
TW-BERT: ponderação de ponta a ponta dos termos de consulta e o futuro da Pesquisa Google
Publicados: 2023-09-14A busca é difícil, como escreveu Seth Godin em 2005.
Quero dizer, se achamos que SEO é difícil (e é), imagine se você estivesse tentando construir um mecanismo de busca em um mundo onde:
- Os usuários variam dramaticamente e mudam suas preferências ao longo do tempo.
- A tecnologia que eles acessam pesquisa avança a cada dia.
- Os concorrentes estão sempre te perseguindo.
Além disso, você também está lidando com SEOs incômodos que tentam manipular seu algoritmo para obter insights sobre a melhor forma de otimizar para seus visitantes.
Isso vai tornar tudo muito mais difícil.
Agora imagine se as principais tecnologias nas quais você precisa se apoiar para avançar tivessem suas próprias limitações – e, talvez pior, custos enormes.
Bem, se você é um dos redatores do artigo publicado recentemente, “Ponderação de termo de consulta ponta a ponta”, você vê isso como uma oportunidade para brilhar.
O que é ponderação de termo de consulta de ponta a ponta?
A ponderação de termo de consulta de ponta a ponta refere-se a um método em que o peso de cada termo em uma consulta é determinado como parte do modelo geral, sem depender de esquemas de ponderação de termo tradicionais ou programados manualmente ou de outros modelos independentes.
Como é isso?
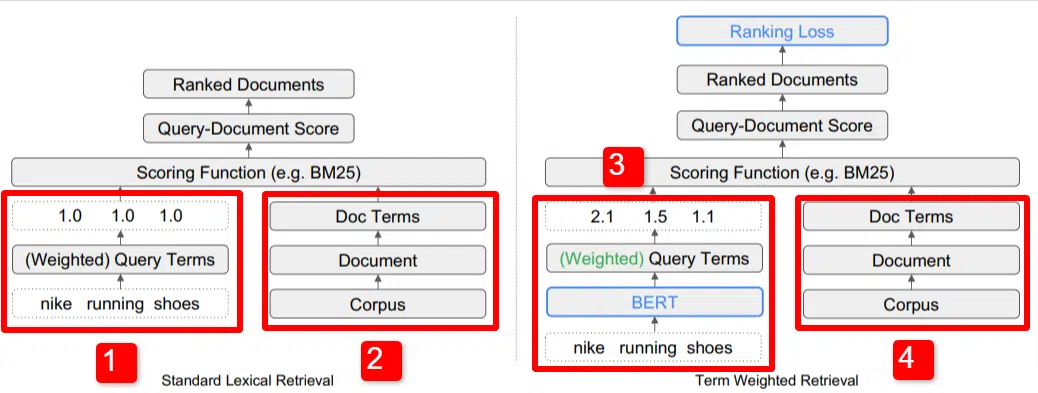
Aqui vemos uma ilustração de um dos principais diferenciais do modelo descrito no artigo (Figura 1, especificamente).
No lado direito do modelo padrão (2) vemos o mesmo que fazemos com o modelo proposto (4), que é o corpus (conjunto completo de documentos no índice), que leva aos documentos, que leva aos termos.
Isso ilustra a hierarquia real do sistema, mas você pode pensar nisso casualmente ao contrário, de cima para baixo. Temos termos. Procuramos documentos com esses termos. Esses documentos estão no corpus de todos os documentos que conhecemos.
No canto inferior esquerdo (1) na arquitetura padrão de recuperação de informações (IR), você notará que não há camada BERT. A consulta usada em sua ilustração (tênis de corrida Nike) entra no sistema, e os pesos são calculados independentemente do modelo e passados para ele.
Na ilustração aqui, os pesos passam igualmente entre as três palavras da consulta. Entretanto, isso não tem que ser assim. É simplesmente uma ilustração padrão e boa.
O que é importante entender é que os pesos são atribuídos de fora do modelo e inseridos com a consulta. Abordaremos por que isso é importante momentaneamente.
Se olharmos para a versão termo-peso no lado direito, você verá que a consulta “tênis de corrida nike” insere BERT (Term Weighting BERT, ou TW-BERT, para ser mais específico), que é usado para atribuir os pesos que seria melhor aplicado a essa consulta.
A partir daí as coisas seguem um caminho semelhante para ambos, uma função de pontuação é aplicada e os documentos são classificados. Mas há uma etapa final importante no novo modelo, que é realmente o objetivo de tudo: o cálculo da perda de classificação.
Esse cálculo, ao qual me referia acima, torna tão importantes os pesos determinados dentro do modelo. Para entender isso melhor, vamos discutir rapidamente as funções de perda, o que é importante para realmente entender o que está acontecendo aqui.
O que é uma função de perda?
No aprendizado de máquina, uma função de perda é basicamente um cálculo de quão errado um sistema está com esse sistema tentando aprender a chegar o mais próximo possível de uma perda zero.
Tomemos como exemplo um modelo concebido para determinar os preços das casas. Se você inseriu todas as estatísticas da sua casa e obteve um valor de $ 250.000, mas sua casa foi vendida por $ 260.000, a diferença seria considerada uma perda (que é um valor absoluto).
