
Spark vs Hadoop: qual estrutura de Big Data elevará seu negócio?
Publicados: 2019-09-24“Dados são o combustível da Economia Digital”
Com as empresas modernas contando com uma grande quantidade de dados para entender melhor seus consumidores e mercado, tecnologias como Big Data estão ganhando um enorme impulso.
O Big Data, assim como a IA, não acabou de entrar na lista das principais tendências de tecnologia para 2020 , mas deve ser adotado por startups e empresas da Fortune 500 para desfrutar de um crescimento exponencial dos negócios e garantir maior fidelidade do cliente. Uma indicação clara disso é que o mercado de Big Data deve atingir US$ 103 bilhões até 2027.
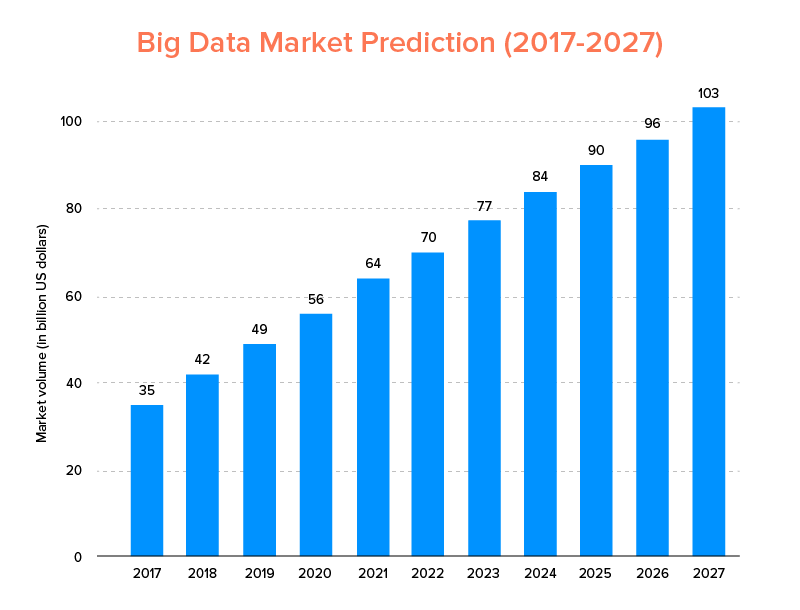
Agora, embora todos estejam altamente motivados para substituir suas ferramentas tradicionais de análise de dados por Big Data – aquele que prepara o terreno para o avanço do Blockchain e da IA, eles também estão confusos sobre como escolher a ferramenta de Big Data certa. Eles estão enfrentando o dilema de escolher entre Apache Hadoop e Spark – os dois titãs do mundo do Big Data.
Portanto, considerando esse pensamento, hoje abordaremos um artigo sobre Apache Spark vs Hadoop e ajudaremos você a determinar qual é a opção certa para suas necessidades.
Mas, primeiro, vamos fazer uma breve introdução do que é Hadoop e Spark.
O Apache Hadoop é uma estrutura de código aberto, distribuída e baseada em Java que permite aos usuários armazenar e processar big data em vários clusters de computadores usando construções de programação simples. É composto por vários módulos que trabalham juntos para oferecer uma experiência aprimorada, que são: -
- Hadoop comum
- Hadoop Distributed File System (HDFS)
- FIO do Hadoop
- Hadoop MapReduce
Por outro lado, o Apache Spark é uma estrutura de big data de computação em cluster distribuída de código aberto que é 'fácil de usar' e oferece serviços mais rápidos.
As duas estruturas de big data são apoiadas por inúmeras grandes empresas devido ao conjunto de oportunidades que oferecem.
Vantagens do Hadoop Big Data Framework
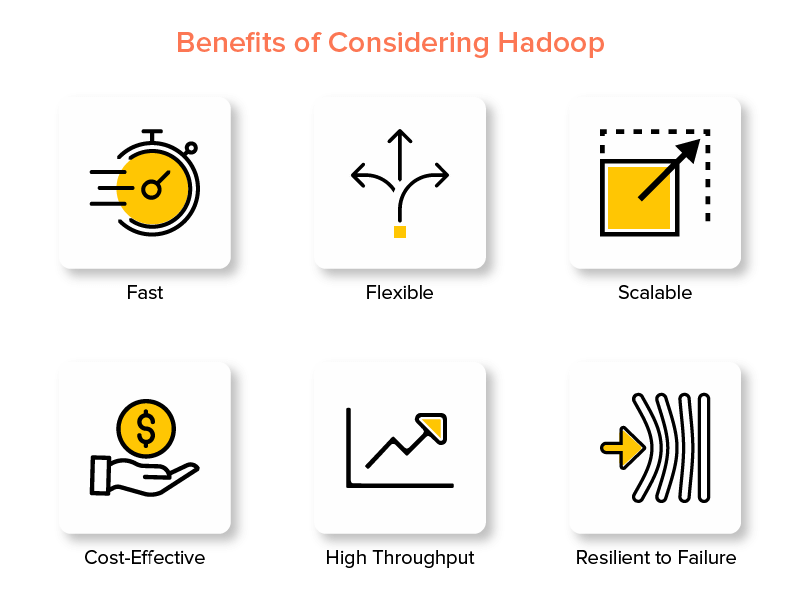
1. Rápido
Um dos recursos do Hadoop que o torna popular no mundo do big data é que ele é rápido.
