
Entity SEO: Ghidul definitiv
Publicat: 2023-04-06Acest articol a fost co-autor de Andrew Ansley .
Lucruri, nu șiruri. Dacă nu ați auzit asta până acum, vine dintr-o postare celebră pe blogul Google care a anunțat Knowledge Graph.
Cea de-a 11-a aniversare a anunțului este la doar o lună, dar mulți încă se luptă să înțeleagă ce înseamnă cu adevărat „lucruri, nu șiruri” pentru SEO.
Citatul este o încercare de a transmite că Google înțelege lucrurile și nu mai este un simplu algoritm de detectare a cuvintelor cheie.
În mai 2012, s-ar putea argumenta că s-a născut entitatea SEO. Învățarea automată de la Google, ajutată de baze de cunoștințe semi-structurate și structurate, ar putea înțelege semnificația din spatele unui cuvânt cheie.
Natura ambiguă a limbajului a avut în sfârșit o soluție pe termen lung.
Deci, dacă entitățile au fost importante pentru Google de peste un deceniu, de ce SEO sunt încă confuzi cu privire la entități?
Buna intrebare. Văd patru motive:
- Entitatea SEO ca termen nu a fost folosit suficient de larg pentru ca SEO să se simtă confortabil cu definiția sa și, prin urmare, să o încorporeze în vocabularul lor.
- Optimizarea pentru entități se suprapune foarte mult cu vechile metode de optimizare centrate pe cuvinte cheie. Ca rezultat, entitățile sunt combinate cu cuvinte cheie. În plus, nu era clar modul în care entitățile au jucat un rol în SEO, iar cuvântul „entități” este uneori interschimbabil cu „subiecte” atunci când Google vorbește despre acest subiect.
- Înțelegerea entităților este o sarcină plictisitoare. Dacă doriți cunoaștere profundă a entităților, va trebui să citiți câteva brevete Google și să cunoașteți elementele de bază ale învățării automate. Entity SEO este o abordare mult mai științifică a SEO - iar știința pur și simplu nu este pentru toată lumea.
- În timp ce YouTube a afectat masiv distribuirea cunoștințelor, a aplatizat experiența de învățare pentru multe materii. Creatorii cu cel mai mare succes pe platformă au parcurs din trecut calea ușoară atunci când își educă publicul. Drept urmare, creatorii de conținut nu au petrecut mult timp pe entități până de curând. Din acest motiv, trebuie să înveți despre entități de la cercetătorii NLP și apoi trebuie să aplici cunoștințele la SEO. Brevetele și lucrările de cercetare sunt esențiale. Încă o dată, acest lucru întărește primul punct de mai sus.
Acest articol este o soluție pentru toate cele patru probleme care i-au împiedicat pe SEO să stăpânească pe deplin o abordare bazată pe entitate a SEO.
Citind aceasta, veți învăța:
- Ce este o entitate și de ce este importantă.
- Istoria căutării semantice.
- Cum se identifică și se utilizează entitățile din SERP.
- Cum să folosiți entitățile pentru a clasifica conținutul web.
De ce sunt importante entitățile?
Entitatea SEO este viitorul în care se îndreaptă motoarele de căutare în ceea ce privește alegerea conținutului pe care să-l clasifice și determinarea sensului acestuia.
Combină acest lucru cu încrederea bazată pe cunoștințe și cred că SEO entității va fi viitorul modului în care se realizează SEO în următorii doi ani.
Exemple de entități
Deci, cum recunoașteți o entitate?
SERP are mai multe exemple de entități pe care probabil le-ați văzut.
Cele mai comune tipuri de entități sunt legate de locații, persoane sau afaceri.
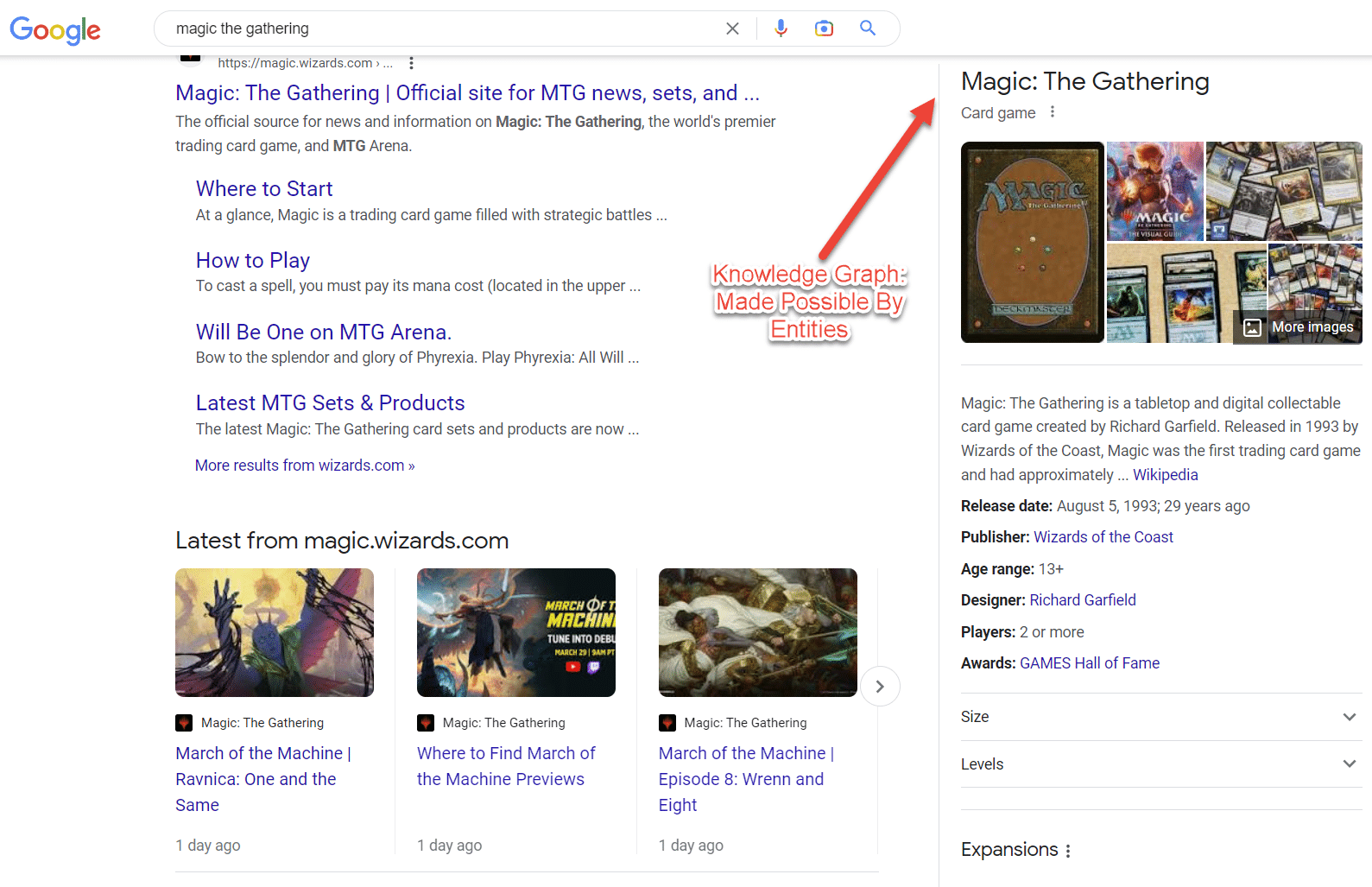
Poate cel mai bun exemplu de entități din SERP sunt clusterele de intenții. Cu cât un subiect este înțeles mai mult, cu atât mai mult apar aceste caracteristici de căutare.
Destul de interesant, o singură campanie SEO poate modifica fața SERP atunci când știți cum să executați campanii SEO centrate pe entitate.
