
Cum poate Apache Spark să ofere aripi analizei companiilor aeriene?
Publicat: 2015-10-30Industria aeriană globală continuă să crească rapid, dar profitabilitatea consistentă și robustă este încă de văzut. Potrivit Asociației Internaționale de Transport Aerian (IATA), industria și-a dublat veniturile în ultimul deceniu, de la 369 de miliarde de dolari în 2005 la 727 de miliarde de dolari în 2015.

În sectorul aviației comerciale, fiecare jucător din lanțul valoric - aeroporturi, producători de avioane, producători de motoare cu reacție, agenți de turism și companii de servicii realizează un profit ordonat.
Toți acești jucători generează în mod individual volume extrem de mari de date datorită numărului mai mare de tranzacții de zbor. Identificarea și captarea cererii este cheia aici, care oferă companiilor aeriene mult mai multe oportunități de a se diferenția. Prin urmare, industriile aviatice pot utiliza informațiile mari de date pentru a-și crește vânzările și pentru a îmbunătăți marja de profit.
Big Data este un termen pentru colectarea de seturi de date atât de mari și complexe încât calcularea lor nu poate fi gestionată de sistemele tradiționale de procesare a datelor sau de instrumente DBMS disponibile.
Apache Spark este un cadru de calcul cluster distribuit, cu sursă deschisă, conceput special pentru interogări interactive și algoritmi iterativi.
Abstracția Spark DataFrame este un obiect de date tabelar similar cu cadrul de date nativ al lui R sau cu pachetul Pythons Pandas, dar stocat în mediul cluster.
Potrivit celui mai recent sondaj Fortunes, Apache Spark este cea mai populară tehnologie din 2015.
Cel mai mare furnizor de Hadoop, Cloudera, își spune la revedere Hadoops MapReduce și Hello to Spark.
Ceea ce dă cu adevărat Spark avantaj față de Hadoop este viteza . Spark se ocupă de majoritatea operațiunilor sale în memorie – copierea acestora din stocarea fizică distribuită în memoria RAM logică mult mai rapidă. Acest lucru reduce cantitatea de timp consumată în scriere și citire pe și de la hard disk-uri mecanice lente și greoaie, care trebuie făcută cu sistemul Hadoops MapReduce.
De asemenea, Spark include instrumente (procesare în timp real, învățare automată și SQL interactiv) care sunt bine concepute pentru a promova obiectivele de afaceri, cum ar fi analiza datelor în timp real, prin combinarea datelor istorice de la dispozitivele conectate, cunoscute și sub numele de Internetul lucrurilor .
Astăzi, să adunăm câteva informații despre exemple de date de aeroport folosind Apache Spark .
În blogul anterior, am văzut cum să gestionăm datele structurate și semi-structurate în Spark utilizând noul API Dataframes și am abordat, de asemenea, cum să procesăm datele JSON în mod eficient.
În acest blog vom înțelege cum să interogăm date în DataFrames folosind SQL , precum și cum să salvăm rezultatul în sistemul de fișiere în format CSV.
Folosind biblioteca de analiză CSV Databricks
Pentru aceasta, voi folosi o bibliotecă de analiză CSV oferită de Databricks, o companie fondată de Creators of Apache Spark și care se ocupă în prezent de dezvoltarea și distribuțiile Spark.
Comunitatea Spark este formată din aproximativ 600 de colaboratori, care îl fac cel mai activ proiect din întreaga Apache Software Foundation, un organism de conducere major pentru software open source, din punct de vedere al numărului de colaboratori.
Biblioteca Spark-csv ne ajută să analizăm și să interogăm datele csv din spark. Putem folosi această bibliotecă atât pentru citirea, cât și pentru scrierea datelor csv către și din orice sistem de fișiere compatibil Hadoop.
Încărcarea datelor în Spark DataFrames
Să încărcăm fișierele noastre de intrare într-un Spark DataFrames folosind biblioteca de analiză spark-csv de la Databricks.
