
Como usar entidades do Google e GPT-4 para criar esboços de artigos
Publicados: 2023-06-06Neste artigo, você aprenderá como usar algumas raspagens e o Knowledge Graph do Google para fazer uma engenharia de prompt automatizada que gera um esboço e um resumo para um artigo que, se bem escrito, conterá muitos ingredientes-chave para uma boa classificação.
Na raiz das coisas, estamos dizendo ao GPT-4 para produzir um esboço de artigo com base em uma palavra-chave e nas principais entidades encontradas em uma página de boa classificação de sua escolha.
As entidades são ordenadas por sua pontuação de saliência.
“Por que pontuação de saliência?” você pode perguntar.
O Google descreve a relevância em seus documentos de API como:
“A pontuação de saliência de uma entidade fornece informações sobre a importância ou centralidade dessa entidade para todo o texto do documento. Pontuações mais próximas de 0 são menos salientes, enquanto pontuações mais próximas de 1,0 são altamente salientes.”
Parece uma métrica muito boa para usar para influenciar quais entidades devem existir em um conteúdo que você deseja escrever, não é?
Começando
Existem duas maneiras de fazer isso:
- Gaste cerca de 5 minutos (talvez 10 se você precisar configurar seu computador) e execute os scripts de sua máquina ou…
- Vá para o Colab que criei e comece a brincar imediatamente.
Sou parcial com o primeiro, mas também pulei para um ou dois Colab na minha época. 😀
Supondo que você ainda esteja aqui e queira configurar isso em sua própria máquina, mas ainda não tenha o Python instalado ou um IDE (Integrated Development Environment), vou direcioná-lo primeiro para uma leitura rápida sobre como configurar sua máquina para usar Caderno Jupyter. Não deve demorar mais do que cerca de 5 minutos.
Agora, é hora de ir!
Usando entidades do Google e GPT-4 para criar esboços de artigos
Para facilitar o acompanhamento, formatarei as instruções da seguinte maneira:
- Etapa : uma breve descrição da etapa em que estamos.
- Código : o código para concluir essa etapa.
- Explicação : Uma breve explicação sobre o que o código está fazendo.
Passo 1: Diga-me o que você quer
Antes de mergulharmos na criação dos contornos, precisamos definir o que queremos.
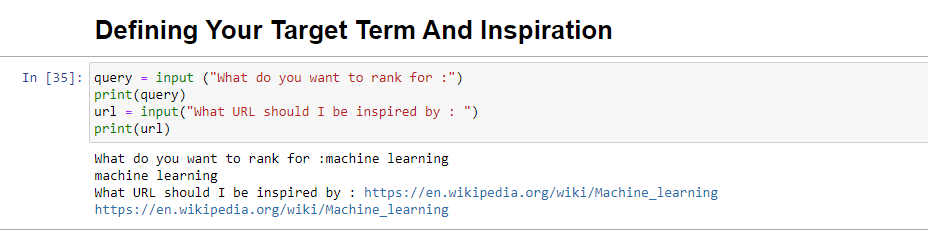
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)Quando executado, esse bloco solicitará que o usuário (provavelmente você) insira a consulta para a qual você gostaria que o artigo se classificasse/se tratasse, além de fornecer um local para colocar a URL de um artigo que você gostaria que sua peça para se inspirar.
Sugiro um artigo que tenha uma boa classificação, esteja em um formato que funcione para o seu site e que você considere merecedor das classificações apenas pelo valor do artigo e não apenas pela força do site.
Ao executar, ficará assim:
Etapa 2: Instalando as bibliotecas necessárias
Em seguida, devemos instalar todas as bibliotecas que usaremos para fazer a mágica acontecer.
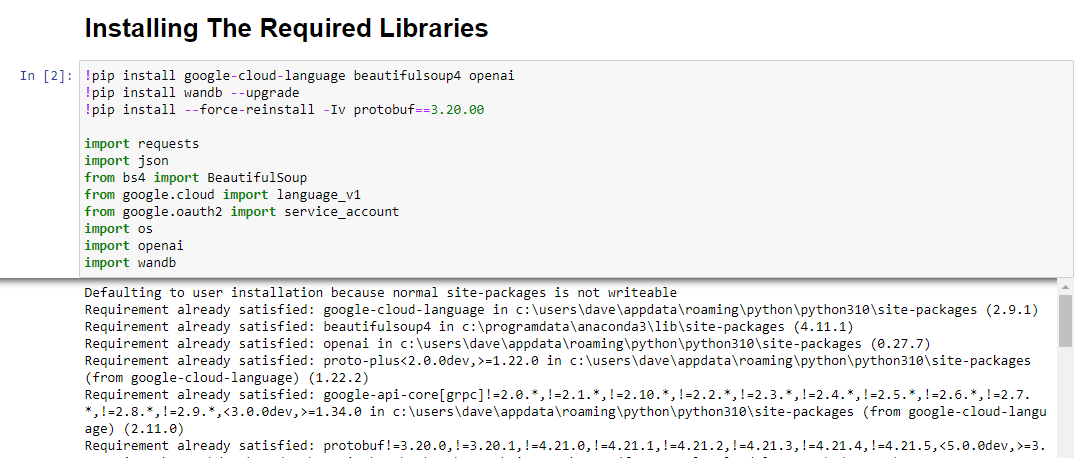
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbEstamos instalando as seguintes bibliotecas:
- Requests : Esta biblioteca permite fazer solicitações HTTP para recuperar conteúdo de sites ou APIs da web.
- JSON : fornece funções para trabalhar com dados JSON, incluindo a análise de strings JSON em objetos Python e a serialização de objetos Python em strings JSON.
