
Cum să utilizați entitățile Google și GPT-4 pentru a crea contururi de articole
Publicat: 2023-06-06În acest articol, veți învăța cum să folosiți răzuirea și Knowledge Graph de la Google pentru a face inginerie automată promptă care generează o schiță și un rezumat pentru un articol care, dacă este bine scris, va conține multe ingrediente cheie pentru a se clasa bine.
La rădăcina lucrurilor, îi spunem GPT-4 să producă o schiță a articolului bazată pe un cuvânt cheie și pe principalele entități pe care le-au găsit pe o pagină bine clasată la alegerea dvs.
Entitățile sunt ordonate după scorul lor de proeminență.
„De ce scorul de proeminență?” ai putea întreba.
Google descrie importanța în documentele API astfel:
„Scorul de proeminență pentru o entitate oferă informații despre importanța sau centralitatea acelei entități pentru întregul text al documentului. Scorurile mai apropiate de 0 sunt mai puțin proeminente, în timp ce scorurile mai apropiate de 1,0 sunt extrem de importante.”
Pare o măsură destul de bună de folosit pentru a influența ce entități ar trebui să existe într-o bucată de conținut pe care ați dori să o scrieți, nu-i așa?
Noțiuni de bază
Există două moduri prin care poți proceda în acest sens:
- Petreceți aproximativ 5 minute (poate 10 dacă trebuie să vă configurați computerul) și rulați scripturile de pe mașina dvs. sau...
- Mergeți la Colab pe care l-am creat și începeți să vă jucați imediat.
Sunt parțial față de primul, dar am sărit și la un Colab sau două în ziua mea. 😀
Presupunând că sunteți încă aici și doriți să configurați acest lucru pe propria mașină, dar nu aveți încă instalat Python sau un IDE (Mediu de dezvoltare integrat), vă voi îndruma mai întâi către o citire rapidă despre configurarea mașinii pentru utilizare. Caietul Jupyter. Nu ar trebui să dureze mai mult de aproximativ 5 minute.
Acum, este timpul să pornim!
Utilizarea entităților Google și GPT-4 pentru a crea contururi ale articolelor
Pentru ca acest lucru să fie ușor de urmat, voi formata instrucțiunile după cum urmează:
- Pas : o scurtă descriere a pasului în care ne aflăm.
- Cod : codul pentru a finaliza acel pas.
- Explicație : O scurtă explicație a ceea ce face codul.
Pasul 1: Spune-mi ce vrei
Înainte de a ne aprofunda în crearea contururilor, trebuie să definim ceea ce ne dorim.
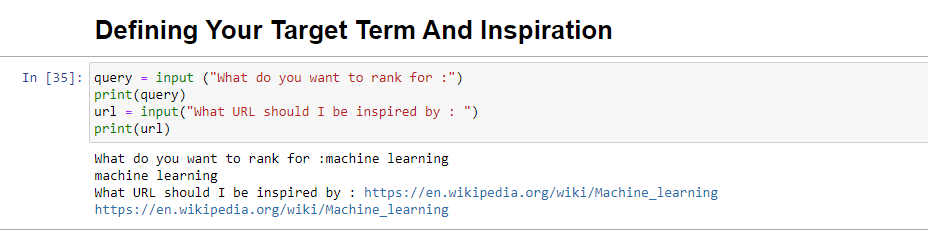
query = input ("What do you want to rank for :") print(query) url = input("What URL should I be inspired by : ") print(url)Când este rulat, acest bloc va solicita utilizatorului (probabil dvs.) să introducă interogarea pentru care doriți să se clasifice/despre care articolul, precum și să vă ofere un loc în care să introduceți adresa URL a unui articol pentru care doriți. piesa din care sa se inspire.
Aș sugera un articol care se clasifică bine, este într-un format care să funcționeze pentru site-ul dvs. și despre care credeți că merită clasamentul numai prin valoarea articolului și nu doar prin puterea site-ului.
Când rulați, va arăta astfel:
Pasul 2: Instalarea bibliotecilor necesare
În continuare, trebuie să instalăm toate bibliotecile pe care le vom folosi pentru a face magia să se întâmple.
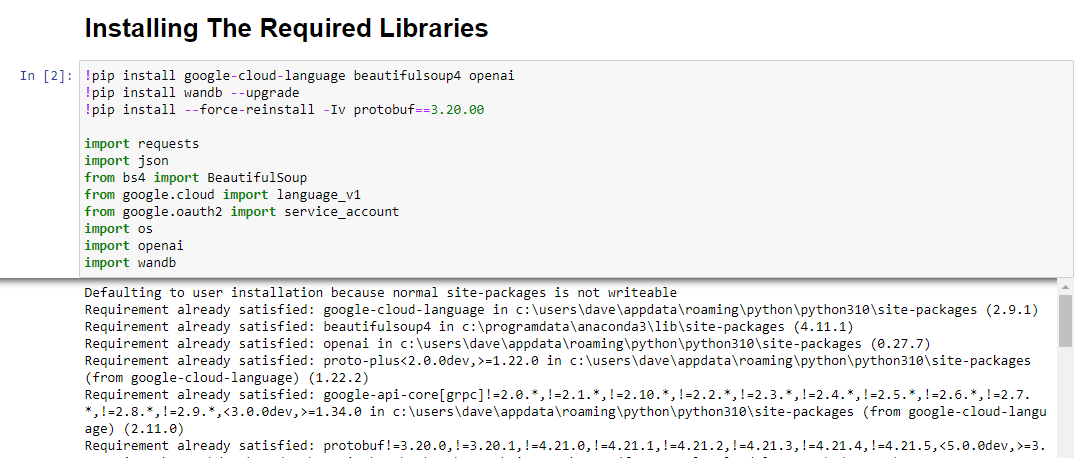
!pip install google-cloud-language beautifulsoup4 openai !pip install wandb --upgrade !pip install --force-reinstall -Iv protobuf==3.20.00 import requests import json from bs4 import BeautifulSoup from google.cloud import language_v1 from google.oauth2 import service_account import os import openai import pandas as pd import wandbInstalăm următoarele biblioteci:
- Solicitări : această bibliotecă permite efectuarea de solicitări HTTP pentru a prelua conținut de pe site-uri web sau API-uri web.
