
Como o Google pode identificar e avaliar autores por meio do EEAT
Publicados: 2023-04-17O Google está dando mais importância à fonte do conteúdo, especificamente ao autor, ao classificar os resultados da pesquisa. A introdução de Perspectivas, Sobre este resultado e Sobre este autor nas SERPs deixa isso claro.
Este artigo explora como o Google pode potencialmente avaliar peças de conteúdo por meio da experiência, conhecimento, autoridade e confiabilidade (EEAT) de seus autores.
EEAT: a ofensiva de qualidade do Google
O Google destacou a importância do conceito EEAT para melhorar a qualidade dos resultados de pesquisa e a experiência do usuário na SERP.
Fatores na página, como a qualidade geral do conteúdo, sinais de link (ou seja, PageRank e textos âncora) e sinais de nível de entidade, todos desempenham um papel vital.
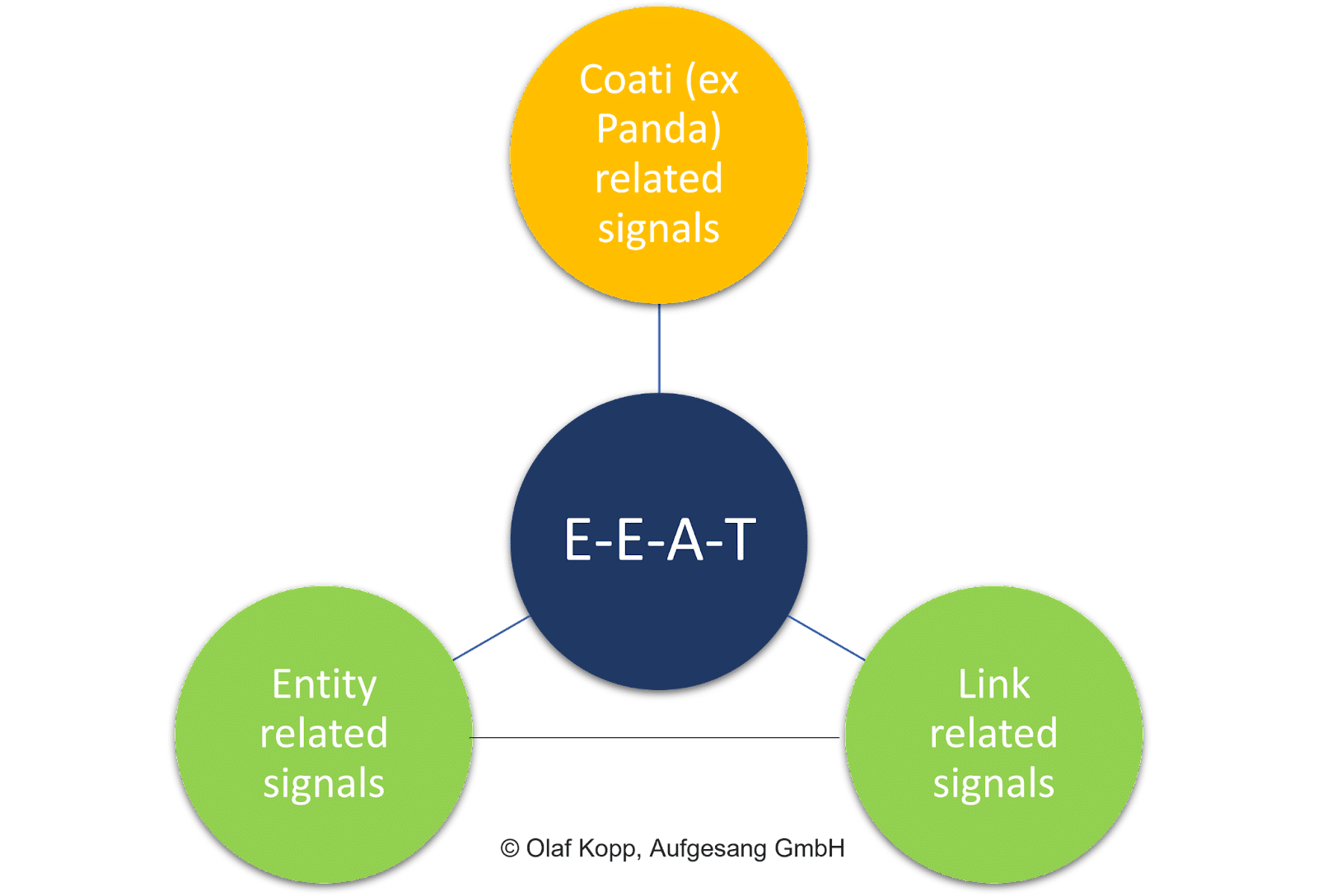
Em contraste com a pontuação do documento, a avaliação do conteúdo individual não é o foco do EEAT.
O conceito tem uma referência temática relacionada com o domínio e a entidade originadora. É independente da intenção de pesquisa e do próprio conteúdo individual.