- BeautifulSoup : esta biblioteca é usada para fins de raspagem da web. Ele ajuda na análise e navegação de documentos HTML ou XML e na extração de informações relevantes deles.
- Google.cloud.language_v1 : é uma biblioteca do Google Cloud que fornece recursos de processamento de linguagem natural. Ele permite a execução de várias tarefas, como análise de sentimento, reconhecimento de entidade e análise de sintaxe em dados de texto.
- Google.oauth2.service_account : esta biblioteca faz parte do pacote Google OAuth2 Python. Ele fornece suporte para autenticação com APIs do Google usando uma conta de serviço, que é uma forma de conceder acesso limitado aos recursos de um projeto do Google Cloud.
- OS : Esta biblioteca fornece uma maneira de interagir com o sistema operacional. Permite acessar diversas funcionalidades como operações de arquivos, variáveis de ambiente e gerenciamento de processos.
- OpenAI : esta biblioteca é o pacote OpenAI Python. Ele fornece uma interface para interagir com os modelos de linguagem do OpenAI, incluindo GPT-4 (e 3). Ele permite que os desenvolvedores gerem texto, executem conclusões de texto e muito mais.
- Pandas : É uma biblioteca poderosa para manipulação e análise de dados. Ele fornece estruturas de dados e funções para manipular e analisar com eficiência dados estruturados, como tabelas ou arquivos CSV.
- WandB : Esta biblioteca significa “Weights & Biases” e é uma ferramenta para rastreamento e visualização de experimentos. Ele ajuda a registrar e visualizar as métricas, hiperparâmetros e outros aspectos importantes dos experimentos de aprendizado de máquina.
Quando executado, ele se parece com isso:
Obtenha a newsletter diária em que os profissionais de marketing de busca confiam.
Consulte os termos.
Passo 3: Autenticação
Vou ter que nos desviar por um momento para partir e colocar nossa autenticação no lugar. Vamos precisar de uma chave de API OpenAI e credenciais de pesquisa do Google Knowledge Graph.
Isso levará apenas alguns minutos.
Obtendo sua API OpenAI
No momento, você provavelmente precisará entrar na lista de espera. Tenho sorte de ter acesso à API antecipadamente e, por isso, estou escrevendo isso para ajudá-lo a se preparar assim que conseguir.
As imagens de inscrição são do GPT-3 e serão atualizadas para o GPT-4 assim que o fluxo estiver disponível para todos.
Antes de poder usar o GPT-4, você precisará de uma chave de API para acessá-lo.
Para obter um, basta acessar a página do produto da OpenAI e clicar em Começar .
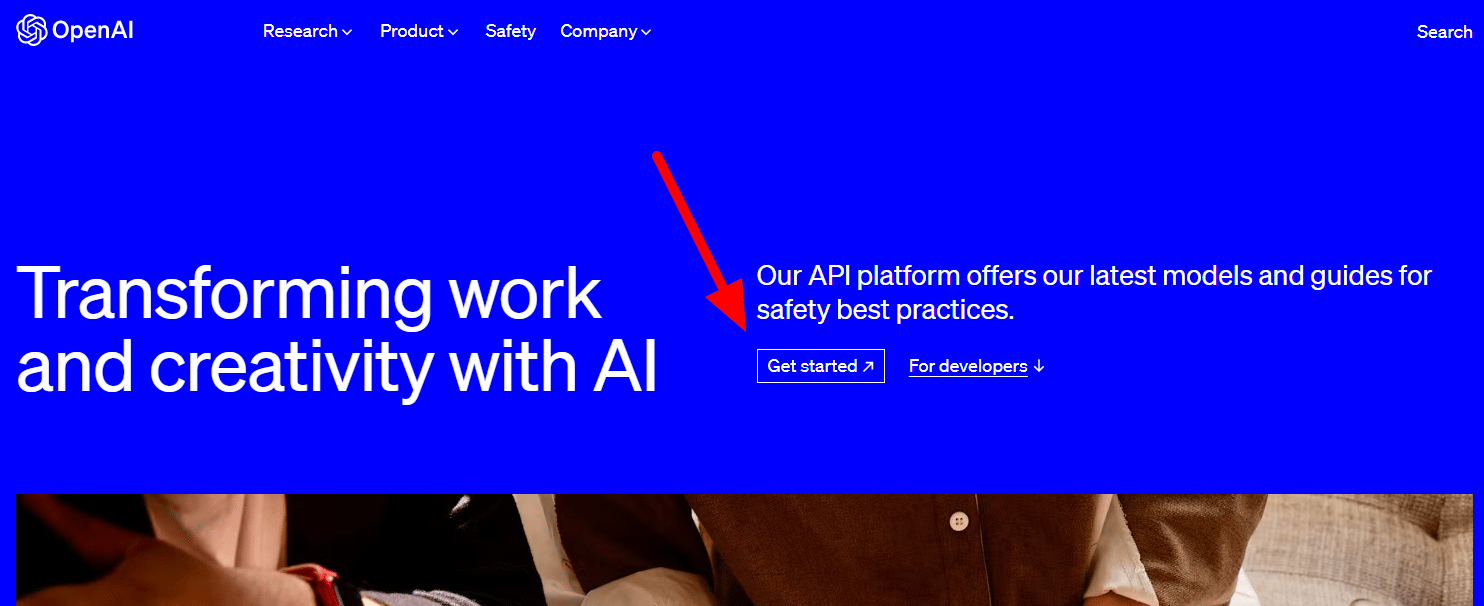
Escolha seu método de inscrição (eu escolhi o Google) e execute o processo de verificação. Você precisará de acesso a um telefone que possa receber mensagens de texto para esta etapa.
