
Um guia de SEO para entender modelos de linguagem grandes (LLMs)
Publicados: 2023-05-08Devo usar modelos de linguagem grandes para pesquisa de palavras-chave? Esses modelos podem pensar? O ChatGPT é meu amigo?
Se você tem se feito essas perguntas, este guia é para você.
Este guia cobre o que os SEOs precisam saber sobre grandes modelos de linguagem, processamento de linguagem natural e tudo mais.
Grandes modelos de linguagem, processamento de linguagem natural e muito mais em termos simples
Existem duas maneiras de levar uma pessoa a fazer algo - dizer a ela para fazer ou esperar que ela mesma faça.
Quando se trata de ciência da computação, a programação diz ao robô para fazer isso, enquanto o aprendizado de máquina espera que o robô faça isso sozinho. O primeiro é aprendizado de máquina supervisionado e o último é aprendizado de máquina não supervisionado.
O processamento de linguagem natural (NLP) é uma maneira de dividir o texto em números e, em seguida, analisá-lo usando computadores.
Os computadores analisam padrões em palavras e, à medida que avançam, nas relações entre as palavras.
Um modelo de aprendizado de máquina de linguagem natural não supervisionado pode ser treinado em muitos tipos diferentes de conjuntos de dados.
Por exemplo, se você treinou um modelo de linguagem em avaliações médias do filme “Waterworld”, você teria um resultado bom para escrever (ou compreender) críticas do filme “Waterworld”.
Se você o treinasse nas duas críticas positivas que fiz do filme “Waterworld”, ele entenderia apenas essas críticas positivas.
Modelos de linguagem grande (LLMs) são redes neurais com mais de um bilhão de parâmetros. Eles são tão grandes que são mais generalizados. Eles não são treinados apenas em críticas positivas e negativas para “Waterworld”, mas também em comentários, artigos da Wikipédia, sites de notícias e muito mais.
Os projetos de aprendizado de máquina trabalham muito com o contexto – coisas dentro e fora do contexto.
Se você tem um projeto de aprendizado de máquina que funciona para identificar bugs e mostrar um gato, não será bom nesse projeto.
É por isso que coisas como carros autônomos são tão difíceis: há tantos problemas fora de contexto que é muito difícil generalizar esse conhecimento.
LLMs parecem e podem ser muito mais generalizado do que outros projetos de aprendizado de máquina. Isso se deve ao tamanho dos dados e à capacidade de processar bilhões de relacionamentos diferentes.
Vamos falar sobre uma das tecnologias revolucionárias que permitem isso – os transformadores.
Explicando transformadores do zero
Um tipo de arquitetura de rede neural, os transformadores revolucionaram o campo da PNL.
Antes dos transformadores, a maioria dos modelos de NLP dependia de uma técnica chamada redes neurais recorrentes (RNNs), que processava o texto sequencialmente, uma palavra por vez. Essa abordagem tinha suas limitações, como ser lenta e difícil de lidar com dependências de longo alcance no texto.
Transformers mudou isso.
No artigo de referência de 2017, “Atenção é tudo o que você precisa”, Vaswani et al. introduziu a arquitetura do transformador.
Em vez de processar o texto sequencialmente, os transformadores usam um mecanismo chamado “autoatenção” para processar palavras em paralelo, permitindo que capturem dependências de longo alcance com mais eficiência.
A arquitetura anterior incluía RNNs e algoritmos de memória de longo prazo.
Modelos recorrentes como esses eram (e ainda são) comumente usados para tarefas envolvendo sequências de dados, como texto ou fala.
No entanto, esses modelos têm um problema. Eles só podem processar os dados um pedaço de cada vez, o que os torna mais lentos e limita a quantidade de dados com os quais eles podem trabalhar. Esse processamento sequencial realmente limita a capacidade desses modelos.
Mecanismos de atenção foram introduzidos como uma maneira diferente de processar dados de sequência. Eles permitem que um modelo examine todos os dados de uma vez e decida quais são os mais importantes.
Isso pode ser muito útil em muitas tarefas. No entanto, a maioria dos modelos que usaram atenção também usa processamento recorrente.
Basicamente, eles tinham essa maneira de processar os dados de uma só vez, mas ainda precisavam analisá-los em ordem. O artigo de Vaswani et al. flutuava: “E se usássemos apenas o mecanismo de atenção?”
