
Instalação do Hadoop usando o Ambari
Publicados: 2015-12-11Tudo o que você quer saber sobre a instalação do Hadoop usando o Ambari
O Apache Hadoop tornou-se uma estrutura de software de fato para computação confiável, escalável, distribuída e em grande escala. Ao contrário de outros sistemas de computação, ele traz computação para dados em vez de enviar dados para computação. O Hadoop foi criado em 2006 no Yahoo por Doug Cutting com base em um artigo publicado pelo Google. À medida que o Hadoop amadureceu, ao longo dos anos muitos novos componentes e ferramentas foram adicionados ao seu ecossistema para aprimorar sua usabilidade e funcionalidade. Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig, Sqoop etc., para citar alguns.
Por que Ambari?
Com a crescente popularidade do Hadoop, muitos desenvolvedores adotam essa tecnologia para experimentá-la. Mas como se costuma dizer, o Hadoop não é para fracos de coração, muitos desenvolvedores nem conseguiram cruzar a barreira de instalar o Hadoop. Muitas distribuições oferecem sandbox pré-instalado de VM para experimentar coisas, mas não lhe dá a sensação de computação distribuída. No entanto, instalar um multi-nó não é uma tarefa fácil e com um número crescente de componentes, é muito complicado lidar com tantos parâmetros de configuração. Felizmente Apache Ambari vem aqui em nosso socorro!
O que é Ambari?
Apache Ambari é uma ferramenta baseada na web para provisionamento, gerenciamento e monitoramento de clusters Apache Hadoop. O Ambari fornece um painel para visualizar a integridade do cluster, como mapas de calor e capacidade de visualizar aplicativos MapReduce, Pig e Hive visualmente, juntamente com recursos para diagnosticar suas características de desempenho de maneira amigável. Possui uma interface do usuário muito simples e interativa para instalar várias ferramentas e realizar várias tarefas de gerenciamento, configuração e monitoramento. Abaixo, mostramos várias etapas na instalação do Hadoop e seus vários componentes do ecossistema no cluster de vários nós.
A arquitetura Ambari é mostrada abaixo
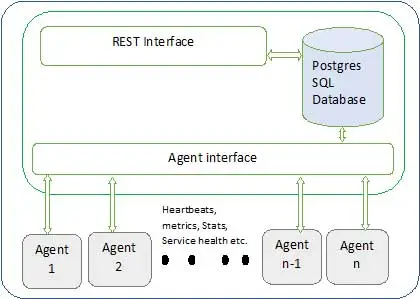
Ambari tem dois componentes
- Servidor Ambari – Este é o processo mestre que se comunica com os agentes Ambari instalados em cada nó participante do cluster. Isso tem uma instância de banco de dados postgres que é usada para manter todos os metadados relacionados ao cluster.
- Agente Ambari – Estes são agentes atuantes para o Ambari em cada nó. Cada agente envia periodicamente seu próprio status de integridade, juntamente com diferentes métricas, status de serviços instalados e muito mais. De acordo com o mestre decide sobre a próxima ação e transmite de volta ao agente para agir.
Como instalar o Ambari?
A instalação do Ambari é uma tarefa fácil de poucos comandos.
Abordaremos a instalação do Ambari e a configuração do cluster. Assume-se que temos 4 nós. Nó1, Nó2, Nó3 e Nó4. E estamos escolhendo o Node1 como nosso servidor Ambari.
Estes são passos de instalação no sistema baseado em RHEL, para o debian e outros passos de sistemas irão variar pouco.
- Instalação do Ambari: –
Do nó do servidor Ambari (nó 1 como decidimos)
eu. Baixe o repositório público Ambari

Este comando adicionará o repositório Hortonworks Ambari ao yum, que é um gerenciador de pacotes padrão para sistemas RHEL.
ii. Instale o Ambari RPMS

Isso levará algum tempo e instalará o Ambari neste sistema.

iii. Configurando o servidor Ambari
A próxima coisa a fazer após a instalação do Ambari é configurar o Ambari e configurá-lo para provisionar o cluster.
O passo a seguir cuidará disso


