
Eficacitatea accesării cu crawlere: cum să creșteți nivelul de optimizare a accesării cu crawlere
Publicat: 2022-10-27Nu este garantat că Googlebot va accesa cu crawlere fiecare adresă URL pe care o poate accesa pe site-ul dvs. Dimpotrivă, marea majoritate a site-urilor le lipsește o bucată semnificativă de pagini.
Realitatea este că Google nu are resursele pentru a accesa cu crawlere fiecare pagină pe care o găsește. Toate adresele URL pe care Googlebot le-a descoperit, dar nu le-a accesat încă, împreună cu adresele URL pe care intenționează să le acceseze din nou cu crawlere sunt prioritizate într-o coadă de accesare cu crawlere.
Aceasta înseamnă că Googlebot accesează cu crawlere numai cele cărora li se atribuie o prioritate suficient de mare. Și deoarece coada de accesare cu crawlere este dinamică, se modifică continuu pe măsură ce Google procesează noi adrese URL. Și nu toate adresele URL se alătură în spatele cozii.
Așadar, cum vă asigurați că adresele URL ale site-ului dvs. sunt VIP-uri și cum săriți coada?
Crawling-ul este extrem de important pentru SEO

Pentru ca conținutul să câștige vizibilitate, Googlebot trebuie să îl acceseze cu crawlere.
Dar beneficiile sunt mai nuanțate decât atât, deoarece cu cât o pagină este accesată cu crawlere mai repede atunci când este:
- Creat , cu atât mai repede poate apărea conținutul nou pe Google. Acest lucru este deosebit de important pentru strategiile de conținut limitate în timp sau primul pe piață.
- Actualizat , cu cât conținutul reîmprospătat poate începe să afecteze clasamentele mai repede. Acest lucru este deosebit de important atât pentru strategiile de republicare a conținutului, cât și pentru tacticile tehnice SEO.
Ca atare, crawling-ul este esențial pentru tot traficul tău organic. Cu toate acestea, prea des se spune că optimizarea accesării cu crawlere este benefică numai pentru site-urile mari.
Dar nu este vorba de dimensiunea site-ului dvs., de frecvența conținutului este actualizat sau de dacă aveți excluderi „Descoperit – momentan neindexat” în Google Search Console.
Optimizarea accesului cu crawlere este benefică pentru fiecare site web. Concepția greșită a valorii sale pare să decurgă din măsurători lipsite de sens, în special din bugetul de crawl.
Bugetul de accesare cu crawlere nu contează

Prea des, accesarea cu crawlere este evaluată pe baza bugetului de accesare cu crawlere. Acesta este numărul de adrese URL pe care Googlebot le va accesa cu crawlere într-un anumit interval de timp pe un anumit site web.
Google spune că este determinat de doi factori:
- Limita ratei de accesare cu crawlere (sau ceea ce Googlebot poate accesa cu crawlere): viteza cu care Googlebot poate prelua resursele site-ului web fără a afecta performanța site-ului. În esență, un server receptiv duce la o rată de accesare cu crawlere mai mare.
- Cererea de accesare cu crawlere (sau ceea ce Googlebot dorește să acceseze cu crawlere): numărul de adrese URL pe care Googlebot le vizitează în timpul unei singure accesări cu crawlere, pe baza cererii de (re)indexare, influențată de popularitatea și învechirea conținutului site-ului.
Odată ce Googlebot își „cheltuie” bugetul de accesare cu crawlere, nu mai accesează cu crawlere un site.
Google nu oferă o cifră pentru bugetul de accesare cu crawlere. Cel mai aproape se afișează numărul total de solicitări de accesare cu crawlere în raportul privind statisticile de accesare cu crawlere Google Search Console.
Atât de mulți SEO, inclusiv eu în trecut, s-au străduit să încerce să deducă bugetul de accesare cu crawlere.
Pașii des prezentați sunt ceva de genul:
- Determinați câte pagini care pot fi accesate cu crawlere aveți pe site-ul dvs., recomandând adesea să vă uitați la numărul de adrese URL din harta site-ului dvs. XML sau să rulați un crawler nelimitat.
- Calculați numărul mediu de accesări cu crawlere pe zi exportând raportul Statistici de accesare cu crawlere Google Search Console sau pe baza solicitărilor Googlebot din fișierele jurnal.
