
O que é IA generativa e como funciona?
Publicados: 2023-09-26A IA generativa, um subconjunto da inteligência artificial, emergiu como uma força revolucionária no mundo da tecnologia. Mas o que é exatamente? E por que está ganhando tanta atenção?
Este guia detalhado abordará como funcionam os modelos generativos de IA, o que eles podem ou não fazer e as implicações de todos esses elementos.
O que é IA generativa?
IA generativa, ou genAI, refere-se a sistemas que podem gerar novos conteúdos, sejam eles textos, imagens, músicas ou até vídeos. Tradicionalmente, IA/ML significava três coisas: aprendizagem supervisionada, não supervisionada e por reforço. Cada um fornece insights com base na saída do cluster.
Os modelos de IA não generativos fazem cálculos com base em informações (como classificar uma imagem ou traduzir uma frase). Em contraste, os modelos generativos produzem “novos” resultados, como escrever ensaios, compor música, desenhar gráficos e até criar rostos humanos realistas que não existem no mundo real.
As implicações da IA generativa
A ascensão da IA generativa tem implicações significativas. Com a capacidade de gerar conteúdo, setores como entretenimento, design e jornalismo estão testemunhando uma mudança de paradigma.
Por exemplo, as agências de notícias podem usar IA para redigir relatórios, enquanto os designers podem obter sugestões de gráficos assistidas por IA. A IA pode gerar centenas de slogans publicitários em segundos – sejam essas opções boas ou não ou não é outra questão.
A IA generativa pode produzir conteúdo personalizado para usuários individuais. Pense em algo como um aplicativo de música que compõe uma música única com base no seu humor ou um aplicativo de notícias que elabora artigos sobre tópicos de seu interesse.
A questão é que, à medida que a IA desempenha um papel mais integral na criação de conteúdos, as questões sobre autenticidade, direitos de autor e o valor da criatividade humana tornam-se mais prevalecentes.
Como funciona a IA generativa?
A IA generativa, em sua essência, trata de prever o próximo dado em uma sequência, seja a próxima palavra em uma frase ou o próximo pixel em uma imagem. Vamos detalhar como isso é conseguido.
Modelos estatísticos
Os modelos estatísticos são a espinha dorsal da maioria dos sistemas de IA. Eles usam equações matemáticas para representar a relação entre diferentes variáveis.
Para a IA generativa, os modelos são treinados para reconhecer padrões nos dados e depois usar esses padrões para gerar dados novos e semelhantes.
Se um modelo for treinado em sentenças em inglês, ele aprende a probabilidade estatística de uma palavra seguir a outra, permitindo gerar sentenças coerentes.
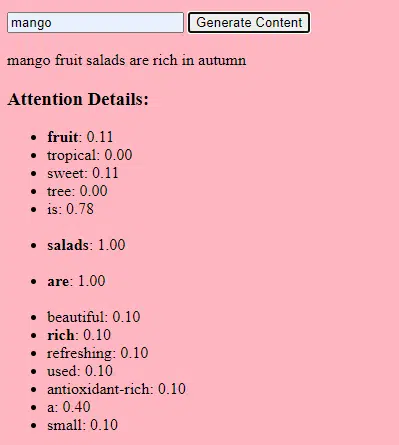
Coleta de dados
Tanto a qualidade como a quantidade de dados são cruciais. Os modelos generativos são treinados em vastos conjuntos de dados para compreender padrões.
Para um modelo de linguagem, isso pode significar a ingestão de bilhões de palavras de livros, sites e outros textos.
Para um modelo de imagem, isso pode significar a análise de milhões de imagens. Quanto mais diversificados e abrangentes forem os dados de treinamento, melhor o modelo gerará diversos resultados.
Como funcionam os transformadores e a atenção
Os transformadores são um tipo de arquitetura de rede neural introduzida em um artigo de 2017 intitulado “Atenção é tudo que você precisa”, de Vaswani et al. Desde então, eles se tornaram a base para a maioria dos modelos de linguagem de última geração. ChatGPT não funcionaria sem transformadores.
O mecanismo de “atenção” permite que o modelo se concentre em diferentes partes dos dados de entrada, da mesma forma que os humanos prestam atenção a palavras específicas ao compreender uma frase.
Este mecanismo permite que o modelo decida quais partes da entrada são relevantes para uma determinada tarefa, tornando-o altamente flexível e poderoso.