- JSON : oferă funcții pentru a lucra cu date JSON, inclusiv analizarea șirurilor JSON în obiecte Python și serializarea obiectelor Python în șiruri JSON.
- BeautifulSoup : Această bibliotecă este folosită în scopuri de web scraping. Ajută la analizarea și navigarea documentelor HTML sau XML și la extragerea informațiilor relevante din acestea.
- Google.cloud.language_v1 : este o bibliotecă de la Google Cloud care oferă capabilități de procesare a limbajului natural. Permite efectuarea diferitelor sarcini, cum ar fi analiza sentimentelor, recunoașterea entităților și analiza de sintaxă a datelor text.
- Google.oauth2.service_account : această bibliotecă face parte din pachetul Google OAuth2 Python. Acesta oferă suport pentru autentificarea cu API-urile Google folosind un cont de serviciu, care este o modalitate de a acorda acces limitat la resursele unui proiect Google Cloud.
- OS : Această bibliotecă oferă o modalitate de a interacționa cu sistemul de operare. Permite accesarea diferitelor funcționalități, cum ar fi operațiuni cu fișiere, variabile de mediu și managementul proceselor.
- OpenAI : Această bibliotecă este pachetul OpenAI Python. Acesta oferă o interfață pentru a interacționa cu modelele de limbaj OpenAI, inclusiv GPT-4 (și 3). Permite dezvoltatorilor să genereze text, să completeze text și multe altele.
- Pandas : este o bibliotecă puternică pentru manipularea și analiza datelor. Oferă structuri și funcții de date pentru a gestiona și analiza eficient datele structurate, cum ar fi tabelele sau fișierele CSV.
- WandB : Această bibliotecă înseamnă „Greutăți și părtiniri” și este un instrument pentru urmărirea și vizualizarea experimentelor. Vă ajută să înregistrați și să vizualizați valorile, hiperparametrii și alte aspecte importante ale experimentelor de învățare automată.
Când rulați, arată astfel:
Obțineți buletinele informative zilnice pe care se bazează marketerii.
Vezi termenii.
Pasul 3: Autentificare
Va trebui să ne deturnăm pentru o clipă pentru a pleca și a ne pune în aplicare autentificarea. Vom avea nevoie de o cheie API OpenAI și de acreditări Google Knowledge Graph Search.
Acest lucru va dura doar câteva minute.
Obținerea API-ului dvs. OpenAI
În prezent, probabil că trebuie să vă alăturați listei de așteptare. Sunt norocos că am acces devreme la API și, prin urmare, scriu acest lucru pentru a vă ajuta să vă configurați imediat ce îl primiți.
Imaginile de înscriere sunt de la GPT-3 și vor fi actualizate pentru GPT-4 odată ce fluxul este disponibil pentru toți.
Înainte de a putea folosi GPT-4, veți avea nevoie de o cheie API pentru a-l accesa.
Pentru a obține unul, accesați pagina de produse OpenAI și faceți clic pe Începe .
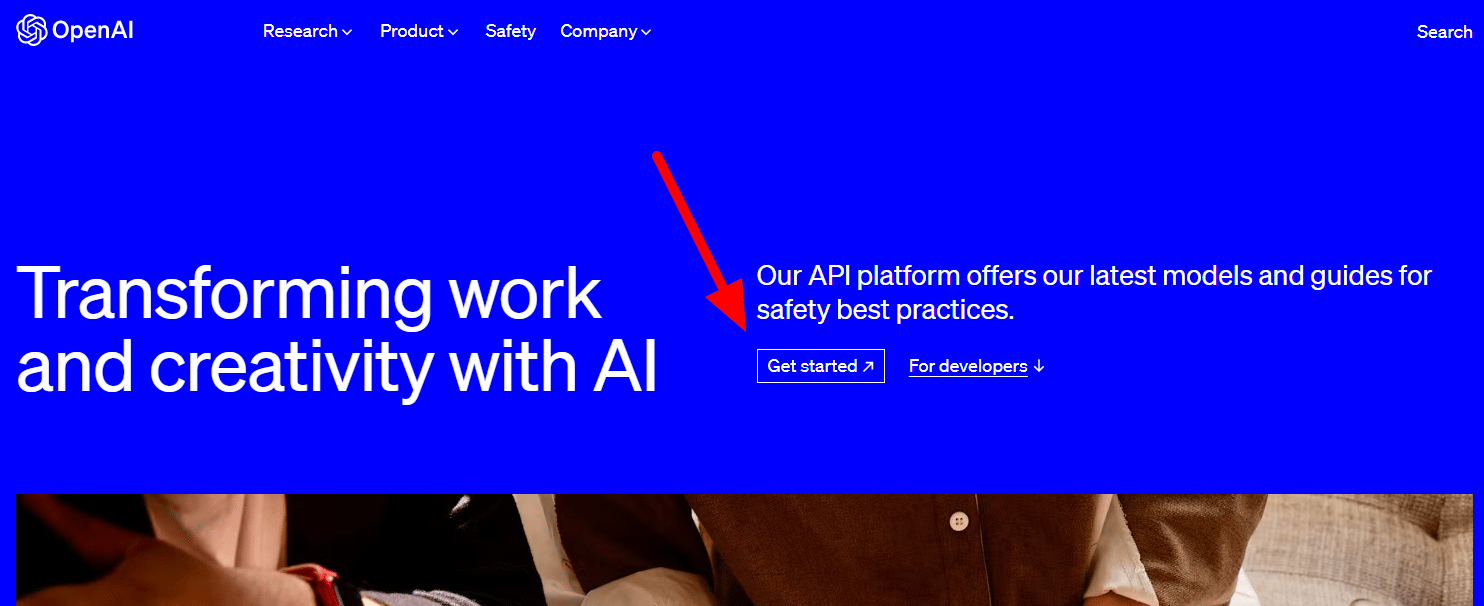
Alegeți metoda dvs. de înscriere (eu am ales Google) și parcurgeți procesul de verificare. Veți avea nevoie de acces la un telefon care poate primi mesaje pentru acest pas.