Seu método de armazenamento é baseado em um sistema de arquivos distribuído que basicamente 'mapeia' os dados onde quer que estejam localizados em um cluster. Além disso, os dados e as ferramentas usadas para processamento de dados geralmente estão disponíveis no mesmo servidor, o que torna o processamento de dados uma tarefa mais rápida e sem complicações.
Na verdade, descobriu-se que o Hadoop pode processar terabytes de dados não estruturados em apenas alguns minutos, enquanto petabytes em horas.
2. Flexível
O Hadoop, ao contrário das ferramentas tradicionais de processamento de dados, oferece flexibilidade de ponta.
Ele permite que as empresas coletem dados de diferentes fontes (como mídias sociais, e-mails, etc.), trabalhem com diferentes tipos de dados (estruturados e não estruturados) e obtenham informações valiosas para uso posterior para fins variados (como processamento de logs, análise de campanhas de mercado, detecção de fraudes, etc).
3. Escalável
Outra vantagem do Hadoop é que ele é altamente escalável. A plataforma, ao contrário dos tradicionais sistemas de banco de dados relacional (RDBMS) , permite que as empresas armazenem e distribuam grandes conjuntos de dados de centenas de servidores que operam paralelamente.
4. Custo-benefício
O Apache Hadoop, quando comparado a outras ferramentas de análise de big data, é muito barato. Isso porque não requer nenhuma máquina especializada; ele é executado em um grupo de hardware comum. Além disso, é mais fácil adicionar mais nós a longo prazo.
Ou seja, um caso aumenta facilmente os nós sem sofrer nenhum tempo de inatividade dos requisitos de pré-planejamento.
5. Alto rendimento
No caso da estrutura Hadoop, os dados são armazenados de maneira distribuída, de modo que um pequeno trabalho seja dividido em vários blocos de dados em paralelo. Isso torna mais fácil para as empresas realizar mais trabalhos em menos tempo, o que acaba resultando em maior rendimento.
6. Resistente a Falhas
Por último, mas não menos importante, o Hadoop oferece opções de alta tolerância a falhas que ajudam a mitigar as consequências da falha. Ele armazena uma réplica de cada bloco que possibilita a recuperação de dados sempre que algum nó estiver inativo.
Desvantagens do Hadoop Framework
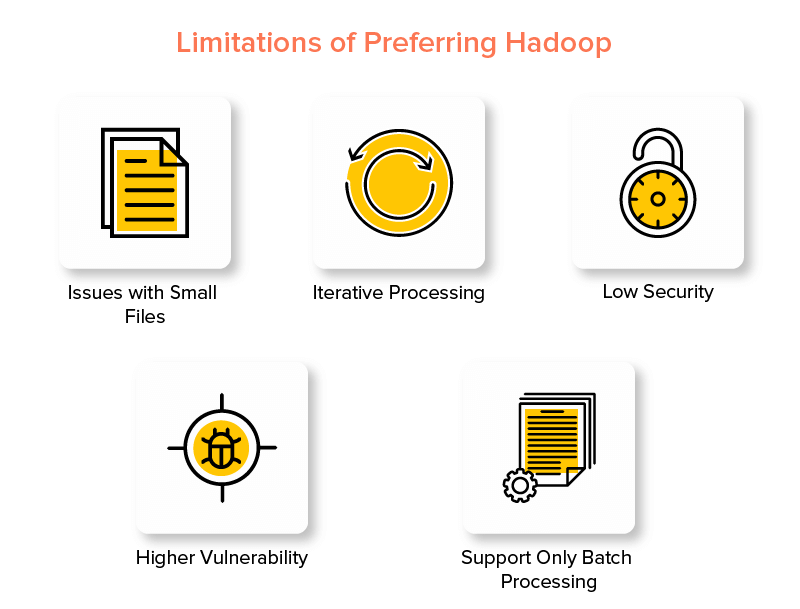
1. Problemas com arquivos pequenos
A maior desvantagem de considerar o Hadoop para análise de big data é que ele não tem o potencial de oferecer suporte à leitura aleatória de pequenos arquivos de forma eficiente e eficaz.