O código abaixo é uma análise fundamental dos mecanismos do transformador, explicando cada peça em inglês simples.
class Transformer: # Convert words to vectors # What this is : turns words into "vector embeddings" –basically numbers that represent the words and their relationships to each other. # Demo : "the pineapple is cool and tasty" -> [0.2, 0.5, 0.3, 0.8, 0.1, 0.9] self.embedding = Embedding(vocab_size, d_model) # Add position information to the vectors # What this is : Since words in a sentence have a specific order, we add information about each word's position in the sentence. # Demo : "the pineapple is cool and tasty" with position -> [0.2+0.01, 0.5+0.02, 0.3+0.03, 0.8+0.04, 0.1+0.05, 0.9+0.06] self.positional_encoding = PositionalEncoding(d_model) # Stack of transformer layers # What this is : Multiple layers of the Transformer model stacked on top of each other to process data in depth. # Why it does it : Each layer captures different patterns and relationships in the data. # Explained like I'm five : Imagine a multi-story building. Each floor (or layer) has people (or mechanisms) doing specific jobs. The more floors, the more jobs get done! self.transformer_layers = [TransformerLayer(d_model, nhead) for _ in range(num_layers)] # Convert the output vectors to word probabilities # What this is : A way to predict the next word in a sequence. # Why it does it : After processing the input, we want to guess what word comes next. # Explained like I'm five : After listening to a story, this tries to guess what happens next. self.output_layer = Linear(d_model, vocab_size) def forward(self, x): # Convert words to vectors, as above x = self.embedding(x) # Add position information, as above x = self.positional_encoding(x) # Pass through each transformer layer # What this is : Sending our data through each floor of our multi-story building. # Why it does it : To deeply process and understand the data. # Explained like I'm five : It's like passing a note in class. Each person (or layer) adds something to the note before passing it on, which can end up with a coherent story – or a mess. for layer in self.transformer_layers: x = layer(x) # Get the output word probabilities # What this is : Our best guess for the next word in the sequence. return self.output_layer(x)No código, você pode ter uma classe Transformer e uma única classe TransformerLayer. É como ter uma planta de um andar em vez de um edifício inteiro.
Este trecho de código do TransformerLayer mostra como funcionam componentes específicos, como atenção de vários cabeçotes e arranjos específicos.
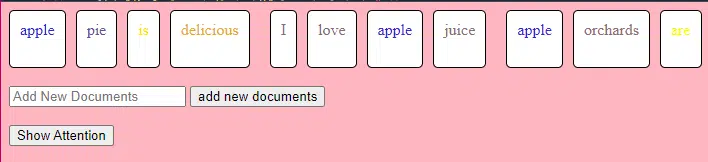
class TransformerLayer: # Multi-head attention mechanism # What this is : A mechanism that lets the model focus on different parts of the input data simultaneously. # Demo : "the pineapple is cool and tasty" might become "this PINEAPPLE is COOL and TASTY" as the model pays more attention to certain words. self.attention = MultiHeadAttention(d_model, nhead) # Simple feed-forward neural network # What this is : A basic neural network that processes the data after the attention mechanism. # Demo : "this PINEAPPLE is COOL and TASTY" -> [0.25, 0.55, 0.35, 0.85, 0.15, 0.95] (slight changes in numbers after processing) self.feed_forward = FeedForward(d_model) def forward(self, x): # Apply attention mechanism # What this is : The step where we focus on different parts of the sentence. # Explained like I'm five : It's like highlighting important parts of a book. attention_output = self.attention(x, x, x) # Pass the output through the feed-forward network # What this is : The step where we process the highlighted information. return self.feed_forward(attention_output)Uma rede neural feed-forward é um dos tipos mais simples de redes neurais artificiais. Consiste em uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída.
Os dados fluem em uma direção – da camada de entrada, passando pelas camadas ocultas e até a camada de saída. Não há loops ou ciclos na rede.
No contexto da arquitetura do transformador, a rede neural feed-forward é utilizada após o mecanismo de atenção em cada camada. É uma transformação linear simples de duas camadas com uma ativação ReLU entre elas.