- Împărțiți numărul de pagini la numărul mediu de accesări cu crawlere pe zi. Se spune adesea, dacă rezultatul este peste 10, concentrați-vă pe optimizarea bugetului de accesare cu crawlere.
Cu toate acestea, acest proces este problematic.
Nu numai pentru că presupune că fiecare URL este accesată cu crawlere o dată, când, în realitate, unele sunt accesate cu crawlere de mai multe ori, altele deloc.
Nu numai pentru că presupune că o accesare cu crawlere este egală cu o pagină. Când, în realitate, o pagină poate necesita mai multe accesări cu crawlere URL pentru a prelua resursele (JS, CSS etc.) necesare pentru a o încărca.
Dar, cel mai important, pentru că atunci când este distilat la o valoare calculată, cum ar fi accesările medii pe zi, bugetul de accesare cu crawlere nu este altceva decât o valoare vanitară.
Orice tactică care vizează „optimizarea bugetului de accesare cu crawlere” (alias, scopul de a crește continuu cantitatea totală de accesare cu crawlere) este o misiune prostească.
De ce ar trebui să vă pese de creșterea numărului total de accesări cu crawlere dacă este folosit pe adrese URL fără valoare sau pe pagini care nu au fost modificate de la ultima accesare cu crawlere? Astfel de accesări cu crawlere nu vor ajuta la performanța SEO.
În plus, oricine s-a uitat vreodată la statisticile de accesare cu crawlere știe că acestea fluctuează, adesea destul de sălbatic, de la o zi la alta, în funcție de o mulțime de factori. Aceste fluctuații se pot corela sau nu cu (re)indexarea rapidă a paginilor relevante pentru SEO.
O creștere sau o scădere a numărului de adrese URL accesate cu crawlere nu este în mod inerent nici bună, nici rea.
Eficacitatea crawl-ului este un KPI SEO

Pentru paginile pe care doriți să le indexați, accentul nu ar trebui să se concentreze asupra faptului că au fost accesate cu crawlere, ci mai degrabă pe cât de repede au fost accesate cu crawlere după ce au fost publicate sau modificate semnificativ.
În esență, scopul este de a minimiza timpul dintre crearea sau actualizarea unei pagini relevante pentru SEO și următoarea accesare cu crawlere Googlebot. Eu numesc acest timp întârziere eficacitatea crawl-ului.
Modul ideal de a măsura eficacitatea accesării cu crawlere este de a calcula diferența dintre data de creare sau actualizare a bazei de date și următoarea accesare cu crawlere Googlebot a adresei URL din fișierele jurnal ale serverului.
Dacă este dificil să obțineți acces la aceste puncte de date, puteți utiliza, de asemenea, ca proxy, data și adresele URL ale interogărilor din API-ul de inspecție URL din Google Search Console pentru ultima stare de accesare cu crawlere (până la o limită de 2.000 de interogări pe zi).
În plus, utilizând API-ul de inspecție URL, puteți, de asemenea, să urmăriți când se schimbă starea de indexare pentru a calcula eficacitatea indexării pentru adresele URL nou create, care reprezintă diferența dintre publicare și indexarea reușită.
Pentru că accesarea cu crawlere fără ca aceasta să aibă un impact asupra stării de indexare sau procesarea unei reîmprospătări a conținutului paginii este doar o risipă.
Eficacitatea accesării cu crawlere este o valoare acționabilă, deoarece pe măsură ce scade, cu atât mai mult conținut critic pentru SEO poate fi prezentat publicului dvs. de pe Google.
De asemenea, îl puteți folosi pentru a diagnostica problemele SEO. Analizați modelele de adrese URL pentru a înțelege cât de rapid este accesat cu crawlere conținutul din diferite secțiuni ale site-ului dvs. și dacă acesta este ceea ce împiedică performanța organică.
Dacă observați că Googlebot durează ore, zile sau săptămâni să acceseze cu crawlere și astfel să indexeze conținutul dvs. nou creat sau actualizat recent, ce puteți face în acest sens?
Obțineți buletinele informative zilnice pe care se bazează marketerii.
Vezi termenii.
7 pași pentru a optimiza accesul cu crawlere
Optimizarea accesării cu crawlere se referă la îndrumarea Googlebot pentru accesarea cu crawlere a adreselor URL importante rapid când sunt (re)publicate. Urmați cei șapte pași de mai jos.