A razão por trás disso é que um arquivo pequeno tem um tamanho de memória comparativamente menor que o tamanho do bloco HDFS. Nesse cenário, se um grande número de arquivos pequenos é armazenado, há maiores chances de sobrecarga do NameNode que armazena o namespace do HDFS, o que praticamente não é uma boa ideia.
2. Processamento Iterativo
O fluxo de dados no framework Hadoop de big data está na forma de uma cadeia, de modo que a saída de um se torna a entrada de outro estágio. Considerando que, o fluxo de dados no processamento iterativo é de natureza cíclica.
Por causa disso, o Hadoop é uma escolha inadequada para soluções baseadas em aprendizado de máquina ou processamento iterativo.
3. Baixa Segurança
Outra desvantagem de usar o framework Hadoop é que oferece recursos de segurança mais baixos.
O framework, por exemplo, possui o modelo de segurança desabilitado por padrão. Se alguém que usa essa ferramenta de big data não souber como habilitá-la, seus dados podem estar em maior risco de serem roubados/utilizados indevidamente. Além disso, o Hadoop não fornece a funcionalidade de criptografia nos níveis de armazenamento e rede, o que novamente aumenta as chances de ameaça de violação de dados.
4. Maior vulnerabilidade
A estrutura do Hadoop é escrita em Java, a linguagem de programação mais popular e bastante explorada. Isso torna mais fácil para os cibercriminosos acessar facilmente as soluções baseadas em Hadoop e fazer uso indevido dos dados confidenciais.
5. Suporte apenas para processamento em lote
Ao contrário de várias outras estruturas de big data, o Hadoop não processa dados transmitidos. Ele suporta apenas processamento em lote , e a razão por trás disso é que o MapReduce não aproveita ao máximo a memória do cluster Hadoop.
Enquanto isso é tudo sobre o Hadoop, seus recursos e desvantagens, vamos dar uma olhada nos prós e contras do Spark para encontrar uma facilidade para entender a diferença entre os dois.
Benefícios do Apache Spark Framework
1. Dinâmico na Natureza
Como o Apache Spark oferece cerca de 80 operadores de alto nível, ele pode ser usado para processar dados dinamicamente. Pode ser considerada a ferramenta de big data certa para desenvolver e gerenciar aplicativos paralelos.
2. Poderoso
Devido à sua capacidade de processamento de dados na memória de baixa latência e à disponibilidade de várias bibliotecas integradas para algoritmos de aprendizado de máquina e análise de gráficos, ele pode lidar com vários desafios de análise. Isso o torna uma poderosa opção de big data no mercado para acompanhar.
3. Análise avançada
Outro recurso distintivo do Spark é que ele não apenas incentiva 'MAP' e 'reduce', mas também oferece suporte a Machine Learning (ML), consultas SQL, algoritmos de gráfico e dados de streaming. Isso o torna adequado para desfrutar de análises avançadas.
4. Reutilização
Ao contrário do Hadoop, o código Spark pode ser reutilizado para processamento em lote, executar consultas ad-hoc no estado do fluxo, ingressar no fluxo em relação a dados históricos e muito mais.
5. Processamento de fluxo em tempo real
Outra vantagem de usar o Apache Spark é que ele permite o manuseio e processamento de dados em tempo real.
6. Suporte multilíngue
Por último, mas não menos importante, essa ferramenta de análise de big data oferece suporte a vários idiomas para codificação, incluindo Java, Python e Scala.
Limitações da ferramenta Spark Big Data

1. Nenhum processo de gerenciamento de arquivos
A principal desvantagem de usar o Apache Spark é que ele não possui seu próprio sistema de gerenciamento de arquivos. Ele depende de outras plataformas como o Hadoop para atender a esse requisito.
2. Poucos Algoritmos
O Apache Spark também fica atrás de outras estruturas de big data ao considerar a disponibilidade de algoritmos como a distância de Tanimoto.
3. Problema de arquivos pequenos
Outra desvantagem de usar o Spark é que ele não lida com arquivos pequenos com eficiência.
Isso ocorre porque ele opera com o Hadoop Distributed File System (HDFS), que torna mais fácil gerenciar um número limitado de arquivos grandes em muitos arquivos pequenos.
