
Como o Apache Spark pode dar asas à análise de companhias aéreas?
Publicados: 2015-10-30A indústria global de companhias aéreas continua a crescer rapidamente, mas a lucratividade consistente e robusta ainda está para ser vista. De acordo com a Associação Internacional de Transporte Aéreo (IATA), o setor dobrou sua receita na última década, de US$ 369 bilhões em 2005 para US$ 727 bilhões em 2015.

No setor de aviação comercial, todos os participantes da cadeia de valor – aeroportos, fabricantes de aviões, fabricantes de motores a jato, agentes de viagens e empresas de serviços obtêm um lucro considerável.
Todos esses players geram individualmente volumes de dados extremamente altos devido ao maior churn de transações de voos. Identificar e capturar a demanda é a chave aqui, que oferece uma oportunidade muito maior para as companhias aéreas se diferenciarem. Assim, as indústrias de aviação podem utilizar insights de big data para aumentar suas vendas e melhorar a margem de lucro.
Big data é um termo para coleta de conjuntos de dados tão grandes e complexos que sua computação não pode ser tratada por sistemas tradicionais de processamento de dados ou ferramentas de SGBD disponíveis.
O Apache Spark é uma estrutura de computação em cluster distribuída de código aberto projetada especificamente para consultas interativas e algoritmos iterativos.
A abstração do Spark DataFrame é um objeto de dados tabular semelhante ao dataframe nativo do R ou pacote de pandas Pythons, mas armazenado no ambiente de cluster.
De acordo com a última pesquisa da Fortunes, o Apache Spark é a tecnologia mais popular de 2015.
O maior fornecedor de Hadoop Cloudera também está dizendo adeus ao Hadoops MapReduce e Olá ao Spark.
O que realmente dá ao Spark vantagem sobre o Hadoop é a velocidade . O Spark lida com a maioria de suas operações na memória – copiando-as do armazenamento físico distribuído para uma memória RAM lógica muito mais rápida. Isso reduz a quantidade de tempo consumido na gravação e leitura de e para discos rígidos mecânicos lentos e desajeitados que precisam ser feitos no sistema Hadoops MapReduce.
Além disso, o Spark inclui ferramentas (processamento em tempo real, aprendizado de máquina e SQL interativo) que são bem elaboradas para impulsionar os objetivos de negócios, como analisar dados em tempo real combinando dados históricos de dispositivos conectados, também conhecidos como Internet das coisas .
Hoje, vamos reunir alguns insights sobre dados de aeroportos de amostra usando o Apache Spark .
No blog anterior vimos como lidar com dados estruturados e semiestruturados no Spark usando a nova API Dataframes e também abordamos como processar dados JSON de forma eficiente.
Neste blog, entenderemos como consultar dados em DataFrames usando SQL , bem como salvar a saída no sistema de arquivos no formato CSV.
Usando a biblioteca de análise CSV do Databricks
Para isso, vou usar uma biblioteca de análise de CSV fornecida pela Databricks , uma empresa fundada pelos criadores do Apache Spark e que atualmente lida com o desenvolvimento e as distribuições do Spark.
A comunidade Spark consiste em cerca de 600 contribuidores que o tornam o projeto mais ativo em toda a Apache Software Foundation, um importante órgão regulador de software de código aberto, em termos de número de contribuidores.
A biblioteca Spark-csv nos ajuda a analisar e consultar dados csv no spark. Podemos usar essa biblioteca para ler e gravar dados csv de e para qualquer sistema de arquivos compatível com Hadoop.
Carregando os dados no Spark DataFrames
Vamos carregar nossos arquivos de entrada em um Spark DataFrames usando a biblioteca de análise spark-csv do Databricks.
Você pode usar essa biblioteca no shell do Spark especificando –packages com.databricks: spark-csv_2.10:1.0.3
Ao iniciar o shell como mostrado abaixo:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
Lembre-se de que você deve estar conectado à Internet, porque o pacote spark-csv será baixado automaticamente quando você der este comando. Estou usando a versão 1.4.0 do Spark
Vamos criar sqlContext com o objeto SparkContext(sc) já criado
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Agora vamos carregar nossos dados csv do arquivo airports.csv (airport csv github) cujo esquema é o seguinte
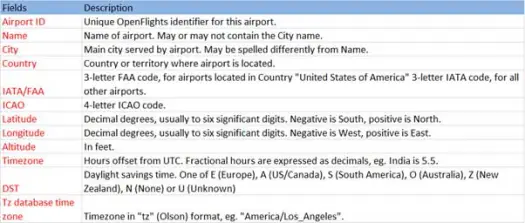
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))A operação de carregamento analisará o arquivo *.csv usando a biblioteca Databricks spark-csv e retornará um dataframe com nomes de coluna iguais aos da primeira linha de cabeçalho do arquivo.
A seguir estão os parâmetros passados para o método load.
- Fonte : "com.databricks.spark.csv" informa ao Spark que queremos carregar como arquivo csv.
- Opções:
- path – caminho do arquivo, onde está localizado.
- Header : "header" -> "true" diz ao Spark para mapear a primeira linha do arquivo para os nomes das colunas para o dataframe resultante.
Vamos ver qual é o esquema do nosso Dataframe
Confira os dados de amostra em nosso dataframe
scala> airportDF.show