După ce este finalizat, veți crea o cheie API. Acest lucru este pentru ca OpenAI să vă poată conecta scripturile la contul dvs.
Ei trebuie să știe cine ce face și să stabilească dacă și cât de mult ar trebui să vă perceapă pentru ceea ce faceți.
Prețurile OpenAI
La înscriere, primești un credit de 5 USD care te va duce surprinzător de departe dacă doar experimentezi.
În momentul scrierii acestui articol, prețurile trecute sunt:

Crearea cheii dvs. OpenAI
Pentru a vă crea cheia, faceți clic pe profilul dvs. în dreapta sus și alegeți Vedeți cheile API .
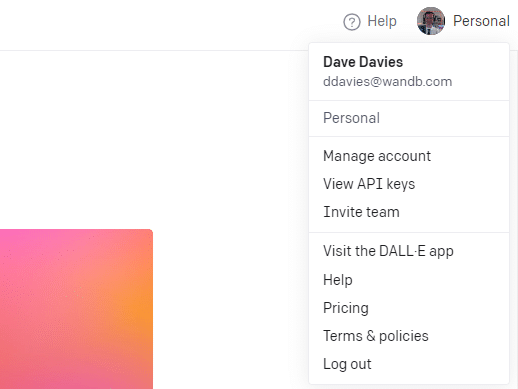
...și apoi îți vei crea cheia.
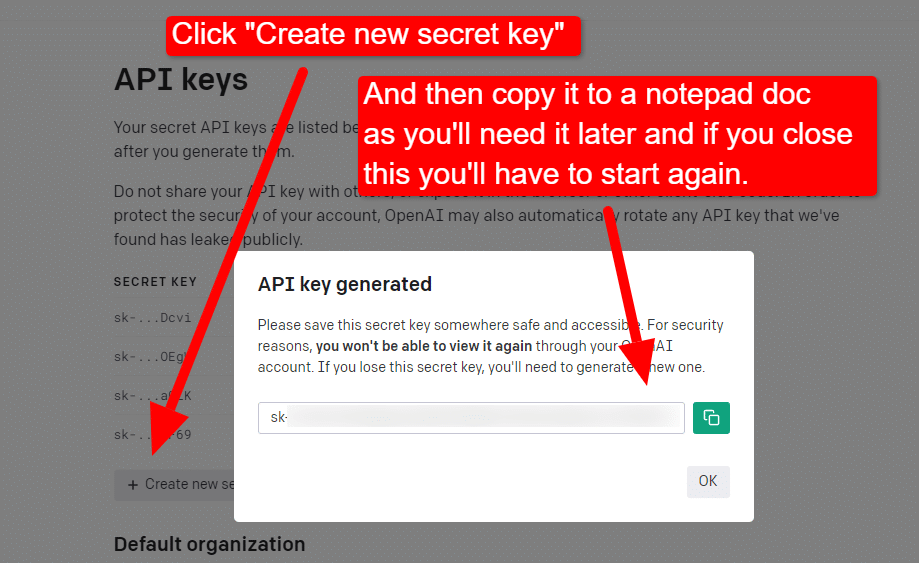
Odată ce închideți caseta de lumină, nu vă puteți vizualiza cheia și va trebui să o recreați, așa că pentru acest proiect, pur și simplu copiați-o într-un document Notepad pentru a o utiliza în scurt timp.
Notă: Nu salvați cheia (un document Notepad de pe desktop nu este foarte sigur). După ce l-ați folosit pentru moment, închideți documentul Notepad fără a-l salva.
Obținerea autentificării Google Cloud
Mai întâi, va trebui să vă conectați la contul dvs. Google. (Ești pe un site SEO, așa că presupun că ai unul. 🙂)
Odată ce ați făcut acest lucru, puteți examina informațiile API Knowledge Graph dacă vă simțiți atât de înclinați sau să treceți direct la Consola API și să începeți.
Odată ce sunteți la consolă:
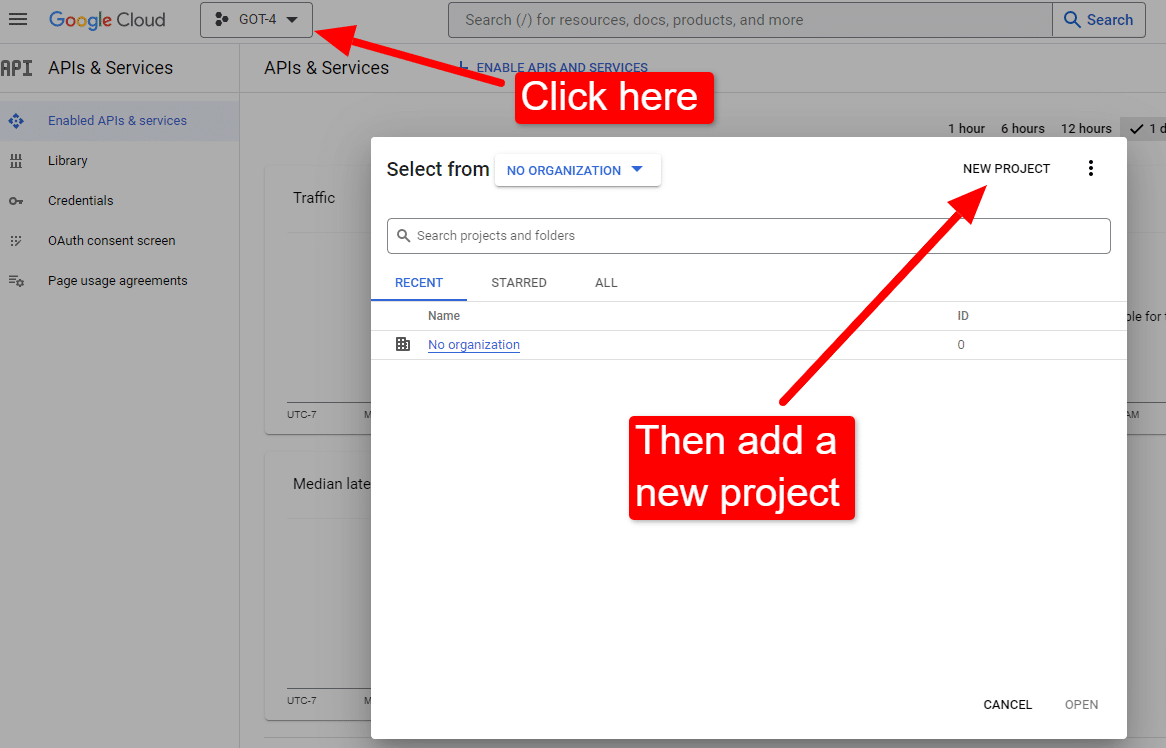
Numiți-o așa cum ar fi „Articolele minunate ale lui Dave”. Știi... ușor de reținut.