A atenção é uma forma de o modelo focar em certas partes da sequência de entrada ao processá-la. Por exemplo, quando lemos uma frase, naturalmente prestamos mais atenção em algumas palavras do que em outras, dependendo do contexto e do que queremos entender.
Se você olhar para um transformador, o modelo calcula uma pontuação para cada palavra na sequência de entrada com base em sua importância para a compreensão do significado geral da sequência.
O modelo então usa essas pontuações para pesar a importância de cada palavra na sequência, permitindo que ele se concentre mais nas palavras importantes e menos nas sem importância.
Esse mecanismo de atenção ajuda o modelo a capturar dependências e relacionamentos de longo alcance entre palavras que podem estar distantes na sequência de entrada sem ter que processar toda a sequência sequencialmente.
Isso torna o transformador tão poderoso para tarefas de processamento de linguagem natural, pois pode entender com rapidez e precisão o significado de uma frase ou uma sequência de texto mais longa.
Vamos pegar o exemplo de um modelo transformador processando a frase “O gato sentou no tapete”.
Cada palavra na frase é representada como um vetor, uma série de números, usando uma matriz de incorporação. Digamos que os embeddings para cada palavra sejam:
- O : [0,2, 0,1, 0,3, 0,5]
- gato : [0,6, 0,3, 0,1, 0,2]
- sat : [0,1, 0,8, 0,2, 0,3]
- em : [0,3, 0,1, 0,6, 0,4]
- o : [0,5, 0,2, 0,1, 0,4]
- tapete : [0,2, 0,4, 0,7, 0,5]
Em seguida, o transformador calcula uma pontuação para cada palavra da frase com base em sua relação com todas as outras palavras da frase.
Isso é feito usando o produto escalar da incorporação de cada palavra com as incorporações de todas as outras palavras na frase.
Por exemplo, para calcular a pontuação da palavra “gato”, tomaríamos o produto escalar de sua incorporação com as incorporações de todas as outras palavras:
- “ O gato “: 0,2*0,6 + 0,1*0,3 + 0,3*0,1 + 0,5*0,2 = 0,24
- “ gato sentado ”: 0,6*0,1 + 0,3*0,8 + 0,1*0,2 + 0,2*0,3 = 0,31
- “ gato em “: 0,6*0,3 + 0,3*0,1 + 0,1*0,6 + 0,2*0,4 = 0,39
- “ cat the “: 0,6*0,5 + 0,3*0,2 + 0,1*0,1 + 0,2*0,4 = 0,42
- “ tapete de gato “: 0,6*0,2 + 0,3*0,4 + 0,1*0,7 + 0,2*0,5 = 0,32
Essas pontuações indicam a relevância de cada palavra para a palavra “gato”. O transformador então usa essas pontuações para calcular uma soma ponderada das incorporações de palavras, onde os pesos são as pontuações.
Isso cria um vetor de contexto para a palavra “gato” que considera as relações entre todas as palavras da frase. Este processo é repetido para cada palavra na frase.
Pense nisso como o transformador desenhando uma linha entre cada palavra da frase com base no resultado de cada cálculo. Algumas linhas são mais tênues e outras menos.
O transformador é um novo tipo de modelo que usa apenas atenção sem nenhum processamento recorrente. Isso o torna muito mais rápido e capaz de lidar com mais dados.
Como o GPT usa transformadores
Você deve se lembrar que no anúncio do BERT do Google, eles se gabaram de permitir que a pesquisa entendesse o contexto completo de uma entrada. Isso é semelhante a como o GPT pode usar transformadores.
Vamos usar uma analogia.
Imagine que você tem um milhão de macacos, cada um sentado na frente de um teclado.
Cada macaco está pressionando teclas aleatoriamente em seu teclado, gerando sequências de letras e símbolos.
Algumas strings são totalmente absurdas, enquanto outras podem se assemelhar a palavras reais ou até mesmo a frases coerentes.
Um dia, um dos treinadores de circo vê que um macaco escreveu “Ser ou não ser”, então o treinador dá uma guloseima ao macaco.
Os outros macacos veem isso e começam a tentar imitar o macaco bem-sucedido, esperando o próprio deleite.
Com o passar do tempo, alguns macacos começam a produzir sequências de texto consistentemente melhores e mais coerentes, enquanto outros continuam a produzir palavras sem sentido.