Depois de concluído, você criará uma chave de API. Isso é para que a OpenAI possa conectar seus scripts à sua conta.
Eles devem saber quem está fazendo o quê e determinar se e quanto devem cobrar pelo que você está fazendo.
Preços do OpenAI
Ao se inscrever, você recebe um crédito de $ 5 que o levará surpreendentemente longe se estiver apenas experimentando.
No momento em que este artigo foi escrito, o preço passado é:

Criando sua chave OpenAI
Para criar sua chave, clique em seu perfil no canto superior direito e escolha Exibir chaves de API .
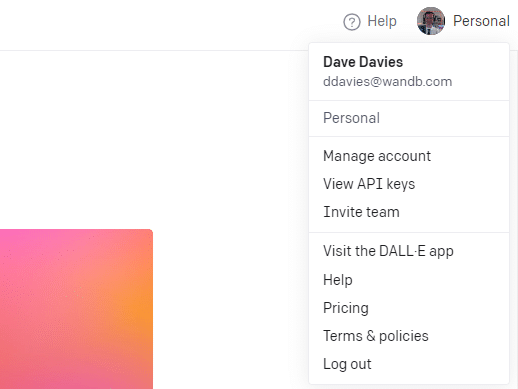
...e então você criará sua chave.
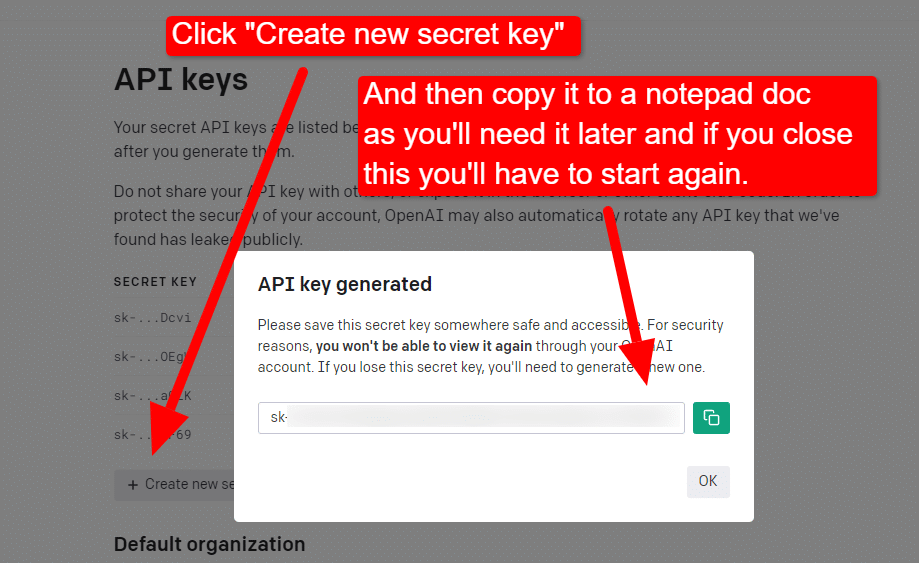
Depois de fechar o lightbox, você não poderá visualizar sua chave e terá que recriá-la, portanto, para este projeto, basta copiá-lo para um documento do Bloco de Notas para usar em breve.
Observação: não salve sua chave (um documento do bloco de notas em sua área de trabalho não é altamente seguro). Depois de usá-lo momentaneamente, feche o documento do bloco de notas sem salvá-lo.
Obtendo sua autenticação do Google Cloud
Primeiro, você precisará fazer login na sua conta do Google. (Você está em um site de SEO, então suponho que você tenha um. 🙂)
Depois de fazer isso, você pode revisar as informações da API do Knowledge Graph se desejar ou pular direto para o API Console e continuar.
Quando estiver no console:
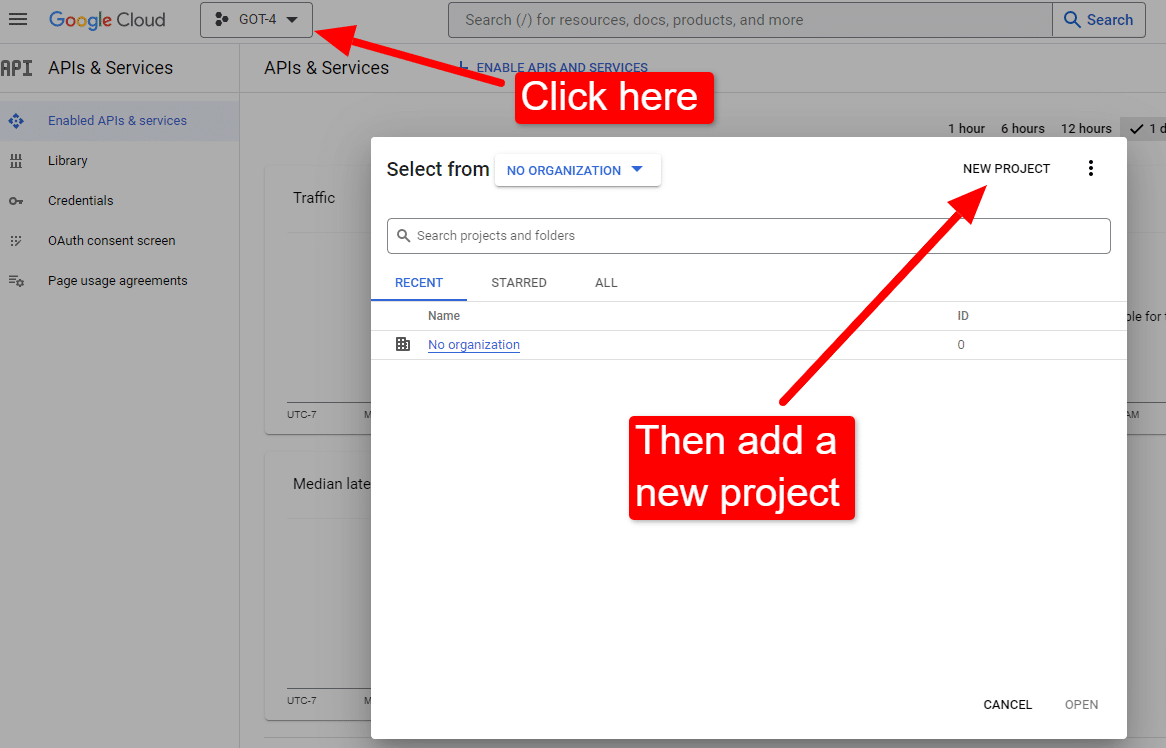
Nomeie algo como "Artigos incríveis de Dave". Você sabe... fácil de lembrar.