Intrările Wikipedia sunt un alt exemplu de entități. Wikipedia oferă un exemplu excelent de informații asociate entităților.
După cum puteți vedea din stânga sus, entitatea are tot felul de atribute asociate cu „peștele”, variind de la anatomia sa până la importanța sa pentru oameni.
Deși Wikipedia conține multe date despre un subiect, nu este deloc exhaustivă.
Ce este o entitate?
O entitate este un obiect sau un lucru identificabil în mod unic, caracterizat prin numele (numele), tipul (tipurile), atributele și relațiile cu alte entități. Se consideră că o entitate există doar atunci când există într-un catalog de entități.
Cataloagele de entități atribuie un ID unic fiecărei entități. Agenția mea are soluții programatice care folosesc ID-ul unic asociat fiecărei entitati (serviciile, produsele și mărcile sunt toate incluse).
Dacă un cuvânt sau o expresie nu se află într-un catalog existent, aceasta nu înseamnă că cuvântul sau expresia nu este o entitate, dar de obicei puteți ști dacă ceva este o entitate prin existența sa în catalog.
Este important de remarcat că Wikipedia nu este factorul decisiv pentru a stabili dacă ceva este o entitate, dar compania este cea mai cunoscută pentru baza de date a entităților.
Orice catalog poate fi folosit atunci când vorbim despre entități. De obicei, o entitate este o persoană, un loc sau un lucru, dar pot fi incluse și idei și concepte.
Câteva exemple de cataloage de entități includ:
- Wikipedia
- Wikidata
- DBpedia
- Freebase
- Yago

Entitățile ajută la reducerea decalajului dintre lumea datelor nestructurate și structurate.
Ele pot fi folosite pentru a îmbogăți semantic textul nestructurat, în timp ce sursele textuale pot fi utilizate pentru a popula bazele de cunoștințe structurate.
Recunoașterea mențiunilor entităților în text și asocierea acestor mențiuni cu intrările corespunzătoare dintr-o bază de cunoștințe este cunoscută ca sarcina de legare a entităților.
Entitățile permit o mai bună înțelegere a sensului textului, atât pentru oameni, cât și pentru mașini.
În timp ce oamenii pot rezolva relativ ușor ambiguitatea entităților pe baza contextului în care sunt menționate, acest lucru prezintă multe dificultăți și provocări pentru mașini.
Intrarea din baza de cunoștințe a unei entități rezumă ceea ce știm despre acea entitate.
Pe măsură ce lumea se schimbă constant, la fel ies la suprafață fapte noi. A ține pasul cu aceste schimbări necesită un efort continuu din partea editorilor și managerilor de conținut. Aceasta este o sarcină solicitantă la scară.
Prin analizarea conținutului documentelor în care sunt menționate entitățile, procesul de găsire a unor fapte noi sau care necesită actualizare poate fi susținut sau chiar complet automatizat.
Oamenii de știință se referă la aceasta ca fiind problema populației bazei de cunoștințe, motiv pentru care este importantă legătura dintre entități.
Entitățile facilitează o înțelegere semantică a nevoii de informații ale utilizatorului, așa cum este exprimată prin interogarea cuvântului cheie și a conținutului documentului. Astfel, entitățile pot fi utilizate pentru a îmbunătăți interogările și/sau reprezentările documentelor.
În lucrarea de cercetare Extended Named Entity, autorul identifică aproximativ 160 de tipuri de entități. Iată două dintre cele șapte capturi de ecran din listă.


Anumite categorii de entități sunt mai ușor de definit, dar este important să ne amintim că conceptele și ideile sunt entități. Aceste două categorii sunt foarte greu de scalat pentru Google pe cont propriu.