# Scaled dot-product attention mechanism class ScaledDotProductAttention: def __init__(self, d_model): # Scaling factor helps in stabilizing the gradients # it reduces the variance of the dot product. # What this is: A scaling factor based on the size of our model's embeddings. # What it does : Helps to make sure the dot products don't get too big. # Why it does it : Big dot products can make a model unstable and harder to train. # How it does it : By dividing the dot products by the square root of the embedding size. # It's used when calculating attention scores. # Explained like I'm five : Imagine you shouted something really loud. This scaling factor is like turning the volume down so it's not too loud. self.scaling_factor = d_model ** 0.5 def forward(self, query, key, value): # What this is : The function that calculates how much attention each word should get. # What it does : Determines how relevant each word in a sentence is to every other word. # Why it does it : So we can focus more on important words when trying to understand a sentence. # How it does it : By taking the dot product (the numeric product: a way to measure similarity) of the query and key, then scaling it, and finally using that to weigh our values. # How it fits into the rest of the code : This function is called whenever we want to calculate attention in our model. # Explained like I'm five : Imagine you have a toy and you want to see which of your friends likes it the most. This function is like asking each friend how much they like the toy, and then deciding who gets to play with it based on their answers. # Calculate attention scores by taking the dot product of the query and key. scores = dot_product(query, key) / self.scaling_factor # Convert the raw scores to probabilities using the softmax function. attention_weights = softmax(scores) # Weight the values using the attention probabilities. return dot_product(attention_weights, value) # Feed-forward neural network # This is an extremely basic example of a neural network. class FeedForward: def __init__(self, d_model): # First linear layer increases the dimensionality of the data. self.layer1 = Linear(d_model, d_model * 4) # Second linear layer brings the dimensionality back to d_model. self.layer2 = Linear(d_model * 4, d_model) def forward(self, x): # Pass the input through the first layer, #Pass the input through the first layer: # Input : This refers to the data you feed into the neural network. I # First layer : Neural networks consist of layers, and each layer has neurons. When we say "pass the input through the first layer," we mean that the input data is being processed by the neurons in this layer. Each neuron takes the input, multiplies it by its weights (which are learned during training), and produces an output. # apply ReLU activation to introduce non-linearity, # and then pass through the second layer. #ReLU activation: ReLU stands for Rectified Linear Unit. # It's a type of activation function, which is a mathematical function applied to the output of each neuron. In simpler terms, if the input is positive, it returns the input value; if the input is negative or zero, it returns zero. # Neural networks can model complex relationships in data by introducing non-linearities. # Without non-linear activation functions, no matter how many layers you stack in a neural network, it would behave just like a single-layer perceptron because summing these layers would give you another linear model. # Non-linearities allow the network to capture complex patterns and make better predictions. return self.layer2(relu(self.layer1(x))) # Positional encoding adds information about the position of each word in the sequence. class PositionalEncoding: def __init__(self, d_model): # What this is : A setup to add information about where each word is in a sentence. # What it does : Prepares to add a unique "position" value to each word. # Why it does it : Words in a sentence have an order, and this helps the model remember that order. # How it does it : By creating a special pattern of numbers for each position in a sentence. # How it fits into the rest of the code : Before processing words, we add their position info. # Explained like I'm five : Imagine you're in a line with your friends. This gives everyone a number to remember their place in line. pass def forward(self, x): # What this is : The main function that adds position info to our words. # What it does : Combines the word's original value with its position value. # Why it does it : So the model knows the order of words in a sentence. # How it does it : By adding the position values we prepared earlier to the word values. # How it fits into the rest of the code : This function is called whenever we want to add position info to our words. # Explained like I'm five : It's like giving each of your toys a tag that says if it's the 1st, 2nd, 3rd toy, and so on. return x # Helper functions def dot_product(a, b): # Calculate the dot product of two matrices. # What this is : A mathematical operation to see how similar two lists of numbers are. # What it does : Multiplies matching items in the lists and then adds them up. # Why it does it : To measure similarity or relevance between two sets of data. # How it does it : By multiplying and summing up. # How it fits into the rest of the code : Used in attention to see how relevant words are to each other. # Explained like I'm five : Imagine you and your friend have bags of candies. You both pour them out and match each candy type. Then, you count how many matching pairs you have. return a @ b.transpose(-2, -1) def softmax(x): # Convert raw scores to probabilities ensuring they sum up to 1. # What this is : A way to turn any list of numbers into probabilities. # What it does : Makes the numbers between 0 and 1 and ensures they all add up to 1. # Why it does it : So we can understand the numbers as chances or probabilities. # How it does it : By using exponentiation and division. # How it fits into the rest of the code : Used to convert attention scores into probabilities. # Explained like I'm five : Lets go back to our toys. This makes sure that when you share them, everyone gets a fair share, and no toy is left behind. return exp(x) / sum(exp(x), axis=-1) def relu(x): # Activation function that introduces non-linearity. It sets negative values to 0. # What this is : A simple rule for numbers. # What it does : If a number is negative, it changes it to zero. Otherwise, it leaves it as it is. # Why it does it : To introduce some simplicity and non-linearity in our model's calculations. # How it does it : By checking each number and setting it to zero if it's negative. # How it fits into the rest of the code : Used in neural networks to make them more powerful and flexible. # Explained like I'm five : Imagine you have some stickers, some are shiny (positive numbers) and some are dull (negative numbers). This rule says to replace all dull stickers with blank ones. return max(0, x)Como funciona a IA generativa – em termos simples
Pense na IA generativa como o lançamento de um dado ponderado. Os dados de treinamento determinam os pesos (ou probabilidades).
Se o dado representar a próxima palavra em uma frase, uma palavra que frequentemente segue a palavra atual nos dados de treinamento terá um peso maior. Portanto, “céu” pode seguir “azul” com mais frequência do que “banana”. Quando a IA “joga os dados” para gerar conteúdo, é mais provável que escolha sequências estatisticamente mais prováveis com base no seu treinamento.
