
Como aproveitar ao máximo a API do Google Search Console usando regex
Publicados: 2022-11-02O Google Search Console é uma ferramenta incrível que fornece dados de pesquisa inestimáveis de usuários reais diretamente do Google. Embora os gráficos e as tabelas sejam fáceis de trabalhar, uma grande parte dos dados não pode ser acessada pela interface do usuário.
A única maneira de obter esses dados ocultos é usar a API e extrair todos os dados de pesquisa valiosos que estão disponíveis para você – se você souber como. Isso é possível com expressões regulares.
Veja como você pode maximizar a API do Google Search Console usando expressões regulares, de acordo com Eric Wu, vice-presidente de crescimento de produtos da Honey, uma empresa do PayPal, que falou na SMX Advanced.
Diagnosticando problemas de SEO com o GSC
Trabalhando em um site com crescimento estagnado ou em declínio ou uma queda na atualização principal?
A maioria dos profissionais de SEO recorre ao Google Search Console (GSC) para diagnosticar esses problemas.
(Ou, se os recursos permitirem, você pode até usar uma ferramenta paga como Ryte ou construir sua própria plataforma.)
Felizmente para a comunidade de SEO, não faltam painéis do Looker Studio (anteriormente Google Data Studio) úteis para análise GSC, incluindo:
- O painel gratuito de Aleyda Solis, que usa dados do GSC para identificar facilmente possíveis alterações de classificação nos últimos dias a partir do Google Core Update.
- O painel de monitoramento de tráfego de pesquisa do Google, que agora extrai dados de tráfego do Discover e do Google News.
- Estúdio do Explorador do Search Console de Hannah Butler. (E se você quiser manipular os dados do GSC de forma prática e encontrar insights rápidos, use a planilha do Search Console Explorer do Butler.)
Os painéis permitem que os SEOs vejam uma visão geral de diferentes tendências, em vez de usar o GSC e fazer vários cliques para obter os dados de que você precisa.
Mas se você estiver analisando sites corporativos, poderá encontrar alguns obstáculos.
- O Looker Studio e o Google Sheets carregam lentamente, especialmente quando você está lidando com sites grandes.
- A interface do GSC tem um limite de exportação de 1.000 linhas.
- O GSC tem um enorme problema de amostragem. As equipes de SEO corporativo perdem 90% de suas palavras-chave GSC, de acordo com Similar.ai. E se você souber extrair os dados, poderá obter 14x as palavras-chave.
Superando o problema de amostragem do GSC
Explorer for Search é outra ferramenta que você pode usar para análise GSC. De Noah Learner e da equipe da Two Octobers, ele é construído com pipelines de dados usando a API do GSC, que envia dados para o BigQuery (basicamente ignorando o Planilhas Google e baixando arquivos CSV) e, em seguida, visualiza as informações com o Data Studio.
Com isso, você pode ter certeza de que está obtendo quase todos os dados.
Ainda há uma ressalva devido ao problema de amostragem do GSC, especialmente para grandes sites de comércio eletrônico com muitas categorias diferentes. O GSC não mostrará necessariamente todos os dados provenientes desses diretórios.
Depois de realizar vários testes para obter o máximo de dados da API do GSC, a equipe do Similar.ai descobriu uma maneira de fechar a lacuna de amostragem do GSC.
Eles descobriram que, ao adicionar mais subdiretórios como perfis diferentes no painel do GSC, você pode extrair ainda mais dados, pois o Google fornece mais informações nesse nível inferior.