Nu poți învăța Google doar cu o singură pagină când lucrezi cu concepte vagi. Înțelegerea entității necesită multe articole și multe referințe susținute în timp.
Istoricul Google cu entități
Pe 16 iulie 2010, Google a achiziționat Freebase. Această achiziție a fost primul pas major care a condus la actualul sistem de căutare a entităților.

După ce a investit în Freebase, Google și-a dat seama că Wikidata are o soluție mai bună. Google a lucrat apoi pentru a îmbina Freebase în Wikidata, o sarcină care a fost mult mai dificilă decât se aștepta.
Cinci oameni de știință Google au scris o lucrare intitulată „De la Freebase la Wikidata: Marea Migrație”. Printre articolele cheie includ.
„Freebase este construit pe noțiunile de obiecte, fapte, tipuri și proprietăți. Fiecare obiect Freebase are un identificator stabil numit „mid” (pentru Machine ID).”
„Modelul de date al Wikidata se bazează pe noțiunile de item și declarație. Un articol reprezintă o entitate, are un identificator stabil numit „qid” și poate avea etichete, descrieri și aliasuri în mai multe limbi; declarații suplimentare și link-uri către pagini despre entitate în alte proiecte Wikimedia – cel mai important Wikipedia. Spre deosebire de Freebase, declarațiile Wikidata nu urmăresc să codifice fapte adevărate, ci afirmații din surse diferite, care se pot contrazice și unele pe altele...”
Entitățile sunt definite în aceste baze de cunoștințe, dar Google a trebuit să-și construiască cunoștințele despre entități pentru date nestructurate (adică, bloguri).
Google a colaborat cu Bing și Yahoo și a creat Schema.org pentru a îndeplini această sarcină.
Google oferă instrucțiuni de schemă, astfel încât managerii de site-uri web să aibă instrumente care ajută Google să înțeleagă conținutul. Amintiți-vă, Google vrea să se concentreze pe lucruri, nu pe șiruri.
În cuvintele Google:
„Ne puteți ajuta oferind indicii explicite despre semnificația unei pagini pentru Google, incluzând date structurate pe pagină. Datele structurate sunt un format standardizat pentru furnizarea de informații despre o pagină și clasificarea conținutului paginii; de exemplu, pe pagina unei rețete, care sunt ingredientele, timpul și temperatura de gătire, caloriile și așa mai departe.”
Google continuă spunând:
„Trebuie să includeți toate proprietățile necesare pentru ca un obiect să fie eligibil pentru apariția în Căutarea Google cu afișare îmbunătățită. În general, definirea unor funcții recomandate poate face mai probabil ca informațiile dvs. să apară în rezultatele căutării cu afișare îmbunătățită. Cu toate acestea, este mai important să furnizați mai puține proprietăți recomandate, dar complete și precise, decât să încercați să furnizați fiecărei proprietăți recomandate posibile date mai puțin complete, prost formate sau inexacte.”
S-ar putea spune mai multe despre schema, dar este suficient să spunem că schema este un instrument incredibil pentru SEO care doresc să facă conținutul paginii clar pentru motoarele de căutare.
Ultima piesă a puzzle-ului provine din anunțul pe blogul Google intitulat „Îmbunătățirea căutării pentru următorii 20 de ani”.
Relevanța și calitatea documentului sunt ideile principale din spatele acestui anunț. Prima metodă folosită de Google pentru a determina conținutul unei pagini a fost în întregime concentrată pe cuvinte cheie.
Google a adăugat apoi straturi de subiecte pentru căutare. Acest strat a fost posibil prin grafice de cunoștințe și prin răzuirea și structurarea sistematică a datelor pe web.
Asta ne aduce la actualul sistem de căutare. Google a trecut de la 570 de milioane de entități și 18 miliarde de fapte la 800 de miliarde de fapte și 8 miliarde de entități în mai puțin de 10 ani. Pe măsură ce acest număr crește, căutarea de entități se îmbunătățește.
Cum este modelul de entitate o îmbunătățire față de modelele de căutare anterioare?
Modelele tradiționale de recuperare a informațiilor bazate pe cuvinte cheie (IR) au o limitare inerentă de a nu putea prelua documente (relevante) care nu au potriviri explicite de termeni cu interogarea.
Dacă utilizați ctrl + f pentru a găsi text pe o pagină, utilizați ceva similar cu modelul tradițional de recuperare a informațiilor bazat pe cuvinte cheie.
O cantitate nebună de date este publicată pe web în fiecare zi.
Pur și simplu nu este fezabil pentru Google să înțeleagă semnificația fiecărui cuvânt, a fiecărui paragraf, a fiecărui articol și a fiecărui site web.
În schimb, entitățile oferă o structură din care Google poate minimiza sarcina de calcul, îmbunătățind în același timp înțelegerea.
„Metodele de recuperare bazate pe concepte încearcă să abordeze această provocare bazându-se pe structuri auxiliare pentru a obține reprezentări semantice ale interogărilor și documentelor într-un spațiu conceptual de nivel superior. Astfel de structuri includ vocabulare controlate (dicționare și tezaure), ontologii și entități dintr-un depozit de cunoștințe.”
– Căutare orientată pe entitate , capitolul 8.3
Krisztian Balog, care a scris cartea definitivă despre entități, identifică trei soluții posibile la modelul tradițional de regăsire a informațiilor.
- Bazat pe expansiune : folosește entitățile ca sursă pentru extinderea interogării cu diferiți termeni.
- Bazat pe proiecție : relevanța dintre o interogare și un document este înțeleasă prin proiectarea acestora într-un spațiu latent de entități
- Bazat pe entitate : Reprezentările semantice explicite ale interogărilor și documentelor sunt obținute în spațiul entității pentru a spori reprezentările bazate pe termeni.
