
Estudo de caso de SEO de um ano: o que você precisa saber sobre o Googlebot
Publicados: 2019-08-30Nota do editor: o CEO do rastreador JetOctopus, Serge Bezborodov, dá conselhos especializados sobre como tornar seu site atraente para o Googlebot. Os dados deste artigo são baseados em pesquisas de um ano e 300 milhões de páginas rastreadas.
Alguns anos atrás, eu estava tentando aumentar o tráfego em nosso site agregador de empregos com 5 milhões de páginas. Decidi usar os serviços da agência de SEO, esperando que o tráfego aumentasse. Mas eu estava errado. Em vez de uma auditoria abrangente, recebi leitura de cartas de tarô. É por isso que voltei à estaca zero e criei um rastreador da Web para uma análise abrangente de SEO na página.
Tenho espionado o Googlebot há mais de um ano e agora estou pronto para compartilhar informações sobre seu comportamento. Espero que minhas observações pelo menos esclareçam como os rastreadores da Web funcionam e, no máximo, ajudem você a conduzir a otimização na página com eficiência. Reuni os dados mais significativos que são úteis para um novo site ou para um que tenha milhares de páginas.
Suas páginas estão aparecendo nas SERPs?
Para saber com certeza quais páginas estão nos resultados da pesquisa, você deve verificar a capacidade de indexação de todo o site. No entanto, a análise de cada URL em um site com mais de 10 milhões de páginas custa uma fortuna, quase tanto quanto um carro novo.
Em vez disso, vamos usar a análise de arquivos de log. Trabalhamos com sites da seguinte maneira: rastreamos as páginas da web como o bot de pesquisa faz e, em seguida, analisamos os arquivos de log que foram coletados durante a metade do ano. Os logs mostram se os bots visitam o site, quais páginas foram rastreadas e quando e com que frequência os bots visitaram as páginas.
Rastreamento é o processo de bots de pesquisa visitando seu site, processando todos os links em páginas da Web e colocando esses links em linha para indexação. Durante o rastreamento, os bots comparam as URLs recém-processadas com as que já estão no índice. Assim, os bots atualizam os dados e adicionam/excluem alguns URLs do banco de dados do mecanismo de pesquisa para fornecer os resultados mais relevantes e atualizados para os usuários.
Agora, podemos facilmente tirar estas conclusões:
- A menos que o bot de pesquisa esteja no URL, esse URL provavelmente não estará no índice.
- Se o Googlebot visitar o URL várias vezes ao dia, esse URL é de alta prioridade e, portanto, requer sua atenção especial.
Ao todo, essas informações revelam o que impede o crescimento orgânico e o desenvolvimento do seu site. Agora, em vez de operar às cegas, sua equipe pode otimizar um site com sabedoria.
Trabalhamos principalmente com sites grandes porque, se seu site for pequeno, o Googlebot rastreará todas as suas páginas da web mais cedo ou mais tarde.
Por outro lado, sites com mais de 100.000 páginas enfrentam um problema quando o rastreador visita páginas invisíveis para os webmasters. Um valioso orçamento de rastreamento pode ser desperdiçado nessas páginas inúteis ou até prejudiciais. Ao mesmo tempo, o bot pode nunca encontrar suas páginas lucrativas porque há uma bagunça na estrutura do site.
O orçamento de rastreamento são os recursos limitados que o Googlebot está disposto a gastar em seu site. Foi criado para priorizar o que analisar e quando. O tamanho do orçamento de rastreamento depende de muitos fatores, como o tamanho do seu site, sua estrutura, volume e frequência de consultas dos usuários, etc.
Observe que o bot de pesquisa não está interessado em rastrear seu site completamente.
O principal objetivo do bot do mecanismo de pesquisa é fornecer aos usuários as respostas mais relevantes com perdas mínimas de recursos.O bot rastreia todos os dados necessários para o objetivo principal. Portanto, é SUA tarefa ajudar o bot a obter o conteúdo mais útil e lucrativo.
Espiar o Googlebot
No ano passado, verificamos mais de 300 milhões de URLs e 6 bilhões de linhas de log em grandes sites. Com base nesses dados, rastreamos o comportamento do Googlebot para ajudar a responder às seguintes perguntas:
- Que tipos de páginas são ignorados?
- Quais páginas são visitadas com frequência?
- O que vale a pena atenção para o bot?
- O que não tem valor?
Abaixo estão nossas análises e descobertas, e não uma reescrita das Diretrizes para webmasters do Google. Na verdade, não damos recomendações não comprovadas e injustificadas. Cada ponto é baseado em estatísticas e gráficos factuais para sua conveniência.
Vamos direto ao assunto e descubra:
- O que realmente importa para o Googlebot?
- O que determina se o bot visita a página ou não?
