
O Google está usando um sistema semelhante ao ChatGPT para detecção de spam e conteúdo de IA e classificação de sites?
Publicados: 2023-02-01O título é intencionalmente enganoso – mas apenas no que diz respeito ao uso do termo “ChatGPT”.
“ChatGPT-like” imediatamente permite que você, leitor, conheça o tipo de tecnologia a que estou me referindo, em vez de descrever o sistema como “um modelo de geração de texto como GPT-2 ou GPT-3”. (Além disso, o último realmente não seria tão clicável…)
O que veremos neste artigo é um artigo do Google mais antigo, mas altamente relevante, de 2020, “Modelos generativos são preditores não supervisionados da qualidade da página: um estudo em escala colossal”.
Do que se trata o papel?
Vamos começar com a descrição dos autores. Eles introduzem o tema assim:
“Muitos levantaram preocupações sobre os perigos potenciais dos geradores de texto neural em estado selvagem, em grande parte devido à sua capacidade de produzir texto com aparência humana em escala.
Classificadores treinados para discriminar entre texto gerado por máquina e humano foram recentemente empregados para monitorar a presença de texto gerado por máquina na web [29]. Pouco trabalho, no entanto, foi feito na aplicação desses classificadores para outros usos, apesar de sua propriedade atraente de não exigir rótulos – apenas um corpus de texto humano e um modelo generativo. Neste trabalho, mostramos por meio de avaliação humana rigorosa que os discriminadores humanos x máquinas disponíveis no mercado servem como poderosos classificadores de qualidade de página . Ou seja, textos que parecem gerados por máquinas tendem a ser incoerentes ou ininteligíveis. Para entender a presença de baixa qualidade de página, aplicamos os classificadores a uma amostra de meio bilhão de páginas da Web em inglês.”
O que eles estão dizendo essencialmente é que descobriram que os mesmos classificadores desenvolvidos para detectar cópias baseadas em IA, usando os mesmos modelos para gerá-las, podem ser usados com sucesso para detectar conteúdo de baixa qualidade.
Claro, isso nos deixa com uma pergunta importante:
Isso é causalidade (ou seja, o sistema está captando porque é genuinamente bom nisso) ou correlação (ou seja, muitos spams atuais são criados de maneira fácil de contornar com ferramentas melhores)?
Antes de explorar isso, no entanto, vamos ver alguns dos trabalhos dos autores e suas descobertas.
a configuração
Para referência, eles usaram o seguinte em seu experimento:
- Dois modelos de geração de texto , o detector GPT-2 baseado em RoBERTa da OpenAI (um detector que usa o modelo RoBERTa com saída GPT-2 e prevê se é provável que seja gerado por IA ou não) e o modelo GLTR, que também tem acesso aos principais saída GPT-2 e opera de forma semelhante.
Podemos ver um exemplo da saída deste modelo no conteúdo que copiei do paper acima:
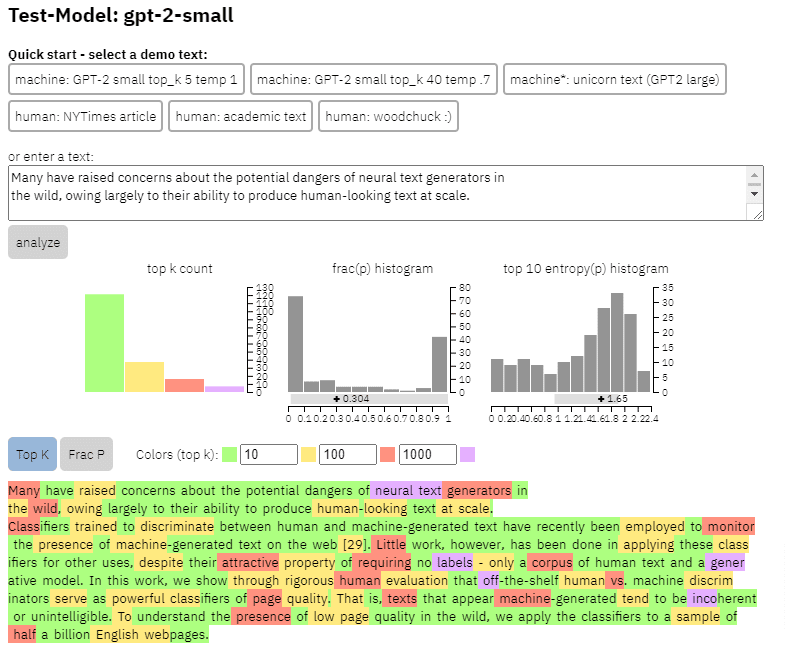
- Três conjuntos de dados Web500M (uma amostragem aleatória de 500 milhões de páginas da web em inglês), GPT-2 Output (250k GPT-2 gerações de texto) e Grover-Output (eles geraram internamente 1,2 milhão de artigos usando o modelo Grover-Base pré-treinado, que foi projetado para detectar notícias falsas).
