
Cum să profitați la maximum de API-ul Google Search Console folosind expresia regulă
Publicat: 2022-11-02Google Search Console este un instrument uimitor care oferă date de căutare neprețuite de către utilizatori reali direct de la Google. În timp ce diagramele și tabelele sunt ușor de utilizat, o mare parte a datelor nu este accesibilă din interfața de utilizare.
Singura modalitate de a ajunge la aceste date ascunse este să utilizați API-ul și să extrageți toate acele date valoroase de căutare care vă sunt disponibile - dacă știți cum. Acest lucru este posibil cu expresii regulate.
Iată cum puteți maximiza API-ul Google Search Console folosind expresii regulate, potrivit Eric Wu, VP Product Growth la Honey, o companie PayPal, care a vorbit la SMX Advanced.
Diagnosticarea problemelor SEO cu GSC
Lucrezi la un site web care se confruntă cu o creștere stagnantă sau în scădere sau cu o scădere a actualizării de bază?
Majoritatea profesioniștilor SEO apelează la Google Search Console (GSC) pentru a diagnostica astfel de probleme.
(Sau, dacă resursele permit, puteți chiar să utilizați un instrument plătit precum Ryte sau să vă construiți propria platformă.)
Din fericire pentru comunitatea SEO, nu lipsesc tablourile de bord Looker Studio (fostul Google Data Studio) utile pentru analiza GSC, inclusiv:
- Tabloul de bord gratuit al Aleydei Solis, care utilizează datele GSC pentru a identifica cu ușurință potențialele modificări ale clasamentelor din ultimele zile de la Google Core Update.
- Tabloul de bord pentru monitorizarea traficului de căutare Google, care acum extrage datele de trafic Discover și Știri Google.
- Hannah Butler Search Console Explorer Studio. (Și dacă doriți să manipulați datele GSC în mod practic și să găsiți informații rapide, puteți utiliza Foaia de explorare a consolei de căutare a lui Butler.)
Tablourile de bord permit SEO să analizeze o privire de ansamblu asupra diferitelor tendințe, spre deosebire de utilizarea GSC și de a face mai multe clicuri pentru a ajunge la datele de care aveți nevoie.
Dar dacă analizați site-uri de întreprindere, puteți întâlni unele blocaje.
- Looker Studio și Google Sheets se încarcă lent, mai ales când aveți de-a face cu site-uri mari.
- Interfața GSC are o limită de export de 1.000 de rânduri.
- GSC are o problemă uriașă de eșantionare. Potrivit Similar.ai, echipele de SEO pentru întreprinderi ratează 90% din cuvintele cheie GSC. Și dacă știți cum să extrageți datele, puteți obține de fapt de 14 ori cuvintele cheie.
Depășirea problemei de eșantionare a GSC
Explorer pentru căutare este un alt instrument pe care îl puteți utiliza pentru analiza GSC. De la Noah Learner și echipa de la Two Octobers, este construit cu conducte de date folosind API-ul GSC care apoi trimite date către BigQuery (în principiu, ocolind Google Sheets și descarcând fișiere CSV), apoi vizualizează informații cu Data Studio.
Cu aceasta, puteți avea încredere că ajungeți la aproape toate datele.
Există încă o avertizare din cauza problemei de eșantionare a GSC, în special pentru site-urile mari de comerț electronic cu multe categorii diferite. GSC nu va afișa neapărat toate datele care vin din acele directoare.
După ce a efectuat diverse teste pentru a obține cele mai multe date din API-ul GSC, echipa Similar.ai a descoperit o modalitate de a reduce decalajul de eșantionare GSC.
Ei au descoperit că, adăugând mai multe subdirectoare ca profiluri diferite în tabloul de bord GSC, puteți extrage și mai multe date, deoarece Google vă oferă mai multe informații la acel nivel inferior.