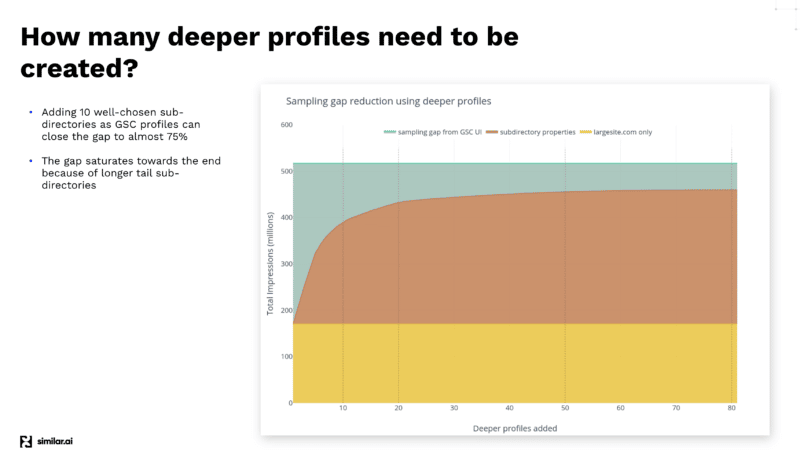
Por exemplo, se você estiver acessando example.com/televisions e adicionar “televisions” como um subdiretório em seu perfil do GSC, o Google fornecerá apenas as palavras-chave e as informações de clique para esse subdiretório e para baixo.
E adicionando muitos desses diferentes subdiretórios, você pode extrair muito mais informações.
Isso resolve o problema de amostragem, mas você pode obter ainda mais dados usando expressões regulares.
Obtendo mais dados GSC com expressões regulares
A expressão regular, ou regex, é uma ferramenta poderosa para entender seus dados.
Em abril de 2021, o Google adicionou suporte regex ao GSC – dando aos SEOs mais maneiras de fatiar e cortar dados de pesquisa orgânica.
Muitas vezes, os dados não são úteis a menos que você possa compreendê-los. E a regex ajuda a extrair insights acionáveis dos dados avançados do GSC.
Mas, por mais poderoso que seja, o regex pode ser difícil de aprender.
O melhor lugar para entender e se aprofundar nas expressões regulares é a documentação oficial do Google no GitHub. (O Google usa RE2 em seus produtos, que é uma espécie de expressão regular.)
Embora o regex esteja disponível em todos os tipos de linguagens de programação diferentes, você o encontrará em quase todos os lugares, mesmo para aqueles que estão modificando arquivos .htaccess.
Nas próximas seções estão os casos de uso para alavancar regex para GSC.
Consultas informativas de regex
Ao analisar consultas de pesquisa informativas reais no GSC, você normalmente deseja entender:
- Como as pessoas estão chegando ao seu site?
- Que perguntas eles estão extraindo?
Observar essas coisas de um ponto de vista pontual, dentro do GSC, pode ser difícil.
Você está sempre procurando as palavras “o quê”, “como”, “por que” e depois “quando”.
Existem algumas maneiras de tornar a extração de consultas informativas menos tediosas com regex.
Daniel K. Cheung compartilhou uma string regex que mostrará todas as consultas contendo "o quê", "como", "por que" e "quando" que receberam um clique ou uma impressão:
-
"what|how|why|when"
E esta string regex compartilhada por Steve Toth leva o exemplo anterior a um nível:
-
^(who|what|where|when|why|how)[" "]
Você pode usar essa string se quiser capturar consultas baseadas em perguntas que começam com “quem”, “o quê”, “onde”, “quando”, “por que” e “como” e depois seguidas por um espaço.
Esta é uma ótima lista para usar quando você estiver procurando por qualquer tipo de palavra que iniciaria uma pergunta:
- são, podem, não podem, poderiam, não podiam, fizeram, não, fazem, fazem, não, como, se, é, não é, deveria, não deveria, era, não era, foram, não foram, o que, quando, onde, quem, quem, de quem, por que, vai, não vai, faria, não faria
Colocar tudo isso no formulário regex seria algo assim:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
Nesta string de 178 caracteres:
- Você tem o acento circunflexo (
^) que informa que a consulta precisa começar com esta palavra: - As palavras são separadas por barras (
|) em vez de vírgulas. - Todas as palavras estão entre parênteses.
- Há uma barra invertida e o “s” (
\s) que denota um espaço após a palavra.
Isso é bom, mas também pode ser tedioso de fazer.