Scopul acestor trei abordări este de a obține o reprezentare mai bogată a informațiilor necesare utilizatorului prin identificarea entităților puternic legate de interogare.
Apoi, Balog identifică șase algoritmi asociați cu metodele bazate pe proiecție de mapare a entităților (metodele de proiecție se referă la conversia entităților în spațiu tridimensional și la măsurarea vectorilor folosind geometrie).
- Analiza semantică explicită (ESA) : Semantica unui anumit cuvânt este descrisă de un vector care stochează punctele forte de asociere ale cuvântului cu conceptele derivate din Wikipedia.
- Modelul spațial al entității latente (LES) : Bazat pe un cadru probabilist generativ. Scorul de recuperare al documentului este considerat o combinație liniară a scorului spațiului latent al entității și scorul de probabilitate a interogării inițial.
- EsdRank: EsdRank este pentru clasarea documentelor, folosind o combinație de caracteristici de interogare-entitate și entitate-document. Acestea corespund noțiunilor de proiecție a interogării și, respectiv, componentelor de proiecție a documentelor din LES, de mai înainte. Folosind un cadru de învățare discriminativ, semnale suplimentare pot fi, de asemenea, încorporate cu ușurință, cum ar fi popularitatea entității sau calitatea documentului
- Clasificare semantică explicită (ESR): Modelul de clasificare semantică explicită încorporează informații despre relații dintr-un grafic de cunoștințe pentru a permite „potrivirea soft” în spațiul entității.
- Cadru duet cuvânt-entitate: acesta încorporează interacțiuni în spații încrucișate între reprezentările bazate pe termeni și cele bazate pe entități, conducând la patru tipuri de potriviri: termeni de interogare la termeni de document, entități de interogare la termeni de document, termeni de interogare la entități de document și entități de interogare. pentru a documenta entitățile.
- Model de clasare bazat pe atenție : Acesta este de departe cel mai complicat de descris.
Iată ce scrie Balog:
„Sunt proiectate în total patru caracteristici de atenție, care sunt extrase pentru fiecare entitate de interogare. Caracteristicile de ambiguitate ale entității sunt menite să caracterizeze riscul asociat cu o adnotare a entității. Acestea sunt: (1) entropia probabilității ca forma de suprafață să fie legată de diferite entități (de exemplu, în Wikipedia), (2) dacă entitatea adnotată este cel mai popular sens al formei de suprafață (adică are cea mai mare comunitate). scor și (3) diferența de scoruri comune între candidații cel mai probabil și al doilea cel mai probabil pentru forma de suprafață dată. A patra caracteristică este apropierea, care este definită ca asemănarea cosinusului dintre entitatea de interogare și interogarea într-un spațiu de încorporare . În mod specific, o încorporare comună de entitate-termen este antrenată utilizând modelul skip-gram pe un corpus, în care mențiunile de entitate sunt înlocuite cu identificatorii de entitate corespunzători. Încorporarea interogării este considerată a fi centroidul înglobărilor termenilor de interogare.”

Pentru moment, este important să avem familiaritate la nivel de suprafață cu acești șase algoritmi centrați pe entități.
Principala concluzie este că există două abordări: proiectarea documentelor la un strat de entitate latentă și adnotări explicite ale documentelor.
Trei tipuri de structuri de date
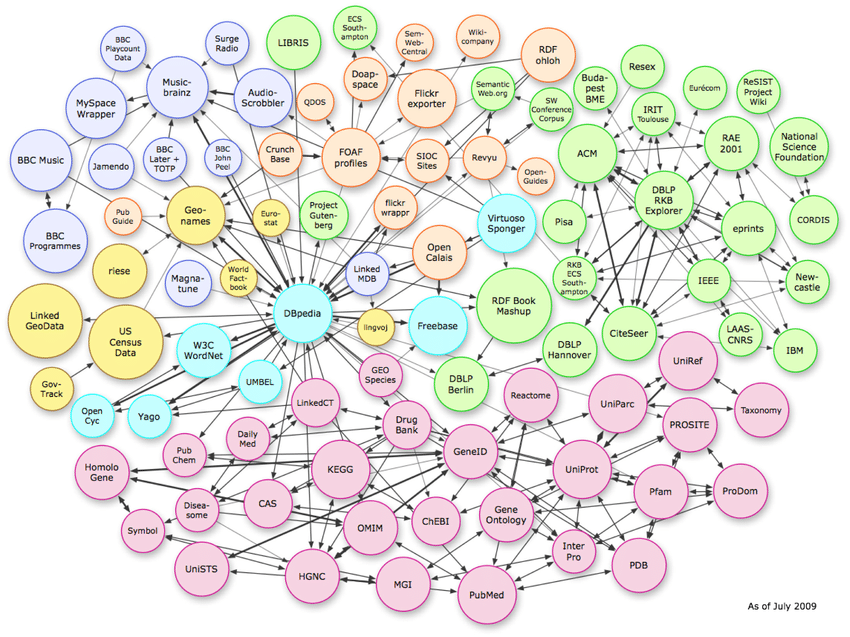
Imaginea de mai sus arată relațiile complexe care există în spațiul vectorial. În timp ce exemplul arată conexiunile grafice de cunoștințe, același model poate fi replicat la nivel de schemă pagină cu pagină.
Pentru a înțelege entitățile, este important să cunoașteți cele trei tipuri de structuri de date pe care le folosesc algoritmii.
- Folosind descrieri nestructurate ale entităților , trimiterile la alte entități trebuie recunoscute și dezambiguate. Marginile direcționate (hyperlink-uri) sunt adăugate de la fiecare entitate la toate celelalte entități menționate în descrierea acesteia.
- Într-un cadru semi-structurat (de exemplu, Wikipedia), legăturile către alte entități pot fi furnizate în mod explicit.
