
Un ghid pentru diagnosticarea problemelor comune JavaScript SEO
Publicat: 2023-07-10Să fim sinceri, JavaScript și SEO nu joacă întotdeauna frumos împreună. Pentru unii SEO, subiectul poate avea impresia că este învăluit într-un văl de complexitate.
Ei bine, vești bune: atunci când îndepărtați straturile, multe probleme SEO bazate pe JavaScript revin la fundamentele modului în care crawlerele motoarelor de căutare interacționează cu JavaScript, în primul rând.
Așadar, dacă înțelegeți aceste elemente fundamentale, puteți explora problemele, puteți înțelege impactul lor și puteți lucra cu dezvoltatorii pentru a le rezolva pe cele care contează.
În acest articol, vom ajuta la diagnosticarea unor probleme comune atunci când site-urile sunt construite pe cadre JS. În plus, vom descompune cunoștințele de bază de care fiecare SEO tehnic are nevoie când vine vorba de randare.
Redare pe scurt
Înainte de a trece la chestii mai granulare, să vorbim de ansamblu.
Pentru ca un motor de căutare să înțeleagă conținutul care este alimentat de JavaScript, trebuie să acceseze cu crawlere și să redea pagina.
Problema este că motoarele de căutare au doar atât de multe resurse de folosit, așa că trebuie să fie selective când merită să le folosească. Nu este un dat că o pagină va fi randată, chiar dacă crawler-ul o trimite la coada de randare.
Dacă alege să nu randeze pagina sau nu poate reda conținutul corect, ar putea fi o problemă.
Se reduce la modul în care front-end-ul servește HTML în răspunsul inițial al serverului.
Când o adresă URL este construită în browser, un front-end precum React, Vue sau Gatsby va genera codul HTML pentru pagină. Un crawler verifică dacă acel HTML este deja disponibil de pe server (HTML „pre-rendat”) înainte de a trimite adresa URL pentru a aștepta randarea, astfel încât să poată privi conținutul rezultat.
Dacă este disponibil vreun HTML pre-rendat, depinde de modul în care este configurat front-end-ul. Acesta va genera codul HTML prin server sau în browserul clientului.
Redare pe partea serverului
Numele spune totul. Într-o configurare SSR, crawler-ul este alimentat cu o pagină HTML redată complet fără a necesita execuție și randare JS suplimentare.
Deci, chiar dacă pagina nu este redată, motorul de căutare poate accesa cu crawlere orice HTML, poate contextualiza pagina (metadate, copie, imagini) și poate înțelege relația acesteia cu alte pagini (breadcrumbs, URL canonic, link-uri interne).
Redare pe partea clientului
În CSR, HTML-ul este generat în browser împreună cu toate componentele JavaScript. JavaScript necesită randare înainte ca HTML să fie disponibil pentru accesare cu crawlere.
Dacă serviciul de randare alege să nu redeze o pagină trimisă la coadă, copia, adresele URL interne, linkurile de imagini și chiar metadatele rămân indisponibile crawlerelor.
Drept urmare, motoarele de căutare au puțin sau deloc context pentru a înțelege relevanța unei adrese URL pentru interogările de căutare.
Notă : poate exista o combinație de HTML care este difuzată în răspunsul HTML inițial, precum și HTML care necesită executarea JS pentru a se randa (apare). Depinde de mai mulți factori, dintre care cei mai obișnuiți includ cadrul, modul în care sunt construite componentele individuale ale site-ului și configurația serverului.
Setul de instrumente JavaScript SEO
Există cu siguranță instrumente care vor ajuta la identificarea problemelor SEO legate de JavaScript.
Puteți face o mare parte din investigație folosind instrumentele browserului și Google Search Console. Iată lista scurtă care alcătuiește un set de instrumente solid:
- Vizualizați sursa: faceți clic dreapta pe o pagină și faceți clic pe „vezi sursa” pentru a vedea HTML-ul pre-rendat al paginii (răspunsul inițial al serverului).