Apoi, veți activa API-ul făcând clic pe Activare API-uri și servicii .

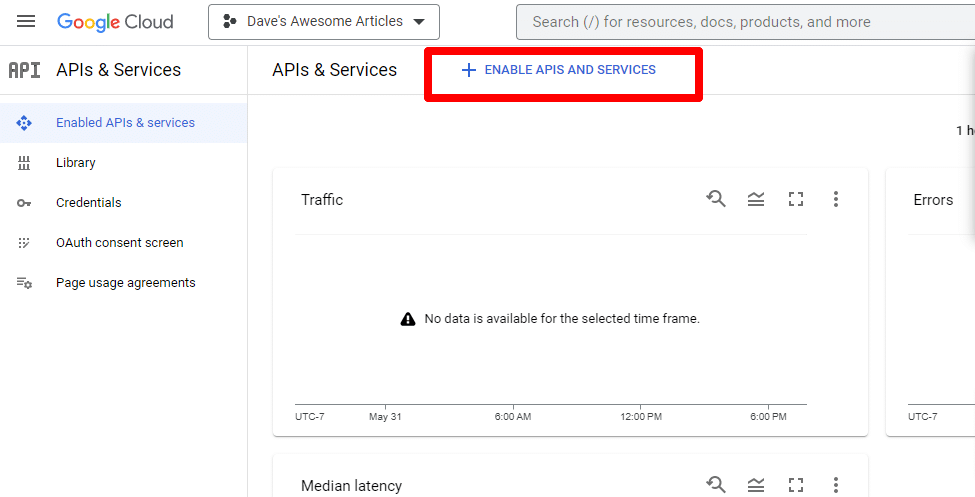
Găsiți API-ul Knowledge Graph Search și activați-l.
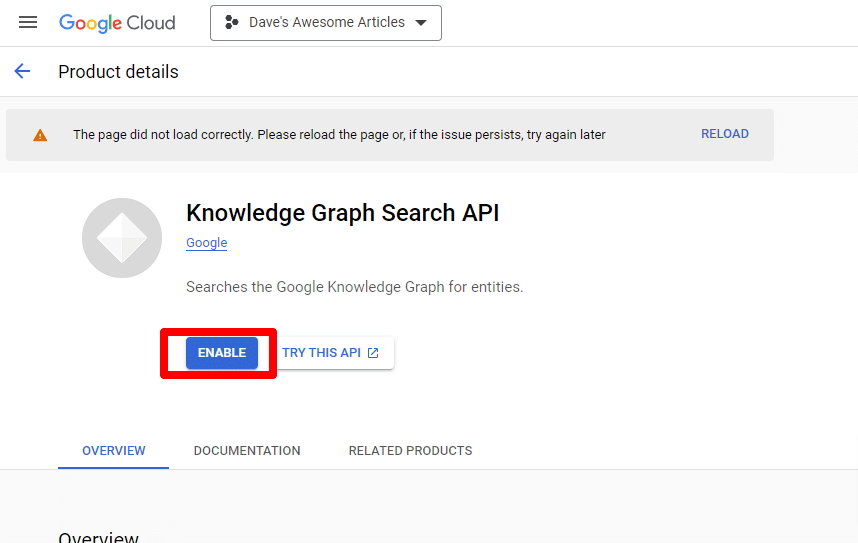
Veți fi apoi dus înapoi la pagina principală API, unde puteți crea acreditări:
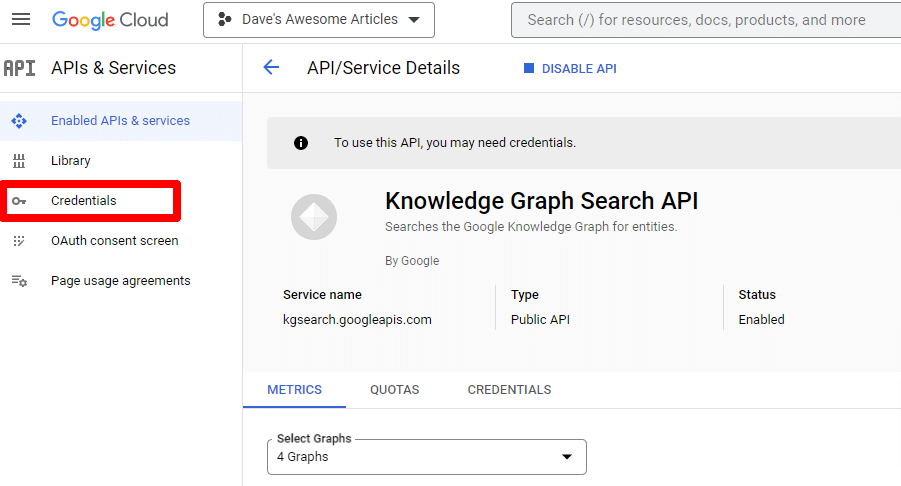
Și vom crea un cont de serviciu.