Abaixo, Wu simplificou a lista anterior de palavras para ser mais amigável com regex e mais curta, o que é ideal para copiar e colar. Mantê-lo dessa maneira também ajuda na eficiência.
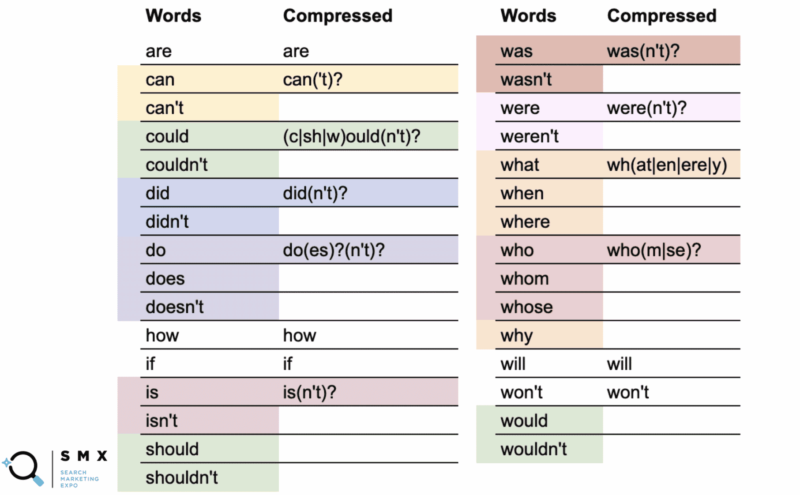
Na primeira coluna estão as palavras normais e na segunda coluna, o regex comprimido.
Por exemplo, a palavra “can” usa a versão compactada can('t)? .
O que o ponto de interrogação indica é que qualquer coisa dentro dos parênteses é opcional. A sintaxe compactada permite cobrir tanto a palavra “pode” quanto “não pode”.
Mais interessante, você pode fazer isso com could/could't, should/shouldn't, e would/wouldn onde a parte -ould das palavras é a base comum, como (c|sh|w)ould(n't)? . Esta sequência curta cobre todos os seis casos.
Ao simplificar essa longa lista de palavras tornou a string menos legível, o que é ótimo é que ela se encaixa mais no campo regex e permite copiar e colar mais facilmente.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Se você for um passo adiante, poderá comprimi-lo ainda mais. Nesse caso, Wu reduziu a contagem de caracteres de 135 para 113 caracteres.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Expressões regulares podem ficar realmente complicadas. Se você está recebendo uma string regex de outra pessoa e gostaria de desambiguar o que está fazendo o quê, você pode usar Regexper para ajudá-lo a visualizá-la.
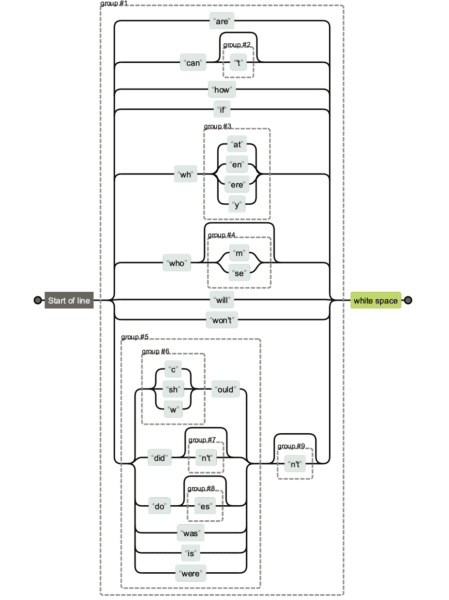
Abaixo, você verá uma comparação das diferentes versões de strings regex. É mais fácil manter o primeiro e obviamente mais difícil manter e ler o último.

Mas às vezes a contagem de caracteres realmente importa, especialmente quando você tem expressões regulares mais longas.
Os limites do filtro Regex para GSC são de 4.096 caracteres, de acordo com o advogado de pesquisa do Google Daniel Waisberg.
Isso pareceria um pouco. No entanto, se você tiver um site de comércio eletrônico e precisar adicionar nomes de domínio, subdomínios ou diretórios mais longos, provavelmente atingirá esse limite.