Identificamos os seguintes fatores:
Distância do índice
DFI significa Distance From Index e é a distância do seu URL para o URL principal/raiz/índice em cliques. É um dos critérios mais importantes que afetam a frequência das visitas do Googlebot. Aqui está um vídeo educacional para aprender mais sobre DFI .
Observe que DFI não é o número de barras no diretório URL como, por exemplo:
site.com/shop/iphone/iphoneX.html – DFI– 3__ _
Portanto, o DFI é contado exatamente pelos CLICKS da página principal
https://site.com/shop/iphone/iphoneX.html
https://site.com Catálogo de iPhones → https://site.com/shop/iphone iPhone X → https://site.com/shop/iphone/iphoneX.html – DFI – 2
Abaixo você pode ver como o interesse do Googlebot no URL com seu DFI foi diminuindo gradualmente durante o último mês e nos últimos seis meses.
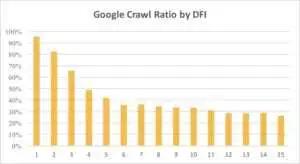
Como você pode ver, se DFI for 5 t0 6, o Googlebot rastreia apenas metade das páginas da web. E a porcentagem de páginas processadas reduz se o DFI for maior. Os indicadores da tabela foram unificados em 18 milhões de páginas. Observe que os dados podem variar dependendo do nicho do site específico.
O que fazer?
É óbvio que a melhor estratégia nesse caso é evitar DFI maior que 5, construir uma estrutura de site de fácil navegação, dar atenção especial aos links, etc.
A verdade é que essas medidas consomem muito tempo para sites com mais de 100.000 páginas. Normalmente, grandes sites têm um longo histórico de redesenhos e migrações. É por isso que os webmasters não devem apenas excluir páginas com DFI de 10, 12 ou mesmo 30. Além disso, inserir um link de páginas visitadas com frequência não resolverá o problema.
A maneira ideal de lidar com DFI longo é verificar e estimar se essas URLs são relevantes, lucrativas e quais posições elas ocupam nas SERPs.
Páginas com DFI longo, mas boas posições nas SERPs, têm alto potencial. Para aumentar o tráfego em páginas de alta qualidade, os webmasters devem inserir links das próximas páginas. Um ou dois links não são suficientes para um progresso tangível.
Você pode ver no gráfico abaixo que o Googlebot visita os URLs com mais frequência se houver mais de 10 links na página.
links
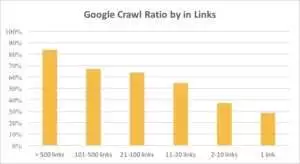
Na verdade, quanto maior um site, mais significativo é o número de links nas páginas da web. Na verdade, esses dados são de sites com mais de 1 milhão de páginas.

Se você descobriu que há menos de 10 links em suas páginas lucrativas, não entre em pânico. Primeiro, verifique se essas páginas são de alta qualidade e lucrativas. Ao fazer isso, insira links em páginas de alta qualidade sem pressa e com iterações curtas, analisando logs após cada etapa.
Tamanho do conteúdo
O conteúdo é um dos aspectos mais populares da análise de SEO. Obviamente, quanto mais conteúdo relevante estiver em seu site, melhor será sua taxa de rastreamento. Abaixo, você pode ver como o interesse do Googlebot diminui drasticamente em páginas com menos de 500 palavras.
O que fazer?
Com base na minha experiência, quase metade de todas as páginas com menos de 500 palavras são páginas de lixo. Vimos um caso em que um site continha 70.000 páginas com apenas o tamanho das roupas listadas, portanto, apenas parte dessas páginas estava no índice.
Portanto, primeiro verifique se você realmente precisa dessas páginas. Se esses URLs forem importantes, você deve adicionar algum conteúdo relevante a eles. Se você não tem nada a acrescentar, relaxe e deixe essas URLs como estão. Às vezes é melhor não fazer nada em vez de publicar conteúdo inútil.
Outros fatores
Os seguintes fatores podem afetar significativamente a taxa de rastreamento:
Tempo de carregamento
A velocidade da página da Web é crucial para rastreamento e classificação. O bot é como um ser humano: odeia esperar muito para carregar uma página da web. Se houver mais de 1 milhão de páginas em seu site, o bot de pesquisa provavelmente baixará cinco páginas com um tempo de carregamento de 1 segundo, em vez de esperar por uma página que carregue em 5 segundos.
O que fazer?
Na verdade, esta é uma tarefa técnica e não existe uma solução “um método para todos”, como usar um servidor maior. A ideia principal é encontrar o gargalo do problema. Você deve entender por que as páginas da Web carregam lentamente. Somente depois que o motivo for revelado, você poderá agir.