Puteți utiliza această bibliotecă în shell-ul Spark specificând –packages com.databricks: spark-csv_2.10:1.0.3
În timp ce porniți shell-ul, așa cum se arată mai jos:
$ bin/spark-shell –pachete com.databricks:spark-csv_2.10:1.0.3
Amintiți-vă că ar trebui să fiți conectat la internet, deoarece pachetul spark-csv va fi descărcat automat când dați această comandă. Folosesc versiunea spark 1.4.0
Să creăm sqlContext cu obiectul SparkContext(sc) deja creat
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
Acum să încărcăm datele noastre csv din fișierul airports.csv (aeroport csv github) a cărui schemă este ca mai jos
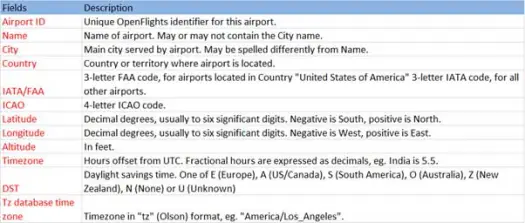
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))Operația de încărcare va analiza fișierul *.csv folosind biblioteca Databricks spark-csv și va returna un cadru de date cu nume de coloană la fel ca în prima linie de antet din fișier.
Următorii sunt parametrii trecuți la metoda de încărcare.
- Sursa : „com.databricks.spark.csv” îi spune lui Spark că vrem să încărcăm ca fișier csv.
- Opțiuni:
- cale – calea fișierului, unde se află.
- Antet : „header” -> „true” îi spune lui spark să mapeze prima linie a fișierului cu numele coloanelor pentru cadrul de date rezultat.
Să vedem care este schema Dataframe-ului nostru
Consultați exemple de date în cadrul nostru de date
scala> airportDF.show


Interogarea datelor CSV folosind tabele temporare:
Pentru a executa o interogare pe un tabel, apelăm metoda sql() pe SQLContext.
Am creat un DataFrame aeroporturilor și am încărcat date CSV, pentru a interoga aceste date DF trebuie să le înregistrăm ca tabel temporar numit aeroporturi.
>
scala> airportDF.registerTempTable("airports")
Să aflăm câte aeroporturi există în partea de sud-est în setul nostru de date
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]
Putem face agregari în interogări sql pe Spark
Vom afla câte orașe unice au aeroporturi în fiecare țară
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
Care este altitudinea medie (în picioare) a aeroporturilor din fiecare țară?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
Acum să aflați în fiecare fus orar câte aeroporturi operează?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
De asemenea, putem calcula latitudinea și longitudinea medie pentru aceste aeroporturi din fiecare țară
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
Să numărăm câte DST-uri diferite sunt acolo
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
Salvarea datelor în format CSV
Până acum am încărcat și interogat datele csv. Acum vom vedea cum să salvăm rezultatele în format CSV înapoi în sistemul de fișiere.
Să presupunem că vrem să trimitem clientului un raport despre toate aeroporturile din partea de nord-vest a tuturor țărilor.
Să calculăm asta mai întâi.
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
Și salvați-l în fișierul CSV
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
Următorii sunt parametrii trecuți pentru metoda de salvare.
- Sursă : este la fel ca metoda de încărcare com.databricks.spark.csv care îi spune lui spark să salveze datele ca csv.
- SaveMode : Acest lucru permite utilizatorului să specifice în avans ce trebuie făcut dacă calea de ieșire dată există deja. Pentru ca datele existente să nu se piardă/suprascrise din greșeală. Puteți arunca erori, adăugați sau suprascrieți. Aici, am lansat o eroare ErrorIfExists , deoarece nu dorim să suprascriem niciun fișier existent.
- Opțiuni : Aceste opțiuni sunt aceleași cu ceea ce am transmis la metoda de încărcare . Opțiuni:
- cale – calea fișierului, unde ar trebui să fie stocat.
- Antet : „header” -> „true” îi spune lui spark să mapeze numele coloanelor din cadrul de date la prima linie a fișierului de ieșire rezultat.
Conversia altor formate de date în CSV
De asemenea, putem converti orice alt format de date precum JSON, parchet, text în CSV folosind această bibliotecă.
În blogul anterior, am creat date json. il gasesti pe github
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
hai să-l salvăm ca CSV.
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
Concluzie:
În această postare am adunat câteva informații despre datele aeroporturilor folosind interogări interactive SparkSQL
și a explorat biblioteca de analiză csv din Spark
Următorul blog vom explora o componentă foarte importantă a Spark, adică Spark Streaming.
Spark Streaming permite utilizatorilor să adune date în timp real în Spark și să le proceseze așa cum se întâmplă și să ofere rezultate instantaneu.