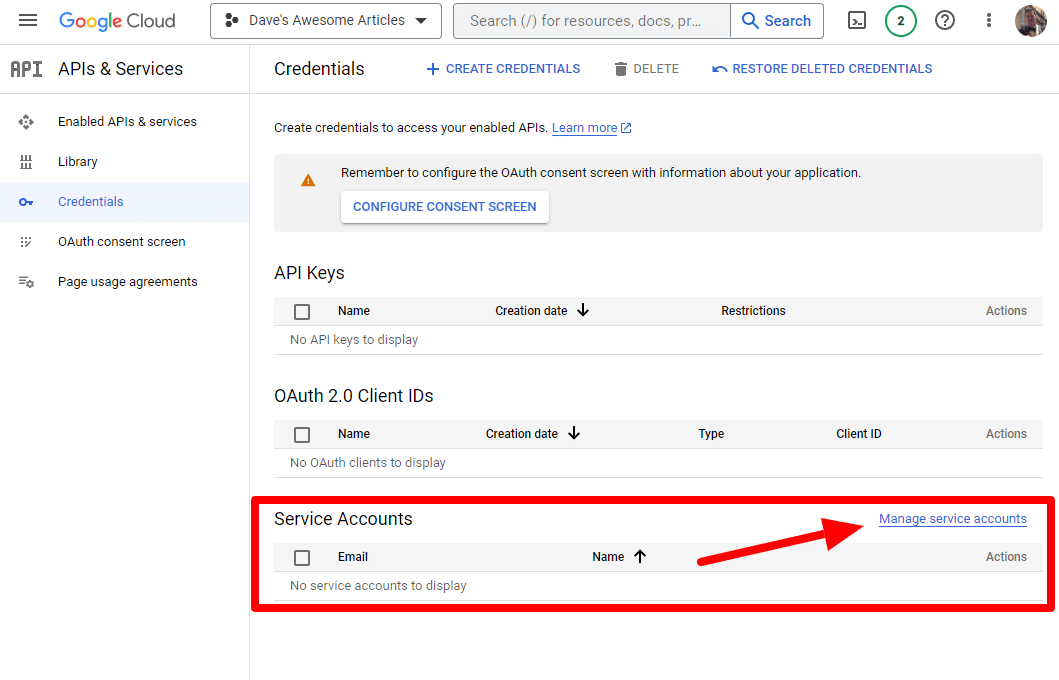
Pur și simplu creați un cont de serviciu:
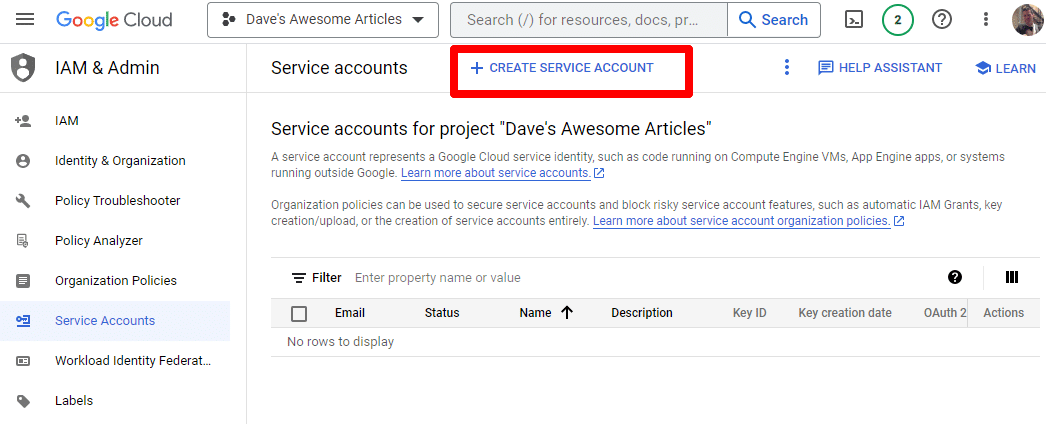
Completați informațiile solicitate:
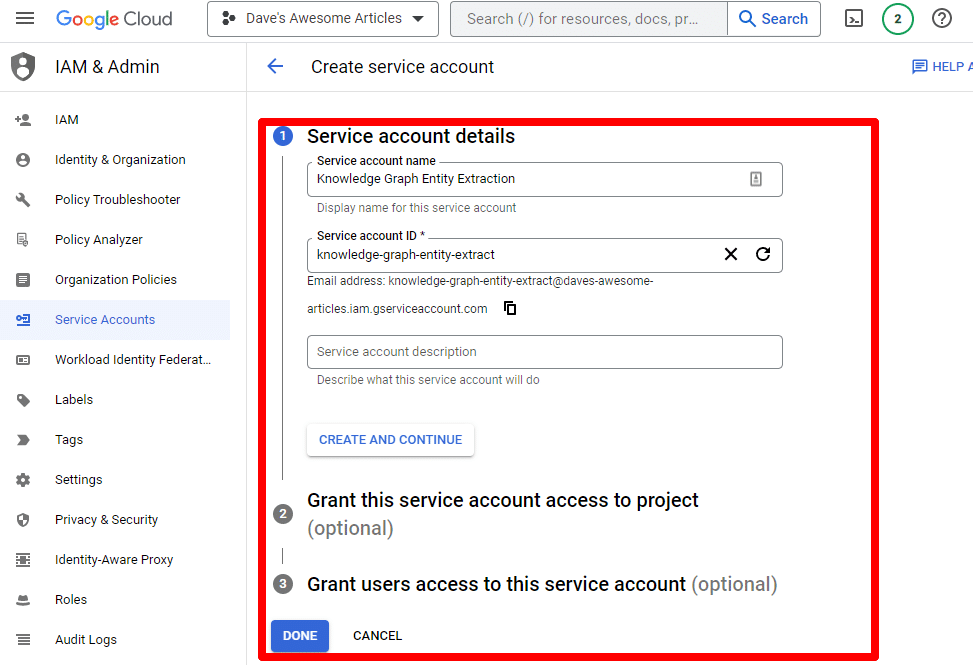
(Va trebui să îi dați un nume și să îi acordați privilegii de proprietar.)