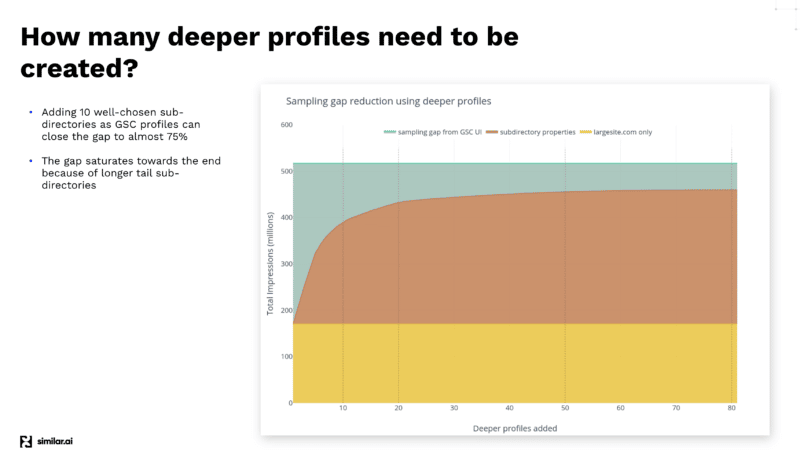
De exemplu, dacă vă uitați la example.com/televisions și adăugați „televizoare” ca subdirector în profilul dvs. GSC, Google vă va oferi numai cuvintele cheie și informațiile despre clic pentru acel subdirector și în jos.
Și adăugând multe dintre aceste subdirectoare diferite, puteți extrage mult mai multe informații.
Aceasta rezolvă problema eșantionării, dar puteți obține și mai multe date utilizând expresii regulate.
Obținerea mai multor date GSC cu expresii regulate
Expresia regulată sau regex este un instrument puternic pentru a vă înțelege datele.
În aprilie 2021, Google a adăugat suport regex la GSC – oferind SEO-urilor mai multe modalități de a tăia și tăia datele de căutare organice.
De multe ori, datele nu sunt utile decât dacă le puteți înțelege. Și regex ajută la extragerea de informații utile din datele bogate ale GSC.
Dar oricât de puternic ar fi, regex poate fi dificil de învățat.
Cel mai bun loc pentru a înțelege și a aprofunda în expresiile regulate este documentația oficială Google pe GitHub. (Google folosește RE2 în produsele sale, care este o aromă de expresie regulată.)
În timp ce regex este disponibil în tot felul de limbaje de programare diferite, îl veți găsi aproape peste tot, chiar și pentru cei care modifică fișierele .htaccess.
În următoarele câteva secțiuni sunt cazuri de utilizare pentru utilizarea regex pentru GSC.
Interogări informaționale Regex
Când vă uitați la interogările reale de căutare informațională în GSC, de obicei doriți să înțelegeți:
- Cum vin oamenii de fapt pe site-ul tău?
- Ce întrebări extrag ei?
Privind aceste lucruri dintr-un punct de vedere unic, în cadrul GSC poate fi dificil.
Cauți mereu cuvintele „ce”, „cum”, „de ce” și apoi „când”.
Există câteva moduri de a face extragerea interogărilor informaționale mai puțin plictisitoare cu regex.
Daniel K. Cheung a distribuit un șir regex care vă va afișa toate interogările care conțin „ce”, „cum”, „de ce” și „când” care au primit fie un clic, fie o impresie:
-
"what|how|why|when"
Și acest șir regex partajat de Steve Toth duce exemplul anterior la un nivel superior:
-
^(who|what|where|when|why|how)[" "]
Puteți folosi acest șir dacă doriți să capturați interogări bazate pe întrebări care încep fie cu „cine”, „ce”, „unde”, „când”, „de ce” și „cum”, apoi urmate de un spațiu.
Aceasta este o listă grozavă de folosit atunci când căutați orice tip de cuvânt care ar începe o întrebare:
- sunt, pot, nu pot, ar putea, nu ar putea, a făcut, nu a făcut, nu, nu, cum, dacă, este, nu este, ar trebui, nu ar trebui, a fost, nu a fost, au fost, nu au fost, ce, când, unde, cine, cui, cui, de ce, vor, nu vor, ar fi, nu ar fi
A pune toate acestea în formă regex ar arăta cam așa:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
În acest șir de 178 de caractere:
- Aveți semnul indicator (
^) care vă spune că interogarea trebuie să înceapă cu acest cuvânt: - Cuvintele sunt separate cu țevi (
|) în loc de virgule. - Toate cuvintele sunt împachetate în paranteze.
- Există o bară oblică inversă și „s” (
\s) care denotă un spațiu după cuvânt.
Acest lucru este bun, dar poate deveni și obositor de făcut.
Mai jos, Wu a simplificat lista anterioară de cuvinte pentru a fi mai prietenoasă cu expresiile regex și mai scurtă, ceea ce este ideal pentru copiere și lipire. Menținerea în acest fel ajută și la eficiență.