Eventualmente, os macacos podem reconhecer e até emular padrões coerentes no texto.
Os LLMs têm uma vantagem sobre os macacos porque os LLMs são treinados primeiro em bilhões de pedaços de texto. Eles já podem ver os padrões. Eles também entendem os vetores e as relações entre essas partes do texto.
Isso significa que eles podem usar esses padrões e relacionamentos para gerar um novo texto que se assemelhe à linguagem natural.
GPT, que significa Generative Pre-trained Transformer, é um modelo de linguagem que usa transformadores para gerar texto em linguagem natural.
Ele foi treinado em uma enorme quantidade de texto da internet, o que lhe permitiu aprender os padrões e as relações entre palavras e frases em linguagem natural.
O modelo funciona pegando um prompt ou algumas palavras de texto e usando os transformadores para prever quais palavras devem vir a seguir com base nos padrões que aprendeu com seus dados de treinamento.
O modelo continua gerando texto palavra por palavra, usando o contexto das palavras anteriores para informar as próximas.
GPT em ação
Um dos benefícios do GPT é que ele pode gerar texto em linguagem natural altamente coerente e contextualmente relevante.
Isso tem muitas aplicações práticas, como gerar descrições de produtos ou responder a consultas de atendimento ao cliente. Também pode ser usado de forma criativa, como gerar poesia ou contos.
No entanto, é apenas um modelo de linguagem. Ele é treinado em dados e esses dados podem estar desatualizados ou incorretos.
- Não tem nenhuma fonte de conhecimento.
- Ele não pode pesquisar na internet.
- Não “sabe” nada.
Ele simplesmente adivinha qual palavra vem a seguir.
Vejamos alguns exemplos:
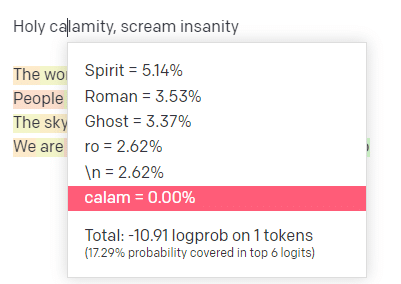
No playground do OpenAI, conectei a primeira linha da faixa clássica da Handsome Boy Modeling School 'Holy calamity [[Bear Witness ii]]'.
Enviei a resposta para que possamos ver a probabilidade de minhas linhas de entrada e saída. Então, vamos passar por cada parte do que isso nos diz.
Para a primeira palavra/símbolo, eu insiro “Santo”. Podemos ver que a próxima entrada mais esperada é Spirit, Roman e Ghost.
Também podemos ver que os seis primeiros resultados cobrem apenas 17,29% das probabilidades do que vem a seguir: o que significa que existem aproximadamente 82% de outras possibilidades que não podemos ver nesta visualização.
Vamos discutir brevemente as diferentes entradas que você pode usar nisso e como elas afetam sua saída.
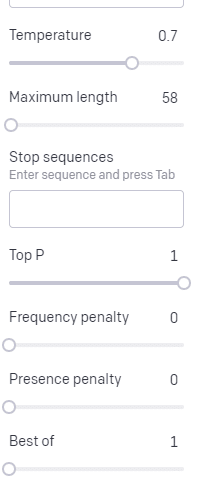
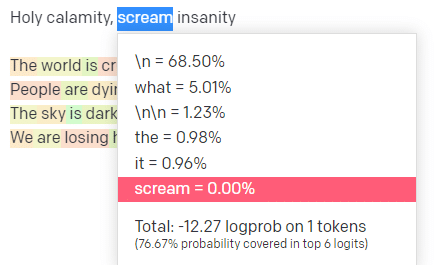
Temperatura é a probabilidade de o modelo pegar palavras diferentes daquelas com maior probabilidade, top P é como ele seleciona essas palavras.
Portanto, para a entrada “Holy Calamity”, o P superior é como selecionamos o cluster dos próximos tokens [Ghost, Roman, Spirit] e a temperatura é a probabilidade de ir para o token mais provável versus mais variedade.
Se a temperatura for mais alta, é mais provável que escolha um token menos provável .
Portanto, uma temperatura alta e um P superior alto provavelmente serão mais selvagens. Está escolhendo entre uma ampla variedade (alto P superior) e é mais provável que escolha tokens surpreendentes.