Então, como os LLMs podem gerar conteúdo que “parece” original?
Vamos pegar uma lista falsa – os “melhores presentes do Eid al-Fitr para profissionais de marketing de conteúdo” – e ver como um LLM pode gerar esta lista combinando dicas textuais de documentos sobre presentes, Eid e profissionais de marketing de conteúdo.
Antes do processamento, o texto é dividido em pedaços menores chamados “tokens”. Esses tokens podem ter apenas um caractere ou uma palavra.
Exemplo: “Eid al-Fitr é uma celebração” torna-se [“Eid”, “al-Fitr”, “é”, “uma”, “celebração”].
Isso permite que o modelo trabalhe com pedaços de texto gerenciáveis e compreenda a estrutura das frases.
Cada token é então convertido em um vetor (uma lista de números) usando embeddings. Esses vetores capturam o significado e o contexto de cada palavra.
A codificação posicional adiciona informações a cada vetor de palavras sobre sua posição na frase, garantindo que o modelo não perca essas informações de ordem.
Em seguida, usamos um mecanismo de atenção : isso permite que o modelo se concentre em diferentes partes do texto de entrada ao gerar uma saída. Se você se lembra do BERT, isso é o que mais entusiasmou os Googlers em relação ao BERT.
Se o nosso modelo viu textos sobre “ presentes ” e sabe que as pessoas dão presentes durante as celebrações , e também viu textos sobre o “ Eid al-Fitr ” ser uma celebração significativa, prestará “ atenção ” a estas ligações.
Da mesma forma, se tiver visto textos sobre “ profissionais de marketing de conteúdo ” que precisam de ferramentas ou recursos específicos, pode conectar a ideia de “ presentes ” a “ profissionais de marketing de conteúdo”.

Agora podemos combinar contextos: à medida que o modelo processa o texto de entrada através de múltiplas camadas do Transformer, ele combina os contextos que aprendeu.
Assim, mesmo que os textos originais nunca tenham mencionado “presentes de Eid al-Fitr para profissionais de marketing de conteúdo”, o modelo pode reunir os conceitos de “Eid al-Fitr”, “presentes” e “profissionais de marketing de conteúdo” para gerar esse conteúdo.
Isso ocorre porque aprendeu os contextos mais amplos em torno de cada um desses termos.
Depois de processar a entrada através do mecanismo de atenção e das redes feed-forward em cada camada do Transformer, o modelo produz uma distribuição de probabilidade sobre seu vocabulário para a próxima palavra na sequência.
Pode-se pensar que depois de palavras como “melhor” e “Eid al-Fitr”, a palavra “presentes” tem uma grande probabilidade de vir a seguir. Da mesma forma, pode associar “presentes” a destinatários potenciais, como “profissionais de marketing de conteúdo”.
Obtenha o boletim informativo diário em que os profissionais de marketing de pesquisa confiam.
Consulte os termos.
Como grandes modelos de linguagem são construídos
A jornada de um modelo básico de transformador para um sofisticado modelo de linguagem grande (LLM), como GPT-3 ou BERT, envolve ampliar e refinar vários componentes.
Aqui está uma análise passo a passo:
LLMs são treinados em grandes quantidades de dados de texto. É difícil explicar quão vastos são esses dados.
O conjunto de dados C4, ponto de partida para muitos LLMs, tem 750 GB de dados de texto. São 805.306.368.000 bytes – muita informação. Esses dados podem incluir livros, artigos, sites, fóruns, seções de comentários e outras fontes.
Quanto mais variados e abrangentes forem os dados, melhores serão as capacidades de compreensão e generalização do modelo.
Embora a arquitetura básica do transformador continue sendo a base, os LLMs têm um número significativamente maior de parâmetros. O GPT-3, por exemplo, possui 175 bilhões de parâmetros. Neste caso, os parâmetros referem-se aos pesos e vieses da rede neural que são aprendidos durante o processo de treinamento.

No aprendizado profundo, um modelo é treinado para fazer previsões ajustando esses parâmetros para reduzir a diferença entre suas previsões e os resultados reais.
O processo de ajuste desses parâmetros é chamado de otimização, que utiliza algoritmos como gradiente descendente.
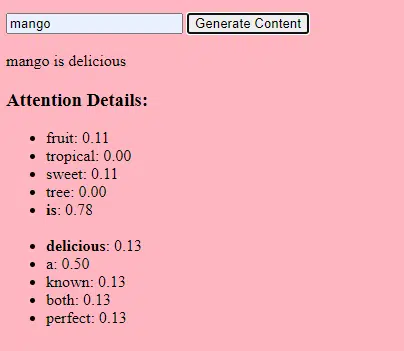
- Pesos: são valores da rede neural que transformam os dados de entrada nas camadas da rede. Eles são ajustados durante o treinamento para otimizar a saída do modelo. Cada conexão entre neurônios em camadas adjacentes possui um peso associado.