Proporção de conteúdo exclusivo e modelo
O equilíbrio entre dados exclusivos e modelo é importante. Por exemplo, você tem um site com variações de nomes de animais de estimação. Quanto conteúdo relevante e exclusivo você pode realmente coletar sobre esse tópico?
Luna foi o nome de cachorro de “celebridade” mais popular, seguido por Stella, Jack, Milo e Leo.
Os bots de pesquisa não gostam de gastar seus recursos nesses tipos de páginas.
O que fazer?
Manter o equilíbrio. Usuários e bots não gostam de visitar páginas com modelos complicados, muitos links de saída e pouco conteúdo.
Páginas órfãs
Páginas órfãs são URLs que não estão na estrutura do site e você não conhece essas páginas, mas essas páginas órfãs podem ser rastreadas por bots. Para deixar claro, observe o Círculo de Euler na figura abaixo:

Você pode ver a situação normal do site jovem, cuja estrutura não foi alterada por um tempo. Existem 900.000 páginas que você e o rastreador podem analisar. Cerca de 500.000 páginas são processadas pelo rastreador, mas são desconhecidas pelo Google. Se você tornar esses 500.000 URLs indexáveis, seu tráfego aumentará com certeza.
Preste atenção: mesmo um site jovem contém algumas páginas (a parte azul na imagem) que não estão na estrutura do site, mas são regularmente visitadas por bots.
E essas páginas podem conter conteúdo lixo, como consultas inúteis de visitantes geradas automaticamente.
Mas grandes sites raramente são tão precisos. Muitas vezes, sites com histórico se parecem com isso:

Aqui está o outro problema: o Google sabe mais sobre o seu site do que você. Pode haver páginas excluídas, páginas em JavaScript ou Ajax, redirecionamentos quebrados e assim por diante. Certa vez, enfrentamos uma situação em que uma lista de 500.000 links quebrados apareceu no mapa do site devido a um erro do programador. Após três dias, o bug foi encontrado e corrigido, mas o Googlebot visitava esses links quebrados há meio ano!
Muitas vezes, seu orçamento de rastreamento é frequentemente desperdiçado nessas páginas órfãs.
O que fazer?
Existem duas maneiras de corrigir esse problema potencial: A primeira é canônica: limpar a bagunça. Organize a estrutura do site, insira links internos corretamente, adicione páginas órfãs ao DFI adicionando links de páginas indexadas, defina a tarefa para os programadores e aguarde a próxima visita do Googlebot.
A segunda maneira é imediata: reúna a lista de páginas órfãs e verifique se elas são relevantes. Se a resposta for “sim”, crie o mapa do site com essas URLs e envie-o ao Google. Dessa forma é mais fácil e rápido, mas apenas metade das páginas órfãs estarão no índice.
O próximo nível
Os algoritmos dos mecanismos de pesquisa melhoraram por duas décadas e é ingênuo pensar que o rastreamento de pesquisa pode ser explicado com alguns gráficos.
Reunimos mais de 200 parâmetros diferentes para cada página e esperamos que esse número aumente até o final do ano. Imagine que seu site é a tabela com 1 milhão de linhas (páginas) e multiplique essas linhas por 200 colunas, a amostra simples não é suficiente para uma auditoria técnica abrangente. Você concorda?
Decidimos nos aprofundar e usar o aprendizado de máquina para descobrir o que influencia o rastreamento do Googlebots em cada caso.

Por um lado, os links do site são cruciais, enquanto o conteúdo é o fator chave para o outro.
O ponto principal desta tarefa era obter respostas fáceis a partir de dados complicados e massivos: O que em seu site mais impacta a indexação? Quais clusters de URLs estão conectados com os mesmos fatores? Para que você possa trabalhar com eles de forma abrangente.
Antes de baixar e analisar logs em nosso site agregador HotWork, a história sobre páginas órfãs que são visíveis para bots, mas não para nós, parecia irreal para mim. Mas a situação real me surpreendeu ainda mais: o Crawl mostrou 500 páginas com redirecionamento 301, mas o Yandex encontrou 700.000 páginas com o mesmo código de status.
Normalmente, geeks técnicos não gostam de armazenar arquivos de log porque esses dados “sobrecarregam” os discos. Mas, objetivamente, na maioria dos sites com até 10 milhões de visitas por mês, a configuração básica de armazenamento de logs funciona perfeitamente.
Falando no volume de logs, a melhor solução é criar um arquivo e baixá-lo no Amazon S3-Glacier (você pode armazenar 250 GB de dados por apenas US$ 1). Para administradores de sistema, essa tarefa é tão fácil quanto preparar uma xícara de café. No futuro, os registros históricos ajudarão a revelar bugs técnicos e estimar a influência das atualizações do Google em seu site.