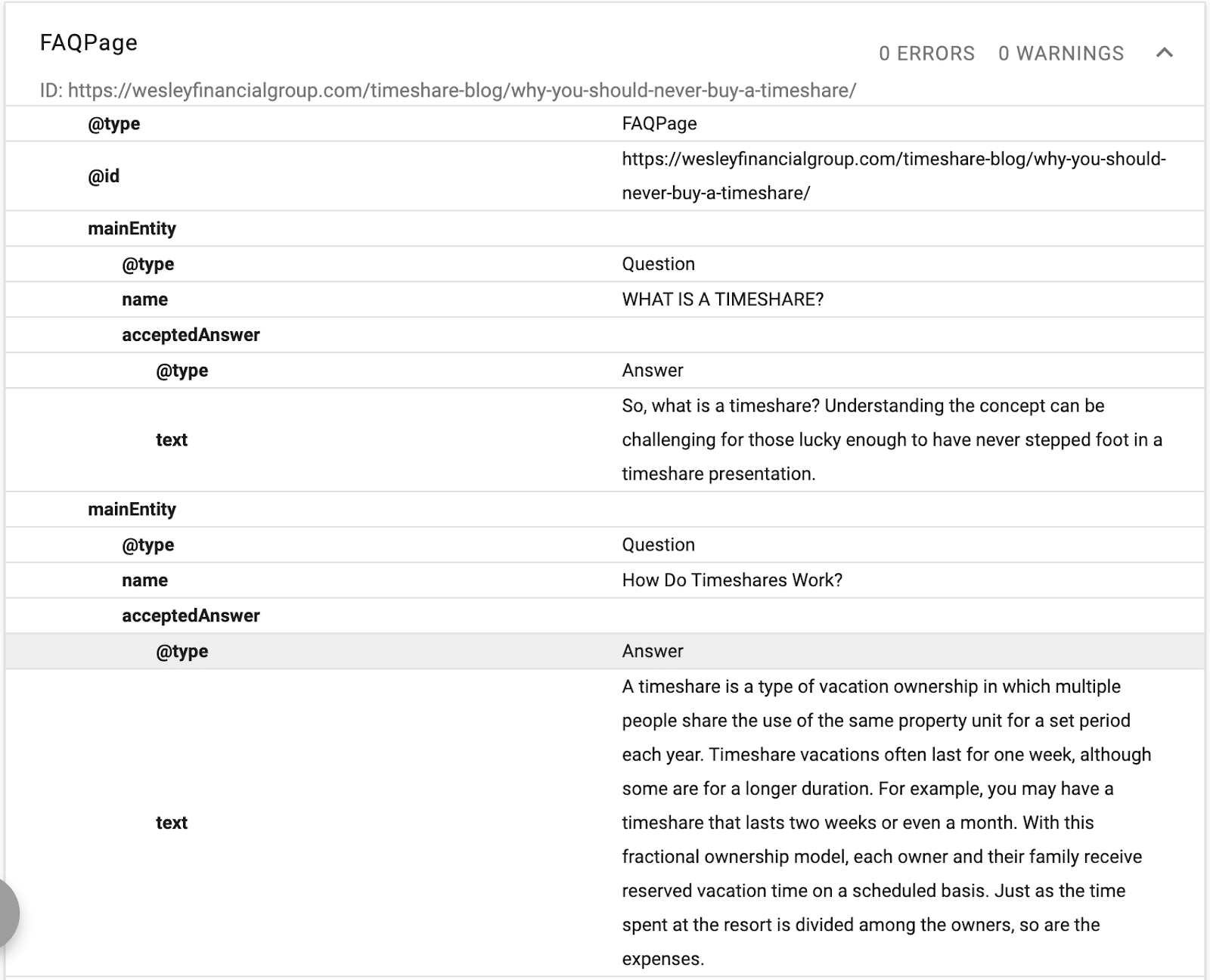
Neste exemplo, você pode ver o esquema fornecendo uma descrição do texto, um ID e uma declaração da entidade principal da página.
(Lembre-se, o Google quer entender a hierarquia do conteúdo, e é por isso que H1–H6 é importante.)
Você verá nomes alternativos e o mesmo que declarações. Agora, ao ler o conteúdo, o Google saberá qual banco de dados estruturado associar ao texto e terá sinônimos e versões alternativas de uma palavra vinculada à entidade.
Ao otimizar com esquema, você otimiza para NER (reconhecimento de entidade nomeada), também conhecido como identificação de entidade, extração de entidade e fragmentação de entidade.
A ideia é se engajar em Desambiguação de Entidades Nomeadas > Wikificação > Vinculação de Entidades.
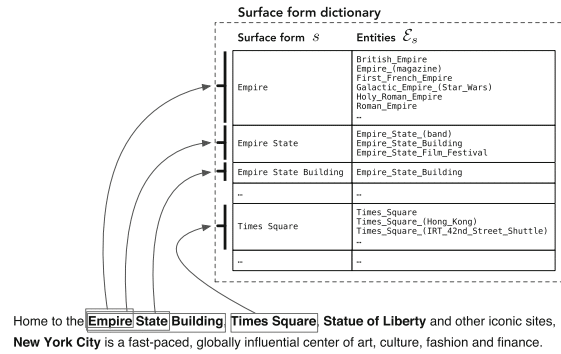
“O advento da Wikipédia facilitou o reconhecimento e desambiguação de entidades em larga escala, fornecendo um catálogo abrangente de entidades junto com outros recursos inestimáveis (especificamente, hiperlinks, categorias e páginas de redirecionamento e desambiguação).