- Vieses: Esses também são valores na rede neural que são adicionados à saída da transformação de uma camada. Eles fornecem um grau adicional de liberdade ao modelo, permitindo que ele se ajuste melhor aos dados de treinamento. Cada neurônio em uma camada possui um viés associado.
Esse dimensionamento permite que o modelo armazene e processe padrões e relacionamentos mais complexos nos dados.
O grande número de parâmetros também significa que o modelo requer poder computacional e memória significativos para treinamento e inferência. É por isso que o treinamento de tais modelos consome muitos recursos e normalmente usa hardware especializado, como GPUs ou TPUs.
O modelo é treinado para prever a próxima palavra em uma sequência usando recursos computacionais poderosos. Ajusta seus parâmetros internos com base nos erros que comete, melhorando continuamente suas previsões.
Mecanismos de atenção como os que discutimos são fundamentais para os LLMs. Eles permitem que o modelo se concentre em diferentes partes da entrada ao gerar a saída.
Ao pesar a importância de diferentes palavras num contexto, os mecanismos de atenção permitem ao modelo gerar texto coerente e contextualmente relevante. Fazer isso em grande escala permite que os LLMs funcionem da maneira que funcionam.
Como um transformador prevê texto?
Os transformadores prevêem texto processando tokens de entrada através de múltiplas camadas, cada uma equipada com mecanismos de atenção e redes feed-forward.
Após o processamento, o modelo produz uma distribuição de probabilidade sobre seu vocabulário para a próxima palavra na sequência. A palavra com a maior probabilidade é normalmente selecionada como previsão.
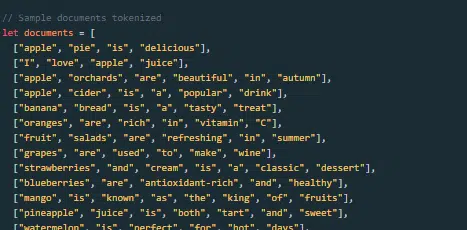
Como um grande modelo de linguagem é construído e treinado?
Construir um LLM envolve coletar dados, limpá-los, treinar o modelo, ajustar o modelo e testes vigorosos e contínuos.
O modelo é inicialmente treinado em um vasto corpus para prever a próxima palavra em uma sequência. Esta fase permite que o modelo aprenda conexões entre palavras que captam padrões gramaticais, relações que podem representar fatos sobre o mundo e conexões que parecem raciocínio lógico. Essas conexões também fazem com que sejam detectados vieses presentes nos dados de treinamento.
Após o pré-treinamento, o modelo é refinado em um conjunto de dados mais restrito, geralmente com revisores humanos seguindo as diretrizes.
O ajuste fino é uma etapa crucial na construção de LLMs. Envolve treinar o modelo pré-treinado em um conjunto de dados ou tarefa mais específico. Tomemos o ChatGPT como exemplo.
Se você já brincou com modelos GPT, sabe que a solicitação é menos “escreva isso” e mais
- Dica: Era uma vez
- Continuação: Havia um bruxo malvado no topo de uma torre.
- Continuação: Havia um bruxo malvado no topo de uma torre.
- Dica : Por que a galinha entrou para uma banda?
- Continuação : Porque tinha as baquetas!
Chegar ao ChatGPT a partir desse ponto envolve muito trabalho mal remunerado. Essas pessoas criam imensos corpora para identificar o peso das respostas da GPT e dos comportamentos esperados. Esses trabalhadores criam toneladas de textos de prompt/continuação que são como:
- Dica : Termine esta história: “Era uma vez..”
- Continuação : Claro! Era uma vez, numa terra muito, muito distante, uma pequena aldeia aninhada entre duas majestosas montanhas.
- Continuação : Claro! Era uma vez, numa terra muito, muito distante, uma pequena aldeia aninhada entre duas majestosas montanhas.
- Dica : Conte-me uma piada sobre uma galinha.
- Continuação : Por que a galinha entrou para uma banda? Porque tinha as baquetas!
Este processo de ajuste fino é essencial por vários motivos:
- Especificidade: Embora o pré-treinamento proporcione ao modelo uma compreensão ampla da linguagem, o ajuste fino restringe seu conhecimento e comportamento para se alinhar mais com tarefas ou domínios específicos. Por exemplo, um modelo ajustado com base em dados médicos responderá melhor às perguntas médicas.