Em última análise, o EEAT é um fator de influência independente das consultas de pesquisa.
O EEAT refere-se principalmente a áreas temáticas e é entendido como uma camada de avaliação que avalia coleções de conteúdo e sinais fora da página em relação a entidades como empresas, organizações, pessoas e seus domínios.
A importância do autor como fonte de conteúdo
Muito antes do (E-)EAT, o Google tentou incluir a classificação das fontes de conteúdo nas classificações de pesquisa. Por exemplo, a atualização de Vince de 2009 deu ao conteúdo criado pela marca uma vantagem de classificação.
Por meio de projetos como Knol ou Google+, que já terminaram há muito tempo, o Google tentou coletar sinais para avaliações de autores (ou seja, por meio de um gráfico social e avaliações de usuários).
Nos últimos 20 anos, várias patentes do Google se referiram direta ou indiretamente a plataformas de conteúdo como o Knol e redes sociais como o Google+.
Avaliar a origem ou o autor de um conteúdo de acordo com os critérios do EEAT é uma etapa crucial para desenvolver ainda mais a qualidade dos resultados da pesquisa.
Com a abundância de conteúdo gerado por IA e spam clássico, não faz sentido para o Google incluir conteúdo inferior no índice de pesquisa.
Quanto mais conteúdo ele indexa e precisa processar durante a recuperação de informações, mais poder de computação é necessário.
O EEAT pode ajudar o Google a classificar com base no nível de entidade, domínio e autor aplicado em uma escala mais ampla sem a necessidade de rastrear cada parte do conteúdo.
Nesse nível macro, o conteúdo pode ser classificado de acordo com a entidade originadora e alocado com mais ou menos orçamento de rastreamento. O Google também pode usar esse método para excluir grupos de conteúdo inteiros da indexação.
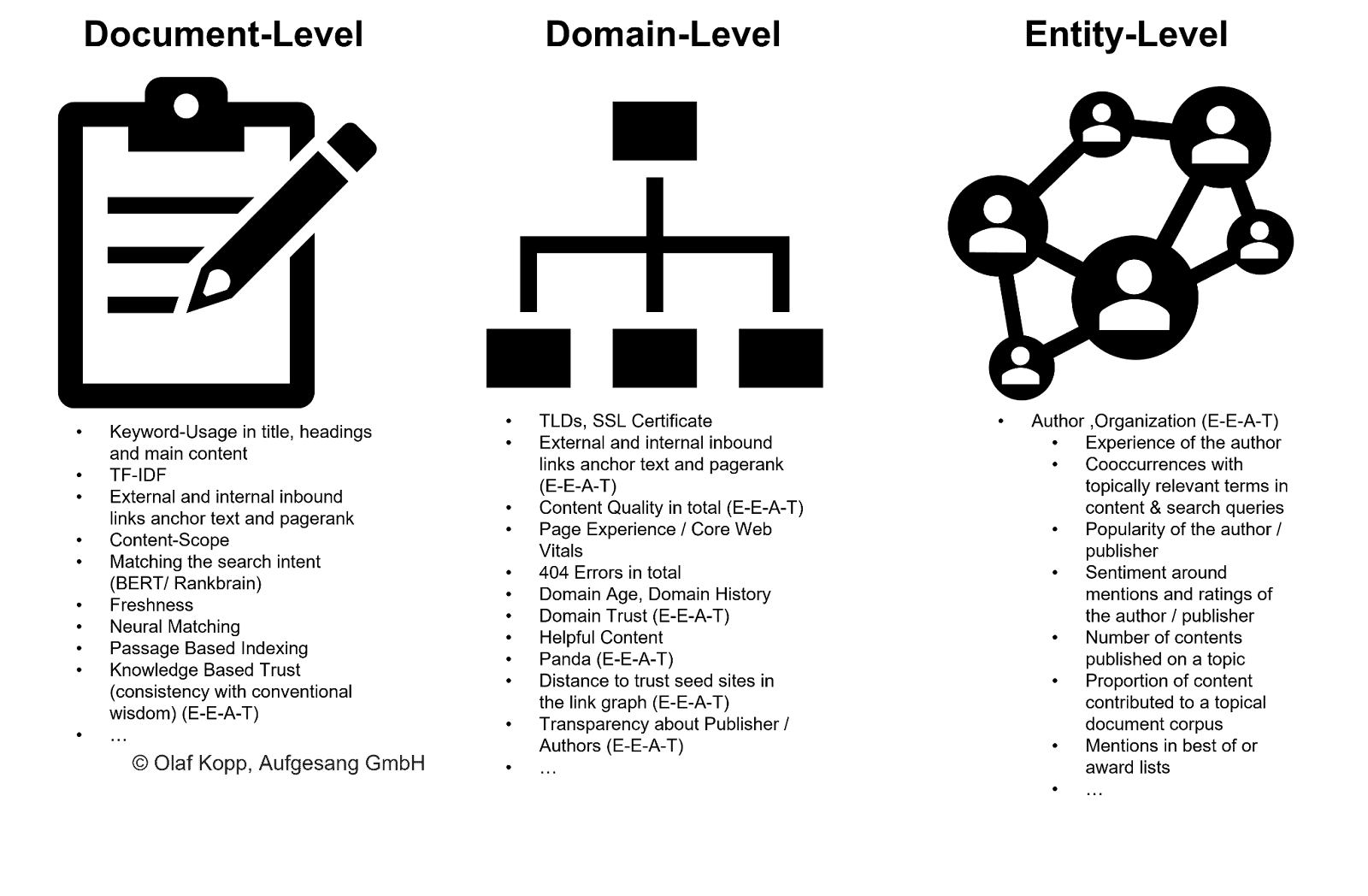
Como o Google pode identificar autores e atribuir conteúdo?