1. Asigurați un răspuns rapid și sănătos al serverului
Un server foarte performant este esențial. Googlebot va încetini sau va opri accesarea cu crawlere atunci când:
- Accesarea cu crawlere a site-ului dvs. afectează performanța. De exemplu, cu cât se accesează cu crawlere mai mult, cu atât timpul de răspuns al serverului este mai lent.
- Serverul răspunde cu un număr notabil de erori sau expirări de conexiune.
Pe de altă parte, îmbunătățirea vitezei de încărcare a paginii, permițând difuzarea mai multor pagini, poate determina Googlebot să acceseze cu crawlere mai multe adrese URL în același timp. Acesta este un beneficiu suplimentar pe lângă viteza paginii, fiind experiența utilizatorului și factor de clasare.
Dacă nu ați făcut-o deja, luați în considerare suportul pentru HTTP/2, deoarece permite posibilitatea de a solicita mai multe adrese URL cu o încărcare similară pe servere.
Cu toate acestea, corelația dintre performanță și volumul de accesare cu crawlere este doar până la un punct . Odată ce depășiți acel prag, care variază de la site la site, este puțin probabil ca orice câștig suplimentar în performanța serverului să se coreleze cu o creștere a accesării cu crawlere.
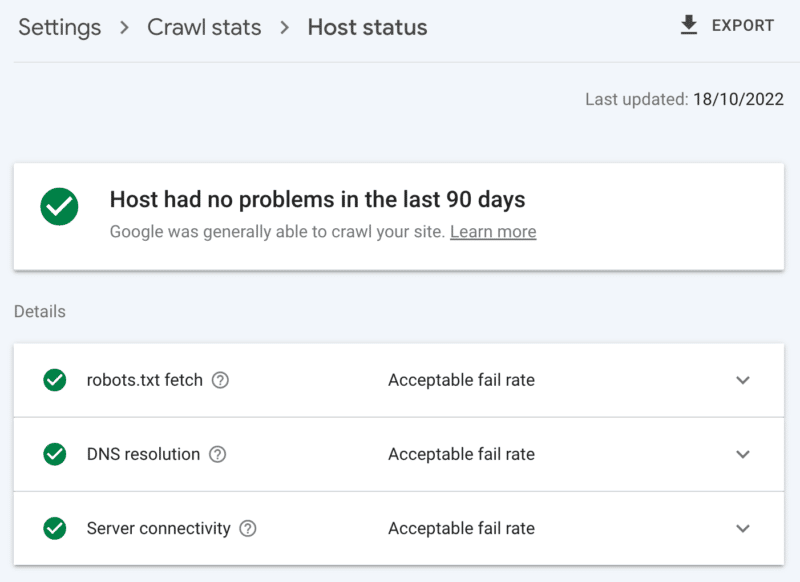
Cum se verifică starea serverului
Raportul privind statisticile de accesare cu crawlere Google Search Console:

- Stare gazdă: arată căpușe verzi.
- Erori 5xx: reprezintă mai puțin de 1%.
- Diagrama timpului de răspuns al serverului: tendință sub 300 de milisecunde.
2. Curățați conținutul de valoare scăzută
Dacă o cantitate semnificativă de conținut de site este învechit, duplicat sau de calitate scăzută, aceasta provoacă concurență pentru activitatea de accesare cu crawlere, întârzierea potențial indexarea conținutului proaspăt sau reindexarea conținutului actualizat.
Adăugați la faptul că curățarea regulată a conținutului de valoare scăzută reduce, de asemenea, balonarea indexului și canibalizarea cuvintelor cheie și este benefică pentru experiența utilizatorului, aceasta este o idee SEO.
Îmbinați conținutul cu o redirecționare 301, atunci când aveți o altă pagină care poate fi văzută ca o înlocuire clară; înțelegerea acestui lucru vă va costa dublarea accesului cu crawlere pentru procesare, dar este un sacrificiu util pentru echitatea linkului.
Dacă nu există conținut echivalent, folosirea unui 301 va avea ca rezultat doar un 404 soft. Eliminați un astfel de conținut folosind un cod de stare 410 (cel mai bun) sau 404 (secunda apropiată) pentru a da un semnal puternic de a nu accesa din nou cu crawlere adresa URL.
