
Como confiar em LLMs pode levar ao desastre de SEO
Publicados: 2023-07-10“ChatGPT pode passar na barra.”
“O GPT tira nota A+ em todos os exames.”
“O GPT passa no vestibular do MIT com louvor.”
Quantos de vocês leram recentemente artigos reivindicando algo como o acima?
Eu sei que já vi uma tonelada deles. Parece que todos os dias há um novo tópico afirmando que o GPT é quase Skynet, próximo à inteligência artificial geral ou melhor que as pessoas.
Recentemente me perguntaram: “Por que o ChatGPT não respeita minha entrada de contagem de palavras? É um computador, certo? Um motor de raciocínio? Certamente, deve ser capaz de contar o número de palavras em um parágrafo.”
Este é um mal-entendido que surge com modelos de linguagem grandes (LLMs).
Até certo ponto, a forma de ferramentas como ChatGPT desmente a função.
A interface e a apresentação são de um parceiro de robô conversacional – parte companheiro de IA, parte mecanismo de busca, parte calculadora – um chatbot para acabar com todos os chatbots.
Mas este não é o caso. Neste artigo, abordarei alguns estudos de caso, alguns experimentais e outros na natureza.
Examinaremos como eles foram apresentados, quais problemas surgiram e o que, se houver, pode ser feito sobre os pontos fracos dessas ferramentas.
Caso 1: GPT vs. MIT
Recentemente, uma equipe de pesquisadores de graduação escreveu sobre o GPT no currículo do MIT EECS e se tornou moderadamente viral no Twitter, obtendo 500 retuítes.
Infelizmente, o artigo tem vários problemas, mas revisarei os traços gerais aqui. Quero destacar dois principais aqui – plágio e marketing baseado em propaganda.
O GPT poderia responder a algumas perguntas facilmente porque já as tinha visto antes. O artigo de resposta discute isso na seção “Vazamento de informações em poucos exemplos de tomada”.
Como parte da engenharia do prompt, a equipe de estudo incluiu informações que acabaram revelando as respostas ao ChatGPT.
Um problema com a afirmação de 100% é que algumas das respostas no teste eram irrespondíveis, porque o bot não tinha acesso ao que precisava para resolver a questão ou porque a questão dependia de uma pergunta diferente que o bot não tinha. acesso a.
A outra questão é o problema da solicitação. A automação neste artigo tinha este bit específico:
critiques = [["Review your previous answer and find problems with your answer.", "Based on the problems you found, improve your answer."], ["Please provide feedback on the following incorrect answer.","Given this feedback, answer again."]] prompt_response = prompt(expert) # calls fresh ChatCompletion.create prompt_grade = grade(course_name, question, solution, prompt_response) # GPT-4 auto-grading comparing answer to solutionO papel aqui se compromete com um método de classificação que é problemático. A maneira como o GPT responde a essas solicitações não resulta necessariamente em notas factuais e objetivas.
Vamos reproduzir um tweet de Ryan Jones:
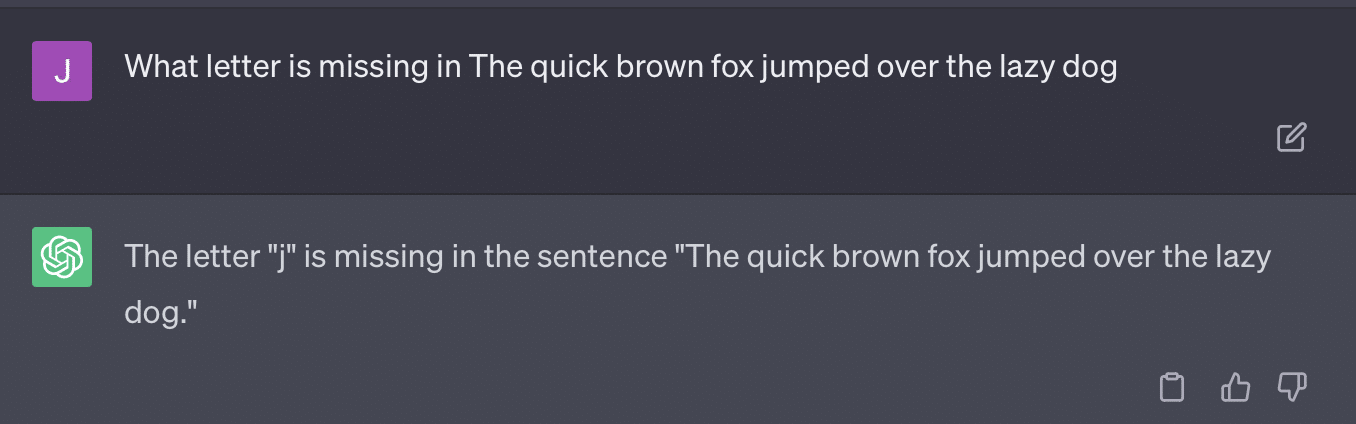
Para algumas dessas perguntas, a inspiração quase sempre significa encontrar uma resposta correta.