Consultas de marca Regex
Outra instância em que você pode começar a atingir o limite de caracteres regex no GSC é quando você o usa para consultas de marca.
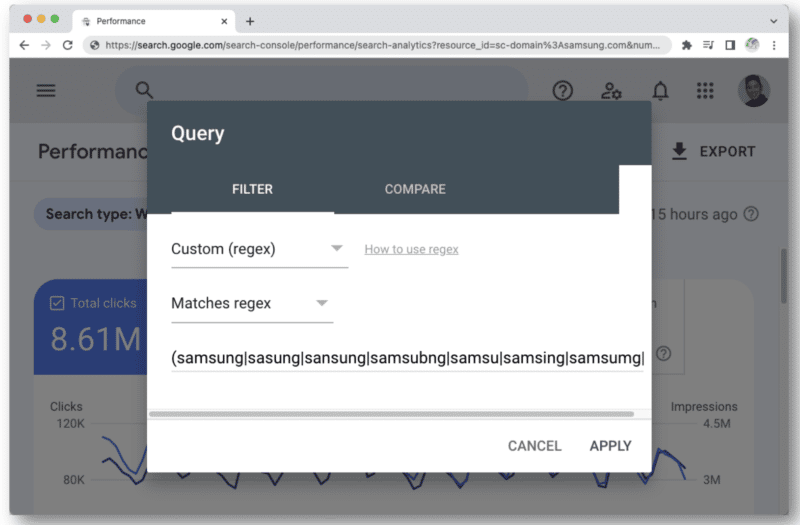
Quando você pensa em todos os diferentes tipos de erros ortográficos de um nome de marca que uma pessoa pode digitar, você rapidamente se depara com a contagem de 4.096 caracteres. Por exemplo:
- aamaung, damsung, mamsang, sam sung, samaung, samdung, samesung, Sameung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung, Samsung , samsun g, samsunb, samsund, samsund, samsunh, samsunt…
É aqui que entender o regex ajuda. Com esta string, você pode capturar o nome da marca “samsung” junto com erros de ortografia:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Muitas vezes, as pessoas escrevem errado as partes do meio da palavra. Mas, em geral, eles obtêm o formato e o comprimento corretos e você pode abordar sua sintaxe dessa maneira.
Para erros de ortografia de consulta de marca, considere o seguinte:

- Letras principais que compõem a consulta da marca.
- Consoantes .
- Letras em torno de consoantes duras .

Em vermelho estão as consoantes duras que as pessoas normalmente não perdem quando estão digitando o nome de uma marca. Estas são as letras principais que compõem essa marca em particular. Para "samsung", o "s" no início, o "m" no meio e depois "n" e "g" no final.
As letras azuis que cercam essas consoantes principais no teclado são as que as pessoas normalmente digitam incorretamente. No exemplo, ao redor de “s”, você vê o “a”, “d” e “z”. (Embora o layout seja diferente para teclados internacionais, o conceito ainda é o mesmo.)
A string regex acima captura todas as variantes possíveis de “samsung”.
O outro grande truque aqui está em [az\s]{1,4} .
Na forma regex, isso basicamente diz: “Quero corresponder qualquer letra “a” a “z”, ou um espaço, de uma a quatro vezes”.
Isso captura todos os erros ortográficos estranhos que podem acontecer no meio de uma consulta de marca – onde uma pessoa pode pressionar a mesma tecla várias vezes ou pressionar espaço acidentalmente.
Além disso, o nome da marca tem um certo comprimento (“samsung” tem sete caracteres). As pessoas provavelmente não acabarão digitando de 20 a 50 caracteres.
Então, nesta expressão regular, estamos supondo que entre "s" e "m" em "samsung", alguém vai digitar de 1 a 4 caracteres errado. E então, de “m” a “g” no final, eles digitarão incorretamente de 1 a 6 caracteres, com espaços incluídos.
Adicionar tudo isso permite que você capture as muitas variações de uma consulta de marca de forma abrangente.