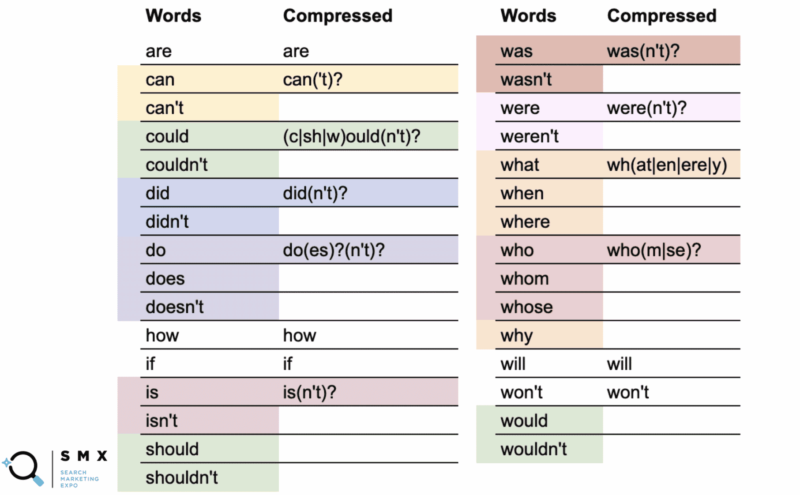
În prima coloană sunt cuvintele normale, iar în a doua coloană, expresia regex comprimată.
De exemplu, cuvântul „poate” folosește versiunea comprimată can('t)? .
Ceea ce indică semnul întrebării este că orice dintre paranteze este opțional. Sintaxa comprimată vă permite să acoperiți atât cuvântul „poate”, cât și „nu se poate”.
Mai interesant, puteți face acest lucru cu could/couldn’t, should/shouldn’t și would/wouldn’t unde partea -ould a cuvintelor este baza comună, cum ar fi (c|sh|w)ould(n't)? . Acest șir scurt acoperă toate cele șase cazuri.
În timp ce simplificarea acestei lungi liste de cuvinte a făcut șirul mai puțin lizibil, ceea ce este grozav este că se potrivește mai mult în câmpul regex și vă permite să copiați și lipiți mai ușor.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Dacă faci un pas mai departe, îl poți comprima și mai mult. În acest caz, Wu a redus numărul de caractere de la 135 la 113 caractere.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Expresiile regulate pot deveni foarte complicate. Dacă primiți un șir regex de la altcineva și doriți să clarificați ce face ce, puteți utiliza Regexper pentru a vă ajuta să îl vizualizați.
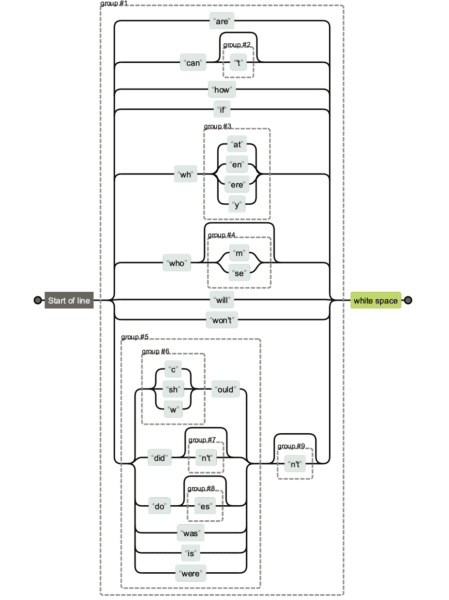
Mai jos veți vedea o comparație a diferitelor versiuni de șiruri regex. Este mai ușor să îl întreținem pe primul și, evident, mai greu să îl întreținem și să îl citești pe ultimul.

Dar uneori numărul de caractere va conta cu adevărat, mai ales atunci când aveți expresii regulate mai lungi.
Limitele filtrului de regex pentru GSC sunt de 4.096 de caractere, potrivit avocatului de căutare Google, Daniel Waisberg.
Asta ar părea destul de puțin. Cu toate acestea, dacă aveți un site de comerț electronic și trebuie să adăugați nume de domenii, subdomenii sau directoare mai lungi, cel mai probabil veți atinge această limită.
Interogări cu marca Regex
Un alt exemplu în care puteți începe să atingeți limita de caractere regex în GSC este atunci când îl utilizați pentru interogări de marcă.