- Când lucrați cu date structurate , triplele RDF definesc un grafic (adică, graficul de cunoștințe). În mod specific, resursele subiect și obiect (URI) sunt noduri, iar predicatele sunt margini.
Problema cu un context semistructurat și care distrag atenția pentru scorul IR este că, dacă un document nu este configurat pentru un singur subiect, scorul IR poate fi diluat de cele două contexte diferite, rezultând un rang relativ pierdut față de un alt document textual.
Diluarea scorului IR implică relații lexicale slab structurate și proximitatea cuvintelor proaste.
Cuvintele relevante care se completează unul pe altul ar trebui folosite îndeaproape într-un paragraf sau secțiune a documentului pentru a semnala contextul mai clar pentru a crește scorul IR.
Utilizarea atributelor și relațiilor entității produce îmbunătățiri relative în intervalul 5-20%. Exploatarea informațiilor de tip entitate este și mai plină de satisfacții, cu îmbunătățiri relative variind de la 25% la peste 100%.
Adnotarea documentelor cu entități poate aduce structura documentelor nestructurate, ceea ce poate ajuta la popularea bazelor de cunoștințe cu informații noi despre entități.
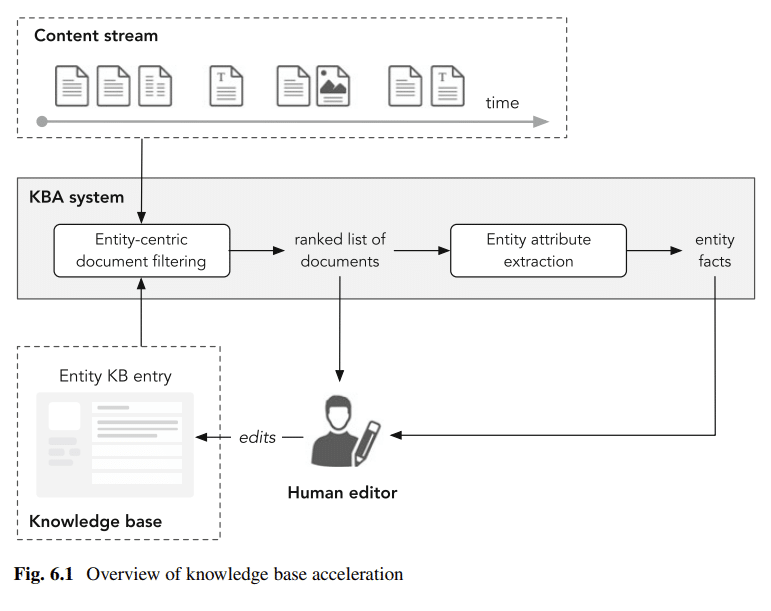
Folosind Wikipedia ca cadru SEO pentru entitate
Structura paginilor Wikipedia
- Titlul (I.)
- Secțiunea de plumb (II.)
- Legături de dezambiguizare (II.a)
- Caseta informativă (II.b)
- Text introductiv (II.c)
- Cuprins (III.)
- Conținutul corpului (IV.)
- Anexe și materie de bază (V.)
- Referințe și note (Va)
- Legături externe (Vb)
- Categorii (Vc)
Majoritatea articolelor Wikipedia includ un text introductiv, „lead”, un scurt rezumat al articolului – de obicei, nu mai mult de patru paragrafe. Acest lucru ar trebui să fie scris într-un mod care să creeze interes pentru articol.
Prima teză și paragraful de început au o importanță deosebită. Prima propoziție „poate fi considerată ca definiția entității descrise în articol”. Primul paragraf oferă o definiție mai elaborată, fără prea multe detalii.
Valoarea link-urilor se extinde dincolo de scopurile de navigare; surprind relaţiile semantice dintre articole. În plus, textele de ancorare sunt o sursă bogată de variante de nume de entități. Link-urile Wikipedia pot fi folosite, printre altele, pentru a ajuta la identificarea și dezambiguizarea mențiunilor de entități din text.
- Rezumați faptele cheie despre entitate (infobox).
- Scurta introducere.
- Link-uri interne. O regulă cheie dată editorilor este de a lega numai la prima apariție a unei entități sau concept.
- Includeți toate sinonimele populare pentru o entitate.
- Desemnarea paginii categoriei.
- Șablon de navigare.
- Referințe.
- Instrumente speciale de analiză pentru înțelegerea paginilor Wiki.
- Mai multe tipuri de media.
Cum să optimizați pentru entități
Următoarele sunt considerente cheie atunci când optimizați entitățile pentru căutare:
- Includerea de cuvinte legate semantic pe o pagină.
- Frecvența cuvintelor și a frazei pe o pagină.
- Organizarea conceptelor pe o pagină.
- Inclusiv date nestructurate, date semistructurate și date structurate pe o pagină.
- Perechi subiect-predicat-obiect (SPO).
- Documente web de pe un site care funcționează ca pagini ale unei cărți.
- Organizarea documentelor web pe un site web.
- Includeți concepte într-un document web care sunt caracteristici cunoscute ale entităților.
Notă importantă: când accentul este pus pe relațiile dintre entități, o bază de cunoștințe este adesea denumită un grafic de cunoștințe.
Deoarece intenția este analizată împreună cu jurnalele de căutare ale utilizatorilor și alte fragmente de context, aceeași expresie de căutare de la persoana 1 ar putea genera un rezultat diferit față de persoana 2. Persoana ar putea avea o intenție diferită cu exact aceeași interogare.
Dacă pagina ta acoperă ambele tipuri de intenții, atunci pagina ta este un candidat mai bun pentru clasarea web. Puteți utiliza structura bazelor de cunoștințe pentru a vă ghida șabloanele de interogare (așa cum sa menționat într-o secțiune anterioară).
