
Apache Spark: stea strălucitoare în firmamentul big data.
Publicat: 2015-09-24- Recomandând milioane de produse clienților potriviți.
- Urmărirea istoricului căutărilor și oferirea de prețuri reduse pentru călătoriile de zbor.
- Compararea abilităților tehnice ale persoanei și sugerarea adecvată a persoanelor cu care să se conecteze în domeniul dvs.
- Înțelegerea tiparelor în miliarde de obiecte mobile, turnuri de rețea și tranzacții de apeluri și calcularea optimizărilor rețelei de telecomunicații sau găsirea lacunelor în rețea.
- Studierea milioanelor de caracteristici ale senzorilor și analiza defecțiunilor din rețelele de senzori.
Datele de bază necesare pentru a obține rezultate corecte pentru toate sarcinile de mai sus sunt comparativ foarte mari. Nu poate fi gestionat eficient (atât din punct de vedere al spațiului, cât și al timpului) de către sistemele tradiționale.
Toate acestea sunt scenarii de date mari.
Pentru a colecta, stoca și face calcule pe acest tip de date voluminoase avem nevoie de un sistem de calcul cluster specializat. Apache Hadoop a rezolvat această problemă pentru noi.
Oferă un sistem de stocare distribuit (HDFS) și o platformă de calcul paralelă (MapReduce).
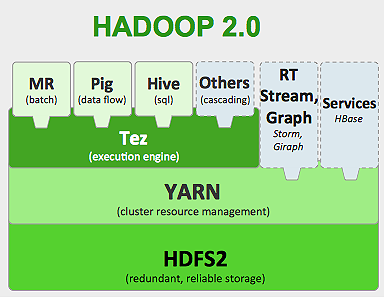
Cadrul Hadoop funcționează după cum urmează:
- Împarte fișierele mari de date în bucăți mai mici pentru a fi procesate de mașini individuale (Distributing Storage).
- Împarte munca mai lungă în sarcini mai mici pentru a fi executate în mod paralel (Calcul paralel).
- Gestionează automat defecțiunile.
Limitările Hadoop
Hadoop are instrumente specializate în ecosistemul său pentru a îndeplini diferite sarcini. Deci, dacă doriți să rulați un ciclu de viață de la capăt la capăt al unei aplicații, trebuie să utilizați mai multe instrumente. De exemplu, pentru interogările SQL veți folosi, hive/pig , pentru sursele de streaming trebuie să utilizați Hadoop încorporat streaming sau Apache Storm (care nu face parte din ecosistemul Hadoop) sau pentru algoritmii de învățare automată trebuie să utilizați Mahout . Integrarea tuturor acestor sisteme împreună pentru a construi un singur caz de utilizare a conductei de date este o sarcină destul de mare.
În jobul MapReduce ,
- Ieșirea tuturor sarcinilor de hartă este descărcată pe discuri locale (sau HDFS).
- Hadoop îmbină toate fișierele de scurgere într-un fișier mai mare, care este sortat și împărțit în funcție de numărul de reductoare.
- Și reduceți sarcinile trebuie să-l încărcați din nou în memorie.
Acest proces face munca mai lentă, provocând I/O pe disc și I/O în rețea. Acest lucru face, de asemenea, Mapreduce inadecvat pentru procesarea iterativă, în care trebuie să aplicați algoritmi de învățare automată aceluiași grup de date din nou și din nou.
Intrați în lumea Apache Spark:
Apache Spark este dezvoltat în UC Berkeley AMPLAB în 2009, iar în 2010 a devenit proiectul open source cu cea mai mare contribuție Apache până în prezent.
Apache Spark este un sistem mai generalizat , în care puteți rula atât joburi batch, cât și joburi de streaming simultan. Acesta îl înlocuiește pe predecesorul MapReduce în ceea ce privește viteza, adăugând capabilități de procesare a datelor mai rapid în memorie. De asemenea, este mai eficient pe disc. Se folosește în procesarea memoriei folosind unitatea de date de bază RDD (Resilient Distributed Dataset). Acestea păstrează cât mai mult set de date posibil în memorie pentru ciclul de viață complet al lucrării, prin urmare economisind I/O pe disc. Unele date pot fi vărsate pe disc după limitele superioare ale memoriei.
Graficul de mai jos arată timpul de rulare în secunde atât pentru Apache Hadoop, cât și pentru Spark pentru calcularea regresiei logistice. Hadoop a durat 110 secunde, în timp ce spark a terminat aceeași lucrare în doar 0,9 secunde.
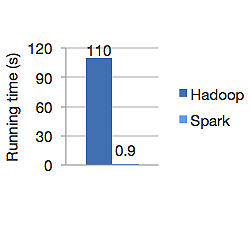
Spark nu stochează toate datele în memorie. Dar dacă datele sunt în memorie, folosește cel mai bine memoria cache LRU pentru a le procesa mai rapid. Este de 100 de ori mai rapid în timpul calculării datelor în memorie și tot mai rapid pe disc decât Hadoop.