Em seguida, você ativará a API clicando em Ativar APIs e serviços .

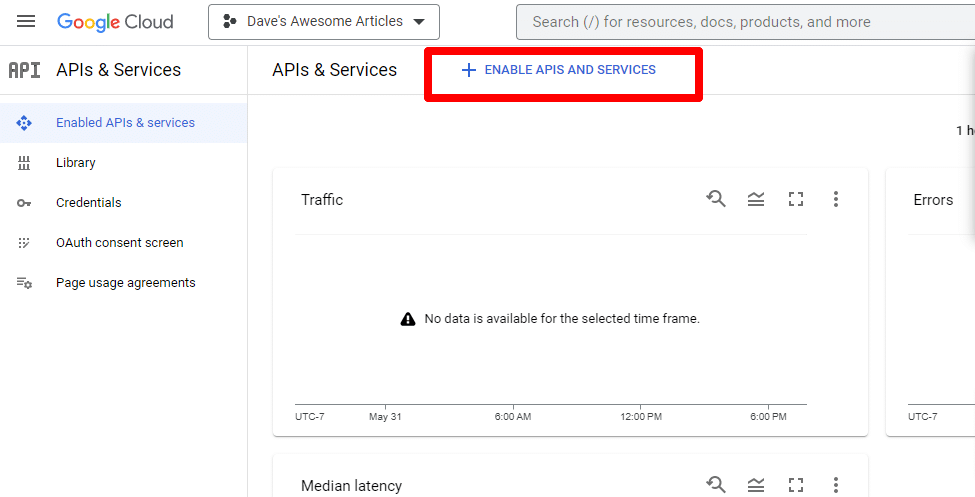
Encontre a API de pesquisa do Knowledge Graph e ative-a.
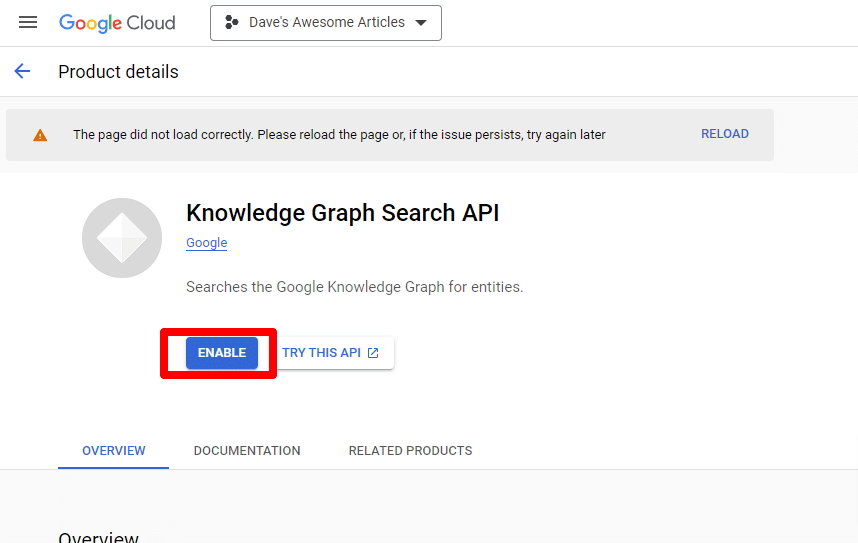
Você será levado de volta à página principal da API, onde poderá criar credenciais:
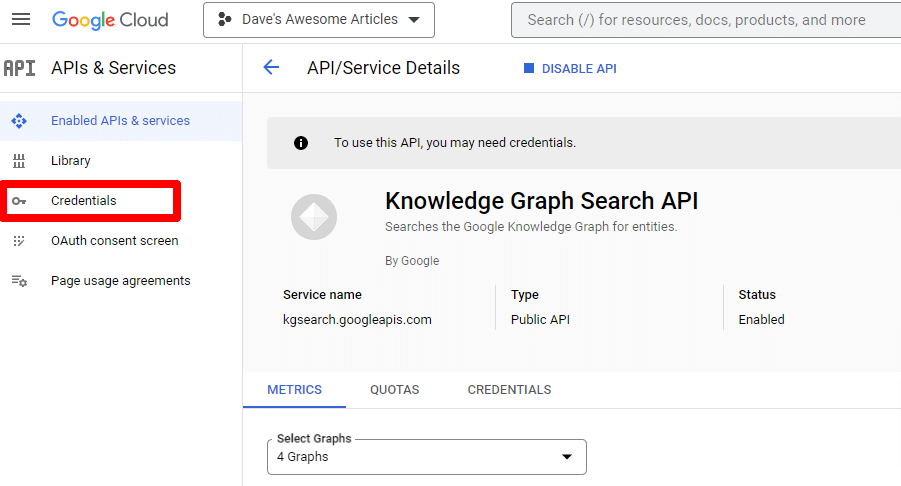
E estaremos criando uma conta de serviço.