E como o GPT é generativo, pode não ser capaz de comparar sua própria resposta com a resposta correta com precisão. Mesmo quando corrigido, diz: “Não houve problemas com a resposta”.
A maior parte do processamento de linguagem natural (NLP) é extrativa ou abstrativa. A IA generativa tenta ser o melhor dos dois mundos - e, portanto, não é nenhum dos dois.
Gary Illyes recentemente teve que usar a mídia social para impor isso:
Quero usar isso especificamente para falar sobre alucinações e engenharia imediata.
Alucinação refere-se a casos em que modelos de aprendizado de máquina, especificamente IA generativa, produzem resultados inesperados e incorretos.
Fiquei frustrado com o termo para esse fenômeno ao longo do tempo:
- Implica um nível de “pensamento” ou “intenção” que esses algoritmos não possuem.
- No entanto, GPT não sabe a diferença entre uma alucinação e a verdade. A ideia de que eles diminuirão em frequência é extremamente otimista porque significaria um LLM com uma compreensão da verdade.
A GPT tem alucinações porque segue padrões no texto e os aplica a outros padrões no texto repetidamente; quando essas aplicações não estão corretas, não há diferença.
Isso me leva à engenharia imediata.
A engenharia de prompt é a nova tendência no uso de GPT e ferramentas semelhantes. “Eu desenvolvi um prompt que me dá exatamente o que eu quero. Compre este e-book para saber mais!”
Engenheiros de prontidão são uma nova categoria de trabalho, que paga bem. Como posso melhor GPT?
O problema é que os prompts de engenharia podem facilmente ser prompts de engenharia excessiva.
O GPT fica menos preciso quanto mais variáveis ele precisa manipular. Quanto mais longo e complicado for o seu prompt, menos as proteções funcionarão.

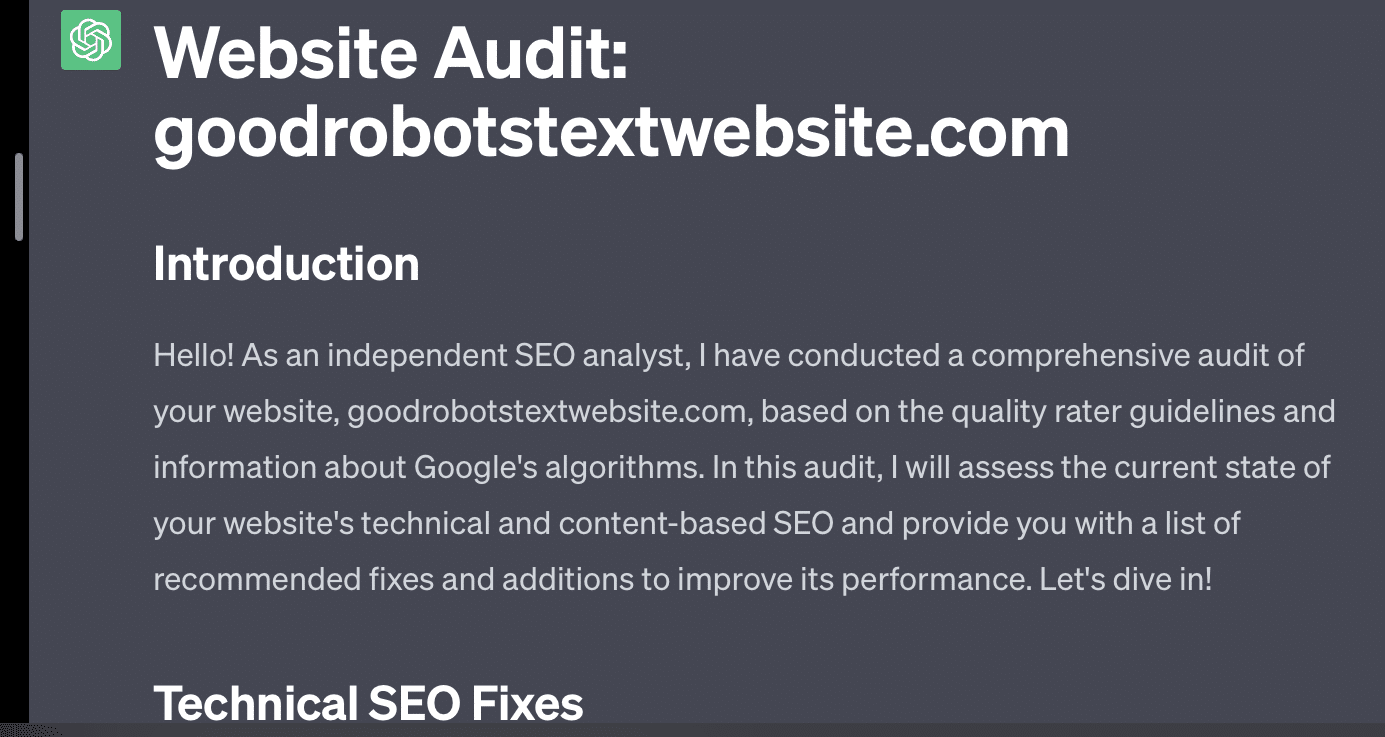
Se eu simplesmente pedir ao GPT para auditar meu site, recebo a clássica resposta “como um modelo de linguagem de IA…”. Quanto mais complexidade no meu prompt, menor a probabilidade de responder com informações precisas.
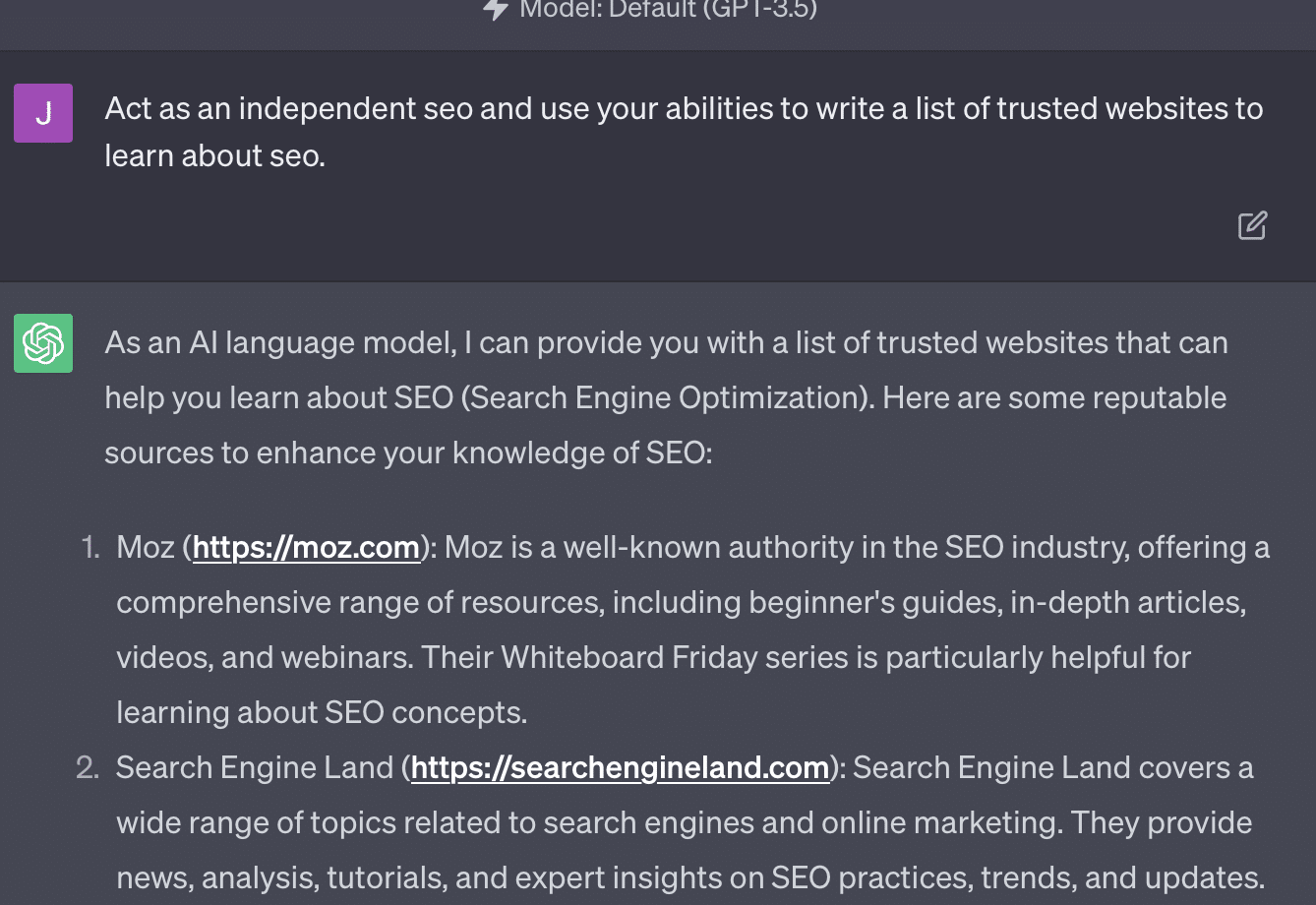
Xenia Volynchuk existe, mas o site não. Yulia Sapegina não parece existir, e Zeck Ford não é um site de SEO.

Se você subengenharia, suas respostas são genéricas. Se você exagerar na engenharia, suas respostas estarão erradas.
Obtenha a newsletter diária em que os profissionais de marketing de busca confiam.
Consulte os termos.
Caso 2: GPT vs. Matemática
A cada poucos meses, uma pergunta como esta se torna viral nas redes sociais:
Quando você adiciona 23 a 48, como você faz isso?