A outra coisa a notar é que o nome da marca pode aparecer em diferentes partes da consulta.

Portanto, precisamos garantir que o próprio nome da marca seja capturado. Deve ser:
- No início da consulta.
- No meio da consulta (portanto, cercado por espaços).
- Ou no final da consulta.
A expressão regular para isso é a seguinte:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Isso captura todas as consultas em que o nome da marca "samsung" está no início, no meio ou no fim.
- Início da string =
^ - Cercado por espaços =
\s - Fim da string =
$
A postagem de JC Chouinard, Expressões regulares (RegEx) no Google Search Console, aprofunda ainda mais os exemplos de regex.
Regex e a API GSC em ação
As expressões regulares foram úteis para Wu e sua equipe quando trabalharam com um cliente que encontrou quedas de tráfego após uma atualização principal.
Depois de analisar os diferentes problemas do site de comércio eletrônico, eles descobriram que o problema residia em algumas páginas de detalhes do produto.
Eles precisavam segmentar tipos de página para análise no GSC. Mas essa era uma tarefa complexa devido às diferentes estruturas de URL para produtos americanos e internacionais.

Os URLs de produtos internacionais do site incluíam códigos de idioma e país, enquanto os URLs de produtos dos EUA não.
Mesmo usar a sintaxe regex foi complicado porque letras e traços existem no slug, categorias e subcategorias do produto. Além disso, eles precisavam filtrar os URLs de produtos internacionais para capturar apenas as páginas dos EUA.
Para obter todas as páginas de destino + detalhes do produto nos EUA ( não páginas i18n), eles criaram as seguintes strings regex:
Incluir: /([^/]+/){1,2}p?
Excluir: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Aqui está um detalhamento:

A equipe queria combinar a categoria, a subcategoria e todos os produtos para que incluíssem:
- Qualquer caractere que não seja uma barra =
[^/]+ - 1 ou 2 diretórios =
/){1,2} - Às vezes seguido por um produto slug =
p?
Um acento circunflexo ( ^ ) normalmente significa o início da string. Mas quando está entre colchetes (como em [^/] ), indica uma negação (ou seja, “nada dentro desta caixa”).
Então essa string /([^/]+/){1,2}p? significa "Eu quero qualquer número de caracteres que não seja uma barra, levando a uma barra (que denota o diretório) e às vezes seguido pela letra 'p' (o prefixo para slugs de produtos)".
Ao mesmo tempo, a equipe não queria combinar a combinação de país e idioma que também continha letras e traços, então excluiu:
- Qualquer diretório de 2 letras =
[a-zA-Z]{2} - Combinação de 2 letras + 2 letras lang-country =
[a-zA-Z]{2}-[a-zA-Z]{2}
Criar uma expressão regular para corresponder a todos os códigos de idioma e país por conta própria seria tedioso devido a todas as combinações possíveis, portanto, eles não conseguiram abordar isso da maneira que fizeram para consultas informativas (onde todos os tipos de combinação foram excluídos).
Mas mesmo depois de criar essas strings regex, elas tiveram um problema.
No Google Search Console, há apenas um campo para colar uma string regex. Você terá que escolher Corresponde ao regex ou Não corresponde ao regex – você não pode usar os dois ao mesmo tempo.
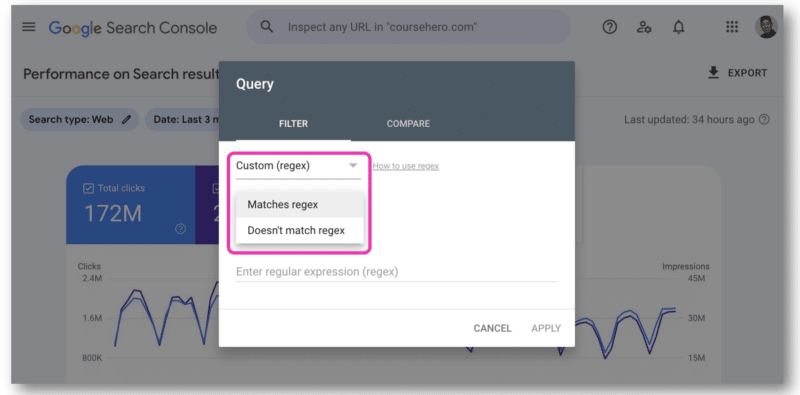
Foi aqui que a API GSC foi útil, pois permite unir strings regex.