Cum să verificați conținutul de valoare scăzută
Numărul de adrese URL din paginile Google Search Console raportează excluderi „accesate cu crawlere – momentan neindexate”. Dacă aceasta este mare, examinați mostrele furnizate pentru modelele de foldere sau alți indicatori de problemă.
3. Examinați controalele de indexare
Rel=legături canonice sunt un indiciu puternic pentru a evita problemele de indexare, dar se bazează adesea în exces și ajung să provoace probleme de accesare cu crawlere, deoarece fiecare adresă URL canonizată costă cel puțin două accesări cu crawlere, una pentru sine și una pentru partenerul său.
În mod similar, directivele roboților noindex sunt utile pentru a reduce balonarea indexului, dar un număr mare poate afecta negativ accesarea cu crawlere – deci folosiți-le numai atunci când este necesar.
În ambele cazuri, întrebați-vă:
- Sunt aceste directive de indexare modalitatea optimă de a gestiona provocarea SEO?
- Unele rute URL pot fi consolidate, eliminate sau blocate în robots.txt?
Dacă îl utilizați, reconsiderați serios AMP ca soluție tehnică pe termen lung.
Având în vedere că actualizarea experienței paginii se concentrează pe elementele vitale web de bază și includerea paginilor non-AMP în toate experiențele Google, atâta timp cât îndepliniți cerințele de viteză a site-ului, analizați cu atenție dacă AMP merită dubla accesare cu crawlere.
Cum să verificați dependența excesivă de controalele de indexare
Numărul de adrese URL din raportul de acoperire Google Search Console clasificate în cadrul excluderilor fără un motiv clar:
- Pagina alternativă cu eticheta canonică adecvată.
- Exclus de eticheta noindex.
- Dublat, Google a ales un alt canonic decât utilizatorul.
- Duplicat, adresa URL trimisă nu a fost selectată ca canonică.
4. Spuneți păianjenilor motoarelor de căutare ce să acceseze cu crawlere și când
Un instrument esențial pentru a ajuta Googlebot să prioritizeze adresele URL importante ale site-urilor și să comunice atunci când astfel de pagini sunt actualizate este o hartă de site XML.
Pentru o ghidare eficientă pe șenile, asigurați-vă că:
- Includeți numai adrese URL care sunt atât indexabile, cât și valoroase pentru SEO – în general, 200 de coduri de stare, pagini de conținut canonice, originale, cu o etichetă roboți „index,follow” pentru care vă pasă de vizibilitatea lor în SERP-uri.
- Includeți etichete de marcare temporală <lastmod> exacte pe adresele URL individuale și pe harta site-ului în sine cât mai aproape posibil de timp real.
Google nu verifică un sitemap de fiecare dată când un site este accesat cu crawlere. Deci, ori de câte ori este actualizat, cel mai bine este să-l trimiteți în atenția Google. Pentru a face acest lucru, trimiteți o solicitare GET în browser sau în linia de comandă la:
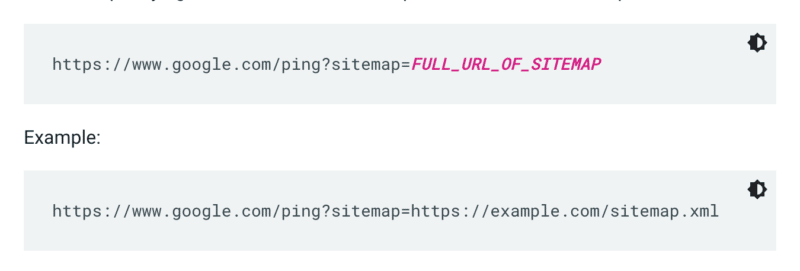
În plus, specificați căile către harta site-ului în fișierul robots.txt și trimiteți-l la Google Search Console utilizând raportul Sitemaps.
De regulă, Google va accesa cu crawlere adresele URL în sitemap-uri mai des decât altele. Dar chiar dacă un mic procent de adrese URL din sitemap-ul dvs. este de calitate scăzută, acesta poate descuraja Googlebot să-l folosească pentru sugestii de accesare cu crawlere.
Sitemapurile și linkurile XML adaugă adrese URL la coada obișnuită de accesare cu crawlere. Există, de asemenea, o coadă de acces cu crawlere prioritară, pentru care există două metode de introducere.
În primul rând, pentru cei cu postări de locuri de muncă sau videoclipuri live, puteți trimite adrese URL către API-ul de indexare Google.
