
Wikipedia Web Scraping 2023: extração de dados para análise
Publicados: 2023-03-29A raspagem online permite coletar dados abertos de sites para fins como comparação de preços, pesquisa de mercado, verificação de anúncios, etc.
Grandes quantidades de dados públicos necessários são normalmente extraídas, mas quando você enfrenta bloqueios, a extração pode se tornar um desafio.
A restrição pode ser bloqueio de taxa ou bloqueio de IP (o endereço IP da solicitação é restrito porque se origina de uma área proibida, tipo de IP proibido etc.). (o endereço IP está bloqueado porque fez várias solicitações).

Agora, se você está disposto a coletar alguns conhecimentos e informações úteis, tenho certeza de que deve ter pensado em coletar a Wikipedia, a enciclopédia de conhecimento que abriga toneladas de informações.
Vamos entender algumas coisas sobre a web scraping Wikipedia.
Índice
Raspagem da Web da Wikipédia
A raspagem da Web é um método automatizado de coleta de dados da Internet. Informações detalhadas sobre a raspagem da web, uma comparação com o rastreamento da web e argumentos a favor da raspagem da web são fornecidos neste artigo.
O objetivo é coletar dados da página inicial da Wikipedia usando vários métodos de extração da web e, em seguida, analisá-los.
Você se familiarizará mais com vários métodos de raspagem da web, bibliotecas de raspagem da web em Python e procedimentos de extração e processamento de dados.
Web Scraping e Python
A raspagem da Web é essencialmente o processo de extração de dados estruturados de uma grande quantidade de dados de um grande número de sites usando um software criado em uma linguagem de programação e salvando-os localmente em nossos dispositivos, preferencialmente em planilhas do Excel, JSON ou planilhas.
Isso ajuda os programadores na criação de código lógico e compreensível para projetos pequenos e grandes.
Python é considerado principalmente como a melhor linguagem para web scraping. Ele pode efetivamente lidar com a maioria das tarefas relacionadas ao rastreamento da Web e é mais versátil.
Como extrair dados da Wikipedia?
Os dados podem ser extraídos de páginas da Web de várias maneiras.
Por exemplo, você mesmo pode implementá-lo usando linguagens de computador como Python. Mas, a menos que você seja conhecedor de tecnologia, precisará estudar muito antes de poder fazer muito com esse processo.
Também é demorado e pode demorar tanto quanto vasculhar manualmente as páginas da Wikipedia. Além disso, raspadores de web gratuitos estão acessíveis online. No entanto, eles frequentemente carecem de confiabilidade e seus fornecedores podem ter intenções duvidosas.
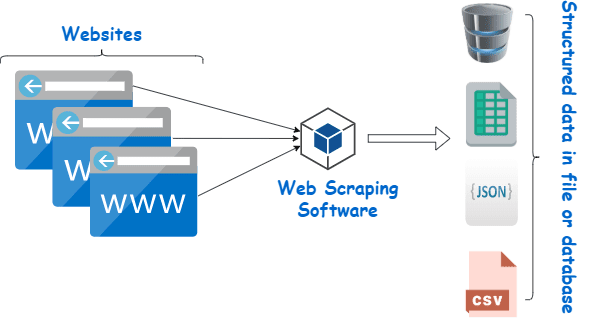
Investir em um web scraper decente de um fornecedor respeitável é o melhor método para coletar dados Wiki.
A próxima etapa geralmente é simples e descomplicada porque o provedor fornecerá instruções sobre como instalar e usar o raspador.
Um proxy é uma ferramenta que você pode usar em conjunto com seu raspador de wiki para coletar dados com mais eficiência. Estruturas baseadas em Python como Scrapy, Scraping Robot e Beautiful Soup são apenas alguns exemplos de como é fácil fazer scraping usando essa linguagem.
Proxy para extrair dados da Wikipedia
Você precisa de proxies que sejam extremamente rápidos, seguros de usar e garantidos para não cair em você quando você precisar deles para coletar dados de forma eficaz. Esses proxies estão disponíveis na Rayobyte a preços razoáveis.
Fazemos um esforço para oferecer uma variedade de proxies porque sabemos que cada usuário tem preferências e casos de uso diferentes.
Rotação de proxies para web scraping Wikipedia
Uma instância de um proxy é aquela que alterna seu endereço IP regularmente. Além disso, para evitar interrupções, o endereço IP é alterado imediatamente quando ocorre um banimento. Isso torna esse proxy específico uma ótima opção para raspagem de sites.
Os proxies estáticos, em comparação, têm apenas um endereço IP. Se o seu ISP não habilitar substituições automatizadas, você se deparará com uma parede de tijolos se tiver acesso apenas a um endereço IP e ele for bloqueado. Por causa disso, proxies estáticos não são a melhor opção para web scraping.
Proxies residenciais para web scraping de dados Wiki
Os proxies residenciais são endereços IP de proxy que os provedores de serviços de Internet (ISPs) distribuem e estão associados a residências específicas. Como eles vêm de pessoas reais, obtê-los é bastante desafiador. Como resultado, eles são escassos e relativamente caros.


Quando você usa proxies residenciais para coletar dados, parece ser um usuário comum porque eles estão vinculados aos endereços de indivíduos reais.
Portanto, usar proxies residenciais reduz significativamente a chance de ser descoberto e bloqueado. Eles são, portanto, excelentes candidatos para raspagem de dados.
Rotação de proxies residenciais para coleta de dados wiki
Um proxy residencial rotativo, que combina os dois tipos de que acabamos de falar, é o melhor proxy para web scraping Wikipedia.