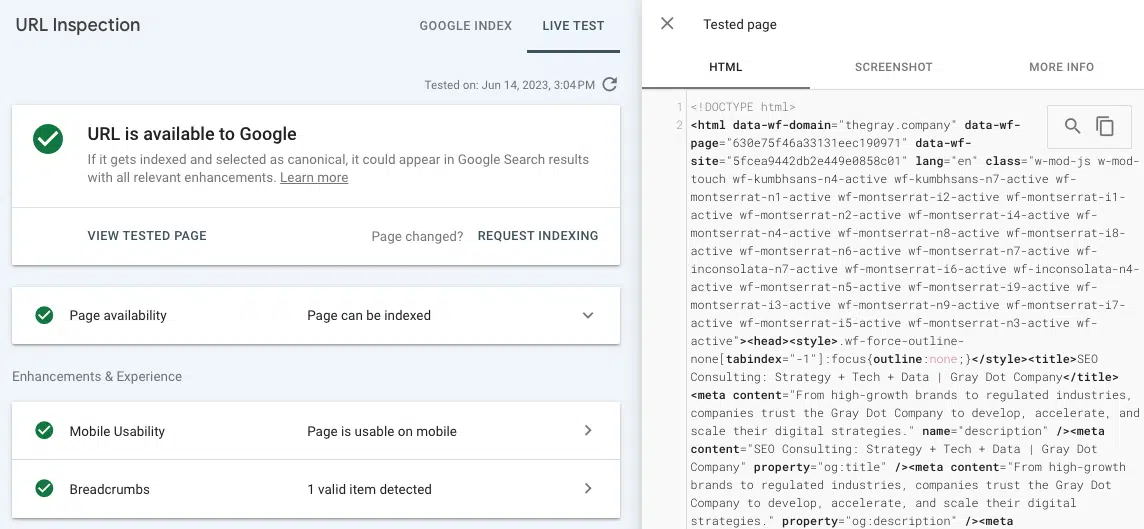
- Testați adresa URL live (inspecție URL): vizualizați o captură de ecran, HTML și alte detalii importante ale unei pagini redate în fila de inspecție URL din Google Search Console. (Multe probleme de randare pot fi găsite comparând HTML-ul pre-ratat din „vizualizare sursă” cu HTML-ul redat de la testarea URL-ului live în GSC.)
- Instrumente pentru dezvoltatori Chrome: faceți clic dreapta pe o pagină și alegeți „Inspectați” pentru a deschide instrumente pentru vizualizarea erorilor JavaScript și multe altele.
- Wappalyzer: vedeți stiva pe care este construit orice site și căutați informații specifice cadrului, instalând această extensie Chrome gratuită.
Probleme comune de SEO JavaScript
Problema 1: HTML-ul pre-rendat este indisponibil la nivel universal
Pe lângă implicațiile negative pentru crawling și contextualizare menționate mai devreme, există și problema timpului și a resurselor de care ar putea fi nevoie un motor de căutare pentru a reda o pagină.
Dacă crawler-ul alege să treacă o adresă URL prin procesul de randare, aceasta va ajunge în coada de randare. Acest lucru se întâmplă deoarece un crawler poate detecta o diferență între structura HTML redată anterior și cea redată. (Ceea ce are foarte mult sens dacă nu există HTML pre-rendat!)
Nu există nicio garanție privind cât timp așteaptă o adresă URL pentru serviciul de redare web. Cea mai bună modalitate de a influența WRS-ul la randarea în timp util este să vă asigurați că există semnale de autoritate cheie la fața locului care ilustrează importanța unei adrese URL (de exemplu, legată în partea de sus a navigației, multe link-uri interne, denumite canonice). Acest lucru devine puțin complicat, deoarece semnalele de autoritate trebuie să fie, de asemenea, accesate cu crawlere.
În Google Search Console, este posibil să vă dați o idee dacă trimiteți semnalele de autoritate potrivite paginilor cheie sau dacă le determinați să rămână în limbo.