Enquanto um P superior de alta temperatura, mas mais baixo, escolherá opções surpreendentes de uma amostra menor de possibilidades:

E baixar a temperatura apenas escolhe os próximos tokens mais prováveis:

Jogar com essas probabilidades pode, na minha opinião, fornecer uma boa visão de como esses tipos de modelos funcionam.
Ele está analisando uma coleção de prováveis próximas seleções com base no que já foi concluído.
O que isso significa na verdade?
Simplificando, os LLMs pegam uma coleção de entradas, agitam-nas e as transformam em saídas.
Já ouvi pessoas brincarem sobre se isso é tão diferente das pessoas.
Mas não é como as pessoas – os LLMs não têm base de conhecimento. Eles não estão extraindo informações sobre uma coisa. Eles estão adivinhando uma sequência de palavras com base na última.
Outro exemplo: pense em uma maçã. O que vem à mente?
Talvez você possa girar um em sua mente.
Talvez você se lembre do cheiro de um pomar de maçãs, da doçura de uma dama rosada, etc.
Talvez você pense em Steve Jobs.
Agora vamos ver o que um prompt “pense em uma maçã” retorna.
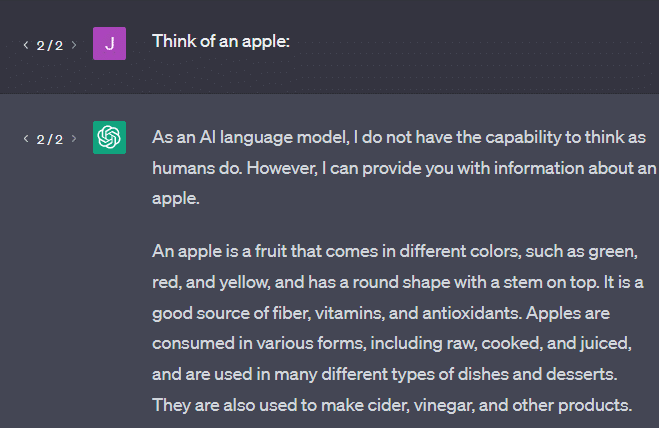
Você pode ter ouvido as palavras “Papagaios estocásticos” flutuando neste ponto.
Stochastic Parrots é um termo usado para descrever LLMs como GPT. Um papagaio é um pássaro que imita o que ouve.
Portanto, os LLMs são como papagaios, pois captam informações (palavras) e produzem algo que se assemelha ao que ouviram. Mas também são estocásticos , o que significa que usam a probabilidade para adivinhar o que vem a seguir.
Os LLMs são bons em reconhecer padrões e relacionamentos entre palavras, mas não têm uma compreensão mais profunda do que estão vendo. É por isso que eles são tão bons em gerar texto em linguagem natural, mas não em entendê-lo.
Bons usos para um LLM
LLMs são bons em tarefas mais generalistas.
Você pode mostrar o texto e, sem treinamento, ele pode executar uma tarefa com esse texto.
Você pode lançar algum texto e pedir uma análise de sentimento, pedir para transferir esse texto para marcação estruturada e fazer algum trabalho criativo (por exemplo, escrever esboços).
Tudo bem em coisas como código. Para muitas tarefas, quase pode chegar lá.
Mas, novamente, é baseado em probabilidade e padrões. Portanto, haverá momentos em que ele capta padrões em sua entrada que você não sabe que existem.
Isso pode ser positivo (ver padrões que os humanos não conseguem), mas também pode ser negativo (por que ele respondeu assim?).
Ele também não tem acesso a nenhum tipo de fonte de dados. Os SEOs que o usam para procurar palavras-chave de classificação terão um mau momento.
Ele não pode procurar tráfego para uma palavra-chave. Ele não possui as informações para dados de palavras-chave além das palavras existentes.

O interessante do ChatGPT é que ele é um modelo de idioma facilmente disponível que você pode usar imediatamente em várias tarefas. Mas não é sem ressalvas.
Bons usos para outros modelos de ML
Eu ouço as pessoas dizerem que estão usando LLMs para certas tarefas, que outros algoritmos e técnicas de PNL podem fazer melhor.

Vamos dar um exemplo, extração de palavra-chave.
Se eu usar TF-IDF, ou outra técnica de palavra-chave, para extrair palavras-chave de um corpus, saberei quais cálculos serão usados nessa técnica.