Os autores pertencem ao tipo entidade pessoa. Deve ser feita uma distinção entre entidades já conhecidas registradas no Knowledge Graph e entidades previamente desconhecidas ou não validadas registradas em um repositório de conhecimento como o Knowledge Vault.
Mesmo que as entidades ainda não tenham sido capturadas no Knowledge Graph, o Google pode reconhecer e extrair entidades de conteúdo não estruturado usando aprendizado de máquina e modelos de linguagem. A solução é chamada de reconhecimento de entidade (NER), uma subtarefa do processamento de linguagem natural.
O NER reconhece entidades com base em padrões linguísticos e os tipos de entidade são atribuídos. De um modo geral, os substantivos são entidades (nomeadas).
Os sistemas modernos de recuperação de informações usam a incorporação de palavras (Word2Vec) para isso.
Um vetor de números representa cada palavra de um texto ou parágrafo de texto, e as entidades podem ser representadas como vetores de nós ou incorporações de entidades (Node2Vec/Entity2Vec).
As palavras são atribuídas a uma classe gramatical (substantivo, verbo, preposições, etc.) por meio da marcação de parte do discurso (POS).
Substantivos são geralmente entidades. Os sujeitos são as entidades principais e os objetos são as entidades secundárias. Verbos e preposições podem relacionar as entidades entre si.
No exemplo abaixo, “olaf kopp”, “head of seo”, “cofundador” e “aufgesang” são as entidades nomeadas. (NN = substantivo).
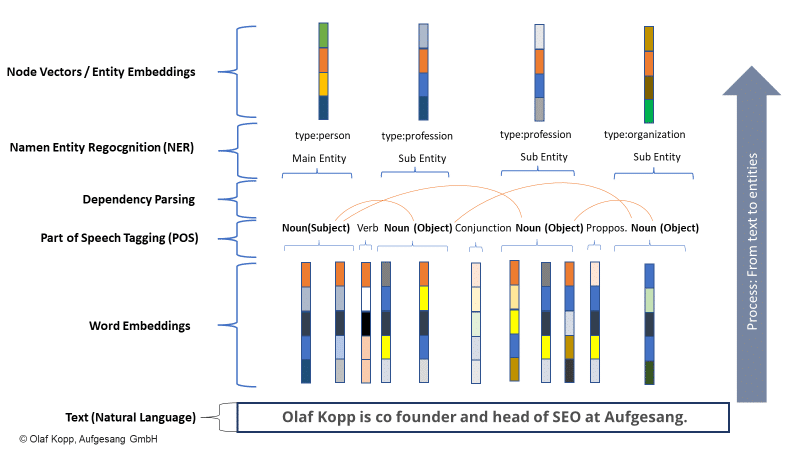
O processamento de linguagem natural pode identificar entidades e determinar o relacionamento entre elas.
Isso cria um espaço semântico que captura e compreende melhor o conceito de uma entidade.
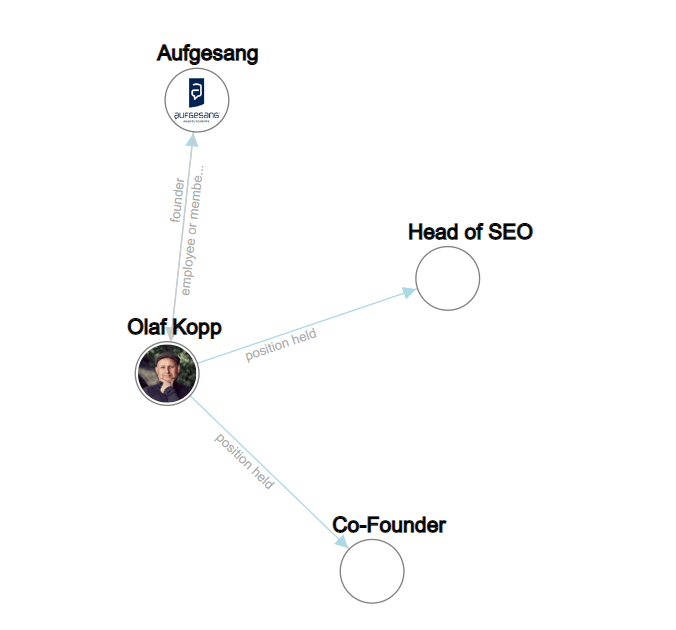
Você pode encontrar mais sobre isso em “Como o Google usa o NLP para entender melhor as consultas de pesquisa e o conteúdo”.