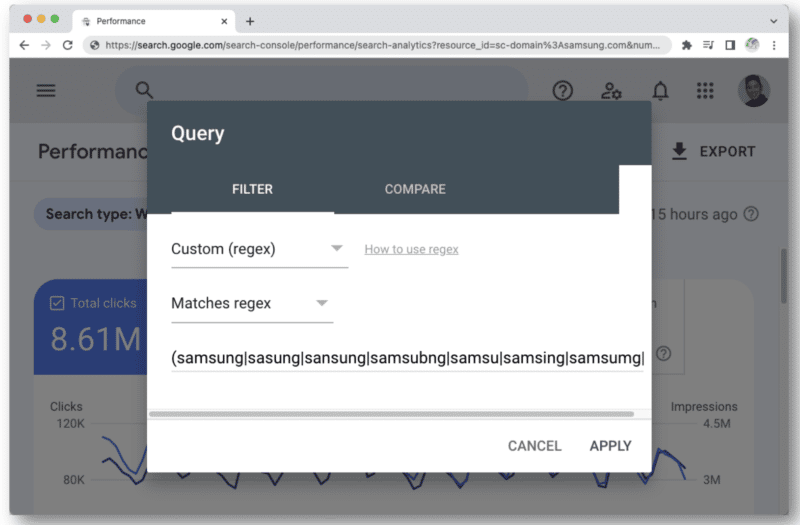
Când vă gândiți la toate tipurile diferite de greșeli de ortografie ale unui nume de marcă pe care o persoană le-ar putea introduce, veți întâlni rapid acel număr de 4.096 de caractere. De exemplu:
- aamaung, damsung, mamsang, sam sung, samaung, samdung, samesung, sameung, samgsung, samgung, samsang, samsaung, samsgu, samshgg, samshng, samsing, samsnug, samssung, samsu, samsuag, samsubg, samsubng, samsug, samsumg , samsun g, samsunb, samsund, samsund, samsunh, samsunt...
Aici ajută înțelegerea expresiilor regex. Cu acest șir, puteți captura numele mărcii „samsung” împreună cu greșelile de ortografie:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
De multe ori, oamenii vor scrie greșit părțile din mijloc ale cuvântului. Dar, în general, au formatul și lungimea corect și vă puteți aborda sintaxa în acest fel.
Pentru greșelile de ortografie ale interogărilor de marcă, luați în considerare următoarele:
- Litere principale care alcătuiesc interogarea mărcii.
- Consoane .
- Litere care înconjoară consoanele dure .

În roșu sunt consoanele dure pe care oamenii de obicei nu le pierd atunci când introduc un nume de marcă. Acestea sunt literele principale care compun acel brand special. Pentru „samsung”, „s” la început, „m” la mijloc și apoi „n” și „g” la sfârșit.

Literele albastre care înconjoară acele consoane principale de pe tastatură sunt cele pe care oamenii de obicei scriu greșit. În exemplu, în jurul lui „s”, vedeți „a”, „d” și „z”. (Deși aspectul este diferit pentru tastaturile internaționale, conceptul este în continuare același.)
Șirul regex de mai sus captează toate variantele posibile de „samsung”.
Celălalt truc important aici este în [az\s]{1,4} .
În formă regex, aceasta spune practic: „Vreau să potrivesc orice literă „a” cu „z” sau un spațiu de una până la patru ori.
Aceasta surprinde toate acele greșeli de ortografie ciudate care se pot întâmpla în mijlocul unei interogări de marcă – în care o persoană poate apăsa aceeași tastă de mai multe ori sau poate apăsa accidental spațiu.
În plus, numele mărcii are o anumită lungime („samsung” are șapte caractere). Oamenii probabil nu vor sfârși prin a introduce 20-50 de caractere.
Deci, în această expresie obișnuită, bănuim că între „s” și „m” în „samsung”, cineva va scrie greșit 1-4 caractere. Și apoi de la „m” la „g” la sfârșit, vor introduce greșit 1–6 caractere, cu spații incluse.
Adăugarea tuturor acestor lucruri vă permite să capturați cuprinzător numeroasele variante ale unei interogări de marcă.
Un alt lucru de remarcat este că numele mărcii poate apărea în diferite părți ale interogării.

Deci trebuie să ne asigurăm că numele mărcii în sine este capturat. Ar trebui să fie fie:
- La începutul interogării.
- În mijlocul interogării (înconjurat astfel de spații).
- Sau la sfârșitul interogării.