Modelul de stocare a datelor distribuite de la Spark, seturi de date distribuite rezistente (RDD), garantează toleranța la erori care, la rândul său, minimizează I/O în rețea. Spark paper spune:

„RDD-urile obțin toleranță la erori printr-o noțiune de descendență: dacă o partiție a unui RDD este pierdută, RDD-ul are suficiente informații despre cum a fost derivat din alte RDD-uri pentru a putea reconstrui doar acea partiție.”
Deci, nu trebuie să replicați datele pentru a obține toleranța la erori.
În Spark MapReduce, ieșirea mapperilor este păstrată în memoria cache a sistemului de operare, iar reductoarele o trag de partea lor și o scriu direct în memoria lor, spre deosebire de Hadoop, unde rezultatul este vărsat pe disc și o citește din nou.
Cache-ul Spark în memorie îl face potrivit pentru algoritmii de învățare automată în care trebuie să utilizați aceleași date din nou și din nou. Spark poate rula joburi complexe, conducte de date în mai mulți pași folosind Direct Acyclic Graph (DAG).
Spark este scris în Scala și rulează pe JVM (Java Virtual Machine). Spark oferă API-uri de dezvoltare pentru limbajele Java, Scala, Python și R. Spark rulează pe Hadoop YARN, Apache Mesos și are propriul manager de cluster autonom.
În 2014, a obținut locul 1 în recordul mondial pentru sortarea datelor de 100 TB (1 trilion de înregistrări) în doar 23 de minute, în timp ce recordul anterior al Hadoop de către Yahoo a fost de aproximativ 72 de minute. Acest lucru demonstrează că Spark a sortat datele de 3 ori mai rapid și cu de 10 ori mai puține mașini. Toate sortările au avut loc pe disc (HDFS), fără a utiliza efectiv capacitatea de cache în memorie spark.
Ecosistemul Spark
Spark este menit să facă analize avansate dintr-o singură mișcare, pentru a reuși să ofere următoarele componente:
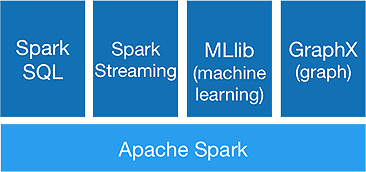
1.Spark Core:
API-ul de bază Spark este baza cadrului Apache Spark, care se ocupă de programarea lucrărilor, distribuția sarcinilor, gestionarea memoriei, operațiunile I/O și recuperarea din eșecuri. Unitatea principală de date logice din spark se numește RDD (Resilient Distributed Dataset), care stochează datele în mod distribuit pentru a fi procesate în paralel ulterior. Calculează leneș operațiuni. Prin urmare, memoria nu trebuie să fie ocupată tot timpul, iar alte locuri de muncă o pot utiliza.
2. Spark SQL:
Oferă capabilități interactive de interogare cu latență scăzută. Noul API DataFrame poate stoca atât date structurate, cât și semi-structurate și permite tuturor operațiunilor și funcțiilor SQL să efectueze calcule.
3.Spark Streaming:
Oferă API-uri de streaming în timp real , care colectează și procesează date în micro loturi.
Utilizează Dstreams , care nu este altceva decât o secvență continuă de RDD-uri , pentru a calcula logica de afaceri pe datele primite și pentru a genera rezultate imediat.
4.MLlib :
Este biblioteca de învățare automată a lui Spark (de aproape 9 ori mai rapidă decât Mahout) care oferă învățare automată, precum și algoritmi statistici precum clasificarea, regresia, filtrarea colaborativă etc.
5.GraphX :
GraphX API oferă capabilități de a gestiona grafice și de a efectua calcule în paralel cu grafice. Include algoritmi grafici precum PageRank și diverse funcții pentru analiza graficelor.
Va marca Spark sfârșitul erei Hadoop?
Spark este încă un sistem tânăr, nu la fel de matur ca Hadoop. Nu există niciun instrument pentru NOSQL precum HBase. Având în vedere necesarul mare de memorie pentru o procesare mai rapidă a datelor, nu puteți spune cu adevărat că rulează pe hardware de bază. Spark nu are propriul sistem de stocare. Se bazează pe HDFS pentru asta.
Așadar, Hadoop MapReduce este încă bun pentru anumite joburi în lot, care nu include multă pipeline de date.
„Noua tehnologie nu o înlocuiește niciodată complet pe cea veche; amândoi ar prefera să coexiste.”
Concluzie
În acest blog, ne-am uitat la motivul pentru care aveți nevoie de un instrument precum Spark, ceea ce îl face mai rapid sistemul de calcul cluster și componentele sale de bază. Partea următoare vom aprofunda în RDD-urile, transformările și acțiunile API de bază Spark.