A contraparte das incorporações de autor são as incorporações de documentos. As incorporações de documentos são comparadas com vetores de autor por meio de análise de espaço vetorial. (Você pode aprender mais na patente do Google “Gerando representações vetoriais de documentos”.)
Todos os tipos de conteúdo podem ser representados como vetores, o que permite:
- Vetores de conteúdo e vetores de autor a serem comparados em espaços vetoriais.
- Documentos a serem agrupados de acordo com a similaridade.
- Autores a atribuir.
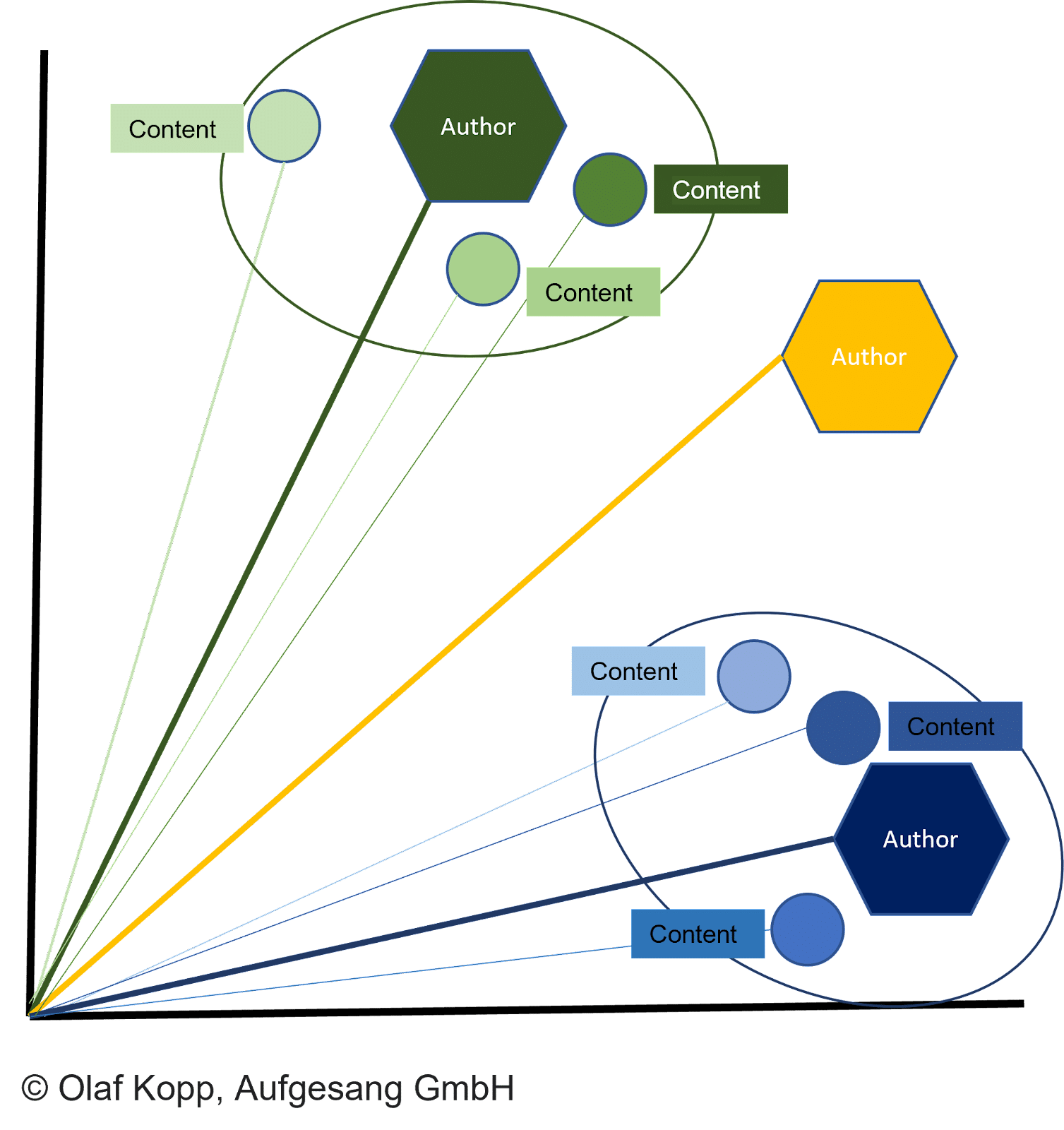
A distância entre os vetores do documento e o vetor do autor correspondente descreve a probabilidade de o autor ter criado os documentos.