Acum avem contul nostru de servicii. Tot ce a mai rămas este să ne creăm cheia.
Faceți clic pe cele trei puncte de sub Acțiuni și faceți clic pe Gestionați cheile .
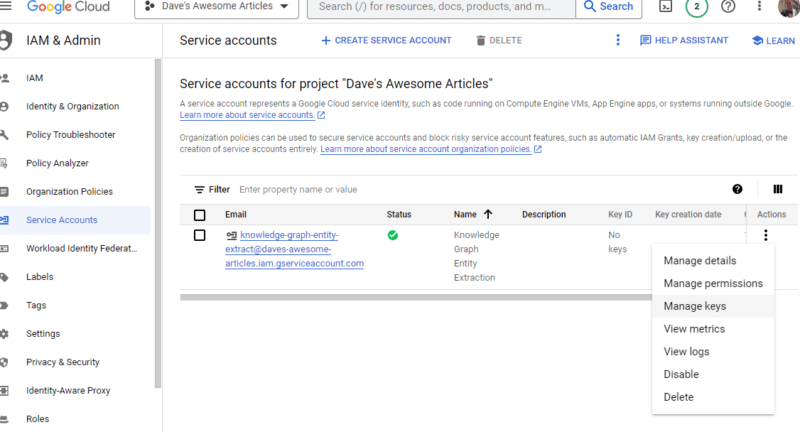
Faceți clic pe Adăugare cheie, apoi pe Creare cheie nouă :
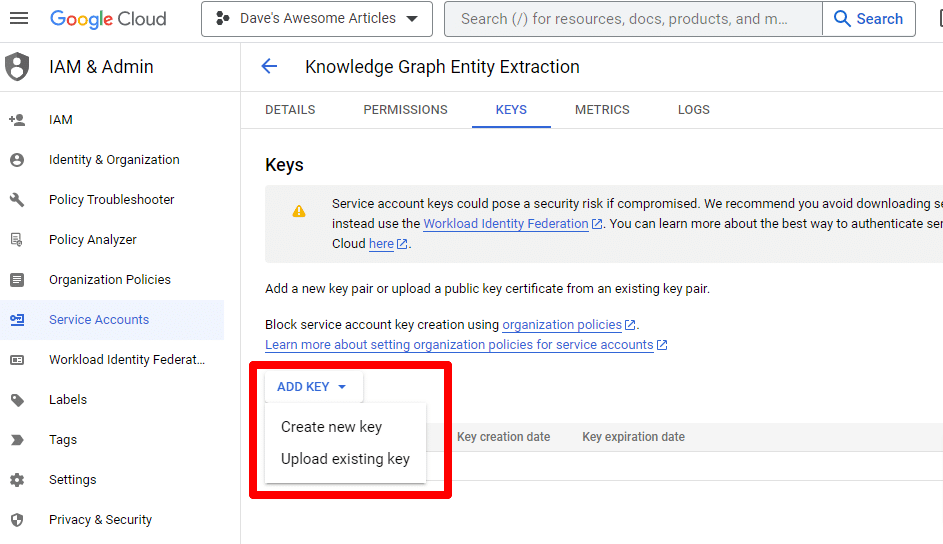
Tipul de cheie va fi JSON.
Imediat, îl veți vedea descărcat în locația implicită de descărcare.
Această cheie va oferi acces la API-urile dvs., așa că păstrați-o în siguranță, la fel ca API-ul dvs. OpenAI.
Bine... și ne-am întors. Sunteți gata să continuați cu scenariul nostru?
Acum că le avem, trebuie să ne definim cheia API și calea către fișierul descărcat. Codul pentru a face acest lucru este:
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/PATH-TO-FILE/FILENAME.JSON' %env OPENAI_API_KEY=YOUR_OPENAI_API_KEY openai.api_key = os.environ.get("OPENAI_API_KEY") Veți înlocui YOUR_OPENAI_API_KEY cu propria dvs. cheie.
De asemenea, veți înlocui /PATH-TO-FILE/FILENAME.JSON cu calea către cheia contului de serviciu pe care tocmai ați descărcat-o, inclusiv numele fișierului.
Rulați celula și sunteți gata să mergeți mai departe.
Pasul 4: Creați funcțiile
În continuare, vom crea funcțiile pentru:
- Răzuiți pagina web pe care am introdus-o mai sus.
- Analizați conținutul și extrageți entitățile.
- Generați un articol folosind GPT-4.
#The function to scrape the web page def scrape_url(url): response = requests.get(url) soup = BeautifulSoup(response.content, "html.parser") paragraphs = soup.find_all("p") text = " ".join([p.get_text() for p in paragraphs]) return text #The function to pull and analyze the entities on the page using Google's Knowledge Graph API def analyze_content(content): client = language_v1.LanguageServiceClient() response = client.analyze_entities( request={"document": language_v1.Document(content=content, type_=language_v1.Document.Type.PLAIN_TEXT), "encoding_type": language_v1.EncodingType.UTF8} ) top_entities = sorted(response.entities, key=lambda x: x.salience, reverse=True)[:10] for entity in top_entities: print(entity.name) return top_entities #The function to generate the content def generate_article(content): openai.api_key = os.environ["OPENAI_API_KEY"] response = openai.ChatCompletion.create( messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, {"role": "user", "content": content}], model="gpt-4", max_tokens=1500, #The maximum with GPT-3 is 4096 including the prompt n=1, #How many results to produce per prompt #best_of=1 #When n>1 completions can be run server-side and the "best" used stop=None, temperature=0.8 #A number between 0 and 2, where higher numbers add randomness ) return response.choices[0].message.content.strip()Acesta este cam exact ceea ce descriu comentariile. Creăm trei funcții pentru scopurile prezentate mai sus.