- The Spam Baseline , um classificador treinado no conjunto de dados de e-mail de spam da Enron. Eles usaram esse classificador para estabelecer o número de qualidade de idioma que atribuiriam, portanto, se o modelo determinou que um documento não é spam com uma probabilidade de 0,2, a pontuação de qualidade de idioma (LQ) atribuída foi de 0,2.
Obtenha a newsletter diária em que os profissionais de marketing de busca confiam.
Consulte os termos.
Um aparte sobre a prevalência de spam
Eu queria fazer um rápido aparte para discutir algumas descobertas interessantes com as quais os autores se depararam. Um é ilustrado na figura a seguir (Figura 3 do papel):
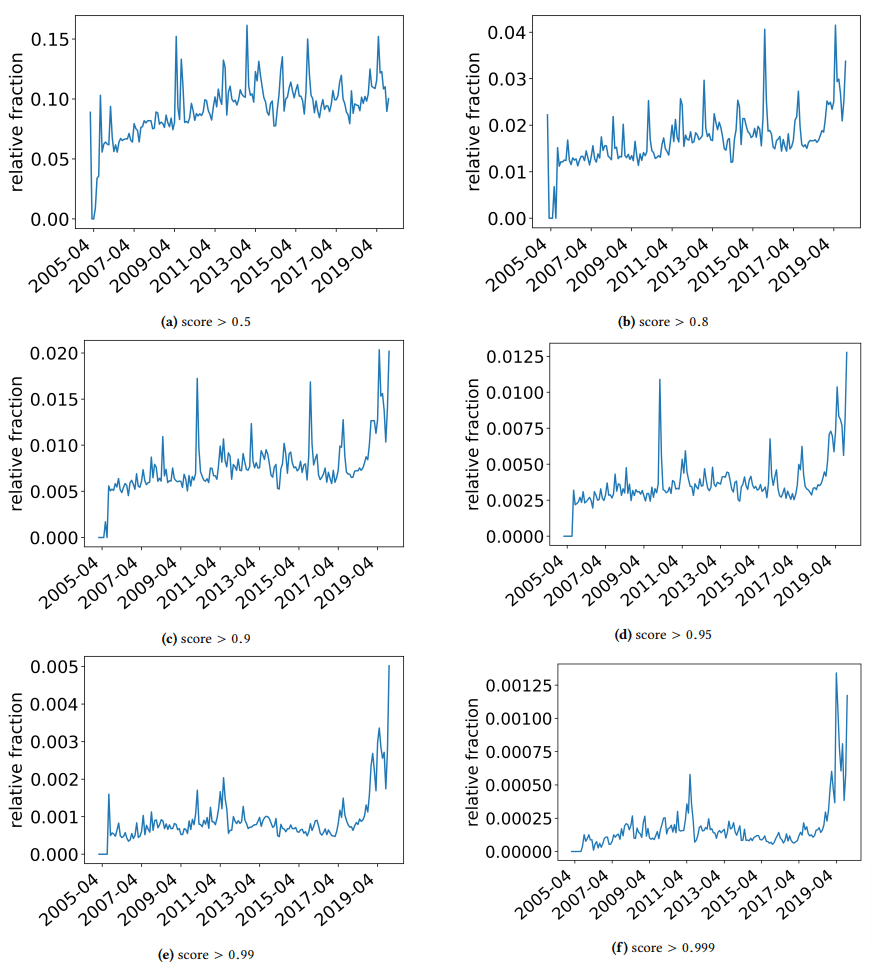
É importante observar a pontuação abaixo de cada gráfico. Um número em direção a 1,0 está se movendo para uma confiança de que o conteúdo é spam. O que estamos vendo então é que a partir de 2017 – e com pico em 2019 – houve uma prevalência de documentos de baixa qualidade.