Você pode acessar um grande número de IPs domésticos usando um proxy que os alterna com frequência.
Isso é crítico porque, apesar da dificuldade em identificar proxies residenciais, o volume de solicitações que eles geram acabará por chamar a atenção do site que está sendo raspado.
A rotação garante que o projeto possa continuar mesmo que o endereço IP inevitavelmente entre na lista negra.
Nós, portanto, temos o que você precisa, quer decida usar vários proxies de datacenter ou prefira investir em alguns proxies residenciais.
Você desfrutará da melhor experiência de raspagem na web com proxies rodando na velocidade de 1 GBS, largura de banda ilimitada e assistência ao cliente 24 horas por dia.
Você também pode ler
- Melhores Técnicas de Web Scraping: Um Guia Prático
- Revisão do Octoparse É realmente uma boa ferramenta de raspagem da Web?
- Melhores ferramentas de raspagem da Web
- O que é Web Scraping? - Como é usado? Como isso pode beneficiar o seu negócio
Por que você deve raspar a Wikipedia?
A Wikipedia é um dos serviços mais confiáveis e ricos em informações no mundo online no momento. Existem respostas e informações para quase todos os tipos de tópicos que você pode imaginar nesta plataforma.
Então, naturalmente, a Wikipedia é uma ótima fonte para coletar dados. Vamos discutir as principais razões pelas quais você deve raspar a Wikipedia.
Web scraping para pesquisa acadêmica
A coleta de dados é uma das atividades mais dolorosas envolvidas na pesquisa. Como já foi discutido, os web scrapers tornam esse procedimento mais rápido e fácil, além de economizar muito tempo e energia.
Com um raspador da web, você pode digitalizar rapidamente várias páginas wiki e coletar todos os dados necessários de maneira organizada.
Suponha por um momento que seu objetivo seja determinar se a depressão e a exposição à luz solar variam de acordo com o país.
Você pode usar um raspador Wiki para localizar informações como a prevalência de depressão em diferentes nações e suas horas ensolaradas, em vez de passar por várias entradas da Wikipédia.
gerenciamento de reputação
Fazer uma página da Wikipedia tornou-se uma estratégia de marketing obrigatória para muitos tipos diferentes de empresas na era moderna, porque as postagens da Wikipedia aparecem com frequência na primeira página do Google.
Mas ter uma página na Wikipedia não deve ser o fim de seus esforços de marketing. A Wikipedia é uma plataforma de crowdsourcing, então o vandalismo é algo que acontece com bastante frequência.
Como resultado, alguém pode adicionar informações desfavoráveis à página da sua empresa e prejudicar sua reputação. Como alternativa, eles podem difamar sua empresa em um artigo wiki relevante.
Por isso, você deve ficar de olho na sua página Wiki, bem como em outras páginas que mencionem o seu negócio depois de criadas. Você pode fazer isso com a ajuda de um raspador wiki com facilidade.
Você pode pesquisar periodicamente as páginas da Wikipedia em busca de referências ao seu negócio e apontar qualquer caso de vandalismo lá.
Aumente o SEO
Você pode utilizar a Wikipedia para aumentar o tráfego para seu site.
Crie uma lista de artigos que você gostaria de alterar usando um raspador de dados Wiki para localizar páginas pertinentes ao seu negócio e ao seu público-alvo.
Comece lendo os artigos e fazendo alguns ajustes úteis para ganhar credibilidade como colaborador do site.
Depois de estabelecer alguma credibilidade, você pode adicionar conexões ao seu site em locais onde há links quebrados ou onde as citações são necessárias.
Links Rápidos
- Melhores Proxies Franceses
- Top Melhor Proxy Spotify
- Melhores Proxies da Nike
Bibliotecas Python usadas para web scraping
Python é a linguagem de programação e ferramenta de web scraping mais popular e respeitável do mundo, como já foi dito. Agora vamos ver as bibliotecas de raspagem da web do Python que estão disponíveis agora.
Biblioteca Requests (HTTP for Humans) para Web Scraping
Ele é usado para enviar diferentes solicitações HTTP, como GET e POST. Entre todas as bibliotecas, é a mais fundamental, mas também a mais crucial.
Biblioteca lxml para Web Scraping
A análise muito rápida e de alto desempenho de texto HTML e XML de sites é oferecida pelo pacote lxml. Este é o escolhido se você pretende raspar bancos de dados enormes.
Linda Biblioteca de Sopas para Web Scraping
Seu trabalho é construir uma árvore de análise para análise de conteúdo. Um ótimo lugar para começar para iniciantes e é altamente amigável.
Biblioteca Selenium para Web Scraping
Essa biblioteca resolve o problema que todas as bibliotecas mencionadas acima têm, ou seja, extrair conteúdo de páginas da Web preenchidas dinamicamente.
Ele foi originalmente projetado para testes automatizados de aplicativos da web. Por isso, é mais lento e inadequado para tarefas de nível industrial.
Scrapy para Web Scraping
Uma estrutura completa de raspagem da Web que usa uso assíncrono é o BOSS de todos os pacotes. Isso aumenta a eficiência e torna incrivelmente rápido.
Conclusão
Portanto, este foi o aspecto mais importante que você precisa saber sobre a raspagem da Web da Wikipedia. Fique ligado conosco para mais postagens informativas sobre Web Scraping e muito mais!
Links Rápidos
- Melhores proxies para agregação de tarifa de viagem
- Melhores Proxies Franceses
- Melhores proxys do Tripadvisor
- Melhores Proxies Etsy
- Código de cupom IPRoyal
- Melhores proxies TikTok