Na documentação da API do Google Search Console, há um link Experimente agora .
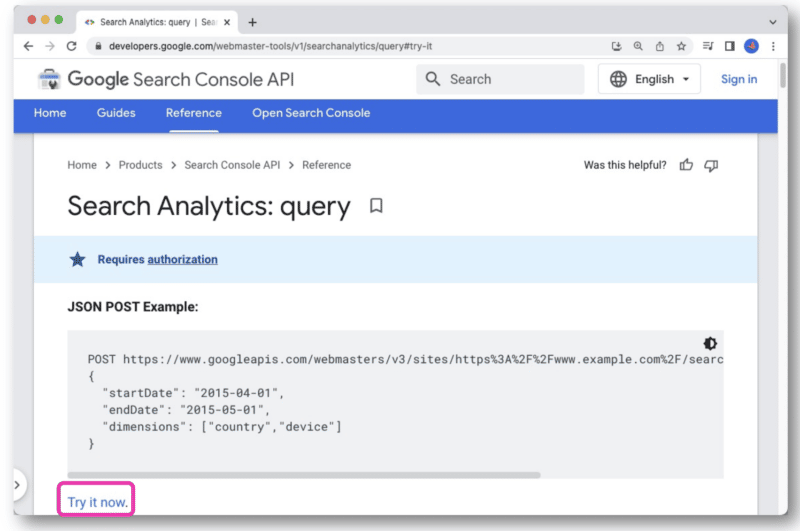
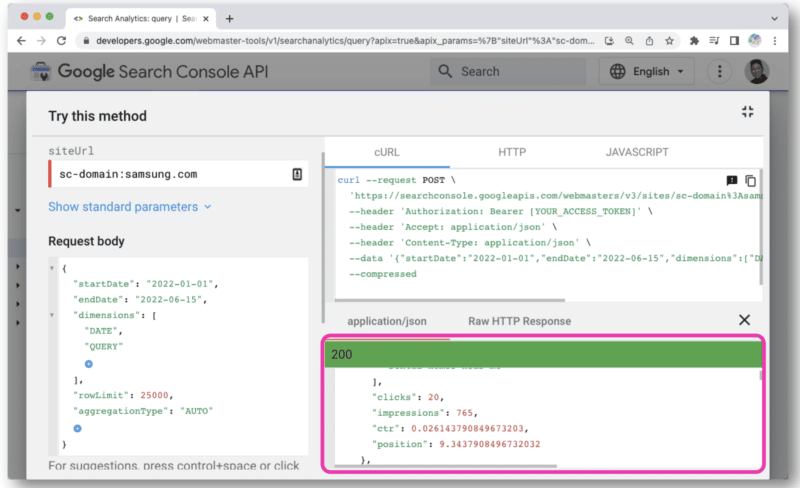
Uma vez clicado, ele abrirá um console que permite selecionar um site e fazer sua solicitação de API por meio da visualização da web.