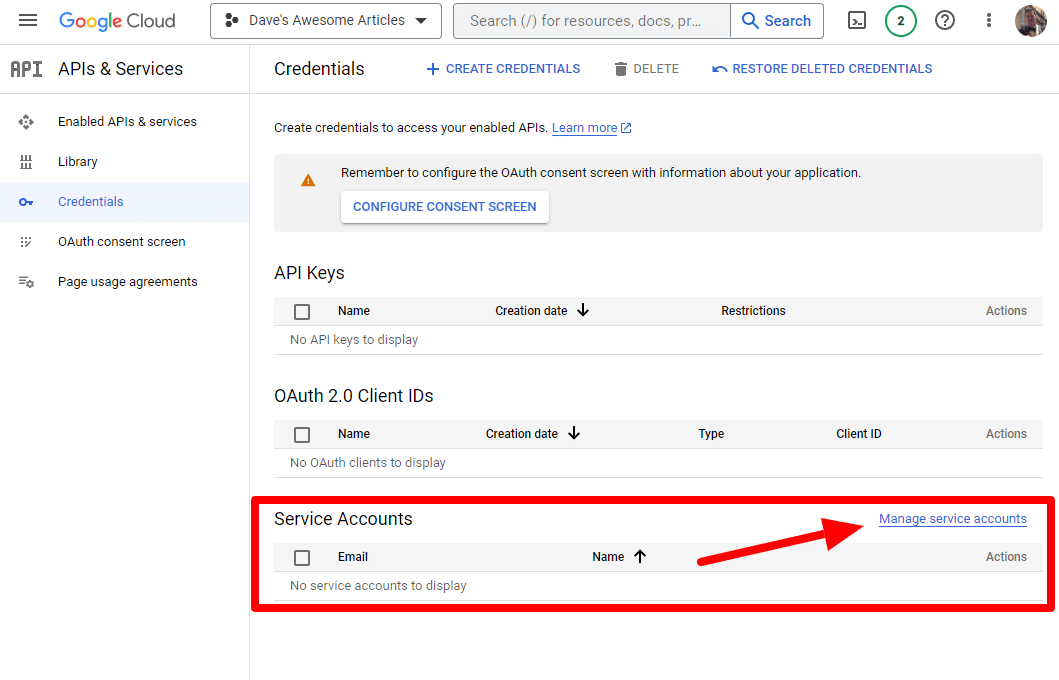
Basta criar uma conta de serviço:
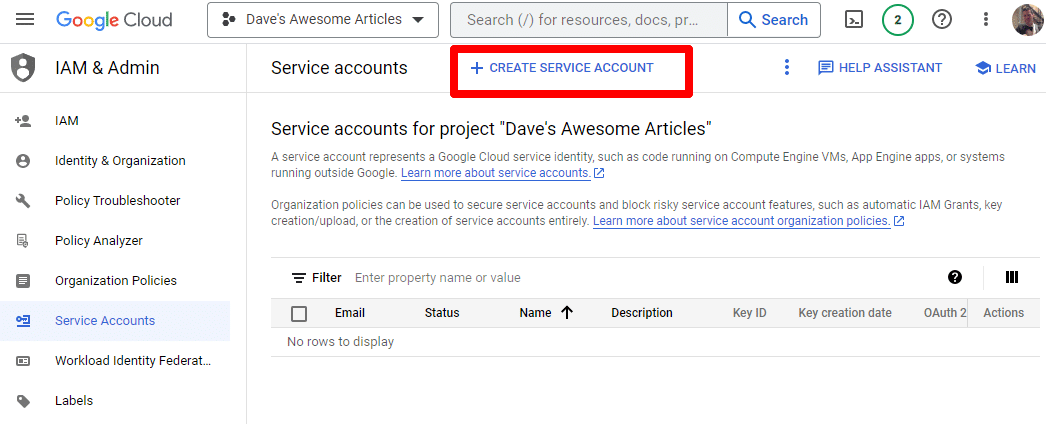
Preencha as informações necessárias:
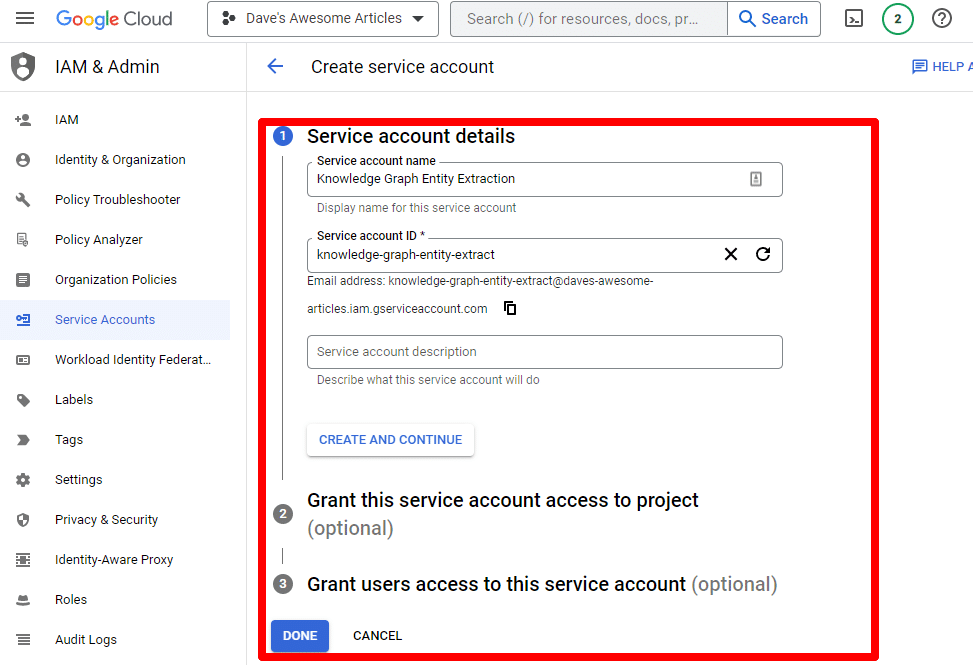
(Você precisará dar um nome a ele e conceder privilégios de proprietário.)