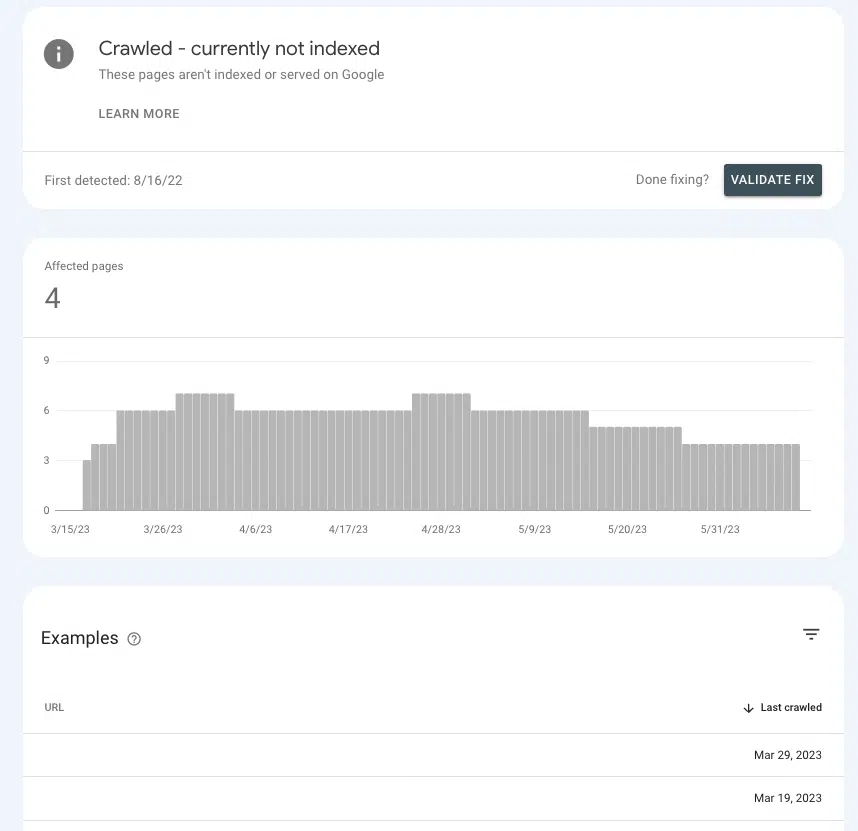
Accesați Pagini > Indexare pagini > Accesat cu crawlere – momentan nu este indexat și căutați prezența paginilor prioritare în listă.
Dacă se află în sala de așteptare, este pentru că Google nu poate stabili dacă sunt suficient de importante pentru a cheltui resurse.
Cauze comune
Setări implicite
Cele mai populare front-end-uri sunt „din cutie” setate la randarea pe partea clientului, deci există o șansă destul de bună ca setările implicite să fie vinovate.
Dacă vă întrebați de ce majoritatea front-end-urilor implicit la CSR, este din cauza beneficiilor de performanță. Dezvoltatorii nu iubesc întotdeauna SSR, deoarece poate limita posibilitățile de accelerare a unui site și de implementare a anumitor elemente interactive (de exemplu, tranziții unice între pagini).
Aplicație cu o singură pagină
Dacă un site este o aplicație cu o singură pagină, este împachetat în întregime în JavaScript și generează toate componentele unei pagini în browser (alias totul) este redat pe partea clientului și paginile noi sunt difuzate fără reîncărcare).
Acest lucru are unele implicații negative, dintre care poate cea mai importantă este că paginile sunt potențial de nedescoperit.
Acest lucru nu înseamnă că este imposibil să configurați un SPA într-un mod mai prietenos cu SEO. Dar șansele sunt că va fi nevoie de o muncă de dezvoltare semnificativă pentru ca acest lucru să se întâmple.
Problema 2: Unele conținut ale paginii sunt inaccesibile crawlerelor
A obține un motor de căutare pentru a reda o adresă URL este grozav, doar atâta timp cât toate elementele sunt disponibile pentru accesare cu crawlere. Ce se întâmplă dacă redă pagina, dar există secțiuni ale unei pagini care nu sunt accesibile?