O documento é atribuído ao autor se a distância for menor que outros vetores e um determinado limite for atingido.
Isso também pode impedir que um documento seja criado sob um sinalizador falso. O vetor autor pode então ser atribuído a uma entidade autor, conforme já descrito, usando o nome do autor especificado no conteúdo.
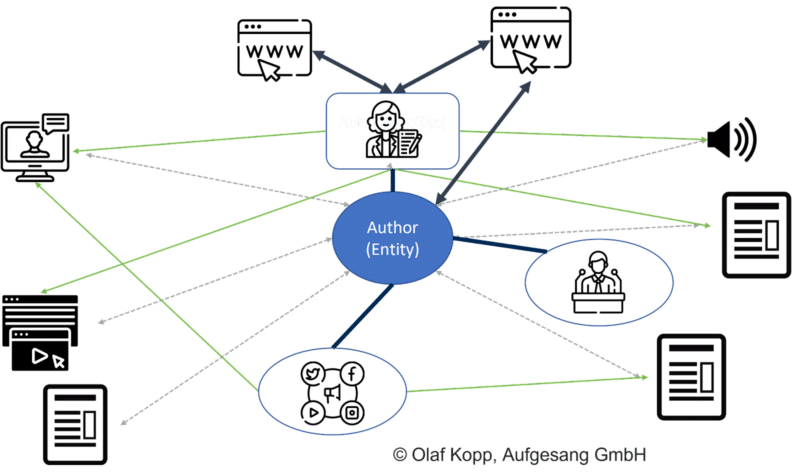
Fontes importantes de informações sobre autores incluem:
- Wikipedia Artigos sobre a pessoa.
- Perfis do autor.
- Perfis de alto-falante.
- Perfis de mídia social.
Se você pesquisar no Google o nome de uma pessoa do tipo entidade, encontrará entradas da Wikipédia, perfis do autor e URLs de domínios que estão diretamente conectados ao autor nos primeiros 20 resultados da pesquisa.
Em SERPs móveis, você pode ver quais fontes o Google estabelece um relacionamento direto com a entidade pessoa.
O Google reconheceu todos os resultados acima dos ícones dos perfis de mídia social como fontes com referência direta à entidade.

Esta captura de tela da consulta de pesquisa por “olaf kopp” mostra que as entidades estão vinculadas às fontes.
Ele também exibe uma nova variante de um painel de conhecimento. Parece que me tornei parte de um teste beta aqui.
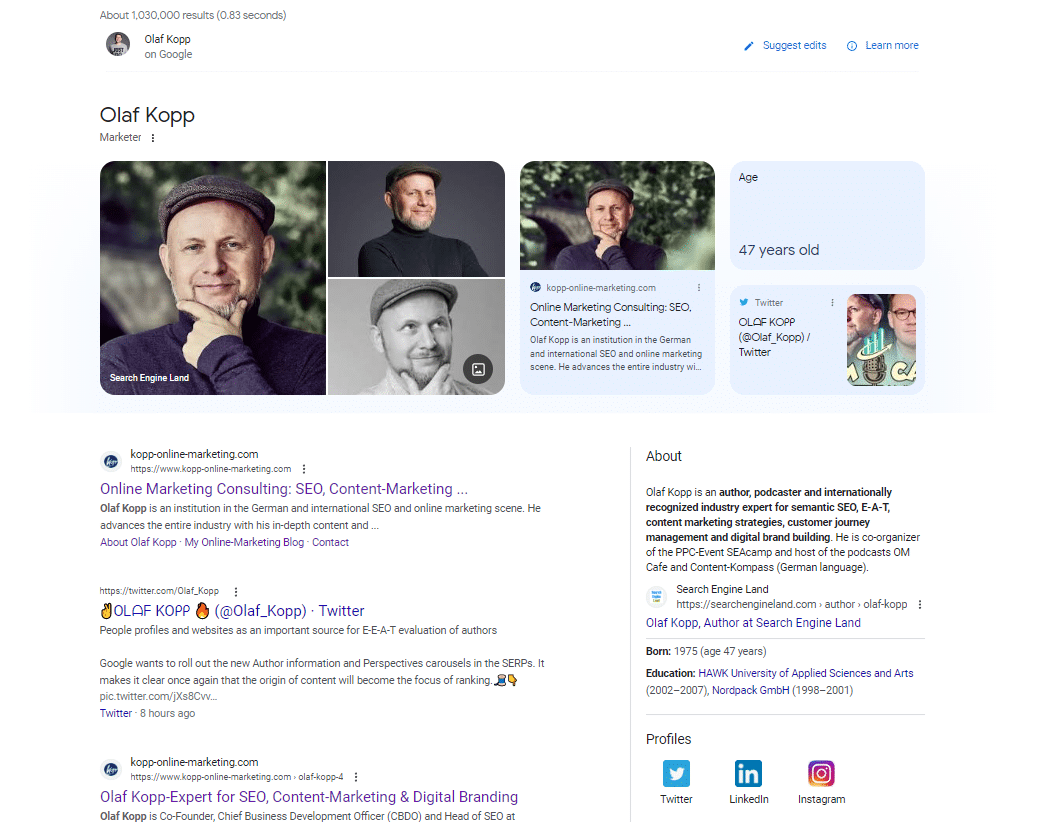
Nesta captura de tela, você verá que, além de imagens e atributos (idade), o Google vinculou diretamente meu domínio e perfil de mídia social à minha entidade e os fornece no painel de conhecimento.