Ochii ageri vor observa:
messages = [{"role": "system", "content": "You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well."}, Puteți edita conținutul ( You are a highly skilled writer, and you want to produce articles that will appeal to users and rank well. ) și să descrii rolul pe care vrei să-l asume ChatGPT. De asemenea, puteți adăuga ton (de exemplu, „Ești un scriitor prietenos...”).
Pasul 5: Răzuiți adresa URL și imprimați entitățile
Acum ne murdărim mâinile. Este timpul să:
- Răzuiți adresa URL pe care am introdus-o mai sus.
- Extrageți tot conținutul care se află în etichetele de paragraf.
- Rulați-l prin API-ul Google Knowledge Graph.
- Ieșiți entitățile pentru o previzualizare rapidă.
Practic, vrei să vezi orice în acest stadiu. Dacă nu vedeți nimic, verificați un alt site.
content = scrape_url(url) entities = analyze_content(content)Puteți vedea că linia unu apelează funcția care răzuiește adresa URL pe care am introdus-o prima dată. A doua linie analizează conținutul pentru a extrage entitățile și valorile cheie.
O parte a funcției analize_conținut tipărește și o listă a entităților găsite pentru referință și verificare rapidă.
Pasul 6: Analizați entitățile
Când am început să joc cu scenariul, am început cu 20 de entități și am descoperit rapid că de obicei sunt prea multe. Dar implicit (10) este corect?
Pentru a afla, vom scrie datele în W&B Tables pentru o evaluare ușoară. Va păstra datele pe termen nelimitat pentru o evaluare viitoare.
În primul rând, va trebui să dureze aproximativ 30 de secunde pentru a vă înscrie. (Nu vă faceți griji, este gratuit pentru acest tip de lucru!) Puteți face acest lucru la https://wandb.ai/site.
Odată ce ați făcut asta, codul pentru a face acest lucru este:
run = wandb.init(project="Article Summary With Entities") columns=["Name", "Salience"] ent_table = wandb.Table(columns=columns) for entity in entities: ent_table.add_data(entity.name, entity.salience) run.log({"Entity Table": ent_table}) wandb.finish()Când rulează, rezultatul arată astfel:
Și când dați clic pe link pentru a vizualiza alergarea, veți găsi:
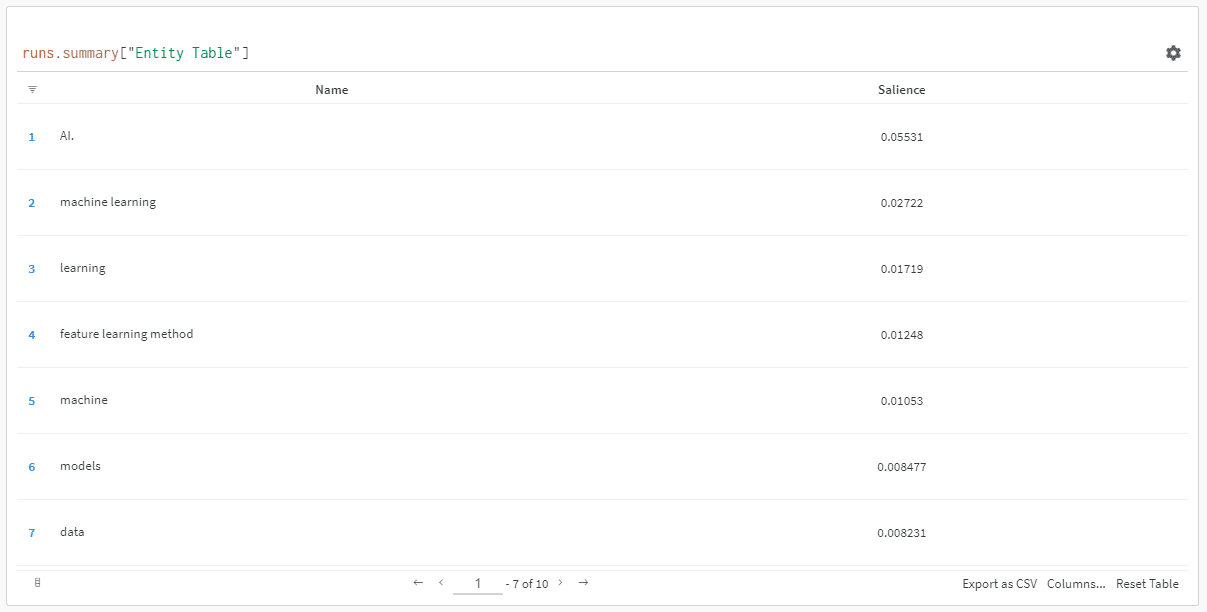
Puteți vedea o scădere a scorului de proeminență. Rețineți că acest scor calculează cât de important este acel termen pentru pagină, nu pentru interogare.
Când examinați aceste date, puteți alege să ajustați numărul de entități în funcție de importanță sau doar când vedeți pop-up termeni irelevanți.