Em um grande número de exemplos, o modelo é ensinado a minimizar a perda atribuindo pesos diferentes aos parâmetros dados até obter o melhor resultado. Um parâmetro, neste caso, pode incluir coisas como metros quadrados, quartos, tamanho do quintal, proximidade de uma escola, etc.
Agora, de volta à ponderação do termo de consulta
Olhando novamente para os dois exemplos acima, precisamos nos concentrar na presença de um modelo BERT para fornecer a ponderação aos termos funil descendente do cálculo da perda de classificação.
Em outras palavras, nos modelos tradicionais, a ponderação dos termos era feita independentemente do modelo em si e, portanto, não podia responder ao desempenho do modelo geral. Não conseguiu aprender como melhorar nas ponderações.

No sistema proposto isso muda. A ponderação é feita dentro do próprio modelo e assim, à medida que o modelo busca melhorar seu desempenho e reduzir a função de perda, ele possui esses mostradores extras para trazer a ponderação de termos para a equação. Literalmente.
ngramas
O TW-BERT não foi projetado para operar em termos de palavras, mas sim de ngramas.
Os autores do artigo ilustram bem por que usam ngrams em vez de palavras quando apontam que na consulta “tênis de corrida nike”, se você simplesmente pesar as palavras, uma página com menções às palavras nike, corrida e tênis poderia ter uma boa classificação. se estiver discutindo “meias de corrida Nike” e “tênis de skate”.
Os métodos tradicionais de RI usam estatísticas de consulta e estatísticas de documentos e podem exibir páginas com este ou outros problemas semelhantes. Tentativas anteriores de resolver isso focaram na co-ocorrência e na ordenação.
Neste modelo, os ngrams são ponderados como as palavras no exemplo anterior, então terminamos com algo como:
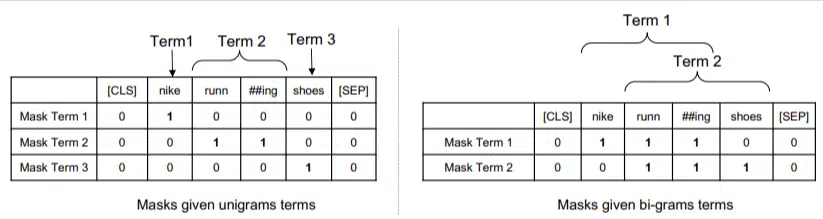
À esquerda vemos como a consulta seria ponderada como unigramas (ngrams de 1 palavra) e à direita, bigramas (ngrams de 2 palavras).
O sistema, porque a ponderação está incorporada nele, pode treinar todas as permutações para determinar os melhores ngramas e também o peso apropriado para cada uma, em vez de depender apenas de estatísticas como frequência.
Tiro zero
Uma característica importante deste modelo é o seu desempenho em tarefas zero-short. Os autores testaram em:
- Conjunto de dados MS MARCO – conjunto de dados da Microsoft para classificação de documentos e passagens
- Conjunto de dados TREC-COVID – artigos e estudos sobre COVID
- Robust04 – Artigos de notícias
- Núcleo Comum – Artigos educacionais e postagens de blog
Eles tinham apenas um pequeno número de consultas de avaliação e não usaram nenhuma para ajuste fino, tornando este um teste zero, já que o modelo não foi treinado para classificar documentos especificamente nesses domínios. Os resultados foram:
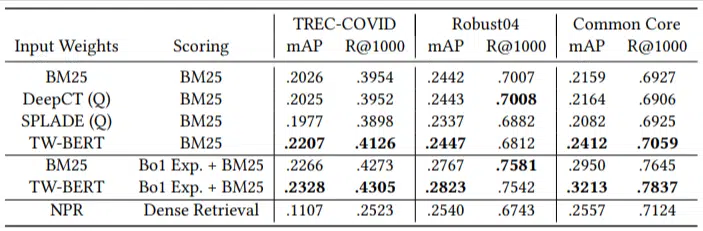
Ele teve desempenho superior na maioria das tarefas e melhor desempenho em consultas mais curtas (1 a 10 palavras).
E é plug-and-play!
OK, isso pode ser simplificador demais, mas os autores escrevem:
“O alinhamento do TW-BERT com os pontuadores do mecanismo de pesquisa minimiza as mudanças necessárias para integrá-lo aos aplicativos de produção existentes , enquanto os métodos de pesquisa baseados em aprendizagem profunda existentes exigiriam maior otimização de infraestrutura e requisitos de hardware. Os pesos aprendidos podem ser facilmente utilizados por recuperadores lexicais padrão e por outras técnicas de recuperação, como expansão de consulta.”
Como o TW-BERT foi projetado para ser integrado ao sistema atual, a integração é muito mais simples e barata do que outras opções.
O que tudo isso significa para você
Com modelos de aprendizado de máquina, é difícil prever, por exemplo, o que você, como SEO, pode fazer a respeito (além de implantações visíveis como Bard ou ChatGPT).
Uma permutação deste modelo será, sem dúvida, implementada devido às suas melhorias e facilidade de implementação (assumindo que as declarações são precisas).
Dito isto, esta é uma melhoria na qualidade de vida do Google, que irá melhorar as classificações e os resultados zero-shot com um custo baixo.
Tudo o que podemos realmente confiar é que, se implementados, melhores resultados surgirão de forma mais confiável. E isso é uma boa notícia para os profissionais de SEO.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.