– Pesquisa Orientada a Entidades
Como vá além das sugestões de ferramentas de SEO
A maioria dos SEOs usa alguma ferramenta na página para otimizar seu conteúdo. Cada ferramenta é limitada em sua capacidade de identificar oportunidades de conteúdo exclusivas e sugestões de profundidade de conteúdo.
Na maioria das vezes, as ferramentas na página estão apenas agregando os principais resultados da SERP e criando uma média para você emular.
Os SEOs devem lembrar que o Google não está procurando as mesmas informações refeitas. Você pode copiar o que os outros estão fazendo, mas informações exclusivas são a chave para se tornar um site de semente/autoridade.
Aqui está uma descrição simplificada de como o Google lida com novos conteúdos:
Uma vez encontrado um documento que mencione uma determinada entidade, esse documento pode ser verificado para possivelmente descobrir novos fatos com os quais a entrada da base de conhecimento dessa entidade pode ser atualizada.
Balog escreve:
“Desejamos ajudar os editores a se manterem informados sobre as mudanças, identificando automaticamente o conteúdo (artigos de notícias, postagens de blog etc.) responsável por)."
Qualquer um que aprimore as bases de conhecimento, o reconhecimento de entidades e a rastreabilidade das informações obterá o amor do Google.
As alterações feitas no repositório de conhecimento podem ser rastreadas até o documento como fonte original.
Se você fornecer conteúdo que abranja o tópico e adicionar um nível de profundidade raro ou novo, o Google poderá identificar se seu documento adicionou essas informações exclusivas.
Eventualmente, essas novas informações mantidas por um período de tempo podem levar seu site a se tornar uma autoridade.
Esta não é uma autoridade baseada na classificação do domínio, mas na cobertura tópica, que acredito ser muito mais valiosa.
Com a abordagem de entidade para SEO, você não está limitado a segmentar palavras-chave com volume de pesquisa.
Tudo o que você precisa fazer é validar o termo principal (“varas de pesca com mosca”, por exemplo) e, em seguida, pode se concentrar em segmentar variações de intenção de pesquisa com base no bom e velho pensamento humano da moda.
Começamos com a Wikipédia. Para o exemplo da pesca com mosca, podemos ver que, no mínimo, os seguintes conceitos devem ser abordados em um site de pesca:
- Espécies de peixes, história, origens, desenvolvimento, melhorias tecnológicas, expansão, métodos de pesca com mosca, casting, spey casting, pesca com mosca de truta, técnicas de pesca com mosca, pesca em água fria, pesca de truta com mosca seca, ninfa para truta, água parada pesca de truta, jogar truta, soltar truta, pesca com mosca de água salgada, equipamento, moscas artificiais e nós.
Os tópicos acima vieram da página da Wikipedia sobre pesca com mosca. Embora esta página forneça uma ótima visão geral dos tópicos, gosto de adicionar ideias de tópicos adicionais que vêm de tópicos semanticamente relacionados.
Para o tópico “peixe”, podemos adicionar vários tópicos adicionais, incluindo etimologia, evolução, anatomia e fisiologia, comunicação dos peixes, doenças dos peixes, conservação e importância para os seres humanos.
Alguém ligou a anatomia da truta à eficácia de certas técnicas de pesca?
Um único site de pesca cobriu todas as variedades de peixes, vinculando os tipos de técnicas de pesca, varas e iscas para cada peixe?
Até agora, você deve ser capaz de ver como a expansão do tópico pode crescer. Tenha isso em mente ao planejar uma campanha de conteúdo.
Não apenas refaça. Adicionar valor. Seja único. Use os algoritmos mencionados neste artigo como seu guia.
Conclusão
Este artigo faz parte de uma série de artigos focados em entidades. No próximo artigo, aprofundarei os esforços de otimização em torno de entidades e algumas ferramentas com foco em entidades no mercado.
Quero terminar este artigo dando um alô para duas pessoas que me explicaram muitos desses conceitos.
Bill Slawski da SEO by the Sea e Koray Tugbert da Holistic SEO. Embora Slawski não esteja mais conosco, suas contribuições continuam a ter um efeito cascata na indústria de SEO.
Eu confio fortemente nas seguintes fontes para o conteúdo do artigo, pois essas fontes são os melhores recursos existentes sobre o assunto:
- Hierarquia estendida de entidades nomeadas por Satoshi Ketine, Kiyoshi Sudo e Chikashi Nobata
- Busca Orientada a Entidades por Krisztian Balog , Information Retrieval Series (INRE, volume 39)
- Reescrita de consulta com detecção de entidade , patente do Google
- Refinando consultas de pesquisa , patente do Google
- Associando uma entidade a uma consulta de pesquisa , patente do Google
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.