Oamenii întreabă și, oamenii caută și Completarea automată sunt legate semantic de interogarea trimisă și fie merg mai adânc în direcția curentă de căutare, fie trec la un alt aspect al sarcinii de căutare.
Știm asta, deci cum putem optimiza pentru asta?
Documentele dvs. ar trebui să conțină cât mai multe variante ale intenției de căutare. Site-ul dvs. ar trebui să conțină fiecare variație a intenției de căutare pentru clusterul dvs. Clustering se bazează pe trei tipuri de similitudini:
- Asemănarea lexicală.
- Asemanare semantică.
- Faceți clic pe similaritate.
Acoperirea subiectului
Ce este –> Lista de atribute –> Secțiune dedicată fiecărui atribut –> Fiecare secțiune trimite la un articol dedicat în întregime subiectului respectiv –> Publicul trebuie specificat și definițiile pentru sub-secțiune –> Ce ar trebui luat în considerare ? –> Care sunt beneficiile? –> Avantajele modificatorului –> Ce este ___ –> Ce face? –> Cum se obține –> Cum se face –> Cine poate să o facă –> Link înapoi la toate categoriile

Google oferă un instrument care oferă un scor de proeminență (similar cu modul în care folosim cuvântul „putere” sau „încredere”) care vă spune cum vede Google conținutul.

Exemplul de mai sus provine dintr-un articol Search Engine Land despre entități din 2018.
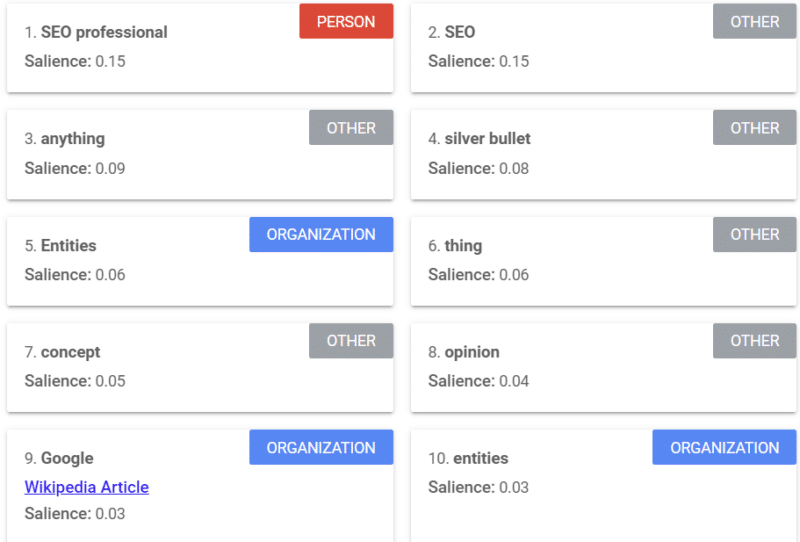
Puteți vedea persoane, alte persoane și organizații din exemplu. Instrumentul este API-ul Google Cloud Natural Language.
Fiecare cuvânt, propoziție și paragraf contează atunci când vorbim despre o entitate. Modul în care vă organizați gândurile poate schimba înțelegerea de către Google a conținutului dvs.
Puteți include un cuvânt cheie despre SEO, dar Google înțelege acel cuvânt cheie așa cum doriți să fie înțeles?
Încercați să plasați un paragraf sau două în instrument și să reorganizați și să modificați exemplul pentru a vedea cum crește sau scade importanța.
Acest exercițiu, numit „dezambiguizare”, este incredibil de important pentru entități. Limbajul este ambiguu, așa că trebuie să facem cuvintele noastre mai puțin ambigue pentru Google.
Abordările moderne de dezambiguizare iau în considerare trei tipuri de dovezi:
Importanța anterioară a entităților și mențiunilor.
Asemănarea contextuală între textul care înconjoară mențiunea și entitatea candidată și coerența între toate deciziile de legare a entităților din document.
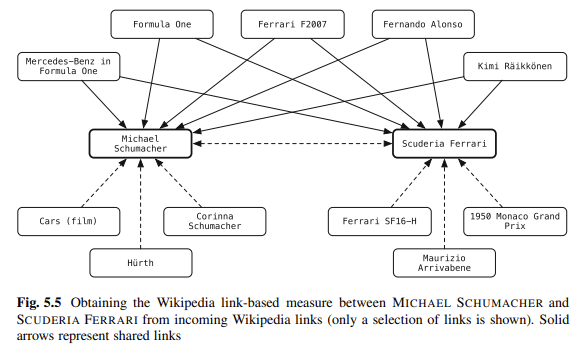
Schema este una dintre modalitățile mele preferate de a dezambiguar conținut. Conectați entitățile din blogul dvs. la depozitele de cunoștințe. Balog spune:
„Conectarea entităților din text nestructurat la un depozit de cunoștințe structurat poate împuternici foarte mult utilizatorii în activitățile lor de consum de informații.”
De exemplu, cititorii unui document pot obține informații contextuale sau de fundal cu un singur clic și pot obține acces ușor la entitățile conexe.
Adnotările de entități pot fi, de asemenea, utilizate în procesarea din aval pentru a îmbunătăți performanța de recuperare sau pentru a facilita o mai bună interacțiune a utilizatorului cu rezultatele căutării.