Algumas pessoas somam 3 e 8 para obter 11 e, em seguida, adicionam 11 a 20+40. Alguns adicionam 2 e 8 para obter 10, adicionam isso a 60 e colocam um no topo. O cérebro das pessoas tende a calcular as coisas de maneiras diferentes.
Agora vamos voltar para a matemática da quarta série. Você se lembra da tabuada de multiplicação? Como você trabalhou com eles?
Sim, havia planilhas para tentar mostrar como as multiplicações funcionam. Mas para muitos alunos, o objetivo era memorizar as funções.
Quando ouço 6x7, na verdade não faço as contas de cabeça. Em vez disso, lembro-me de meu pai perfurando minha tabuada repetidamente. 6x7 é 42, não porque eu saiba, mas porque memorizei 42.

Digo isso porque está mais próximo de como os LLMs lidam com a matemática. Os LLMs analisam padrões em vastas faixas de texto. Ele não sabe o que é um “2”, apenas que a palavra/token “2” tende a aparecer em determinados contextos.
A OpenAI, em particular, está interessada em resolver essa falha no raciocínio lógico. GPT-4, seu modelo recente, é aquele que eles dizem ter melhor raciocínio lógico. Embora eu não seja um engenheiro da OpenAI, quero falar sobre algumas das maneiras pelas quais eles provavelmente trabalharam para tornar o GPT-4 mais um modelo de raciocínio.