4. Inicie o servidor e faça login na interface do usuário da web
Inicie o servidor com

Agora podemos acessar a interface do usuário da web do Ambari (hospedado na porta 8080).
Faça login no Ambari com o nome de usuário padrão “admin” e a senha padrão “admin”
Configurando o cluster do Hadoop
1. Página de destino
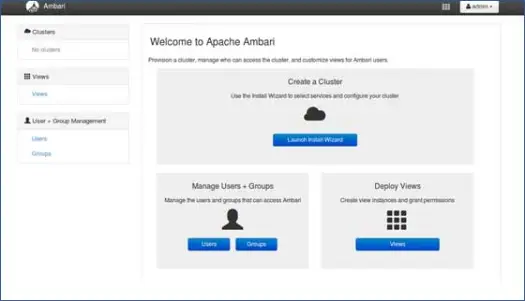
Clique em “Launch Install Wizard” para iniciar a configuração do cluster
2. Nome do cluster
Dê ao cluster um bom nome.
Nota: Este é apenas um nome simples para cluster, não é tão significativo, então não se preocupe com isso e escolha qualquer nome para ele.
3. Seleção de pilha
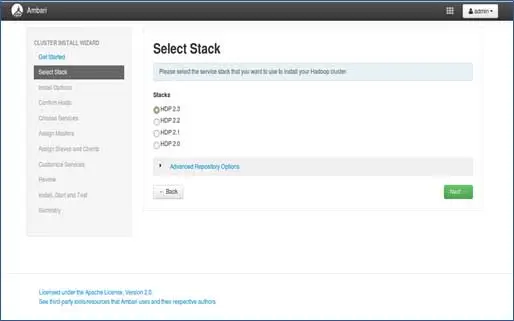
Esta página listará as pilhas disponíveis para instalação. Cada pilha é pré-empacotada com o componente do ecossistema Hadoop. Essas pilhas são da Hortonworks. (Podemos instalar o Hadoop simples também. Isso abordaremos em posts posteriores).
4. Entrada de hosts e entrada de chave SSH

Antes de avançar nesta etapa, devemos ter uma configuração SSH sem senha para todos os nós participantes.
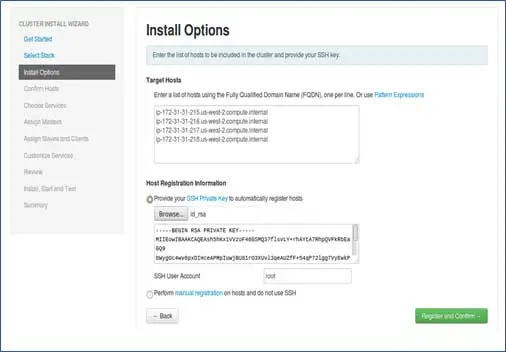
Adicione os nomes de host dos nós, entrada única em cada linha. [Adicionar FQDN que pode ser obtido pelo comando hostname –f]. Selecione a chave privada usada ao configurar a senha menos SSH e nome de usuário usando qual chave privada foi criada.
5. Status de registro de anfitriões
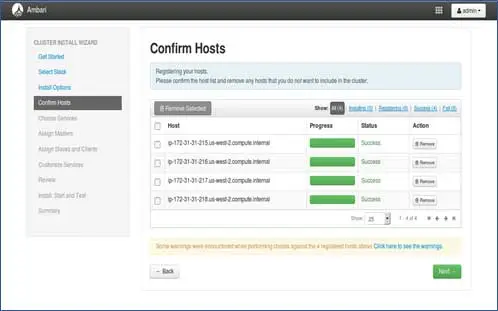
Você pode ver algumas operações sendo executadas, essas operações incluem a configuração do agente Ambari em cada nó, criando configurações básicas em cada nó. Uma vez que vemos ALL GREEN estamos prontos para seguir em frente. Às vezes, isso pode levar tempo, pois instala poucos pacotes.

6. Escolha os serviços que deseja instalar
De acordo com as pilhas selecionadas na etapa 3, temos o número de serviços que podemos instalar no cluster. Você pode escolher o que quiser. O Ambari seleciona de forma inteligente os serviços dependentes se você não os tiver selecionado. Por exemplo, você selecionou o HBase, mas não o Zookeeper, ele solicitará o mesmo e adicionará o Zookeeper também ao cluster.
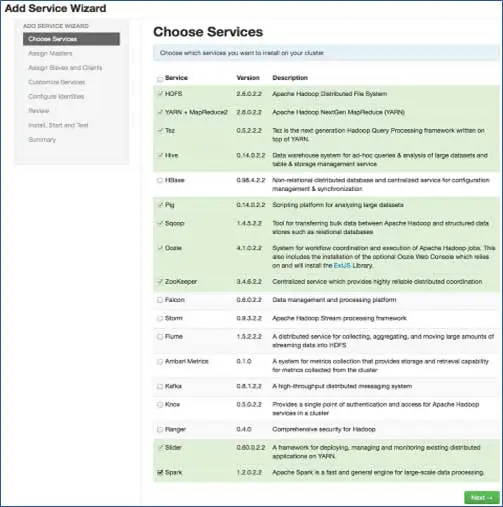
7. Mapeamento de serviços mestre com nós
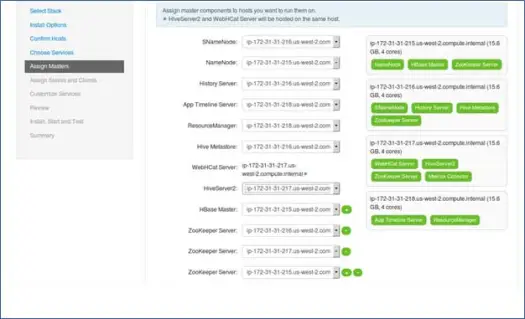
Como você sabe, o ecossistema Hadoop possui ferramentas baseadas na arquitetura mestre-escravo. Nesta etapa, associaremos os processos mestres ao nó. Aqui, certifique-se de equilibrar adequadamente seu cluster. Além disso, lembre-se de que serviços primários e secundários, como Namenode e Namenode secundário, não estão na mesma máquina.