Como não há nenhum artigo da Wikipédia sobre mim, a descrição Sobre é fornecida a partir do perfil do autor no Search Engine Land nos EUA e do perfil do autor no site da agência na Alemanha.
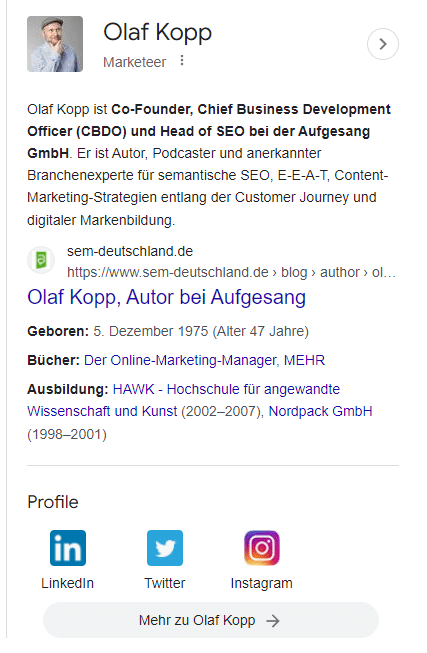
Os perfis pessoais na web ajudam o Google a contextualizar os autores e identificar perfis de mídia social e domínios associados a um autor.
Caixas de autor ou coleções de autores em perfis de autor ajudam o Google a atribuir conteúdo aos autores. O nome do autor é insuficiente como identificador, pois podem surgir ambiguidades.
Você deve prestar atenção às descrições de todos os autores para garantir a consistência. O Google pode usá-los para verificar a validade da entidade em comparação entre si.
Obtenha a newsletter diária em que os profissionais de marketing de busca confiam.
Consulte os termos.
Patentes interessantes do Google para classificação EEAT de autores
As patentes a seguir compartilham um vislumbre de possíveis metodologias de como o Google identifica autores, atribui conteúdo a eles e os avalia em termos de EEAT.
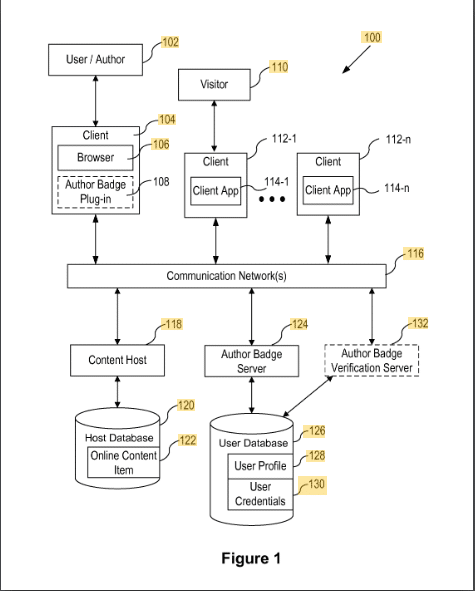
Distintivos de autor de conteúdo
Esta patente descreve como o conteúdo é atribuído aos autores por meio de um crachá.

O conteúdo é atribuído a um crachá de autor usando uma ID, como o endereço de e-mail ou o nome do autor. A verificação é feita através de um addon no navegador do autor.
Gerando vetores de autor
A Google assinou esta patente em 2016, com prazo até 2036. No entanto, só houve pedidos de patente para os EUA, o que sugere que ainda não é utilizada nas pesquisas do Google a nível mundial.
A patente descreve como os autores são representados como vetores com base nos dados de treinamento.
Um vetor torna-se parâmetros únicos identificados com base no estilo de escrita típico do autor e na escolha de palavras.
Dessa forma, conteúdos não atribuídos anteriormente ao autor podem ser atribuídos a eles, ou autores semelhantes podem ser agrupados em clusters.
A classificação do conteúdo pode ser ajustada para um ou mais autores com base no comportamento do usuário no passado na pesquisa (no Discover, por exemplo).
Assim, o conteúdo de autores que já foram descobertos e os de autores semelhantes seriam classificados melhor.