Sau, dacă doriți să atrageți atenția Microsoft Bing sau Yandex, puteți utiliza API-ul IndexNow pentru orice adresă URL. Cu toate acestea, în propriile mele teste, a avut un impact limitat asupra accesării cu crawlere a adreselor URL. Deci, dacă utilizați IndexNow, asigurați-vă că monitorizați eficacitatea accesării cu crawlere pentru Bingbot.
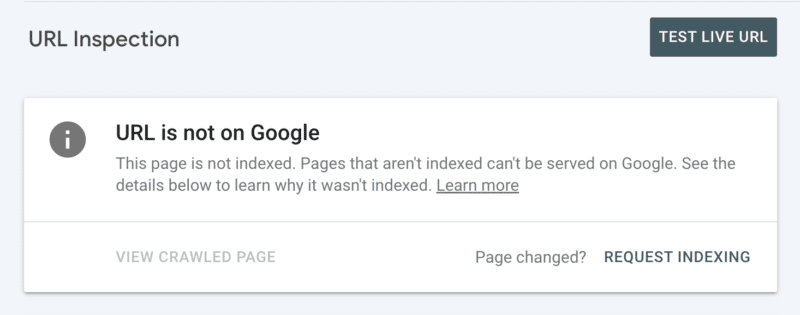
În al doilea rând, puteți solicita manual indexarea după ce ați inspectat adresa URL în Search Console. Deși rețineți că există o cotă zilnică de 10 adrese URL și accesarea cu crawlere poate dura încă câteva ore. Cel mai bine este să vedeți acest lucru ca pe un patch temporar în timp ce săpați pentru a descoperi rădăcina problemei dvs. de crawling.
Cum să verificați dacă Googlebot face ghiduri esențiale pentru accesarea cu crawlere
În Google Search Console, harta site-ului dvs. XML arată starea „Succes” și a fost citită recent.
5. Spune-i păianjenilor motoarelor de căutare ce să nu acceseze cu crawlere
Unele pagini pot fi importante pentru utilizatori sau pentru funcționalitatea site-ului, dar nu doriți să apară în rezultatele căutării. Preveniți astfel de rute URL să distragă atenția crawlerelor cu un robots.txt interzis. Aceasta ar putea include:
- API-uri și CDN-uri . De exemplu, dacă sunteți client al Cloudflare, asigurați-vă că nu permiteți folderul /cdn-cgi/ care este adăugat pe site-ul dvs.
- Imagini, scripturi sau fișiere de stil neimportante , dacă paginile încărcate fără aceste resurse nu sunt afectate semnificativ de pierdere.
- Pagina funcțională , cum ar fi un coș de cumpărături.
- Spații infinite , cum ar fi cele create de paginile calendarului.
- Pagini de parametri . În special cei de la navigarea cu fațete care filtrează (de exemplu, ?price-range=20-50), reordonează (de exemplu, ?sort=) sau caută (de exemplu, ?q=), deoarece fiecare combinație este contorizată de crawler-uri ca o pagină separată.
Aveți grijă să nu blocați complet parametrul de paginare. Paginarea accesabilă cu crawlere până la un punct este adesea esențială pentru ca Googlebot să descopere conținut și să proceseze linkurile interne. (Consultați acest webinar Semrush despre paginare pentru a afla mai multe detalii despre motivul.)
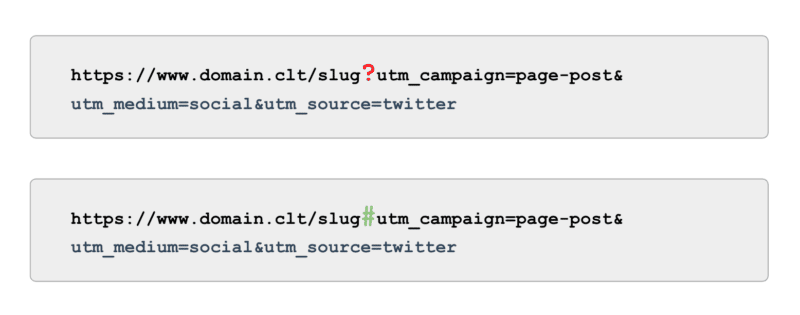
Și când vine vorba de urmărire, în loc să utilizați etichete UTM alimentate de parametri (alias, „?”), utilizați ancore (alias, „#”). Oferă aceleași beneficii de raportare în Google Analytics fără a fi accesat cu crawlere.