Pentru a ajusta numărul de entități, ați merge la celula cu funcții și ați edita:
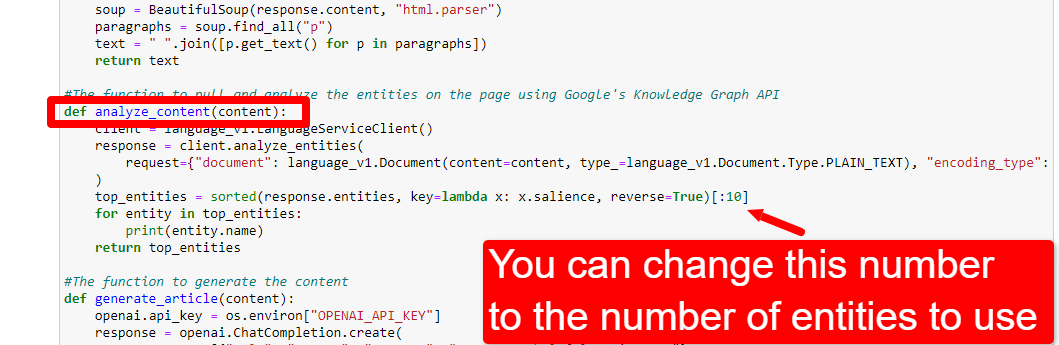
Va trebui apoi să rulați din nou celula și cea pe care ați rulat-o pentru a răzui și analiza conținutul pentru a utiliza noul număr de entități.
Pasul 7: Generați schița articolului
Momentul pe care l-ați așteptat cu toții, este timpul să generați schița articolului.
Acest lucru se face în două părți. Mai întâi, trebuie să generăm promptul prin adăugarea celulei:
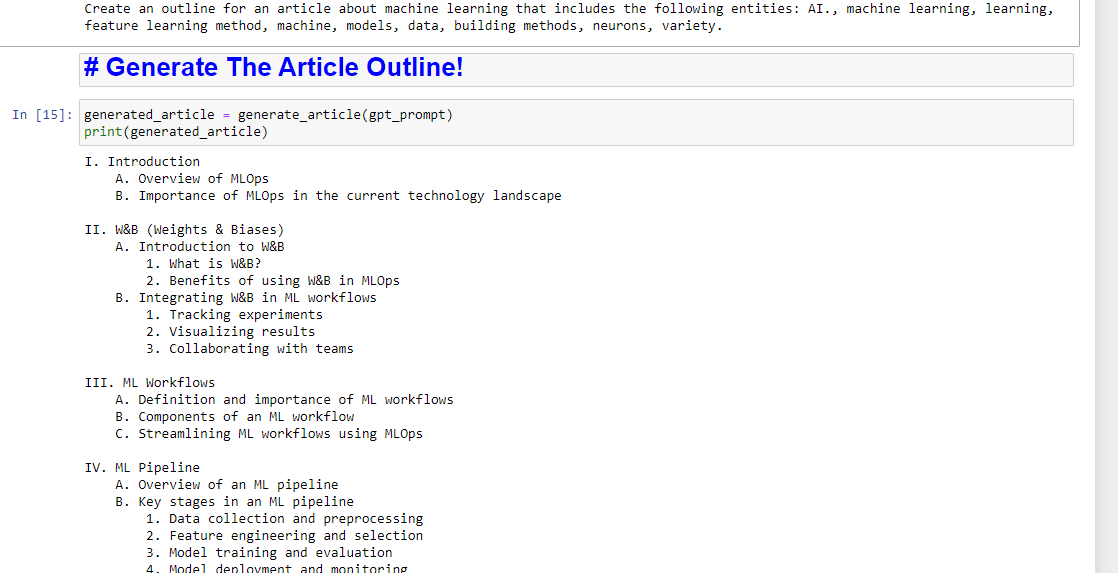
entity_names = [entity.name for entity in entities] gpt_prompt = f"Create an outline for an article about {query} that includes the following entities: {', '.join(entity_names)}." print(gpt_prompt)Acest lucru creează, în esență, un prompt pentru a genera un articol:

Și apoi, tot ce rămâne este să generați schița articolului folosind următoarele:
generated_article = generate_article(gpt_prompt) print(generated_article)Care va produce ceva de genul:
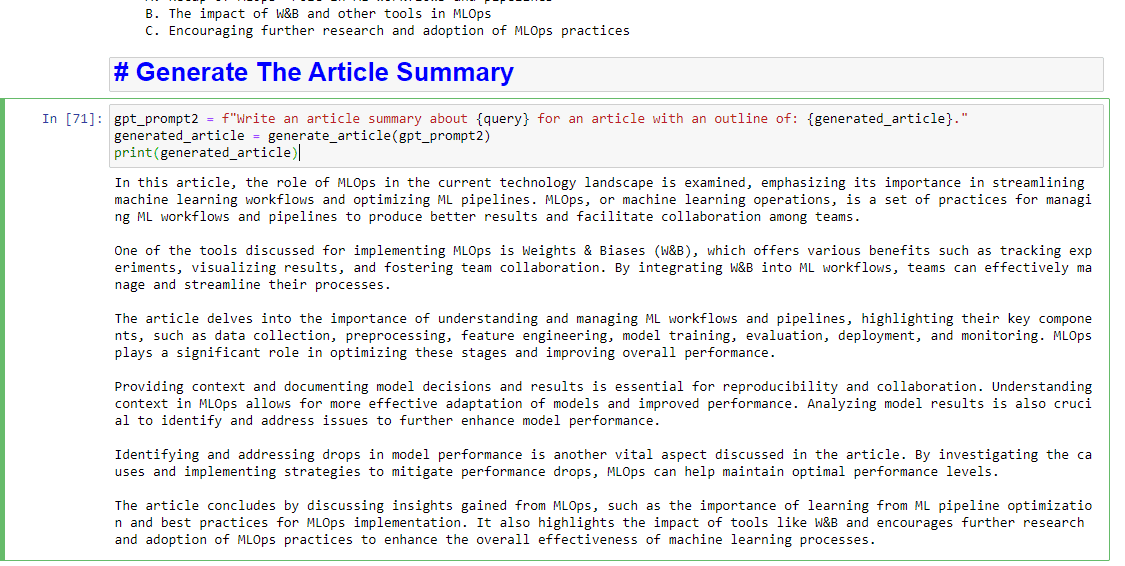
Și dacă doriți să obțineți și un rezumat, puteți adăuga:
gpt_prompt2 = f"Write an article summary about {query} for an article with an outline of: {generated_article}." generated_article = generate_article(gpt_prompt2) print(generated_article)Care va produce ceva de genul:
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.