De exemplu, un SEO face o analiză a link-urilor interne și găsește puține sau deloc link-uri interne raportate pentru o adresă URL legată de mai multe pagini.
Dacă linkul nu apare în HTML redat din instrumentul Test Live URL, atunci este probabil să fie difuzat în resurse JavaScript pe care Google nu le poate accesa.
Pentru a restrânge vinovatul, ar fi o idee bună să căutați punctele comune în ceea ce privește locul în care conținutul paginii lipsă sau linkurile interne se află pe pagină între adrese URL.
De exemplu, dacă este un link cu întrebări frecvente care apare în aceeași secțiune a fiecărei pagini de produs, acesta ajută în mare măsură dezvoltatorii să restrângă o soluție.
Cauze comune
Erori JavaScript
Să începem cu o declinare a răspunderii aici. Majoritatea erorilor JavaScript pe care le întâlniți nu contează pentru SEO.
Deci, dacă mergi în căutarea erorilor, duci o listă lungă dezvoltatorului tău și începi conversația cu „Care sunt toate aceste erori?”, s-ar putea să nu o primească atât de bine.
Abordați cu „de ce” vorbind despre problemă, astfel încât ei să poată fi expert în JavaScript (pentru că sunt!).
Acestea fiind spuse, există erori de sintaxă care ar putea face restul paginii imposibil de analizat (de exemplu, „blocarea randării”). Când se întâmplă acest lucru, dispozitivul de redare nu poate sparge elementele HTML individuale, nu poate structura conținutul în DOM sau nu poate înțelege relațiile.
În general, aceste tipuri de erori sunt recunoscute deoarece au un fel de efect și în vizualizarea browserului.
Pe lângă confirmarea vizuală, este posibil să vedeți erori JavaScript făcând clic dreapta pe pagină, alegând „inspectați” și navigând la fila „Consolă”.
Obțineți buletinele informative zilnice pe care se bazează marketerii.
Vezi termenii.
Conținutul necesită o interacțiune cu utilizatorul
Unul dintre cele mai importante lucruri de reținut despre randare este că Google nu poate reda niciun conținut care impune utilizatorilor să interacționeze cu pagina. Sau, pentru a spune mai simplu, nu poate „face clic” pe lucruri.

De ce contează asta? Gândiți-vă la vechiul nostru prieten de încredere, la meniul drop-down acordeon și la câte site-uri îl folosesc pentru organizarea conținutului, cum ar fi detalii despre produse și întrebări frecvente.
În funcție de modul în care este codificat acordeonul, este posibil ca Google să nu poată reda conținutul din meniul drop-down dacă nu se completează până când JS nu se execută.
Pentru a verifica, puteți „Inspecta” o pagină și puteți vedea dacă conținutul „ascuns” (ceea ce se afișează odată ce faceți clic pe un acordeon) este în HTML.
Dacă nu este, înseamnă că Googlebot și alte crawler-uri nu văd acest conținut în versiunea redată a paginii.
Problema 3: secțiunile unui site nu sunt accesate cu crawlere
Google poate să vă redeze sau nu pagina dacă o accesează cu crawlere și o trimite la coadă. Dacă nu accesează cu crawlere pagina, chiar și acea oportunitate nu este disponibilă.
Pentru a înțelege dacă Google accesează cu crawlere pagini, raportul Statistici de accesare cu crawlere poate fi util Setări > Statistici de accesare cu crawlere .
Selectați Solicitări de accesare cu crawlere: OK (200) pentru a vedea toate cazurile de accesare cu crawlere a 200 de pagini de stare din ultimele trei luni. Apoi, utilizați filtrarea pentru a căuta adrese URL individuale sau directoare întregi.