4. Nenhum processo de otimização automático
Ao contrário de várias outras plataformas de big data e baseadas em nuvem, o Spark não possui nenhum processo automático de otimização de código. É preciso otimizar o código apenas manualmente.
5. Não é adequado para ambiente multiusuário
Como o Apache Spark não pode lidar com vários usuários ao mesmo tempo, ele não opera com eficiência em um ambiente multiusuário. Algo que novamente adiciona às suas limitações.
Com os conceitos básicos de ambas as estruturas de big data cobertos, é provável que você espere se familiarizar com as diferenças entre o Spark e o Hadoop.
Então, não vamos esperar mais e ir para a comparação deles para ver qual deles lidera a batalha 'Spark vs Hadoop'.
Spark vs Hadoop: como as duas ferramentas de Big Data se comparam
[ID da tabela=38 /]
1. Arquitetura
Quando se trata de arquitetura Spark e Hadoop, este último lidera mesmo quando ambos operam em ambiente de computação distribuída.
Isso ocorre porque a arquitetura do Hadoop – diferentemente do Spark – possui dois elementos principais – HDFS (Hadoop Distributed File System) e YARN (Yet Another Resource Negotiator). Aqui, o HDFS lida com o armazenamento de big data em vários nós, enquanto o YARN cuida das tarefas de processamento por meio de mecanismos de alocação de recursos e agendamento de tarefas. Esses componentes são então divididos em mais componentes para oferecer melhores soluções com serviços como tolerância a falhas.
2. Facilidade de uso
O Apache Spark permite que os desenvolvedores introduzam várias APIs amigáveis, como Scala, Python, R, Java e Spark SQL em seu ambiente de desenvolvimento. Além disso, ele vem carregado com um modo interativo que suporta usuários e desenvolvedores. Isso o torna fácil de usar e com baixa curva de aprendizado.
Considerando que, ao falar sobre o Hadoop, oferece complementos para dar suporte aos usuários, mas não um modo interativo. Isso faz com que o Spark vença o Hadoop nesta batalha de 'big data'.
3. Tolerância a Falhas e Segurança
Embora o Apache Spark e o Hadoop MapReduce ofereçam facilidade de tolerância a falhas, o último vence a batalha.
Isso porque é preciso começar do zero caso um processo falhe no meio da operação no ambiente Spark. Mas, quando se trata do Hadoop, eles podem continuar a partir do ponto do próprio acidente.
4. Desempenho
Quando se trata de considerar o desempenho do Spark vs MapReduce, o primeiro vence o segundo.
O framework Spark é capaz de rodar 10 vezes mais rápido no disco e 100 vezes na memória. Isso possibilita gerenciar 100 TB de dados 3 vezes mais rápido que o Hadoop MapReduce.
5. Processamento de Dados
Outro fator a ser considerado durante a comparação Apache Spark vs Hadoop é o processamento de dados.
Embora o Apache Hadoop ofereça uma oportunidade apenas de processamento em lote, a outra estrutura de big data permite trabalhar com processamento interativo, iterativo, de fluxo, gráfico e em lote. Algo que prova que o Spark é a melhor opção para desfrutar de melhores serviços de processamento de dados.
6. Compatibilidade
A compatibilidade do Spark e do Hadoop MapReduce é um pouco a mesma.
Embora, às vezes, ambas as estruturas de big data funcionem como aplicativos independentes, elas também podem funcionar juntas. O Spark pode ser executado com eficiência no Hadoop YARN, enquanto o Hadoop pode se integrar facilmente ao Sqoop e ao Flume. Por causa disso, ambos oferecem suporte a fontes de dados e formatos de arquivo um do outro.
7. Segurança
O ambiente Spark é carregado com diferentes recursos de segurança, como log de eventos e uso de filtros de servlet javax para proteger UIs da web. Além disso, incentiva a autenticação por meio de segredo compartilhado e pode aproveitar o potencial de permissões de arquivo HDFS, criptografia entre modos e Kerberos quando integrado com YARN e HDFS.
Por outro lado, o Hadoop suporta autenticação Kerberos , autenticação de terceiros, permissões de arquivos convencionais e listas de controle de acesso e muito mais, o que eventualmente oferece melhores resultados de segurança.
Portanto, ao considerar a comparação Spark vs Hadoop em termos de segurança, o último lidera.
8. Custo-benefício
Ao comparar o Hadoop e o Spark, o primeiro precisa de mais memória em disco, enquanto o último requer mais memória RAM. Além disso, como o Spark é bastante novo em comparação com o Apache Hadoop, os desenvolvedores que trabalham com o Spark são mais raros.