Isso significa que os resultados serão padronizados, reprodutíveis e sei que estarão relacionados especificamente àquele corpus.
Com LLMs como o ChatGPT, se você está solicitando a extração de palavras-chave, não está necessariamente obtendo as palavras-chave extraídas do corpus. Você está obtendo o que a GPT pensa que seria uma resposta para corpus + palavras-chave de extração.
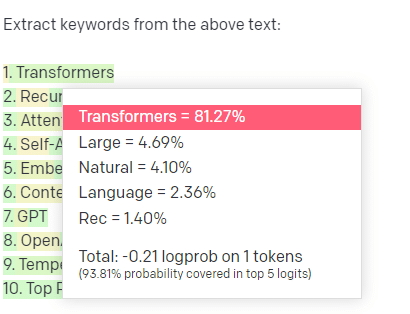
Isso é semelhante a tarefas como agrupamento ou análise de sentimento. Você não está necessariamente obtendo o resultado ajustado com os parâmetros que definiu. Você está obtendo o que há alguma probabilidade com base em outras tarefas semelhantes.
Novamente, os LLMs não têm base de conhecimento e nenhuma informação atual. Muitas vezes, eles não podem pesquisar na web e analisam o que obtêm das informações como tokens estatísticos. As restrições quanto à duração da memória de um LLM são devidas a esses fatores.
Outra coisa é que esses modelos não podem pensar. Eu só uso a palavra “pensar” algumas vezes ao longo deste artigo porque é realmente difícil não usá-la quando falo sobre esses processos.
A tendência é para o antropomorfismo, mesmo quando se discutem estatísticas sofisticadas.
Mas isso significa que, se você confiar um LLM a qualquer tarefa que exija “pensamento”, não estará confiando em uma criatura pensante.
Você está confiando em uma análise estatística de como centenas de esquisitos da Internet respondem a tokens semelhantes.
Se você confia em usuários da Internet com uma tarefa, pode usar um LLM. De outra forma…
Coisas que nunca devem ser modelos de ML
Um chatbot executado por meio de um modelo GPT (GPT-J) teria encorajado um homem a se matar. A combinação de fatores pode causar danos reais, incluindo:
- Pessoas antropomorfizando essas respostas.
- Acreditando que eles são infalíveis.
- Usá-los em locais onde os humanos precisam estar na máquina.
- E mais.
Embora você possa pensar: “Sou um SEO. Não tenho nada a ver com sistemas que podem matar alguém!”
Pense nas páginas YMYL e em como o Google promove conceitos como EEAT.
O Google faz isso porque quer irritar os SEOs ou porque não quer ser culpado por esse dano?
Mesmo em sistemas com fortes bases de conhecimento, danos podem ser causados.
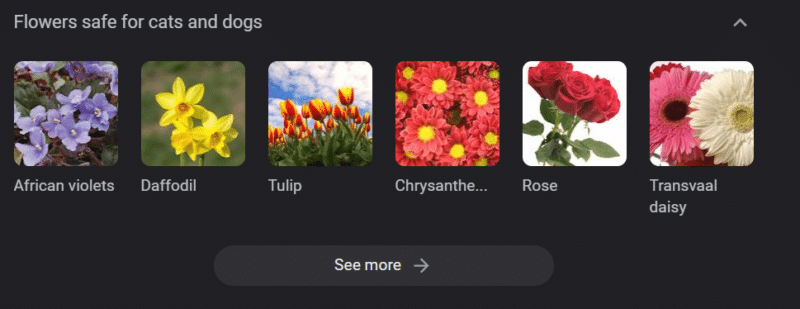
O texto acima é um carrossel de conhecimento do Google para “flores seguras para cães e gatos”. Os narcisos estão nessa lista, apesar de serem tóxicos para os gatos.
Digamos que você esteja gerando conteúdo para um site veterinário em grande escala usando GPT. Você conecta um monte de palavras-chave e faz ping na API ChatGPT.
Você tem um freelancer lendo todos os resultados e ele não é um especialista no assunto. Eles não percebem um problema.
Você publica o resultado, o que incentiva a compra de narcisos para donos de gatos.
Você mata o gato de alguém.
Não diretamente. Talvez eles nem saibam que foi aquele site em particular.
Talvez os outros sites veterinários comecem a fazer a mesma coisa e se alimentando uns dos outros.