Consultando dados CSV usando tabelas temporárias:

Para executar uma consulta em uma tabela, chamamos o método sql() no SQLContext.
Criamos o DataFrame dos aeroportos e carregamos os dados CSV, para consultar esses dados do DF temos que registrá-los como uma tabela temporária chamada aeroportos.
>
scala> airportDF.registerTempTable("airports")
Vamos descobrir quantos aeroportos existem na parte sudeste em nosso conjunto de dados
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Podemos fazer agregações em consultas sql no Spark
Descobriremos quantas cidades únicas têm aeroportos em cada país
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Qual é a altitude média (em pés) dos aeroportos em cada país?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Agora, para descobrir em cada fuso horário quantos aeroportos estão operando?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
Também podemos calcular a latitude e longitude médias desses aeroportos em cada país
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Vamos contar quantos DSTs diferentes existem
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Salvando dados no formato CSV
Até agora, carregamos e consultamos dados csv. Agora veremos como salvar os resultados no formato CSV de volta ao sistema de arquivos.
Suponha que queremos enviar um relatório ao cliente sobre todos os aeroportos na parte noroeste de todos os países.
Vamos calcular isso primeiro.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
E salve-o no arquivo CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
A seguir estão os parâmetros passados para salvar o método.
- Fonte : é igual ao método de carregamento com.databricks.spark.csv , que informa ao Spark para salvar dados como csv.
- SaveMode : Isso permite que o usuário especifique antecipadamente o que precisa ser feito se o caminho de saída fornecido já existir. Para que os dados existentes não sejam perdidos/substituídos por engano. Você pode lançar erro, anexar ou substituir. Aqui, lançamos um erro ErrorIfExists , pois não queremos substituir nenhum arquivo existente.
- Options : Essas opções são as mesmas que passamos para o método load . Opções:
- path – caminho do arquivo, onde deve ser armazenado.
- Header : "header" -> "true" diz ao spark para mapear os nomes das colunas do dataframe para a primeira linha do arquivo de saída resultante.
Convertendo outros formatos de dados para CSV
Também podemos converter qualquer outro formato de dados como JSON, parquet, texto para CSV usando esta biblioteca.
No blog anterior, criamos dados json. você encontra no github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
vamos apenas salvá-lo como CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Conclusão:
Neste post, reunimos alguns insights sobre dados de aeroportos usando consultas interativas do SparkSQL
e explorou a biblioteca de análise csv do Spark
No próximo blog vamos explorar um componente muito importante do Spark, ou seja, Spark Streaming.
O Spark Streaming permite que os usuários coletem dados em tempo real no Spark e os processem à medida que acontecem e entregam os resultados instantaneamente.