- Controle: o ajuste fino dá aos desenvolvedores mais controle sobre os resultados do modelo. Os desenvolvedores podem usar um conjunto de dados selecionado para orientar o modelo a produzir as respostas desejadas e evitar comportamentos indesejados.
- Segurança: Ajuda a reduzir resultados prejudiciais ou tendenciosos. Ao usar diretrizes durante o processo de ajuste fino, os revisores humanos podem garantir que o modelo não produza conteúdo impróprio.
- Desempenho: o ajuste fino pode melhorar significativamente o desempenho do modelo em tarefas específicas. Por exemplo, um modelo que foi ajustado para suporte ao cliente será muito melhor nisso do que um modelo genérico.
Você pode dizer que o ChatGPT foi aprimorado em alguns aspectos.
Por exemplo, “raciocínio lógico” é algo com que os LLMs tendem a ter dificuldades. O melhor modelo de raciocínio lógico do ChatGPT – GPT-4 – foi intensamente treinado para reconhecer explicitamente padrões em números.
Em vez de algo assim:
- Dica : Quanto é 2+2?
- Processo : Muitas vezes em livros didáticos de matemática para crianças 2+2 =4. Ocasionalmente, há referências a "2+2=5", mas geralmente há mais contexto relacionado a George Orwell ou Star Trek, quando for o caso. Se isto fosse nesse contexto o peso seria mais a favor de 2+2=5. Mas esse contexto não existe, então neste caso o próximo token é provavelmente o 4.
- Resposta : 2+2=4
O treinamento faz algo assim:
- treinamento: 2+2=4
- treinamento: 4/2=2
- treinamento: metade de 4 é 2
- treinamento: 2 de 2 é quatro
…e assim por diante.
Isso significa que para os modelos mais “lógicos”, o processo de treinamento é mais rigoroso e focado em garantir que o modelo compreenda e aplique corretamente os princípios lógicos e matemáticos.
O modelo é exposto a vários problemas matemáticos e suas soluções, garantindo que possa generalizar e aplicar esses princípios a problemas novos e inéditos.
A importância deste processo de ajuste fino, especialmente para o raciocínio lógico, não pode ser exagerada. Sem ele, o modelo pode fornecer respostas incorretas ou sem sentido a questões lógicas ou matemáticas simples.
Modelos de imagem vs. modelos de linguagem
Embora os modelos de imagem e de linguagem possam usar arquiteturas semelhantes, como transformadores, os dados que eles processam são fundamentalmente diferentes:
Modelos de imagem
Esses modelos lidam com pixels e geralmente funcionam de maneira hierárquica, analisando primeiro pequenos padrões (como bordas), depois combinando-os para reconhecer estruturas maiores (como formas) e assim por diante até compreenderem a imagem inteira.
Modelos de linguagem
Esses modelos processam sequências de palavras ou caracteres. Eles precisam compreender o contexto, a gramática e a semântica para gerar um texto coerente e contextualmente relevante.
Como funcionam as interfaces generativas de IA proeminentes
Dall-E + meio da jornada
Dall-E é uma variante do modelo GPT-3 adaptado para geração de imagens. Ele é treinado em um vasto conjunto de dados de pares texto-imagem. Midjourney é outro software de geração de imagens baseado em um modelo proprietário.
- Entrada: você fornece uma descrição textual, como "um flamingo de duas cabeças".
- Processamento: Esses modelos codificam esse texto em uma série de números e depois decodificam esses vetores, encontrando relações com pixels, para produzir uma imagem. O modelo aprendeu as relações entre descrições textuais e representações visuais a partir de seus dados de treinamento.
- Saída: uma imagem que corresponde ou se relaciona com a descrição fornecida.
Dedos, padrões, problemas
Por que essas ferramentas não conseguem gerar mãos que pareçam normais de forma consistente? Essas ferramentas funcionam observando pixels próximos uns dos outros.
Você pode ver como isso funciona ao comparar imagens geradas anteriormente ou mais primitivas com imagens mais recentes: os modelos anteriores parecem muito confusos. Em contraste, os modelos mais recentes são muito mais nítidos.
Esses modelos geram imagens prevendo o próximo pixel com base nos pixels já gerados. Este processo é repetido milhões de vezes para produzir uma imagem completa.
As mãos, especialmente os dedos, são complexas e possuem muitos detalhes que precisam ser capturados com precisão.
O posicionamento, comprimento e orientação de cada dedo podem variar muito em imagens diferentes.
Ao gerar uma imagem a partir de uma descrição textual, o modelo tem que fazer muitas suposições sobre a pose e estrutura exatas da mão, o que pode levar a anomalias.
Bate-papoGPT
ChatGPT é baseado na arquitetura GPT-3.5, um modelo baseado em transformador projetado para tarefas de processamento de linguagem natural.
- Entrada: um prompt ou uma série de mensagens para simular uma conversa.