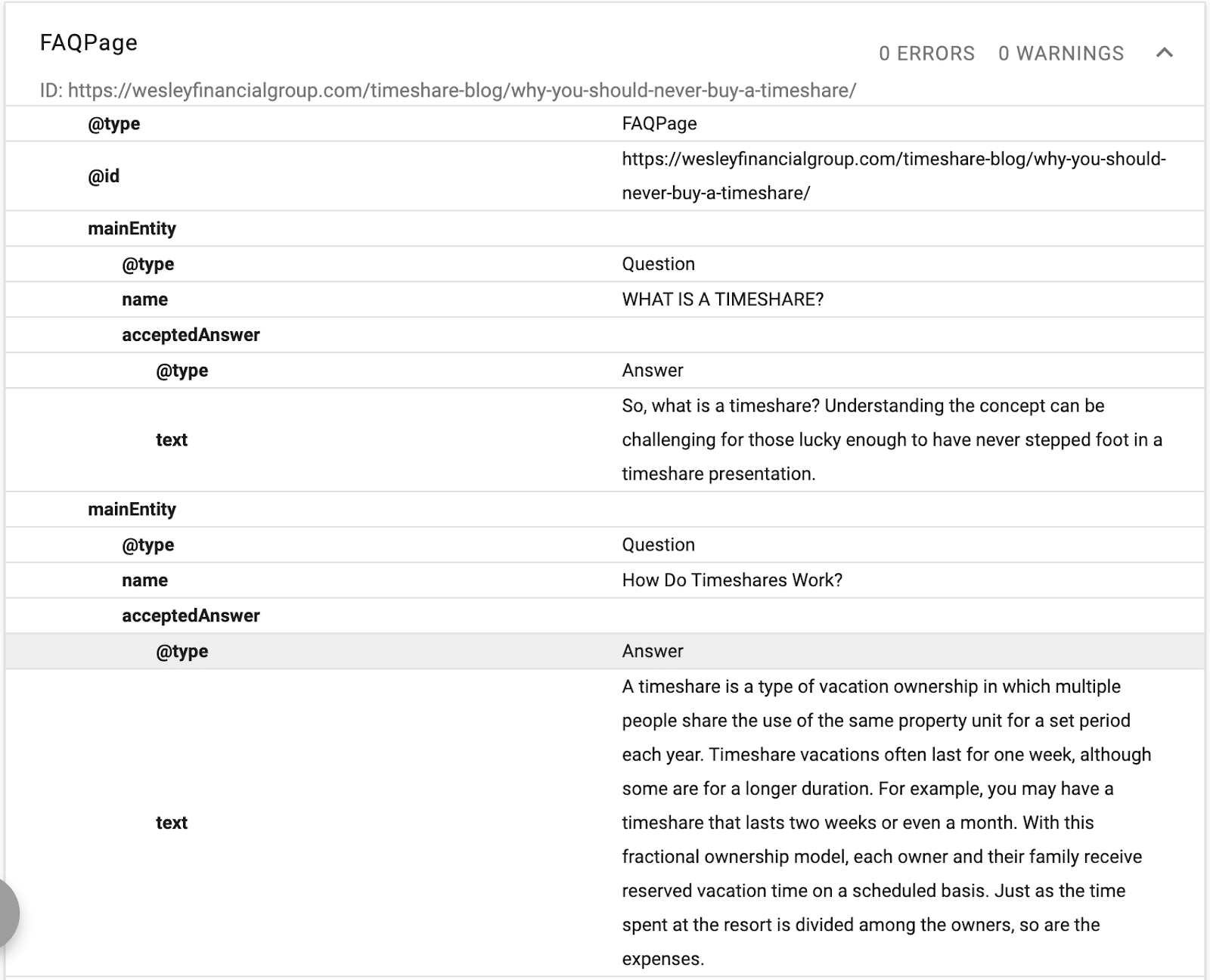
Aici puteți vedea că conținutul întrebărilor frecvente este structurat pentru Google folosind schema de întrebări frecvente.
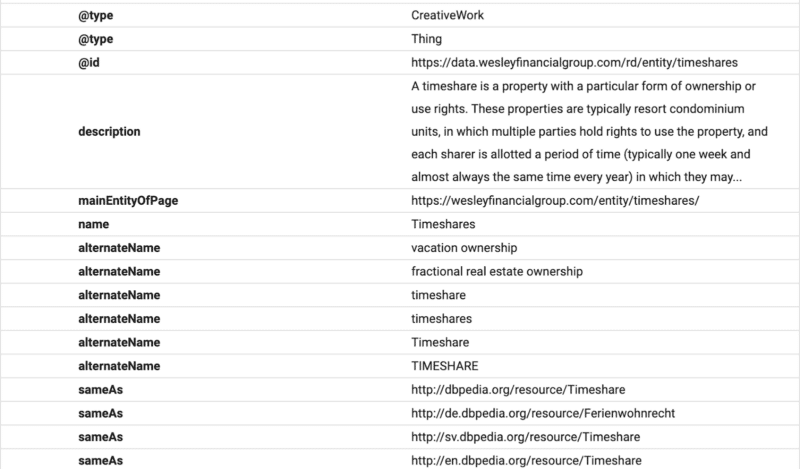
În acest exemplu, puteți vedea schema care oferă o descriere a textului, un ID și o declarație a entității principale a paginii.
(Rețineți că Google dorește să înțeleagă ierarhia conținutului, motiv pentru care H1–H6 este important.)
Veți vedea nume alternative și la fel ca și declarațiile. Acum, când Google citește conținutul, va ști ce bază de date structurată să asocieze textului și va avea sinonime și versiuni alternative ale unui cuvânt legat de entitate.
Când optimizați cu schema, optimizați pentru NER (recunoașterea entității numite), cunoscută și sub numele de identificare a entității, extracție a entității și fragmentare a entității.
Ideea este să vă angajați în Dezambiguarea entității cu nume > Wikification > Conectarea entităților.