O principal resultado de pesquisa do Google para “os narcisos são tóxicos para gatos” é um site que diz que não.
Outros freelancers lendo outros conteúdos de IA – páginas e mais páginas de conteúdo de IA – na verdade verificam os fatos. Mas os sistemas agora têm informações incorretas.
Ao discutir esse atual boom de IA, menciono muito o Therac-25. É um estudo de caso famoso de má conduta de computador.
Basicamente, era uma máquina de radioterapia, a primeira a usar apenas mecanismos de bloqueio de computador. Uma falha no software significava que as pessoas recebiam dezenas de milhares de vezes a dose de radiação que deveriam receber.
Algo que sempre me chama a atenção é que a empresa voluntariamente recolheu e inspecionou esses modelos.
Mas presumiram que, como a tecnologia era avançada e o software “infalível”, o problema estava nas partes mecânicas da máquina.
Assim, repararam os mecanismos mas não verificaram o software – e o Therac-25 manteve-se no mercado.
Perguntas frequentes e equívocos
Por que o ChatGPT mente para mim?
Uma coisa que vi de algumas das maiores mentes de nossa geração e também influenciadores no Twitter é uma reclamação de que o ChatGPT “mentira” para eles. Isso se deve a alguns equívocos em conjunto:
- Esse ChatGPT tem “desejos”.
- Que tenha uma base de conhecimento.
- Que os tecnólogos por trás da tecnologia têm algum tipo de agenda além de “ganhar dinheiro” ou “fazer uma coisa legal”.
Os preconceitos estão presentes em todas as partes do seu dia-a-dia. Assim como as exceções a esses vieses.
A maioria dos desenvolvedores de software atualmente são homens: eu sou um desenvolvedor de software e uma mulher.
Treinar uma IA com base nessa realidade a levaria a sempre assumir que os desenvolvedores de software são homens, o que não é verdade.
Um exemplo famoso é a IA de recrutamento da Amazon, treinada em currículos de funcionários bem-sucedidos da Amazon.
Isso levou ao descarte de currículos de faculdades de maioria negra, embora muitos desses funcionários pudessem ter sido extremamente bem-sucedidos.
Para combater esses vieses, ferramentas como o ChatGPT usam camadas de ajuste fino. É por isso que você obtém a resposta “Como modelo de linguagem de IA, não posso…”.
Alguns trabalhadores no Quênia tiveram que passar por centenas de avisos, procurando calúnias, discursos de ódio e respostas e avisos absolutamente terríveis.
Em seguida, uma camada de ajuste fino foi criada.
Por que você não pode inventar insultos sobre Joe Biden? Por que você pode fazer piadas sexistas sobre homens e não sobre mulheres?
Não é devido ao viés liberal, mas por causa de milhares de camadas de ajuste fino dizendo ao ChatGPT para não dizer a palavra com N.
Idealmente, o ChatGPT seria totalmente neutro em relação ao mundo, mas eles também precisam dele para refletir o mundo.
É um problema semelhante ao que o Google tem.
O que é verdade, o que deixa as pessoas felizes e o que dá uma resposta correta a uma solicitação geralmente são coisas muito diferentes .
Por que o ChatGPT apresenta citações falsas?
Outra questão que vejo surgir com frequência é sobre citações falsas. Por que alguns deles são falsos e outros reais? Por que alguns sites são reais, mas as páginas são falsas?
Esperançosamente, lendo como os modelos estatísticos funcionam, você pode analisar isso. Mas aqui vai uma breve explicação:
Você é um modelo de linguagem AI. Você foi treinado em uma tonelada da web.
Alguém lhe diz para escrever sobre uma coisa tecnológica – digamos Mudança Cumulativa de Layout.
Você não tem muitos exemplos de artigos CLS, mas sabe o que é e conhece a forma geral de um artigo sobre tecnologias. Você conhece o padrão de aparência desse tipo de artigo.

Então você começa com sua resposta e se depara com um tipo de problema. Da maneira como você entende a redação técnica, você sabe que uma URL deve ser a próxima em sua frase.
Bem, de outros artigos do CLS, você sabe que o Google e o GTMetrix são frequentemente citados sobre o CLS, então esses são fáceis.