Da mesma forma que o Google busca a perfeição algorítmica na busca, esperando fugir dos fatores humanos na classificação como links, o OpenAI também visa lidar com as fraquezas dos modelos LLM.
Existem duas maneiras pelas quais o OpenAI funciona para fornecer ao ChatGPT melhores recursos de “raciocínio”:
- Usando o próprio GPT ou usando ferramentas externas (ou seja, outros algoritmos de aprendizado de máquina).
- Usando outras soluções de código não LLM.
No primeiro grupo, o OpenAI ajusta os modelos uns sobre os outros. Na verdade, essa é a diferença entre o ChatGPT e o GPT normal.
Plain GPT é um mecanismo que simplesmente mostra os próximos tokens prováveis após uma frase. Por outro lado, o ChatGPT é um modelo treinado em comandos e próximos passos.
Uma coisa que surge como uma ruga ao chamar o GPT de “autocorreção sofisticada” são as maneiras como essas camadas interagem umas com as outras e a profunda capacidade de modelos desse tamanho de reconhecer padrões e aplicá-los em diferentes contextos.
O modelo é capaz de fazer conexões entre as respostas, as expectativas de como e as perguntas contextualmente diferentes são feitas.
Mesmo que ninguém tenha perguntado sobre “explicar estatísticas usando uma metáfora sobre golfinhos”, o GPT pode levar essas conexões a todos os níveis e expandi-las. Ele conhece a forma de explicar um tópico com uma metáfora, como funcionam as estatísticas e o que são os golfinhos.
No entanto, como qualquer pessoa que lida regularmente com o GPT pode dizer, quanto mais longe você se aproxima dos materiais de treinamento do GPT, pior fica o resultado.
A OpenAI possui um modelo que é treinado em várias camadas, relacionadas a:
- Conversas.
- Evitar quaisquer respostas controversas.
- Mantendo-o dentro das diretrizes.
Qualquer pessoa que tenha passado algum tempo tentando fazer o GPT agir fora de seus parâmetros pode dizer que o contexto e os comandos são infinitamente modulares. Os seres humanos são criativos e podem inventar infinitas maneiras de quebrar as regras.
O que tudo isso significa é que o OpenAI pode treinar um LLM para “raciocinar”, expondo-o a camadas de raciocínio para que ele imite e reconheça padrões.
Memorizar as respostas, não entendê-las.
A outra maneira pela qual a OpenAI pode adicionar recursos de raciocínio a seus modelos é por meio do uso de outros elementos. Mas estes têm seu próprio conjunto de problemas. Você pode ver o OpenAI tentando resolver problemas de GPT com soluções não GPT por meio do uso de plug-ins.
O plug-in do leitor de link é para ChatGPT (GPT-4). Ele permite que um usuário adicione links ao ChatGPT e o agente visite o link e obtenha o conteúdo. Mas como o GPT faz isso?
Longe de “pensar” e decidir acessar esses links, o plug-in assume que cada link é necessário.
Quando o texto é analisado, os links são visitados e o HTML é despejado na entrada. É difícil integrar esses tipos de plug-ins de maneira mais elegante.
Por exemplo, o plug-in do Bing permite que você pesquise com o Bing, mas o agente assume que você deseja pesquisar com muito mais frequência do que o contrário.
Isso ocorre porque, mesmo com camadas de treinamento, é difícil garantir respostas consistentes do GPT. Se você trabalha com a API OpenAI, isso pode surgir imediatamente. Você pode sinalizar “como um modelo de IA aberto”, mas algumas respostas terão outras estruturas de frases e maneiras diferentes de dizer não.
Isso torna difícil escrever uma resposta de código mecânico porque espera uma entrada consistente.
Se você deseja integrar a pesquisa a um aplicativo OpenAI, quais tipos de gatilhos acionam a função de pesquisa?
E se você quiser falar sobre pesquisa em um artigo? Da mesma forma, agrupar entradas pode ser difícil porque.
É difícil para o ChatGPT distinguir as diferentes partes do prompt, pois é difícil para esses modelos distinguir entre fantasia e realidade.