Isso torna o trabalho com o Spark um assunto caro. Ou seja, o Hadoop oferece soluções econômicas quando se concentra no custo do Hadoop vs Spark.
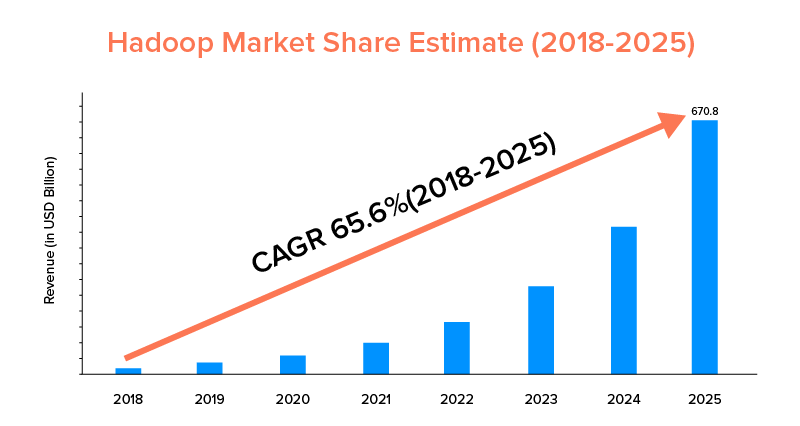
9. Escopo do mercado
Embora o Apache Spark e o Hadoop sejam apoiados por grandes empresas e tenham sido usados para diferentes propósitos, o último lidera em termos de escopo de mercado.
De acordo com as estatísticas do mercado, o mercado Apache Hadoop deverá crescer com um CAGR de 65,6% durante o período de 2018 a 2025, quando comparado ao Spark com um CAGR de apenas 33,9%.
Embora esses fatores ajudem a determinar a ferramenta de big data certa para sua empresa, é lucrativo conhecer seus casos de uso. Então, vamos cobrir aqui.
Casos de uso do Apache Spark Framework
Essa ferramenta de big data é adotada pelas empresas quando desejam:
- Transmita e analise dados em tempo real.
- Aprecie o poder do Machine Learning.
- Trabalhe com análises interativas.
- Introduzir Fog e Edge Computing em seu modelo de negócios.
Casos de uso do Apache Hadoop Framework
Hadoop é preferido por startups e empresas quando querem:-
- Analisar dados de arquivo.
- Desfrute de melhores opções financeiras de negociação e previsão.
- Executar operações compostas por hardware Commodity.
- Considere o processamento de dados linear.
Com isso, esperamos que você tenha decidido qual deles é o vencedor da batalha 'Spark vs Hadoop' em relação ao seu negócio. Caso contrário, sinta-se à vontade para entrar em contato com nossos especialistas em Big Data para tirar todas as dúvidas e obter serviços exemplares com maior índice de sucesso.
PERGUNTAS FREQUENTES
1. Qual estrutura de Big Data escolher?
A escolha depende completamente das necessidades do seu negócio. Se você está se concentrando em desempenho, compatibilidade de dados e facilidade de uso, o Spark é melhor que o Hadoop. Considerando que, a estrutura de big data do Hadoop é melhor quando você se concentra em arquitetura, segurança e economia.
2. Qual é a diferença entre Hadoop e Spark?
Existem várias diferenças entre o Spark e o Hadoop. Por exemplo:-
- O Spark é 100 vezes maior que o Hadoop MapReduce.
- Enquanto o Hadoop é empregado para processamento em lote, o Spark destina-se a lote, gráfico, aprendizado de máquina e processamento iterativo.
- O Spark é compacto e mais fácil que a estrutura de big data do Hadoop.
- Ao contrário do Spark, o Hadoop não oferece suporte ao armazenamento em cache de dados.
3. O Spark é melhor que o Hadoop?
O Spark é melhor que o Hadoop quando seu foco principal é velocidade e segurança. No entanto, em outros casos, essa ferramenta de análise de big data fica atrás do Apache Hadoop.
4. Por que o Spark é mais rápido que o Hadoop?
O Spark é mais rápido que o Hadoop devido ao menor número de ciclos de leitura/gravação no disco e ao armazenamento de dados intermediários na memória.
5. Para que serve o Apache Spark?
O Apache Spark é usado para análise de dados quando se quer
- Analise dados em tempo real.
- Introduza ML e Fog Computing em seu modelo de negócios.
- Trabalhe com análises interativas.