8. Mapeamento de escravos com nós
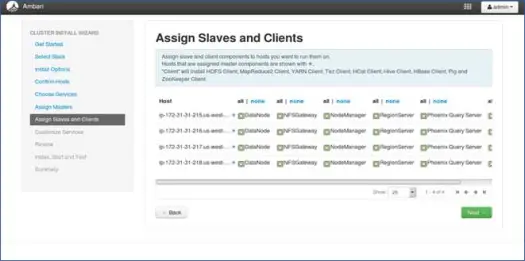
Semelhante aos mestres, mapeie os serviços escravos nos nós. Em geral, todos os nós terão um processo escravo rodando pelo menos para Datanodes e Nodemanagers.
9. Personalize serviços
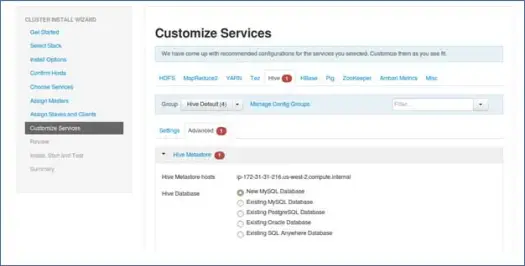
Esta é uma página muito importante para os administradores.
Aqui você pode configurar as propriedades do seu cluster para torná-lo mais adequado aos seus casos de uso.
Também terá algumas propriedades obrigatórias como a senha do metastore do Hive (se o hive estiver selecionado) etc. Estes serão apontados com erros vermelhos como símbolos.
10. Revise e inicie o provisionamento
Certifique-se de revisar a configuração do cluster antes de iniciar, pois isso evitará configurações erradas definidas inconscientemente.
11. Inicie e fique para trás até que o status fique VERDE.
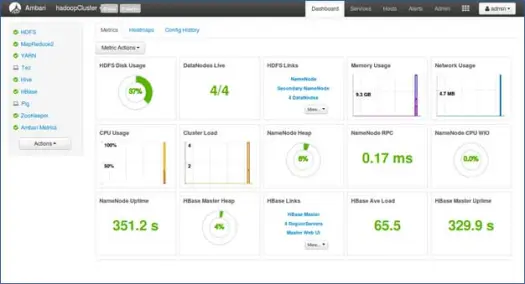
Próximos passos
Eba! Instalamos com sucesso o Hadoop e todos os componentes em todos os nós do cluster. Agora podemos começar a brincar com o Hadoop.
O Ambari executa um trabalho de contagem de palavras MapReduce para verificar se tudo está funcionando bem. Vamos verificar o log que o trabalho executou pelo usuário ambari-qa.
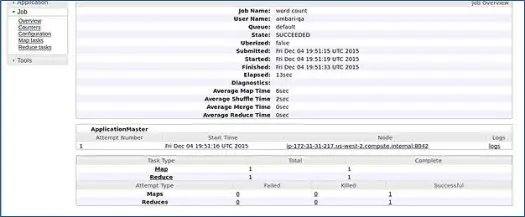
Como você pode ver na captura de tela acima, o trabalho WordCount foi concluído com sucesso. Isso confirma que nosso cluster está funcionando bem.
Conclusão
É isso, agora aprendemos como instalar o Hadoop e seus componentes no cluster de vários nós usando uma ferramenta simples baseada na Web chamada Apache Ambari. O Apache Ambari nos fornece uma interface mais simples e economiza muito de nossos esforços na instalação, monitoramento e gerenciamento, o que seria muito tedioso com tantos componentes e suas diferentes etapas de instalação e controles de monitoramento.
Deixe-me deixá-lo com um hack

O Ambari Installer verifica /etc/lsb-release para obter detalhes do SO. No Linux Mint, o mesmo arquivo para a versão do Ubuntu está em /etc/upstream-release/lsb-release. Para enganar o instalador, basta substituir o primeiro pelo último (você deve fazer backup do arquivo primeiro).

Em algum momento após a instalação, você pode restaurar o original com:

PS Este é um hack sem garantias, funcionou para mim, então pensei em compartilhá-lo com você.
Você é um desenvolvedor/dev-ops e precisa instalar o Hadoop rapidamente. Temos uma boa notícia para você, o Ambari fornece uma maneira pela qual você pode pular o processo completo do assistente e o processo de instalação concluído com um único script, e eu o trarei no próximo post, então fique atento e até lá Feliz Hadooping!