Expresia regulată pentru aceasta este următoarea:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Aceasta captează toate interogările în care numele mărcii „samsung” este fie la început, la mijloc sau la sfârșit.
- Începutul șirului =
^ - Înconjurat de spații =
\s - Sfârșitul șirului =
$
Postarea lui JC Chouinard, Expresii regulate (RegEx) din Google Search Console, aprofundează și mai mult în exemplele de expresii regulate.
Regex și API-ul GSC în acțiune
Expresiile regulate au fost utile pentru Wu și echipa sa atunci când au lucrat cu un client care a întâmpinat scăderi de trafic în urma unei actualizări de bază.
După ce s-au uitat la diferitele probleme ale site-ului de comerț electronic, au descoperit că problema rezidă în unele pagini cu detalii despre produse.
Au trebuit să segmenteze tipurile de pagini pentru analiză în GSC. Dar aceasta a fost o sarcină complexă din cauza structurilor URL diferite pentru produsele din SUA și internaționale.

Adresele URL internaționale ale site-ului includ coduri de limbă și de țară, în timp ce adresele URL ale produselor din SUA nu.
Chiar și utilizarea sintaxei regex a fost dificilă, deoarece literele și liniuțele există în slug-ul de produs, categorii și subcategorii. În plus, trebuiau să filtreze adresele URL internaționale ale produselor pentru a captura numai paginile din SUA.
Pentru a obține toate paginile de destinație + detalii ale produselor din SUA ( nu paginile i18n), au venit cu următoarele șiruri regex:
Includeți: /([^/]+/){1,2}p?
Excludeți: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Iată o defalcare:

Echipa a dorit să se potrivească categoria, subcategoria și toate produsele, astfel încât acestea includ:
- Orice caracter care nu este o bară oblică =
[^/]+ - 1 sau 2 directoare =
/){1,2} - Uneori urmat de un produs slug =
p?
Un accent ( ^ ) înseamnă de obicei începutul șirului. Dar când este între paranteze (ca în [^/] ), indică o negație (adică, „nu nimic în această casetă”).
Deci acest șir /([^/]+/){1,2}p? înseamnă „Vreau orice număr de caractere care să nu fie o bară oblică, care să conducă la o bară oblică (care denotă directorul) și uneori urmate de litera „p” (prefixul pentru slug-uri de produs).”
În același timp, echipa nu a dorit să se potrivească combinația de țară și limbă care conținea și litere și liniuțe, așa că a exclus:
- Orice director de 2 litere =
[a-zA-Z]{2} - Combo cu 2 litere + 2 litere limba-țară =
[a-zA-Z]{2}-[a-zA-Z]{2}
Crearea unei expresii regulate care să se potrivească singură cu toate codurile de limbă și de țară ar fi plictisitoare din cauza tuturor combinațiilor posibile, așa că nu au putut aborda acest lucru așa cum au făcut-o pentru interogările informaționale (unde fiecare tip de combinație a fost exclus).
Dar chiar și după crearea acestor șiruri regex, au avut o problemă.
În Google Search Console, există un singur câmp pentru a lipi un șir regex. Va trebui să alegeți fie Se potrivește regex , fie Nu se potrivește regex – nu le puteți folosi pe ambele în același timp.
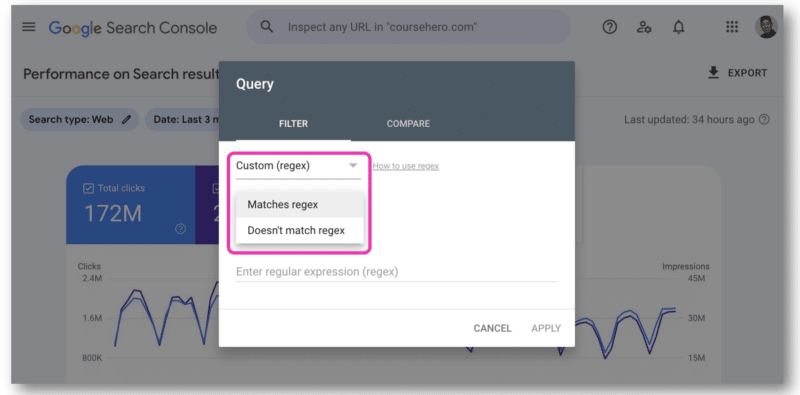
Aici a fost utilă API-ul GSC, deoarece permite alăturarea șirurilor de expresii regex.
În documentația API-ului Google Search Console, există un link Încercați acum .