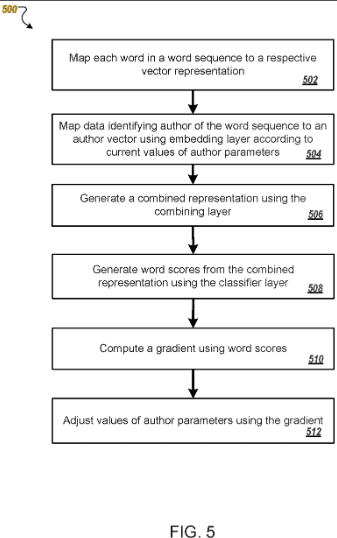
Esta patente é baseada nos chamados embeddings, como autores e word embeddings.
Hoje, as incorporações são o padrão tecnológico em aprendizado profundo e processamento de linguagem natural.
Portanto, é óbvio que esses métodos do Google também serão usados para reconhecimento e atribuição de autores.
Pontuação de reputação de um autor
Esta patente foi assinada pela primeira vez pelo Google em 2008 e tem um prazo mínimo de 2029. Esta patente refere-se originalmente ao projeto Google Knol há muito encerrado.
Assim, é ainda mais emocionante porque o Google o desenhou novamente em 2017 sob o novo título Monetização de conteúdo online. O Knol foi fechado pelo Google em 2012.
A patente é sobre a determinação de uma pontuação de reputação. Os seguintes fatores podem ser levados em consideração para isso:
- Nível de moldura do autor.
- Publicações em veículos de renome.
- Número de publicações.
- Era dos últimos lançamentos.
- Há quanto tempo o autor trabalha oficialmente como autor.
- Número de links gerados pelo conteúdo do autor.
Um autor pode ter várias pontuações de reputação por tópico e vários aliases por área de assunto.
Muitos dos pontos levantados na patente estão relacionados a uma plataforma fechada como a Knol. Portanto, esta patente deve ser suficiente neste ponto.
Classificação do agente
Esta patente do Google foi assinada pela primeira vez em 2005 e tem prazo mínimo até 2026.
Além dos EUA, também foi registrado na Espanha, Canadá e no mundo, tornando-o provável de ser usado na pesquisa do Google.
A patente descreve como o conteúdo digital é atribuído a um agente (editor e/ou autor). Esse conteúdo é classificado com base na classificação do agente, entre outras coisas.
A classificação do agente é independente da intenção de pesquisa da consulta de pesquisa e é determinada com base nos documentos atribuídos ao agente e seus backlinks.
A classificação do agente refere-se exclusivamente a uma consulta de pesquisa, cluster de consulta de pesquisa ou áreas de assunto inteiras.
“As classificações do agente também podem opcionalmente ser calculadas em relação aos termos de pesquisa ou categorias de termos de pesquisa. Por exemplo, termos de pesquisa (ou coleções estruturadas de termos de pesquisa, ou seja, consultas) podem ser classificados em tópicos, por exemplo, esportes ou especialidades médicas, e um agente pode ter uma classificação diferente em relação a cada tópico.”
Credibilidade de um autor de conteúdo online
Esta patente da Google foi assinada pela primeira vez em 2008 e tem um prazo mínimo de 2029, tendo sido registada apenas nos EUA até ao momento.
Justin Lawyer o desenvolveu da mesma forma que o Patent Reputation Score de um autor e está diretamente relacionado ao uso em buscas.
Na patente, encontram-se pontos semelhantes aos da patente acima mencionada.
Para mim, é a patente mais emocionante para avaliar autores em termos de confiança e autoridade.
Esta patente faz referência a vários fatores que podem ser usados para determinar algoritmicamente a credibilidade de um autor.
Ele descreve como um mecanismo de pesquisa pode classificar documentos sob a influência do fator de credibilidade e pontuação de reputação de um autor.
Um autor pode ter várias pontuações de reputação, dependendo de quantos tópicos diferentes eles publicam conteúdo.
A pontuação de reputação de um autor é independente do editor.
Novamente nesta patente, há uma referência a links como um fator possível em uma classificação EEAT. O número de links para conteúdo publicado pode influenciar a pontuação de reputação de um autor.
Os seguintes sinais possíveis para uma pontuação de reputação são mencionados:
- Há quanto tempo o autor produz conteúdo em uma área de assunto.
- Conscientização do autor.
- Avaliações de conteúdo publicado por usuários.
- Se outro editor publicar o conteúdo do autor com avaliações acima da média.
- A quantidade de conteúdo publicado pelo autor.
- Há quanto tempo o autor publicou pela última vez.
- Avaliações de publicações anteriores sobre um tema semelhante pelo autor.
Outras informações interessantes sobre a pontuação de reputação da patente:
- Um autor pode ter várias pontuações de reputação, dependendo de quantos tópicos diferentes eles publicam conteúdo.
- A pontuação de reputação de um autor é independente do editor.
- A pontuação de reputação pode ser rebaixada se o conteúdo duplicado ou trechos forem publicados várias vezes.