Mas você também sabe que os truques de CSS geralmente são vinculados a artigos da web: você sabe que geralmente os URLs de truques de CSS têm uma determinada aparência: então você pode construir um URL de truques de CSS como este:
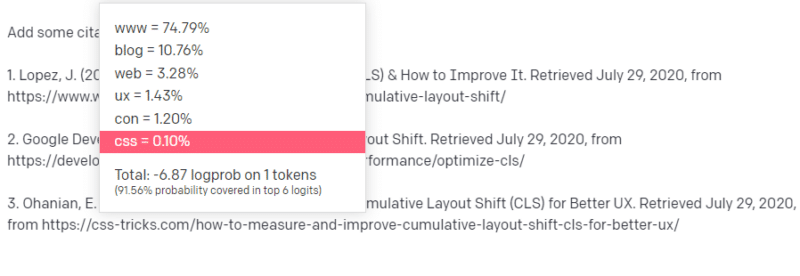
O truque é: é assim que todas as URLs são construídas, não apenas as falsas:

Este artigo do GTMetrix existe: mas existe porque era uma provável sequência de valores que viria no final desta frase.
GPT e modelos semelhantes não conseguem distinguir entre uma citação real e uma falsa.
A única maneira de fazer essa modelagem é usar outras fontes (bases de conhecimento, Python, etc.) para analisar essa diferença e verificar os resultados.
O que é um 'Papagaio Estocástico'?
Eu sei que já passei por isso, mas vale a pena repetir. Papagaios estocásticos são uma maneira de descrever o que acontece quando grandes modelos de linguagem parecem generalistas por natureza.
Para o LLM, nonsense e realidade são a mesma coisa. Eles veem o mundo como um economista, como um monte de estatísticas e números descrevendo a realidade.
Você conhece a citação: “Existem três tipos de mentiras: mentiras, mentiras malditas e estatísticas”.
LLMs são um grande monte de estatísticas.
Os LLMs parecem coerentes, mas isso ocorre porque fundamentalmente vemos as coisas que parecem humanas como humanas.
Da mesma forma, o modelo chatbot ofusca grande parte das solicitações e informações necessárias para que as respostas GPT sejam totalmente coerentes.
Sou um desenvolvedor: tentar usar LLMs para depurar meu código tem resultados extremamente variáveis. Se for um problema semelhante ao que as pessoas costumam ter online, os LLMs podem detectar e corrigir esse resultado.
Se for um problema que não foi encontrado antes, ou se for uma pequena parte do corpus, não resolverá nada.
Por que o GPT é melhor do que um mecanismo de pesquisa?
Eu redigido isso de uma forma picante. Não acho que o GPT seja melhor do que um mecanismo de pesquisa. Preocupa-me que as pessoas tenham substituído a pesquisa pelo ChatGPT.
Uma parte pouco reconhecida do ChatGPT é o quanto ele existe para seguir as instruções. Você pode pedir para fazer basicamente qualquer coisa.
Mas lembre-se, tudo é baseado na próxima palavra estatística de uma frase, não na verdade.
Portanto, se você fizer uma pergunta que não tenha uma boa resposta, mas de uma maneira que seja obrigada a responder, obterá uma resposta ruim.
Ter uma resposta projetada para você e ao seu redor é mais reconfortante, mas o mundo é uma massa de experiências.
Todas as entradas em um LLM são tratadas da mesma forma: mas algumas pessoas têm experiência e sua resposta será melhor do que uma mistura de respostas de outras pessoas.
Um especialista vale mais do que mil peças de pensamento.
É este o alvorecer da IA? A Skynet está aqui?
Koko, o gorila, era um macaco que aprendeu a linguagem de sinais. Pesquisadores em estudos linguísticos fizeram toneladas de pesquisas mostrando que os macacos poderiam aprender a linguagem.
Herbert Terrace então descobriu que os macacos não estavam juntando frases ou palavras, mas simplesmente imitando seus manipuladores humanos.
Eliza era uma terapeuta de máquinas, uma das primeiras chatterbots (chatbots).
As pessoas a viam como uma pessoa: uma terapeuta em quem confiavam e com quem se importavam. Eles pediram aos pesquisadores que ficassem a sós com ela.
A linguagem faz algo muito específico no cérebro das pessoas. As pessoas ouvem algo se comunicar e esperam pensar por trás disso.
Os LLMs são impressionantes, mas de uma forma que mostram uma amplitude de realização humana.
LLMs não têm testamentos. Eles não podem escapar. Eles não podem tentar dominar o mundo.