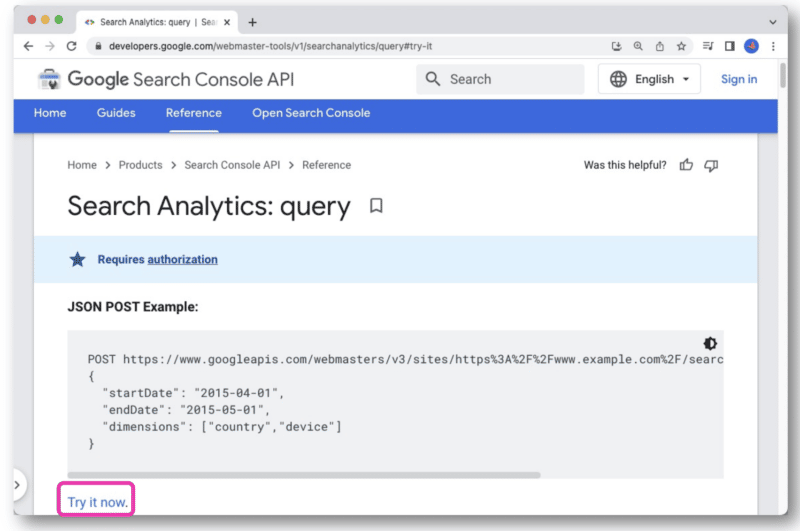
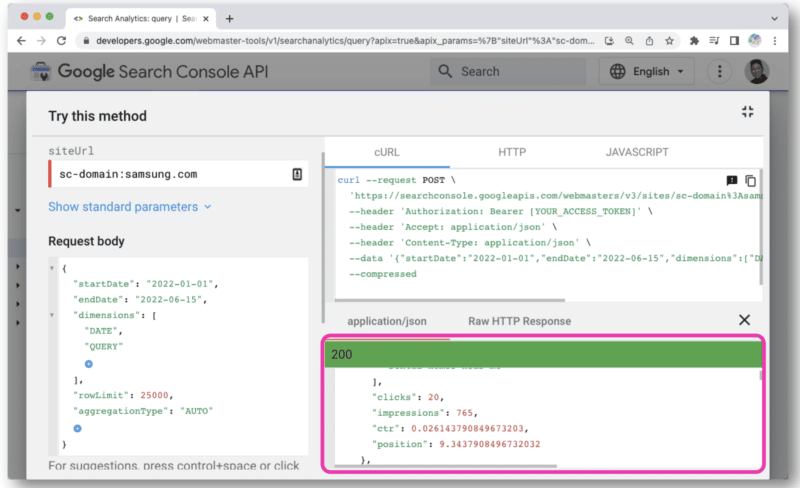
Odată făcut clic, se va deschide o consolă care vă permite să selectați un site și să faceți cererea dvs. API prin vizualizarea web.
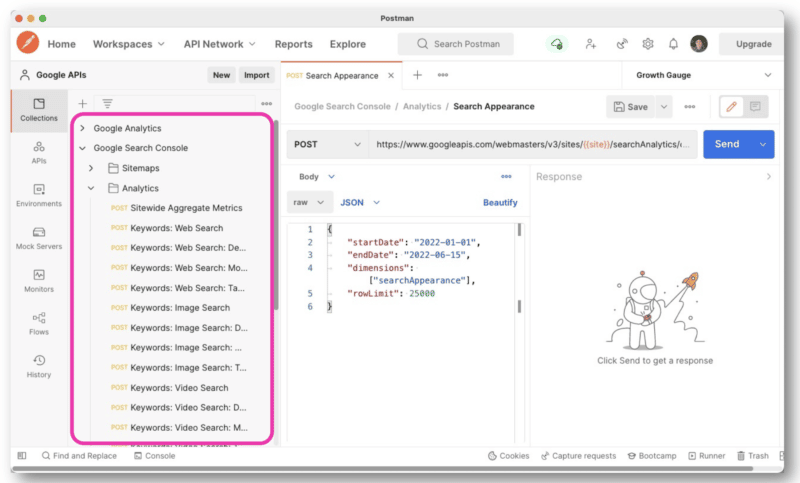
Dar pentru a gestiona mai bine interogările API, Wu recomandă să utilizați Postman pe desktop sau Paw (care este nativ pentru Mac).