- Processamento: ChatGPT utiliza seu vasto conhecimento de diversos textos da Internet para gerar respostas. Considera o contexto fornecido na conversa e tenta produzir a resposta mais relevante e coerente.
- Saída: uma resposta de texto que continua ou responde à conversa.
Especialidade
A força do ChatGPT reside na sua capacidade de lidar com vários tópicos e simular conversas humanas, tornando-o ideal para chatbots e assistentes virtuais.
Bard + Experiência Gerativa de Pesquisa (SGE)
Embora detalhes específicos possam ser proprietários, Bard é baseado em técnicas de IA de transformadores, semelhantes a outros modelos de linguagem de última geração. SGE é baseado em modelos semelhantes, mas combina outros algoritmos de ML que o Google usa.
A SGE provavelmente gera conteúdo usando um modelo generativo baseado em transformador e, em seguida, extrai respostas difusas das páginas de classificação na pesquisa. (Isso pode não ser verdade. Apenas um palpite baseado em como parece funcionar ao brincar com ele. Por favor, não me processe!)
- Entrada: Um prompt/comando/pesquisa
- Processamento: Bard processa a entrada e funciona da mesma forma que outros LLMs. O SGE usa uma arquitetura semelhante, mas adiciona uma camada onde busca seu conhecimento interno (adquirido a partir de dados de treinamento) para gerar uma resposta adequada. Ele considera a estrutura, o contexto e a intenção do prompt para produzir conteúdo relevante.
- Saída: Conteúdo gerado que pode ser uma história, resposta ou qualquer outro tipo de texto.
Aplicações de IA generativa (e suas controvérsias)
Arte e Design
A IA generativa agora pode criar obras de arte, músicas e até designs de produtos. Isso abriu novos caminhos para a criatividade e a inovação.
Controvérsia
A ascensão da IA na arte gerou debates sobre a perda de empregos em áreas criativas.
Além disso, existem preocupações sobre:
- Violações trabalhistas, especialmente quando conteúdo gerado por IA é usado sem a devida atribuição ou compensação.
- Executivos que ameaçam os escritores com sua substituição por IA é uma das questões que estimularam a greve dos escritores.
Processamento de linguagem natural (PNL)
Os modelos de IA são agora amplamente utilizados para chatbots, tradução de idiomas e outras tarefas de PNL.
Fora do sonho da inteligência artificial geral (AGI), este é o melhor uso para LLMs, uma vez que estão próximos de um modelo de PNL “generalista”.
Controvérsia
Muitos usuários consideram os chatbots impessoais e às vezes irritantes.
Além disso, embora a IA tenha feito progressos significativos na tradução de línguas, muitas vezes carece das nuances e da compreensão cultural que os tradutores humanos trazem, levando a traduções impressionantes e imperfeitas.
Medicina e descoberta de medicamentos
A IA pode analisar rapidamente grandes quantidades de dados médicos e gerar potenciais compostos medicamentosos, acelerando o processo de descoberta de medicamentos. Muitos médicos já usam LLMs para escrever notas e comunicações aos pacientes
Controvérsia
Depender de LLMs para fins médicos pode ser problemático. A medicina exige precisão e quaisquer erros ou omissões da IA podem ter consequências graves.
A medicina também já tem preconceitos que só ficam mais fortes com o uso de LLMs. Existem também questões semelhantes, conforme discutido abaixo, com privacidade, eficácia e ética.
Jogos
Muitos entusiastas da IA estão entusiasmados com o uso da IA em jogos: eles dizem que a IA pode gerar ambientes de jogo, personagens e até mesmo enredos de jogo realistas, melhorando a experiência de jogo. O diálogo com os NPCs pode ser aprimorado com o uso dessas ferramentas.
Controvérsia
Há um debate sobre a intencionalidade no design de jogos.
Embora a IA possa gerar grandes quantidades de conteúdo, alguns argumentam que lhe falta o design deliberado e a coesão narrativa que os designers humanos trazem.
Watchdogs 2 tinha NPCs programáticos, o que pouco contribuiu para a coesão narrativa do jogo como um todo.
Marketing e publicidade
A IA pode analisar o comportamento do consumidor e gerar anúncios personalizados e conteúdo promocional, tornando as campanhas de marketing mais eficazes.
Os LLMs têm contexto a partir da escrita de outras pessoas, o que os torna úteis para gerar histórias de usuários ou ideias programáticas mais diferenciadas. Em vez de recomendar TVs para alguém que acabou de comprar uma TV, os LLMs podem recomendar acessórios que alguém possa querer.
Controvérsia
The use of AI in marketing raises privacy concerns. There's also a debate about the ethical implications of using AI to influence consumer behavior.