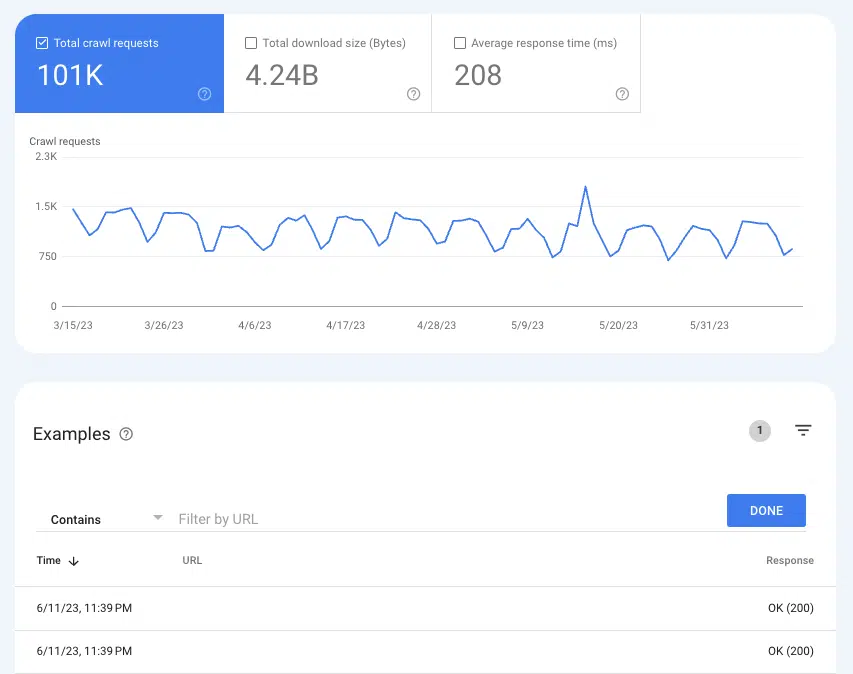
Dacă adresele URL nu apar în jurnalele de accesare cu crawlere, există șanse mari ca Google să nu poată descoperi paginile și să le acceseze cu crawlere (sau nu au 200 de pagini, ceea ce este o problemă cu totul diferită).
Cauze comune
Link-urile interne nu pot fi accesate cu crawlere
Legăturile sunt semnele rutiere pe care le urmează crawlerii către pagini noi. Acesta este unul dintre motivele pentru care paginile orfane sunt o problemă atât de mare.
Dacă aveți un site bine conectat și vedeți pagini orfane care apar în auditurile site-ului dvs., există șanse mari să fie pentru că linkurile nu sunt disponibile în HTML-ul pre-radat.
O modalitate ușoară de a verifica este să accesați o adresă URL care trimite la pagina orfană raportată. Faceți clic dreapta pe pagină și faceți clic pe „Afișați sursa”.
Apoi, utilizați CMD + f pentru a căuta adresa URL a paginii orfane. Dacă nu apare în HTML-ul pre-ratat, dar apare pe pagină când este redat în browser, treceți mai departe la ediția patru.
Harta site-ului XML nu a fost actualizată
Harta site-ului XML este esențială pentru a ajuta Google să descopere pagini noi și să înțeleagă ce adrese URL să acorde prioritate într-o accesare cu crawlere.
Fără harta site-ului XML, descoperirea paginii este posibilă numai prin următoarele link-uri.
Deci, pentru site-urile fără HTML pre-rendat, o hartă a site-ului învechită sau lipsă înseamnă așteptarea ca Google să redea pagini, să urmeze link-uri interne către alte pagini, să le pună în coadă, să le reda, să le urmeze linkurile și așa mai departe.
În funcție de front-end-ul pe care îl utilizați, este posibil să aveți acces la pluginuri care pot crea sitemap-uri XML dinamice.
Adesea au nevoie de personalizare, așa că este important ca SEO-urile să documenteze cu sârguință orice URL-uri care nu ar trebui să fie în harta site-ului și logica de ce este aceasta.
Acest lucru ar trebui să fie relativ ușor de verificat prin rularea sitemap-ului prin instrumentul tău SEO preferat.