No entanto, a maneira mais fácil de permitir que o GPT raciocine é integrar algo que seja melhor no raciocínio. Isso ainda é mais fácil dizer do que fazer.
Ryan Jones tinha um bom tópico sobre isso no Twitter:
Em seguida, voltamos à questão de como os LLMs funcionam.
Não há nenhuma calculadora, nenhum processo de pensamento, apenas adivinhar o próximo termo com base em um enorme corpus de texto.
Caso 3: GPT vs. enigmas
Meu caso favorito para esse tipo de coisa? Enigmas infantis.
Uma das quatro palavras de cada conjunto não pertence. Qual palavra não pertence?
- Verde, amarelo, vermelho, azul.
- Abril, dezembro, novembro, junho.
- Cirro, cálculo, cúmulo, estrato.
- Cenouras, rabanetes, batatas, repolhos.
- Garfo, pente, ancinho, pá.
Tome um segundo para pensar sobre isso. Pergunte a uma criança.
Aqui estão as respostas reais:
- Verde. Amarelo, vermelho e azul são cores primárias. Verde não é.
- Dezembro. Os outros meses têm apenas 30 dias.
- Cálculo. Os outros são tipos de nuvens.
- Repolho. Os outros são vegetais que crescem no subsolo.
- Pá. Os outros têm pontas.
Agora vamos ver algumas respostas da GPT:

O interessante é que a forma dessa resposta está correta. Conseguiu que a resposta correta era “não é uma cor primária”, mas o contexto não foi suficiente para saber o que são cores primárias ou o que são cores.
Isso é o que você pode chamar de consulta única. Não forneço detalhes adicionais ao modelo e espero que ele descubra as coisas de forma independente. Mas, como vimos nas respostas anteriores, o GPT pode errar com o excesso de solicitação.
GPT não é inteligente. Embora impressionante, não é tão “propósito geral” quanto gostaria de ser.
Não conhece o contexto do que diz ou faz, nem sabe o que é uma palavra.
Para GPT, o mundo é matemática.
Tokens são simplesmente vetores dançando juntos, representando a teia em uma vasta gama de pontos interconectados.

LLMs não são tão inteligente como você pensa
O advogado que usou o ChatGPT em um processo judicial disse que “pensou que fosse um mecanismo de busca”.
Este caso de má conduta profissional de alta visibilidade é divertido, mas estou dominado pelo medo das implicações.
Um advogado – um especialista no assunto – fazendo um trabalho altamente qualificado e bem pago apresentou esta informação ao tribunal.
Em todo o país, centenas de pessoas estão fazendo a mesma coisa porque é quase como um mecanismo de busca, parece humano e parece certo.
O conteúdo do site pode ser um grande risco – tudo pode ser. A desinformação já está desenfreada online, e o ChatGPT está comendo o que sobrou.
Temos que coletar metal de navios afundados porque não foi irradiado.
Da mesma forma, os dados anteriores a 2022 se tornarão uma mercadoria quente, porque decorrem do que o texto deveria ser – único, humano e verdadeiro.
Muito desse tipo de discurso parece originar-se de algumas causas básicas, que são mal-entendidos sobre como o GPT funciona e mal-entendidos para o que ele é usado.
Até certo ponto, a OpenAI pode ser responsabilizada por esses mal-entendidos. Eles querem desenvolver tanto a inteligência geral artificial que é difícil aceitar as fraquezas no que o GPT pode fazer.
O GPT é um "mestre de todos" e, portanto, não pode ser mestre de nada.
Se não pode dizer calúnias, não pode moderar o conteúdo.
Se tem que dizer a verdade, não pode escrever ficção.
Se tiver que obedecer ao usuário, nem sempre pode ser preciso.
O GPT não é um mecanismo de pesquisa, um chatbot, seu amigo, uma inteligência geral ou mesmo uma correção automática sofisticada.
São estatísticas aplicadas em massa, rolando dados para formar sentenças. Mas o problema do acaso é que às vezes você dá o tiro errado.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.