Dig deeper: How to scale the use of large language models in marketing
Continuing issues with LLMS
Contextual understanding and comprehension of human speech
- Limitation: AI models, including GPT, often struggle with nuanced human interactions, such as detecting sarcasm, humor, or lies.
- Example: In stories where a character is lying to other characters, the AI might not always grasp the underlying deceit and might interpret statements at face value.
Pattern matching
- Limitation: AI models, especially those like GPT, are fundamentally pattern matchers. They excel at recognizing and generating content based on patterns they've seen in their training data. However, their performance can degrade when faced with novel situations or deviations from established patterns.
- Example: If a new slang term or cultural reference emerges after the model's last training update, it might not recognize or understand it.
Lack of common sense understanding
- Limitation: While AI models can store vast amounts of information, they often lack a "common sense" understanding of the world, leading to outputs that might be technically correct but contextually nonsensical.
Potential to reinforce biases
- Ethical consideration: AI models learn from data, and if that data contains biases, the model will likely reproduce and even amplify those biases. This can lead to outputs that are sexist, racist, or otherwise prejudiced.
Challenges in generating unique ideas
- Limitation: AI models generate content based on patterns they've seen. While they can combine these patterns in novel ways, they don't "invent" like humans do. Their "creativity" is a recombination of existing ideas.
Data Privacy, Intellectual Property, and Quality Control Issues:
- Ethical consideration : Using AI models in applications that handle sensitive data raises concerns about data privacy. When AI generates content, questions arise about who owns the intellectual property rights. Ensuring the quality and accuracy of AI-generated content is also a significant challenge.
Bad code
- AI models might generate syntactically correct code when used for coding tasks but functionally flawed or insecure. I have had to correct the code people have added to sites they generated using LLMs. It looked right, but was not. Even when it does work, LLMs have out-of-date expectations for code, using functions like “document.write” that are no longer considered best practice.
Hot takes from an MLOps engineer and technical SEO
This section covers some hot takes I have about LLMs and generative AI. Feel free to fight with me.
Prompt engineering isn't real (for generative text interfaces)
Generative models, especially large language models (LLMs) like GPT-3 and its successors, have been touted for their ability to generate coherent and contextually relevant text based on prompts.
Because of this, and since these models have become the new “gold rush," people have started to monetize “prompt engineering” as a skill. This can be either $1,400 courses or prompt engineering jobs.
However, there are some critical considerations:
LLMs change rapidly
As technology evolves and new model versions are released, how they respond to prompts can change. What worked for GPT-3 might not work the same way for GPT-4 or even a newer version of GPT-3.
This constant evolution means prompt engineering can become a moving target, making it challenging to maintain consistency. Prompts that work in January may not work in March.
Uncontrollable outcomes
While you can guide LLMs with prompts, there's no guarantee they'll always produce the desired output. For instance, asking an LLM to generate a 500-word essay might result in outputs of varying lengths because LLMs don't know what numbers are.
Similarly, while you can ask for factual information, the model might produce inaccuracies because it cannot tell the difference between accurate and inaccurate information by itself.
Using LLMs in non-language-based applications is a bad idea
LLMs are primarily designed for language tasks. While they can be adapted for other purposes, there are inherent limitations:
Struggle with novel ideas
LLMs are trained on existing data, which means they're essentially regurgitating and recombining what they've seen before. They don't "invent" in the truest sense of the word.
Tasks that require genuine innovation or out-of-the-box thinking should not use LLMs.
You can see an issue with this when it comes to people using GPT models for news content – if something novel comes along, it's hard for LLMs to deal with it.

For example, a site that seems to be generating content with LLMs published a possibly libelous article about Megan Crosby. Crosby was caught elbowing opponents in real life.
Without that context, the LLM created a completely different, evidence-free story about a “controversial comment.”
Text-focused
At their core, LLMs are designed for text. While they can be adapted for tasks like image generation or music composition, they might not be as proficient as models specifically designed for those tasks.
LLMs don't know what the truth is
They generate outputs based on patterns encountered in their training data. This means they can't verify facts or discern true and false information.
If they've been exposed to misinformation or biased data during training, or they don't have context for something, they might propagate those inaccuracies in their outputs.
This is especially problematic in applications like news generation or academic research, where accuracy and truth are paramount.
Think about it like this: if an LLM has never come across the name “Jimmy Scrambles” before but knows it's a name, prompts to write about it will only come up with related vectors.
Designers are always better than AI-generated Art
AI has made significant strides in art, from generating paintings to composing music. However, there's a fundamental difference between human-made art and AI-generated art:
Intent, feeling, vibe
Art is not just about the final product but the intent and emotion behind it.
A human artist brings their experiences, emotions, and perspectives to their work, giving it depth and nuance that's challenging for AI to replicate.
A “bad” piece of art from a person has more depth than a beautiful piece of art from a prompt.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.