Eles são um espelho: um reflexo das pessoas e do usuário especificamente.
O único pensamento que existe é uma representação estatística do inconsciente coletivo.
O GPT aprendeu um idioma inteiro sozinho?
Sundar Pichai, CEO do Google, continuou em “60 Minutes” e afirmou que o modelo de idioma do Google aprendeu bengali.
O modelo foi treinado nesses textos. É incorreto dizer que “falava uma língua estrangeira para a qual nunca foi treinado”.
Há momentos em que a IA faz coisas inesperadas, mas isso em si é esperado.
Quando você está olhando para padrões e estatísticas em grande escala, necessariamente haverá momentos em que esses padrões revelarão algo surpreendente.
O que isso realmente revela é que muitos dos C-suite e do pessoal de marketing que estão vendendo IA e ML não entendem realmente como os sistemas funcionam.
Já ouvi algumas pessoas muito espertas falarem sobre propriedades emergentes, inteligência artificial geral (AGI) e outras coisas futurísticas.
Posso ser apenas um simples engenheiro de operações de ML do país, mas isso mostra quanto exagero, promessas, ficção científica e realidade se misturam ao falar sobre esses sistemas.
Elizabeth Holmes, a infame fundadora da Theranos, foi crucificada por fazer promessas que não puderam ser cumpridas.
Mas o ciclo de fazer promessas impossíveis faz parte da cultura das startups e de ganhar dinheiro. A diferença entre o hype da Theranos e da IA é que a Theranos não conseguiu fingir por muito tempo.
O GPT é uma caixa preta? O que acontece com meus dados no GPT?
GPT é, como modelo, não uma caixa preta. Você pode ver o código-fonte para GPT-J e GPT-Neo.
O GPT da OpenAI é, no entanto, uma caixa preta. A OpenAI não lançou e provavelmente tentará não liberar seu modelo, já que o Google não libera o algoritmo.
Mas não é porque o algoritmo é muito perigoso. Se isso fosse verdade, eles não venderiam assinaturas de API para nenhum cara bobo com um computador. É por causa do valor dessa base de código proprietária.
Ao usar as ferramentas da OpenAI, você está treinando e alimentando a API deles com suas entradas. Isso significa que tudo que você coloca no OpenAI o alimenta.
Isso significa que as pessoas que usaram o modelo GPT da OpenAI nos dados do paciente para ajudar a escrever anotações e outras coisas violaram o HIPAA. Essa informação está agora no modelo e será extremamente difícil extraí-la.
Como muitas pessoas têm dificuldade em entender isso, é muito provável que o modelo contenha toneladas de dados privados, apenas aguardando o prompt certo para liberá-los.
Por que o GPT é treinado em discurso de ódio?
Outra coisa que surge com frequência é que o corpus de texto em que o GPT foi treinado inclui discurso de ódio.
Até certo ponto, a OpenAI precisa treinar seus modelos para responder ao discurso de ódio, por isso precisa ter um corpus que inclua alguns desses termos.
A OpenAI alegou eliminar esse tipo de discurso de ódio do sistema, mas os documentos de origem incluem o 4chan e toneladas de sites de ódio.
Rastreie a web, absorva o viés.
Não há uma maneira fácil de evitar isso. Como você pode fazer com que algo reconheça ou entenda ódio, preconceito e violência sem tê-lo como parte de seu conjunto de treinamento?
Como você evita preconceitos e entende preconceitos implícitos e explícitos quando é um agente de máquina selecionando estatisticamente o próximo token em uma frase?
TL;DR
O hype e a desinformação são atualmente os principais elementos do boom da IA. Isso não significa que não haja usos legítimos: essa tecnologia é incrível e útil.
Mas como a tecnologia é comercializada e como as pessoas a usam pode promover desinformação, plágio e até mesmo causar danos diretos.
Não use LLMs quando a vida estiver em jogo. Não use LLMs quando um algoritmo diferente for melhor. Não se deixe enganar pelo hype.
Compreender o que são LLMs – e não são – é necessário
Eu recomendo esta entrevista de Adam Conover com Emily Bender e Timnit Gebru.
Os LLMs podem ser ferramentas incríveis quando usados corretamente. Existem muitas maneiras de usar LLMs e ainda mais maneiras de abusar dos LLMs.
ChatGPT não é seu amigo. É um monte de estatísticas. A AGI não “já está aqui”.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.