Problema 4: legăturile interne lipsesc
Indisponibilitatea legăturilor interne către crawler-uri nu este doar o potențială problemă de descoperire, este și o problemă de capital. Deoarece linkurile trec egalitatea SEO de la adresa URL de referință la adresa URL țintă, ele sunt un factor important în creșterea autorității atât a paginii, cât și a domeniului.
Link-urile de pe pagina de start sunt un exemplu grozav. În general, este cea mai autorizată pagină de pe un site web, așa că un link către o altă pagină de pe pagina de pornire are o mare greutate.
Dacă acele linkuri nu pot fi accesate cu crawlere, atunci este un pic ca și cum ai avea o sabie laser spartă. Unul dintre cele mai puternice instrumente ale tale devine inutil (joc de cuvinte).
Cauze comune
Este necesară interacțiunea cu utilizatorul pentru a ajunge la link
Exemplul de acordeon pe care l-am folosit mai devreme este doar un exemplu în care conținutul este ascuns în spatele unei interacțiuni a utilizatorului. Un altul care poate avea implicații pe scară largă este paginarea derulării infinite – mai ales pentru site-urile de comerț electronic cu cataloage substanțiale de produse.
Într-o configurație de defilare infinită, nenumărate produse de pe o pagină de listare de produse (categorie) nu se vor încărca decât dacă un utilizator derulează dincolo de un anumit punct (încărcare leneșă) sau atinge butonul „afișați mai multe”.
Deci, chiar dacă JavaScript este redat, un crawler nu poate accesa link-urile interne pentru produsele care urmează să fie încărcate. Cu toate acestea, încărcarea tuturor acestor produse pe o singură pagină ar avea un impact negativ asupra experienței utilizatorului din cauza performanței slabe a paginii.
Acesta este motivul pentru care SEO preferă, în general, paginarea adevărată, în care fiecare pagină de rezultate are o adresă URL distinctă, accesabilă cu crawlere.
Deși există modalități prin care un site poate optimiza încărcarea leneșă și adăuga toate produsele la HTML-ul pre-randat, acest lucru ar duce la diferențe între HTML-ul redat și HTML-ul pre-ratat.
În mod efectiv, acest lucru creează un motiv pentru a trimite mai multe pagini la coada de randare și pentru a face crawlerele să lucreze mai mult decât trebuie - și știm că nu este grozav pentru SEO.
Urmați cel puțin recomandările Google pentru optimizarea derulării infinite.
Link-urile nu au fost codificate corect
Când Google accesează cu crawlere un site sau redă o adresă URL în coadă, descarcă o versiune fără stat a unei pagini. Acesta este o mare parte din motivul pentru care este atât de important să folosiți etichete href și ancore adecvate (structura de legătură pe care o vedeți cel mai des). Un crawler nu poate urmări formate de link precum router, span sau onClick.
Poate urma:
- <a href="https://example.com">
- <a href="/relative/path/file">
Nu pot urmări:
- <a routerLink="some/path">
- <span href="https://example.com">
- <a>
Pentru scopurile unui dezvoltator, toate acestea sunt modalități valide de a codifica link-urile. Implicațiile SEO sunt un strat suplimentar de context și nu este treaba lor să știe, ci SEO-ul.
O parte uriașă a muncii unui SEO bun este de a oferi dezvoltatorilor acel context prin documentare.
Problema 5: Metadatele lipsesc
Într-o pagină HTML, metadate precum titlul, descrierea, adresa URL canonică și eticheta meta roboti sunt toate imbricate în cap.
Din motive evidente, lipsa metadatelor este dăunătoare pentru SEO, dar cu atât mai mult pentru SPA-uri. Elemente precum o adresă URL canonică cu auto-referință sunt cruciale pentru îmbunătățirea șanselor ca o pagină JS să treacă cu succes în coada de randare.
Dintre toate elementele care ar trebui să fie prezente în HTML-ul pre-rendat, capul este cel mai important pentru indexare.
Din fericire, această problemă este destul de ușor de depistat, deoarece va declanșa o mulțime de erori pentru metadatele lipsă în orice instrument SEO îl folosește un site pentru raportarea de igienă. Apoi, puteți confirma căutând capul în codul sursă.