Postman vă permite să creați interogări și să le salvați pentru mai târziu. Și dacă aveți acces la alte site-uri, nu trebuie să creați o interogare nouă de fiecare dată. Pur și simplu schimbați numele site-ului cu o variabilă și apoi faceți mai multe solicitări.
Paw, pe de altă parte, este mult mai ușor de privit și de utilizat.
Pentru a accesa API-ul, va trebui să obțineți cheile API. (Iată un tutorial util de la Chouinard.)
După ce obțineți aceste informații, veți avea ID-ul și secretele clientului, pe care le veți adăuga la autentificarea OAuth 2.0 fie în Postman, fie în Paw.
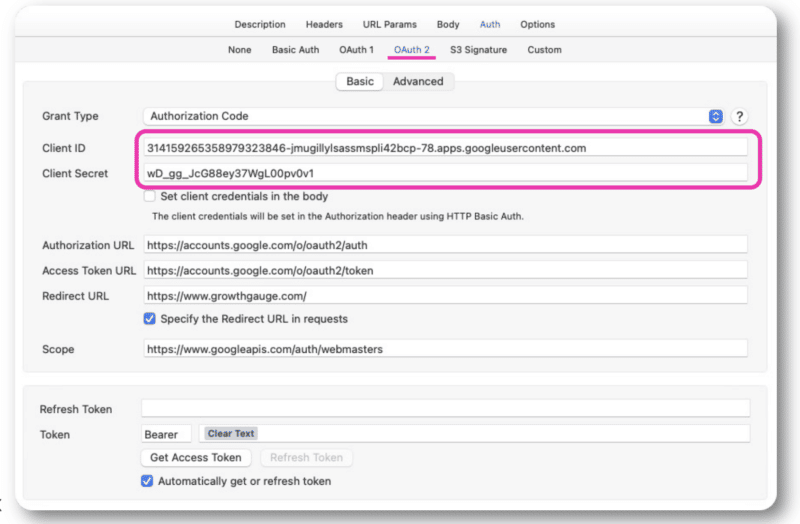
De acolo, vă veți putea conecta cu contul dvs. obișnuit.
Wu a făcut în principal solicitări GSC API folosind șirurile regex din Paw. Interogarea este introdusă în mijlocul interfeței.
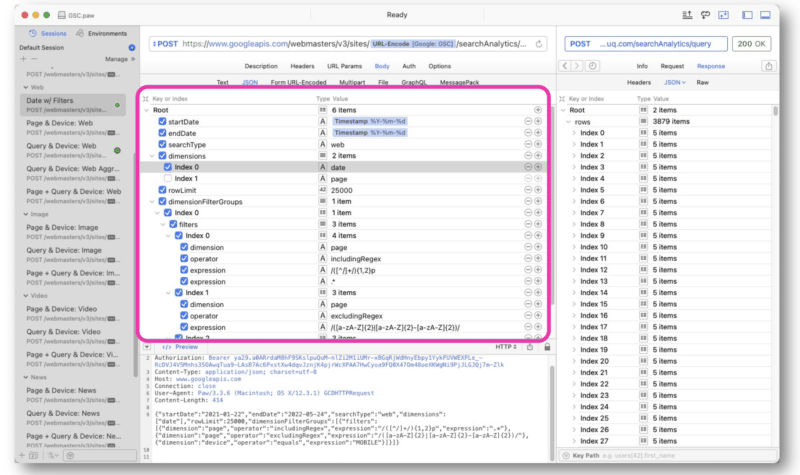
Răspunsul de la Google este similar cu cel al vizualizării web GSC API. Datele pot fi apoi exportate pentru procesare.
Deoarece datele sunt în JSON, informațiile pot fi dezordonate și greu de citit.

Pentru aceasta, puteți utiliza un procesor JSON de linie de comandă gratuit și open-source numit JQ pentru a imprima destul de mult informațiile.

Datele nu sunt atât de utile până când nu le introduceți într-o foaie de calcul. Introduceți fișierul pe care l-ați exportat din Paw în JQ. Deschideți-l și apoi repetați peste fiecare rând - salvând fiecare element, astfel încât să le puteți scoate într-un CSV.