Agora temos nossa conta de serviço. Tudo o que resta é criar nossa chave.
Clique nos três pontos em Ações e clique em Gerenciar chaves .
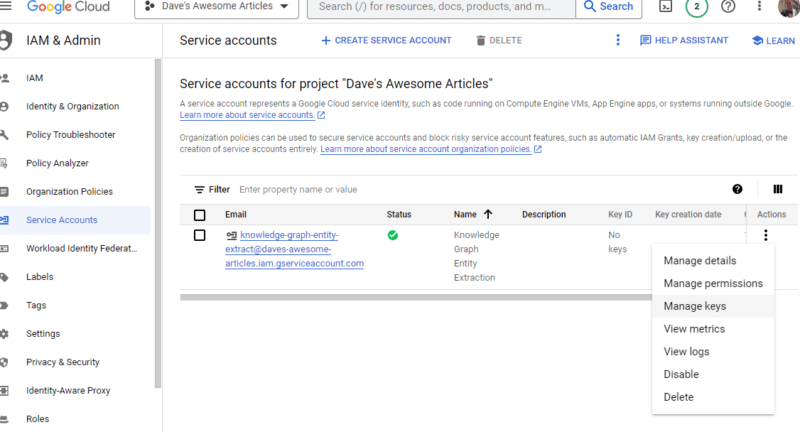
Clique em Adicionar chave e depois em Criar nova chave :
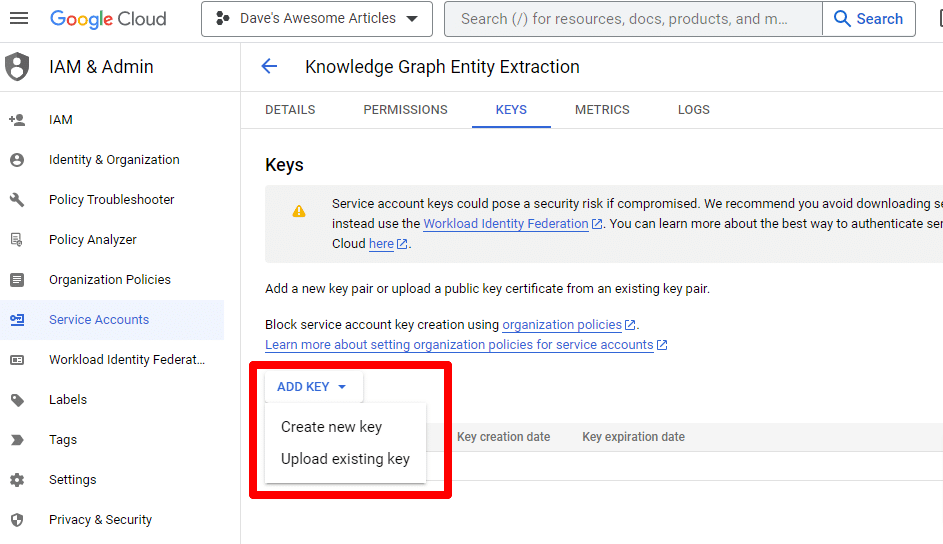
O tipo de chave será JSON.
Imediatamente, você verá o download para o local de download padrão.
Essa chave dará acesso às suas APIs, portanto, mantenha-a segura, assim como sua API OpenAI.
Tudo bem… e estamos de volta. Pronto para continuar com nosso roteiro?
Agora que os temos, precisamos definir nossa chave de API e o caminho para o arquivo baixado. O código para fazer isso é:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") Você substituirá YOUR_OPENAI_API_KEY por sua própria chave.
Você também substituirá /PATH-TO-FILE/FILENAME.JSON pelo caminho para a chave da conta de serviço que acabou de baixar, incluindo o nome do arquivo.
Execute a célula e você está pronto para seguir em frente.
Passo 4: Crie as funções
Em seguida, criaremos as funções para:
- Raspe a página da web que inserimos acima.
- Analise o conteúdo e extraia as entidades.
- Gere um artigo usando GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()Isso é exatamente o que os comentários descrevem. Estamos criando três funções para os propósitos descritos acima.
Olhos atentos notarão:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, Você pode editar o conteúdo ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) E descreva a função que deseja que o ChatGPT assuma. Você também pode adicionar tom (por exemplo, “Você é um escritor amigável…”).
Passo 5: Raspe o URL e imprima as entidades
Agora estamos sujando as mãos. É hora de:
- Raspe o URL que inserimos acima.
- Puxe todo o conteúdo que reside nas tags de parágrafo.
- Execute-o por meio da API do Google Knowledge Graph.
- Gere as entidades para uma visualização rápida.
Basicamente, você quer ver qualquer coisa nesta fase. Se você não vir nada, verifique um site diferente.
content = scrape_url(url) entities = analyze_content(content)Você pode ver que a linha um chama a função que extrai o URL que inserimos primeiro. A segunda linha analisa o conteúdo para extrair as entidades e as principais métricas.