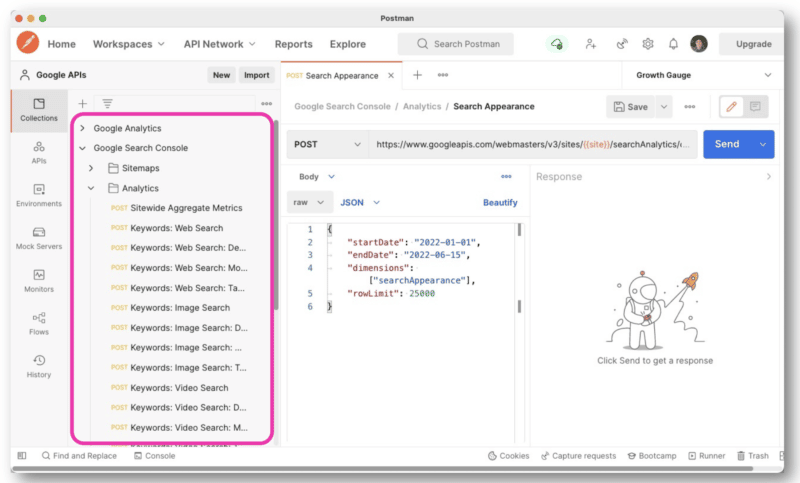
Mas para gerenciar melhor as consultas de API, Wu recomenda usar o Postman na área de trabalho ou o Paw (que é nativo do Mac).
O Postman permite criar consultas e salvá-las para mais tarde. E se você tiver acesso a outros sites, não precisará criar uma nova consulta a cada vez. Você simplesmente altera o nome do site com uma variável e faz várias solicitações.
Paw, por outro lado, é muito mais fácil de olhar e utilizar.
Para acessar a API, você precisará obter suas chaves de API. (Aqui está um tutorial útil de Chouinard.)
Depois de obter essas informações, você terá o ID do cliente e os segredos do cliente, que serão adicionados à autenticação do OAuth 2.0 no Postman ou no Paw.
A partir daí, você poderá fazer login com sua conta normal.
Wu fez principalmente solicitações de API GSC usando as strings regex em Paw. A consulta é inserida no meio da interface.
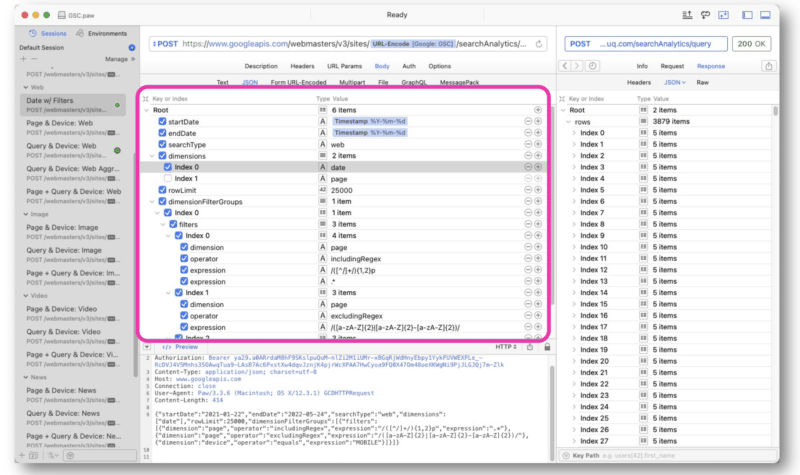
A resposta do Google é semelhante à da visualização da Web da API GSC. Os dados podem então ser exportados para processamento.
Como os dados estão em JSON, as informações podem ser confusas e difíceis de ler.

Para isso, você pode usar um processador JSON de linha de comando gratuito e de código aberto chamado JQ para imprimir as informações.

Os dados não são tão úteis até que você os coloque em uma planilha. Encaminhe o arquivo que você exportou de Paw para JQ. Abra-o e itere em cada linha – salvando cada elemento para que você possa enviá-los para um CSV.