Cauze comune
Lipsa vehiculului metadate sau configurat greșit
Într-un cadru JS, un plugin creează capul și inserează metadatele în cap. (Cel mai popular exemplu este React Helmet.) Chiar dacă un plugin este deja instalat, acesta trebuie de obicei configurat corect.
Din nou, acesta este un domeniu în care tot ceea ce pot face SEO este să aducă problema dezvoltatorului, să explice de ce și să lucreze îndeaproape pentru a stabili criterii de acceptare bine documentate.
Problema 6: Resursele nu sunt accesate cu crawlere
Fișierele de script și imaginile sunt elemente de bază esențiale în procesul de randare.
Deoarece au și propriile lor adrese URL, legile privind accesarea cu crawlere se aplică și acestora. Dacă fișierele sunt blocate de accesare cu crawlere, Google nu poate analiza pagina pentru a o reda.
Pentru a vedea dacă adresele URL sunt accesate cu crawlere, puteți vedea solicitările anterioare în Statisticile de accesare cu crawlere GSC.
- Imagini: accesați Setări > Statistici de accesare cu crawlere > Solicitări de accesare cu crawlere: imagine
- JavaScript: accesați Setări > Statistici de accesare cu crawlere > Solicitări de accesare cu crawlere: imagine
Cauze comune
Director blocat de robots.txt
Atât adresele URL ale scriptului, cât și cele ale imaginii se încadrează, în general, în propriul subdomeniu sau subdosar dedicat, astfel încât o expresie interzisă în robots.txt va împiedica accesarea cu crawlere.
Unele instrumente SEO vă vor spune dacă orice fișier script sau imagine este blocat, dar problema este destul de ușor de identificat dacă știți unde sunt imbricate imaginile și fișierele script. Puteți căuta acele structuri URL în robots.txt.
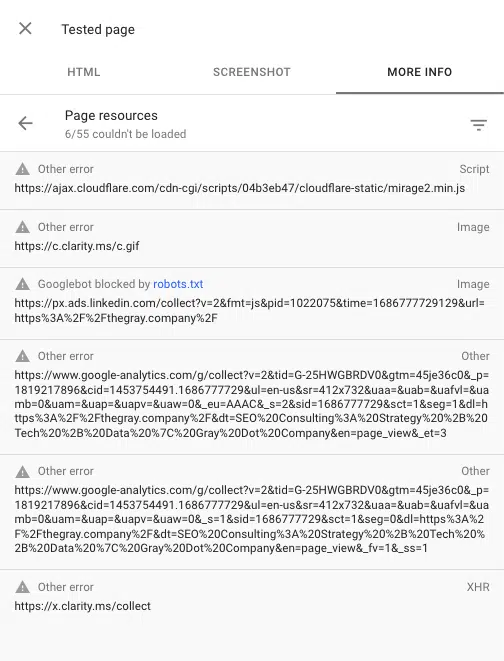
De asemenea, puteți vedea orice scripturi blocate atunci când redați o pagină utilizând instrumentul de inspecție URL din Google Search Console. „Testați adresa URL live”, apoi accesați Vizualizare pagina testată > Mai multe informații > Resurse paginii .
Aici puteți vedea orice scripturi care nu se încarcă în timpul procesului de randare. Dacă un fișier este blocat de robots.txt, acesta va fi marcat ca atare.
Fă-ți prieteni cu JavaScript
Da, JavaScript poate veni cu unele probleme de SEO. Dar pe măsură ce SEO evoluează, cele mai bune practici devin sinonime cu o experiență excelentă pentru utilizator.
O experiență excelentă a utilizatorului depinde adesea de JavaScript. Așadar, deși misiunea unui SEO nu este să codifice JavaScript, trebuie să știm cum interacționează, redă și utilizează motoarele de căutare cu acesta.
Cu o înțelegere solidă a procesului de randare și unele probleme comune de SEO în cadrele JS, sunteți pe cale de a identifica problemele și de a fi un aliat puternic pentru dezvoltatorii dvs.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.