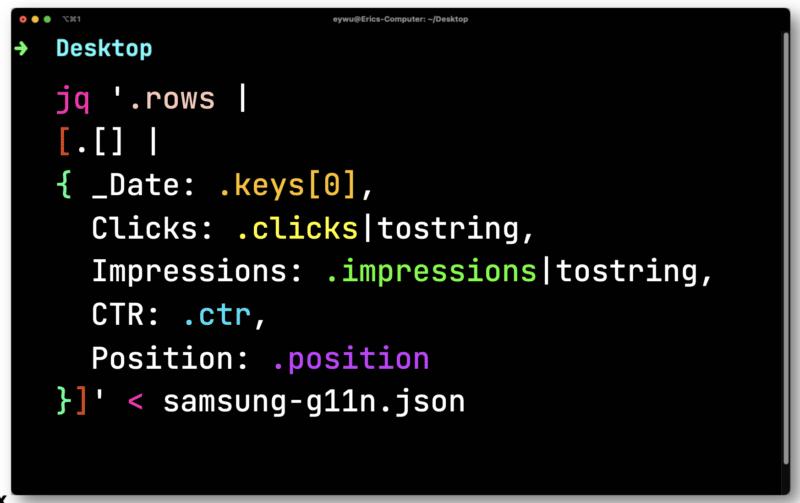
Aici, va trebui să convertiți clicurile și afișările care sunt flotanți (un număr care are o zecimală). Ambele trebuie convertite în șiruri compatibile cu un CSV.
JQ va scoate apoi următorul format mult mai simplu.
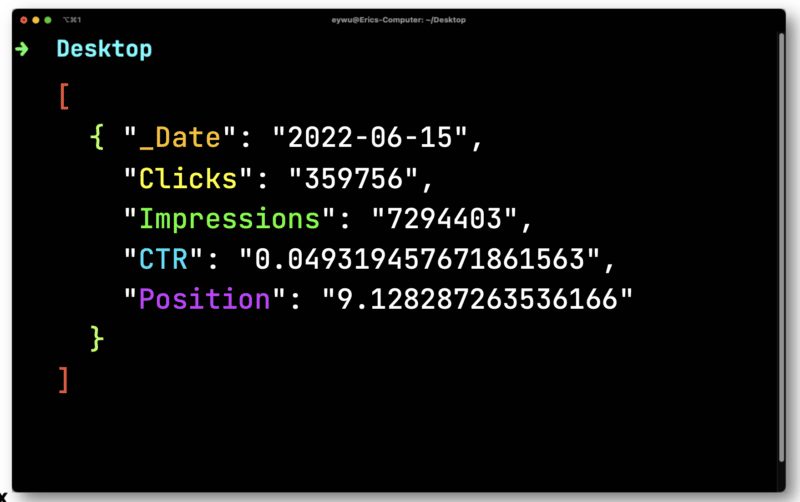
Apoi, veți folosi Dasel pentru a prelua acest format și apoi îl veți transforma într-un CSV.
Și iată rezultatul final.
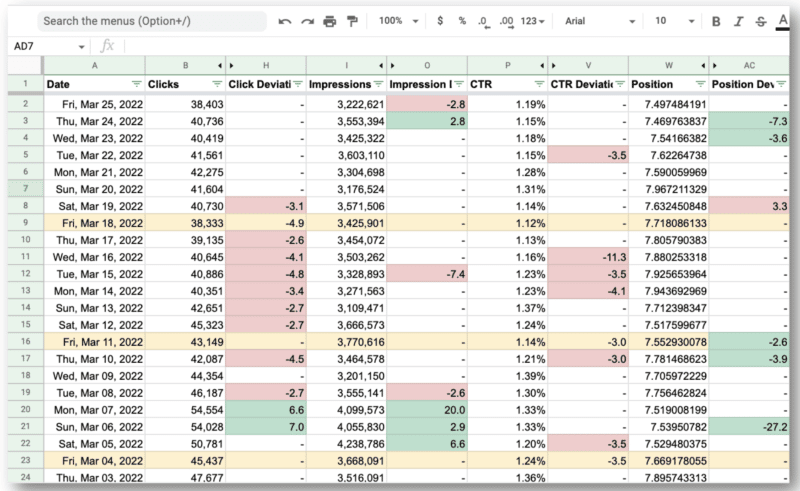
Ceea ce este uimitor pentru echipa lui Wu este că au putut folosi API-ul Google Search Console și expresiile regulate pentru a:
- Filtrați toate interogările internaționale și priviți doar SUA, unde au avut probleme principale.
- Identificați zilele în care site-ul a avut probleme.
Urmăriți: obțineți la maximum API-ul Google Search Console
Mai jos este videoclipul complet al prezentării SMX Advanced a lui Wu.