Parte da função analysis_content também imprime uma lista das entidades encontradas para referência e verificação rápidas.
Passo 6: Analise as entidades
Quando comecei a brincar com o script, comecei com 20 entidades e rapidamente descobri que geralmente é demais. Mas o padrão (10) está certo?
Para descobrir, gravaremos os dados nas tabelas W&B para facilitar a avaliação. Ele manterá os dados indefinidamente para avaliação futura.
Primeiro, você precisará levar cerca de 30 segundos para se inscrever. (Não se preocupe, é grátis para esse tipo de coisa!) Você pode fazer isso em https://wandb.ai/site.
Depois de fazer isso, o código para fazer isso é:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()Quando executado, a saída se parece com isso:
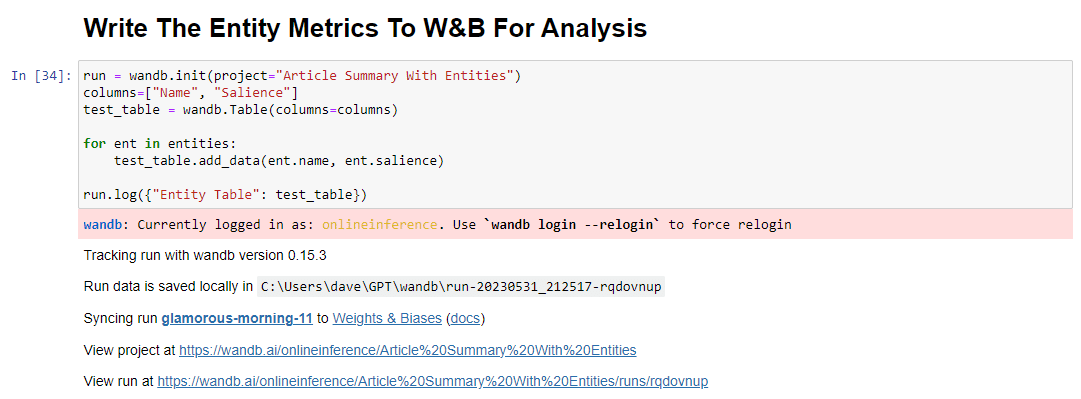
E ao clicar no link para visualizar sua corrida, você encontrará:
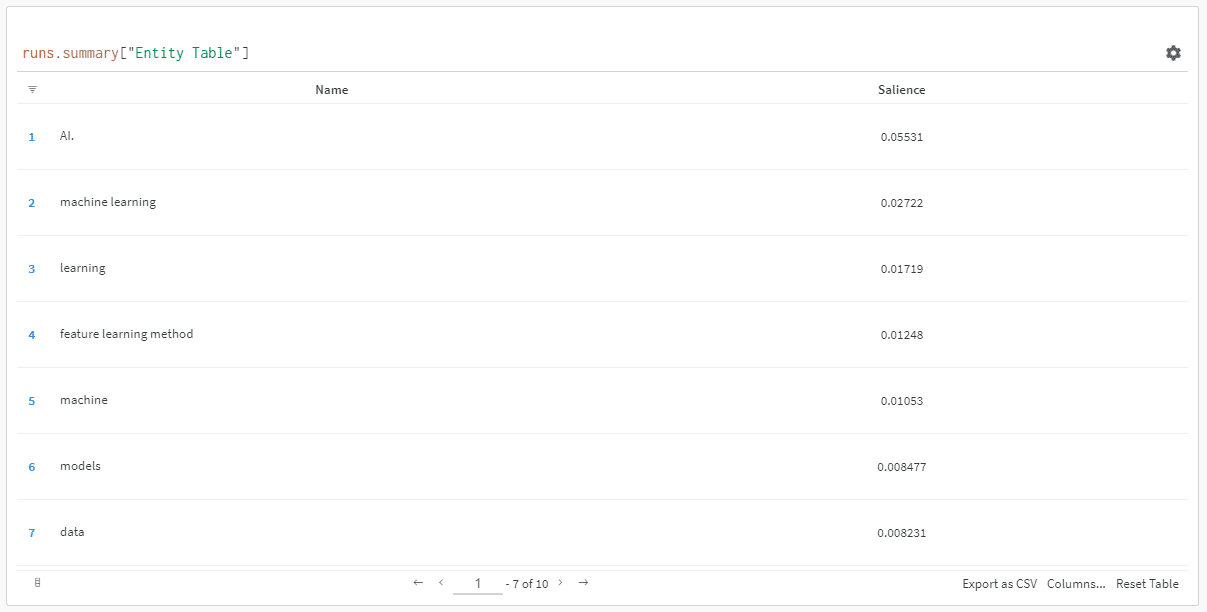
Você pode ver uma queda na pontuação de saliência. Lembre-se de que essa pontuação calcula a importância desse termo para a página, não a consulta.
Ao revisar esses dados, você pode optar por ajustar o número de entidades com base na saliência ou apenas quando aparecerem termos irrelevantes.