- O número de links para o conteúdo publicado pode influenciar a pontuação de reputação.
Além disso, a patente aborda um fator de credibilidade para os autores. Os seguintes fatores de influência são mencionados:
- Informações verificadas sobre a profissão ou função do autor em uma empresa. Também considera a credibilidade da empresa.
- Relevância da ocupação para os tópicos do conteúdo publicado.
- Grau de escolaridade e formação do autor.
- Experiência do autor com base no tempo. Quanto mais tempo um autor publica sobre um tópico, mais confiável ele é. A experiência do autor/editor pode ser determinada algoritmicamente para o Google por meio da data da primeira publicação em uma área de assunto.
- O número de conteúdo publicado em um tópico. Se um autor publica muitos artigos sobre um tema, pode-se supor que ele seja um especialista e tenha certa credibilidade.
- Tempo decorrido até a última liberação. Quanto mais tempo se passou desde a última publicação de um autor em um tópico, mais uma possível pontuação de reputação para esse tópico diminui. Quanto mais atualizado o conteúdo, maior ele é.
- Menções do autor/editor em listas de prêmios e melhores.
Sistemas e métodos de reclassificação de resultados de pesquisa classificados
Esta patente do Google foi assinada pela primeira vez em 2013 e tem prazo mínimo até 2033. Ela foi registrada nos EUA e no mundo, o que torna provável que o Google a utilize.
Entre os inventores da patente está Chung Tin Kwok, que esteve envolvido em várias patentes relevantes do Google EEAT.
A patente descreve como os buscadores, além das referências ao conteúdo do autor, também podem considerar a proporção que ele pode contribuir para um corpus de documento temático em uma pontuação de autor.
"Em algumas modalidades, a determinação da pontuação do autor original para a respectiva entidade inclui: identificar uma pluralidade de porções de conteúdo no índice de conteúdo conhecido identificado como associado à respectiva entidade, cada porção na pluralidade de porções representando uma quantidade predeterminada de dados no índice de conteúdo conhecido; e calcular uma porcentagem da pluralidade das porções que são primeiras instâncias das porções de conteúdo no índice de conteúdo conhecido."
Ele descreve uma reclassificação dos resultados da pesquisa com base na pontuação do autor, incluindo a pontuação da citação. A pontuação de citação é baseada no número de referências aos documentos de um autor.
Outro critério para a pontuação do autor é a proporção de conteúdo que um autor contribuiu para um corpus de documentos relacionados ao tópico.
"[Neste documento, determinar a pontuação do autor para uma respectiva entidade inclui: determinar uma pontuação de citação para a respectiva entidade, em que a pontuação de citação corresponde a uma frequência na qual o conteúdo associado à respectiva entidade é citado; determinar uma pontuação de autor original para o respectiva entidade, em que a pontuação do autor original corresponde a uma porcentagem do conteúdo associado à respectiva entidade que é uma primeira instância do conteúdo em um índice de conteúdo conhecido; e combinar a pontuação da citação e a pontuação do autor original usando uma função predeterminada para produzir a pontuação do autor."
O objetivo da patente é identificar "imitadores" e rebaixar seu conteúdo nos rankings, mas também pode ser usada para avaliação geral de autores.
Fatores-chave para classificar um autor
Além dos possíveis fatores para uma avaliação do autor listados nas patentes acima, aqui estão mais alguns a serem considerados (alguns dos quais já mencionei em meu artigo "14 maneiras como o Google pode avaliar a EAT").
- Qualidade geral do conteúdo de um tópico: A qualidade que um autor oferece sobre seu conteúdo em um tópico como um todo, independentemente do domínio e do formato, pode ser um fator para o EEAT. Os sinais para isso podem ser sinais do usuário, links e outros sinais de qualidade no nível do conteúdo.
- PageRank ou referências ao conteúdo do autor.
- Coocorrências do autor em conteúdos (podcasts, vídeos, sites, PDFs, livros) com temas ou termos relevantes.
- Coocorrências do autor em consultas de pesquisa com tópicos ou termos relevantes.
Aplicando EEAT a entidades de autor
Os métodos de aprendizado de máquina permitem reconhecer e mapear estruturas semânticas de conteúdo não estruturado em grande escala.
Isso permite que o Google reconheça e entenda muito mais entidades do que as mostradas anteriormente no Knowledge Graph.
Como resultado, a fonte de conteúdo desempenha um papel cada vez mais importante. O EEAT pode ser aplicado algoritmicamente além de documentos, conteúdo e domínio.
O conceito também pode abranger as entidades autoras do conteúdo (ou seja, os autores e organizações responsáveis pelo conteúdo).
Acho que veremos um impacto ainda mais significativo do EEAT na pesquisa do Google nos próximos anos. Esse fator pode até ser tão importante para o ranqueamento quanto a otimização da relevância do conteúdo individual.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.