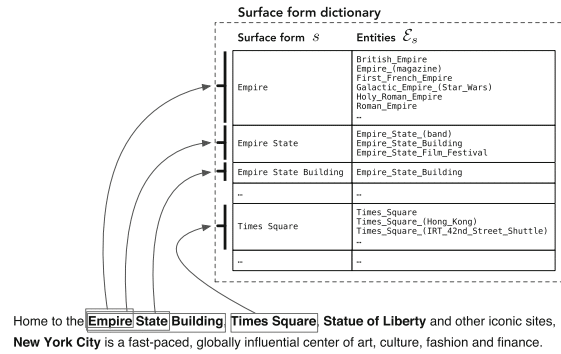
„Apariția Wikipedia a facilitat recunoașterea și dezambiguizarea la scară largă a entităților, oferind un catalog cuprinzător de entități, împreună cu alte resurse de neprețuit (în special, hyperlinkuri, categorii și pagini de redirecționare și dezambiguizare."
– Căutare orientată pe entitate
Cum să treceți dincolo de sugestiile instrumentelor SEO
Majoritatea SEO-urilor folosesc un instrument pe pagină pentru a-și optimiza conținutul. Fiecare instrument este limitat în capacitatea sa de a identifica oportunități unice de conținut și sugestii de profunzime de conținut.
În cea mai mare parte, instrumentele de pe pagină sunt doar cumulează primele rezultate SERP și creează o medie pe care să o emulați.
SEO-ul trebuie să-și amintească că Google nu caută aceleași informații refăcute. Puteți copia ceea ce fac alții, dar informațiile unice sunt cheia pentru a deveni un site de semințe/un site de autoritate.
Iată o descriere simplificată a modului în care Google gestionează noul conținut:
Odată ce s-a constatat că un document menționează o anumită entitate, acel document poate fi verificat pentru a descoperi posibile noi fapte cu care ar putea fi actualizată intrarea din baza de cunoștințe a acelei entități.
Balog scrie:
„Dorim să ajutăm editorii să rămână la curent cu schimbările prin identificarea automată a conținutului (articole de știri, postări pe blog etc.) care pot implica modificări ale intrărilor KB ale unui anumit set de entități de interes (adică entități pe care le este un anumit editor). răspunzător de)."
Oricine îmbunătățește bazele de cunoștințe, recunoașterea entităților și accesul cu crawlere a informațiilor va primi dragostea Google.
Modificările făcute în depozitul de cunoștințe pot fi urmărite până la document ca sursă originală.
Dacă furnizați conținut care acoperă subiectul și adăugați un nivel de profunzime care este rar sau nou, Google poate identifica dacă documentul dvs. a adăugat acele informații unice.
În cele din urmă, aceste noi informații susținute de-a lungul unei perioade de timp ar putea duce la site-ul dvs. web să devină o autoritate.
Aceasta nu este o autoritate bazată pe evaluarea domeniului, ci o acoperire de actualitate, care cred că este mult mai valoroasă.
Cu abordarea de entitate a SEO, nu vă limitați la direcționarea cuvintelor cheie cu volumul de căutare.
Tot ce trebuie să faceți este să validați termenul principal („undițe de pescuit la muscă”, de exemplu) și apoi vă puteți concentra pe direcționarea variațiilor intenției de căutare bazate pe gândirea umană bună.
Începem cu Wikipedia. Pentru exemplul pescuitului cu muscă, putem observa că, cel puțin, următoarele concepte ar trebui acoperite pe un site de pescuit:
- Specii de pești, istorie, origini, dezvoltare, îmbunătățiri tehnologice, expansiune, metode de pescuit cu muscă, turnare, spey casting, pescuit cu muscă la păstrăv, tehnici de pescuit cu muscă, pescuit în apă rece, pescuit la păstrăv cu muscă uscată, nimfă pentru păstrăv, apă plată pescuitul la păstrăv, jocul la păstrăv, eliberarea păstrăvului, pescuitul cu muscă în apă sărată, echipament, muște artificiale și noduri.
Subiectele de mai sus au venit de pe pagina Wikipedia pescuitul cu muscă. În timp ce această pagină oferă o prezentare excelentă a subiectelor, îmi place să adaug idei de subiecte suplimentare care provin din subiecte legate semantic.
Pentru subiectul „pește”, putem adăuga mai multe subiecte suplimentare, inclusiv etimologia, evoluția, anatomia și fiziologia, comunicarea peștilor, bolile peștilor, conservarea și importanța pentru oameni.
A legat cineva anatomia păstrăvului de eficiența anumitor tehnici de pescuit?
Un singur site de pescuit acoperă toate soiurile de pește în timp ce leagă tipurile de tehnici de pescuit, undițe și momeală la fiecare pește?
Până acum, ar trebui să puteți vedea cum poate crește extinderea subiectului. Țineți cont de acest lucru atunci când planificați o campanie de conținut.
Nu doar repetați. Adaugă valoare. Fi unic. Utilizați algoritmii menționați în acest articol ca ghid.
Concluzie
Acest articol face parte dintr-o serie de articole axate pe entități. În următorul articol, voi aprofunda eforturile de optimizare din jurul entităților și a unor instrumente centrate pe entități de pe piață.
Vreau să închei acest articol dând un strigăt la două persoane care mi-au explicat multe dintre aceste concepte.
Bill Slawski de la SEO by the Sea și Koray Tugbert de la SEO Holistic. În timp ce Slawski nu mai este printre noi, contribuțiile sale continuă să aibă un efect de undă în industria SEO.
Mă bazez foarte mult pe următoarele surse pentru conținutul articolului, deoarece aceste surse sunt cele mai bune resurse care există pe acest subiect:
- Ierarhie extinsă a entităților cu nume de Satoshi Ketine, Kiyoshi Sudo și Chikashi Nobata
- Căutare orientată pe entitate de Krisztian Balog , Seria de regăsire a informațiilor (INRE, volumul 39)
- Rescrierea interogărilor cu detectarea entității , patent Google
- Rafinarea interogărilor de căutare , patent Google
- Asocierea unei entități cu o interogare de căutare , patent Google
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.