Para ajustar o número de entidades, vá para a célula de funções e edite:
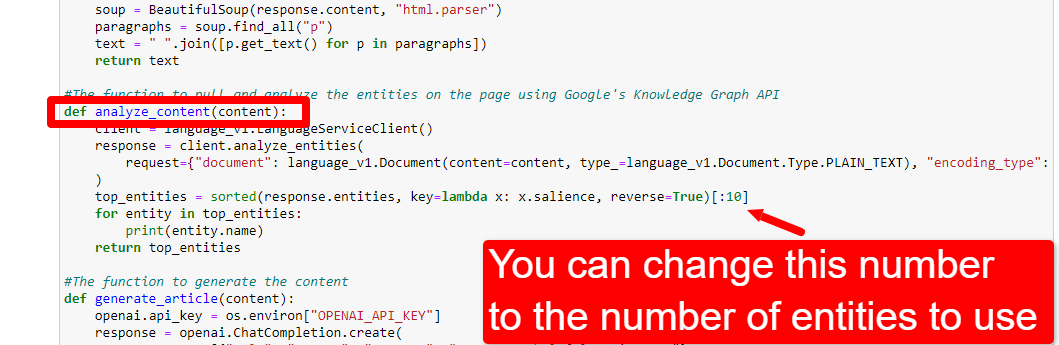
Em seguida, você precisará executar a célula novamente e aquela que executou para coletar e analisar o conteúdo para usar a nova contagem de entidade.
Passo 7: Gere o esboço do artigo
No momento que todos esperavam, é hora de gerar o esboço do artigo.
Isso é feito em duas partes. Primeiro, precisamos gerar o prompt adicionando a célula:
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)Isso basicamente cria um prompt para gerar um artigo:

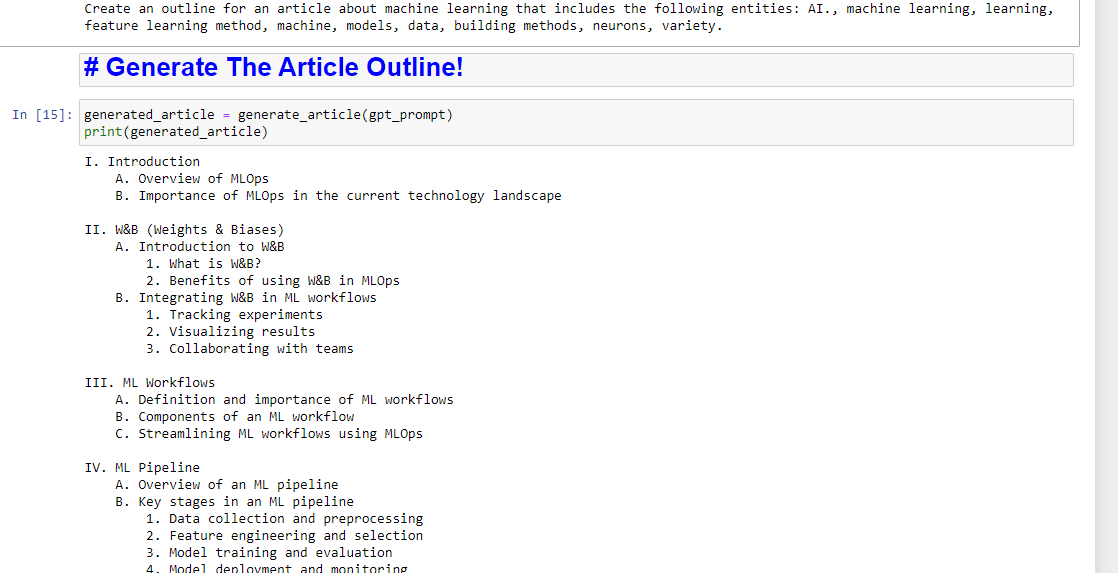
E então, tudo o que resta é gerar o esboço do artigo usando o seguinte:
generated_article = generate_article(gpt_prompt) print(generated_article)Que produzirá algo como:
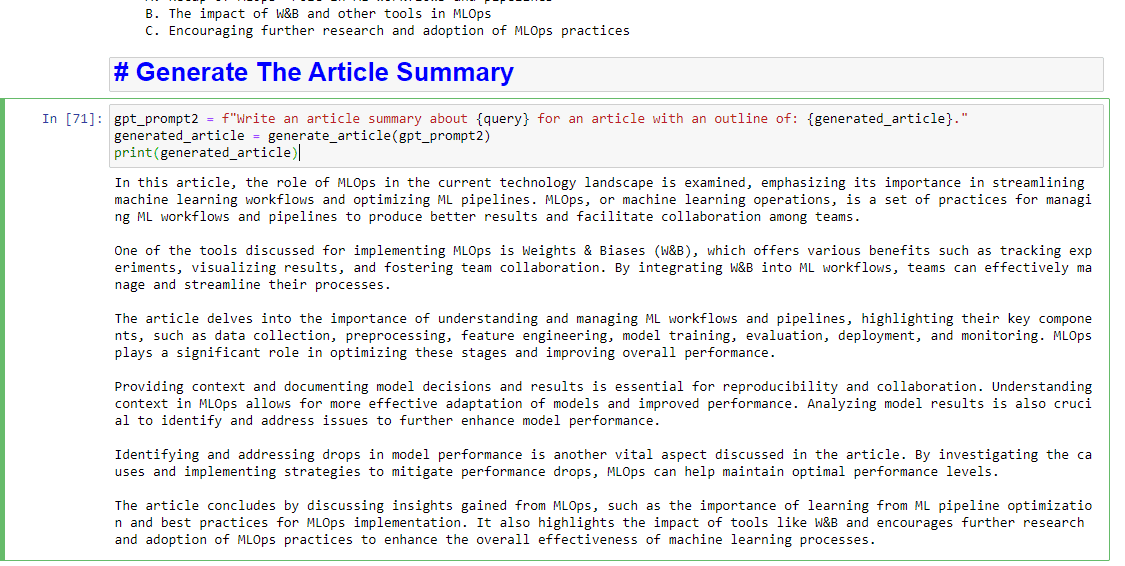
E se você também gostaria de obter um resumo escrito, você pode adicionar:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)Que produzirá algo como:
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.