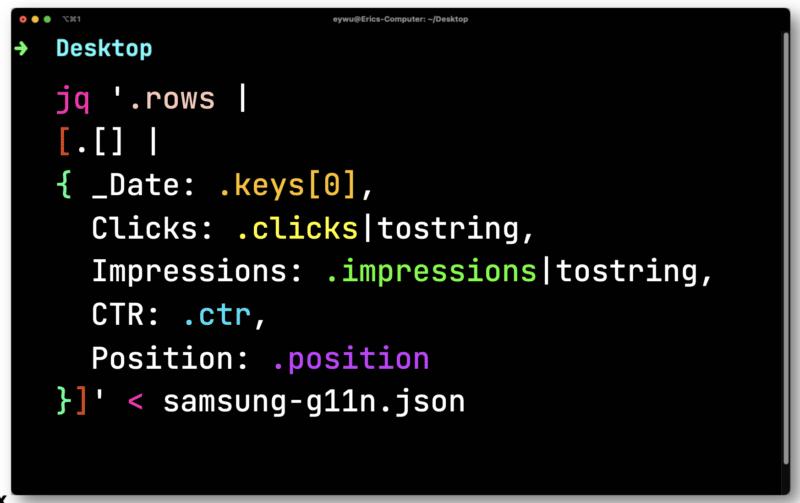
Aqui, você precisará converter cliques e impressões que são flutuantes (um número que tem uma casa decimal). Ambos precisam ser convertidos em strings compatíveis com um CSV.
O JQ produzirá o seguinte formato muito mais simples.
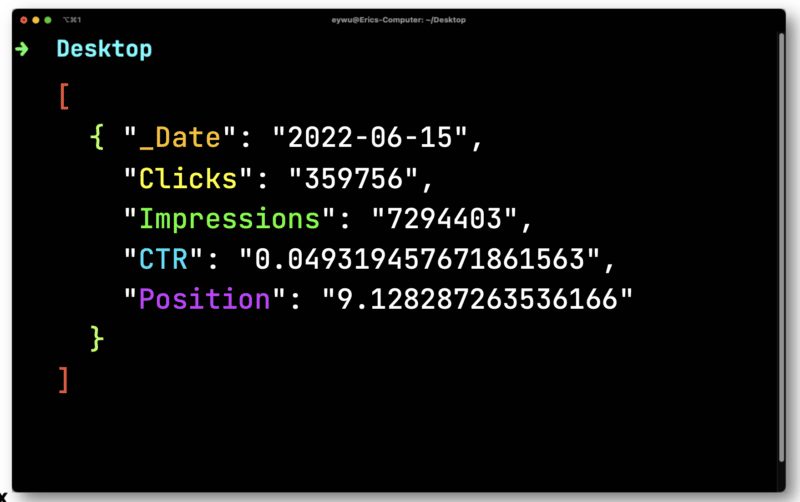
Em seguida, você usará o Dasel para pegar esse formato e transformá-lo em um CSV.
E aqui está o resultado final.
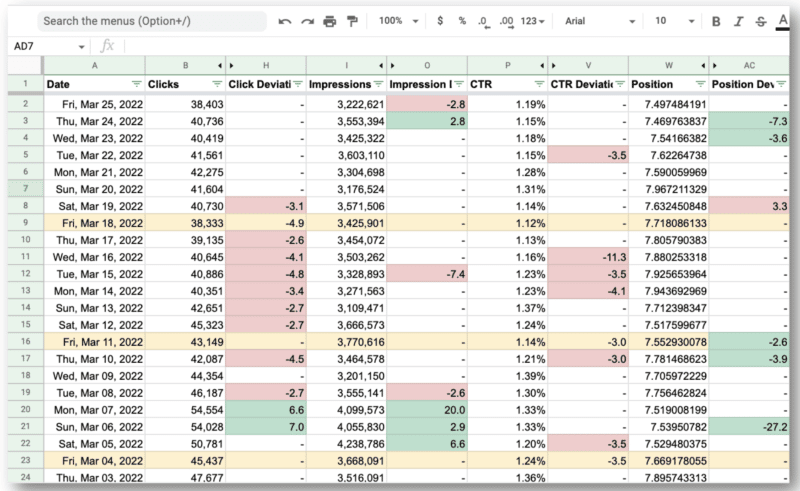
O que é incrível para a equipe de Wu é que eles conseguiram usar a API do Google Search Console e as expressões regulares para:
- Filtre todas as consultas internacionais e veja apenas os EUA onde eles estavam tendo os principais problemas.
- Identifique os dias em que o site estava com problemas.
Assista: Aproveitando ao máximo a API do Google Search Console
Abaixo está o vídeo completo da apresentação SMX Advanced de Wu.