Cum să verificați dacă Googlebot nu accesați ghidul cu crawlere
Examinați eșantionul de adrese URL „indexate, netrimise în sitemap” în Google Search Console. Ignorând primele pagini de paginare, ce alte căi găsiți? Ar trebui să fie incluse într-un sitemap XML, blocate de a fi accesate cu crawlere sau lăsate să fie?
De asemenea, examinați lista „Descoperit – momentan neindexat” – blocând în robots.txt orice căi URL care oferă o valoare mică sau deloc pentru Google.
Pentru a trece acest lucru la nivelul următor, examinați toate accesările cu crawlere ale smartphone-urilor Googlebot în fișierele jurnal ale serverului pentru căi fără valoare.
6. Creați linkuri relevante
Backlink-urile către o pagină sunt valoroase pentru multe aspecte ale SEO, iar crawling-ul nu face excepție. Dar linkurile externe pot fi dificil de obținut pentru anumite tipuri de pagini. De exemplu, pagini profunde precum produse, categorii de la nivelurile inferioare din arhitectura site-ului sau chiar articole.
Pe de altă parte, link-urile interne relevante sunt:
- Scalabil tehnic.
- Semnale puternice către Googlebot pentru a acorda prioritate unei pagini pentru accesare cu crawlere.
- Deosebit de impact pentru accesarea cu crawlere profundă a paginilor.
Pesmeturile, blocurile de conținut aferente, filtrele rapide și utilizarea etichetelor bine îngrijite sunt toate un beneficiu semnificativ pentru eficacitatea accesării cu crawlere. Deoarece sunt conținut esențial pentru SEO, asigurați-vă că astfel de linkuri interne nu depind de JavaScript, ci mai degrabă utilizați un link <a> standard, care poate fi accesat cu crawlere.
Ținând cont de astfel de legături interne, ar trebui, de asemenea, să adauge valoare reală pentru utilizator.
Cum să verificați pentru link-uri relevante
Rulați o accesare manuală a site-ului dvs. complet cu un instrument precum păianjenul SEO al lui ScreamingFrog, căutând:
- URL-uri orfane.
- Link-uri interne blocate de robots.txt.
- Link-uri interne către orice cod de stare non-200.
- Procentul de adrese URL neindexabile conectate intern.
7. Auditați problemele de crawling rămase
Dacă toate optimizările de mai sus sunt finalizate și eficacitatea accesării cu crawlere rămâne suboptimă, efectuați un audit profund.
Începeți prin a examina exemplele de excluderi rămase din Google Search Console pentru a identifica problemele de accesare cu crawlere.
Odată ce acestea sunt abordate, mergeți mai profund utilizând un instrument manual de accesare cu crawlere pentru a accesa cu crawlere toate paginile din structura site-ului, așa cum ar face Googlebot. Faceți referințe încrucișate cu fișierele jurnal restrânse la IP-uri Googlebot pentru a înțelege care dintre acele pagini sunt și nu sunt accesate cu crawlere.
În cele din urmă, lansați în analiza fișierului jurnal restrâns la IP-ul Googlebot pentru cel puțin patru săptămâni de date, ideal mai multe.
Dacă nu sunteți familiarizat cu formatul fișierelor jurnal, utilizați un instrument de analiză a jurnalelor. În cele din urmă, aceasta este cea mai bună sursă pentru a înțelege cum accesează Google site-ul cu crawlere.
Odată ce auditul dvs. este finalizat și aveți o listă a problemelor de accesare cu crawlere identificate, clasificați fiecare problemă după nivelul de efort așteptat și impactul asupra performanței.
Notă : Alți experți SEO au menționat că clicurile din SERP-uri cresc accesarea cu crawlere a adresei URL a paginii de destinație. Cu toate acestea, încă nu am putut confirma acest lucru prin testare.
Prioritizează eficacitatea accesării cu crawlere față de bugetul de accesare cu crawlere
Scopul accesării cu crawlere nu este acela de a obține cea mai mare cantitate de accesare cu crawlere și nici de a avea fiecare pagină a unui site web accesată cu crawlere în mod repetat, ci este de a atrage un acces cu crawlere de conținut relevant pentru SEO cât mai aproape de momentul în care o pagină este creată sau actualizată.
În general, bugetele nu contează. Contează ceea ce investești.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.