Além disso, eles descobriram que o impacto do conteúdo de baixa qualidade era maior em alguns setores do que em outros (lembrando que uma pontuação mais alta reflete uma maior probabilidade de spam).
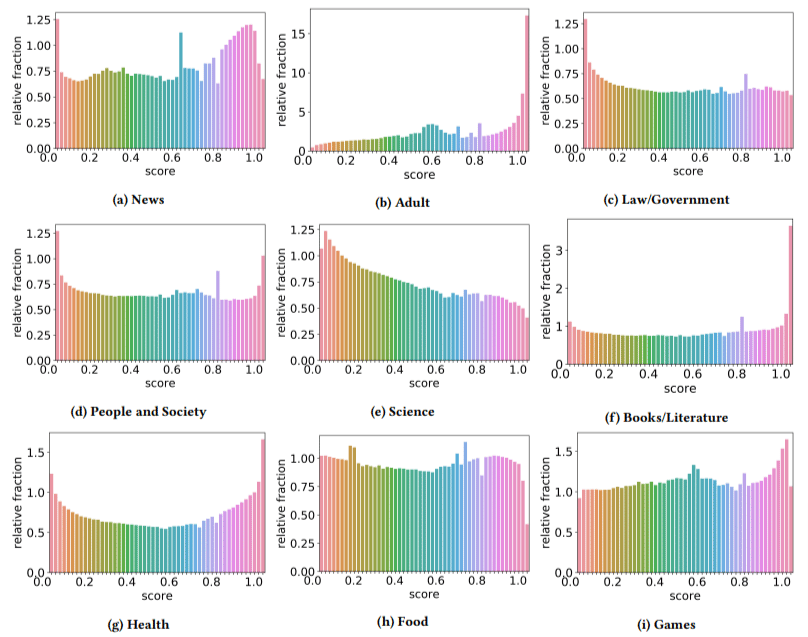
Eu cocei minha cabeça em alguns deles. Adulto fazia sentido, obviamente.
Mas os livros e a literatura foram uma surpresa. E a saúde também - até que os autores mencionaram o Viagra e outros sites de "produtos de saúde para adultos" como "saúde" e fazendas de ensaios como "literatura" - isto é.
Suas descobertas
Além do que discutimos sobre setores e o pico em 2019, os autores também encontraram várias coisas interessantes com as quais os SEOs podem aprender e devem ter em mente, especialmente quando começamos a nos apoiar em ferramentas como o ChatGPT.
- O conteúdo de baixa qualidade tende a ser menor (chegando a 3.000 caracteres).
- Os sistemas de detecção treinados para determinar se o texto foi escrito por uma máquina ou não também são bons para classificar conteúdo de baixo e alto nível.
- Eles chamam nosso conteúdo projetado para classificações como um culpado específico, embora eu suspeite que estejam se referindo ao lixo que todos sabemos que não deveria estar lá.
Os autores não afirmam que esta é uma solução definitiva, mas sim um ponto de partida e tenho certeza de que eles avançaram a barra nos últimos dois anos.
Uma observação sobre conteúdo gerado por IA
Os modelos de linguagem também se desenvolveram ao longo dos anos. Embora o GPT-3 existisse quando este artigo foi escrito, os detectores que eles usavam eram baseados no GPT-2, que é um modelo significativamente inferior.
O GPT-4 provavelmente está chegando e o Sparrow do Google está programado para ser lançado ainda este ano. Isso significa que não apenas a tecnologia está melhorando em ambos os lados do campo de batalha (geradores de conteúdo versus mecanismos de pesquisa), mas também as combinações serão mais fáceis de colocar em jogo.
O Google pode detectar conteúdo criado por Sparrow ou GPT-4? Pode ser.
Mas e se fosse gerado com Sparrow e depois enviado para GPT-4 com um prompt de reescrita?
Outro fator que precisa ser lembrado é que as técnicas utilizadas neste trabalho são baseadas em modelos auto-regressivos. Simplificando, eles preveem uma pontuação para uma palavra com base no que eles preveem que essa palavra será dada às que a precederam.
À medida que os modelos desenvolvem um grau mais alto de sofisticação e começam a criar ideias completas de cada vez, em vez de uma palavra seguida por outra, a detecção de IA pode falhar.
Por outro lado, a detecção de conteúdo simplesmente ruim deve aumentar – o que pode significar que o único conteúdo de “baixa qualidade” que vencerá é gerado por IA.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.